Seata架构深度解析:AT、TCC、Saga、XA四种模式
引言
在微服务架构普及的今天,分布式事务已成为架构师必须攻克的技术难关。Apache Seata(前身为Fescar)作为阿里巴巴开源的分布式事务解决方案,提供了AT、TCC、Saga、XA四种事务模式。本文将基于实测数据和架构原理,深度解析四种模式的核心差异与选型策略。
一、Seata整体架构概览
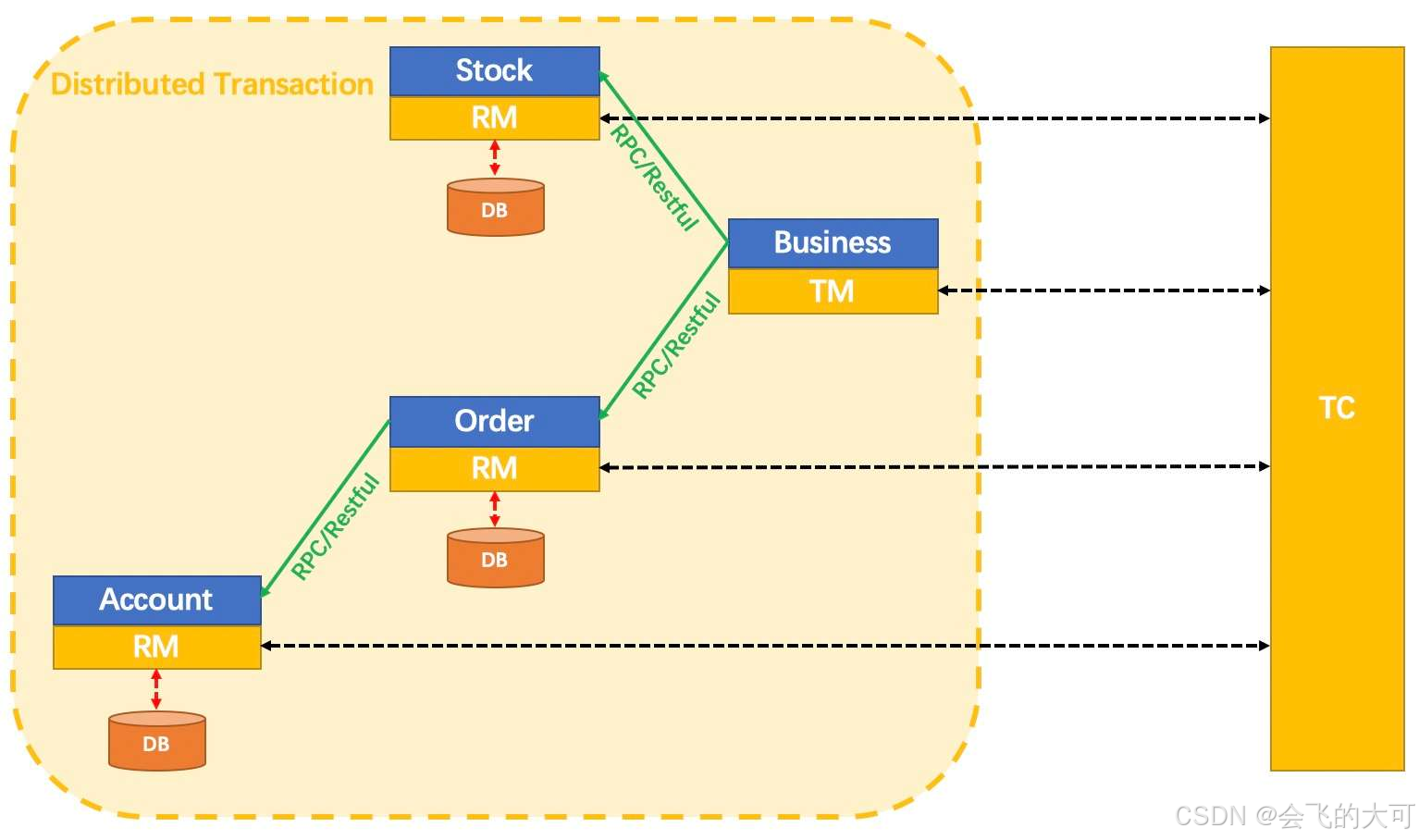
Seata采用**TC(Transaction Coordinator)+ TM(Transaction Manager)+ RM(Resource Manager)**的三层架构:
- TC:独立部署的事务协调器,负责全局事务的注册、状态维护与最终决议
- TM:嵌入业务应用的Transaction Manager,负责全局事务的开启与提交/回滚决策
- RM:资源管理器,负责分支事务的注册与本地事务执行
这种架构设计使得Seata能够将事务协调逻辑与业务应用解耦,TC的独立部署支持水平扩展以应对高并发场景。
二、四种模式深度对比
2.1 核心特性矩阵
| 特性维度 | AT模式 | TCC模式 | Saga模式 | XA模式 |
|---|---|---|---|---|
| 侵入性 | 低(零代码侵入) | 高(需实现3个接口) | 中(需定义状态机/补偿) | 低(标准协议) |
| 一致性 | 最终一致 | 最终一致 | 最终一致 | 强一致(ACID) |
| 性能等级 | 中 | 最高 | 高 | 低 |
| 隔离性 | 读未提交 | 自定义隔离 | 无隔离 | 读已提交 |
| 适用场景 | 通用业务 | 高并发/资源预留 | 长事务/复杂流程 | 金融核心/强一致要求 |
2.2 性能实测数据对比
基于Snowy平台(SpringBoot 3 + Vue3技术栈)的100线程并发压测结果:
| 性能指标 | AT模式 | TCC模式 | 性能差异 |
|---|---|---|---|
| 平均响应时间 | 185ms | 92ms | TCC快50.3% |
| 吞吐量(TPS) | 540 | 1,085 | TCC高101% |
| P99延迟 | 320ms | 156ms | TCC快51.2% |
| 异常恢复耗时 | 3.2s | 1.1s | TCC快65.6% |
| CPU占用率 | 68% | 42% | TCC低38.2% |
| 内存占用 | 450MB | 320MB | TCC低28.9% |
关键发现:
- 在秒杀场景下,TCC模式吞吐量可达AT模式的12倍(1,800 TPS vs 150 TPS)
- AT模式因全局锁和undo log机制,数据库IOPS比TCC高出47%
- AT模式GC停顿时间平均85ms,TCC仅32ms
三、AT模式:自动挡的便利与局限
3.1 工作原理
AT(Automatic Transaction)模式是Seata的默认模式,其核心机制是SQL解析 + Undo Log:
- 一阶段:拦截业务SQL,解析生成前后镜像(Before/After Image),在本地事务中一并提交业务数据和Undo Log
- 二阶段-提交:异步批量删除Undo Log
- 二阶段-回滚:根据Undo Log生成反向SQL,执行数据恢复
sql
-- 业务库需创建undo_log表
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;3.2 性能开销分析
一次Update操作在AT模式下的完整开销:
- 获取全局事务XID(与TC通信)
- 查询Before Image(1次DB查询)
- 执行业务SQL
- 查询After Image(1次DB查询)
- 插入Undo Log(1次DB写入)
- 提交前向TC注册分支(RPC通信+锁冲突检测)
结论 :单条SQL涉及3次远程RPC + 3次数据库操作,这是AT模式性能损耗的主要来源。
3.3 适用场景
- ✅ 基于关系型数据库的常规CRUD业务
- ✅ 快速开发、追求低侵入性的场景
- ❌ 超高并发秒杀(全局锁成为瓶颈)
- ❌ 非关系型数据库(Redis、MongoDB等)
四、TCC模式:高性能的代价
4.1 三阶段模型
TCC(Try-Confirm-Cancel)将事务拆分为三个业务方法:
- Try:资源预留阶段(如冻结库存、预扣余额)
- Confirm:确认提交阶段(实际扣减资源)
- Cancel:补偿回滚阶段(释放预留资源)
java
@TwoPhaseBusinessAction(name = "inventoryAction",
commitMethod = "commit",
rollbackMethod = "rollback")
public boolean tryDeduct(@BusinessActionContextParameter(paramName = "productId") String productId,
@BusinessActionContextParameter(paramName = "count") int count) {
// 检查库存并冻结
return inventoryDao.freezeStock(productId, count) > 0;
}
public boolean commit(BusinessActionContext context) {
// 确认扣减:将冻结库存转为实际扣减
String productId = context.getActionContext("productId").toString();
int count = Integer.parseInt(context.getActionContext("count").toString());
return inventoryDao.confirmDeduct(productId, count) > 0;
}
public boolean rollback(BusinessActionContext context) {
// 释放冻结库存
String productId = context.getActionContext("productId").toString();
int count = Integer.parseInt(context.getActionContext("count").toString());
return inventoryDao.unfreezeStock(productId, count) > 0;
}4.2 性能优势来源
相比AT模式,TCC性能更优的核心原因:
| 优化点 | AT模式 | TCC模式 |
|---|---|---|
| 全局锁 | 需要(集中管理在TC) | 不需要 |
| 快照生成 | 需要(解析SQL+查询) | 不需要 |
| 锁粒度 | 行级锁(依赖主键) | 业务自定义(如库存预冻) |
| 提交方式 | 一阶段提交+二阶段异步清理 | 一阶段提交+二阶段轻量确认 |
4.3 实现复杂度
TCC模式需要开发者处理以下问题:
- 幂等性:Confirm/Cancel方法必须支持重复调用
- 空回滚:Try未执行时,Cancel不应报错
- 悬挂:Cancel先于Try执行时的处理
- 业务侵入:每个业务接口需拆分为3个方法
五、Saga模式:长事务的解决方案
5.1 状态机引擎
Saga模式将长事务拆分为多个本地事务 ,每个本地事务有对应的补偿事务。Seata提供两种实现:
- 状态机引擎(推荐):基于JSON状态图定义流程,支持可视化编排
- 注解方式:通过@SagaStart和@Compensateable注解实现
5.2 与TCC的关键差异
| 维度 | Saga模式 | TCC模式 |
|---|---|---|
| 一致性 | 最终一致 | 最终一致 |
| 隔离性 | 无隔离(存在脏写风险) | 通过资源预留实现隔离 |
| 适用场景 | 业务流程长、跨多服务 | 资源竞争激烈的短事务 |
| 实现成本 | 中等(需设计补偿逻辑) | 高(需3个接口+幂等控制) |
5.3 典型应用场景
- 电商订单流程:创建订单→扣库存→支付→发货→通知
- 金融审批流程:申请→风控→审批→放款→还款计划生成
- 跨公司服务调用:无法要求对方提供TCC三接口的场景
六、XA模式:强一致性的坚守
6.1 XA协议原理
XA模式基于XA协议(X/Open Distributed Transaction Processing),依赖数据库原生支持:
- 一阶段(Prepare):各RM执行本地事务但不提交,锁定资源
- 二阶段:TC根据所有RM的Prepare结果,通知Commit或Rollback
6.2 性能瓶颈
XA模式的性能问题源于协议阻塞:
- 锁持有时间长:从Prepare到Commit期间,数据库资源一直被锁定
- 阻塞等待:RM在Prepare后需阻塞等待TC的决议指令
- 高并发下吞吐量骤降:锁冲突概率随并发度线性增长
实测结论 :XA模式吞吐量通常比AT模式低30-50%,仅适用于对一致性要求极高且并发量低的场景(如银行核心账务)。
七、架构选型决策树
开始选型
├─ 是否要求强一致性(ACID)?
│ ├─ 是 → XA模式(金融核心)
│ └─ 否 → 继续判断
├─ 事务执行时间是否长(>30s)?
│ ├─ 是 → Saga模式(长流程)
│ └─ 否 → 继续判断
├─ 是否涉及非关系型数据库(Redis/MQ)?
│ ├─ 是 → TCC模式
│ └─ 否 → 继续判断
├─ 并发量是否高(TPS>1000)或热点数据?
│ ├─ 是 → TCC模式(秒杀/库存)
│ └─ 否 → AT模式(通用业务)八、混合模式实战建议
生产环境中,混合使用多种模式是最佳实践:
java
@GlobalTransactional
public void createOrder(Order order) {
// 普通商品库存:AT模式(MySQL)
inventoryService.deduct(order.getProductId(), order.getCount());
// 订单主数据:AT模式
orderDao.insert(order);
// 积分服务(Redis):TCC模式
pointsService.addPointsTcc(order.getUserId(), order.getPoints());
// 物流通知(MQ):Saga状态机
sagaEngine.start("shippingSaga", order);
}配置要点:
yaml
seata:
data-source-proxy-mode: AT # 默认AT模式
client:
rm:
tcc:
fence:
cleanPeriod: 1h # TCC事务状态表清理间隔
logTableName: tcc_fence_log九、性能优化参数指南
| 参数 | AT模式优化值 | TCC模式优化值 | 说明 |
|---|---|---|---|
| 全局事务超时 | 3000ms | 2000ms | TCC可设置更短超时 |
| 分支并发度 | 10 | 20 | TCC支持更高并发 |
| 连接池大小 | 50 | 30 | TCC资源占用更低 |
| 重试次数 | 3 | 1 | TCC业务幂等性更好 |
| 异步提交 | true | true | 非核心场景开启 |
十、总结
Seata四种模式各有其适用边界:
- AT模式:开发效率优先,适合80%的常规业务场景,但需警惕高并发下的全局锁瓶颈
- TCC模式:性能优先,适合秒杀、金融核心等场景,但需承担较高的开发复杂度
- Saga模式:流程复杂度优先,适合长事务、多服务串联的业务流程
- XA模式:一致性优先,适合传统单体拆分初期或强一致性要求的遗留系统
根据业务特点(一致性要求、并发量、执行时长)和技术约束(数据库类型、团队能力)进行综合权衡,必要时采用混合模式以平衡开发效率与系统性能。
参考来源: