目录
下面是一份面向零基础的全流程安装指南。带你一步步完成WSL与Java的配置,并依次安装Hadoop、Hive、Spark、Flink和DolphinScheduler,最后用一个整合案例来验证所有组件是否已正确安装和配置。
第一章:WSL与Java环境安装
步骤 1:启用WSL
以管理员身份打开PowerShell或命令提示符,输入:
wsl --install这条命令会自动启用WSL功能并安装默认的Ubuntu发行版。如果命令无效,可以手动启用虚拟化功能:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart安装完成后,根据提示重启电脑。重启后打开Ubuntu应用,设置一个纯英文的用户名和密码。
步骤 2:更新软件包并安装Java 8
注意:其它版本的java版本和部分大数据组件会出现 兼容性 问题,所以我们安装java 8
打开Ubuntu终端,执行以下命令:
# 用于更新软件源并升级所有已安装软件到最新版;
sudo apt update && sudo apt upgrade -y
# 用于安装 Java 8 开发环境,为后续大数据组件提供运行基础。
# 卸载所有与 openjdk 相关的包(包括 JDK、JRE、headless 等)
sudo apt purge -y 'openjdk-*'
# 清理不再需要的依赖
sudo apt autoremove -y
# 验证是否卸载干净(应该没有输出)
dpkg -l | grep openjdk
# 下载 jdk 8
sudo apt install -y openjdk-8-jdk执行成功后显示如下内容:
验证Java是否安装成功:
java -version输出如下内容,即表示安装成功:

配置JAVA_HOME环境变量,编辑 ~/.bashrc 文件:
nano ~/.bashrc在文件末尾添加以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH如图所示:
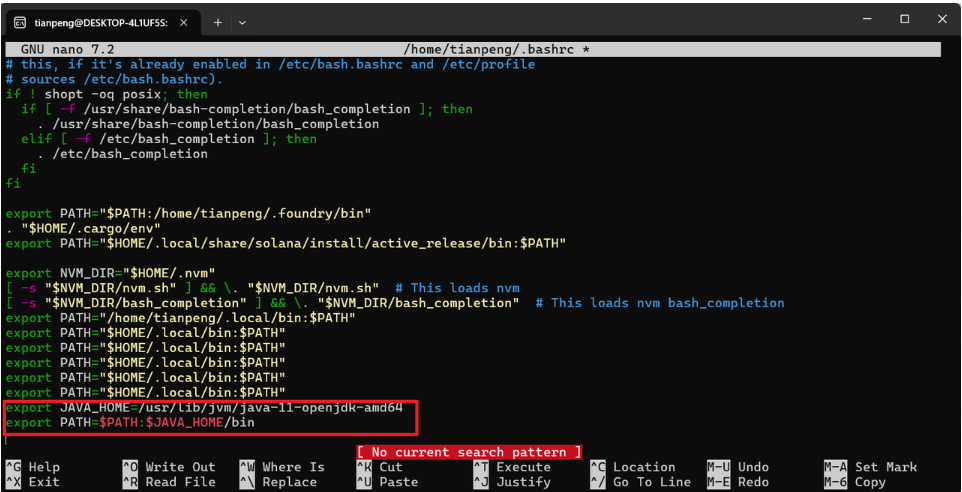
在 nano 编辑器中,按 Ctrl+O 回车保存,再按 Ctrl+X 退出。
**注意:**在 nano 编辑器的"File Name to Write"提示下,直接按 回车键 (Enter) 即可保存文件,然后再按 Ctrl+X 退出编辑器。
执行 如下命令使配置生效
source ~/.bashrc第二章:Hadoop安装与配置
步骤 1:下载并解压 Hadoop
# 创建一个bigdata文件夹
mkdir bigdata
# :切换到bigdata目录中。
cd bigdata
# :从 Apache 官网下载 Hadoop 3.3.6 的压缩包。
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# :解压下载的 Hadoop 压缩包(-x 解压,-z 处理 gzip,-v 显示详情,-f 指定文件)。
tar -xzvf hadoop-3.3.6.tar.gz步骤 2:配置 环境变量
编辑 ~/.bashrc,在末尾添加:
# 配置环境变量
nano ~/.bashrc
# 在文件末尾添加以下两行(注意路径要指向你当前的 bigdata 目录):
export HADOOP_HOME=/home/tianpeng/bigdata/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存(Ctrl+O,回车,Ctrl+X),然后执行:
source ~/.bashrc
# 验证安装
hadoop version执行 source ~/.bashrc 使配置生效,输出如下内容:
步骤 3:配置 Hadoop 核心文件
1、修改 hadoop-env.sh 中的 JAVA_HOME
nano /home/tianpeng/bigdata/hadoop-3.3.6/etc/hadoop/hadoop-env.sh找到 export JAVA_HOME 行,修改为:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd642、编辑 core-site.xml
nano /home/tianpeng/bigdata/hadoop-3.3.6/etc/hadoop/core-site.xml在 <configuration> 内添加:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>3、编辑 hdfs-site.xml
nano /home/tianpeng/bigdata/hadoop-3.3.6/etc/hadoop/hdfs-site.xml在 <configuration> 内添加:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>4、编辑 yarn-env.sh
nano $HADOOP_HOME/etc/hadoop/yarn-env.sh在文件末尾添加以下内容 找到(或新增)YARN_RESOURCEMANAGER_OPTS 和 YARN_NODEMANAGER_OPTS 变量,并添加 --add-opens 参数:
# 为 ResourceManager 和 NodeManager 开放 java.lang 模块,允许反射访问
export YARN_RESOURCEMANAGER_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.lang.reflect=ALL-UNNAMED --add-opens java.base/java.net=ALL-UNNAMED"
export YARN_NODEMANAGER_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.lang.reflect=ALL-UNNAMED --add-opens java.base/java.net=ALL-UNNAMED"这些参数会告诉 JVM 允许未命名模块(比如 Hadoop 的 jar 包)访问 java.lang、java.util 等包内的受保护方法。
步骤四:格式化 NameNode 并启动 Hadoop
# 格式化(仅首次执行)
hdfs namenode -format
# 安装 SSH 服务并启动
sudo apt update
sudo apt install openssh-server -y
sudo service ssh start
# 配置无密码 SSH 登录(本地)
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh-keyscan -H localhost >> ~/.ssh/known_hosts
# 测试 SSH 连接
ssh localhost
# 启动 HDFS 和 YARN
start-dfs.sh
start-yarn.sh显示如下内容,即表示安装成功:
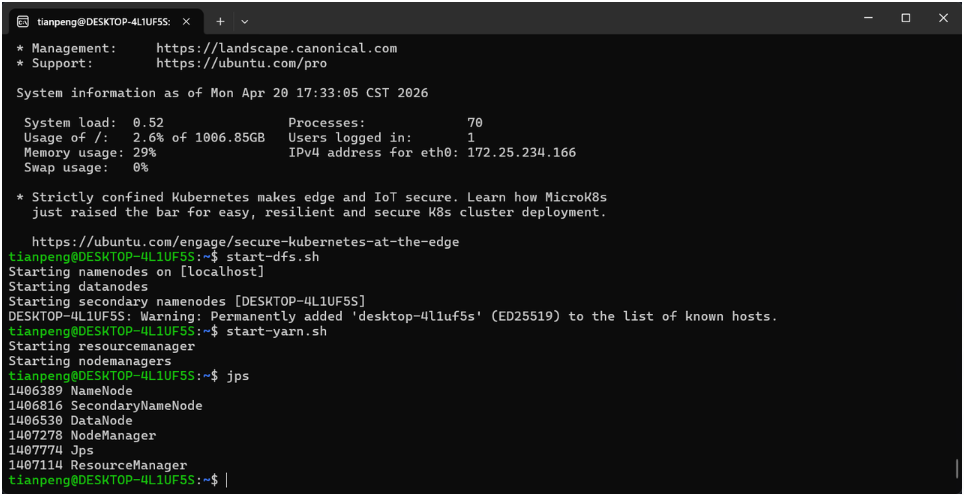
如果提示命令未找到,请确保已执行 source ~/.bashrc 或使用绝对路径:
/home/tianpeng/bigdata/hadoop-3.3.6/sbin/start-dfs.sh
/home/tianpeng/bigdata/hadoop-3.3.6/sbin/start-yarn.sh检查进程:
jps应该看到 NameNode、DataNode、ResourceManager、NodeManager。如果 jps 不存在,执行:
sudo apt install openjdk-11-jdk-headless -y步骤 5:验证 Hadoop 安装
在 Windows 浏览器中访问:
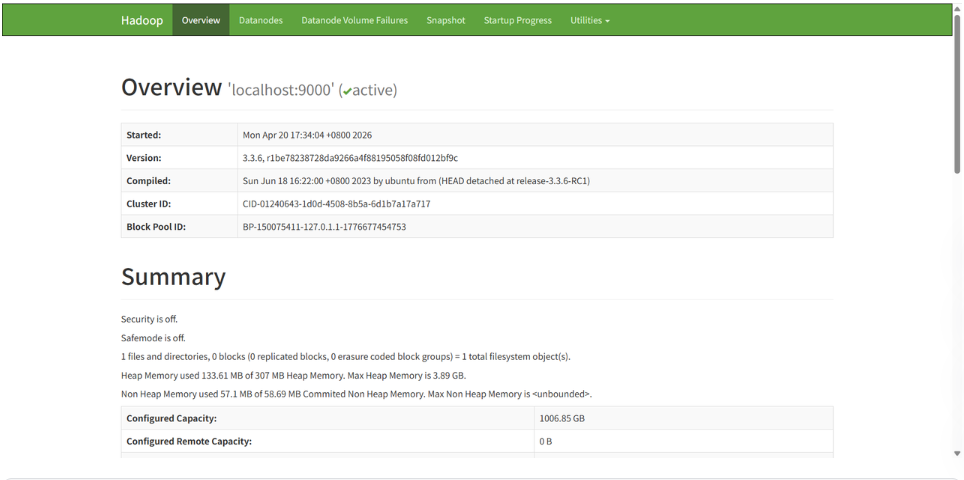
# HDFS NameNode : 显示 Hadoop 概述页面,含集群 ID、存储容量等信息
http://localhost:9870看到 Hadoop Web 界面即成功。
# YARN ResourceManager : 显示集群资源管理和应用列表
http://localhost:8088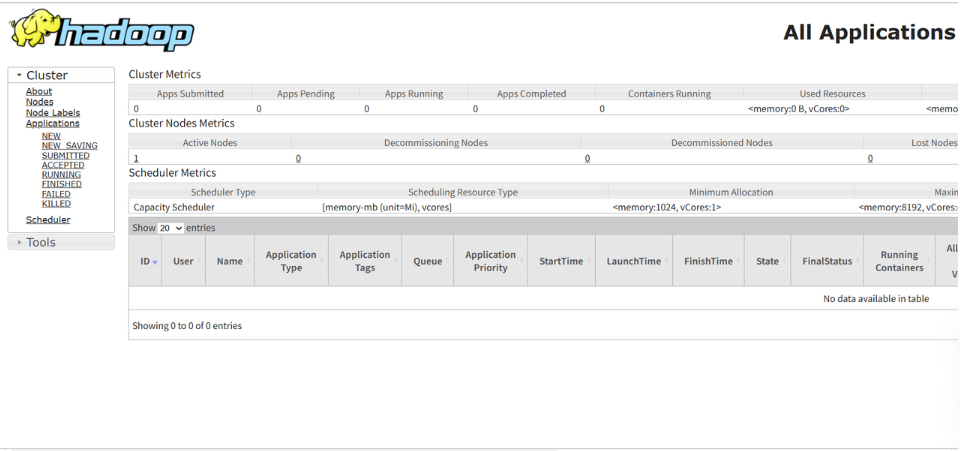
附:停止服务命令
stop-dfs.sh
stop-yarn.sh现在你可以继续后续 Hive、Spark 等组件的安装了。
第三章:Hive安装与配置
好的,根据你之前成功连接 WSL 中 MySQL 的经验,我重新编写了 步骤 1:安装并配置 MySQL 作为 Hive 元数据库,确保你能在 Windows 的 DBeaver 中顺利连接。
步骤 1:安装并配置 MySQL(供 Hive 使用)
1、在 WSL 中安装 MySQL
# 更新软件包列表并安装 MySQL 服务器
sudo apt update
sudo apt install mysql-server -y
# 启动 MySQL 服务
sudo service mysql start
# 检查 MySQL 运行状态
sudo service mysql status2、设置 root 密码并完成安全配置
# 进入mysql数据库 (没有设置密码的情况下)
sudo mysql
# 设置密码的情况下执行
mysql -u root -p
# 执行语句修改root账户密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
FLUSH PRIVILEGES;
EXIT;
# 验证密码是否生效
mysql -u root -p3、配置 MySQL 允许远程连接
编辑 MySQL 配置文件:
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf找到 bind-address = 127.0.0.1,将其注释或改为 0.0.0.0:
# bind-address = 127.0.0.1
bind-address = 0.0.0.0保存(Ctrl+O,回车,Ctrl+X),然后重启 MySQL:
sudo service mysql restart4、创建允许远程连接的用户
为了安全,建议创建一个专门用于远程连接的用户(例如 dbeaver),并授予所有权限。
# 登录 MySQL(使用 root 密码)
mysql -u root -p在 MySQL 命令行中执行:
-- 为现有的 root 用户添加远程访问权限(允许从任何主机连接)
CREATE USER IF NOT EXISTS 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
EXIT;如果你更习惯使用
root远程连接,也可以创建'root'@'%',但生产环境不推荐。
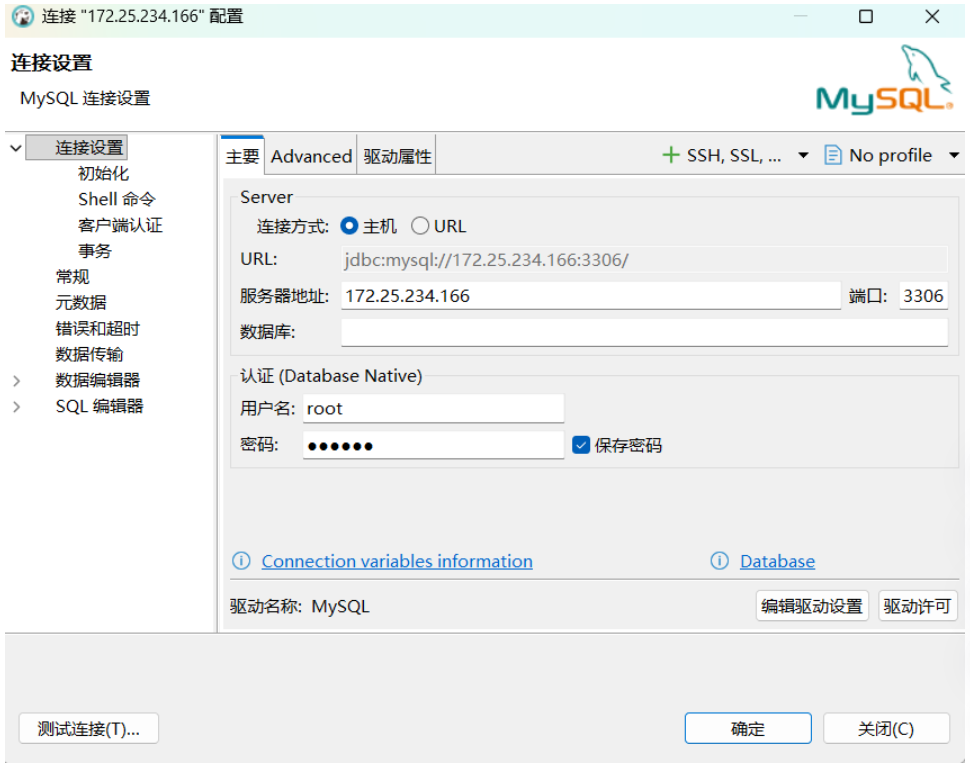
5、在 Windows 的 DBeaver 中连接
(1)新建 MySQL 连接
通过命名查看WSL的IPv4地址:
ip addr show eth0 | grep inet输出如下内容:

配置连接:
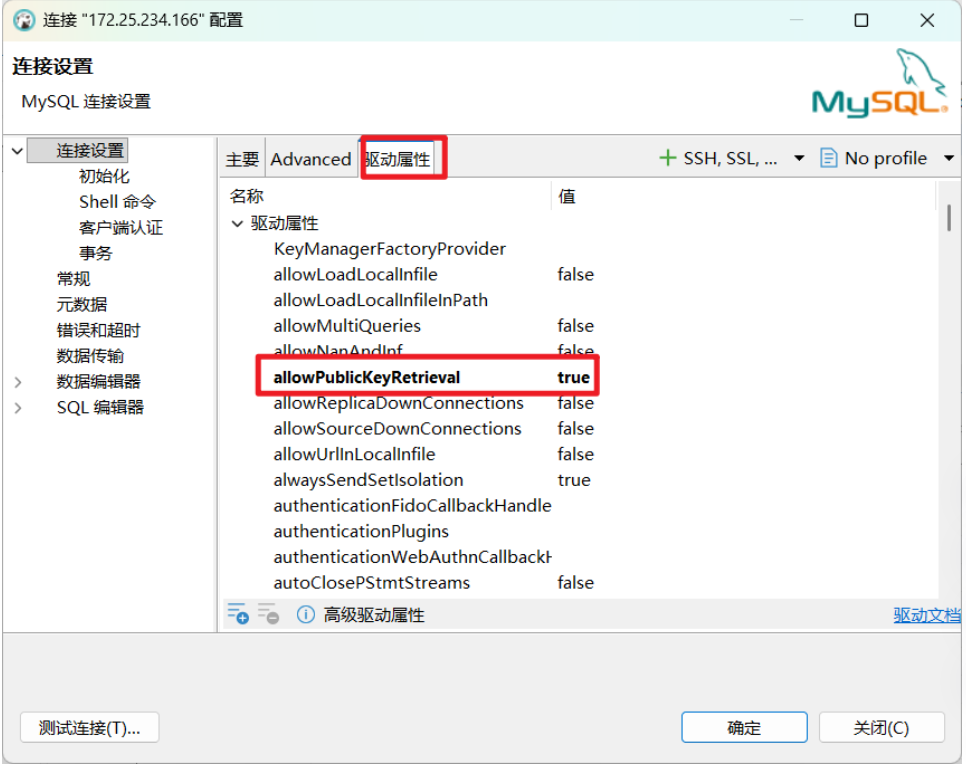
(2)配置驱动属性
切换到 驱动属性 标签页,添加以下两个属性:
| 属性名 | 值 |
|---|---|
allowPublicKeyRetrieval |
true |
useSSL |
false |
(3)测试连接
点击 测试连接,如果提示下载驱动,允许下载。成功后会显示"已连接"。
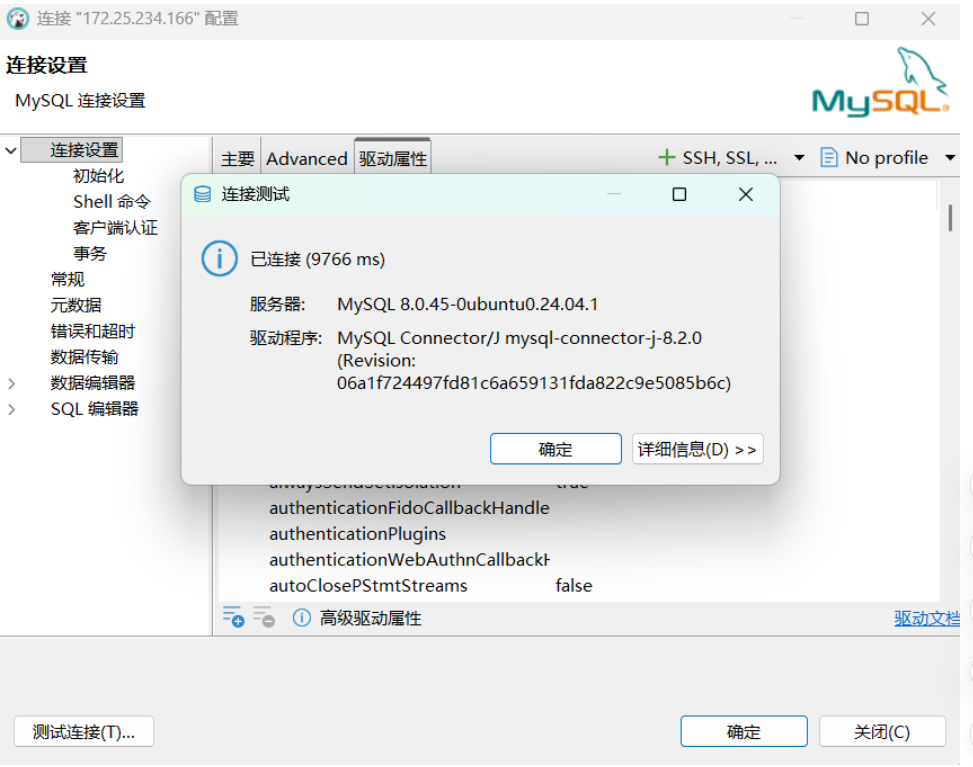
(4)验证数据库
连接成功后,执行 SHOW DATABASES;,应该能看到默认数据库(如 information_schema、mysql、sys 等)。
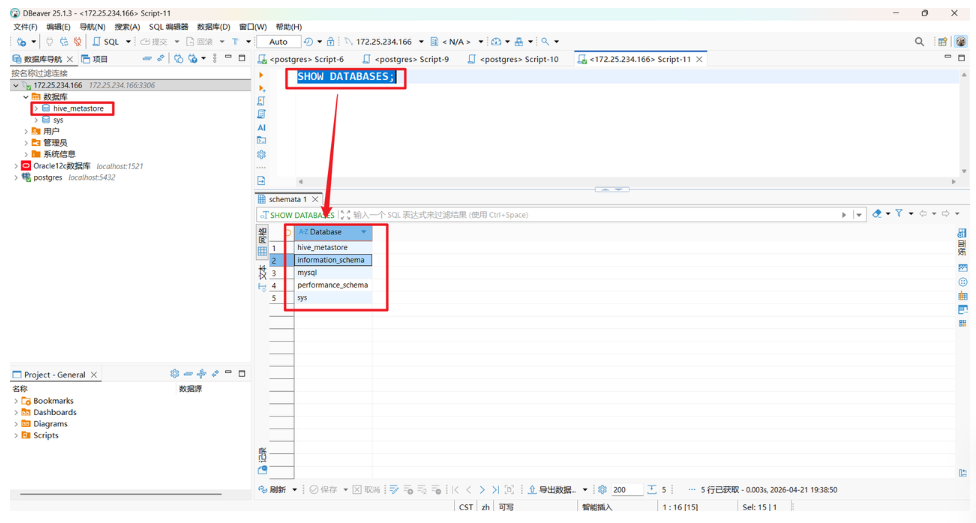
注意:
hive_metastore是后续初始化后才会显示出来,可以用来验证mysql数据库与Hive是否连通
步骤 2:在 ~/bigdata 目录下下载并解压 Hive
# 下载Hive安装包(使用华为镜像下载)
wget https://mirrors.huaweicloud.com/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 解压
tar -xzvf apache-hive-3.1.3-bin.tar.gz此时 Hive 的安装路径为:/home/tianpeng/bigdata/hive-3.1.3
步骤 3:配置 Hive 环境变量
编辑 ~/.bashrc,执行如下命令:
nano ~/.bashrc添加以下两行:
export HIVE_HOME=/home/tianpeng/bigdata/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin保存后执行:
source ~/.bashrc根据你当前的目录结构(~/bigdata/apache-hive-3.1.3-bin/conf 中已存在 hive-default.xml.template)。
步骤4:配置 Hive(使用最小配置文件)
1 进入 Hive 配置目录
cd $HIVE_HOME/conf2 删除可能存在的旧配置文件(避免冲突)
rm -f hive-site.xml3 使用 cat 命令创建 hive-site.xml 并写入内容
直接复制以下整段命令到终端执行:
cat > hive-site.xml << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
EOF注意 :请将
<value>123456</value>中的123456替换为你的 MySQL root 实际密码。
4 验证文件内容是否正确
cat hive-site.xml应该看到以 <?xml version="1.0" encoding="UTF-8"?> 开头的完整 XML 内容。
5 保存并退出(无需额外操作, cat 命令已自动保存)
步骤5:下载 MySQL JDBC 驱动并初始化元数据库
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.16/mysql-connector-java-8.0.16.jar
cp mysql-connector-java-8.0.16.jar $HIVE_HOME/lib/初始化 Hive 元数据库:
# 配置环境变量
export PATH=$PATH:$HIVE_HOME/bin
# 初始化元数据库
schematool -dbType mysql -initSchema看到输出 schemaTool completed 表示成功,如下图所示:
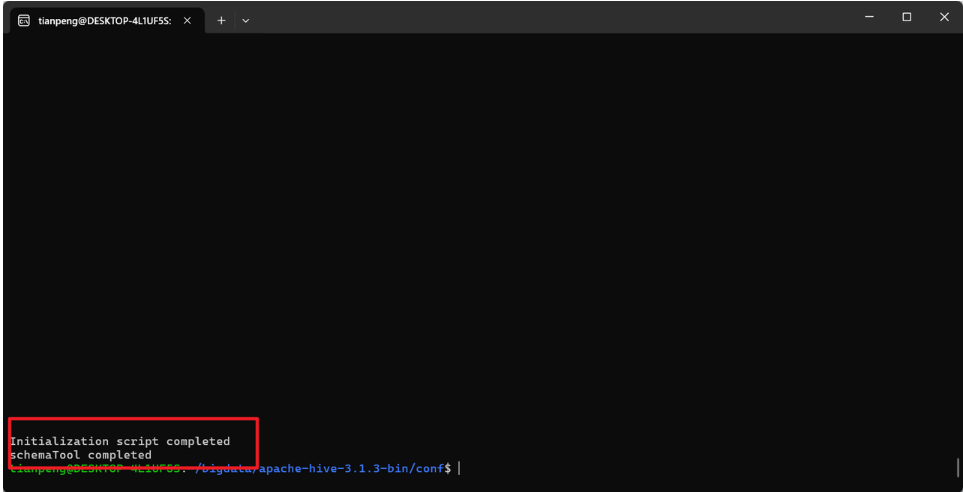
验证mysql数据库中hive的元数据是否配置成功:
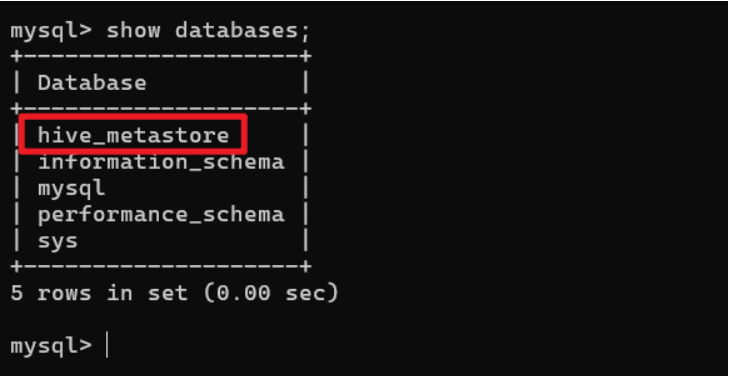
步骤6:验证 Hive 是否可用
启动 Hive 命令行:
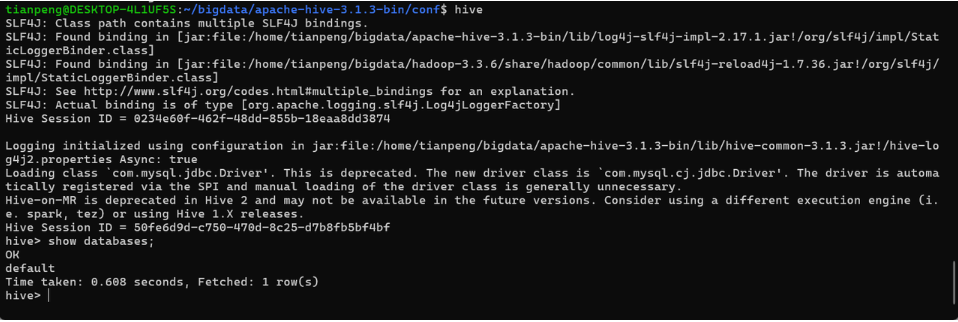
hive在 hive> 提示符下执行:
show databases;如果能正常显示,说明 Hive 安装配置成功。
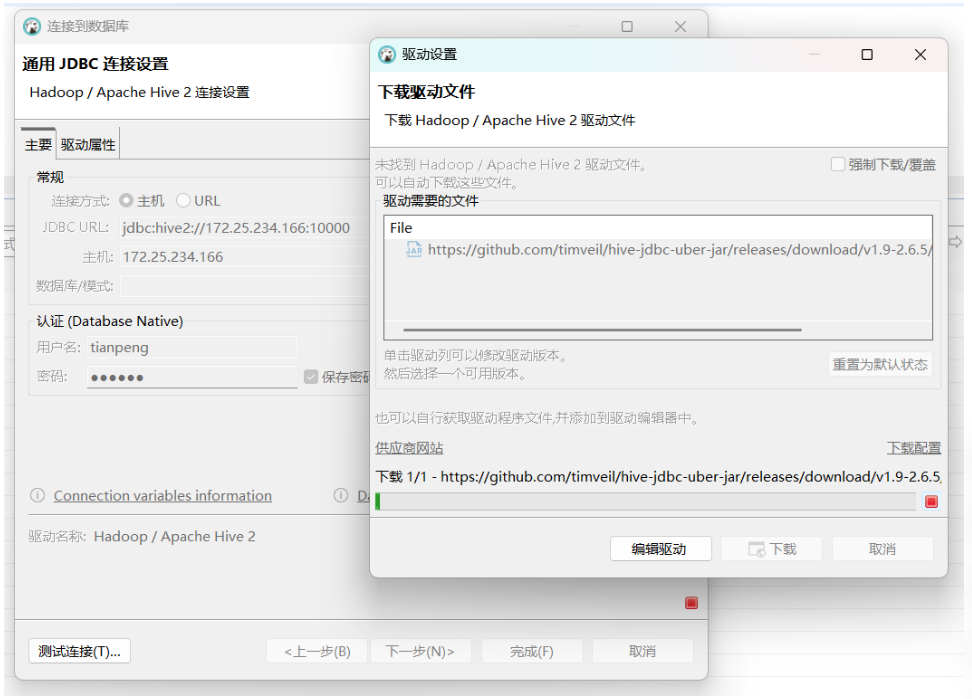
步骤7:使用 DBeaver 去连接 Hive :
在 DBeaver 中连接 Hive 需要先启动 HiveServer2 服务(默认端口 10000),然后在 DBeaver 中配置 Hive 驱动和连接参数。以下是完整步骤。
1、禁用 HiveServer2 的代理用户模拟
在 hive-site.xml 中添加配置
nano $HIVE_HOME/conf/hive-site.xml在 <configuration> 中添加:
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>Disable impersonation, all queries run as the HiveServer2 process user (tianpeng).</description>
</property>2、在 WSL 中启动 HiveServer2
HiveServer2 是 Hive 提供的 JDBC 服务,允许外部工具(如 DBeaver)连接。
# 进入 Hive 安装目录
cd $HIVE_HOME
# 后台启动 Metastore 服务
nohup bin/hive --service metastore &
# 启动 HiveServer2(后台运行)
nohup bin/hive --service hiveserver2 &验证是否启动成功:
ss -tlnp | grep -E "9083|10000"输出如下内容,即表示启动成功:

2、在 DBeaver 中创建 Hive 连接
(1)点击 数据库 → 新建连接 → 选择 Hive JDBC(刚创建的驱动)。
(2)填写连接参数:
通过输入如下命令查询WSL的IPv4地址:

-
端口 :
10000 -
数据库 :
default(可留空) -
用户名 :当前 WSL 用户名(如:
tianpeng),因为 Hive 默认使用操作系统用户认证 -
密码:通常为空(如果未配置认证)
(3)点击 测试连接,如果提示下载驱动,允许下载。
(4)连接成功后,即可在 DBeaver 中浏览 Hive 的表和执行 SQL。
3、验证连接
连接成功后,在 DBeaver 的 SQL 编辑器中执行:
SHOW DATABASES;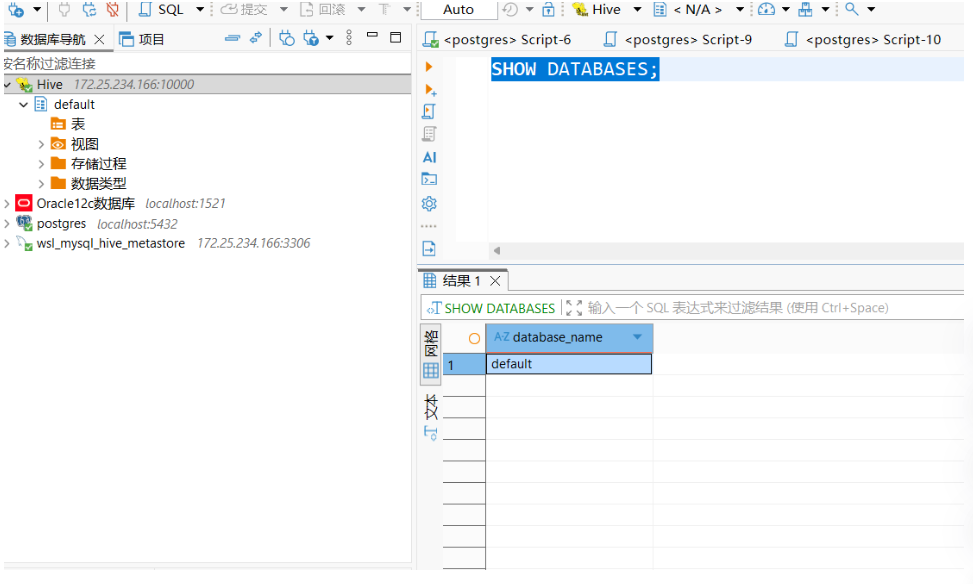
应该能看到 default 和你之前创建的 test 等数据库。如果之前创建了 hive_metastore 数据库,那是元数据内部库,通常不会在 Hive 中显示
第四章:Spark安装与配置
步骤 1:下载并解压 Spark(在用户目录)
# 进入 bigdata 目录(如果不存在则创建)
cd ~/bigdata
# 使用华为云镜像下载 Spark 3.4.3(与 Hadoop 3.3 兼容)
wget https://mirrors.huaweicloud.com/apache/spark/spark-3.4.3/spark-3.4.3-bin-hadoop3.tgz
# 解压
tar -xzvf spark-3.4.3-bin-hadoop3.tgz解压后会得到目录:~/bigdata/spark-3.4.3-bin-hadoop3。
后续路径将使用
/home/tianpeng/bigdata/spark-3.4.3(假设你的用户名为tianpeng)。
步骤 2:配置 Spark 环境变量
编辑 ~/.bashrc 文件,将 Spark 的路径添加到环境变量中。
nano ~/.bashrc在文件末尾添加以下两行(注意路径是你的实际解压目录):
export SPARK_HOME=/home/tianpeng/bigdata/spark-3.4.3-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin保存:Ctrl+O → 回车 → Ctrl+X。
然后执行以下命令使配置立即生效:
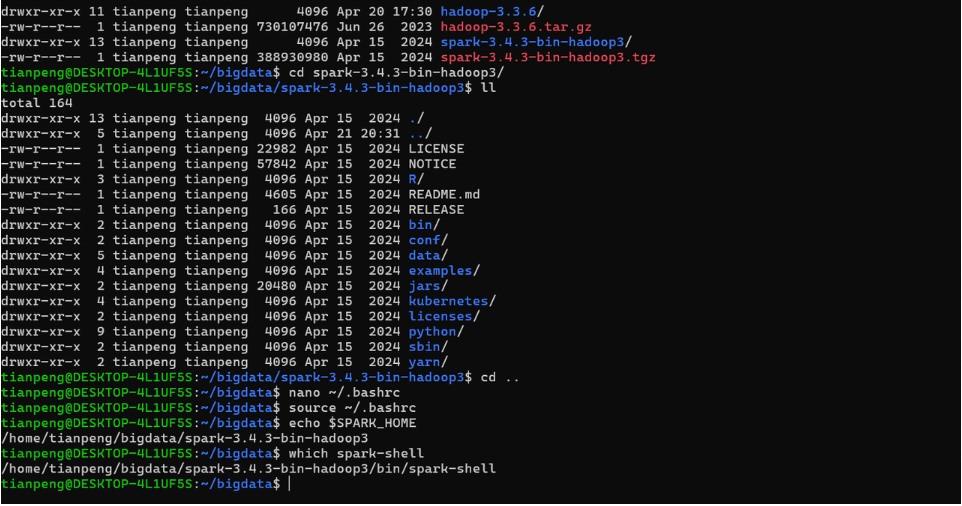
source ~/.bashrc验证:
echo $SPARK_HOME
which spark-shell输出如下内容:
步骤 3:配置 Spark 与 Hadoop 集成
Spark 需要知道 Hadoop 的配置目录(core-site.xml、hdfs-site.xml 等),以便访问 HDFS 和 YARN。
首先,复制 Spark 的环境配置文件模板:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh然后编辑该文件:
nano $SPARK_HOME/conf/spark-env.sh在文件末尾添加以下两行(注意 Hadoop 路径是你的实际安装位置):
export HADOOP_CONF_DIR=/home/tianpeng/bigdata/hadoop-3.3.6/etc/hadoop
export SPARK_MASTER_HOST=localhost保存并退出。
如果你之前已将 Hadoop 移动到
/usr/local/hadoop,则HADOOP_CONF_DIR应改为/usr/local/hadoop/etc/hadoop。这里以你之前的~/bigdata/hadoop-3.3.6为例。
步骤 5:配置与 MySQL 集成,访问 Hive 的元数据库
将mysql的驱动复制一份到spark的路径下:
# 确认 Spark 的 jars 目录路径
ls -ld $SPARK_HOME/jars
# 复制驱动文件(选择一个,比如 mysql-connector-java-8.0.16.jar)
cp /home/tianpeng/bigdata/mysql-connector-java-8.0.16.jar $SPARK_HOME/jars/
# 验证复制成功
ls -l $SPARK_HOME/jars/mysql-connector-java-*.jar步骤 6:启动 Spark 并验证
Spark 支持独立集群模式(Standalone),我们启动一个 Master 和一个 Worker 进程。
# 1. 停止所有 Spark 进程(Master、Worker、Thrift Server)
cd ~/bigdata/spark-3.4.3-bin-hadoop3
./sbin/stop-master.sh
./sbin/stop-worker.sh
./sbin/stop-thriftserver.sh
# 强制清理残留(如果有)
jps | grep -E "Master|Worker|HiveThriftServer2" | awk '{print $1}' | xargs kill -9
# 3. 验证 Master 监听状态 应该显示 172.25.234.166:7077 或 0.0.0.0:7077,不是 127.0.0.1:7077。
sudo netstat -tlnp | grep 7077
# 4. 启动 Worker
./sbin/start-worker.sh spark://172.25.234.166:7077
# 5. 重新启动 Spark Thrift Server(连接到 Master,使用 10003 端口)
./sbin/start-thriftserver.sh \
--master spark://172.25.234.166:7077 \
--hiveconf hive.server2.thrift.port=10003 \
--hiveconf hive.server2.thrift.bind.host=0.0.0.0执行如下命令,验证是否连接成功:
jps输出如下内容:
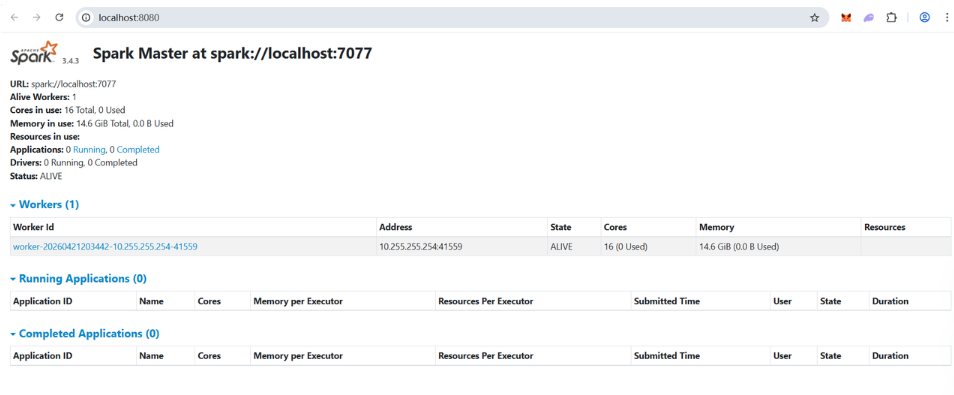
验证 Master Web UI
打开 Windows 浏览器,访问:http://localhost:8080
应该能看到 Spark Master 的 Web 界面,显示 Worker 资源等信息。
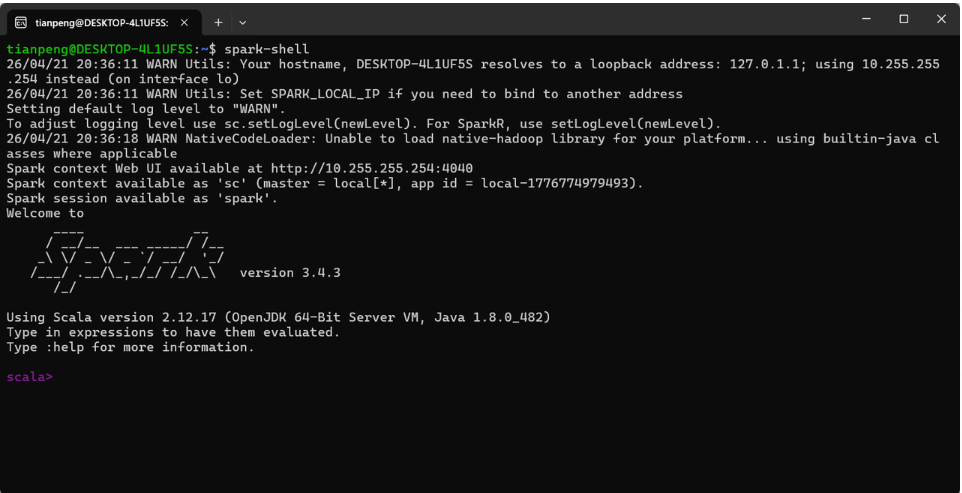
验证 Spark Shell
另开一个终端,执行:
spark-shell如果能进入 Scala 交互式环境(出现 scala> 提示符),说明 Spark 安装成功:如下图收所示:
补充说明
-
停止 Spark 服务:
$SPARK_HOME/sbin/stop-master.sh $SPARK_HOME/sbin/stop-worker.sh- 提交任务到 YARN(可选):
如果你希望 Spark 任务运行在 Hadoop YARN 上,可以修改 spark-env.sh 并确保 Hadoop 已启动。但单机学习环境下,Standalone 模式足够。
步骤 7:通过Dbeaver去连接SparkSQL完成开发
1、在 DBeaver 中配置并连接 Spark
(1)创建新的数据库连接
1)在 DBeaver 中,点击 数据库 -> 新建数据库连接。
2)在 通用 或 All 标签页中,搜索你创建的驱动名称(如 Apache Spark SQL),选中它,然后点击 下一步。
jdbc:hive2://172.25.234.166:10003/default?auth=noSasl
# 如果认证报错,可以尝试:
jdbc:hive2://172.25.234.166:10003/default?auth=user
(2)配置连接参数
在连接设置窗口中,填写以下信息:
| 参数 | 说明 | 示例值 |
|---|---|---|
| 主机 | WSL 的 IP 地址。你可以通过 WSL 终端命令 `ip addr show eth0 | grep inet` 查看。 |
| 端口 | Spark Thrift Server 的默认端口是 1000 3 ,不是 10000。如果启动时修改了端口,请填写你指定的端口。 |
10003 |
| 数据库 | 目标数据库名称,例如 default。也可以留空,连接后再选择。 |
default |
| 用户名 | 如果未配置认证,可随意填写。在启用了代理用户(impersonation)的环境下,建议填写你的 WSL 用户名,如 tianpeng。 |
tianpeng |
| 密码 | 如果未配置认证,可以留空。 | (留空) |
| URL | (可选)如果你更习惯使用完整的 JDBC URL,可以切换到此模式,URL 格式通常为 jdbc:hive2://<host>:<port>/<database>。 |
jdbc:hive2://172.25.234.166:10002/default |
(3)测试并完成连接
1)点击 测试连接 按钮。
2)如果是第一次连接,DBeaver 会提示你下载驱动文件,点击 下载 即可。首次连接可能需要一点时间,请耐心等待。
3)测试成功后,点击 完成。此时,DBeaver 的数据库导航器中就会出现你的 Spark SQL 连接。
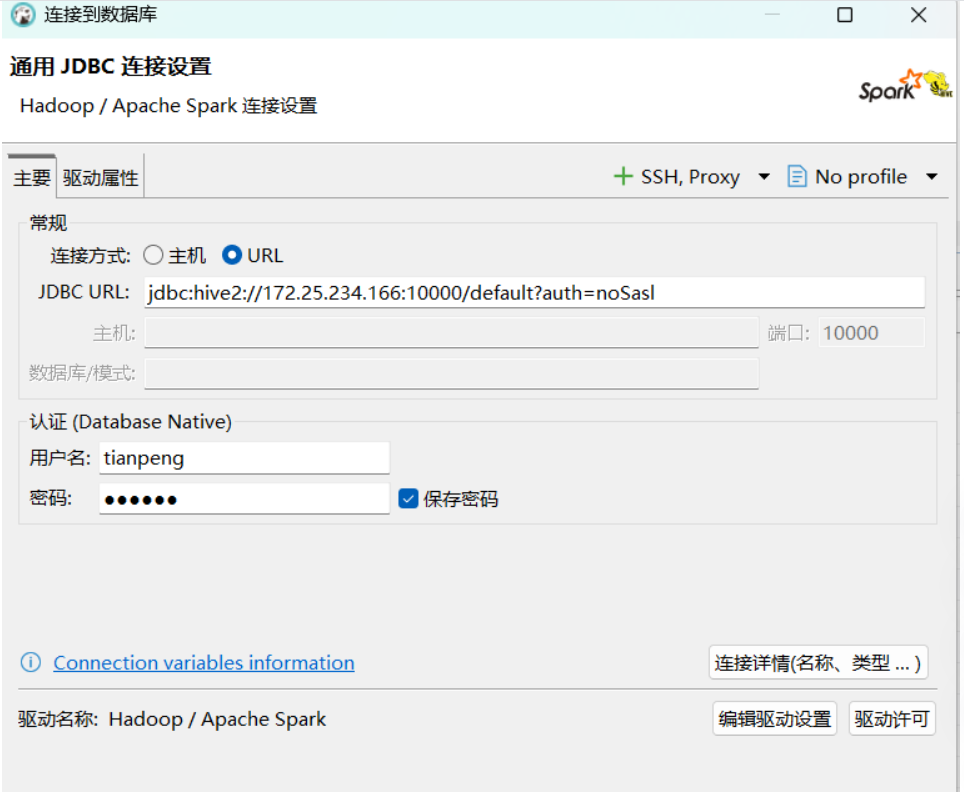
**注意:**因为 DBeaver 用了 Hive 的驱动来连接 Spark,而 Spark 读取的又是 Hive 的元数据,所以界面上显示为 Hive 是完全正常的。这本质上就是通过 Spark 引擎来执行 Hive 上的任务,也就是我们常说的 "Spark on Hive" 架构。
有一点需要明确,"Spark on Hive" 和 "Hive on Spark" 是两个不同的概念:
Spark on Hive:指的是 Spark 作为 SQL 引擎,读取 Hive Metastore 中的元数据来操作数据。
Hive on Spark:指的是 Hive 原本的 MapReduce 执行引擎被替换成了更快的 Spark 引擎。
因为无论是 Spark(启用 Hive 支持)还是 Hive 客户端,它们操作的都是同一份元数据。当你在 Spark 中执行
CREATE DATABASE ...或CREATE TABLE ...时,对应的库、表的定义信息(字段、类型、HDFS 路径等)会被写入共享的 Hive Metastore 数据库。Hive 客户端在读取元数据时,自然也能看到这些新增的对象。
3、在 DBeaver 中执行 Spark SQL 查询
连接成功后,你就可以像操作传统数据库一样,在 DBeaver 中编写和执行 Spark SQL 了。
示例:使用 Spark SQL 处理销售数据
-- 创建一个新数据库,用于存放本次示例表
CREATE DATABASE IF NOT EXISTS sales_db;
-- 创建销售数据表 sales_data
CREATE TABLE IF NOT EXISTS sales_db.sales_data (
order_id BIGINT,
product_category STRING,
sale_amount DECIMAL(10,2),
customer_id BIGINT,
sale_date DATE
);
-- 插入示例数据
INSERT INTO sales_db.sales_data VALUES
(1, 'Electronics', 299.99, 101, date_add(current_date(),1)),
(2, 'Clothing', 49.99, 102, date_add(current_date(),2)),
(3, 'Electronics', 599.00, 101, date_add(current_date(),3)),
(4, 'Books', 19.99, 103, date_add(current_date(),4)),
(5, 'Clothing', 89.99, 104, date_add(current_date(),5)),
(6, 'Electronics', 199.99, 105, date_add(current_date(),6)),
(7, 'Books', 29.99, 103, date_add(current_date(),7)),
(8, 'Clothing', 39.99, 106, date_add(current_date(),8)),
(9, 'Electronics', 899.00, 107, date_add(current_date(),9)),
(10, 'Books', 15.99, 108, date_add(current_date(),10));
-- 验证数据
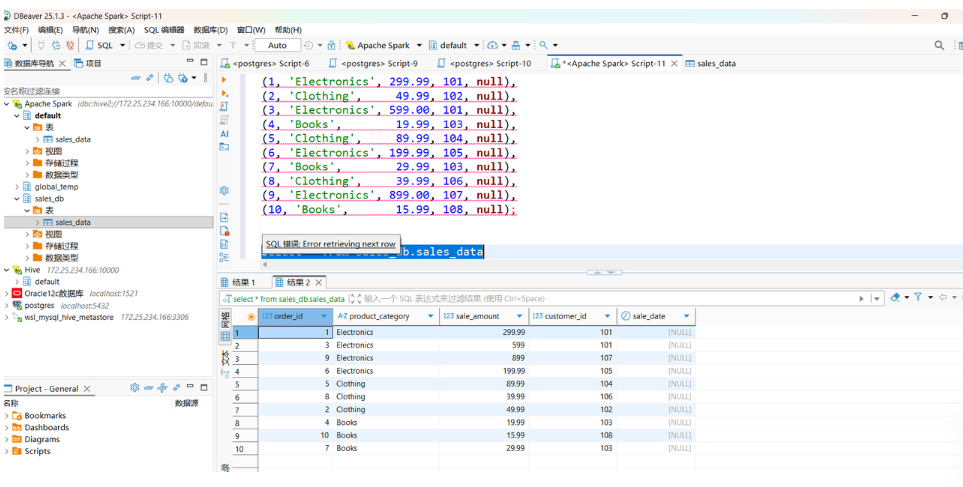
SELECT * FROM sales_db.sales_data LIMIT 5;这个查询会交给 Spark 引擎去执行,DBeaver 会负责展示最终的计算结果。
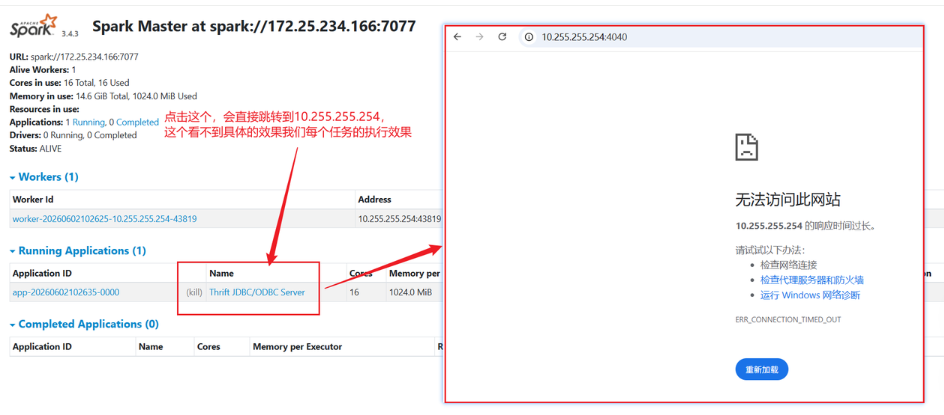
配置端口转发
(1)Spark 应用的 Driver UI 默认绑定到了 WSL 2 的虚拟 IP(10.255.255.254),而不是 0.0.0.0 或 Windows 可访问的地址。
(2)Windows 宿主机无法直接访问 WSL 2 的私网 IP(WSL 2 使用 NAT 网络,IP 会变化且不对外路由)。
在 Windows 管理员 PowerShell 中执行:
# 获取当前 WSL 的 IP
$wsl_ip = wsl hostname -I
# 添加端口转发规则
netsh interface portproxy add v4tov4 listenport=4040 listenaddress=0.0.0.0 connectport=4040 connectaddress=$wsl_ip
# (可选)开放防火墙
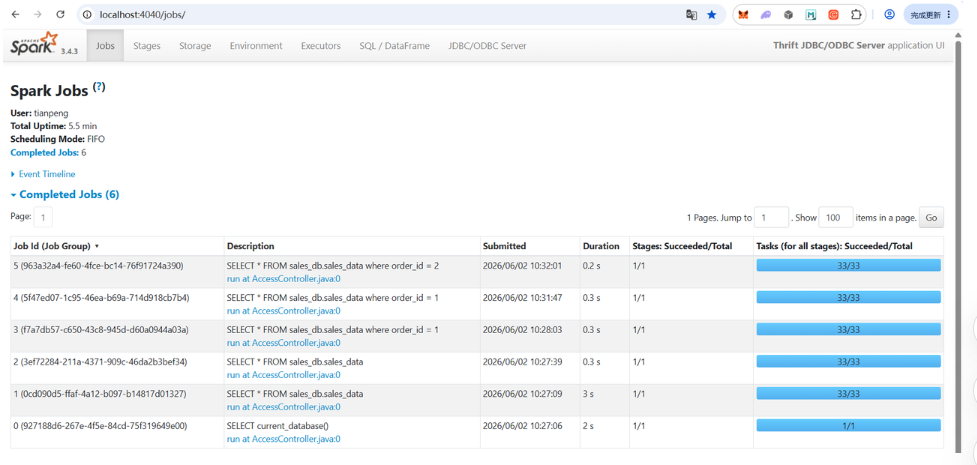
New-NetFirewallRule -DisplayName "Spark 4040" -Direction Inbound -LocalPort 4040 -Protocol TCP -Action Allow完成后访问 http://localhost:4040 即可。即可看到我们每次跑的SparkSQL任务
性能优化建议
-
使用执行计划分析:DBeaver 提供了可视化执行计划的功能,可以帮助你理解 Spark SQL 是如何被执行的,从而找出性能瓶颈。
-
善用 Spark SQL 特有函数 :Spark SQL 拥有丰富的内置函数,如
approx_percentile,collect_list等,可以在查询中充分利用它们来简化逻辑。 -
调整查询以利用 Spark 优化:例如,在多表 JOIN 时,合理调整 JOIN 顺序,使用 Broadcast Join 来优化小表与大表的关联,可以显著提升性能。
第五章:Flink安装与配置
步骤 1:下载并解压 Flink
# 切换到当前用户主目录下的 bigdata 文件夹。
cd ~/bigdata
# 从华为云镜像站下载 Flink 1.18.1 的安装包。
wget https://mirrors.huaweicloud.com/apache/flink/flink-1.18.1/flink-1.18.1-bin-scala_2.12.tgz
# 解压下载的 Flink 压缩包(-x 解压,-z 处理 gzip,-v 显示详情,-f 指定文件)。
tar -xzvf flink-1.18.1-bin-scala_2.12.tgz此时 Flink 的安装路径为:/home/tianpeng/bigdata/flink-1.18.1
步骤 2:配置 Flink 环境变量
执行如下的命令:
nano ~/.bashrc编辑 ~/.bashrc 文件,在末尾添加以下两行:
export FLINK_HOME=/home/tianpeng/bigdata/flink-1.18.1
export PATH=$PATH:$FLINK_HOME/bin保存后执行:
source ~/.bashrc验证环境变量:
echo $FLINK_HOME步骤 3:修改 Flink 配置
修改 Flink 配置文件
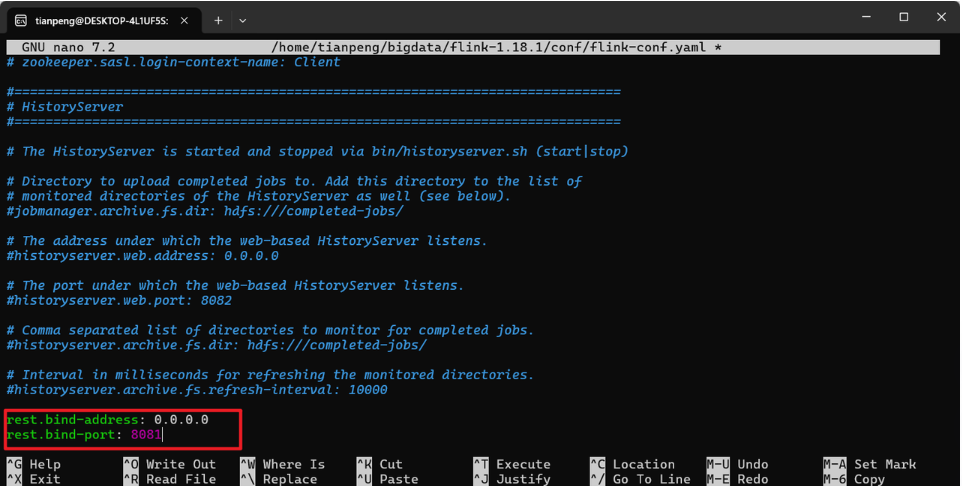
nano $FLINK_HOME/conf/flink-conf.yaml在文件中找到或添加以下几行(如果已存在则修改值):
rest.bind-address: 0.0.0.0
rest.bind-port: 8083
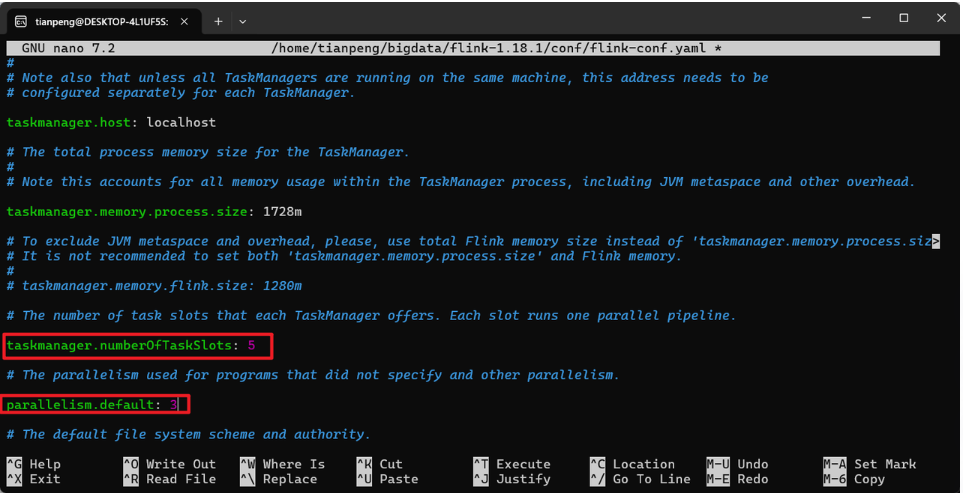
taskmanager.numberOfTaskSlots: 5
parallelism.default: 3注意:Spark Worker默认端口是8081,我们将其更改为8083。避免端口冲突。
将下面两个参数的数据调整为5和3:
保存:Ctrl+O → 回车 → Ctrl+X。
重启 Flink 集群
$FLINK_HOME/bin/stop-cluster.sh
$FLINK_HOME/bin/start-cluster.sh验证监听地址
ss -tlnp | grep 8083现在应该显示 0.0.0.0:8081 或 *:8083。
在 Windows 浏览器中访问
打开浏览器,访问 http://localhost:808``3,应该能看到 Flink Dashboard。
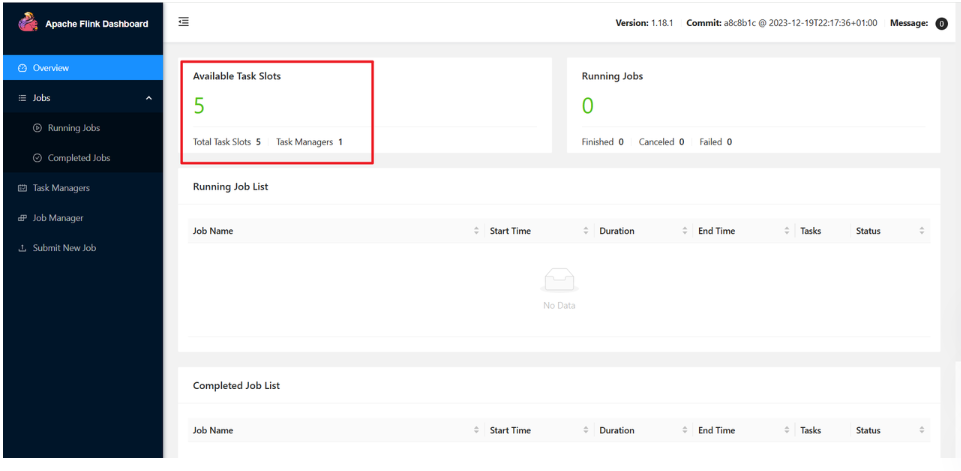
注意事项:
-
所有文件均保留在
~/bigdata下,与 Hadoop、Hive、Spark 等保持一致,无需sudo权限。 -
如果后续需要升级 Flink 版本,只需下载新版本解压并修改
FLINK_HOME环境变量即可。 -
启动 Flink 前无需启动 Hadoop,Flink 可以独立运行(Standalone 模式)。如果需要访问 HDFS,则需确保 Hadoop 已启动并配置好
HADOOP_HOME。
这样,你的 Flink 就安装在了用户目录下,与其他大数据组件统一管理。
步骤 4:案例演示
下面给出一个 Flink SQL 实时统计案例 ,使用内置的 datagen 数据源生成模拟数据,进行简单的聚合计算,并将结果输出到控制台。这个案例无需依赖 Kafka、MySQL 等外部组件,只要 Flink 集群正常运行即可执行,非常适合快速验证和学习。
1. 启动 Flink 集群
确保 Flink 已启动:
$FLINK_HOME/bin/start-cluster.sh访问 http://localhost:808``3 确认 Web UI 正常。
2. 启动 Flink SQL Client
$FLINK_HOME/bin/sql-client.sh embedded -D rest.address=localhost -D rest.port=8083进入 Flink SQL> 提示符后,可以执行以下 SQL。
3. 创建 数据源 表(模拟订单流)
-- 创建一个 datagen 源表,每秒生成 2 条订单数据
CREATE TABLE orders_source (
order_id INT,
product_name STRING,
amount DECIMAL(10,2),
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '2',
'fields.order_id.kind' = 'sequence',
'fields.order_id.start' = '1',
'fields.order_id.end' = '1000000',
'fields.product_name.length' = '5',
'fields.amount.min' = '10',
'fields.amount.max' = '500'
);输出如下内容:
4. 创建数据结果表(打印到控制台)
CREATE TABLE order_stats_sink (
window_start TIMESTAMP(3),
product_name STRING,
total_amount DECIMAL(10,2),
order_count BIGINT
) WITH (
'connector' = 'print'
);输出如下内容:
5. 执行统计查询并写入结果表
INSERT INTO order_stats_sink
SELECT
TUMBLE_START(event_time, INTERVAL '1' MINUTE) AS window_start,
product_name,
SUM(amount) AS total_amount,
COUNT(*) AS order_count
FROM orders_source
GROUP BY
TUMBLE(event_time, INTERVAL '1' MINUTE),
product_name;输出如下内容:
6. 观察输出
提交后,Flink 作业会开始运行。在 SQL Client 中,你会看到类似以下的打印输出(每 1 分钟输出一次):
+I[2025-04-22 10:15:00.000, product_abc, 1240.50, 8]
+I[2025-04-22 10:15:00.000, product_xyz, 980.00, 6]
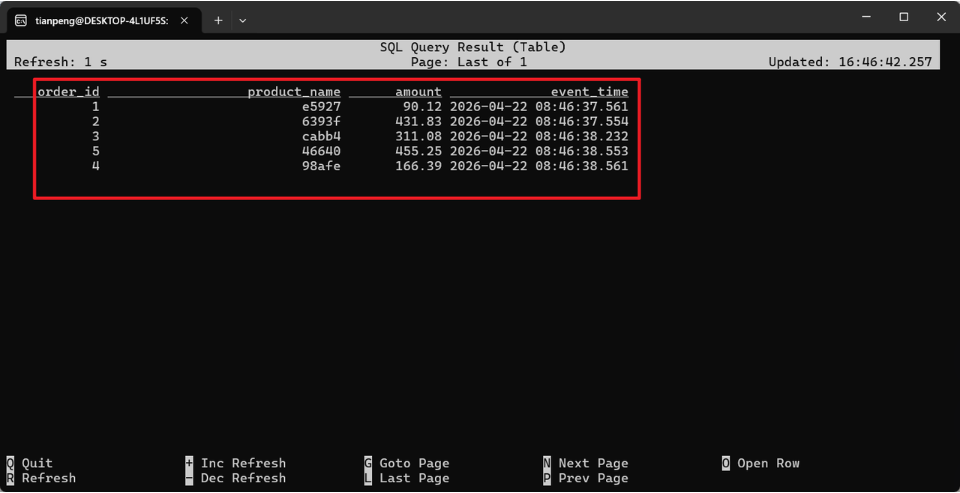
...在 SQL Client 中执行如下SQL, 应看到生成的模拟数据:
SET 'parallelism.default' = '1';
SELECT * FROM orders_source LIMIT 5;注意:
-
你的 TaskManager 有 5 个 slots,
INSERT作业默认的并行度通常是parallelism.default(在 Flink 1.18.1 中默认为3)。如果作业使用了 3 个 slot,那么剩余 2 个 slot。 -
SELECT * FROM orders_source LIMIT 5;也是一个独立的流查询作业,默认也会尝试申请相同数量的 slot(3 个),但可用 slot 可能不足(例如只剩 2 个),就会报资源不足。
所以我们在执行select查询前 ,先执行 SET 'parallelism.default' = '1';
7. 停止作业
在 SQL Client 中,按 Ctrl+C 退出客户端,或者通过 Web UI 取消作业。
**总结:**这个案例展示了 Flink SQL 的核心能力:
-
使用
datagen生成测试数据(无需外部数据源) -
定义水位线(WATERMARK)处理乱序数据
-
使用滚动窗口(TUMBLE)进行时间窗口聚合
-
将结果输出到
print连接器(控制台)
在你的 Flink SQL 小案例中,数据是实时流动的,并没有像传统数据库那样被"存储"在一个持久化的位置。具体来说:
-
源表
orders_source使用了datagen连接器。这个连接器只在内存中模拟生成数据,数据不会落盘,一旦 Flink 作业停止,所有生成的数据就消失了。 -
结果表
order_stats_sink使用了print连接器。它会将计算结果直接输出到 Flink TaskManager 的 标准输出 (通常是日志文件),例如在$FLINK_HOME/log/目录下的.out文件中,也不会持久化保存。
因此,整个案例中没有数据被永久存储 。你执行的 INSERT INTO ... SELECT 实际上启动了一个持续运行的流计算作业,它实时读取源表生成的数据、按分钟窗口聚合、并将每个窗口的结果实时打印到控制台(或日志)。当你停止作业或退出 SQL Client 时,所有中间状态和结果都会丢失。
如果你希望数据能被持久化,可以使用 Kafka 、JDBC 或 FileSystem 等连接器来定义源表和结果表。
在 Flink 中创建的表,其定义 和数据 是分开存储的。简单来说,数据的存储位置取决于创建表时指定的连接器(Connector) ,而表的定义则取决于你是否将其注册到了持久化的 Catalog 中。
🗄️ 表的数据存储在连接器定义的地方
Flink SQL 创建的表更像是一个"虚拟视图",它告诉 Flink 去哪里读取和写入数据。真正的数据存储在连接器定义的外部系统里。
| 连接器 (Connector) | 存储位置 |
|---|---|
| DataGen | 数据在内存中即时生成,不持久化存储。用于测试。 |
数据直接输出到 TaskManager 的日志文件(.out 或 .err),用于调试。 |
|
| Kafka | 数据存储在 Kafka Broker 中,Flink 负责生产和消费。 |
| FileSystem ( HDFS /S3) | 数据持久化到分布式文件系统。 |
| JDBC ( MySQL / PostgreSQL ) | 数据存储在关系型数据库中。 |
| Hive | 数据存储在 Hive 的 Metastore 中,可实现与 Hive 的互通。 |
📝 表的定义存储在 Catalog 中
-
元数据默认不持久化:表的定义(Schema、Connector 配置等)默认存储在 Flink SQL Client 的临时内存中。因此,退出 Client 后表定义会丢失。
-
使用 Catalog 持久化 :要持久化表定义,可以创建并使用一个持久化的 Catalog ,如 HiveCatalog。将表创建在持久化 Catalog 下,关闭 Client 后再打开,表定义依然存在。
💾 作业状态数据存储在状态后端
在执行有状态的流计算(如窗口聚合)时,作业的中间状态(State)会存储在 Flink 的状态后端中。可配置的状态后端如下:
| 状态后端 (State Backend) | 存储位置 |
|---|---|
| HashMapStateBackend | 状态存储在 TaskManager 的 JVM 堆内存中。 |
| RocksDBStateBackend | 状态存储在 TaskManager 本地磁盘(如 SSD/HDD)上。 |
- 持久化与恢复 :为防止作业崩溃时状态丢失,Flink 会定期将状态数据持久化到外部文件系统(如 HDFS、S3),生成 Checkpoint 。作业失败时,可以从最近的 Checkpoint 恢复状态。你也可以手动创建 Savepoint 来保存状态,用于作业升级或迁移。
**💎 总结:**总的来说,Flink 中的数据存储是一个分层、可插拔的系统,它允许你根据不同的需求和场景来选择合适的存储方式。
如果对某个特定连接器(比如 Kafka 或 HDFS)的数据存储细节感兴趣,随时可以继续问我。
步骤 5:通过 DBeaver 连接FlinkSQL
DBeaver 默认不包含 Flink 驱动,我们接下来要手动添加的步骤。这个过程其实很简单,本质就是为它配上一个专属的"翻译官"。你当前遇到的"No items found"是正常情况,这正是我们需要手动添加 Flink 驱动的原因。
1、在 DBeaver 中添加 Flink JDBC 驱动
我们需要先为 DBeaver 配置一个能"听懂" Flink 语言的新驱动。
(1)打开驱动管理器 :在 DBeaver 菜单栏点击 数据库(Database) -> 驱动管理器(Driver Manager)。
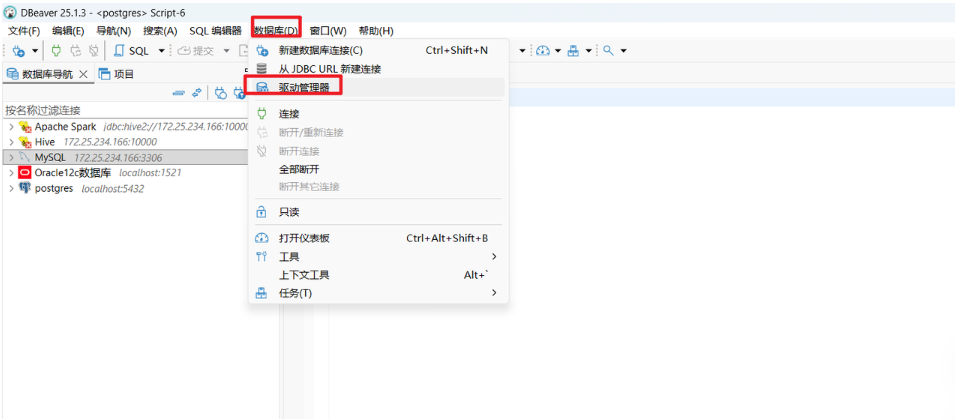
(2)新建驱动 :在驱动管理器窗口中,点击 新建(New) 按钮。
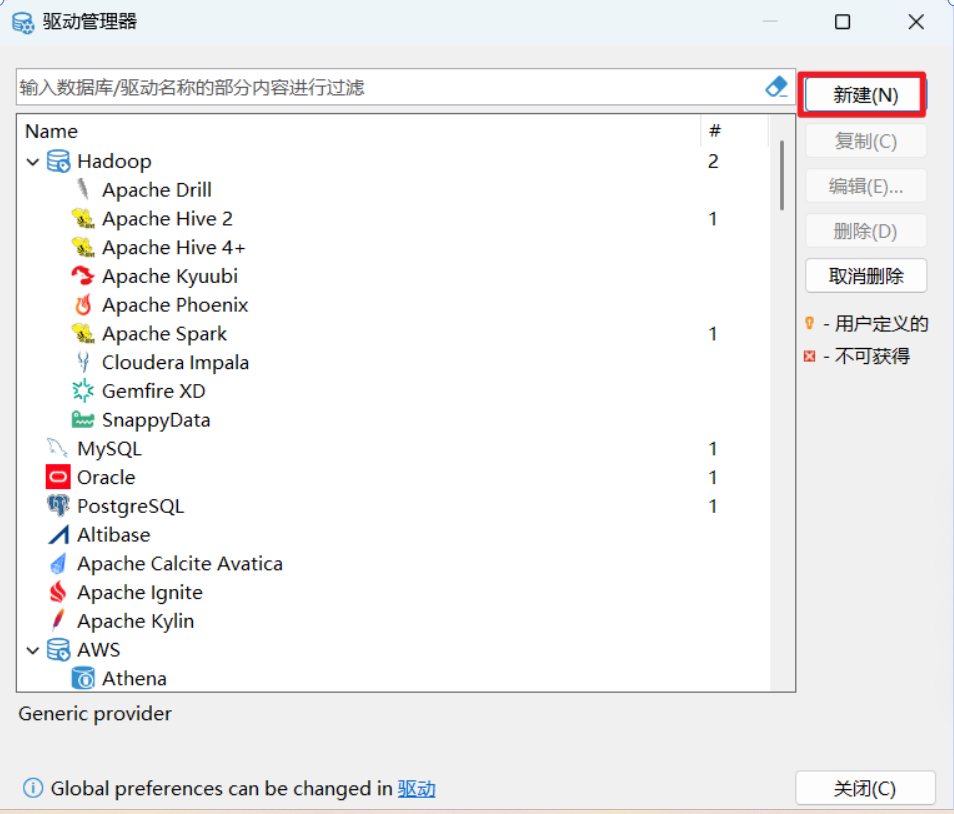
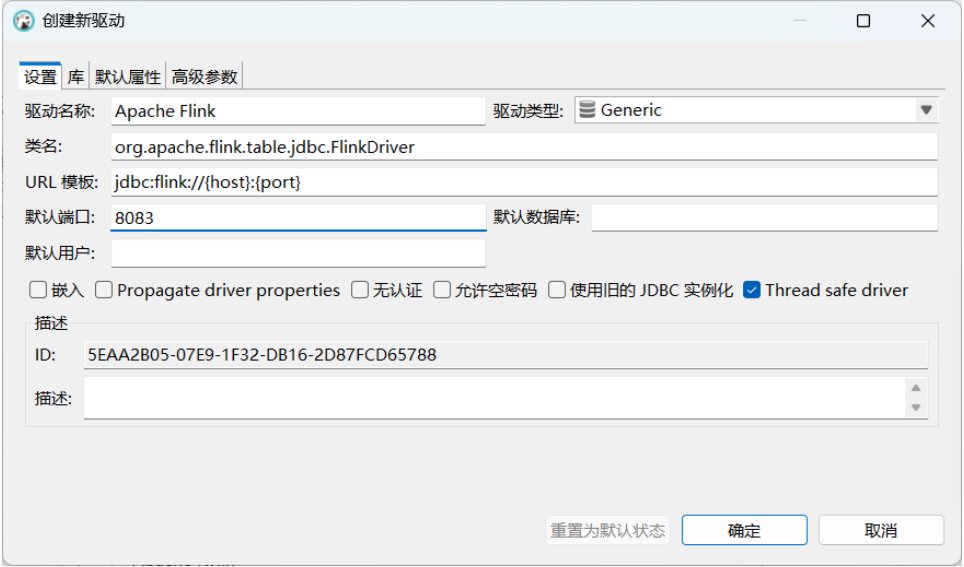
(3)填写驱动信息:在弹出的"创建新驱动"窗口中,按以下信息填写:
-
驱动名称 (Driver Name) :
Apache Flink(可自定义) -
类名 (Class Name) :
org.apache.flink.table.jdbc.FlinkDriver -
URL 模板 (URL Template) :
jdbc:flink://{host}:{port} -
默认 端口 (Default Port) :
8083(这是 Flink SQL Gateway 的默认端口)
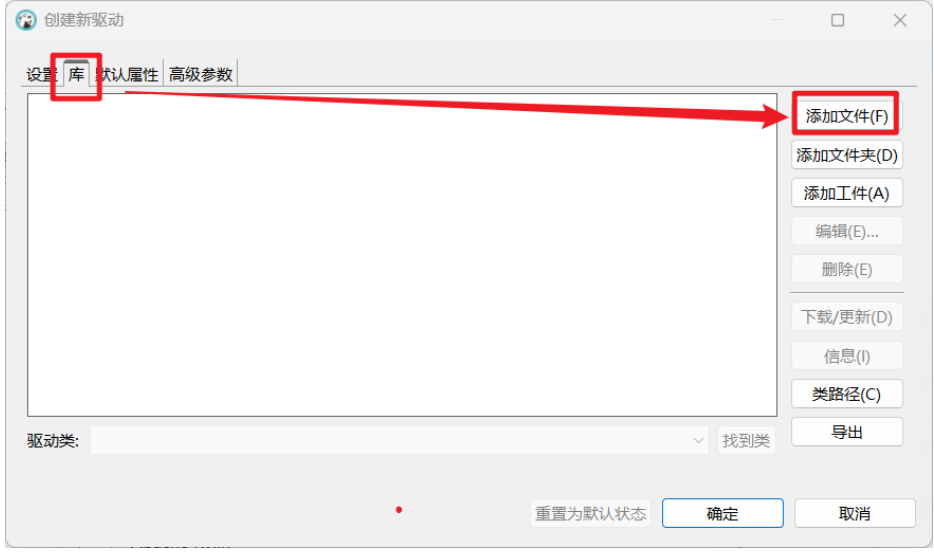
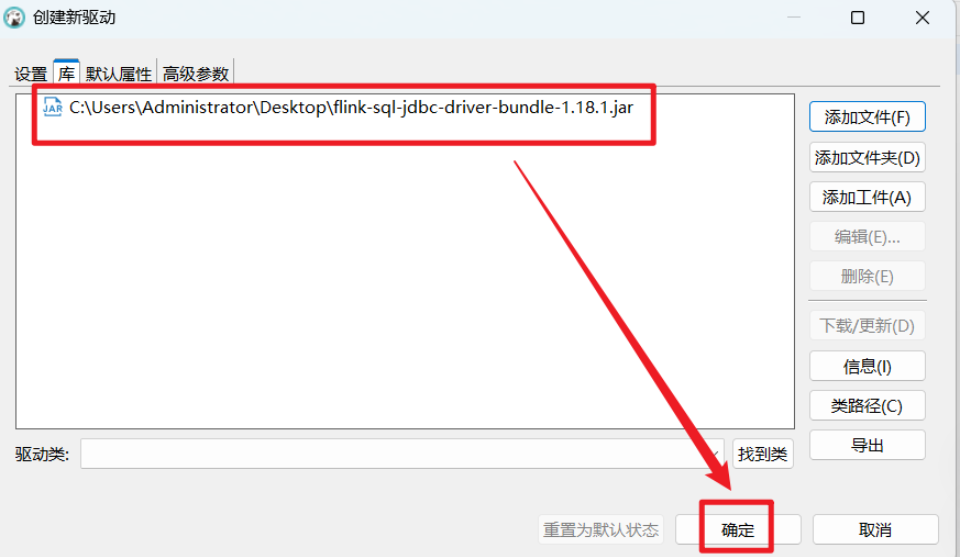
(4)添加驱动文件 (Libraries):
-
切换到 库(Libraries) 标签页。
-
点击 添加文件(Add File) 按钮。
-
-
关键一步 :你需要一个专用的
flink-sql-jdbc-driver-bundleJAR 包。Flink 官方并没有将它打包在发行版里,需要我们手动获取。 -
如何获取?
-
你可以从 Maven 官方仓库下载:点击这里下载。
-
选择与你 Flink 版本(如 1.18.1)匹配的
flink-sql-jdbc-driver-bundle-{VERSION}.jar文件下载。 -

-
(5)保存驱动 :点击 确定(OK) 保存。
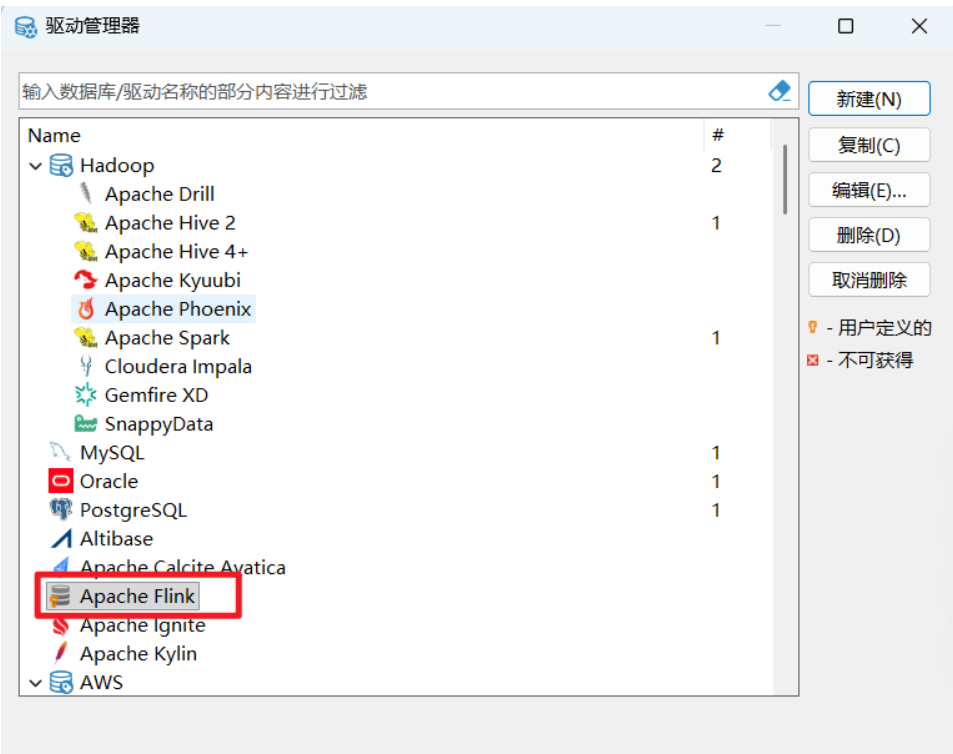
即表示配置成功:
2、启动 Flink SQL Gateway 服务
驱动配置好后,我们需要在 WSL 里把 Flink 的"服务端"启动起来,让 DBeaver 能找到它。
(1)打开一个新的 WSL 终端 ,并确保 Flink 集群本身已启动 ($FLINK_HOME/bin/start-cluster.sh)。
(2)启动 SQL Gateway:
cd $FLINK_HOME
./bin/sql-gateway.sh start -Dsql-gateway.endpoint.rest.address=localhost -Dsql-gateway.endpoint.rest.port=8084启动成功后,输入如下命令,验证端口(服务会监听在 8083 端口):
ss -tlnp | grep 8084
3、在 DBeaver 中创建连接
现在万事俱备,可以创建连接了。
(1)新建连接 :在 DBeaver 主界面点击 新建连接 按钮。
(2)选择驱动 :在"通用"或"全部"分类下,找到你刚刚创建的 Apache Flink 驱动。
(3)配置连接:
-
主机 (Host):WSL的IPv4地址来登录
-
端口 (Port) :
8083 -
用户名/密码:当前版本可以留空。
(4)测试连接 :点击 测试连接(Test Connection)。如果一切顺利,你应该会看到"连接成功"的提示。
(5)完成 :点击 完成(Finish),连接就会出现在左侧的数据库导航器中。
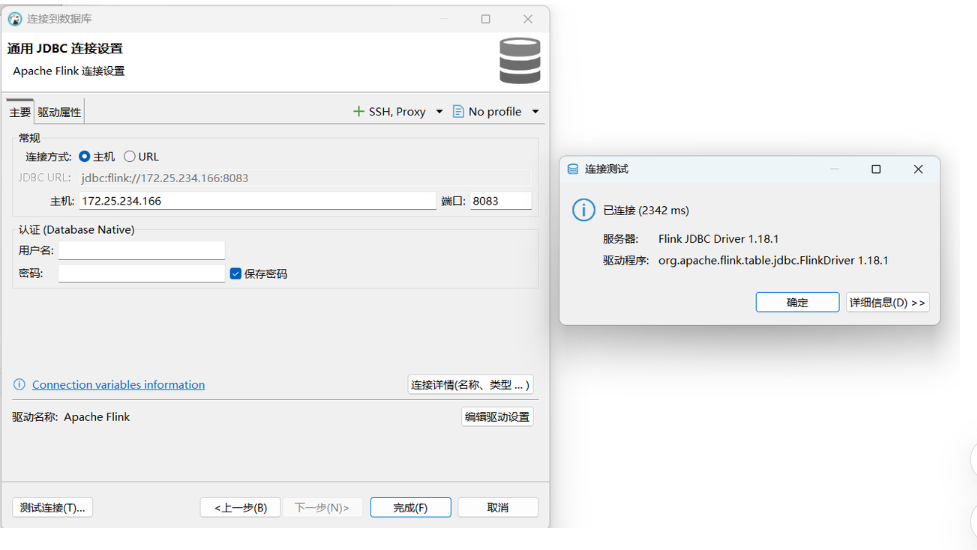
4、连接后的功能与限制
成功连接后,你就可以像使用普通数据库一样,在 DBeaver 中编写和执行 Flink SQL 了。但需要了解以下几点:
-
核心用途:在 DBeaver 中编写 Flink SQL 代码,并提交给 Flink 集群执行,非常方便。
-
主要限制:
-
⚠️ 流计算作业 :对于持续运行的流计算任务(比如
INSERT INTO ... SELECT ...),你可能需要在 Flink 的 Web UI (localhost:8081) 上手动取消作业,DBeaver 的"停止"按钮可能无法直接中断它。 -
📄 结果集限制 :使用
SELECT语句查询有限数据集 (如加了LIMIT子句)时,DBeaver 能正常返回结果。但对于无界的流式数据,查询会一直运行而不会自动返回,这时需要在 Web UI 上手动取消作业。 -
🔧 功能 兼容性:DBeaver 可能不完全支持 Flink 的所有高级 SQL 特性。
-
我们在DBeaver中输入如下的查询语句,查看数据:
SHOW CATALOGS;
SHOW DATABASES;
USE default_catalog.default_database;
SHOW TABLES;如果上述脚本都能正常跑通,说明连接正常。
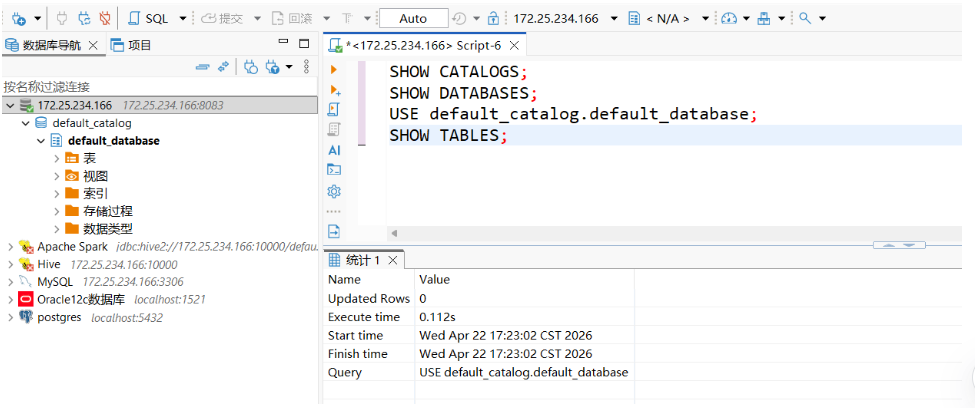
注意:此时执行如下命令可能会报错
SELECT * FROM orders_source LIMIT 5;查询失败原因:很可能是
datagen表通过 JDBC 查询时不受支持。建议改用批式源表(如filesystem、kafka且消费有限数据)或使用 Flink SQL Client 执行流查询。
第六章:DolphinScheduler安装与配置
1、环境前提
-
✅ WSL 中已有 Java 8(
java -version显示 1.8) -
✅ MySQL 服务已启动(
sudo service mysql status) -
✅ 网络连接正常
2、下载与解压
cd ~/bigdata
# 下载(使用华为云镜像,速度更快)
wget https://mirrors.huaweicloud.com/apache/dolphinscheduler/3.1.9/apache-dolphinscheduler-3.1.9-bin.tar.gz
# 解压
tar -xzvf apache-dolphinscheduler-3.1.9-bin.tar.gz
# 进入解压目录
cd apache-dolphinscheduler-3.1.9-bin3、创建 MySQL 数据库和用户
mysql -u root -p在 MySQL 中执行:
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE USER 'dolphin'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphin'@'%';
FLUSH PRIVILEGES;
EXIT;如果用户已存在,可以先
DROP USER 'dolphin'@'%';再创建。
4、配置数据库连接(通过 环境变量 ,无需编辑复杂的 YAML )
(1)修改 bin/env/dolphinscheduler_env.sh ,在apache-dolphinscheduler-3.1.9-bin目录下进入。
nano bin/env/dolphinscheduler_env.sh在文件末尾添加以下内容(注意,不要修改已有的其他配置,只追加):
export DATABASE=mysql
export SPRING_PROFILES_ACTIVE=mysql
export SPRING_DATASOURCE_URL="jdbc:mysql://localhost:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true"
export SPRING_DATASOURCE_USERNAME=dolphin
export SPRING_DATASOURCE_PASSWORD=123456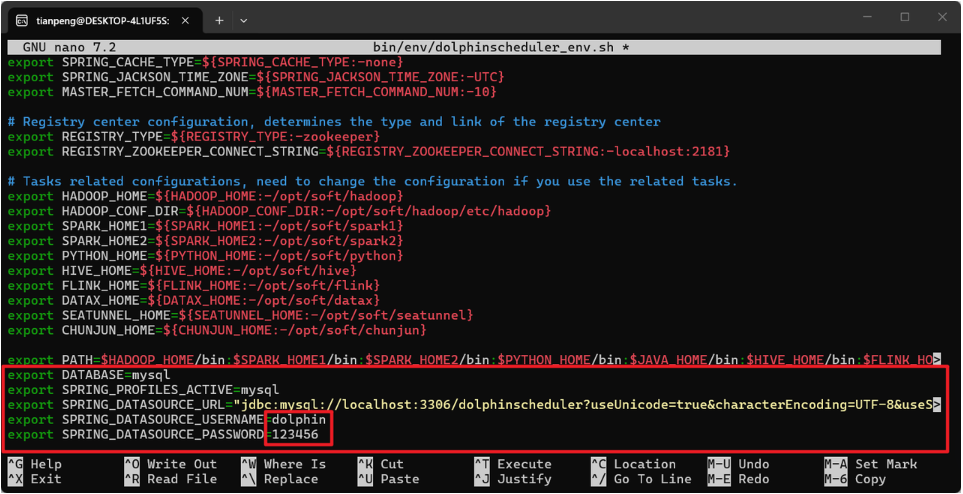 保存并退出(
保存并退出(Ctrl+O, 回车, Ctrl+X)。
(2)下载并放置 MySQL JDBC 驱动
我之前的驱动下载到**~/bigdata/apache-hive-3.1.3-bin** 中,不在**~/bigdata/**目录下,需要根据自己安装时的位置来处理。
# 复制驱动到 tools/libs(用于初始化数据库)
cp ~/bigdata/mysql-connector-java-8.0.16.jar tools/libs/
# 复制驱动到 standalone-server/libs/standalone-server(用于运行服务)
cd ~/bigdata/apache-dolphinscheduler-3.1.9-bin/standalone-server/libs/standalone-server
cp ~/bigdata/mysql-connector-java-8.0.16.jar .4、初始化数据库表结构
cd ~/bigdata/apache-dolphinscheduler-3.1.9-bin
bash tools/bin/upgrade-schema.sh输出如下内容:
等待执行完成,看到类似 schema upgrade success 或没有 ERROR 即为成功。如果报错连接 PostgreSQL,说明环境变量未生效,请检查上一步是否正确设置并执行 source 命令(可选,但可执行:source bin/env/dolphinscheduler_env.sh 后再运行升级脚本)。
6、启动 Standalone Server
bash bin/dolphinscheduler-daemon.sh start standalone-server查看启动日志(等待约 30 秒):
tail -f standalone-server/logs/dolphinscheduler-standalone.log当看到 Started StandaloneServer in ... seconds 且日志中无 ERROR 时,表示启动成功。
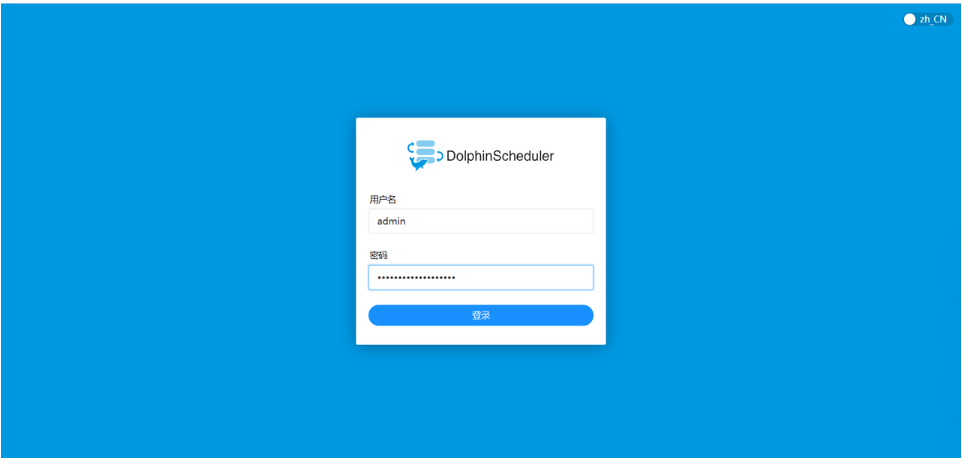
7、访问 Web UI
默认端口为 12345。但是由于spark已经使用打开 Windows 浏览器访问:
http://localhost:12345/dolphinscheduler/ui如果无法访问,尝试使用 WSL 的 IP 地址(例如 http://172.25.234.166:12345/dolphinscheduler/ui)。
默认账号:
-
用户名:
admin -
密码:
dolphinscheduler123
8、初次登录后的必要配置
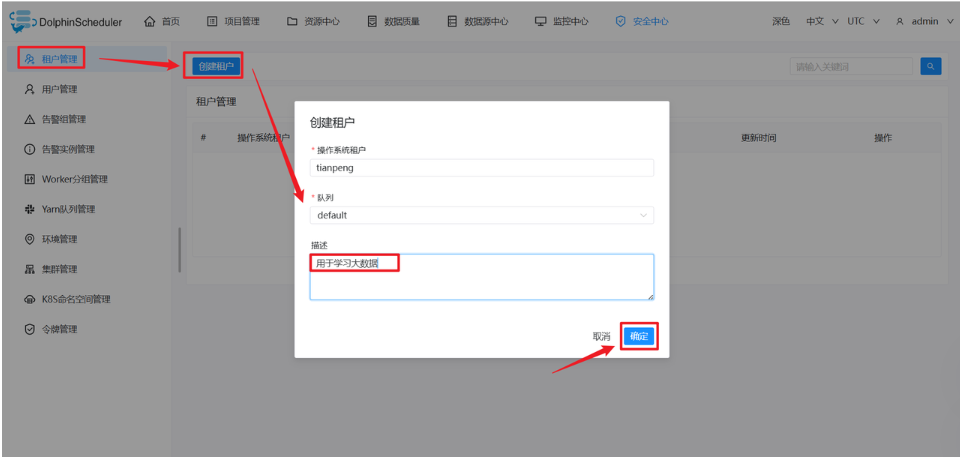
(1)创建租户(必须!否则任务无法执行)
登录后,点击右上角用户名 → 安全中心 → 租户管理 → 创建租户。
-
租户编码 :输入您的 WSL 用户名(例如
tianpeng,可通过whoami命令查看) -
租户名称:可同编码
-
队列 :默认
default -
点击 提交
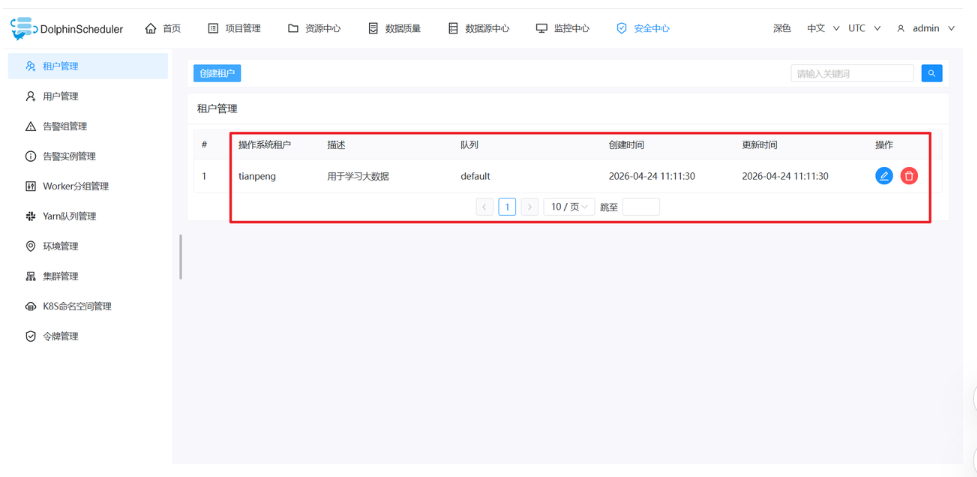
租户是 DolphinScheduler 执行任务时使用的 Linux 用户,必须与 WSL 用户名一致,否则任务会因权限不足失败。
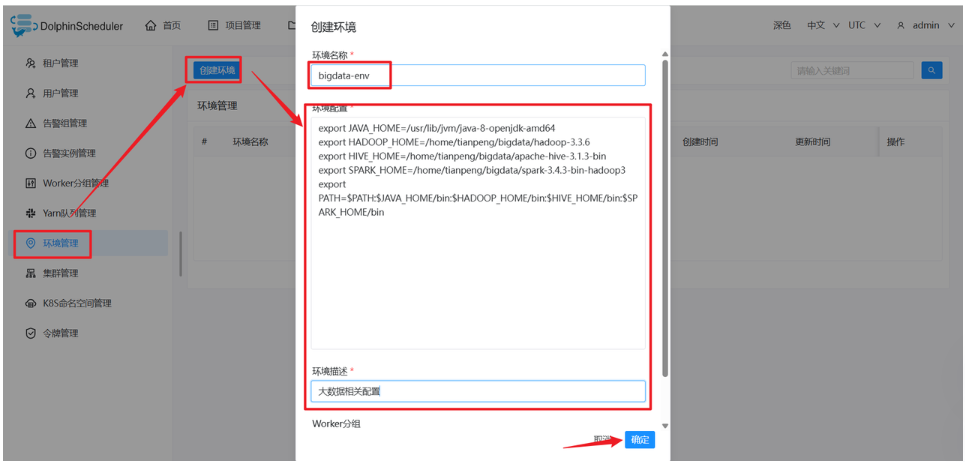
(2)创建环境(可选但推荐,便于后续运行大数据任务)
安全中心 → 环境管理 → 创建环境:
-
环境名称 :例如
bigdata-env -
环境配置:根据您的组件路径填写,例如:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HADOOP_HOME=/home/tianpeng/bigdata/hadoop-3.3.6 export HIVE_HOME=/home/tianpeng/bigdata/apache-hive-3.1.3-bin export SPARK_HOME=/home/tianpeng/bigdata/spark-3.4.3-bin-hadoop3 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin -
点击 提交
 9、停止服务
9、停止服务
cd ~/bigdata/apache-dolphinscheduler-3.1.9-bin
bash bin/dolphinscheduler-daemon.sh stop standalone-server常见问题与排错
| 问题 | 原因与解决方法 |
|---|---|
upgrade-schema.sh 尝试连接 PostgreSQL |
环境变量未生效。请确保 bin/env/dolphinscheduler_env.sh 中正确设置了 DATABASE=mysql 和 SPRING_PROFILES_ACTIVE=mysql。可以执行 source bin/env/dolphinscheduler_env.sh 后再运行升级脚本。 |
| 启动后没有监听 8080 端口 | 检查 standalone-server/logs/dolphinscheduler-standalone.log 中的错误。常见原因为 8080 端口被占用,可修改端口(见下方)。 |
| 访问 Web UI 时页面空白或 404 | 使用正确的路径 /dolphinscheduler/ui,不要只访问根路径。或尝试清除浏览器缓存。 |
| 租户创建后任务执行失败 | 确认租户编码与 WSL 用户名完全一致,并且该用户有执行命令的权限(如 hive、spark-submit 等)。 |
| 需要修改 Web 端口 | 在 standalone-server/conf/application.yaml 中创建(如不存在)并添加:server: port: 12345 然后重启。 |
验证安装成功:
(1)Web UI 能正常登录。
(2)创建一个测试工作流(例如 Shell 任务,输出 echo "Hello DolphinScheduler"),运行后查看日志输出正常。
至此,您已经成功安装了 DolphinScheduler 并完成了必要配置。可以开始使用它调度您的大数据任务了。
第七章:DataX安装
1、安装与配置 DataX
DataX 安装的核心就是"下载解压,开箱即用",非常方便,无需复杂编译。
(1)环境准备
-
Java: DataX 依赖 Java 8 运行,请确认 Java 环境已就绪。
-
Python : DataX 的启动脚本
datax.py依赖于 Python 2.6+ 环境。如果你的默认 Python 是 Python 3,需确保python命令能指向 Python 2.x。Python3 的安装和配置
sudo apt update
sudo apt install python3 python3-pip -y确认python是否安装成功
python3 --version
查询安装路径
which python3
注意:先检查Python是否安装,未安装的需要先安装Python3
(2)下载与解压DataX
在终端执行以下命令:
cd ~/bigdata
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz
tar -zxvf datax.tar.gz解压完成后,得到一个 datax 目录,DataX 即安装完毕。
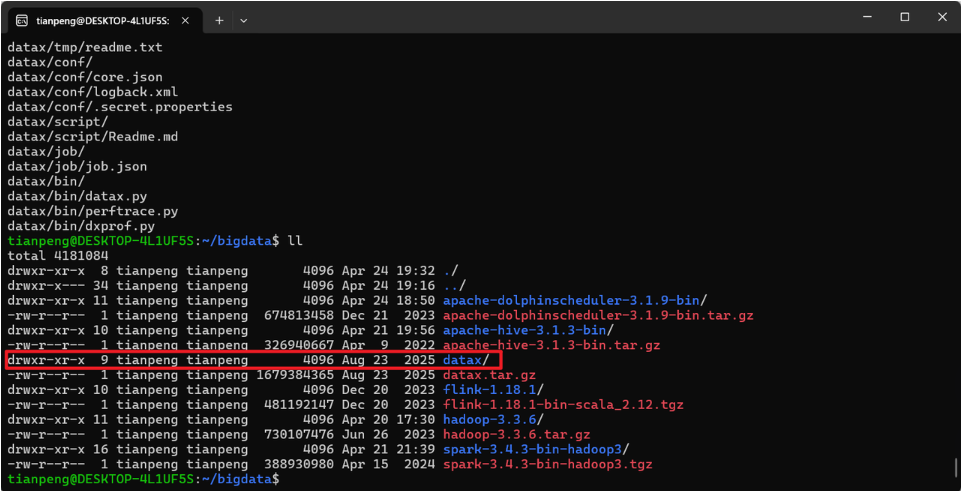
(3)验证安装
运行官方自带的测试任务,验证 DataX 是否可以正常工作。
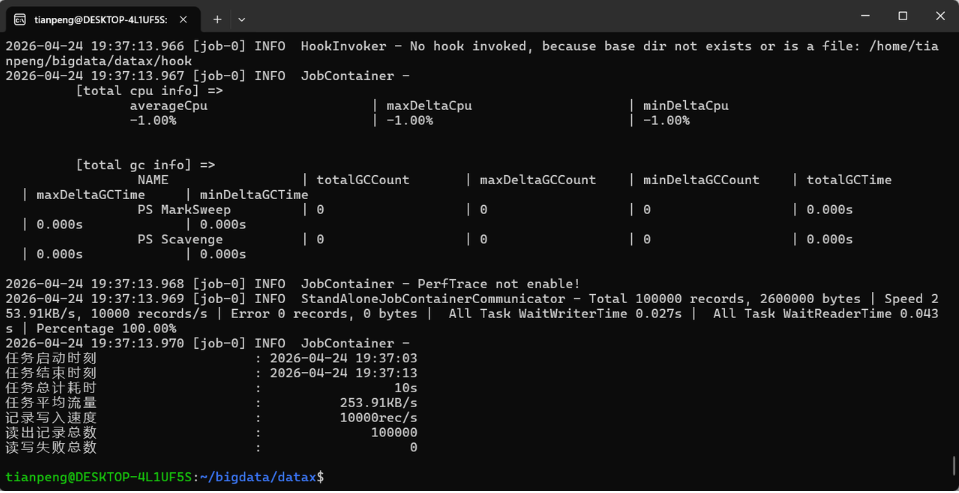
cd ~/bigdata/datax
python3 bin/datax.py job/job.json如果看到任务成功结束的统计信息,说明 DataX 安装成功,如下图
(4)核心概念:DataX 任务配置文件 ( JSON )
DataX 通过 JSON 配置文件定义数据同步任务,文件结构如下:
{
"job": {
"setting": { ... }, # 全局配置,如并发通道数(channel)
"content": [ # 任务内容,可定义多个同步任务
{
"reader": { # 读取端配置,指定数据源
"name": "mysqlreader",
"parameter": { ... }
},
"writer": { # 写入端配置,指定目标数据源
"name": "hdfswriter",
"parameter": { ... }
}
}
]
}
}2、部署 DataX-Web (可视化界面)
DataX-Web 为 DataX 提供了一个 Web 操作界面,让创建、管理和监控同步任务变得更直观。
(1)环境准备
-
Java :
DataX-Web需要Java 8。 -
MySQL :
DataX-Web的元数据需要依赖MySQL 5.7+数据库。 -
Maven :
DataX-Web需要从源码编译构建,所以你需要提前在WSL中安装好Maven。可以在终端输入mvn -version检查Maven是否已安装。
注意:上面的需要安装好以后才继续往下安装,如果没有安装的问AI。
(2) 源码 获取与编译
DataX-Web 没有直接提供安装包,需要我们克隆其源码并使用 Maven 构建。
cd ~/bigdata
git clone https://gitcode.com/gh_mirrors/da/datax-web
cd datax-web
mvn clean package -Dmaven.test.skip=true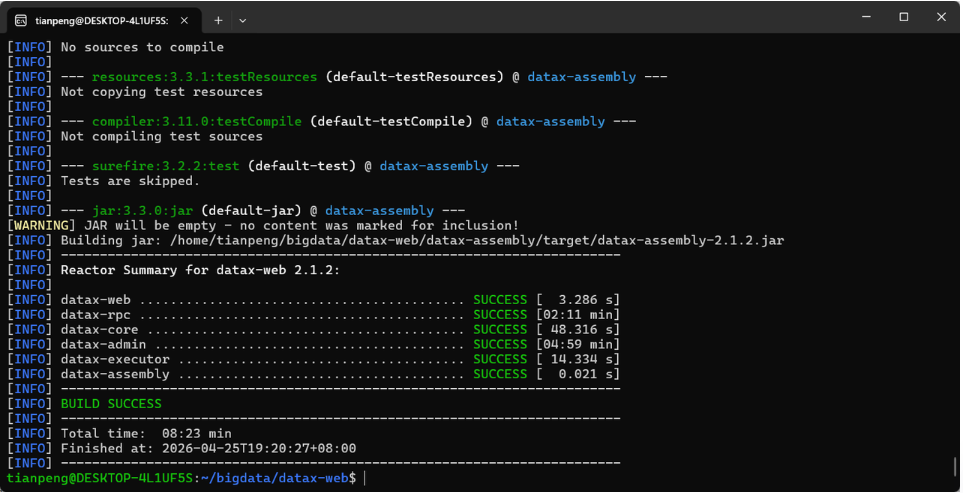
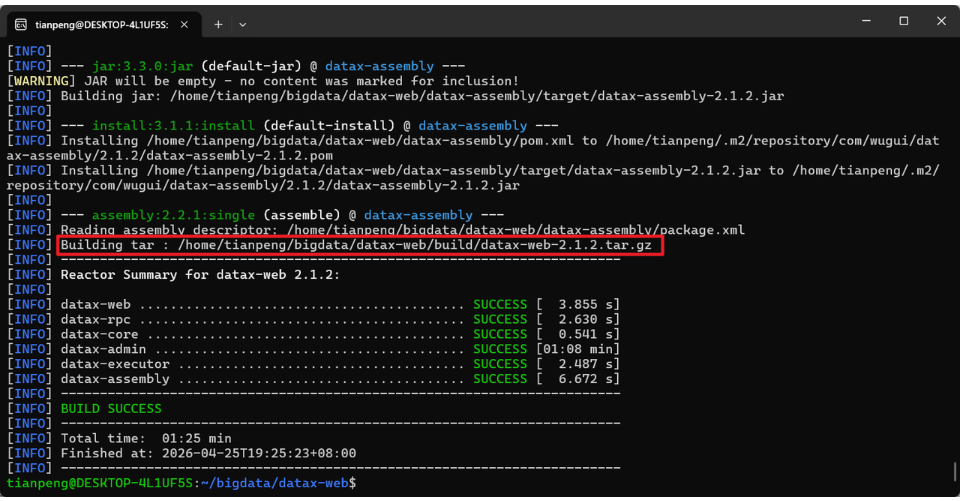
从源码安装需要先打包。由于DataX-Web 是一个 Maven 多模块项目,所以 build 目录需要通过 mvn clean install 命令来生成
# 执行Maven打包命令(会自动进行清理和安装步骤)
mvn clean install编译成功后,会在 datax-web/build/ 目录下生成一个名为 datax-web-<version>.tar.gz 的安装包
(3)解压与一键安装
将生成的安装包解压,并使用其自带的一键安装脚本进行部署。
# 进入 DataX-Web 源码编译后生成的构建输出目录
cd ~/bigdata/datax-web/build
# 解压生成的 DataX-Web 安装包(版本为 2.1.2)到 ~/bigdata 目录下
tar -zxvf datax-web-2.1.2.tar.gz -C ~/bigdata(4)数据库配置与初始化
方法一:使用一键安装脚本进行交互式初始化(推荐)
如果你的 MySQL 和 DataX-Web 在同一台 WSL 环境中,这个方法最简单:
进入安装目录并执行脚本:
cd /home/tianpeng/bigdata/datax-web-2.1.2
./bin/install.sh --force回答脚本的交互式问题:
-
脚本执行后,会根据系统环境依次询问信息:
-
是否初始化数据库 :当出现
Do you want to initialize database with sql: .../bin/db/datax-web.sql? (Y/N)时,输入Y。 -
数据库 IP 地址
db host:直接按 回车 ,或输入127.0.0.1。 -
数据库 端口
db port:直接按 回车 ,使用默认的3306。 -
数据库用户名
db username:输入你之前创建的 MySQL 用户名,比如dolphin或root。 -
数据库密码
db password:输入该数据库用户的密码。 -
数据库名称
db name:输入之前为 DataX-Web 创建的数据库名称,例如datax_web。
-
成功的话,你会看到一条初始化成功的提示。
方法二:手动执行 SQL 脚本(通用)
如果自动脚本没有执行数据库初始化,或你需要手动操作,可以按以下步骤进行。
找到 SQL 脚本文件 :SQL脚本通常位于安装目录下的
bin/db/datax-web.sql。登录 MySQL:
mysql -u root -p执行 SQL 文件来初始化数据库:
USE datax_web; SOURCE /home/tianpeng/bigdata/datax-web-2.1.2/bin/db/datax-web.sql;这个步骤会为你创建 DataX-Web 所需的所有表结构。
➡️ 修改配置文件
数据库初始化完成后,我们需要修改几个关键文件,告诉 DataX-Web 如何连接数据库,以及 DataX 在哪里。
设置 DataX 执行引擎的路径 :编辑 modules/datax-executor/bin/env.properties 文件,指定 Python 和 DataX 的路径。
cd /home/tianpeng/bigdata/datax-web-2.1.2
nano modules/datax-executor/bin/env.properties找到 PYTHON_PATH 这一行,将其修改为:
PYTHON_PATH=/usr/bin/python3保存并退出。
修改 datax-admin 数据库连接配置:
cd /home/tianpeng/bigdata/datax-web-2.1.2
nano modules/datax-admin/conf/bootstrap.properties找到并确认数据库连接信息与你创建的数据库信息一致:
DB_HOST=127.0.0.1
DB_PORT=3306
DB_USERNAME=root
DB_PASSWORD=123456
DB_DATABASE=dataxweb保存并退出。
▶️ 启动与停止服务
启动所有服务
进入启动脚本目录,一键启动所有服务:
cd /home/tianpeng/bigdata/datax-web-2.1.2/bin && ./start-all.sh启动成功后,你可以通过 jps 命令查看是否有 DataXAdminApplication 和 DataXExecutorApplication 这两个进程,以此确认服务是否正常运行。
访问 Web 界面:
- 服务启动后,在浏览器中访问
http://localhost:9527/index.html,登录 DataX-Web。
登录:
-
用户名 :
admin -
密码 :
123456
进行简单的连接测试:
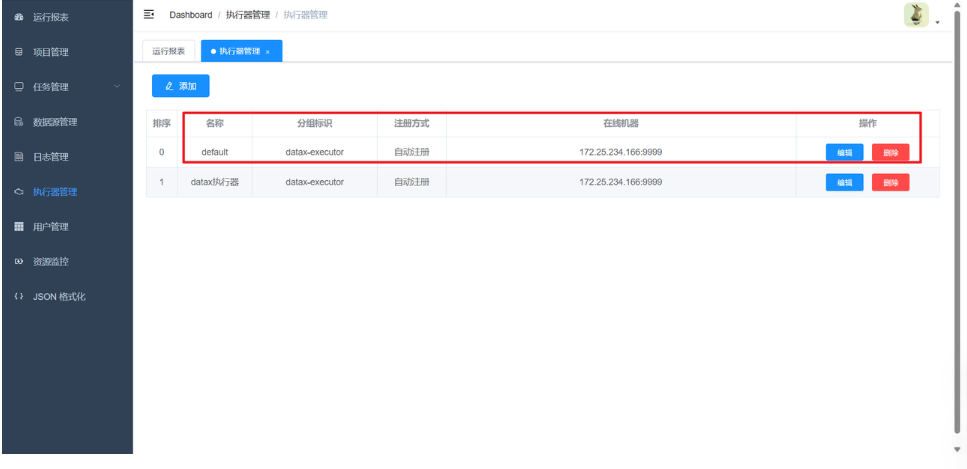
- 登录后,建议立即前往 "执行器管理" 页面,你应该能看到一个自动注册的名为
datax-executor的执行器,且其状态应为"在线"。如果状态不是"在线",请检查日志排查原因。
3、在 DataX-Web 中创建你的第一个任务
成功登录后,我们可以通过 Web 界面来创建一个任务,整个过程将取代手动编写 JSON 文件。
(1)配置执行器
-
登录后,进入 执行器管理 页面。
-
点击"新增执行器",AppName 填写
datax-executor,名称填写default,注册方式选择"自动注册",然后保存。等待片刻,执行器状态会变为"在线"。
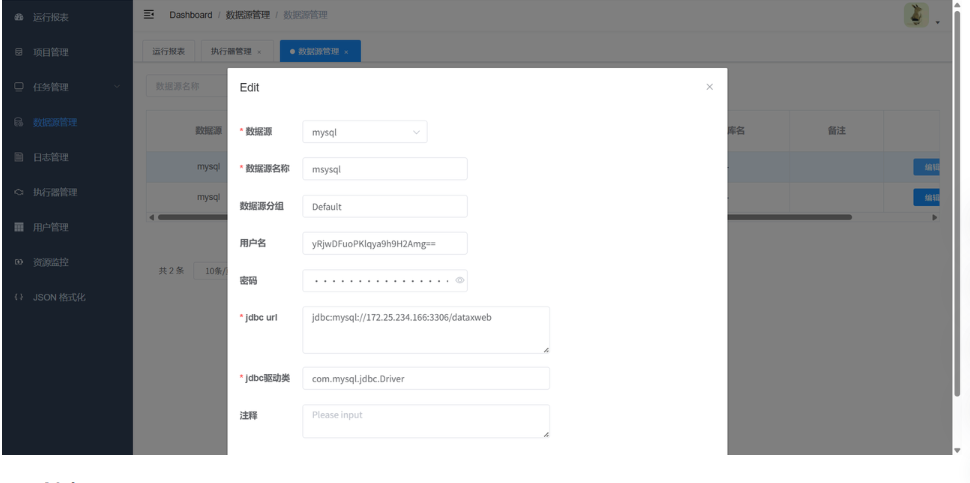
(2)配置 数据源
-
进入 数据源 管理 页面,点击"新建数据源"。
-
选择要连接的数据源类型,例如
MySQL,填写连接信息、用户名和密码。 -
同理,创建另一个目标数据源,如
HDFS或Hive。
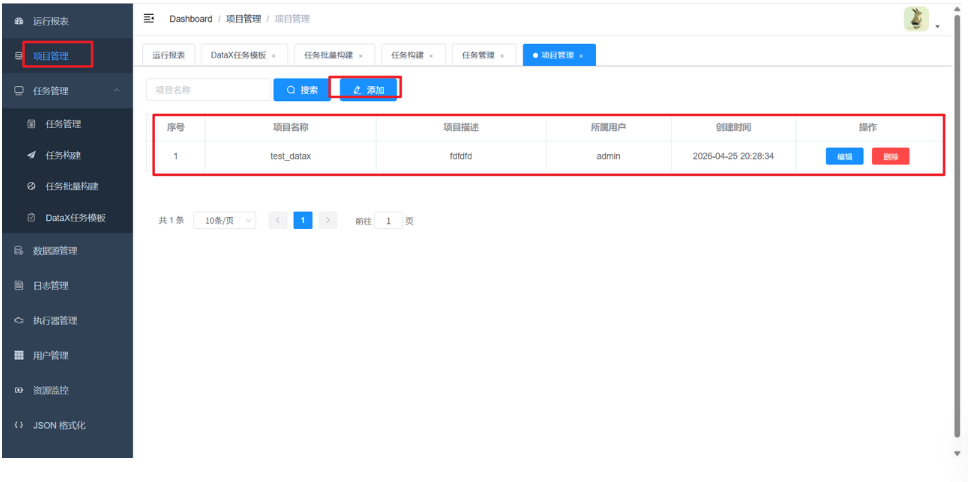
(3) 创建项目
(4)创建模板
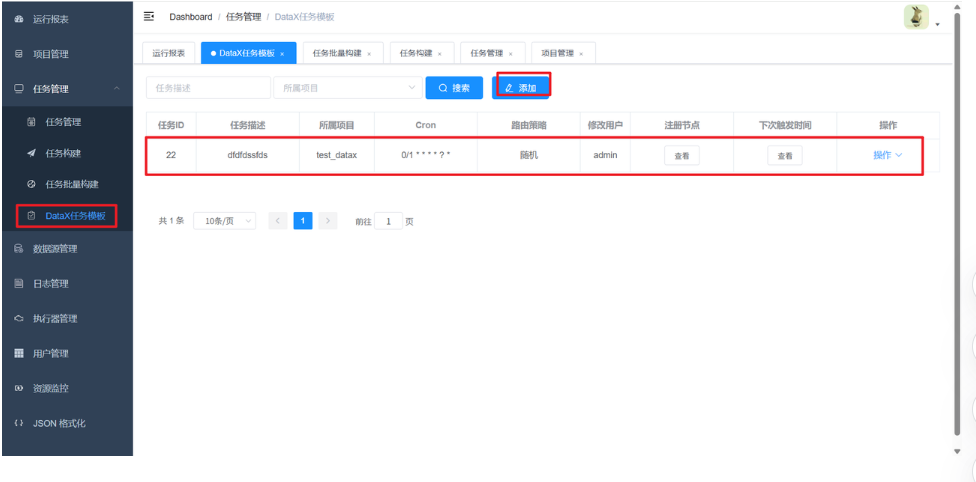
(5)创建与配置任务
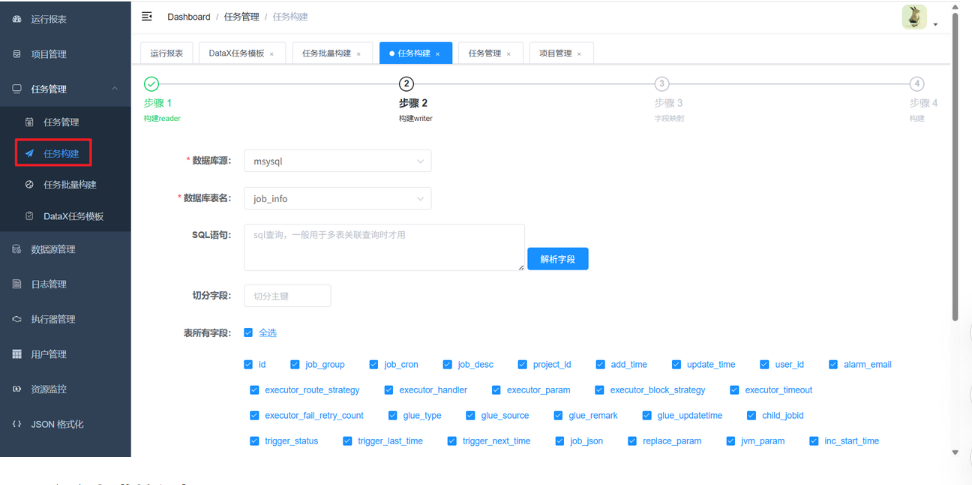
-
进入 任务管理 页面,点击"新建任务"。
-
选择任务类型为
DataX,然后选择你刚才创建的Reader和Writer数据源。 -
在字段映射环节,页面会自动生成
Reader和Writer之间的字段映射关系,你可以根据需要调整。 -
确认无误后,保存任务。
(4)运行与监控任务
-
在任务列表中,点击"运行"按钮即可手动触发一次同步任务。
-
你可以在任务列表中查看任务的执行日志 和历史记录,获取详细的执行结果。
-
如果需要定时同步,可以在"任务管理"中配置任务的调度策略,DataX-Web 集成了 XXL-JOB,支持 Cron 表达式来设置定时任务。
(5)停止所有服务
在 bin 目录下执行:
cd /home/tianpeng/bigdata/datax-web-2.1.2/bin && ./stop-all.sh至此,你已经完成了 DataX 和 DataX-Web 的完整安装,并成功通过 Web 界面创建并运行了一个数据同步任务。
第八章:Kafka安装
1. 检查 Java 版本
在终端中执行:
java -version # 或 java -version根据输出结果,选择合适的 Kafka 版本:
| Java 版本 | 推荐 Kafka 版本 | 模式 | 说明 |
|---|---|---|---|
| Java 8 或 11 | Kafka 3.5.x(3.x 系列) | ZooKeeper 模式 | 稳定可靠,支持 Java 8+ |
| Java 11+ | Kafka 3.5.x 或 4.0.x | KRaft 模式(3.x 实验性,4.x 稳定) | 推荐后者,需 Java 17+ |
| Java 17+ | Kafka 4.0.x | KRaft 模式 | 最新,去掉 ZooKeeper |
根据你之前安装 Hadoop、Spark 等组件时使用的大概率是 Java 8(因为 Hive 3.1.3 需要 Java 8),所以下面以 Java 8 + Kafka 3.5.x(ZooKeeper 模式)为例给出安装步骤。如果你的 Java 版本更高,可以在后续步骤中切换到 KRaft 模式。
安装 Kafka 3.5.x( ZooKeeper 模式,兼容 Java 8/11)
第一步:下载与解压
cd ~/bigdata
wget https://mirrors.huaweicloud.com/apache/kafka/3.9.0/kafka_2.12-3.9.0.tgz
tar -xzf kafka_2.12-3.9.0.tgz
cd kafka_2.12-3.9.0第二步:启动 ZooKeeper 和 Kafka
ZooKeeper 是 Kafka 3.x 的元数据管理依赖,需要先启动。
# 启动 ZooKeeper(后台运行)
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
# 等待 3 秒,确保 ZooKeeper 启动
sleep 3
# 启动 Kafka Broker(后台运行)
./bin/kafka-server-start.sh -daemon config/server.properties第三步:验证服务是否启动
# 查看进程
jps应该能看到 QuorumPeerMain(ZooKeeper)和 Kafka 两个进程。
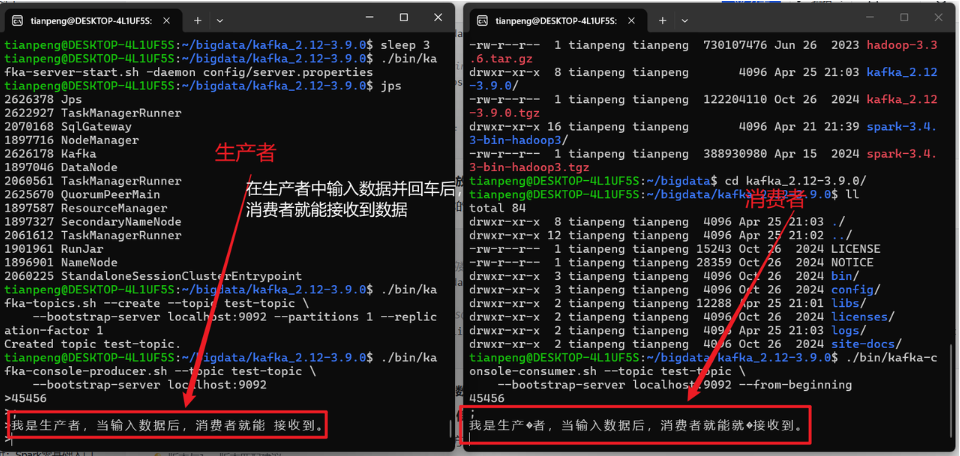
第四步:创建主题并测试
# 创建测试主题
bigdata/kafka_2.12-3.9.0/bin/kafka-topics.sh --create --topic test-topic \
--bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
# 启动生产者(键盘输入消息)
bigdata/kafka_2.12-3.9.0/bin/kafka-console-producer.sh --topic test-topic \
--bootstrap-server localhost:9092
# 另开一个终端,启动消费者(会显示生产者输入的消息)
bigdata/kafka_2.12-3.9.0/bin/kafka-console-consumer.sh --topic test-topic \
--bootstrap-server localhost:9092 --from-beginning生产者中输入数据时,消费者既能接收到数据。
第五步:停止服务(可选)
# 停止 Kafka
./bin/kafka-server-stop.sh
# 停止 ZooKeeper
./bin/zookeeper-server-stop.sh备选:KRaft 模式(若 Java 版本 ≥ 17)
如果你检查 Java 版本是 17 或更高,可以使用 Kafka 4.0 的 KRaft 模式(无需 ZooKeeper)。安装步骤如下:
cd ~/bigdata
wget https://downloads.apache.org/kafka/4.0.0/kafka_2.13-4.0.0.tgz
tar -xzf kafka_2.13-4.0.0.tgz
cd kafka_2.13-4.0.0
# 生成集群 UUID
UUID=$(./bin/kafka-storage.sh random-uuid)
echo $UUID
# 格式化日志目录
./bin/kafka-storage.sh format -t $UUID -c config/kraft/server.properties
# 启动 Kafka(不带 ZooKeeper)
./bin/kafka-server-start.sh config/kraft/server.properties验证方式相同。
总结:
-
先
java --version确认版本。 -
若 Java 8/11 → 安装 Kafka 3.5.x(ZooKeeper 模式)。
-
若 Java 17+ → 安装 Kafka 4.0.x(KRaft 模式)。
请执行 java --version 并告诉我输出,我可以为你精确调整安装命令。如果已经明确,直接按上述对应方案安装即可。
第九章:FlinkCDC安装
要搭建 Flink CDC,需要先部署好 Apache Flink 环境,再把 CDC 组件接进去,它本身不是一个独立运行的程序。下面我会以一个清晰、通用的流程来介绍。
为了方便你快速安装,我把整个过程梳理成下面这张流程图:
---
config:
theme: forest
---
flowchart TD
A[准备工作\n(JDK 11, Flink)] --> B[部署 Flink Standalone 集群]
B --> C[下载并解压\nFlink CDC 发行包]
C --> D[配置 Flink CDC 环境]
D --> E{选择作业提交方式}
E -- "DataStream API\n(Java/Scala 代码)" --> F[在 Flink 应用代码中\n添加 Maven 依赖]
E -- "YAML Pipeline\n(推荐,Flink CDC 3.x)" --> G[编写 YAML 配置文件]
F --> H[打包并提交 Flink 作业]
G --> H
H --> I[在 Flink Web UI \n监控作业运行状态]下面我们来逐一拆解这张流程图里的关键步骤。
1. 准备工作
在开始前,请确保你的环境满足以下要求:
-
JDK :要求 JDK 11 或更高版本。
-
操作系统:WSL(Ubuntu)完全可以,任何类 Unix 环境都适用。
2. 部署 Flink
Flink CDC 是运行在 Flink 之上的。在你刚刚配置好的 Flink 环境目录下,按顺序执行以下命令:
# 进入 Flink 安装目录
cd ~/bigdata/flink-1.18.1
# 启动集群
./bin/start-cluster.sh
# 启动集群后,可以通过以下命令快速查看进程状态
ps aux | grep flink你也可以访问 http://localhost:8081 查看 Flink Web UI,确认集群已正常运行。
3. 下载与安装 Flink CDC
Flink CDC 提供了一个独立的发行包,里面包含了运行所需的脚本和核心依赖。
# 进入你的软件目录
cd ~/bigdata
# 下载 Flink CDC 安装包(示例版本为 3.5.0,建议访问 Apache 官网获取最新版本号)
wget https://dlcdn.apache.org/flink/flink-cdc-3.5.0/flink-cdc-3.5.0-bin.tar.gz
# 下载 jdk 11
# sudo apt install -y openjdk-11-jdk
# 解压
tar -zxvf flink-cdc-3.5.0-bin.tar.gz4. ⚙️ 配置环境并放置连接器 JAR 包
你可能需要根据你的数据源和目标端,下载相应的连接器 JAR 包,并放到 Flink CDC 发行包的 lib/ 目录下。
# 假设你的数据源是 MySQL
cd ~/bigdata/flink-cdc-3.5.0
# 下载 MySQL CDC Connector JAR(以 3.5.0 版本为例)
wget -P lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-cdc-pipeline-connector-mysql/3.5.0/flink-cdc-pipeline-connector-mysql-3.5.0.jar5. ✍️ 开发与提交数据同步作业
方式一(推荐):使用 YAML 文件提交
Flink CDC 的主流方式是编写一个简洁的 YAML 配置文件,然后通过 flink-cdc.sh 脚本提交。
1. 编写 YAML 配置文件
创建一个 mysql-to-kafka.yaml 文件,用于定义从 MySQL 到 Kafka 的数据同步任务:
nano mysql-to-kafka.yaml
# mysql-to-kafka.yaml
source:
type: mysql
hostname: 172.25.234.166
port: 3306
username: root
password: 123456
tables: app_db.\.* # 同步 app_db 库下的所有表
server-id: 5400-5404 # 建议为 MySQL 同步任务配置一个唯一的 server-id 范围,避免与其它同步任务产生冲突
sink:
type: kafka
brokers: localhost:9092
topic: mysql_${table_name} # 将每张表的数据动态写入名为 "mysql_表名" 的 Kafka Topic 中
pipeline:
name: mysql_to_kafka_pipeline
parallelism: 22. 提交作业
cd ~/bigdata/flink-cdc-3.5.0
./bin/flink-cdc.sh mysql-to-kafka.yaml方式二:通过编程方式(DataStream API )
这种方式更适合需要复杂数据处理的场景。你需要在 Java/Scala 项目中引入 Flink CDC 的 Maven 依赖,来编写代码。
MySQL 用户须知
如果数据源是 MySQL,需要创建一个有特定权限的用户,并开启 Binlog。相关的 SQL 如下:
CREATE USER 'flinkcdc'@'%' IDENTIFIED BY 'your_password'; GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flinkcdc'@'%'; flush privileges;同时,MySQL 的 Binlog 格式必须是
ROW。server-id这个参数也很重要,如果同一个 MySQL 实例上有多个同步任务,每个任务都需要配置不同且全局唯一的server-id范围,以避免冲突。
🧪 步骤 6:验证同步结果
同步任务提交后,数据就会从 MySQL 实时流向 Kafka。要验证同步是否成功,可以检查 Flink Web UI(http://localhost:8081)上作业的运行状态。如果数据已成功写入,你应该能看到作业的 Records Sent 计数在增加。同时,也可以在 Kafka 中消费对应的 Topic(例如 mysql_表名)来确认消息。
🧹 环境清理(可选)
测试完成后,可以用下面的命令清理环境。
# 停止 Flink 集群
cd ~/bigdata/flink-1.18.1
./bin/stop-cluster.sh
# (可选)删除 Flink CDC 安装目录
cd ~/bigdata
rm -rf flink-cdc-3.5.0
# (可选)删除 MySQL 测试用户
# mysql -u root -p -e "DROP USER IF EXISTS 'flinkcdc'@'%';"💎 总结
整个 Flink CDC 的安装和基本使用,关键就这么几点:
-
核心架构:Flink CDC 必须运行在 Flink 集群之上,不是独立程序。
-
主流用法 :官方推荐使用 YAML 文件 +
flink-cdc.sh脚本来提交任务,非常直观。 -
关键前置准备:取决于你的数据源,需要提前做好配置,例如在 MySQL 中开启 Binlog 并创建合适的用户。
-
版本兼容:务必留意 Flink 和 Flink CDC 的版本对应关系,生产环境建议选用官方推荐的稳定版本。
为了能帮你出更合适的建议,方便告诉我你计划同步什么数据(比如从MySQL到Kafka,还是到HDFS)吗?我可以针对你的场景,给出一份具体的YAML配置示例。
第十章:Iceberg安装
一、在 WSL 中安装 Apache Iceberg 的详细步骤(与 Spark 集成)
1. 环境准备
确保已安装:
-
Java 11(推荐)或 17:
sudo apt install openjdk-11-jdk -
Spark 3.4+:下载解压到
~/bigdata/spark-3.4.3-bin-hadoop3 -
配置
$SPARK_HOME环境变量:echo 'export SPARK_HOME=~/bigdata/spark-3.4.3-bin-hadoop3' >> ~/.bashrc && source ~/.bashrc
2. 下载 Iceberg Spark Runtime JAR
cd $SPARK_HOME/jars
wget https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.4_2.12/1.5.0/iceberg-spark-runtime-3.4_2.12-1.5.0.jar版本号可根据需要调整:
iceberg-spark-runtime-3.4_2.12对应 Spark 3.4 + Scala 2.12。
3. 配置 Spark 的 spark-defaults.conf
创建或编辑配置文件:
nano $SPARK_HOME/conf/spark-defaults.conf添加以下内容(使用 HadoopCatalog,元数据存储在本地文件系统):
spark.sql.extensions org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
spark.sql.catalog.iceberg_catalog org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.iceberg_catalog.type hadoop
spark.sql.catalog.iceberg_catalog.warehouse file:///home/tianpeng/iceberg_warehouse保存:Ctrl+O,回车;退出:Ctrl+X。
4. 创建 Iceberg 数据仓库 目录
mkdir -p ~/iceberg_warehouse5. 启动 Spark Shell 验证
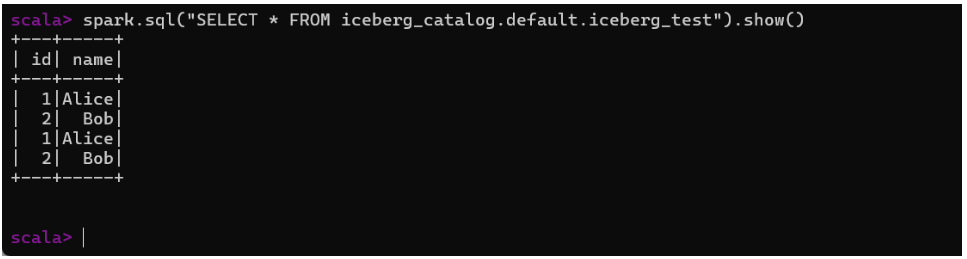
$SPARK_HOME/bin/spark-shell在 Scala 中执行:
spark.sql("CREATE TABLE iceberg_catalog.default.iceberg_test (id INT, name STRING) USING iceberg")
spark.sql("INSERT INTO iceberg_catalog.default.iceberg_test VALUES (1, 'Alice'), (2, 'Bob')")
spark.sql("SELECT * FROM iceberg_catalog.default.iceberg_test").show()成功则显示数据。
二、使用 DBeaver 连接 Iceberg 的详细步骤(通过 Spark Thrift Server )
1. 配置 Spark Thrift Server 支持 Iceberg
编辑 Spark 配置文件,确保已包含 Iceberg 扩展(若未配置则添加):
nano $SPARK_HOME/conf/spark-defaults.conf确认存在以下配置(若已有则跳过):
spark.sql.extensions org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
spark.sql.catalog.iceberg_catalog org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.iceberg_catalog.type hadoop
spark.sql.catalog.iceberg_catalog.warehouse file:///home/tianpeng/iceberg_warehouse2. 启动 Spark Thrift Server (使用 端口 10004)
cd $SPARK_HOME
./sbin/start-thriftserver.sh \
--master local[*] \
--hiveconf hive.server2.thrift.port=10004 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.iceberg_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.iceberg_catalog.type=hadoop \
--conf spark.sql.catalog.iceberg_catalog.warehouse=file:///home/tianpeng/iceberg_warehouse检查进程:
jps | grep HiveThriftServer2
netstat -tlnp | grep 100043. 在 DBeaver 中配置 Spark 驱动
-
打开 DBeaver → 菜单栏"数据库" → "驱动管理器" → "新建"
-
驱动名称:
Spark Iceberg -
类名:
org.apache.hive.jdbc.HiveDriver -
URL 模板:
jdbc:hive2://{host}:{port}/{database} -
默认端口:
10004 -
点击"库" → "添加文件" → 选择
$SPARK_HOME/jars/hive-jdbc-*.jar和$SPARK_HOME/jars/hive-service-*.jar(或下载 Hive JDBC 驱动包:https://repo1.maven.org/maven2/org/apache/hive/hive-jdbc/4.0.1/hive-jdbc-4.0.1-standalone.jar) -
点击"找到类" → 选择
org.apache.hive.jdbc.HiveDriver
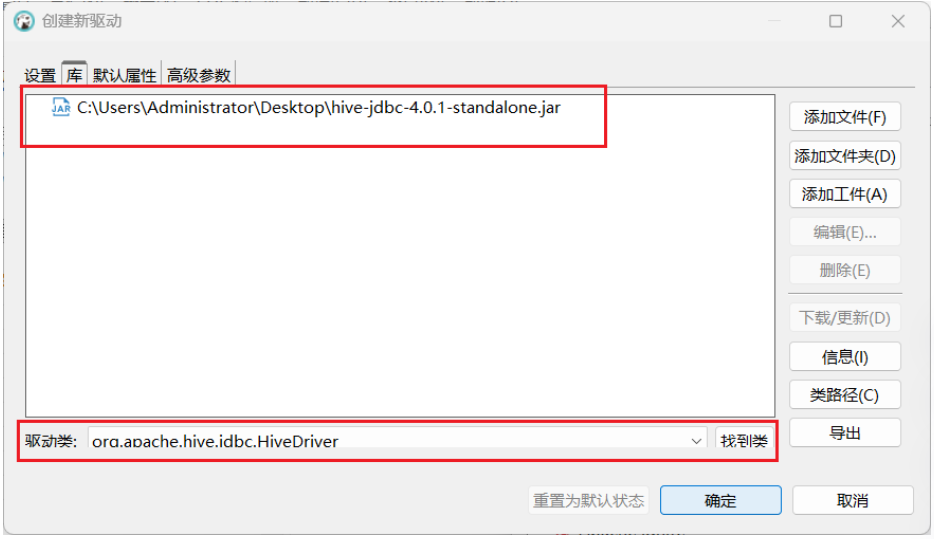
- 确定保存。
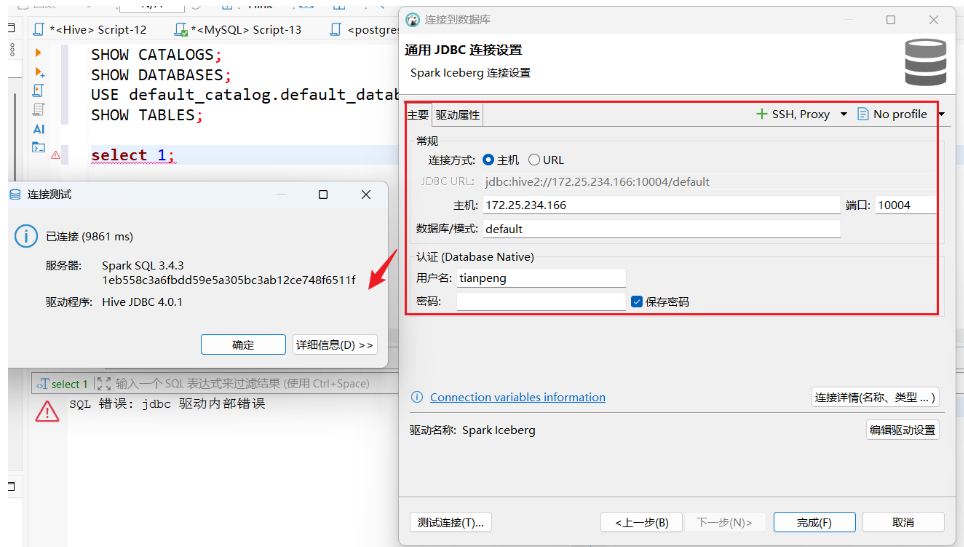
4. 创建 DBeaver 连接
-
点击"新建数据库连接" → 选择
Spark Iceberg驱动 -
主机:
localhost -
端口:
10004 -
数据库:
default -
用户名:
tianpeng(随意) -
点击"测试连接" → 应提示"已连接"
5. 查询 Iceberg 表
在 SQL 编辑器中执行:
USE iceberg_catalog.default;
SHOW TABLES;
SELECT * FROM iceberg_test;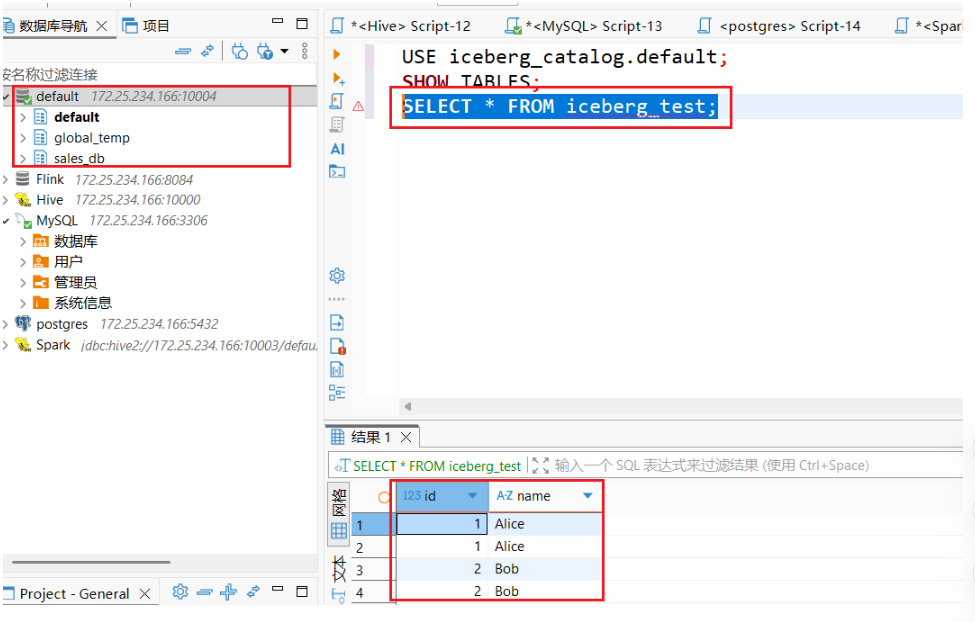
以上命令均包含具体的文件打开(nano)和修改内容,可直接复制执行。如需使用 HiveCatalog 或其他存储,可替换对应的配置项。
第十一章:大数据组件完整卸载脚本
将以下内容完整复制,保存为 uninstall_all.sh,放在用户主目录(~)下,执行 bash uninstall_all.sh 即可一键删除所有组件、安装包、数据库、环境变量。
#!/bin/bash
# ============================================================
# 大数据组件完整卸载脚本
# 适用于:WSL Ubuntu 环境
# 作者:根据《第02讲:大数据环境安装》文档定制
# 用法:bash uninstall_all.sh
# 注意:此脚本会删除 ~/bigdata 下所有内容及相关数据库!
# ============================================================
set -e
USER_NAME=$(whoami)
USER_HOME="/home/${USER_NAME}"
BIGDATA_DIR="${USER_HOME}/bigdata"
echo "========================================="
echo " 大数据组件完整卸载脚本"
echo " 用户:${USER_NAME}"
echo " 目标目录:${BIGDATA_DIR}"
echo " 开始时间:$(date)"
echo "========================================="
echo ""
echo "警告:此脚本将删除所有大数据组件、安装包、数据库和环境变量!"
read -p "确认继续?(输入 YES 继续): " confirm
if [ "$confirm" != "YES" ]; then
echo "已取消"
exit 0
fi
# ============================================================
# 第一步:停止所有运行中的服务
# ============================================================
echo ""
echo "========================================="
echo "[1/8] 停止所有运行中的服务..."
echo "========================================="
# 停止 Crabc
if pgrep -f "crabc-admin" > /dev/null 2>&1; then
echo " - 停止 Crabc..."
ps -ef | grep crabc-admin | grep -v grep | awk '{print $2}' | xargs kill 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - Crabc 未运行"
fi
# 停止 DolphinScheduler
if [ -d "${BIGDATA_DIR}/apache-dolphinscheduler-3.1.9-bin" ]; then
echo " - 停止 DolphinScheduler..."
cd ${BIGDATA_DIR}/apache-dolphinscheduler-3.1.9-bin 2>/dev/null && bash bin/dolphinscheduler-daemon.sh stop standalone-server 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - DolphinScheduler 未安装"
fi
# 停止 DataX-Web
if [ -f "${BIGDATA_DIR}/datax-web-2.1.2/bin/stop-all.sh" ]; then
echo " - 停止 DataX-Web..."
cd ${BIGDATA_DIR}/datax-web-2.1.2/bin 2>/dev/null && bash stop-all.sh 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - DataX-Web 未安装"
fi
# 停止 Flink
if [ -d "${BIGDATA_DIR}/flink-1.18.1" ]; then
echo " - 停止 Flink..."
cd ${BIGDATA_DIR}/flink-1.18.1 2>/dev/null && ./bin/stop-cluster.sh 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - Flink 未安装"
fi
# 停止 Spark
if [ -d "${BIGDATA_DIR}/spark-3.4.3-bin-hadoop3" ]; then
echo " - 停止 Spark..."
cd ${BIGDATA_DIR}/spark-3.4.3-bin-hadoop3 2>/dev/null
sbin/stop-worker.sh 2>/dev/null || true
sbin/stop-master.sh 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - Spark 未安装"
fi
# 停止 HiveServer2 和 MetaStore
if pgrep -f "HiveServer2" > /dev/null 2>&1; then
echo " - 停止 HiveServer2..."
kill $(pgrep -f "HiveServer2") 2>/dev/null || true
echo " ✓ 已停止"
fi
if pgrep -f "HiveMetaStore" > /dev/null 2>&1; then
echo " - 停止 HiveMetaStore..."
kill $(pgrep -f "HiveMetaStore") 2>/dev/null || true
echo " ✓ 已停止"
fi
if ! pgrep -f "HiveServer2" > /dev/null 2>&1 && ! pgrep -f "HiveMetaStore" > /dev/null 2>&1; then
echo " - Hive 服务未运行"
fi
# 停止 Hadoop
if [ -d "${BIGDATA_DIR}/hadoop-3.3.6" ]; then
echo " - 停止 Hadoop..."
export HADOOP_HOME=${BIGDATA_DIR}/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
${HADOOP_HOME}/sbin/stop-yarn.sh 2>/dev/null || true
${HADOOP_HOME}/sbin/stop-dfs.sh 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - Hadoop 未安装"
fi
# 停止 Kafka
if [ -d "${BIGDATA_DIR}/kafka_2.12-3.9.0" ]; then
echo " - 停止 Kafka..."
cd ${BIGDATA_DIR}/kafka_2.12-3.9.0 2>/dev/null
bin/kafka-server-stop.sh 2>/dev/null || true
bin/zookeeper-server-stop.sh 2>/dev/null || true
echo " ✓ 已停止"
else
echo " - Kafka 未安装"
fi
# 确保 MySQL 运行以删除数据库
echo " - 启动 MySQL(用于删除数据库)..."
sudo service mysql start 2>/dev/null || true
sleep 2
echo " 所有服务已停止。"
# ============================================================
# 第二步:删除 MySQL 数据库
# ============================================================
echo ""
echo "========================================="
echo "[2/8] 删除 MySQL 数据库..."
echo "========================================="
DB_LIST=("hive_metastore" "dolphinscheduler" "dataxweb" "crabc")
for db in "${DB_LIST[@]}"; do
echo " - 删除数据库 ${db}..."
sudo mysql -u root -e "DROP DATABASE IF EXISTS ${db};" 2>/dev/null && echo " ✓ 已删除" || echo " - 不存在"
done
# 删除 MySQL 用户(可选)
echo " - 删除专用用户..."
sudo mysql -u root -e "DROP USER IF EXISTS 'dolphin'@'%';" 2>/dev/null || true
sudo mysql -u root -e "DROP USER IF EXISTS 'crabc'@'localhost';" 2>/dev/null || true
sudo mysql -u root -e "DROP USER IF EXISTS 'devuser'@'%';" 2>/dev/null || true
sudo mysql -u root -e "DROP USER IF EXISTS 'flinkcdc'@'%';" 2>/dev/null || true
echo " ✓ 用户已清理"
# 停止 MySQL
echo " - 停止 MySQL..."
sudo service mysql stop 2>/dev/null || true
# ============================================================
# 第三步:删除 bigdata 目录(包括所有组件和安装包)
# ============================================================
echo ""
echo "========================================="
echo "[3/8] 删除 bigdata 目录(所有组件 + 安装包)..."
echo "========================================="
if [ -d "${BIGDATA_DIR}" ]; then
echo " 准备删除以下目录:"
echo " ${BIGDATA_DIR}"
echo " 包含的组件:"
ls ${BIGDATA_DIR} 2>/dev/null | head -20
echo ""
read -p " 确认删除整个 bigdata 目录?(y/N): " confirm_dir
if [ "$confirm_dir" = "y" ] || [ "$confirm_dir" = "Y" ]; then
rm -rf ${BIGDATA_DIR}
echo " ✓ bigdata 目录已完全删除"
else
echo " - 跳过目录删除"
fi
else
echo " - bigdata 目录不存在"
fi
# ============================================================
# 第四步:清理环境变量
# ============================================================
echo ""
echo "========================================="
echo "[4/8] 清理环境变量..."
echo "========================================="
if [ -f ~/.bashrc ]; then
# 备份
BACKUP_FILE=~/.bashrc.bak.$(date +%Y%m%d_%H%M%S)
cp ~/.bashrc ${BACKUP_FILE}
echo " - .bashrc 已备份到 ${BACKUP_FILE}"
# 删除所有大数据组件相关的环境变量
sed -i '/export JAVA_HOME=\/usr\/lib\/jvm\/java-11-openjdk-amd64/d' ~/.bashrc 2>/dev/null || true
sed -i '/export JAVA_HOME=\/usr\/lib\/jvm\/java-8-openjdk-amd64/d' ~/.bashrc 2>/dev/null || true
sed -i '/export JAVA_HOME=\/usr\/lib\/jvm\/java-17-openjdk-amd64/d' ~/.bashrc 2>/dev/null || true
sed -i '/export HADOOP_HOME=/d' ~/.bashrc 2>/dev/null || true
sed -i '/export HIVE_HOME=/d' ~/.bashrc 2>/dev/null || true
sed -i '/export SPARK_HOME=/d' ~/.bashrc 2>/dev/null || true
sed -i '/export FLINK_HOME=/d' ~/.bashrc 2>/dev/null || true
# 删除包含 bigdata 的 PATH 行
sed -i '/export PATH=.*bigdata/d' ~/.bashrc 2>/dev/null || true
sed -i '/export PATH=.*hadoop/d' ~/.bashrc 2>/dev/null || true
sed -i '/export PATH=.*hive/d' ~/.bashrc 2>/dev/null || true
sed -i '/export PATH=.*spark/d' ~/.bashrc 2>/dev/null || true
sed -i '/export PATH=.*flink/d' ~/.bashrc 2>/dev/null || true
echo " ✓ 环境变量已清理"
fi
# ============================================================
# 第五步:清理 SSH 密钥
# ============================================================
echo ""
echo "========================================="
echo "[5/8] 清理 SSH 密钥..."
echo "========================================="
if [ -f ~/.ssh/id_rsa ]; then
rm -f ~/.ssh/id_rsa ~/.ssh/id_rsa.pub
echo " ✓ SSH 密钥已删除"
else
echo " - SSH 密钥不存在"
fi
if [ -f ~/.ssh/authorized_keys ]; then
> ~/.ssh/authorized_keys
echo " ✓ authorized_keys 已清空"
fi
if [ -f ~/.ssh/known_hosts ]; then
> ~/.ssh/known_hosts
echo " ✓ known_hosts 已清空"
fi
# ============================================================
# 第六步:清理临时文件
# ============================================================
echo ""
echo "========================================="
echo "[6/8] 清理临时文件..."
echo "========================================="
# Hadoop 临时文件
rm -rf /tmp/hadoop-${USER_NAME} 2>/dev/null || true
rm -rf /tmp/hadoop-* 2>/dev/null || true
echo " ✓ Hadoop 临时文件"
# Flink 临时文件
rm -rf /tmp/flink-* 2>/dev/null || true
echo " ✓ Flink 临时文件"
# Spark 临时文件
rm -rf /tmp/spark-* 2>/dev/null || true
echo " ✓ Spark 临时文件"
# nohup 输出
rm -f ~/nohup.out 2>/dev/null || true
echo " ✓ nohup 输出"
# MySQL JDBC 驱动残留
find /tmp -name "mysql-connector-java-*.jar" -delete 2>/dev/null || true
echo " ✓ JDBC 驱动残留"
# ============================================================
# 第七步:清理 Maven 本地仓库(询问用户)
# ============================================================
echo ""
echo "========================================="
echo "[7/8] 清理 Maven 本地仓库..."
echo "========================================="
if [ -d ~/.m2/repository ]; then
read -p " 是否清理 Maven 本地仓库 (~/.m2/repository)?所有缓存的依赖将被删除。(y/N): " clean_maven
if [ "$clean_maven" = "y" ] || [ "$clean_maven" = "Y" ]; then
rm -rf ~/.m2/repository
echo " ✓ Maven 本地仓库已清理"
else
echo " - 跳过 Maven 清理"
fi
else
echo " - Maven 本地仓库不存在"
fi
# ============================================================
# 第八步:验证清理结果
# ============================================================
echo ""
echo "========================================="
echo "[8/8] 验证清理结果..."
echo "========================================="
# 检查进程
echo " 检查残留 Java 进程..."
JPS_COUNT=$(jps 2>/dev/null | grep -v Jps | wc -l)
if [ "$JPS_COUNT" -gt 0 ]; then
echo " ⚠ 警告:仍有 Java 进程残留:"
jps 2>/dev/null | grep -v Jps
echo " - 可手动执行 kill 命令清理"
else
echo " ✓ 无残留 Java 进程"
fi
# 检查 bigdata 目录
if [ -d "${BIGDATA_DIR}" ]; then
REMAIN=$(ls ${BIGDATA_DIR} 2>/dev/null)
if [ -z "$REMAIN" ]; then
echo " ✓ bigdata 目录已清空"
else
echo " - bigdata 目录仍有残留内容:"
echo "$REMAIN"
fi
else
echo " ✓ bigdata 目录已不存在"
fi
# ============================================================
# 完成
# ============================================================
echo ""
echo "========================================="
echo " 卸载完成!"
echo " 结束时间:$(date)"
echo "========================================="
echo ""
echo "后续步骤:"
echo " 1. 执行 source ~/.bashrc 刷新环境变量"
echo " 2. 如需彻底重置 WSL 环境,在 Windows PowerShell 中执行:"
echo " wsl --shutdown"
echo " 3. 重新打开 Ubuntu 终端即可"
echo ""
echo "如果卸载过程中有任何问题,可联系系统管理员。"
echo "========================================="使用方法
复制全部内容,在 WSL 终端中执行:
nano ~/uninstall_all.sh粘贴内容后,按 Ctrl+O 回车保存,Ctrl+X 退出。
赋予执行权限:
chmod +x ~/uninstall_all.sh执行脚本:
bash ~/uninstall_all.sh完成后:
source ~/.bashrc此脚本会删除的内容
| 类别 | 具体内容 |
|---|---|
| 所有组件目录 | Hadoop, Hive, Spark, Flink, Kafka, DataX, DataX-Web, DolphinScheduler, FlinkCDC, Crabc |
| 所有安装包 | *.tar.gz, *.tgz 压缩包 |
| 源码 目录 | crabc, datax-web 等 git clone 的源码 |
| MySQL 数据库 | hive_metastore, dolphinscheduler, dataxweb, crabc |
| MySQL 用户 | dolphin, crabc, devuser, flinkcdc |
| 环境变量 | JAVA_HOME, HADOOP_HOME, HIVE_HOME, SPARK_HOME, FLINK_HOME 及所有 PATH 引用 |
| SSH 密钥 | id_rsa, id_rsa.pub, authorized_keys, known_hosts |
| 临时文件 | /tmp/hadoop-*, /tmp/flink-*, /tmp/spark-*, 残留 JDBC 驱动 |
| Maven 仓库(可选) | ~/.m2/repository |