HTTP协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种**应用层协议,**是一个至关重要的协议,它规定了客户端(比如你的浏览器)和服务器之间如何通信、如何传输数据的一套规则
HTTP 的核心特点
- 简单易用:报文格式清晰,基于文本,容易理解和实现;
- 无连接(HTTP/1.1 已优化为长连接) :早期 HTTP/1.0 每次请求都要新建 TCP 连接,HTTP/1.1 引入
Keep-Alive实现长连接,减少连接开销; - 无状态:服务器不保存客户端的状态,如需保持状态(比如登录),需要借助 Cookie、Session 等机制;
- 可扩展:支持自定义请求头 / 响应头,也衍生出 HTTPS(加密)、HTTP/2(多路复用)、HTTP/3(基于 UDP)等升级版本。
认识域名与URL
URL
- URL 全称:Uniform Resource Locator
- 中文:统一资源定位符
- 作用:互联网上任何资源的 "唯一地址",用来定位服务器上的文件、接口、图片、页面等。
URL 标准结构
一个完整 URL 由 9 部分组成:
bash
协议://用户名:密码@主机名:端口/路径?查询参数#片段协议 scheme
告诉浏览器 / 客户端用什么规则通信。常见:
http://明文传输https://加密传输(现在主流)ftp://文件传输file://本地文件
主机 host
可以是:
- 域名:
www.xxxx.com - IP:
192.168.1.1
作用:找到哪台服务器。
域名解析服务器DNS
DNS = Domain Name System
中文:域名系统
作用一句话:
把人类好记的域名,翻译成机器能懂的 IP 地址。
- 域名:
www.xxxx.com - IP:192.168.0.0
你访问域名 → DNS 查 IP → 浏览器去连 IP
DNS 就是互联网的 "电话本"。
DNS 核心工作流程
当你输入 www.example.com 时:
-
浏览器先查自己缓存最近访问过,直接用,不查。
-
查操作系统缓存(Windows 的 hosts、Linux 的 /etc/hosts)
-
**发给 本地 DNS 服务器(递归服务器)**比如电信、移动、谷歌 8.8.8.8、阿里 223.5.5.5
-
本地 DNS 去问 根 DNS 服务器 根服务器说:我不知道,但我知道
.com服务器在哪。 -
问 顶级域名服务器(.com) 它说:我不知道,但我知道
example.com的权威 DNS 在哪。 -
问 权威 DNS 服务器 它说:
www.example.com对应 IP 是xxx.xxx.xxx.xxx -
本地 DNS 把结果返回给浏览器
-
浏览器去请求这个 IP
整个过程叫:递归查询 + 迭代查询
结论:域名就是IP
端口 port
范围:0~65535作用:找到服务器上的哪个服务
默认端口可以省略:
- http → 80
- https → 443
- ftp → 21
路径 path
服务器上资源的位置,像文件夹路径。
查询参数 query
以 ? 开头,key=value 形式,多个用 & 分隔。
片段 fragment
以 # 开头,只在浏览器端使用,不会发给服务器。作用:跳转到页面内某个锚点 / 位置。
结论:
http本质是为了获取服务器上的文件内容
IP+Port+目标文件地址 -> 全网内唯一的文件
在全网中定位某个文件---URL
urlencode和urldecode(了解)
像/?:等这样的字符,已经被ur当做特殊意义理解了.因此这些字符不能随意出现比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义转义的规则如下:
- 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
协议轮廓
HTTP请求与应答格式
http底层,浏览器底层,用的都是TCPsocket,用的都是ip+port的进程间通信机制。

http请求格式
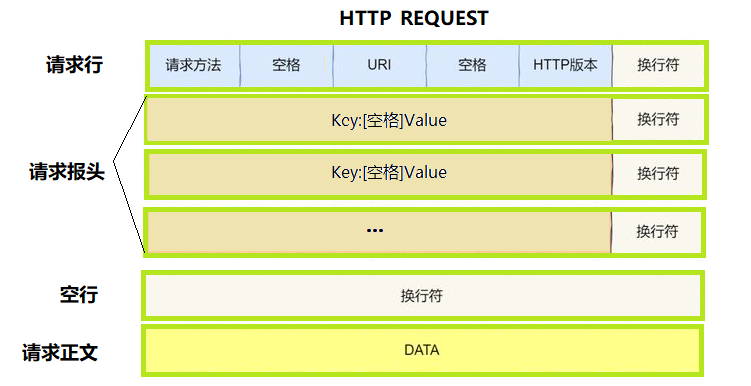
- 从第二行开始到空行之前为请求报头
- 换行符:\r\n
- 最常见的请求方法:GET POST
- URI:资源路径
- 空行前的内容:统一叫做报头
- 空行后的内容:有效载荷
- 在请求报头中含有有效载荷的长度:Content-Length:20\r\n;
http中将有效载荷和报头分离:利用"\r\n"(空行)来区分报头与有效载荷。
http的请求就是一个大的"字符串"(字节流),"\r\n"也属于字符串的一部分,在计算机看来这就是一整条字符串,没有多行这一说。
http版本:日常最常用的版本为http1.1,主流学习的版本为http1.0,通常代表客户端的http的版本。
请求格式中'http版本'的作用:
- 我们在玩游戏时,如果一款游戏我们很长时间不玩了,我们设备上的客户端一直停留在下载时的版本,但是服务端是需要一直更新的,当我们再次上线游戏时,客户端向服务端请求服务,在报头带上版本号后,服务端接收到信息,发现我们的客户端的版本是老版本,就会在应答报文中让我们进行版本更新。
- 当一个服务端更新新版本后,如果该软件有1亿个客户端用户,不会让所有用户立刻更新,而是先让一小部分用户更新新版本,在当前这些用户使用一段时间后,新版本不会出现问题,才会让所有用户更新新版本,使用梯度式的更新,在同一时间段内,市场中同时会有新版本和老版本存在,那么就会有不同版本的客户端向服务端请求服务,服务端就需要根据版本的新旧推送不同种类的信息或服务。
请求格式中的'URI'
cpp
http://www.xxx.com/a/b/c.html- 请求行中的不同内容使用空格分隔。
- 常规情况下uri叫做统一资源标识符,url:统一资源定位符。
- "/a/b/c.html"就是客户端请求的资源在服务器中的路径。
- "www.xxx.com"在网络中找到唯一的主机。
- 找到目标文件后,服务端返回文件内容。
- http请求,请求资源的位置由uri决定。
请求报头:
请求报头都是K:V结构。
http应答格式

- 应答报文在宏观结构上与请求报文一模一样。
状态行
http版本:服务端的版本
状态码:http规定,不管成功还是失败,都必须有应答, 如果应答出现错误由状态码表示,应答失败返回对应的错误码,有代表性的错误码就是常见的404,应答成功的状态码:2XX(二百多)。
状态码描述:根据状态码,解释成人能看懂的字符串,404==OK Not Found.
相应正文
客户端请求的资源在响应正文中返回。
HTTP原理
- http超文本请求的本质:其实就是通过网络服务器把linux机器上,特定目录下的文件以http应答的方式返回给client(浏览器或者app)
HTTP请求方法
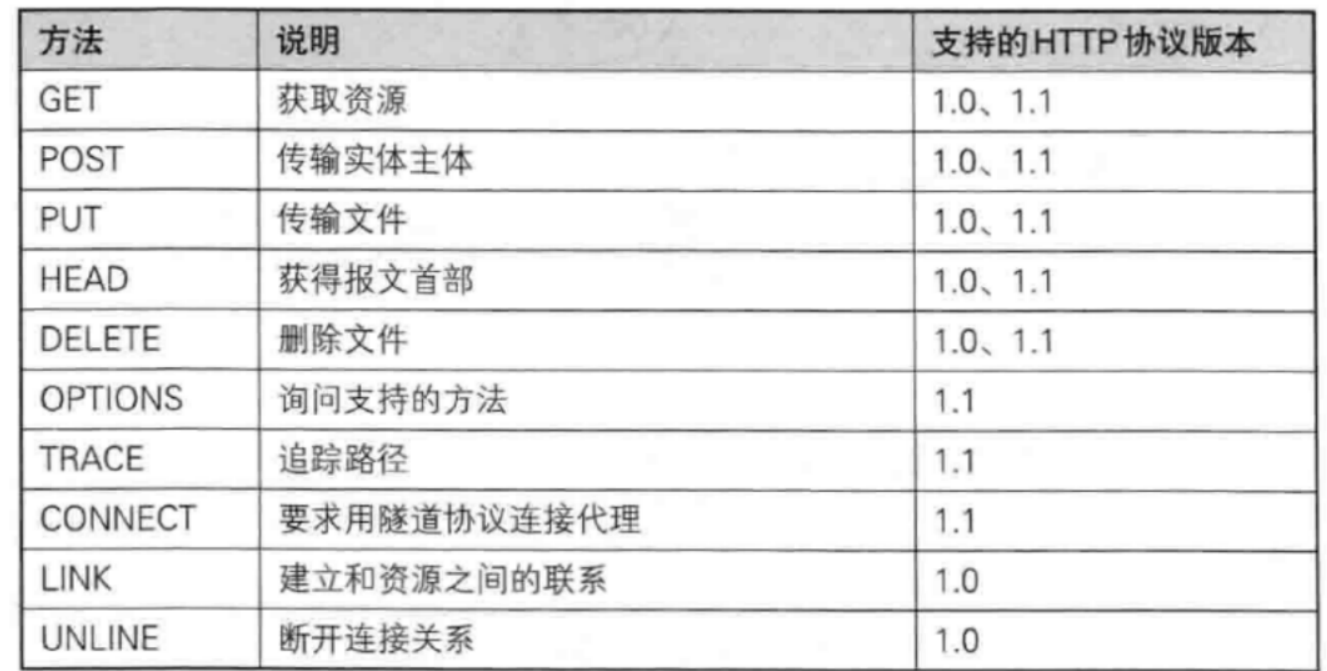
http这么多方法中基本上只使用,get和post方法
GET方法
- 全称:Retrieve (获取)
- 核心作用 :从服务端获取数据 ,是只读请求,不会修改服务端的数据。
- 通俗理解 :像查字典、看网页、搜资料,只拿数据,不修改内容。
- 如果一个网页中有图片,视频等,客户端需要额外发送新的请求(一个网页中有10张图片,浏览器需要发送11次请求)
- 如果是http1.0的话,每次请求都要先建立连接,1.1版本的http支持常链接。
get方法浏览器把参数传给服务器
比如注册页面的账号密码等数据在uri中传递,格式为:uri = /服务?name=*****&passwd=*****.
POST方法
- 全称:Submit (提交)
- 核心作用 :向服务端提交数据 ,会新增 / 修改服务端的数据。
- 通俗理解 :像注册账号、发帖子、上传文件、支付,主动把数据发给服务器处理。
| 对比维度 | GET | POST |
|---|---|---|
| 核心用途 | 获取数据(查询) | 提交数据(新增 / 修改) |
| 数据传输位置 | 拼接在 URL 地址栏 中 | 放在 请求体(Request Body) 中 |
| 数据大小限制 | 有严格限制(浏览器 / 服务器限制,一般≤2KB) | 无大小限制(可传大文件、大数据) |
| 安全性 | 低(数据明文可见) | 相对高(数据不可见,需抓包查看) |
| 是否可缓存 | 可被浏览器缓存 | 默认不缓存 |
| 是否可收藏 / 刷新 | 可收藏、刷新无副作用 | 不可收藏,刷新可能重复提交数据 |
| 编码类型 | 仅支持 ASCII 字符 |
支持多种编码(ASCII、二进制、中文等) |
| 幂等性 | 幂等(多次请求结果一致) | 非幂等(多次请求可能重复提交) |
理解浏览器给服务端提交参数的过程

- 前端网页中必须要有表单
- 用户填写表单,浏览器自动提取表单里面的内容---构建带参数的http request
- GET方法在uri中传递表单内容
- post方法在正文中传递表单内容
如何看待一个http请求中的uri
- linux web根目录下存在的一个文件路径,静态资源访问,视频,音频,html。。。
- 当作一个字符串,用来请求httpserver中所对应的服务,"字符串",也往往以路径形式体现,只不过这个路径不能在web根目录下存在:"/login""/register""/Search".
post和get方法的区别:
- post方法更具有私密性,get方法会出现回显。
- 不管是get方法还是post方法,它们传递参数时都不安全。
- post和get方法都是明文传送的,我们的账号密码等信息会被抓包工具劫持,会导致泄露。
PUT方法
**用途:**用于传输文件,将请求报文主体中的文件保存到请求URL指定的位置
示例:PUT /example.html HTTP/1.1
这种方法,在常规网站中都是禁掉的,防止用户向服务器中恶意传输文件。
应用场景:在QQ或微信等软件中,更换头像,需要用户来上传图片文件。
HEAD方法
用途:与get方法类似,但回应该请求报文的应答报文只有报头和报文,没有正文部分。
作用:用来确认URL的有效性,让客户端判断服务端是否在线,或者用来获取资源更新的日期时间等

- 命令行的一个指令
- 向URLs发起一个请求,把URLS部分构建http请求,采用get或post方法,以客户端的形式向服务器发起访问。
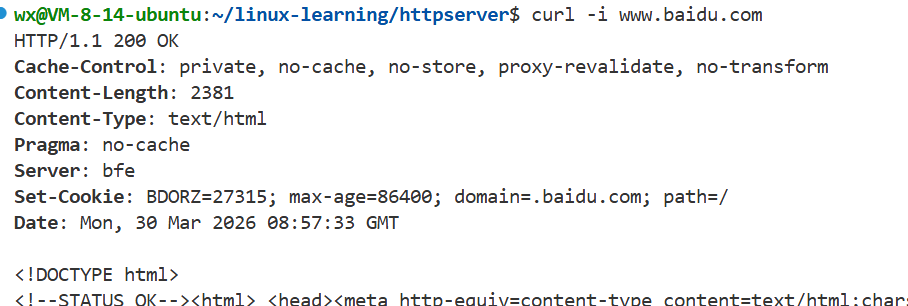
使用head方法发起请求:
DELETE方法
用途:用于删除文件,是put的相反方法
示例:DELETE /example.html HTTP/1.1
按照请求报文中的URI删除指定资源,这个方法一般也是禁掉的,防止客户端误删服务端的资源。
OPTIIONS方法
用途:针对指定的url,请求url指定的资源的支持的方法,询问服务器支持什么方法。
示例:OPTIONS * HTTP/1.1
返回服务器支持的方法,如:get,post等,该方法默认也是关闭的。
应答报文
bash
HTTP/1.1 200 OK
Allow: GET, HEAD, POST, OPTIONS
Content-Type: text/plain
Content-Length: 0
Server: nginx/1.18.0 (Ubuntu)
Date: Sun, 16 Jun 2024 09:04:44 GMT
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, OPTIONS
Access-Control-Allow-Headers: Content-Type, AuthorizationHttp常见的header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的⻓度
- Host: 客⼾端告知服务器, 所请求的资源是在哪个主机的哪个端⼝上;
- User-Agent: 声明⽤⼾的操作系统和浏览器版本信息;
- Referer: 当前⻚⾯是从哪个⻚⾯跳转过来的;
- Location: 搭配3xx状态码使⽤, 告诉客⼾端接下来要去哪⾥访问;
- Cookie: ⽤于在客⼾端存储少量信息. 通常⽤于实现会话(session)的功能;
Http的状态码
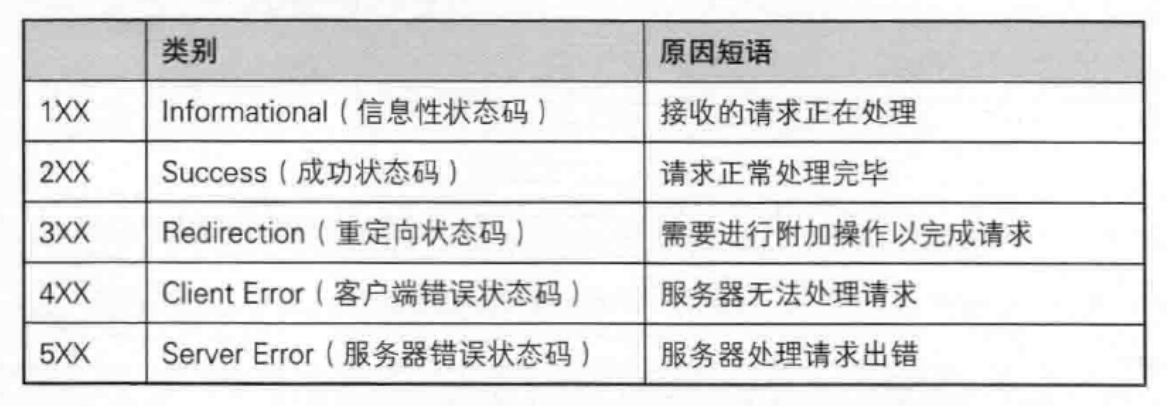
|-----|-----------------------|--------------------------------|
| 状态码 | 含义 | 应⽤样例 |
| 100 | Continue | 上传⼤⽂件时,服务器告诉客⼾端可以继续上传 |
| 200 | OK | 访问⽹站⾸⻚,服务器返回⽹⻚内容 |
| 201 | Created | 发布新⽂章,服务器返回⽂章创建成功的信息 |
| 204 | No Content | 删除⽂章后,服务器返回"⽆内容"表⽰操作成功 |
| 301 | Moved Permanently | ⽹站换域名后,⾃动跳转到新域名;搜索引擎更新⽹站 链接时使⽤ |
| 302 | Found 或 See Other | 用户登录成功后,重定向到用户首页 |
| 304 | Not Modified | 浏览器缓存机制,对未修改的资源返回304状态码 |
| 400 | Bad Request | 填写表单时,格式不正确导致提交失败 |
| 401 | Unauthorized | 访问需要登录的⻚⾯时,未登录或认证失败 |
| 403 | Forbidden | 尝试访问你没有权限查看的⻚⾯ |
| 404 | Not Found | 访问不存在的⽹⻚链接 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致⻚⾯⽆法加载 |
| 502 | Bad Gateway | 使⽤代理服务器时,代理服务器⽆法从上游服务器获取 有效响应 |
| 503 | Service Unavailable | 服务器维护或过载,暂时⽆法处理请求 |
|-----|--------------------|-------|---------------------|
| 307 | Temporary Redirect | 临时重定向 | 临时重定向资源到新的位 置(较少使⽤) |
| 308 | Permanent Redirect | 永久重定向 | 永久重定向资源到新的位 置(较少使⽤) |
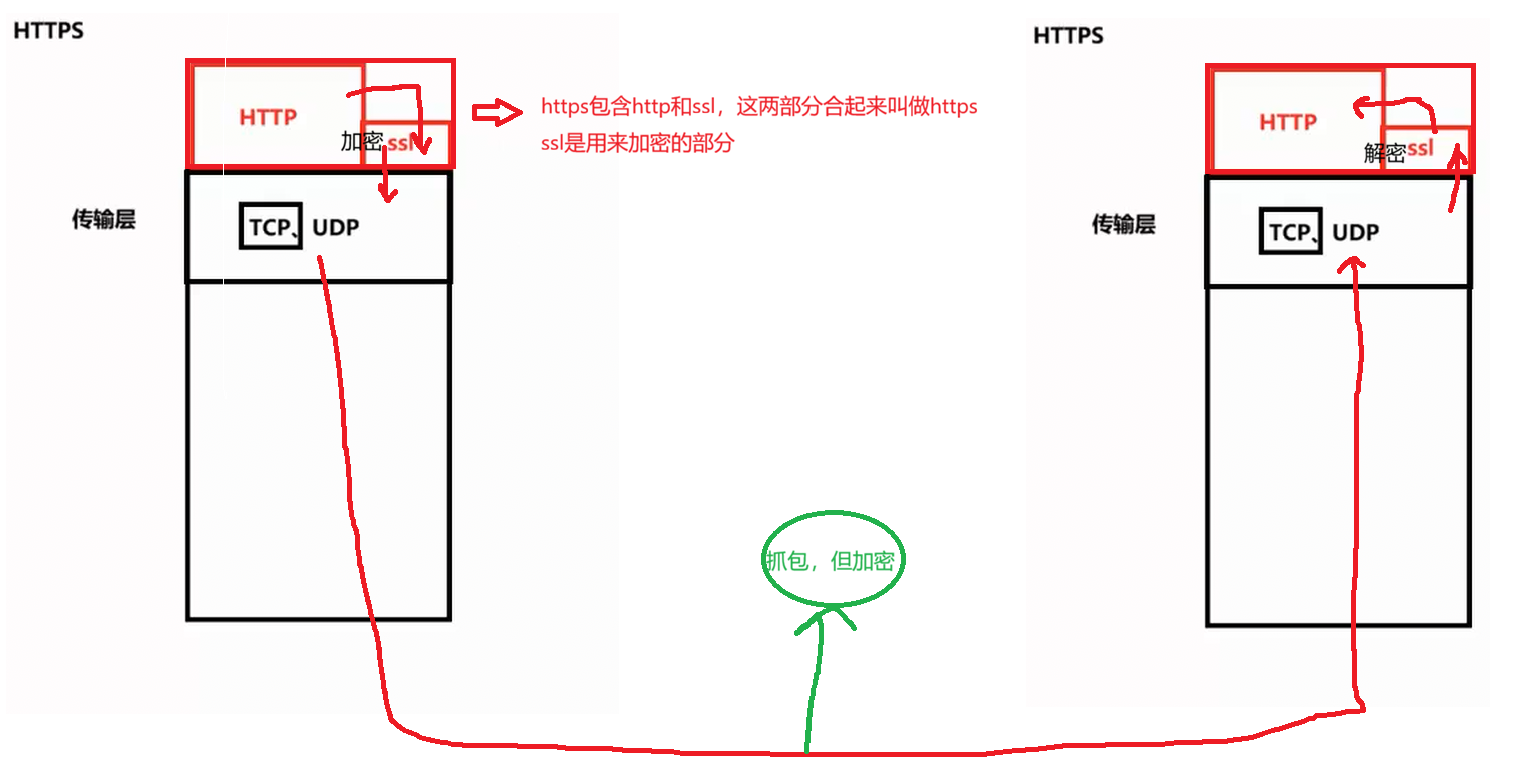
Https(更安全的网络协议)
HTTP的会话管理功能
Cookie
一个网站一次登录,我们可以很长时间,都会在线---减少用户频繁登录的问题。
http本身的特点:http不管是常链接还是短链接,http都是无状态,无连接的。
无状态:每次点击浏览器的刷新页面,都会向服务器发送一个请求,http不记得我们请求过哪些网页,网页中的一些图片视频等文件,浏览器会帮我们缓存,所以,第二次访问某些网站,会比第一次快很多。
无连接:http使用TCP,从网络分层角度来看,链接是TCP的,http并不知道有链接。
问题:在我们登录一些网站时,今天登录后,退出网站,当我们再次进入该网站,我们仍旧保持登录的状态。
- 如果一个站点记不住用户,那么这个站点就很没用。
方案:
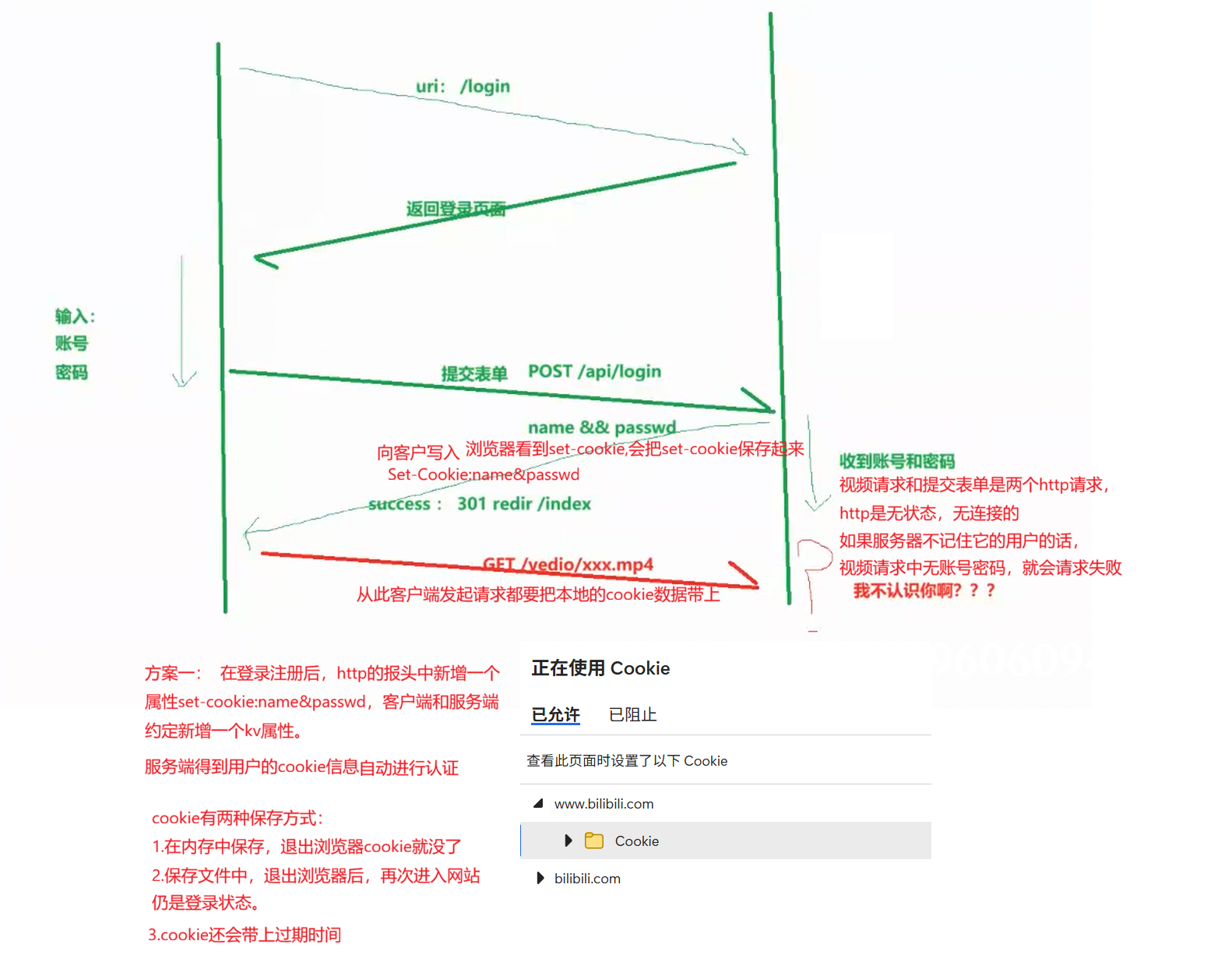
认识cookie
- http存在一个报头选项:Set-cookie,可以用来给浏览器设置cookie值。
基本格式
bash
Set-Cookie: <name>=<value>
其中 <name> 是 Cookie 的名称,<value> 是 Cookie 的值。完整的set-cookie
bash
Set-Cookie: username=peter; expires=Thu, 18 Dec 2024 12:00:00 UTC; path=/;
domain=.example.com; secure; HttpOnly问题:
纯cookie做法,把用户的私密信息保存在客户客户端本地,如果用户下载了一些流氓软件,cookie中的账号密码就容易被盗取。
解决方案
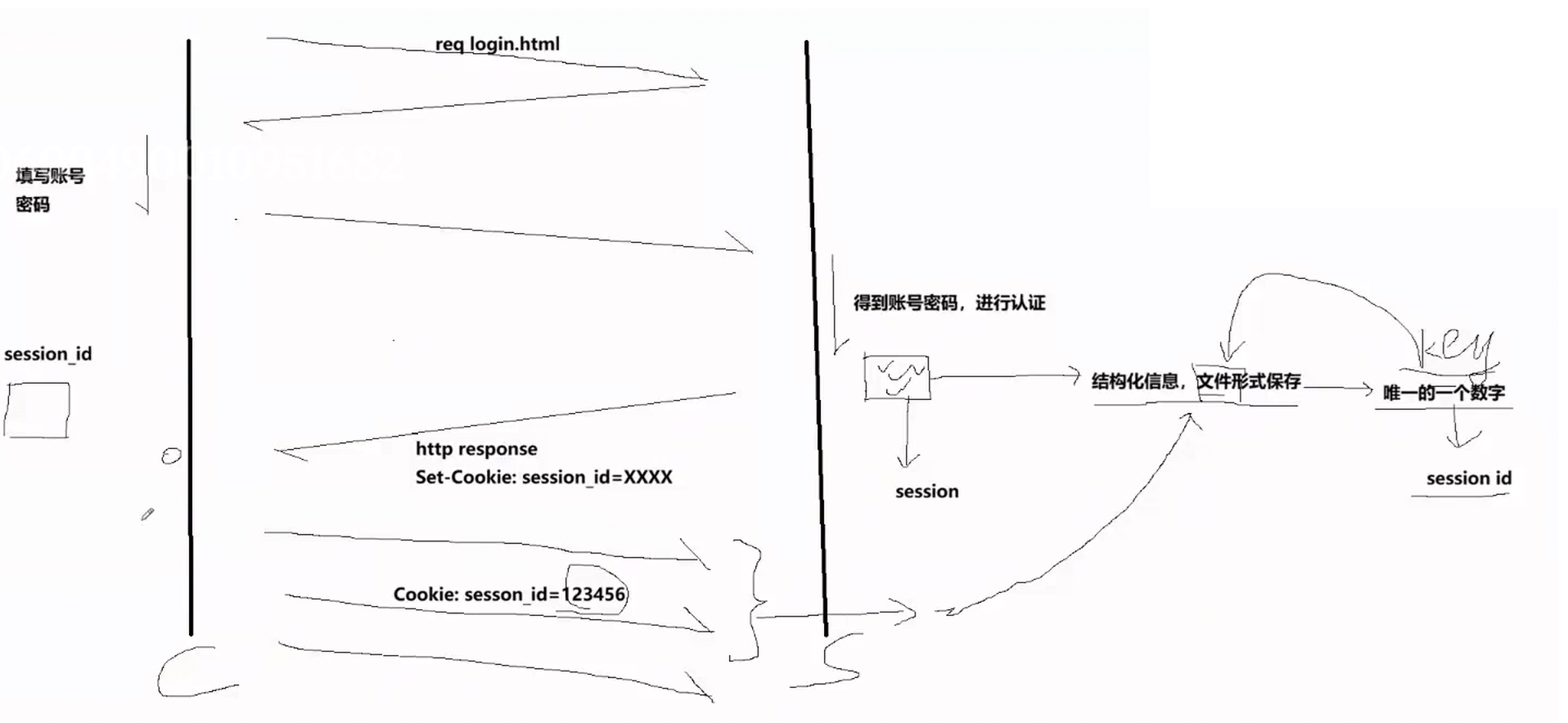
服务端得到账号密码后,服务端把账号密码保存在服务器中,以结构化信息保存在文件中,同时给这个文件命名全服务器内唯一一个数字。
用户的会话信息,全保存在服务器端。
用户的会话信息整体叫做session,服务端把session保存在文件中,文件名就叫做session ID。
服务端保存sesion信息后,服务端的应答报文会把session_id返回给客户端。
客户端以后的每次请求都会带上session_id,服务端收到session_id后,在自己的特定路径下通过session_id找到特定的文件,获取到用户的session信息。
当代使用的是session+cookie=会话管理。
HTTP的Connection报头
HTTP中的 Connection 字段是HTTP报⽂头的⼀部分,它主要⽤于控制和管理客⼾端与服务器之间
的连接状态
核⼼作⽤:
管理持久连接:
Connection 字段还⽤于管理持久连接(也称为⻓连接)。持久连接允许客⼾端和服务器在请求/响应完成后不⽴即关闭TCP连接,以便在同⼀个连接上发送多个请求和接收多个响应。
持久连接(⻓连接)
- HTTP/1.1:在HTTP/1.1协议中,默认使⽤持久连接。当客⼾端和服务器都不明确指定关闭连接时,连接将保持打开状态,以便后续的请求和响应可以复⽤同⼀个连接
- HTTP/1.0:在HTTP/1.0协议中,默认连接是⾮持久的。如果希望在HTTP/1.0上实现持久连接,需要在请求头中显式设置 Connection: keep-alive 。
语法格式
Connection: keep-alive :表⽰希望保持连接以复⽤TCP连接。
Connection: close :表⽰请求/响应完成后,应该关闭TCP连接。
http服务端学习代码
Http.hpp
cpp
#pragma once
#include <iostream>
#include <cstdio>
#include <string>
#include <sstream>
#include <unordered_map>
#include <fstream>
#include <functional>
#include "Logger.hpp"
// #define DEBUG 1
const std::string linesep = "\r\n";
const std::string spacesep = " ";
const std::string headersep = ": ";
const std::string suffixsep = ".";
const std::string argsep = "?";
const std::string g_http_version = "HTTP/1.0";
const std::string g_first_page = "index.html";
const std::string g_wwwroot = "wwwroot";
const std::string page_404 = "./wwwroot/404.html";
using namespace NS_LOG_MODULE;
class Util
{
public:
// 1. 空:没有完整行
// 2. \r\n: 读取到了空行
// 3. 其他情况: 分析到了一行具体内容
static std::string ReadLine(std::string &str)
{
auto pos = str.find(linesep);
if (pos == std::string::npos)
return std::string();
std::string line = str.substr(0, pos);
str.erase(0, line.size() + linesep.size());
if (line.empty())
return linesep;
return line;
}
// 如果我们要读取二进制文件,vector<char>
//返回存储文件内容的字符串
static std::string ReadFile(const std::string &filename)
{
// 采用二进制方式读取数据
std::ifstream in(filename, std::ios::binary);
if (!in.is_open())
{
return std::string();
}
in.seekg(0, in.end);//将文件指针移动到文件末尾
//最好将类型变为auto,如果文件过大,int类型可能会溢出
auto filesize = in.tellg();//该函数返回文件指针的位置,此时文件指针处于文件末尾,返回值就是文件的大小
in.seekg(0, in.beg);//将文件指针重新移动到文件开头
std::string content;
content.resize(filesize);//将字符串变为文件的大小。
in.read((char *)content.c_str(), filesize);//读取整个文件的大小,存储到字符串中。
in.close();//关闭文件
return content;
// bug
// std::ifstream in(filename);
// if (!in.is_open())
// {
// return std::string();
// }
// std::string content;
// std::string line;
// while (std::getline(in, line))
// content += line;
// in.close();
// return content;
}
};
// 1. 你怎么知道你读取到的是完整的报文 --
//解析请求报文
class HttpRequest
{
private:
//获取请求行
bool ParseReqLine(std::string &httpstr)
{
std::string req_line = Util::ReadLine(httpstr);//获取请求行
if (req_line.empty() || req_line == linesep)//空行请求不合法
return false;
std::stringstream ss(req_line);
ss >> _method >> _uri >> _version;//提取请求行中的内容
if (_uri == "/")//如果请求路径为空,默认访问首页
_uri += g_first_page; // uri: /-> uri: /index.html
//补全路径
_uri = g_wwwroot + _uri; // wwwroot/index.html: web 根目录 // wwwroot/Login
// wwwroot/index.html
// wwwroot/index.css
// wwwroot/index.js
// wwwroot/image/xxx.jpg,png...
// wwwroot/video/xxx.mpx
//在文件路径中逆查找,找'.'获取文件后缀
auto pos = _uri.rfind(suffixsep);
if (pos == std::string::npos)//没有后缀默认找主页
_suffix = ".html";
else
_suffix = _uri.substr(pos);//获取文件后缀
return true;
}
//解析请求报头
bool ParseHeaderkv(std::string &httpstr)
{
std::string header_line;
do
{//先获取请求报头的第一行,放入kv哈希表中,之后继续循环一行行获取
header_line = Util::ReadLine(httpstr);
if (header_line.empty())//请求报头为空,直接返回
return false;
if (header_line != linesep)//不是空行
{
auto pos = header_line.find(headersep);//找':'分割kv
if (pos == std::string::npos)
{
return false;
}
std::string key = header_line.substr(0, pos);
std::string value = header_line.substr(pos + headersep.size());
// _header[key] = value;
_header.insert(std::make_pair(key, value));//插入哈希表
// _header.insert({key, value});
}
} while (header_line != linesep);//读到空行停止
return true;
}
//解析请求报头的正文
bool ParseText(std::string &httpstr)
{
// 1. 有没有正文??结合方法
if (strcasecmp(_method.c_str(), "GET") == 0)
{
auto pos = _uri.find(argsep);
if(pos == std::string::npos)
{
_text = std::string();
return true;
}
else
{
std::cout << "_URI: "<< _uri << std::endl;
std::string temp = _uri;
_uri = temp.substr(0, pos);//'?'前是用户名,后是密码
std::cout << "_URI: "<< _uri << std::endl;
_text = temp.substr(pos+argsep.size());
std::cout << "_text: "<< _text << std::endl;
}
}
else//如果不是get方法,直接获取正文
{
if (_header.find("Content-Length") == _header.end())//没有找到正文的长度
{
_text = "";
}
// 2. 正文多大?从哪开始?
// POST方法
//截取正文
int content_len = std::stoi(_header["Content-Length"]);
_text = httpstr.substr(0, content_len);
httpstr.erase(0, content_len);//删除已经读取的正文
}
return true;
}
public:
// 反序列化
bool Deserialize(std::string &httpstr)
{
std::cout << httpstr;
// 1. 解析请求行
bool n = ParseReqLine(httpstr);
(void)n;
// LOG(LogLevel::DEBUG) << "_method# " << _method;
// LOG(LogLevel::DEBUG) << "_uri# " << _uri;
// LOG(LogLevel::DEBUG) << "_version# " << _version;
// std::cout << httpstr;
// 2. 解析报头
n = ParseHeaderkv(httpstr);
(void)n;
_blank_line = linesep;
// for(auto &header : _header)
// {
// std::cout << header.first << " ## " << header.second << "\r\n\r\n";
// }
// std::cout << "start|" << httpstr << "|end";
// 3. 解析正文部分
n = ParseText(httpstr);
(void)n;
return true;
}
std::string Uri() { return _uri; }
//// 读取文件内容(网页、图片等
std::string RequestContent()
{
return Util::ReadFile(_uri);
}
std::string Suffix() { return _suffix; }
void DebugPrint()
{
std::cout << "_version: " << _version << std::endl;
std::cout << "_uri: " << _uri << std::endl;
std::cout << "_method: " << _method << std::endl;
for (auto &header : _header)
{
std::cout << "==>" << header.first << " # " << header.second << std::endl;
}
std::cout << _blank_line;
std::cout << _text << std::endl;
}
std::string Text()
{
return _text;
}
// 反序列化
private:
// 结构化字段
std::string _method;//请求方法
std::string _uri; //请求资源的路径
std::string _version;//http的版本
std::unordered_map<std::string, std::string> _header;//请求报头
std::string _blank_line;//空行
std::string _text;//请求正文
// 私有数据
std::string _suffix; // 后缀类型
};
//应答报头
class HttpResponse
{
private:
//状态码转描述
std::string CodeToDesc(int code)
{
switch (code)
{
// 1xx
case 100:
return "Continue";
case 101:
return "Switching Protocols";
// 2xx
case 200:
return "OK";
case 201:
return "Created";
case 202:
return "Accepted";
case 204:
return "No Content";
case 206:
return "Partial Content";
// 3xx
case 301:
return "Moved Permanently";
case 302:
return "Found";
case 304:
return "Not Modified";
case 307:
return "Temporary Redirect";
case 308:
return "Permanent Redirect";
// 4xx
case 400:
return "Bad Request";
case 401:
return "Unauthorized";
case 403:
return "Forbidden";
case 404:
return "Not Found";
case 405:
return "Method Not Allowed";
case 408:
return "Request Timeout";
case 409:
return "Conflict";
case 413:
return "Payload Too Large";
case 429:
return "Too Many Requests";
// 5xx
case 500:
return "Internal Server Error";
case 501:
return "Not Implemented";
case 502:
return "Bad Gateway";
case 503:
return "Service Unavailable";
case 504:
return "Gateway Timeout";
case 505:
return "HTTP Version Not Supported";
// 默认情况
default:
return "Unknown Status Code";
}
}
public:
HttpResponse() : _version(g_http_version), _code(0), _blank_line(linesep)
{
}
//设置状态码
void SetCode(int code)
{
_code = code;
_code_desc = CodeToDesc(_code);
}
//设置响应正文
void SetBody(const std::string &content)
{
_text = content;
}
//获取响应正文的大小
int BodySize()
{
return _text.size();
}
//添加响应报头
void AddHeader(const std::string &key, const std::string &value)
{
// 如果存在就覆盖,如果不存在就添加
_header[key] = value;
}
//序列化
std::string Serialize()
{
// 构建状态行
std::string respstr = _version;
respstr += spacesep;
respstr += std::to_string(_code);
respstr += spacesep;
respstr += _code_desc;
respstr += linesep;
// 构建报头
for (auto &header : _header)
{
std::string line = header.first + headersep + header.second + linesep;
respstr += line;
}
// 添加换行符
respstr += _blank_line;
// 添加正文
respstr += _text;
return respstr;
}
private:
std::string _version;
int _code;
std::string _code_desc;
std::unordered_map<std::string, std::string> _header;
std::string _blank_line;
std::string _text;
};
using service_t = std::function<void(HttpRequest &req, HttpResponse &resp)>;
class MiniType
{
public:
static std::string Suffix2MimeType(const std::string &suffix)
{
auto iter = _mime_map.find(suffix);
if (iter != _mime_map.end())
return iter->second;
else
return "text/html";
}
private:
static std::unordered_map<std::string, std::string> _mime_map;
};
// 初始化10种常见的文件后缀到Content-Type的映射
std::unordered_map<std::string, std::string> MiniType::_mime_map = {
// 文本类型
{".txt", "text/plain"},
{".html", "text/html"},
{".htm", "text/html"},
{".css", "text/css"},
// 图片类型
{".jpg", "image/jpeg"},
{".jpeg", "image/jpeg"},
{".png", "image/png"},
{".gif", "image/gif"},
// 应用类型
{".pdf", "application/pdf"},
{".json", "application/json"},
{".xml", "application/xml"},
// 脚本类型
{".js", "application/javascript"},
// 其他常用类型
{".zip", "application/zip"},
{".mp3", "audio/mpeg"},
{".mp4", "video/mp4"}};
class HttpProtocol
{
public:
HttpProtocol()
{
}
// 注册 URI 对应的处理函数
void RegisterService(const std::string &uri, service_t service)
{
// 拼接成完整路径:wwwroot + /Login → wwwroot/Login
std::string key = g_wwwroot + uri;
// 存入哈希表:路径 → 处理函数
_http_services[key] = service; // key -> wwwroot/Login
}
// 判断请求的 URI 是否是注册的功能服务
bool IsReqService(const std::string &uri)
{
auto iter = _http_services.find(uri);
if (iter == _http_services.end())
return false;
else
return true;
}
std::string HandlerHttpRequest(std::string &req)
{
#ifdef DEBUG
std::cout << "#############################" << std::endl;
std::cout << req << std::endl;
std::string status_line = "HTTP/1.1 200 OK\r\n";
// status_line += "Connection: close\r\n";
status_line += "\r\n";
std::string html = "<html><body><h1>hello world!</h1></body></html>";
return status_line + html;
#else
//解析请求
HttpRequest http_req;
http_req.Deserialize(req);
HttpResponse http_resp;
if (IsReqService(http_req.Uri()))
{
// 功能路由
_http_services[http_req.Uri()](http_req, http_resp);
}
else
{
// 1. 保证报文完整性 --- IGN
// 2. 反序列化
// std::cout << "handler pid: " << getpid() << std::endl;
// std::cout << "Suffix: " << http_req.Suffix() << std::endl;
// 3. 根据不同的请求方法和请求URI,给用户返回不同的报文
// 根据结构化http_req 转换 成为 结构化的http_resp
std::string content = http_req.RequestContent();
//文件为空
if (content.empty())
{
// http_resp.SetCode(404);
// http_resp.SetBody(Util::ReadFile(page_404));
// http_resp.AddHeader("Content-Length", std::to_string(http_resp.BodySize()));
http_resp.SetCode(302);
http_resp.AddHeader("Location", "/404.html");
}
else//文件存在
{
http_resp.SetCode(200);
//添加响应报头
http_resp.AddHeader("Content-Length", std::to_string(content.size()));
http_resp.AddHeader("Content-Type", MiniType::Suffix2MimeType(http_req.Suffix()));
http_resp.AddHeader("Connection", "close");
http_resp.AddHeader("Set-Cookie", "username=peter;");
http_resp.SetBody(content);
}
}
return http_resp.Serialize();
#endif
}
~HttpProtocol()
{
}
private:
std::unordered_map<std::string, service_t> _http_services; // 根据uri(服务路径)进行功能路由
};HttpServer.cc
cpp
#include "TcpServer.hpp"
#include "Http.hpp"
#include <memory>
static void Usage(const std::string &proc)
{
std::cout << "Usage:\n\t" << proc << " port" << std::endl;
}
// 使用HTTP 实现restful风格的服务接口
// GET /Login HTTP/1.1
// GET /exec HTTP/1.1
//
// ls -a -l
// 可不可以是另一个http的client?
void Login(HttpRequest&req, HttpResponse &resp)
{
std::cout << "\nLogin functon been called!" << std::endl;
req.DebugPrint();
std::string data = req.Text();
std::cout << "data is: " << data << std::endl; // name=aaaaa&passwd=bbbbb
// 根据分隔符 name aaaaa passwd bbb
// 访问数据库, 查找数据库
resp.SetCode(200);
resp.AddHeader("Content-Type", MiniType::Suffix2MimeType(".txt"));
resp.SetBody("Login success!");
resp.AddHeader("Content-Length", std::to_string(resp.BodySize()));
}
void Connect(HttpRequest&req, HttpResponse &resp)
{
// 我们的http是浏览器或者其他客户端的服务端
// 但是我们的服务端,可不可以是其他server的客户端!
}
// POST "/api/log" HTTP/1.1
//
// 代码信息
// 你的代码
// void sort()
// 服务器提供
// int main(){
// sort(arr1), printf(arr1)
// sort(arr2), printf(arr2)
// sort(arr3), printf(arr3)
// sort(arr4), printf(arr4)
// }
// 结果
// 12345
// 6789
void OJ(HttpRequest&req, HttpResponse &resp)
{
// pipe();
// if(fork() == 0)
// {
// dup();
// execl("/usr/bin/gcc", ....);
// }
// 从管道中,读取python处理完成的结果!
}
void Register(HttpRequest&req, HttpResponse &resp)
{
}
void GetProductList(HttpRequest&req, HttpResponse &resp)
{
}
void Search(HttpRequest&req, HttpResponse &resp)
{
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(1);
}
ENABLE_CONSOLE_LOG_STRATEGY();
uint16_t port = std::stoi(argv[1]);
// 2. 定义HTTP协议
std::unique_ptr<HttpProtocol> protocol = std::make_unique<HttpProtocol>();
// GET /yuyinshibie HTTP/1.1
//
// {xxxxx}
protocol->RegisterService("/Login", Login);
protocol->RegisterService("/Register", Register);
protocol->RegisterService("/Search", Search);
protocol->RegisterService("/api/getprocutlist", GetProductList);
// 3. 定义网络对象
std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer>(
[&protocol](std::string &inbuffer)->std::string{
return protocol->HandlerHttpRequest(inbuffer);
}, port
);
// 4. 启动
tsvr->Loop();
return 0;
}
其他文件在往期博客中。