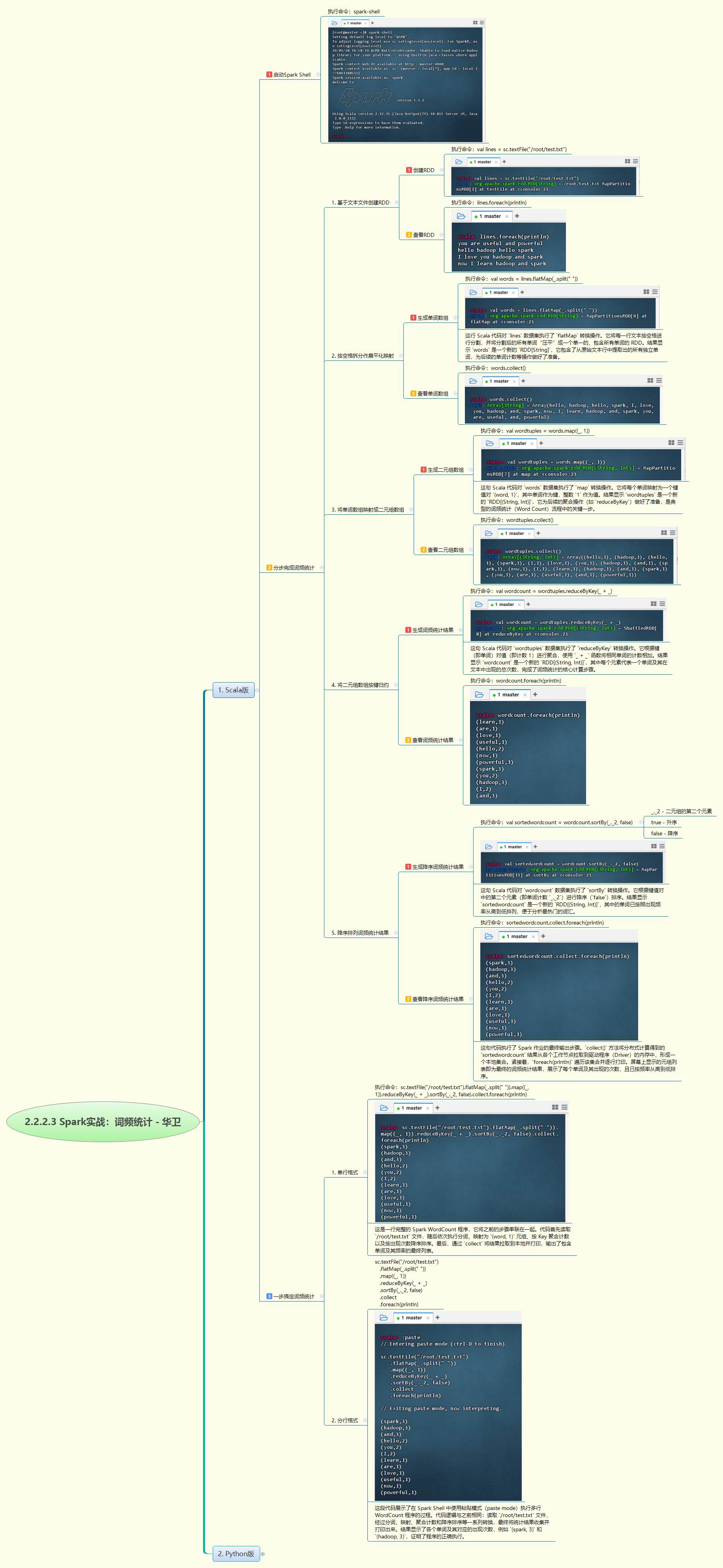
本次实战涵盖了Spark词频统计(WordCount)的两种主流实现方式。首先,利用Scala在spark-shell中完成从读取文件、flatMap分词、map映射到reduceByKey聚合的完整流程,并实现结果的降序排序。其次,针对Spark 3.3.2版本的需求,详细演示了Python 3.7.7的源码编译安装过程,包括依赖库配置、环境变量设置及验证。最后,在PySpark环境中复现了相同的词频统计逻辑,通过Lambda表达式完成RDD转换与聚合,对比展示了两种语言在大数据处理上的异同与应用。