Docker 集群运行 Spark 的一些记录
docker spark 的镜像怎么获取?
- 通过打开 Docker hub 搜索 Spark 就可以看相对应版本的镜像了
- 根据那里的提示进行 pull 就可以了
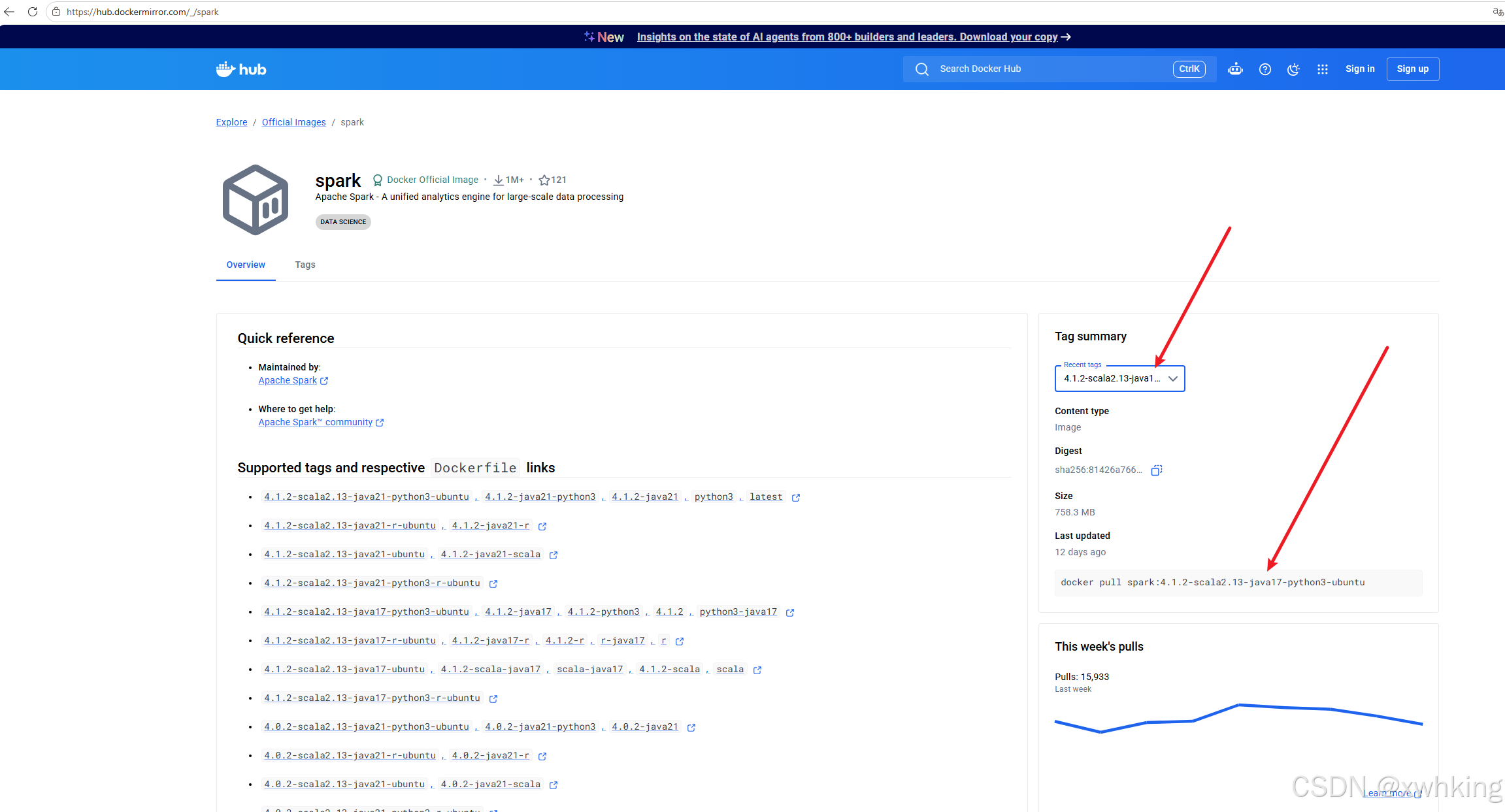
docker compose 示例:
yml
version: "3"
services:
master:
image: spark:4.1.2-scala2.13-java17-python3-ubuntu
hostname: master
command: /opt/spark/bin/spark-class org.apache.spark.deploy.master.Master
ports:
- "8080:8080" # Master WEBUI
- "7077:7077" # 任务提交端口
- "6066:6066" # REST API 端口
- "50070:50070"
environment:
- SPARK_MASTER_WEBUI_PORT=8080
#- SPARK_MASTER_HOST=10.12.43.198 #新增:监听全地址
networks:
spark-net:
worker:
image: spark:4.1.2-scala2.13-java17-python3-ubuntu
command: /opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
environment:
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=2g
depends_on:
- master
networks:
spark-net:
networks:
spark-net:运行命令示例:
bash
docker compose -f xxx.yml down # 停止运行
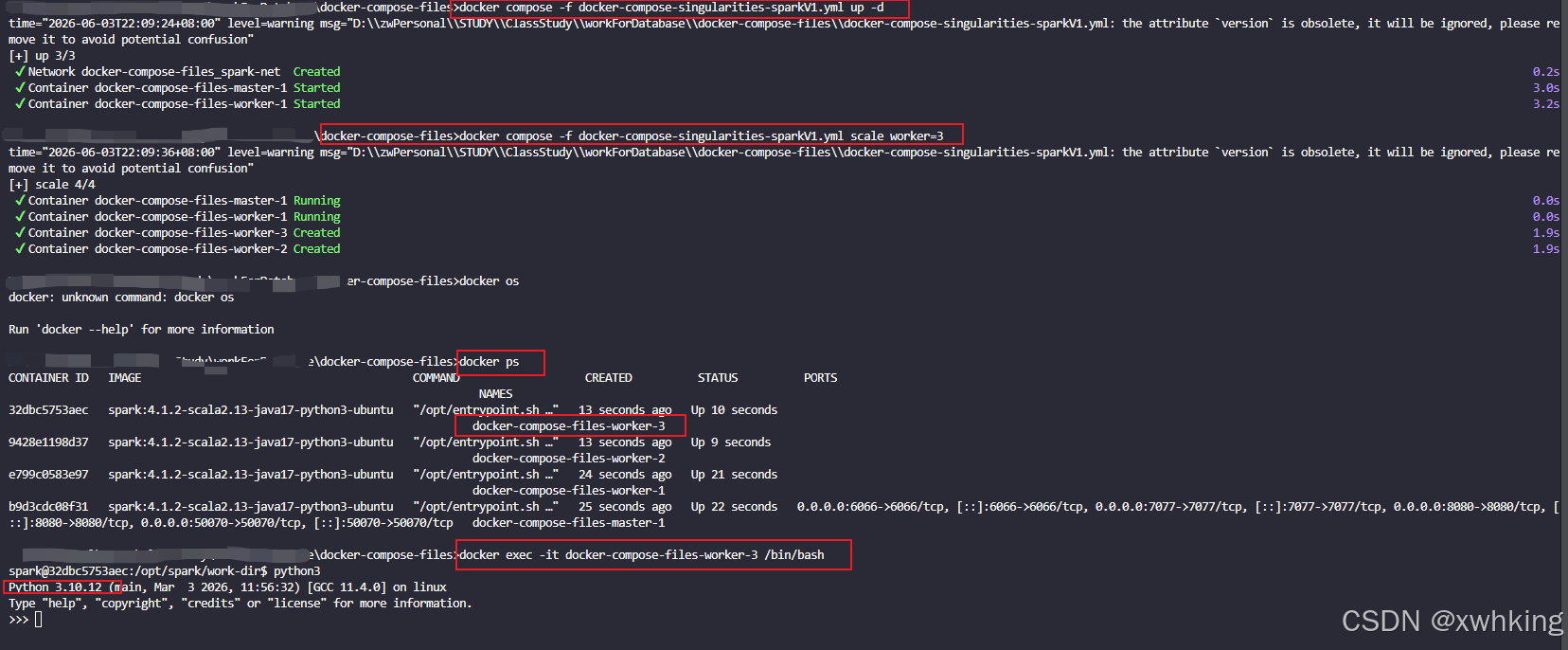
docker compose -f xxx.yml up -d # 运行
docker compose -f xxx.yml scale worker=3 # 开启从节点拉取镜像以后在 Docker 集群,Windows 的环境配置
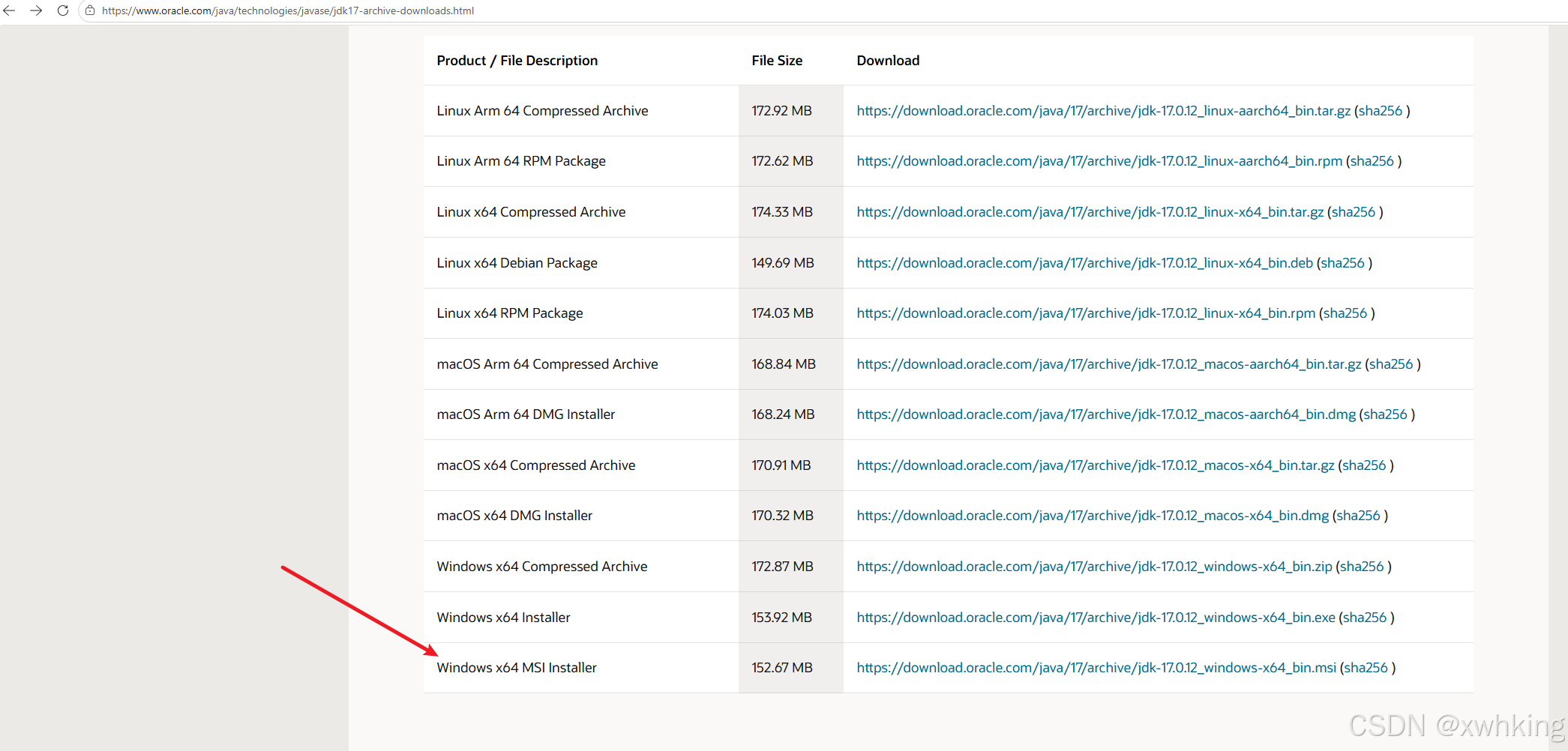
- 下载 Jdk ,这个 Jdk 的大版本要与拉取的镜像一致,地址
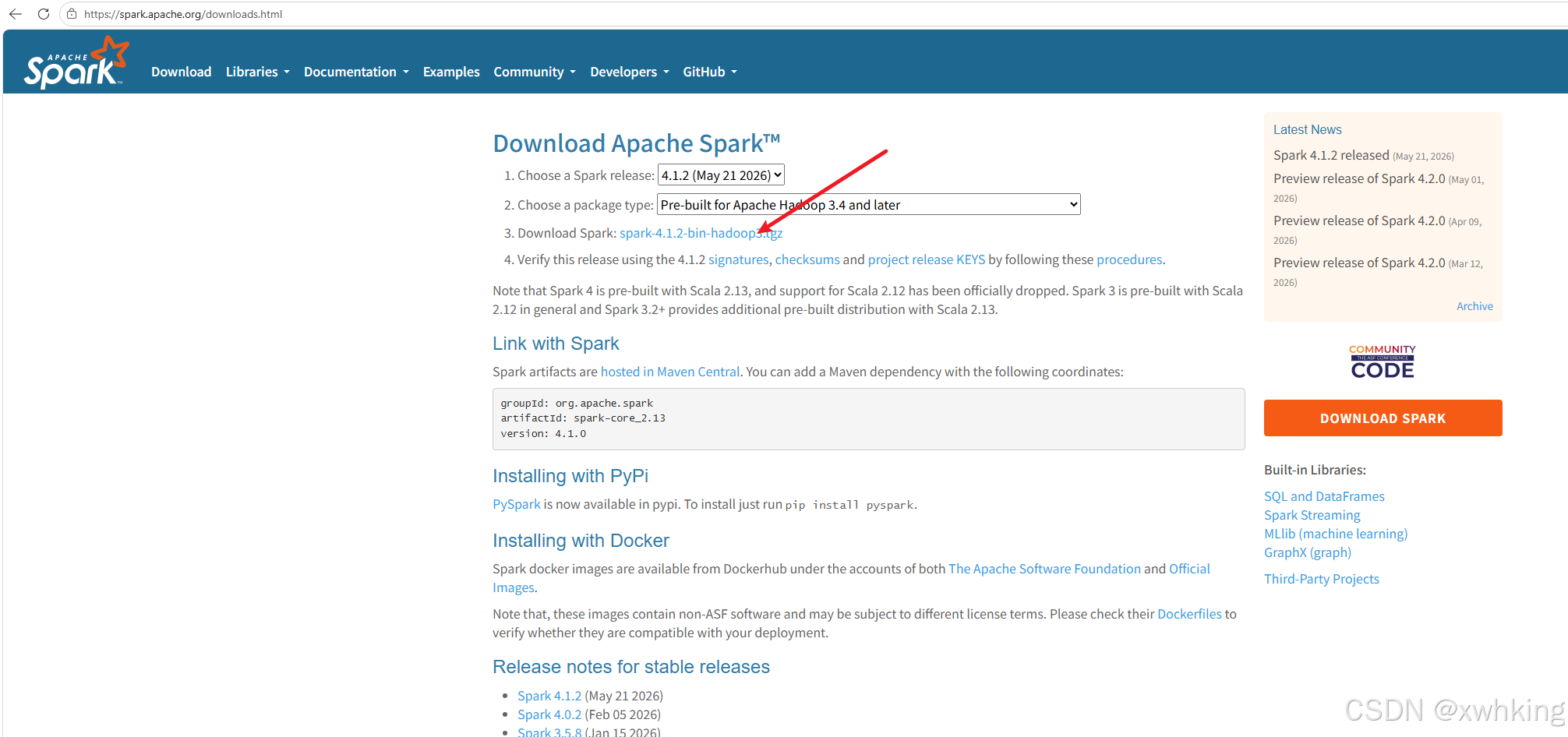
- 下载 Windows 的 Spark ,这个直接根据镜像的版本然后去官网下载就好了。
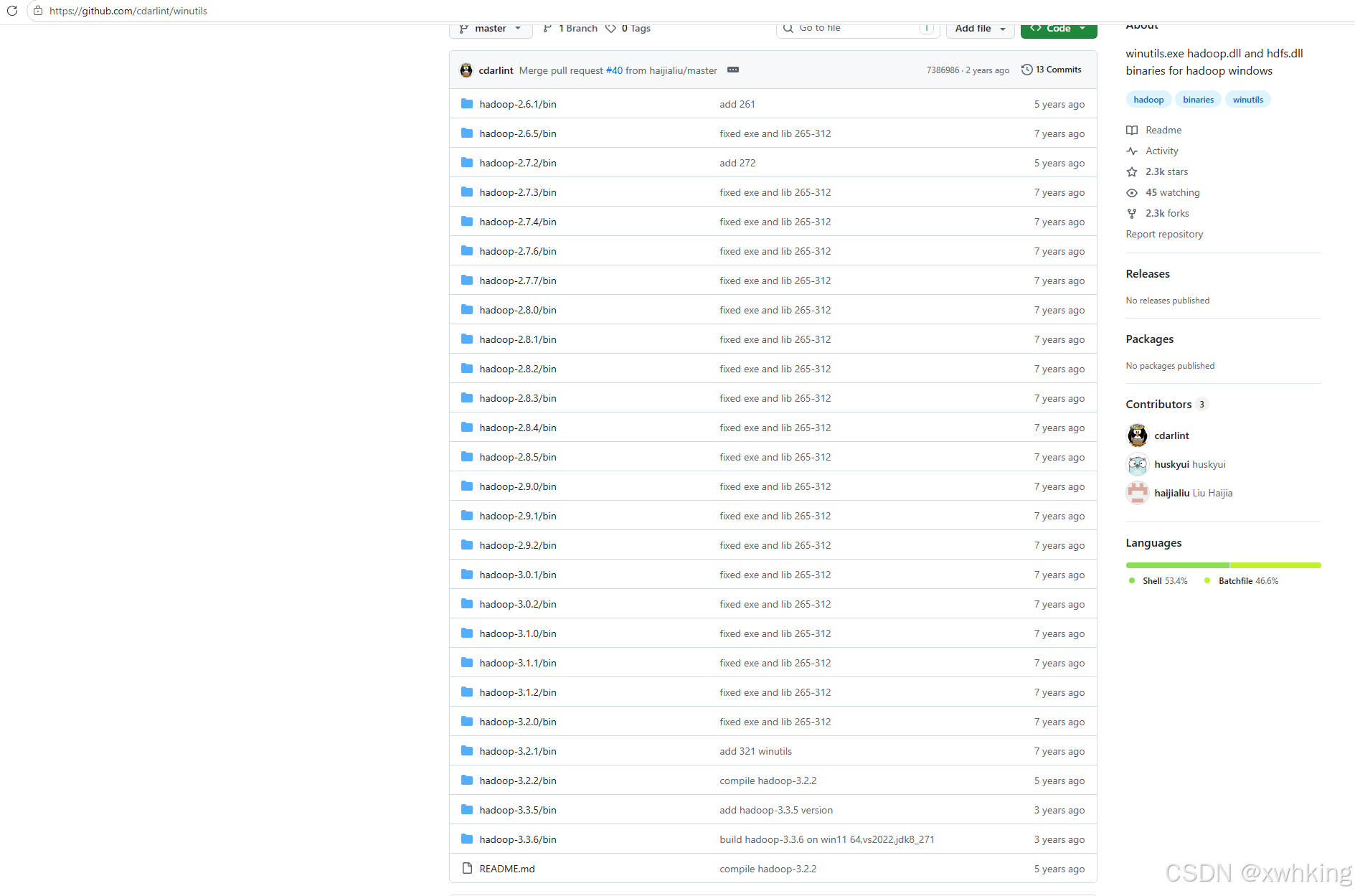
- 下载 Hadoop 这个直接也可以在官方的 Github 库进行下载 下载对应版本就好了
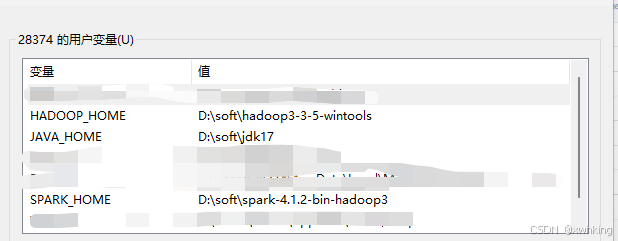
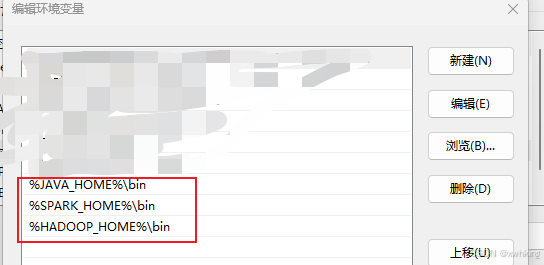
- 上面下载好了以后,就要设置 HOME 环境变量,然后再把 bin 加入 Path
- Windows python 下载这个 python 的版本要与容器内的一样,建议下载 miniconda,然后通过命令
conda create --name xxx python=3.10.12
通过下面的方法查看容器内的 python 版本
Windows 进行通讯的相关设置
集群好了以后并且设置好了上面的环境,那么就可以和集群进行通讯了。
Windows Python 测试代码:
python
from pyspark import SparkConf
from pyspark.sql import SparkSession
conf = SparkConf()
# 改成你的Ubuntu机器IP
conf.setMaster("spark://localhost:7077")
conf.setAppName("DockerTest").set("spark.driver.host", "10.12.43.198").set("spark.driver.bindAddress", "0.0.0.0") # 新增:设置driver host为localhost
spark = SparkSession.builder.config(conf=conf).getOrCreate()
rdd = spark.sparkContext.parallelize(["spark","docker"])
print(rdd.count())
spark.stop()1️⃣ 背景:Driver 和 Executor 的关系
在 Spark 集群模式下:
- Driver:你的 Python 程序所在进程,负责生成 DAG、调度任务。
- Executor:运行在 Worker 上的进程,负责实际执行任务。
- Master:管理资源和任务分配。
执行一个简单操作 rdd.count() 流程:
Python Driver
|
| DAG + Task 描述
v
Spark Master
|
| 分配 Executor
v
Worker 1 / Worker 2 / ...
|
| 向 Driver 汇报任务完成情况
v
Python Driver关键点:Executor 必须能访问 Driver 的 IP 和端口,才能汇报任务状态。
2️⃣ 原来的问题
你之前写的是:
python
conf.setMaster("spark://127.0.0.1:7077")- Python Driver 在 Windows 上运行
- Master + Worker 在 Docker 容器里
- Driver 的 IP 对容器来说是 127.0.0.1(容器里的 localhost)
所以 Worker 试图连接 Driver 时:
Docker Worker -> 127.0.0.1:随机端口127.0.0.1 指的是 Worker 容器自己,不是 Windows 主机的 IP。
结果就会出现:
WARN TaskSchedulerImpl: Initial job has not accepted any resources也就是 Executor 无法与 Driver 建立通信,任务永远卡住。
3️⃣ 解决方法:设置 Driver 的可访问地址
你新加的两行:
python
.set("spark.driver.host", "10.12.43.198") # Windows 主机真实 IP,可被 Docker 访问
.set("spark.driver.bindAddress", "0.0.0.0") # Driver 绑定所有网卡解释:
- spark.driver.bindAddress = 0.0.0.0
- Driver 绑定在 所有可用网络接口,而不是默认的 localhost
- 这样 Docker 容器才能从外部访问这个 Driver
- spark.driver.host = 10.12.43.198
- 告诉 Spark Master/Executor "如果要联系 Driver,请使用这个 IP"
- 对 Docker 容器来说,这是可以访问 Windows 主机的真实 IP
这样:
Docker Worker -> 10.12.43.198:随机端口Executor 就能正常连接 Driver,任务就可以执行了。
4️⃣ 总结
- 之前卡住的根本原因:Executor 无法找到 Driver
- 修改
spark.driver.host+spark.driver.bindAddress之后:- Driver 对外可见
- Worker 可以正常注册并执行任务
- 资源充足,任务自然就能运行
💡 小建议:
- 在 Docker 内运行 Spark 的情况下,如果 Driver 也在 Docker 网络里,会更简单,不用管 host IP。
- 你现在的设置适合 Driver 在宿主机,Executor 在 Docker 的场景。
如果你愿意,我可以画一张图,把 Driver + Master + Executor 的网络访问关系 画出来,这样以后遇到同类问题就一眼就能看懂。
你想让我画吗?