2.3.插入排序------像打牌一样整理数组,为什么它对"几乎有序"数据特别友好?
系列 :搜索与排序 | 第 3 篇,共 16 篇
难度 :⭐☆☆☆☆ 入门级
标签 :排序插入排序稳定排序基础算法小数据优化
上一篇 :2.2.选择排序------每轮找最小,为什么交换更少却反而不稳定?
下一篇 :2.4.快速排序------先分区再递归,为什么它平均这么快却可能退化?
前言
"插入排序不也是 O(n²) 吗,为什么它的口碑往往比冒泡和选择更好?"
这是很多初学者学到第三个基础排序时都会冒出来的问题。
插入排序表面上看也不复杂:每次拿一个新元素,插到前面已经有序的部分里。但真正往下挖,你会发现它有几个很值得讲透的点:
- 为什么它像"整理手里的扑克牌"?
- 为什么它在最坏情况下还是 O(n²),却对"几乎有序"数据特别友好?
- 为什么它是稳定排序?
- 为什么很多工程实现会在小区间切换到插入排序?
- 它和希尔排序、链表排序之间又有什么联系?
这篇就把插入排序讲透。
一、算法思想:维护前缀有序区间
插入排序的核心思想很直观:
把数组看成"前面已经有序、后面还未处理"两部分,每一轮从后半部分拿出一个元素,把它插入到前半部分的正确位置。
假设数组长度为 n:
- 初始时,可以认为第
0个元素自己就是一个长度为 1 的有序区间 - 第 1 轮:把第
1个元素插入到区间[0, 0]中 - 第 2 轮:把第
2个元素插入到区间[0, 1]中 - 第 3 轮:把第
3个元素插入到区间[0, 2]中 - ......
- 第
n-1轮结束后,整个数组有序
📌 核心不变量 :第
i轮结束后,区间[0, i]已经有序,并且保持了这i+1个元素在排序后的正确相对顺序。
这也是它和前两篇算法的区别:
- 冒泡排序:不断交换相邻元素,把大元素往后"推"
- 选择排序:扫描未排序区间,把最值"选"出来
- 插入排序:把当前元素拿出来,插入到前面有序区间的合适位置
如果你打过扑克牌,这个过程会非常自然:
- 手牌左边已经排好序
- 右手新摸到一张牌
- 从右往左找位置
- 给它腾出空位,再把它插进去
这就是插入排序。
二、完整图解过程
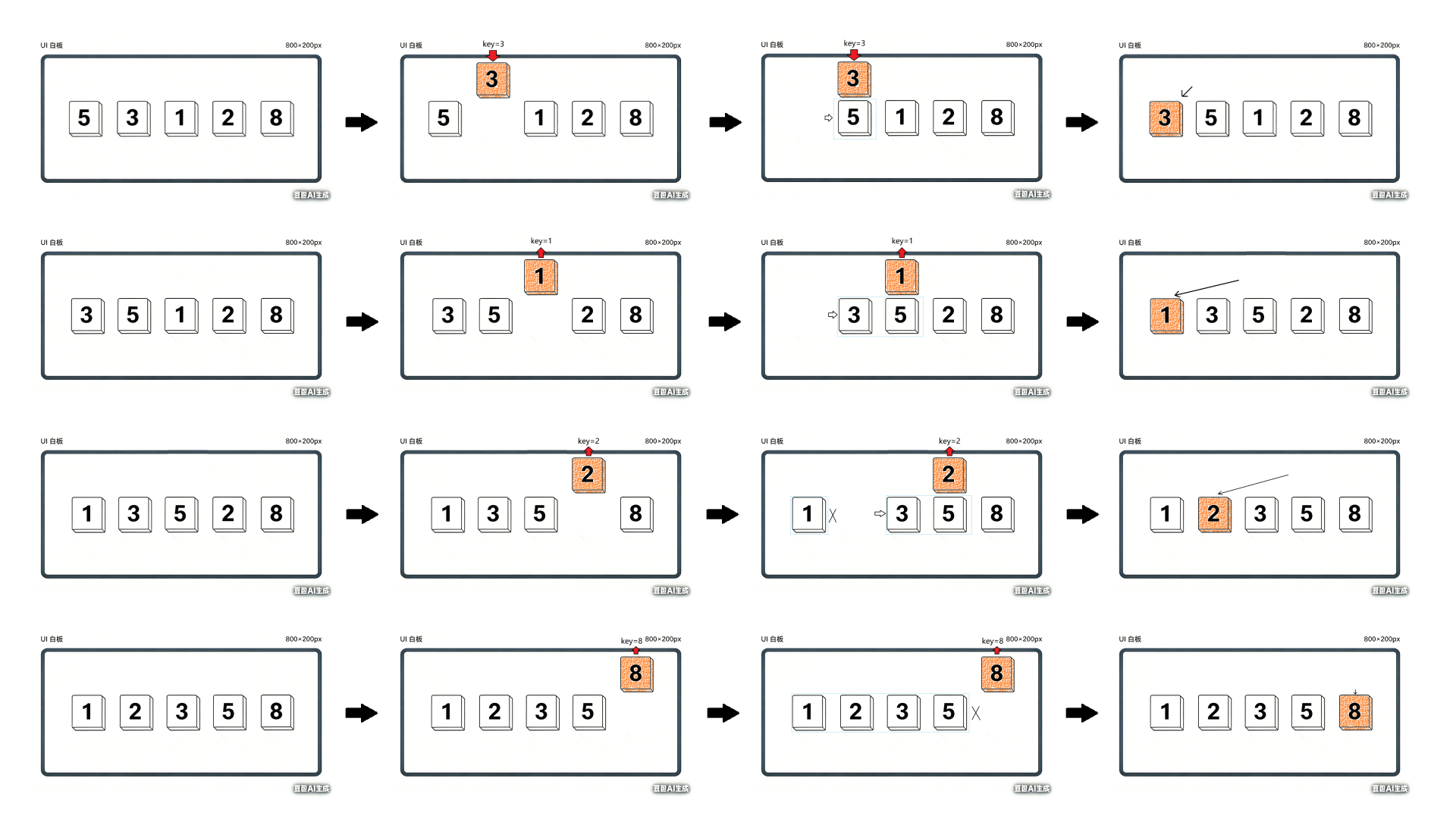
以数组 [5, 3, 8, 1, 2] 为例,逐步演示插入排序的全过程。
第 1 轮:把 3 插入到 [5] 中
text
初始: [5 | 3, 8, 1, 2]
↑ 左边视为已排序区间
取出 key = 3
比较 5 和 3:5 > 3,5 右移一位
腾出位置后,把 3 放进去
结果: [3, 5 | 8, 1, 2]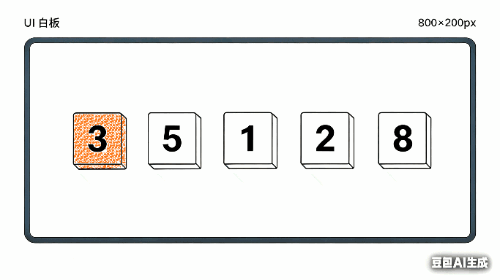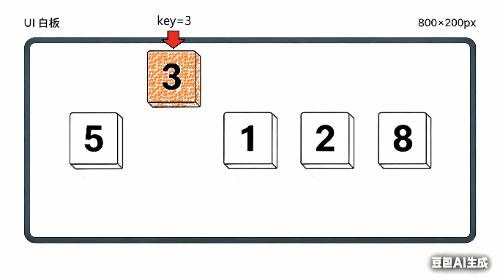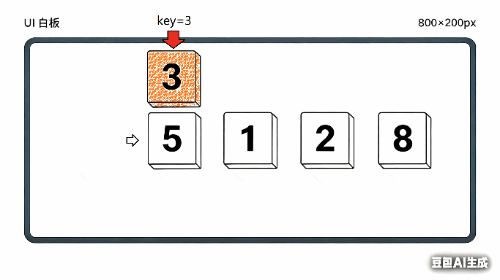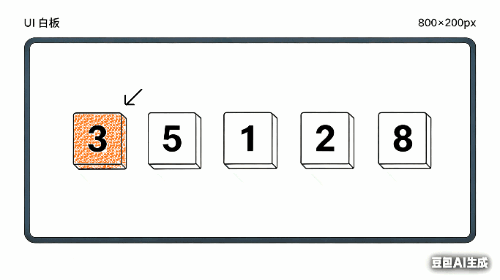
第 2 轮:把 8 插入到 [3, 5] 中
text
当前: [3, 5 | 8, 1, 2]
取出 key = 8
比较 5 和 8:5 < 8,不需要移动
直接放在末尾
结果: [3, 5, 8 | 1, 2]这一步很能体现插入排序的特点:
- 如果当前元素本来就比前面的都大
- 那它几乎不用动
- 这也是它在"几乎有序"数据上会很快的原因之一
第 3 轮:把 1 插入到 [3, 5, 8] 中
text
当前: [3, 5, 8 | 1, 2]
取出 key = 1
比较 8 和 1:8 > 1,8 右移
比较 5 和 1:5 > 1,5 右移
比较 3 和 1:3 > 1,3 右移
腾出第 0 位后,把 1 放进去
结果: [1, 3, 5, 8 | 2]这一轮能看出插入排序的本质:
- 它不是不断交换
- 而是先把
key暂存起来 - 再把比它大的元素整体向右挪
- 最后一次性落位
第 4 轮:把 2 插入到 [1, 3, 5, 8] 中
text
当前: [1, 3, 5, 8 | 2]
取出 key = 2
比较 8 和 2:8 > 2,8 右移
比较 5 和 2:5 > 2,5 右移
比较 3 和 2:3 > 2,3 右移
比较 1 和 2:1 < 2,停止
把 2 放到 1 后面
结果: [1, 2, 3, 5, 8]最终结果:[1, 2, 3, 5, 8] ✅
整体过程汇总
| 轮次 | 当前 key | 已排序区间变化 | 结果 |
|---|---|---|---|
| 第 1 轮 | 3 | [5] -> [3, 5] |
[3, 5, 8, 1, 2] |
| 第 2 轮 | 8 | [3, 5] -> [3, 5, 8] |
[3, 5, 8, 1, 2] |
| 第 3 轮 | 1 | [3, 5, 8] -> [1, 3, 5, 8] |
[1, 3, 5, 8, 2] |
| 第 4 轮 | 2 | [1, 3, 5, 8] -> [1, 2, 3, 5, 8] |
[1, 2, 3, 5, 8] |
三、代码实现
Python 版本(带注释)
python
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key = arr[i] # 当前待插入元素
j = i - 1
# 把所有比 key 大的元素向右移动一位
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
# 把 key 放到正确位置
arr[j + 1] = key
return arr
arr = [5, 3, 8, 1, 2]
print(insertion_sort(arr)) # [1, 2, 3, 5, 8]C++ 版本
cpp
#include <iostream>
#include <vector>
using namespace std;
void insertionSort(vector<int>& arr) {
int n = arr.size();
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
int main() {
vector<int> arr = {5, 3, 8, 1, 2};
insertionSort(arr);
for (int &x : arr) {
cout << x << " ";
}
return 0;
}四、复杂度分析
1)时间复杂度
| 情况 | 时间复杂度 | 原因 |
|---|---|---|
| 最好情况 | O(n) | 数组本身有序,每轮只需比较一次,几乎不用移动 |
| 最坏情况 | O(n²) | 数组完全逆序,第 i 轮可能要移动 i 个元素 |
| 平均情况 | O(n²) | 平均每轮都要向左寻找插入位置 |
最好情况为什么是 O(n)?
因为如果数组已经有序,比如:
text
[1, 2, 3, 4, 5]那么每一轮都会发生:
key取出来- 与前一个元素比较一次
- 发现不用动
- 直接结束
总共只需要做大约 n-1 次比较,所以是 O(n)。
最坏情况为什么是 O(n²)?
因为如果数组完全逆序,比如:
text
[5, 4, 3, 2, 1]那么:
- 第 1 轮移动 1 次
- 第 2 轮移动 2 次
- 第 3 轮移动 3 次
- ......
- 第
n-1轮移动n-1次
总操作量约为:
text
1 + 2 + 3 + ... + (n-1) = n(n-1)/2 = O(n²)2)空间复杂度
| 指标 | 值 | 原因 |
|---|---|---|
| 空间复杂度 | O(1) | 只使用了 key、j 等少量辅助变量 |
| 是否原地 | ✅ | 不需要额外数组 |
3)数据移动特点
插入排序最值得记住的一点是:
它的比较和移动次数,不是固定的,而是跟数组"离有序还有多远"强相关。
这也是它和选择排序最不一样的地方:
- 选择排序的比较次数几乎固定
- 插入排序的工作量会随着"逆序程度"变化
五、稳定性:为什么它是稳定排序?
先回顾稳定性的定义:
如果两个相等元素在排序前后的相对顺序不变,那么这个排序算法就是稳定的。
插入排序是稳定排序。
原因就在这句条件判断:
cpp
while (j >= 0 && arr[j] > key)注意这里写的是:
arr[j] > key
而不是:
arr[j] >= key
这意味着:
- 只有当前面的元素严格大于
key时,才会右移 - 如果前面的元素和
key相等,就不会继续右移 - 于是后出现的相等元素,只会被插到前面相等元素的后面
六、为什么它对"几乎有序"数据特别友好?
这是插入排序最有价值的一个性质。
如果数组本来就差不多有序,那么每一轮插入时:
key往左移动的距离很短- 甚至很多轮根本不用移动
- 因而总开销会非常小
比如数组:
text
[1, 2, 3, 4, 6, 5, 7, 8]这里只有 6 和 5 的位置有点不对。
插入排序处理到 5 时:
- 把
6右移一位 - 再把
5放到6前面
整个数组就已经有序了。
也就是说,它没有做很多"无意义的大动作"。
一个更本质的理解:它和逆序对数量有关
设数组中的逆序对数量为 k。
对于插入排序来说:
- 内层
while循环每执行一次 - 本质上都在消除一个"当前 key 与前面某个元素"的逆序关系
因此可以把插入排序的时间复杂度理解成:
O(n + k)
其中:
n是外层扫描一遍数组的成本k是需要通过移动元素来消除的逆序关系数量
这就解释了为什么:
- 数据越接近有序,插入排序越快
- 在某些近乎有序的小数组里,它甚至会比快排、归并这类
O(n log n)算法更顺手
这也是很多工程实现会在小区间 或近乎有序区间里切换到插入排序的原因。
七、优化与变体
优化 1:使用"后移"而不是频繁交换
很多初学者第一次写插入排序时,会把它写成这样:
- 遇到逆序就不断swap交换相邻元素
虽然逻辑上也能排出来,但这样会产生更多赋值操作。
更推荐的标准写法是:
- 先把当前元素保存到
key - 把所有比
key大的元素统一右移 - 最后一次性把
key放到空出来的位置
也就是我们前面代码里的这种写法。
它的好处是:
- 代码逻辑更清楚
- 数据写入次数更少
- 更符合插入排序"腾位置再落位"的本质
变体 2:二分插入排序
插入排序有两个主要成本:
- 比较:找插入位置
- 移动 :给
key腾位置
如果想减少比较次数,可以在已经有序的区间里用二分查找定位插入位置。
cpp
#include <vector>
using namespace std;
void binaryInsertionSort(vector<int>& arr) {
int n = arr.size();
for (int i = 1; i < n; i++) {
int key = arr[i];
int left = 0, right = i - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] > key) {
right = mid - 1;
} else {
left = mid + 1;
}
}
for (int j = i - 1; j >= left; j--) {
arr[j + 1] = arr[j];
}
arr[left] = key;
}
}它的特点是:
- 查找插入位置从线性扫描变成二分查找
- 比较次数减少了
- 但元素右移的次数并没有本质减少
所以:
二分插入排序不能把整体复杂度降到 O(n log n),因为移动元素的成本仍然可能是 O(n²)。
变体 3:希尔排序,本质上是"分组插入"
如果继续沿着"插入排序太怕远距离逆序"这个问题往前走,就会得到一个更强的改进思路:
- 先让相距较远的元素也能提前比较和移动
- 再逐步缩小间隔
- 最后回到普通插入排序收尾
这就是希尔排序的核心想法。后续讲到希尔排序时再详细说。
八、与冒泡排序、选择排序对比
| 对比项 | 冒泡排序 | 选择排序 | 插入排序 |
|---|---|---|---|
| 核心动作 | 相邻比较并交换 | 扫描后选最值交换 | 取出当前元素,插入前面有序区间 |
| 最好时间复杂度 | O(n) | O(n²) | O(n) |
| 平均时间复杂度 | O(n²) | O(n²) | O(n²) |
| 稳定性 | 稳定 | 不稳定 | 稳定 |
| 对几乎有序数据是否友好 | 较友好 | 不友好 | 非常友好 |
| 数据移动特点 | 交换频繁 | 交换少但比较固定 | 以"元素后移 + 最后落位"为主 |
| 工程小数组优化价值 | 一般 | 一般 | 较高 |
一句话总结:
冒泡是在"推",选择是在"挑",插入是在"腾位置后放进去"。
九、OJ 例题讲解
例题 1:LeetCode 1051 --- 高度检查器(小数据,插入排序可直接通过)
题目来源 :LeetCode,题号 1051 难度:⭐☆☆☆☆ 简单
题目链接 :https://leetcode.cn/problems/height-checker/
题目描述:
给你一个整数数组
heights,表示学生当前站位的身高。把它按非递减顺序排好后,统计有多少个位置上的值与原数组不同。
数据范围:
1 <= n <= 1001 <= heights[i] <= 100
为什么这题适合用插入排序?
这题的数据规模非常小,n 最多只有 100。
所以完全可以:
- 先复制原数组
- 对副本使用插入排序
- 再逐位比较原数组与排序后数组,统计不同位置数量
也就是说,这不是"只能拿来做模板练习"的题,而是一道直接手写插入排序也能顺利通过的基础题。
C++ 解法(插入排序写法):
cpp
// 头文件编译平台提供
class Solution {
public:
int heightChecker(vector<int>& heights) {
vector<int> expected = heights;
int n = expected.size();
for (int i = 1; i < n; i++) {
int key = expected[i];
int j = i - 1;
while (j >= 0 && expected[j] > key) {
expected[j + 1] = expected[j];
j--;
}
expected[j + 1] = key;
}
int ans = 0;
for (int i = 0; i < n; i++) {
if (heights[i] != expected[i]) {
ans++;
}
}
return ans;
}
};这题适合拿来练什么?
- 练最标准的数组插入排序模板
- 练"排序后再比较"的常见解题套路
- 体会小数据范围下
O(n²)算法依然完全可用
例题 2:LeetCode 147 --- 对链表进行插入排序(思想直接对应)
题目来源 :LeetCode,题号 147 难度:⭐⭐⭐☆☆ 中等
题目链接 :https://leetcode.cn/problems/insertion-sort-list/
题目描述:
给定单链表的头节点
head,请你使用插入排序对链表进行排序,并返回排序后的链表头节点。Definition for singly-linked list.
struct ListNode {
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
为什么这题和插入排序高度匹配?
因为题目要求的就是"链表版插入排序"。
它和数组版插入排序的共同点是:
- 都维护一个"已经有序"的部分
- 每次从未排序部分取出一个元素
- 把它插到已排序部分的正确位置
不同点在于:
- 数组:插入时往往要移动一串元素
- 链表:插入时不需要搬值,只要改指针
所以这题非常适合帮助你理解:
插入排序的核心不在"数组",而在"把一个新元素插到已有序结构中"。
C++ 解法:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
ListNode dummy(0); // 无实际意义的头结点,用dummy->next来指当前生成的链表
ListNode* cur = head;
while (cur != nullptr) {
ListNode* nextNode = cur->next;
ListNode* prev = &dummy;
while (prev->next != nullptr && prev->next->val < cur->val) {
prev = prev->next;
}
cur->next = prev->next;
prev->next = cur;
cur = nextNode;
}
return dummy.next;
}
};这题适合拿来练什么?
- 练"插入排序思想"和"链表操作"结合
- 练虚拟头结点
dummy的写法 - 理解为什么链表在"插入"这件事上天然比数组更顺手
例题 3:POJ 1007 --- DNA Sorting(稳定排序的价值)
题目来源 :POJ / PKU OJ,题号 1007 难度:⭐⭐☆☆☆
题目链接 :http://poj.org/problem?id=1007
题目描述:
给你
m个长度为n的 DNA 字符串,需要按每个字符串的"逆序数"从小到大进行稳定排序后输出。
数据范围:
n <= 50m <= 100
为什么这题适合出现在插入排序章节?
这题和插入排序的契合点非常强:
- 数据量不大 :
m最多只有100,完全可以直接手写稳定排序 - 题目明确要求稳定排序:而插入排序天然稳定
- 排序对象不是整数,而是"带权记录":更能体现稳定排序在真实题目里的价值
也就是说,这题不是单纯的"把数字排一下",而是要你意识到:
当排序键相同、又要求保留原顺序时,稳定排序就很重要。
C++ 解法(计算逆序数 + 稳定插入排序):
cpp
#include <iostream>
#include <string>
#include <vector>
using namespace std;
struct Node {
string s;
int score;
};
int getScore(const string& s) {
int cnt = 0;
int n = s.size();
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (s[i] > s[j]) {
cnt++;
}
}
}
return cnt;
}
int main() {
int n, m;
cin >> n >> m;
vector<Node> arr(m);
for (int i = 0; i < m; i++) {
cin >> arr[i].s;
arr[i].score = getScore(arr[i].s);
}
for (int i = 1; i < m; i++) {
Node key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j].score > key.score) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
for (int i = 0; i < m; i++) {
cout << arr[i].s << endl;
}
return 0;
}这题适合拿来练什么?
- 练"结构体排序"而不是"纯整数排序"
- 练稳定排序的真实使用场景
- 体会插入排序为什么在小规模、稳定性要求明确的题里依然有价值
十、适用场景
| 场景 | 是否适用 | 原因 |
|---|---|---|
数据量很小(如 n < 50 或 n < 100) |
✅ | 常数小、代码短、实现简单 |
| 数组几乎有序 | ✅ | 总移动距离短,速度很可观 |
| 需要稳定排序 | ✅ | 相等元素相对顺序不变 |
| 小区间工程优化 | ✅ | 常作为大排序算法的小区间收尾方案 |
| 大规模随机数组 | ❌ | 平均仍是 O(n²),不适合主力排序 |
| 元素远距离错位很多 | ❌ | 会产生大量后移操作 |
十一、常见错误总结
| 错误 | 原因 | 正确做法 |
|---|---|---|
| 每次比较都直接交换相邻元素 | 把"后移插入"写成了"频繁交换" | 先保存 key,统一后移赋值,再一次落位 |
while 写成 arr[j] >= key |
会破坏稳定性 | 只在 arr[j] > key 时右移 |
忘记最后 arr[j + 1] = key |
找到了位置却没真正插进去 | 循环结束后必须落位 |
| 误以为二分插入排序是 O(n log n) | 忽略了元素移动成本 | 比较次数降了,但移动仍可能是 O(n²) |
| 误以为它只适合教学 | 忽略了它对近乎有序数据和小区间优化的价值 | 记住它在工程里也常被拿来做小范围收尾 |
总结
| 要点 | 内容 |
|---|---|
| 核心思想 | 每轮取出一个元素,插入到前面已经有序的区间中 |
| 时间复杂度 | 最好 O(n),平均/最坏 O(n²) |
| 空间复杂度 | O(1),原地排序 |
| 稳定性 | ✅ 稳定 |
| 关键特点 | 对几乎有序数据特别友好 |
| 思想延伸 | 二分插入、链表插入、希尔排序 |
一句话记住它:
插入排序最像人手整理扑克手牌------每接收一个新排(新元素),把它插入手牌中对应位置(插入已有序队列中的对应位置)
上一篇 :2.2.选择排序------每轮找最小,为什么交换更少却反而不稳定?
下一篇 :2.4.快速排序------先分区再递归,为什么它平均这么快却可能退化?
💬 看完有收获的话,点个赞再走~ 有问题欢迎评论区讨论 🙏