CIMD 汇集的不是随意爬取的网络文本,而是具有代表性的权威文本。来源主体包括国家法律法规、行业标准、学术期刊、科研院所、行业协会和券商机构,专业深度覆盖铁矿石资源、采选加工、烧结球团、炼铁生产等完整产业链。每条记录都保留 source_details 字段,可以回溯到原始来源。这种权威性使得基于 CIMD 训练的模型在专业深度、行业可信度和实际应用价值上具备更高上限。
完整数据体系:不是文件汇总,而是知识图谱
CIMD 的数据组织不是简单的文件堆积,而是围绕铁矿石及矿冶产业链建立的完整行业数据体系。整个体系包含 9 个一级分类、42 个二级分类和 335 个三级/四级来源节点,覆盖法律文件与法规依据、行业规章与管理办法、政策文件与行业指导、行业标准、专利与知识产权、学术与培训资料、互联网舆情与观点分析、企业经营与运营信息、行业研究与市场报告等核心门类。这种体系化组织为专题扩展、增量采集、行业补数、基准任务设计和数据资产编目提供了结构框架。
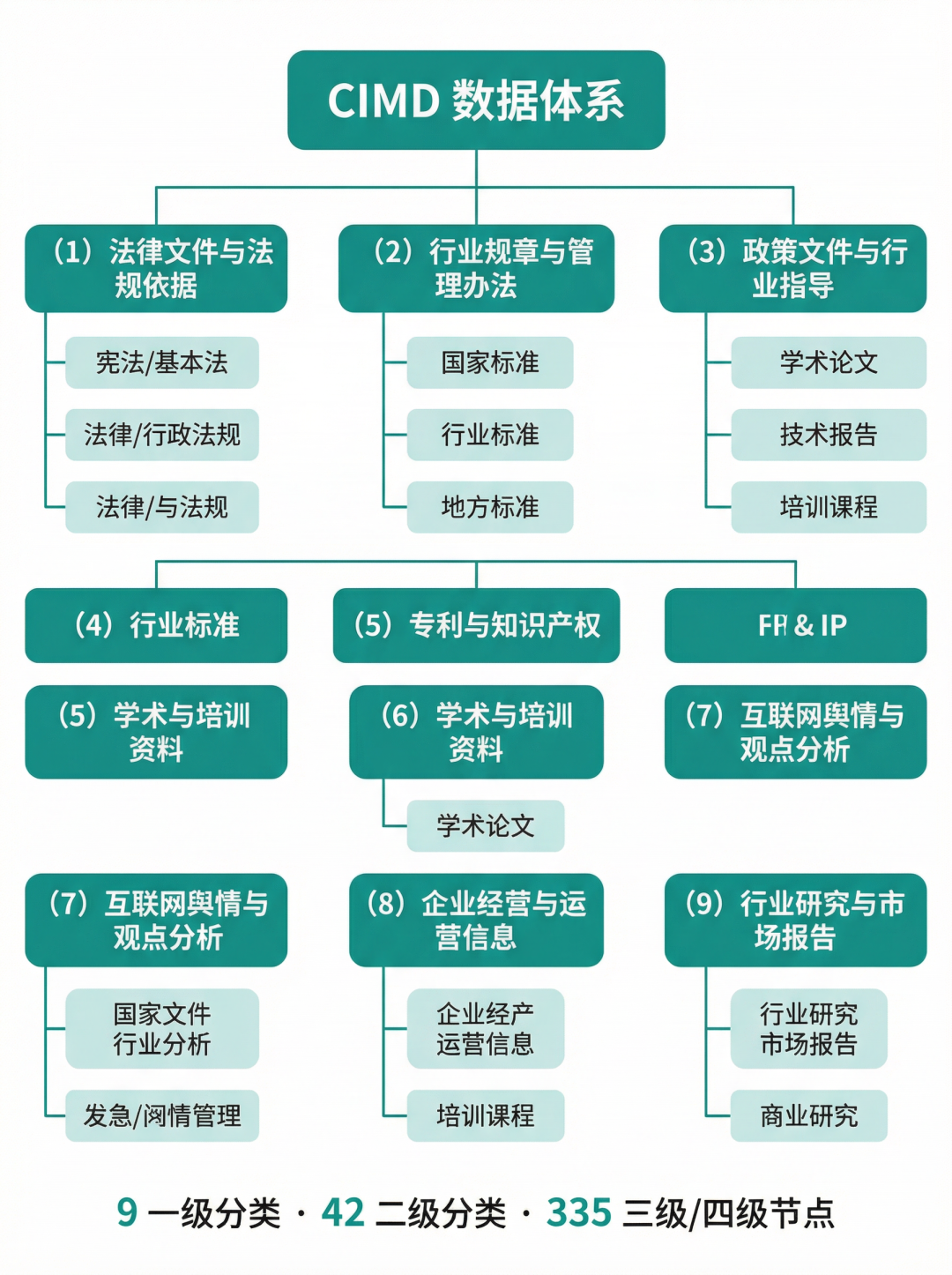
元数据完整:从"能用"到"好用"的关键
CIMD 在每条记录中保留了丰富的元数据字段,包括 file_id、data_id、title、source_type、author、original_time、content_time、language、keywords、license_type 和 source_details。使用者可以按来源筛选只使用法律法规或只使用学术论文,按时间过滤获取特定时间段的政策变化,按语言分类进行中英文分离或混合使用,还可以将检索到的文本片段回溯到原始文件。对于长文档检索、来源归因、审计留痕、授权控制、质量抽检和数据资产管理,这类记录级元数据比单纯正文更有操作价值。
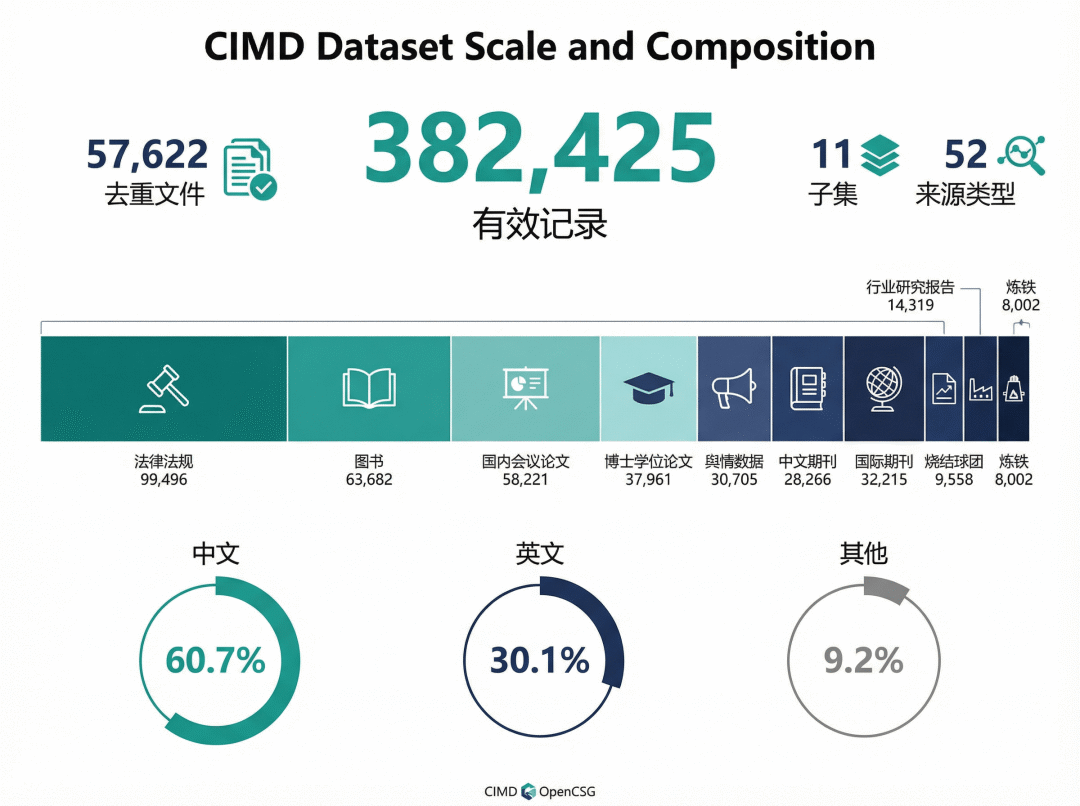
数据规模:38 万+记录,覆盖完整产业链
从语言分布来看,中文记录占 60.7%(232,169 条),英文记录占 30.1%(115,113 条),其他语言占 9.2%(35,143 条)。从来源类型来看,期刊论文最多达 116,926 条,其次是国家法律法规 95,394 条、学术出版物 57,492 条、学位论文 38,075 条、社会公众与自媒体舆情 31,178 条、企业基本信息 11,656 条、产能与产量数据 6,282 条、科研院所报告 5,143 条、行业协会报告 4,664 条和国内产业政策 2,393 条。
技术亮点:对标国家数据标准,面向可信流通
CIMD 的数据组织方式与国家数据局和全国数据标准化技术委员会发布的《高质量数据集 建设指南》《高质量数据集 格式要求》《高质量数据集 分类指南》《高质量数据集 质量评测规范》以及《国家数据基础设施建设指引》等系列标准保持同向。数据集将标识、来源、分类、时间、授权和来源说明直接放在记录体内,而不是外部台账,使得同一份快照可以直接进入数据目录编制、质量抽检、授权审计、责任追踪和可信流通流程,不需要在语料之外再补一套独立的元数据体系。这种设计使得 CIMD 不仅是一个研究数据集,更是一个符合国家数据基础设施建设方向的行业数据资产。
应用场景:从检索到 Agent 的全链路支撑
CIMD 的设计目标是直接可用于模型与应用,当前公开版本以统一 JSONL 格式发布,可直接进入:
场景一:垂直领域 RAG 系统
以铁矿石产业智能问答助手为例,当用户询问"2024 年铁矿石进口政策有哪些变化"时,系统可以沿着法律法规库、政策文件库、行业研究库到市场数据库的检索路径,基于跨来源证据链生成完整答案并标注来源。统一的 JSONL 格式可以直接接入向量数据库,完整的元数据支持精确过滤和来源归因,跨来源结构天然适配多跳推理。
场景二:行业 Agent 工作流
在矿企合规审查 Agent 的应用中,系统需要评估某矿企的环保合规性。完整的工作流包括检索相关法律法规和政策文件、查询企业经营信息和产能数据、对比行业标准和技术规范、分析舆情和行业研究报告,最终生成合规评估报告。完整的数据体系可以支撑这种复杂推理链,权威来源保证结论可信度,元数据则支持审计和责任追溯。
场景三:领域继续预训练与 SFT
在构建铁矿石产业垂直大模型时,预训练阶段可以使用全量 38 万+记录进行领域知识注入,SFT 阶段基于法规问答、技术问答、市场分析等构建指令数据,评测阶段则使用 CIMD 构建行业基准测试集。中英文混合语料提升多语言能力,跨来源结构增强知识融合能力,完整元数据支持数据筛选和质量控制。
场景四:文档智能与知识抽取
在产业知识图谱构建中,CIMD 可以支持矿企名称、矿区地点、技术术语等实体识别,企业-产能、政策-影响、技术-应用等关系抽取,以及政策发布、产能变化、市场波动等事件抽取。52 种来源类型覆盖完整产业链,丰富的关键词字段辅助标注,时间字段则支持时序分析。
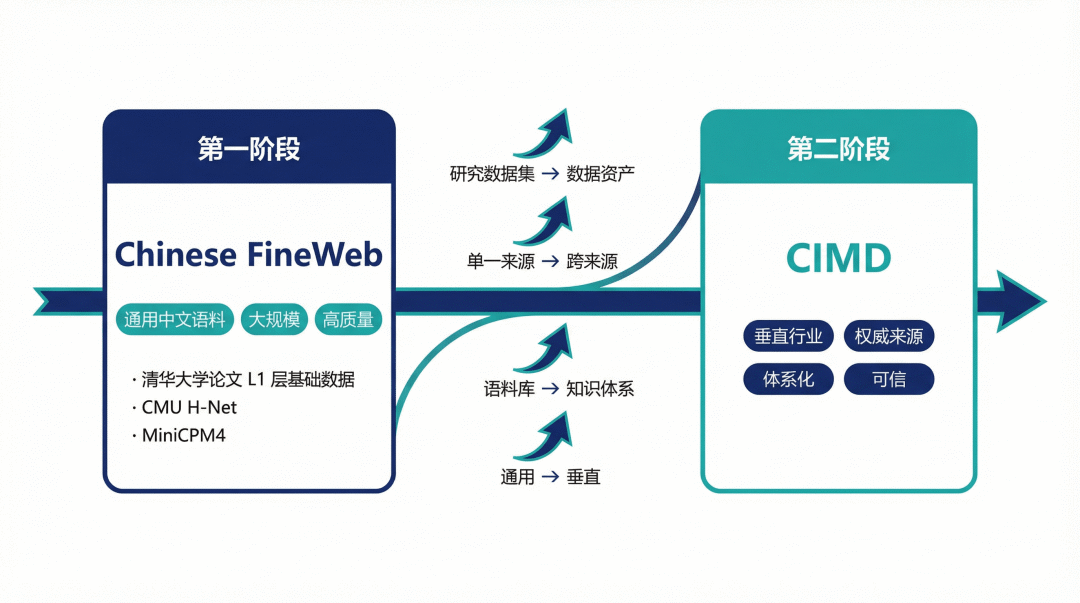
从 Chinese FineWeb 到 CIMD: OpenCSG 的数据战略演进
如果我们回顾 OpenCSG 的数据开源历程,会发现一条清晰的战略演进路径:
第一阶段:通用中文语料(Chinese FineWeb 系列)
这一阶段的目标是为中文大模型提供高质量预训练语料。Chinese FineWeb 被清华大学论文选为 L1 层基础数据,支撑了 CMU H-Net、MiniCPM4 等多个前沿模型,成为中文 AI 研发的必备资源。这一阶段的特点是通用、大规模、高质量。
第二阶段:垂直行业语料(CIMD)
这一阶段的目标是为行业 AI 提供专业知识底座。CIMD 实现了从通用走向垂直、从单一来源走向跨来源整合、从语料库走向知识体系、从研究数据集走向数据资产的创新。这一阶段的特点是专业、权威、体系化、可信。
这种演进反映了 OpenCSG 对 AI 发展趋势的深刻洞察:通用大模型是基础,垂直行业 AI 是未来。
开源承诺:商业友好,推动产业智能化
CIMD 采用OpenCSG 数据集许可协议 (OpenCSG Dataset License Agreement)。在 Hugging Face 和 OpenCSG 平台的仓库 metadata 中,license 字段标注为other,表示本数据集采用平台预设列表之外的自定义许可协议;数据集的实际许可条款以 OpenCSG 数据集许可协议为准。
该协议明确支持商业用途。使用者可以将数据集用于研究、评测、验证、内部开发、模型训练、模型微调、检索增强、质量分析和合规审查等场景。如果计划将本数据集、基于本数据集训练或增强的模型、系统、Agent、API 服务或商业产品用于商业场景,需要遵循该协议的相关条款。OpenCSG 的开源核心理念:既要保护数据来源方的合法权益和知识产权,又要为行业 AI 发展提供必要的数据支撑。通过清晰的授权边界、完善的合规要求和灵活的商业许可机制,CIMD 为企业合规使用行业数据、构建垂直 AI 能力提供了可信路径。
数据获取与使用指南
通过 Git 获取(推荐)
bash
git lfs installgitclonehttps://opencsg.com/datasets/OpenCSG/CIMD.gitcdCIMDgit lfs pull使用 Hugging Face datasets
bash
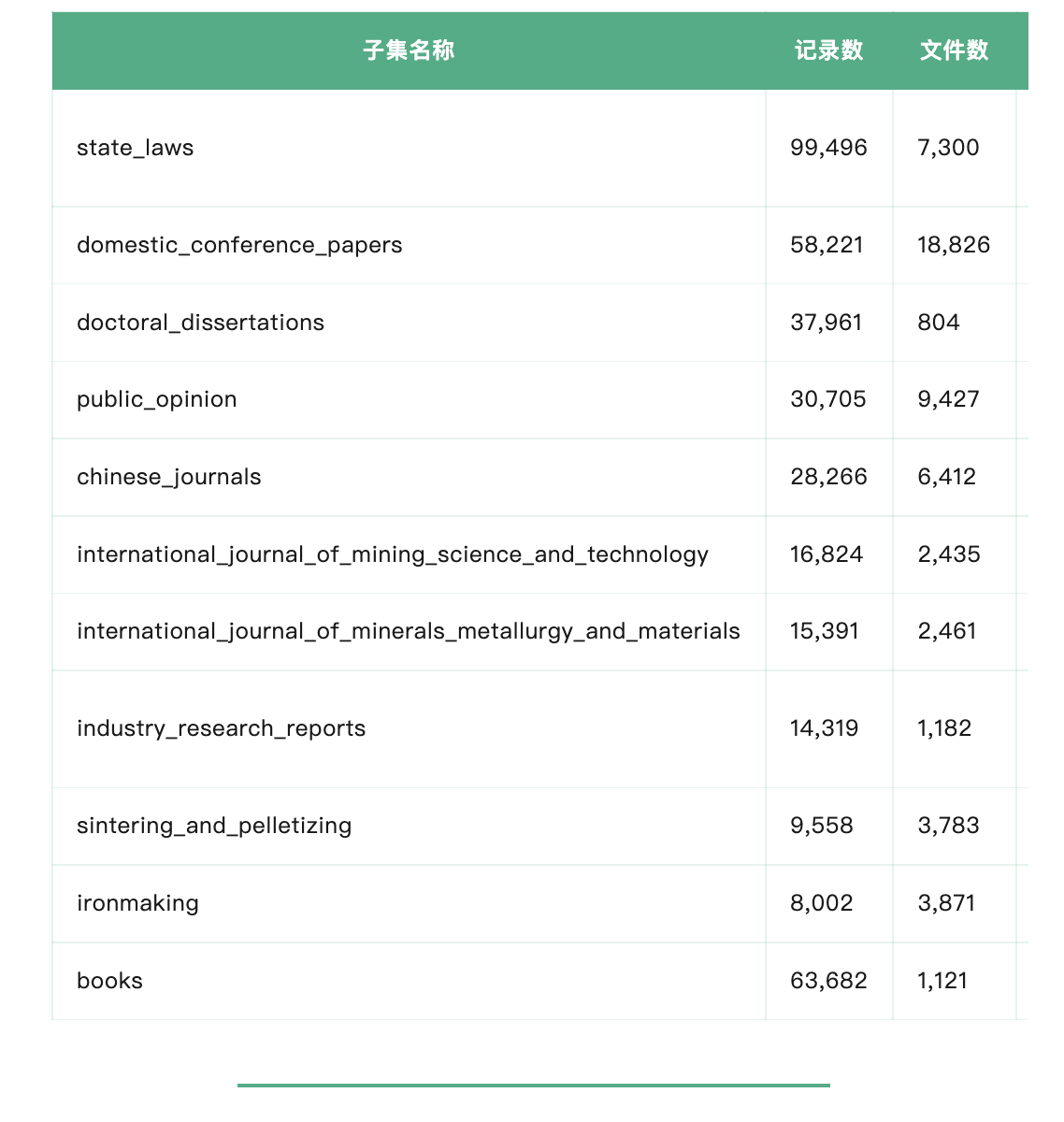
fromdatasetsimportload_datasetdataset = load_dataset( "OpenCSG/CIMD", "state_laws", # 可选子集 split="train", streaming=True,)11 个子集说明
使用注意事项
当前统计为解析记录数,不等同于去重后的原始文档数。子集通过 Git LFS 管理,clone 后需执行git lfs pull。不同来源之间可能存在重复、近重复或解析噪声。时间字段可能表示发布时间、内容时间或抽取时间,需结合具体记录判断。用于训练、分发或商用前,需结合来源信息核验实际授权范围。
展望:从铁矿石到更多行业
CIMD 的发布只是 OpenCSG 垂直行业数据战略的第一步。从数据体系的设计来看,这套方法论具有很强的可复制性和可扩展性。它可以复制到能源行业(石油、天然气、新能源)、化工行业(石化、精细化工)、金融行业(银行、证券、保险)、医疗行业(临床、药品、器械)等领域。同时,这套体系还可以在时间维度上持续更新构建时序数据集,在深度维度上增加更多细分领域和专题,在广度维度上扩展到上下游产业链,在质量维度上引入更精细的质量分层。
OpenCSG 正在探索的,是一条从通用 AI 到行业 AI、从语料库到知识体系、从研究数据集到数据资产的完整路径。
结语:行业 AI 的基础设施,从数据开始
当我们谈论 AI 在产业中的落地时,往往聚焦于模型架构、算法优化、算力投入,却容易忽视一个更基础的问题:行业 AI 需要什么样的数据?
CIMD 给出了一个清晰的答案:行业 AI 需要的不是简单的网络爬虫数据,而是权威来源的专业语料;不是单一类型的文本堆积,而是跨来源整合的知识体系;不是只有正文的纯文本,而是带有完整元数据的数据资产;不是封闭的研究数据集,而是商业友好的开源资源。

OpenCSG 通过 CIMD 的开源,正在做一件具有战略意义的事情:为行业 AI 构建数据基础设施。
这不是终点,而是起点。当越来越多的垂直行业拥有像 CIMD 这样的高质量数据集,当数据的组织方式从"文件堆积"升级为"知识体系",当数据资产的流通从"封闭私有"转向"可信开放",我们才能真正实现 AI 技术从实验室到产业的跨越。
CIMD 的开源,是行业 AI 从"能说话"到"真懂行"的关键一步。
引用格式:
bash
@dataset{opencsg_cimd_2026, title = {CIMD: A Cross-Source Industry Corpus for Iron Ore, Mining, Metallurgy, Policy, and Market Intelligence}, author = {OpenCSG}, year = {2026}, url = {https://opencsg.com/datasets/OpenCSG/CIMD}, note = {OpenCSG dataset repository}
}OpenCSG社区:https://opencsg.com/datasets/OpenCSG/CIMD
hf社区:https://huggingface.co/datasets/opencsg/CIMD
魔搭社区:https://modelscope.cn/datasets/opencsg/CIMD
关于 OpenCSG
OpenCSG是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是**人工智能领域的一种AI原生方法论,**由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。