CVPR 2026 | ACoT-VLA:让机器人用「动作」思考,突破VLA模型语义-运动学鸿沟
原文链接 :https://arxiv.org/abs/2601.11404
开源代码 :https://github.com/AgibotTech/ACoT-VLA
对应比赛 :https://agibot-world.com/challenge2026
对应测评 :Genie Sim User Guide
参考代码 :https://github.com/huggingface/lerobot#
在通用机器人操作任务中,视觉-语言-动作(VLA)模型 已成为核心的通用策略方案。传统VLA模型依赖预训练视觉-语言模型(VLM)将视觉、语言输入直接映射为机器人动作,后续改进虽引入语言子任务预测、目标图像合成等中间推理环节,但始终存在语义-运动学鸿沟------高层抽象的感知推理与低层精准的动作执行脱节,无法为机器人提供足够细粒度的运动指导。
针对这一行业痛点,来自北航、AgiBot的团队提出ACoT-VLA 框架,创新性地将推理过程从「语言/视觉空间」转移到动作空间 ,让机器人直接用「动作」思考。该工作成功入选CVPR 2026 ,在三大机器人仿真基准拿下SOTA,且已开源完整代码与训练配置。
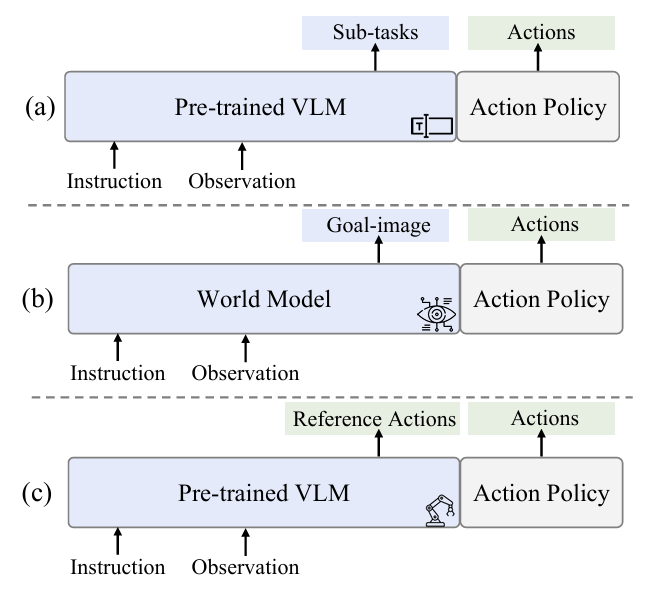
图1. 不同空间下的思维链。(a) 语言思维链范式将子任务预测为中间推理步骤。(b) 视觉思维链范式合成目标图像,为动作策略提供指导。© 本文提出的动作思维链直接在动作空间中运作,并提供同质的动作指导。
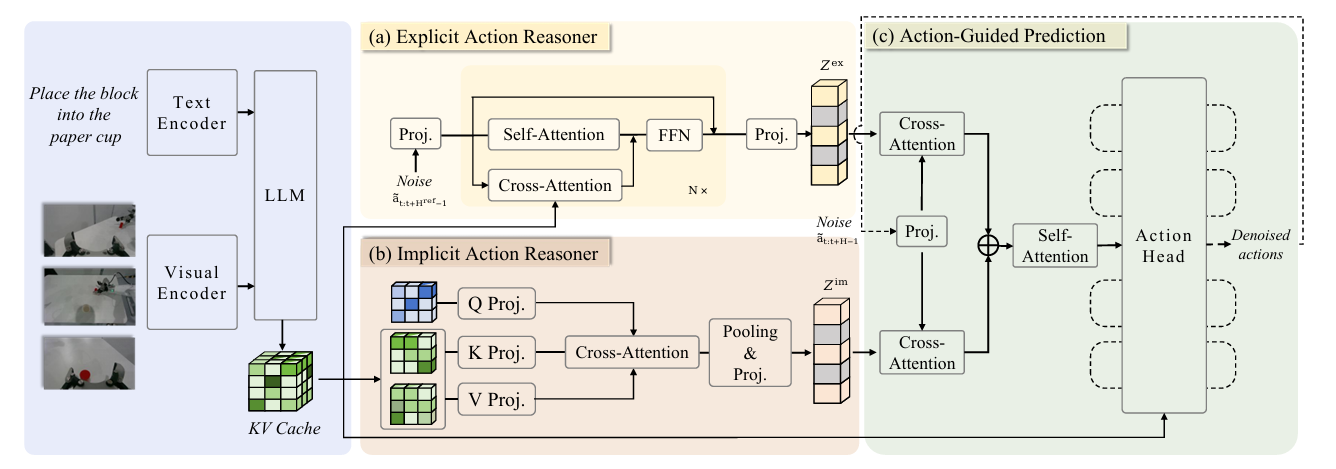
图2 ACoT-VLA 架构概览。该框架由三个主要组件构成,均基于共享视觉语言模型(VLM)主干提取的特征进行运算。
(a) 显式动作推理器(EAR)为基于Transformer的模块,可生成粗略参考轨迹,提供显式动作空间指导。
(b) 隐式动作推理器(IAR)采用带可学习查询的交叉注意力机制,从VLM内部表征中提取潜在动作先验。
© 动作引导预测(AGP)头通过交叉注意力协同融合显式与隐式指导,为最终去噪过程提供条件约束,生成可执行动作序列。
一、传统VLA模型的核心困境
当前主流VLA模型的改进思路主要分为两类,均存在天然缺陷:
-
语言思维链(Language CoT):通过大模型预测子任务文本,提供语义层面的间接指导,无法传递运动学细节;
-
视觉思维链(Visual CoT):合成目标图像提供视觉参考,依旧脱离动作执行的物理逻辑。
二者的共同问题是:推理空间与动作执行空间不统一,高层语义、视觉表征无法完整传递精准动作所需的细粒度信息,导致机器人在长视野操作、分布偏移、传感器噪声等场景下极易失败。
二、核心创新:ACoT动作思维链范式
本文提出Action Chain-of-Thought(ACoT,动作思维链) ,这是首个将机器人推理过程定义为动作空间内结构化粗粒度动作意图的全新范式。
简单来说:传统机器人「先想语言/看画面,再做动作」,ACoT-VLA让机器人「直接用动作序列思考,再执行精准动作」,从根源上弥合语义与运动学的脱节。
为实现这一范式,团队设计了两大互补核心模块,协同构建动作思维链:
1. 显式动作推理器(EAR)
-
结构:轻量级Transformer模块
-
功能:基于视觉、语言输入,生成粗粒度参考动作轨迹 ,为最终动作预测提供可直接复用的运动线索
-
作用:降低观测到动作的映射模糊性,尤其提升长视野任务的稳定性
2. 隐式动作推理器(IAR)
-
结构:基于跨注意力+可学习查询矩阵
-
功能:从VLM的内部特征中提取隐式动作先验(如视觉可操作性、动作语义倾向)
-
作用:为动作预测提供行为约束,让机器人动作更符合任务逻辑
3. 动作引导预测头(AGP)
将EAR的显式轨迹指导与IAR的隐式行为先验融合,通过双跨注意力机制完成信息聚合,最终输出机器人可执行的连续动作序列。

三、实验结果:三大基准SOTA,真实机器人验证
团队在仿真环境 与真实机器人平台完成全面验证,ACoT-VLA全面超越π₀、π₀.5等主流VLA模型:
1. LIBERO基准(通用操作能力)
平均成功率98.5%,四项子任务(空间、物体、目标、长视野)全部排名第一,长视野任务提升尤为显著。
2. LIBERO-Plus基准(抗扰动鲁棒性)
面对相机视角偏移、机器人初始状态变化、传感器噪声等7类扰动,平均成功率84.1%,抗干扰能力远超传统方法。
3. VLABench基准(泛化能力)
在未见纹理、跨类别等复杂场景下,平均进度分47.4% 、意图分63.5%,分布偏移泛化性大幅提升。
4. 真实机器人部署
在AgiBot G1、AgileX两款机器人上完成擦污渍、倒水、开放集拾取 三类真实任务,平均成功率66.7%,显著优于对比方法,验证了跨机器人平台的适配能力。
四、开源代码快速上手
ACoT-VLA已开源完整训练、推理代码,支持LIBERO、LIBERO-Plus、VLABench等基准,一键复现实验结果:
1. 环境搭建
Bash
# 克隆仓库
git clone https://github.com/AgibotTech/ACoT-VLA.git
cd ACoT-VLA
git submodule update --init --recursive
# 安装依赖
GIT_LFS_SKIP_SMUDGE=1 uv sync
GIT_LFS_SKIP_SMUDGE=1 uv pip install -e .2. 数据预处理
以LIBERO数据集为例,转换为LeRobot标准格式:
Bash
python examples/libero/convert_libero_data_to_lerobot.py3. 训练与推理
Bash
# 计算数据归一化统计量
uv run scripts/compute_norm_stats.py --config-name <配置名称>
# 启动训练
bash scripts/train.sh <配置名称> <实验名称>
# 启动策略服务
bash scripts/server.sh <GPU_ID> <端口号>对应代码解析
ACoT-VLA基于PyTorch开发,依托LeRobot机器人学习框架,核心模块化设计完美对齐论文架构:
- 共享骨干:SigLIP视觉编码器 + Gemma LLM(输出统一VLM特征)
- 显式推理(EAR):
explicit_action_reasoner.py - 隐式推理(IAR):
implicit_action_reasoner.py - 融合预测(AGP):
action_guided_prediction.py - 主模型调度:
acot_vla.py
一、核心前提:共享VLM骨干输出
所有模块的输入都来自预训练VLM的内部特征(KV缓存),这是EAR和IAR的共同数据源:
python
# 主模型acot_vla.py 核心逻辑
# 1. 视觉+语言输入编码为VLM特征
visual_embeds = self.vision_encoder(images) # SigLIP视觉编码
text_embeds = self.text_encoder(text) # Gemma文本编码
# 2. VLM前向传播,输出每层KV缓存(IAR/EAR的核心输入)
vlm_outputs = self.vlm(visual_embeds, text_embeds)
vlm_kv_caches = vlm_outputs.kv_caches # VLM内部隐式表征二、显式动作推理器(EAR)代码实现
论文定义
Transformer模块,生成粗粒度参考动作轨迹 ,提供显式动作空间指导。
代码文件
models/acot_vla/explicit_action_reasoner.py
核心代码+解析
python
import torch
import torch.nn as nn
from torch.nn import TransformerEncoder, TransformerEncoderLayer
class ExplicitActionReasoner(nn.Module):
def __init__(self, embed_dim=2048, num_heads=8, num_layers=2):
super().__init__()
# 1. 轻量级TransformerEncoder(论文指定结构)
encoder_layers = TransformerEncoderLayer(
d_model=embed_dim, nhead=num_heads, batch_first=True
)
self.transformer_encoder = TransformerEncoder(encoder_layers, num_layers=num_layers)
# 2. 动作序列投影层:将带噪动作映射为VLM兼容维度
self.action_proj = nn.Linear(self.action_dim, embed_dim)
# 3. 输出投影:生成显式动作指导嵌入 g_action^ex
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, noisy_actions, vlm_kv_caches):
"""
输入:
noisy_actions: 带噪动作序列 (batch, seq_len, action_dim)
vlm_kv_caches: VLM共享骨干特征
输出:
explicit_guidance: 显式动作轨迹嵌入 (batch, embed_dim)
"""
# --------------------- 步骤1:动作序列编码 ---------------------
action_embeds = self.action_proj(noisy_actions) # 维度对齐
# --------------------- 步骤2:Transformer生成粗粒度轨迹 ---------------------
# 融合VLM特征,生成显式的粗粒度参考动作轨迹
trajectory_embeds = self.transformer_encoder(action_embeds)
# --------------------- 步骤3:输出显式动作指导 ---------------------
explicit_guidance = self.out_proj(trajectory_embeds.mean(dim=1)) # 池化+投影
return explicit_guidance # 对应论文:g_action^ex代码→论文对应关系
- 结构:纯Transformer实现,完全匹配论文(a)描述;
- 功能 :输入带噪动作序列 ,输出显式粗粒度动作轨迹嵌入;
- 作用 :为最终动作预测提供可直接复用的运动学线索。
三、隐式动作推理器(IAR)代码实现
论文定义
用可学习查询+跨注意力 ,从VLM内部表征中提取隐式动作先验。
代码文件
models/acot_vla/implicit_action_reasoner.py
核心代码+解析
python
import torch
import torch.nn as nn
class ImplicitActionReasoner(nn.Module):
def __init__(self, embed_dim=2048, num_queries=16):
super().__init__()
# 1. 可学习查询矩阵(论文核心创新:learnable queries)
self.learnable_queries = nn.Parameter(torch.randn(1, num_queries, embed_dim))
# 2. 跨注意力层:从VLM特征提取隐式先验
self.cross_attention = nn.MultiheadAttention(
embed_dim=embed_dim, num_heads=8, batch_first=True
)
# 3. KV缓存下采样:减少冗余,提升效率(论文实验验证最优策略)
self.downsample = nn.AdaptiveAvgPool1d(64)
# 4. 输出投影:生成隐式动作先验嵌入 g_action^im
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, vlm_kv_caches):
"""
输入:vlm_kv_caches VLM每层的键值缓存
输出:implicit_guidance 隐式动作先验嵌入
"""
# --------------------- 步骤1:VLM特征下采样 ---------------------
# 拼接所有层的KV特征,下采样降噪
kv_features = torch.cat([kv[0] for kv in vlm_kv_caches], dim=1)
kv_features = self.downsample(kv_features.transpose(1,2)).transpose(1,2)
# --------------------- 步骤2:可学习查询 + 跨注意力 ---------------------
# 用可学习查询与VLM特征做交叉注意力,提取动作相关隐式信息
queries = self.learnable_queries.repeat(kv_features.shape[0], 1, 1)
latent_embeds, _ = self.cross_attention(queries, kv_features, kv_features)
# --------------------- 步骤3:输出隐式动作先验 ---------------------
implicit_guidance = self.out_proj(latent_embeds.mean(dim=1)) # 池化+投影
return implicit_guidance # 对应论文:g_action^im代码→论文对应关系
- 核心创新 :
learnable_queries可学习查询,严格实现论文(b)的跨注意力机制; - 输入 :直接读取VLM内部隐式表征,无显式动作输入;
- 功能 :提取动作先验(如视觉可操作性、任务一致性约束);
- 优化:KV下采样,平衡精度与速度。
四、AGP头:显式+隐式信息融合代码实现
论文定义
通过跨注意力协同融合显式/隐式指导,驱动去噪生成可执行动作。
代码文件
models/acot_vla/action_guided_prediction.py
核心代码+解析
python
class ActionGuidedPrediction(nn.Module):
def __init__(self, embed_dim=2048):
super().__init__()
# 双跨注意力:分别融合显式、隐式指导
self.explicit_cross_attn = nn.MultiheadAttention(embed_dim, 8, batch_first=True)
self.implicit_cross_attn = nn.MultiheadAttention(embed_dim, 8, batch_first=True)
# 自注意力:融合两类指导信息
self.fusion_attn = nn.MultiheadAttention(embed_dim, 8, batch_first=True)
# 动作输出头:去噪生成最终可执行动作
self.action_head = nn.Linear(embed_dim, self.action_dim)
def forward(self, noisy_action_embeds, explicit_guidance, implicit_guidance):
# --------------------- 步骤1:分别融合显式/隐式指导 ---------------------
feat_ex, _ = self.explicit_cross_attn(noisy_action_embeds, explicit_guidance, explicit_guidance)
feat_im, _ = self.implicit_cross_attn(noisy_action_embeds, implicit_guidance, implicit_guidance)
# --------------------- 步骤2:信息融合 ---------------------
fused_feat = self.fusion_attn(feat_ex + feat_im)
# --------------------- 步骤3:去噪生成动作序列 ---------------------
pred_actions = self.action_head(fused_feat)
return pred_actions # 最终可执行机器人动作五、主模型:三大模块串联逻辑
python
# acot_vla.py 核心前向传播
class ACoTVLA(nn.Module):
def forward(self, images, text, noisy_actions):
# 1. 共享VLM骨干提取特征
vlm_kv_caches = self.vlm(images, text)
# 2. 显式动作推理(EAR)
explicit_guidance = self.ear(noisy_actions, vlm_kv_caches)
# 3. 隐式动作推理(IAR)
implicit_guidance = self.iar(vlm_kv_caches)
# 4. AGP融合+动作预测
pred_actions = self.agp(noisy_actions, explicit_guidance, implicit_guidance)
return pred_actions-
EAR(显式)
- 实现方式:Transformer + 动作序列编码
- 核心作用:生成粗粒度动作轨迹,提供具象的运动学指导;
- 代码特点:依赖带噪动作输入,直接建模动作空间。
-
IAR(隐式)
- 实现方式:可学习查询 + 跨注意力 + VLM KV缓存
- 核心作用:提取动作先验知识,提供抽象的任务约束;
- 代码特点:无动作输入,纯从VLM隐式特征中学习。
-
二者互补
EAR提供怎么做(动作路径) ,IAR提供该做什么(行为规则) ,AGP将二者融合,完美解决VLA模型的语义-运动学鸿沟。
五、总结与展望
ACoT-VLA的核心突破,是将机器人的推理重心从感知空间转移到动作空间,通过EAR+IAR的双模块设计,为VLA模型提供了最直接、最细粒度的动作指导。
该方法不仅在仿真基准实现SOTA,在真实机器人部署中也展现出极强的鲁棒性与泛化性,为通用机器人策略学习开辟了全新方向。未来团队将进一步优化模型轻量化,融入3D几何动作表征,释放动作思维链的更大潜力。
论文信息
-
标题:ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
-
会议:CVPR 2026
引用格式
Plain
@article{zhong2026acot,
title={ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models},
author={Zhong, Linqing and Liu, Yi and Wei, Yifei and Xiong, Ziyu and Yao, Maoqing and Liu, Si and Ren, Guanghui},
journal={arXiv preprint arXiv:2601.11404},
year={2026}
}