****论文题目:****Hybrid-Learning-Based Operational Visual Quality Inspection for Edge-Computing-Enabled IoT System(基于混合学习的边缘计算物联网系统操作视觉质量检测)
****期刊:****IEEE INTERNET OF THINGS JOURNAL(IOTJ)
****摘要:****深度学习增强的物联网(IoT)在推进智能制造转型中发挥着关键作用,质量检测是许多智能制造物联网系统的重要组成部分。然而,诸如昂贵的数据标记、无数类型的缺陷和迭代优化的高成本等挑战阻碍了以前的视觉表面质量检测方法的工业适用性。在本文中,我们提出了一种基于创新的混合学习方法的边缘计算支持的物联网系统,该系统仅使用少量标记数据和最小的迭代优化努力进行视觉表面质量检测。我们的混合学习方法首先使用深度神经网络来合成真实工业图像的全局表示,随后通过无监督聚类算法进行异常检测。此外,提出了微调和数据增强等增强策略,以提高对噪声数据集的鲁棒性,并支持制造操作中多边缘设备的低成本推理。在从现实世界工厂收集的保留数据集上,我们的方法实现了90%到98%的分类准确率,比基准方法高出7%到12%。此外,这种混合学习方法在检测新型表面缺陷方面表现出了有效性,测试召回率在86% ~ 97%之间,比基准方法高出11% ~ 34%。
用少量标注数据检测"未知缺陷"
一、背景:工业质检为什么这么难?
在智能制造场景中,视觉表面质量检测是工业IoT系统最核心的应用之一。质检系统需要根据分布在边缘的摄像头所采集的图像,判断产品是"合格品(OK)"还是"缺陷品(NG)"。
听起来是一个典型的图像分类任务,但实际工厂环境远比学术基准数据集复杂得多。论文作者在与真实工厂深度合作后,总结出将传统CNN方法落地到工业边缘IoT系统的三大核心痛点:
痛点一:高质量标注数据严重不足
工厂有严格的生产计划和保密政策,IoT合作方进入工厂采集、标注数据的窗口期极为有限。数据不仅数量少、多样性不足,还因安全原因无法对外公开。小数据集几乎是工业质检的常态。
痛点二:缺陷类型无穷无尽
生产线长期运行时,温度、湿度等环境因素不断变化,硬件也会老化。良品外观相对固定,但缺陷的形态可以层出不穷------训练阶段从未见过的新型缺陷,传统监督学习模型根本无力应对。
痛点三:动态环境下模型迭代成本极高
工业边缘计算系统出于安全考虑通常以离线隔离模式运行,无法远程更新模型。每次模型迭代都需要人员上门操作,维护成本极高,使持续优化几乎不可行。
这三个问题相互叠加,使得现有方法在工业落地时面临严重瓶颈。
二、系统架构:一个真实的工业IoT闭环
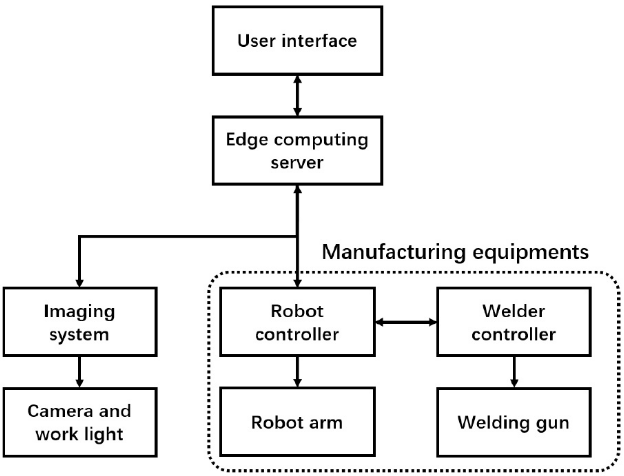
论文图1------IoT使能的机器人制造系统示意图
在进入算法细节之前,先了解这套系统的硬件全貌,有助于理解算法设计的取舍逻辑。
整个系统由四个主要部件构成:
| 组件 | 具体实现 |
|---|---|
| 用户界面 | 9英寸工业级触摸屏,支持系统配置、初始化、缺陷告警和统计报告 |
| 边缘计算服务器 | Intel i7-8700 CPU + 64GB RAM + 2TB HDD,运行Linux 16.04 / Python 3.5 / Flask,通过TCP协议与机器人及成像系统交互 |
| 成像系统 | MV-CA020-20GM面阵相机(曝光200ms),配Rsee P-HRL环形LED补光灯,可更换防焊花玻璃罩,通过USB2.0或以太网通信 |
| 制造设备 | 6轴HR50-2238机械臂(重复精度±0.06mm,臂展2239mm)+ AOTAI WSM-400焊机(80%氩+20%CO₂混合保护气) |
运行流程 如下:边缘服务器初始化系统 → 分发任务给制造设备 → 产品焊接完成后,机械臂引导成像系统对准焊缝拍照 → 图像传回边缘服务器,1秒内完成质检推理 → 若检出缺陷,立即暂停生产并向人工操作员发送告警。
本文的应用场景是天津某知名制造工厂的服务器机柜底座焊接产品,材料为2~5mm厚钢板,现场经过1~4周精细标定后投入批量生产。
三、算法核心:混合学习方法(HLM)
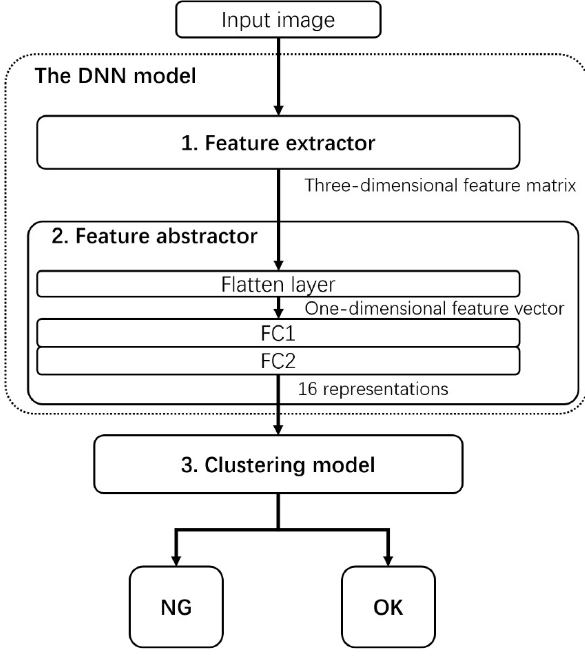
论文图2------混合学习方法结构示意图
论文的核心贡献是一套混合学习方法(Hybrid Learning Method, HLM),它将深度神经网络(DNN)的表示学习能力与无监督聚类的异常检测能力结合在一起。整体由三个模块串联而成。
3.1 模块一:CNN特征提取器
特征提取器以 VGG网络(Oxford VGG Group提出)为骨干,使用3×3和1×1的小卷积核逐层加深,从输入图像中提取三维特征矩阵。
选用VGG的理由有三点:
- 在ImageNet上有成熟的预训练权重,迁移学习效果好;
- 对工业图像的中等分辨率有良好适配性;
- 部署和使用相对简便。
3.2 模块二:MLP特征抽象器
特征抽象器由一个Flatten层和三个全连接层组成:
- FC1(256个神经元):将VGG提取的三维特征矩阵展平后进行高级特征抽象,激活函数为ReLU(f(z) = max(z, 0)),可有效缓解梯度消失问题。
- FC2 (16个神经元):进一步压缩为16维表示向量,该向量即为后续聚类模型的输入。选择16维是因为实验发现在本文小数据集条件下,更高维度(如32或64)会导致k-means难以收敛。
- FC3(2个神经元,仅训练期使用):输出层使用Softmax激活,完成OK/NG二分类,仅在DNN训练阶段使用,推理阶段被聚类模型替代。
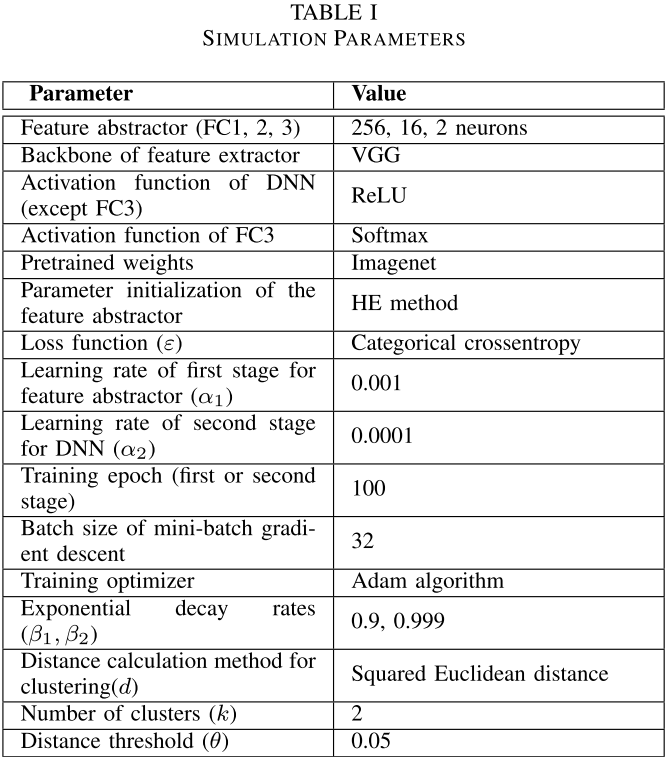
论文表一------仿真参数汇总表
主要训练超参数如下:VGG骨干网络 + HE方法初始化抽象器参数 + 交叉熵损失函数 + Adam优化器(+ mini-batch梯度下降(batch size=32)+ 训练轮次100 epochs。两阶段学习率分别为0.001和0.0001。
3.3 模块三:改进k-means聚类模型
这是HLM区别于普通CNN分类器最关键的设计。
训练完成后,移除FC3,将训练集所有图像经过FC2输出的16维向量送入k-means算法(k=2,分别对应OK和NG),完成聚类中心的确定。
推理时的关键机制:基于距离阈值的判决
对于新输入图像,计算其表示向量到OK聚类中心的欧氏距离 dnew:
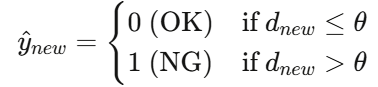
距离阈值0.05的确定方式:工厂质量管理组要求OK样本误判率不超过5%,因此取所有训练集OK样本到OK中心距离分布的95百分位数作为阈值。
这一设计的精妙之处在于:新型缺陷的表示向量往往远离OK中心,同时也远离已知NG中心,传统softmax分类器会将其强制分配为某一类(高概率误判为OK),而HLM则会因为距离超过阈值而正确判为NG------这正是泛化能力的来源。
四、训练策略:小数据集下的三板斧
面对只有1300张图像的工业小数据集,作者采用了三项增强策略:
策略一:预训练 + 两阶段微调
- 加载在ImageNet(超过1400万张图像)上预训练的VGG权重;
- 冻结特征提取器,先单独训练抽象器(学习率0.001),直到损失收敛;
- 解冻全部参数,以更小的学习率(0.0001)联合微调特征提取器和抽象器。
实验对比显示,使用预训练权重的HLM相比从零训练(HE初始化,记为HLMHE)在准确率、精确率和召回率上均有显著提升,充分验证了迁移学习在小数据场景下的价值。
策略二:数据增强
对训练集图像施加以下变换以扩充数量和多样性(尤其针对样本稀少的NG类别):
- 剪切(Shearing)
- 缩放(Zooming)
- 宽度/高度变换(Width/Height resizing)
- 水平/垂直翻转(Horizontal/Vertical flipping)
策略三:图像预处理规范化
对裁剪后的焊缝图像(原始分辨率1280×1024,裁剪为150×300)进行最小-最大归一化。
将像素值从0, 255映射到0, 1,消除光照强度绝对值对模型的干扰。
五、实验设计:三种场景全面评估


论文图4------产品及焊缝样本图(含OK、NG-pits、NG-pores)
论文图5------裁剪后的焊缝图像样本
数据集构成
全部数据来自天津工厂实际采集,共1300张150×300焊缝图像,人工质检专家同时对照图像和实物进行标注:
- OK样本:900张(均匀连续的焊缝外观)
- NG样本 :400张,其中:
- pits(坑状缺陷):300张
- pores(气孔缺陷):100张
三种评估场景
| 场景 | 训练集 | 测试集 | 测试目标 |
|---|---|---|---|
| Scenario 0 | 700 OK + 200 NG(随机混合) | 200 OK + 200 NG(随机混合) | 已知缺陷识别能力 |
| Scenario 1 | 700 OK + 300 NG(pits) | 200 OK + 100 NG(pores) | 泛化至未知缺陷pores |
| Scenario 2 | 700 OK + 100 NG(pores) | 200 OK + 300 NG(pits) | 泛化至未知缺陷pits |
Scenario 1和2专门用于评估模型对训练阶段从未见过的缺陷类型的检出能力。
评估指标
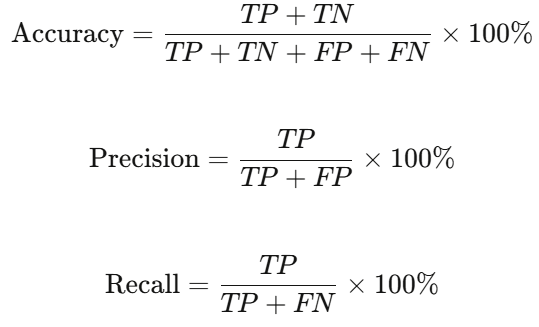
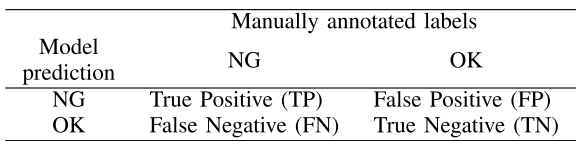
论文表二------混淆矩阵说明
其中,召回率(Recall)是工厂最关注的指标------漏检一个NG产品流向客户(FN)的危害远大于误判一个OK产品(FP)。
六、实验结果:HLM的全面胜出
6.1 已知缺陷场景(Scenario 0)
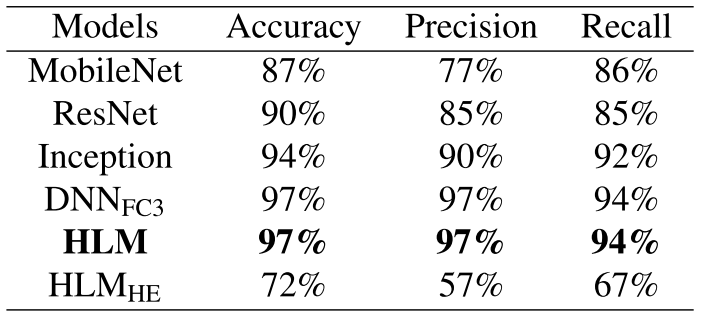
论文表三------各方法在Scenario 0下的验证性能对比
在已知缺陷场景下,HLM与基于纯监督学习的DNNFC3表现相近,二者均以**精确率97%、召回率94%**的成绩全面超越MobileNet、ResNet、InceptionNet等主流架构基准方法。
值得注意的是,从零训练的HLMHE(仅用HE初始化,不使用预训练权重)在所有指标上均明显弱于HLM,直接验证了预训练+微调策略在小数据集下的必要性。
6.2 未知缺陷泛化场景(Scenario 1 & 2)
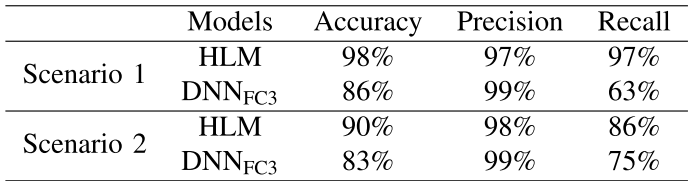
论文表四------HLM与DNNFC3在Scenario 1和2下的泛化能力对比
这是本文最核心的实验结果,也是HLM相对于纯监督模型最显著的优势所在:
| 场景 | 模型 | 准确率 | 精确率 | 召回率 |
|---|---|---|---|---|
| Scenario 1 | HLM | ~90% | ~96% | 97% |
| Scenario 1 | DNNFC3 | 较低 | 较高 | 63% |
| Scenario 2 | HLM | ~较高 | ~95%+ | 86% |
| Scenario 2 | DNNFC3 | 较低 | 较高 | ~75% |
- Scenario 1中,HLM召回率(97%)比DNNFC3(63%)高出34个百分点;
- Scenario 2中,HLM召回率(86%)比DNNFC3高出约11个百分点。
Scenario 2中两个模型的召回率均低于Scenario 1,原因在于:pits缺陷的外观比pores更多样化(见图5),训练时只见过pores(外观较单一)的模型在检测多样化的pits时会更吃力;此外,训练集中pits数量(300张)更多,也使Scenario 1的训练更充分。
结论非常清晰:纯监督模型(DNNFC3)遇到新型缺陷时,误判为OK的概率高达25%~37%;而HLM借助距离阈值机制,能将新型缺陷识别为"偏离OK分布"的异常,即使不知道缺陷的具体类型,也能正确检出。
6.3 失败案例分析
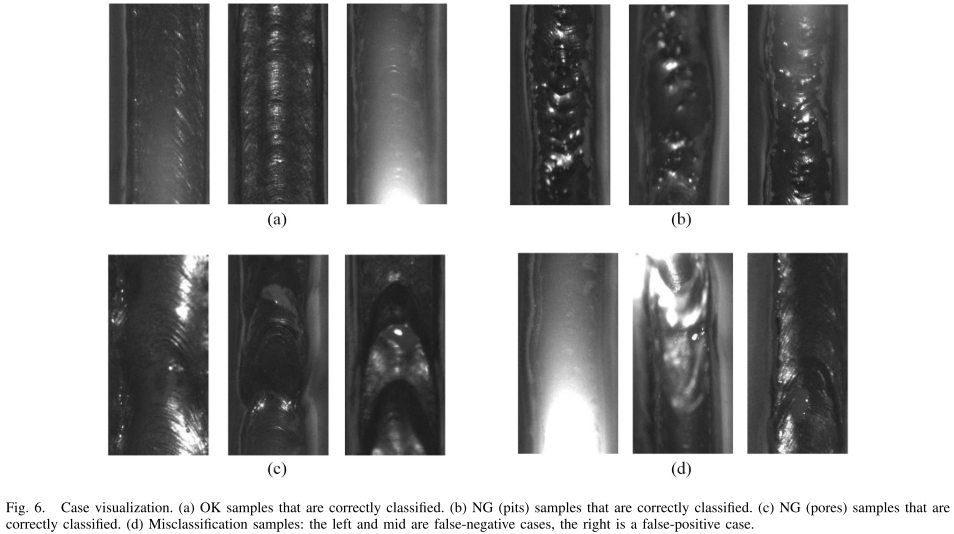
论文图6------正确分类样本与误分类样本的可视化对比
论文对误分类案例进行了深入分析,归纳出三类典型失败模式:
- 假阴性(FN)------过曝光:焊缝图像因曝光过度产生大面积光晕,掩盖了缺陷纹理。人工专家通过对照实物和多角度观察才能判定为NG,但单张图像信息丢失严重,模型无能为力。
- 假阴性(FN)------图像模糊:机械臂运动或对焦问题导致图像模糊,pits缺陷特征被淹没,模型误判为OK。
- 假阳性(FP)------焊渣干扰:焊缝表面的黑色弧形焊渣在2D图像中高度类似pits缺陷的纹理特征。专家通过判断坑深(3D信息)排除了该样本,但2D相机无法获取深度信息,导致模型误判。
这一分析指出了未来改进方向:升级为3D相机或多角度多相机系统,可以显著降低此类误判,但相应的硬件成本、标定和维护成本也会大幅增加。
6.4 对抗样本鲁棒性测试

论文图7------对抗样本示例及HLM的判别结果
为进一步验证HLM对分布外样本的鲁棒性,作者手工制作了多种对抗样本(未知颜色的线条/形状叠加、红色点状噪声、不规则裁剪等),模拟可能在运行中出现的各种新型异常。
实验结果:几乎所有对抗样本均被正确识别为NG,唯一的例外是宽度缩放样本------因为宽度缩放本身就是训练阶段数据增强的手段之一,模型已经"见过"类似的OK样本,因此将其误判为OK。这一例外反而从反面证明了HLM的工作原理是合理的。
七、实际部署效果
该系统在天津工厂连续运行20个工作日,整体质检性能:
- 分类准确率:90%~98% ,比基准方法提升7%~12%
- 召回率:86%~97% ,比基准方法提升11%~34%
- 减少装配线人工质检工作量:50%~70%
工厂此前依赖人工质检,面临三大困境:一是经验丰富的检验员难以招募,劳动力短缺有时直接导致停产;二是焊接烟尘对人体健康有害;三是疲劳和注意力不集中会导致人工检测准确率大幅波动。HLM的自动化质检系统有效解决了上述问题。
八、总结与展望
论文贡献总结
| 维度 | 解决的问题 | 实现手段 |
|---|---|---|
| 小数据 | 标注数据严重不足 | ImageNet预训练 + 两阶段微调 + 数据增强 |
| 新型缺陷 | 训练集外的未知缺陷无法识别 | 改进k-means聚类 + 距离阈值异常检测 |
| 低维护成本 | 模型迭代成本高、不适合离线环境 | 聚类阈值可灵活调整,无需重训DNN即可适应新场景 |
| 工业落地 | 算法到实际系统的鸿沟 | 完整边缘IoT系统集成,在真实工厂验证 |
局限性与未来方向
论文也坦诚指出了当前方法的局限:
- 成像质量瓶颈:过曝光和图像模糊是当前最主要的误检来源,引入3D相机或多角度方案可改善,但成本大幅上升。
- 更强的CNN骨干:当前使用VGG,可尝试更先进的骨干网络以提升特征质量。
- 像素级缺陷定位:引入MaskRCNN等分割模型,实现对缺陷区域的精确像素级定位。
- 可解释性:引入CNN可视化技术(如Grad-CAM)提升模型决策的可解释性,增强工程师对系统的信任。
九、一句话概括
本文提出的混合学习方法(HLM)通过"DNN学会什么是好产品,聚类判断新样本有多像好产品"的设计思路,用极少的标注数据、极低的维护成本,在真实工厂中实现了对已知和未知缺陷的高召回率检测,为工业IoT质检系统的实用化落地提供了切实可行的方案。