
作为 MySQL 进阶核心知识点,存储过程和触发器能大幅提升数据库操作的效率、安全性和可维护性。本文将从概念到实战,逐字逐句拆解所有关键知识点,既保证内容不遗漏,又用通俗易懂的语言和丰富案例帮你彻底掌握,无论是学习还是面试都能直接套用!
学习相关知识之后,我们对下面的高频面试问题应该就可以回答了吧!
1. 存储过程的作用是什么?
2. 如何创建一个存储过程?
3. MySQL 中的变量都有哪几种?
4. 如何定义一个变量?
5. MySQL 中使用变量是否需要提前声明?
6. MySQL 中的参数分为哪几种?
7. 用过游标吗?游标的作用是什么?
8. 了解条件处理程序吗?介绍一下如何使用
9. 存储函数与存储过程的区别是什么?
10. 如何查看数据库中创建的存储过程?
11. 什么是触发器?
12. MySQL 中触发器分为几种类型?
13. 行级触发器与语句级触发器的区别是什么?
14. 说一下了解的触发器使用场景都有哪些?
15. 如果对一表中的数据进行更新,要在日志表中记录该条记录更新前与更新后的值,如何实现?
16. 如何查看数据库中创建的触发器?
一、存储过程:封装 SQL 的 "数据库函数"
1.1 什么是存储过程?
存储过程是一组为完成特定功能的SQL 语句集 ,经编译 后存储在数据库中。用户只需通过指定存储过程名称和参数,就能快速执行这组 SQL,并获取相应的结果,无需重复编写复杂逻辑。
简单说,存储过程就像数据库里的 "函数"------ 把常用的 SQL 逻辑打包,调用时直接传参即可,不用关心内部实现细节。
存储过程是预先编译并存储在 MySQL 服务端 的一组 SQL 语句集合。我们的业务代码只需要通过 CALL 存储过程名(参数列表) 来调用,无需在客户端拼接复杂 SQL ,直接传入参数即可执行完整的业务逻辑。
这里就可以看出这种设计的优势:
- 减少网络传输开销
- 复用 SQL 逻辑
- 提升安全性(控制数据访问权限)

1.2 核心特点
- 封装性:将复杂业务逻辑(比如多表查询、事务处理)封装在数据库内部,应用程序只需调用接口,降低代码复杂度。
- 可维护性:逻辑集中管理,修改时只需更新存储过程,无需改动应用程序代码。
- 可重用性:一次创建多次调用,避免重复编写相同 SQL,提升开发效率。
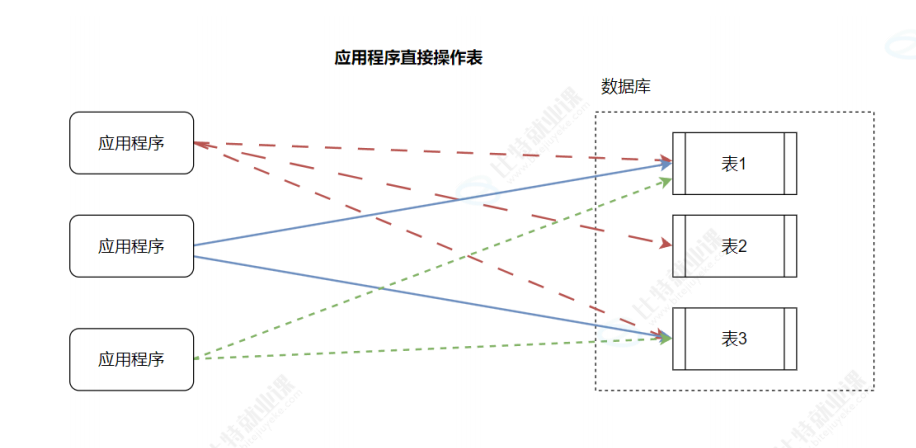
1. 应用程序直接操作表
- 流程:多个应用程序直接与数据库中的表(表 1、表 2、表 3)交互,业务逻辑由应用程序自身处理。
- 优势:应用程序分散处理业务逻辑,能减轻数据库的压力,从而提升系统性能 。
- 背景:数据库的核心职责是 "数据的存储与检索",如果让它过度承担业务逻辑,会违背其设计初衷。
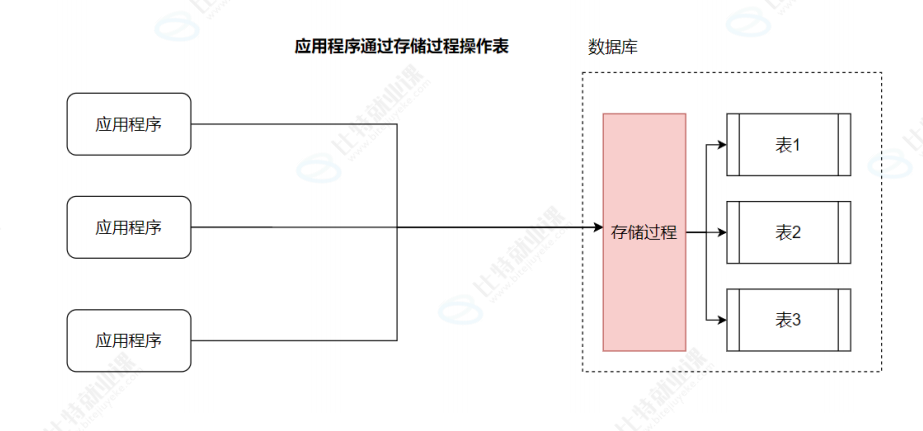
2. 应用程序通过存储过程操作表
- 流程:应用程序不直接操作表,而是调用数据库中的存储过程 ;由存储过程来完成对表 1、表 2、表 3 的操作,业务逻辑集中在数据库层的存储过程中处理。
- 问题:如果把大部分业务逻辑都放在数据库层面处理,会导致数据库负担过重,性能必然受到影响 。
通过对比两种数据交互模式,说明业务逻辑的 "归属层" 会直接影响系统性能:让应用程序分散处理业务逻辑,能优化性能;若过度依赖数据库的存储过程处理业务,反而会拖累性能。
现在业界更倾向于不使用存储过程 ,核心原因是:
- 业务逻辑散落在数据库端,难以版本控制、调试和单元测试,破坏了代码的可维护性;
- 数据库本身更适合做数据存储和查询,复杂的存储过程会加重数据库负载,影响整体性能和扩展性;
- 微服务架构下,业务逻辑更适合下沉到应用代码中,便于分布式部署、灰度发布和故障隔离,同时也能更好地复用和迭代。
简单说:把逻辑放回代码里,让数据库只做它擅长的 "存和取" ,系统会更清晰、更易维护。
1.3 优缺点全解析
优点
- 性能更优:创建时编译并存储,执行速度比单次执行多条 SQL 更快。
- 代码复用:减少重复代码,后续维护只需修改存储过程,降低维护成本。
- 安全性高:可限制用户直接操作数据表,通过存储过程间接访问,防止误操作或恶意修改。
- 事务支持:能在存储过程中实现复杂事务逻辑,保证数据一致性。
- 低耦合:表结构变更时,只需修改对应的存储过程,应用程序基本无需改动。
缺点
- 可移植性差:不同数据库(如 MySQL、Oracle)的存储过程语法差异大,更换数据库需重新编写。
- 调试困难:多数数据库管理系统不支持存储过程调试,开发和排错成本高。
- 高并发不友好:高并发场景下,大量存储过程调用会增加数据库压力,难以横向扩展。
具体来说:
「只编译一次」的优势确实存在
- 存储过程在首次创建时编译并缓存执行计划 ,后续调用直接复用,避免了每次解析 SQL、生成执行计划的开销,单次调用的执行效率确实更高 。
- 对于简单、重复的批量操作,这种 "预编译 + 复用" 能节省少量 CPU 和网络开销。
那为什么复杂存储过程反而更慢、更难扩展?
- 负载错配 :数据库的核心优势是高效的 IO 和查询优化 ,而复杂存储过程会把大量计算、循环、分支逻辑 压在数据库 CPU 上,挤占了本该用于查询和事务的资源,导致整体吞吐率下降。
- 难以并行与扩容 :应用层可以轻松水平扩容(加机器、分布式部署),但存储过程绑定在数据库实例上,一旦逻辑复杂,数据库就成了性能瓶颈,无法像应用代码那样通过微服务拆分、灰度发布来平滑迭代。
- 调试与维护成本极高 :存储过程的逻辑藏在数据库里,没有版本控制、难以断点调试、无法写单元测试,出问题排查成本远高于应用层代码,长期来看反而拖慢了整体开发效率。
1.4 核心语法
创建存储过程
创建前需先修改 SQL 结束标识符(默认分号会导致存储过程提前执行)
这个等下面具体来说明,这里我直接在 Navicat 上进行操作,这个会帮助我们自动处理,上面说要创建这个结束符的,这个影响的是我们将其交付到命令行的!
语法如下:
sql
-- 1. 修改结束标识符为//(避免与存储过程内分号冲突)
DELIMITER //
-- 2. 创建存储过程(参数列表可选)
CREATE PROCEDURE 存储过程名 ([IN/OUT/INOUT 参数名 参数类型])
BEGIN
-- 核心SQL逻辑(可包含多句)
SQL语句;
END //
-- 3. 恢复默认结束标识符
DELIMITER ;
sql
CREATE PROCEDURE TotalScore ()
BEGIN
select name, chinese + math + english as TotalScore from exam;
END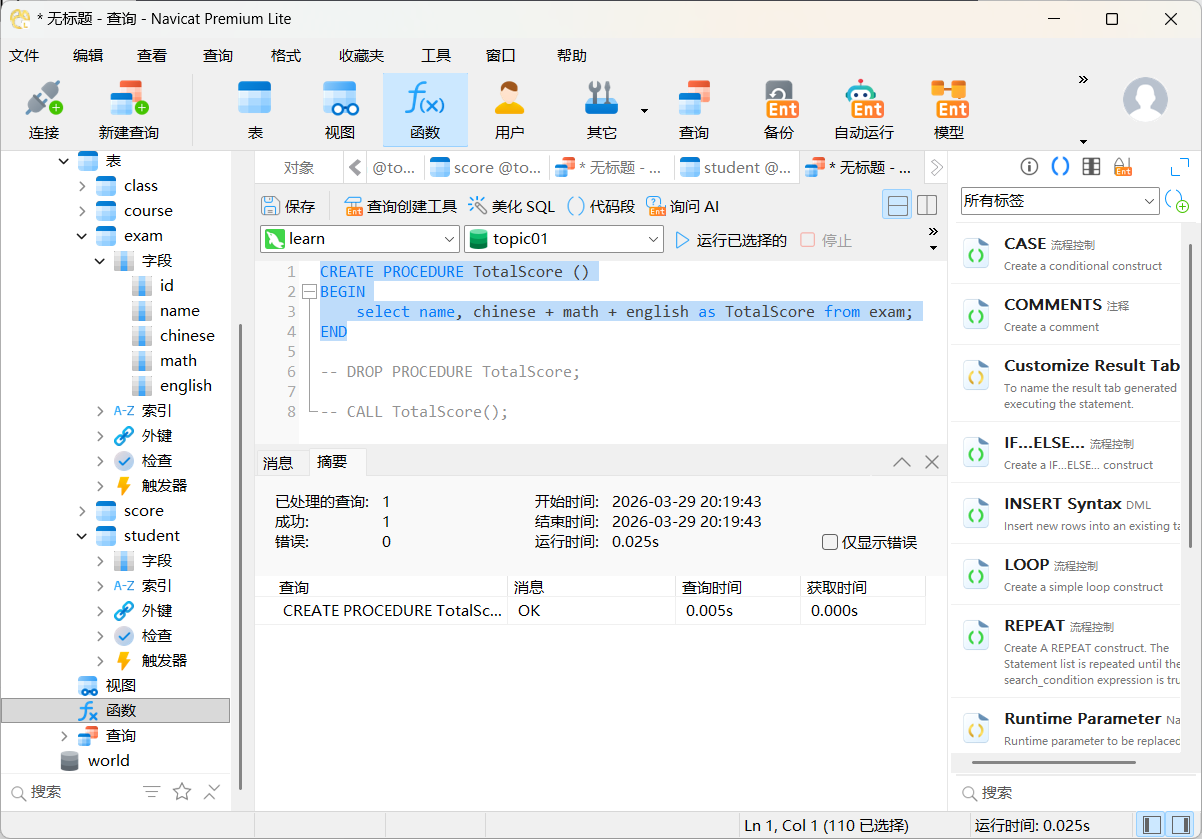
调用存储过程
sql
CALL 存储过程名 ([参数列表]);
sql
CALL TotalScore();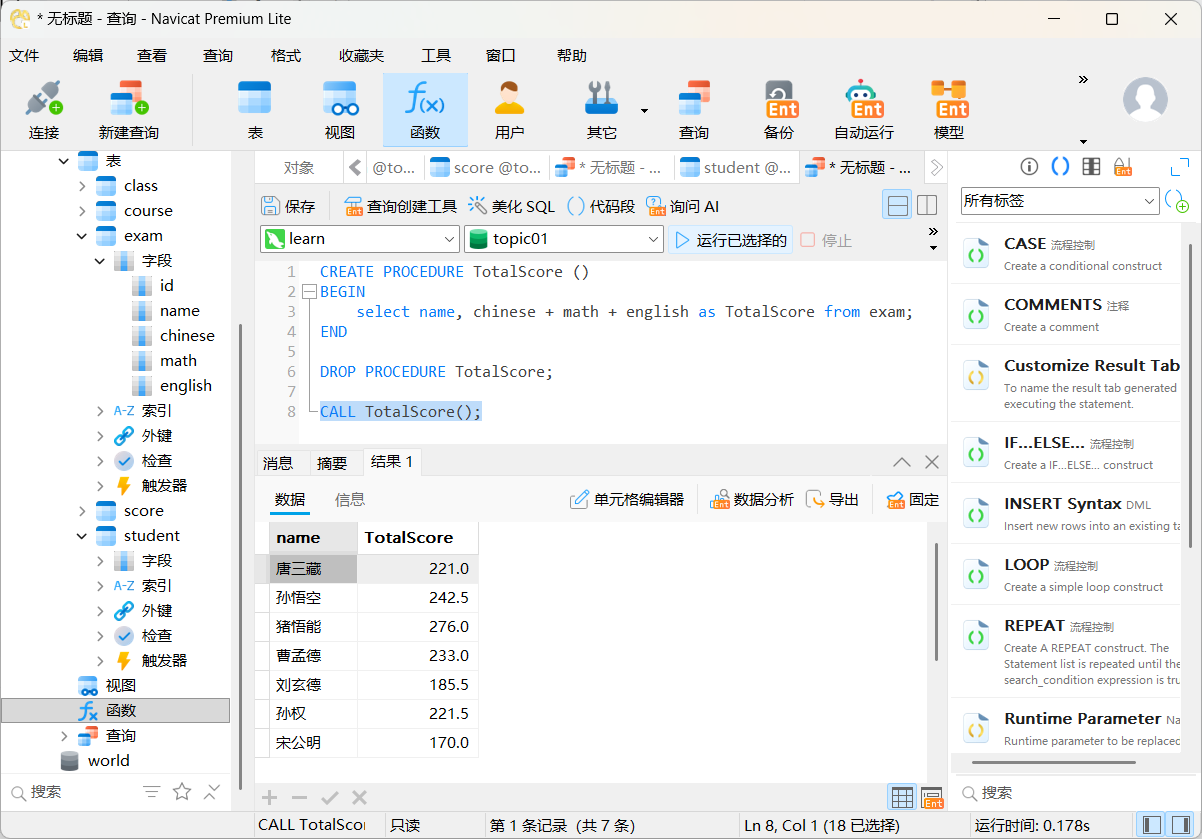
查看存储过程
查看指定数据库的所有存储过程:
sql
SELECT * FROM information_schema.ROUTINES WHERE ROUTINE_SCHEMA = '数据库名';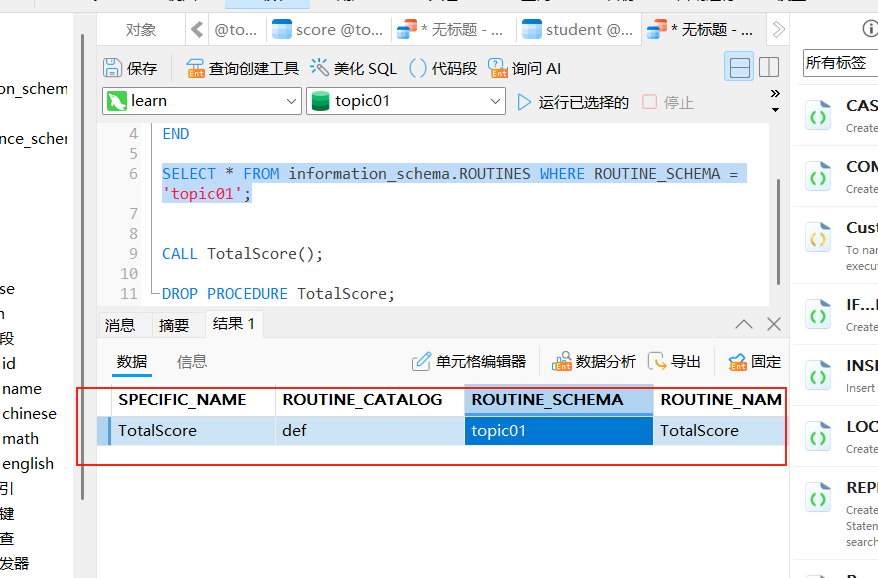
查看存储过程的具体定义:
sql
SHOW CREATE PROCEDURE 存储过程名;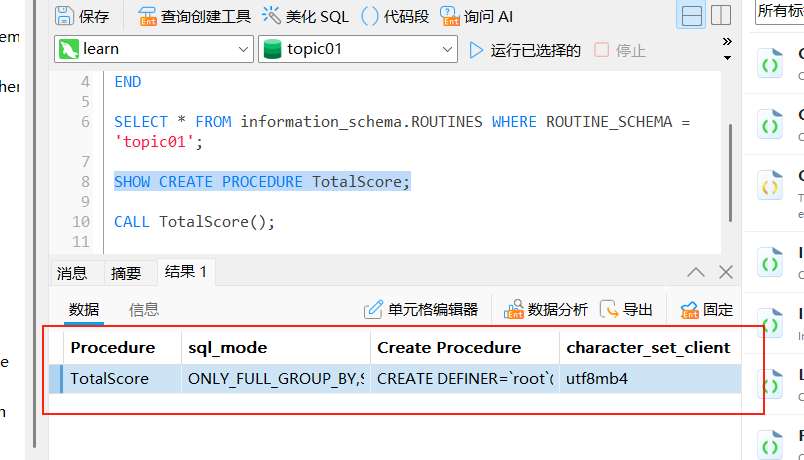
删除存储过程
sql
DROP PROCEDURE [IF EXISTS] 存储过程名; -- IF EXISTS可选,避免删除不存在的存储过程报错
1.5 相关疑问
DELIMITER 是什么?
DELIMITER 是 MySQL 客户端的命令,用来临时修改语句结束符 (默认是 ;)。
为什么需要修改?
在创建存储过程、函数、触发器等复合语句 时,这些对象内部会包含多个以 ; 结束的语句。如果不修改结束符,MySQL 客户端会在遇到第一个 ; 时就执行前面的内容,导致存储过程定义不完整、报错。
sql
mysql> CREATE PROCEDURE TotalScore ()
-> BEGIN
-> select name, chinese + math + english as TotalScore from exam;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 3我们发现存储过程还没有写完就发生了 MySQL 的语法错误!
所以,正确过程应该是:
sql
mysql> -- 1. 修改结束标识符为//(避免与存储过程内分号冲突)
mysql> DELIMITER //
mysql>
mysql> -- 2. 创建存储过程(参数列表可选)
mysql> CREATE PROCEDURE TotalScore ()
-> BEGIN
-> select name, chinese + math + english as TotalScore from exam;
-> END //
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> -- 3. 恢复默认结束标识符
mysql> DELIMITER ;
mysql>
mysql> CALL TotalScore();
+-----------+------------+
| name | TotalScore |
+-----------+------------+
| 唐三藏 | 221.0 |
| 孙悟空 | 242.5 |
| 猪悟能 | 276.0 |
| 曹孟德 | 233.0 |
| 刘玄德 | 185.5 |
| 孙权 | 221.5 |
| 宋公明 | 170.0 |
+-----------+------------+
7 rows in set (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
mysql>过程解析
DELIMITER //:将语句结束符临时改为//,这样 MySQL 就不会把存储过程内部的;当作结束信号。- 定义存储过程
p_calAvg(),内部的SELECT ... ;不会触发执行。 END //:用//标识存储过程定义结束,MySQL 此时才会执行整个创建语句。DELIMITER ;:将结束符恢复为默认的;,不影响后续常规 SQL 语句的执行。
二、MySQL 变量:3 类变量用法
MySQL 变量分为系统变量 、用户自定义变量 、局部变量,各自作用域和用法不同,面试常考区分。
2.1 系统变量:数据库的 "配置开关"
系统变量是 MySQL 服务器的配置参数,控制服务器行为和性能,分为全局变量(GLOBAL)和会话变量(SESSION)。
查看系统变量
查看所有系统变量:
sql
SHOW [GLOBAL|SESSION] VARIABLES; -- 不指定则默认查看SESSION变量模糊查询指定系统变量(常用):
sql
SHOW GLOBAL VARIABLES LIKE 'auto%'; -- 查看以auto开头的全局变量
SHOW SESSION VARIABLES LIKE 'char%'; -- 查看以char开头的会话变量精准查询单个系统变量:
sql
SELECT @@GLOBAL.autocommit; -- 查看全局事务自动提交配置
SELECT @@SESSION.sql_mode; -- 查看当前会话的SQL模式设置系统变量
sql
-- 方式1:使用SET关键字
SET [GLOBAL|SESSION] 系统变量名 = 值;
-- 方式2:使用@@符号(仅适用于会话变量)
SET @@SESSION.autocommit = 0; -- 关闭当前会话的事务自动提交
-- 示例:开启事务自动提交(会话级别)
SET autocommit = 1; -- 不指定GLOBAL/SESSION,默认是SESSION注意:
- 会话变量仅在当前连接有效,连接关闭后失效;
- 全局变量需重启 MySQL 才能永久生效,否则重启后恢复默认值(需修改配置文件)。
MySQL 的会话变量 SESSION 就像 Linux 里当前终端执行的 export ,只对当前连接 / 当前 shell 有效,断开就消失;全局变量 GLOBAL 只对新连接生效,但重启 MySQL 就会失效 ,它不是永久配置;真正重启后还生效的,是写在 my.cnf / my.ini 里的配置,对应 Linux 中 /etc/profile 这种永久环境变量配置。
其中:MySQL 的核心配置参数涵盖了服务运行、性能、安全与高可用等关键维度:port 定义服务监听端口,basedir 指向程序安装目录,datadir 存储所有数据库与表数据,character-set-server 设定默认字符集以避免乱码;max_connections 控制最大并发连接数,wait_timeout 清理空闲连接防止资源耗尽;innodb_buffer_pool_size 是 InnoDB 引擎核心性能参数,决定内存缓存数据与索引的大小,直接影响读写效率;innodb_flush_log_at_trx_commit 平衡数据安全与性能,控制日志刷盘策略;slow_query_log 开启慢查询日志用于性能排查,default_authentication_plugin 设定登录认证方式;server-id 与 log_bin 是主从复制的基础,支撑数据同步与灾备,这些参数共同决定了 MySQL 的运行行为、性能表现与可靠性。
2.2 用户自定义变量:会话级的 "临时容器"
用户自定义变量无需提前声明,作用域为当前会话(连接关闭后失效),适合临时存储数据。
赋值方式(4 种,推荐第 2 种)
方式 1:SET + 等号(注意与比较运算符冲突,不推荐)
sql
SET @var_name = 表达式;不推荐使用 SET @var_name = 表达式 这种赋值方式,核心原因是等号 = 在 SQL 中同时承担「赋值」和「比较判断」双重作用,极易产生语法歧义 :在非赋值场景下=会被 MySQL 识别为等于比较符,而非赋值符号,会直接导致语句报错或执行不符合预期,代码可读性和稳定性极差,因此官方及工程规范都不推荐。
方式 2:SET + 冒号等号(推荐,避免冲突)
sql
SET @age := 18; -- 定义变量age并赋值18方式 3:SELECT 语句中直接赋值
sql
SELECT @total := 100 + 200; -- 计算结果赋值给total方式 4:查询结果赋值(常用)
sql
SELECT sno INTO @sno FROM student WHERE id = 1; -- 把id=1的学生学号赋值给sno使用示例
sql
-- 1. 定义并赋值
SET @count := 0;
-- 2. 接收查询结果
SELECT COUNT(*) INTO @count FROM student;
-- 3. 查看变量值
SELECT @count; -- 输出学生表总记录数
-- 未赋值的变量返回NULL
SELECT @unset_var; -- 结果为NULL2.3 局部变量:存储过程 / 函数内的 "临时变量"
局部变量仅在存储过程、函数或触发器的 BEGIN...END 块内有效,必须用 DECLARE 声明,且需指定数据类型。
声明与赋值
声明语法:
sql
DECLARE 变量名 变量类型 [DEFAULT 默认值]; -- 默认值可选,不指定则为NULL赋值方式(与用户自定义变量类似):
sql
-- 方式1:SET赋值
DECLARE stu_count INT DEFAULT 0;
SET stu_count := 10;
-- 方式2:查询结果赋值
SELECT COUNT(*) INTO stu_count FROM student;使用示例:统计学生总数
sql
DELIMITER //
CREATE PROCEDURE p1()
BEGIN
-- 声明局部变量并设默认值0
DECLARE stu_count INT DEFAULT 0;
-- 赋值:查询学生表总记录数
SELECT COUNT(*) INTO stu_count FROM student;
-- 使用变量:输出结果
SELECT stu_count;
END //
DELIMITER ;
-- 调用存储过程
CALL p1();2.4 变量使用注意事项(避坑重点)
- 变量名不区分大小写,但建议统一风格(如小写 + 下划线);
- 局部变量必须在存储过程 / 函数内声明,且需放在 BEGIN 块最前面;
- 避免使用 MySQL 保留字(如 SELECT、UPDATE)作为变量名;
- 作用域优先级:局部变量 > 用户自定义变量(同一名称时,局部变量生效)。
三、SQL 编程:条件判断、循环、游标全实战
存储过程的核心价值在于支持 SQL 编程,实现复杂逻辑。以下是高频编程语法,结合案例讲解。
3.1 条件判断:IF 语句
语法
sql
IF 条件1 THEN
语句1;
ELSEIF 条件2 THEN
语句2;
...
ELSE
语句N;
END IF; -- 必须结束IF块示例:根据分数判定等级
需求:传入分数,返回优秀(≥90)、良好(80-89)、及格(60-79)、不及格(<60)
sql
DELIMITER //
CREATE PROCEDURE p3(IN score INT, OUT result VARCHAR(10))
BEGIN
IF score >= 90 THEN
SET result := '优秀';
ELSEIF score >= 80 AND score < 90 THEN
SET result := '良好';
ELSEIF score >= 60 AND score < 80 THEN
SET result := '及格';
ELSE
SET result := '不及格';
END IF;
END //
DELIMITER ;
-- 调用:传入88分,接收结果
CALL p3(88, @result);
-- 查看结果
SELECT @result; -- 输出"良好"3.2 多条件分支:CASE 语句
CASE 语句适合多条件等值判断或范围判断,比 IF 更简洁。
两种语法
- 语法 1:等值判断(适合固定值匹配)
sql
CASE 变量/表达式
WHEN 值1 THEN 语句1;
WHEN 值2 THEN 语句2;
...
ELSE 语句N;
END CASE;- 语法 2:范围判断(适合区间匹配)
sql
CASE
WHEN 条件1 THEN 语句1;
WHEN 条件2 THEN 语句2;
...
ELSE 语句N;
END CASE;示例 1:状态码解析
需求:传入状态码,返回对应含义(0 = 成功,10001 = 用户名密码错误等)
sql
DELIMITER //
CREATE PROCEDURE p5(IN code INT, OUT result VARCHAR(50))
BEGIN
CASE code
WHEN 0 THEN SET result := '成功';
WHEN 10001 THEN SET result := '用户名或密码错误';
WHEN 10002 THEN SET result := '您没有对应的权限';
WHEN 20001 THEN SET result := '你传入的参数有误';
WHEN 20002 THEN SET result := '没有找到相应的结果';
ELSE SET result := '服务器错误,请联系管理员';
END CASE;
END //
DELIMITER ;
-- 调用:解析状态码10001
CALL p5(10001, @result);
SELECT @result; -- 输出"用户名或密码错误"示例 2:月份转季度
需求:传入月份,返回对应的季度
sql
DELIMITER //
CREATE PROCEDURE p6(IN month INT, OUT result VARCHAR(50))
BEGIN
CASE
WHEN month >= 1 AND month <= 3 THEN SET result := '第一季度';
WHEN month >= 4 AND month <= 6 THEN SET result := '第二季度';
WHEN month >= 7 AND month <= 9 THEN SET result := '第三季度';
WHEN month >= 10 AND month <= 12 THEN SET result := '第四季度';
ELSE SET result := '非法参数';
END CASE;
END //
DELIMITER ;
-- 调用:查询6月所属季度
CALL p6(6, @result);
SELECT @result; -- 输出"第二季度"3.3 循环语句:WHILE、REPEAT、LOOP
MySQL 支持 3 种循环,分别适用于不同场景,核心是控制循环的开始和结束。
WHILE 循环:先判断后执行
语法:先判断条件,条件成立才执行循环体
sql
WHILE 条件 DO
循环体语句;
END WHILE;示例:计算 1 累加到 n 的值
sql
DELIMITER //
CREATE PROCEDURE p7(IN n INT)
BEGIN
DECLARE total INT DEFAULT 0; -- 存储累加结果
WHILE n > 0 DO
SET total := total + n; -- 累加
SET n := n - 1; -- 循环变量递减
END WHILE;
SELECT total; -- 输出结果
END //
DELIMITER ;
-- 调用:计算1-100的和
CALL p7(100); -- 输出5050REPEAT 循环:先执行后判断
语法:先执行一次循环体,再判断条件,条件成立则继续循环(至少执行一次)
sql
REPEAT
循环体语句;
UNTIL 条件 -- 条件成立时退出循环
END REPEAT;示例:同样计算 1 累加到 n
sql
DELIMITER //
CREATE PROCEDURE p8(IN n INT)
BEGIN
DECLARE total INT DEFAULT 0;
REPEAT
SET total := total + n;
SET n := n - 1;
UNTIL n <= 0 END REPEAT; -- n≤0时退出
SELECT total;
END //
DELIMITER ;
-- 调用:计算1-100的和
CALL p8(100); -- 输出5050LOOP 循环:灵活控制(配合 LEAVE/ITERATE)
LOOP 是最灵活的循环,需配合标签和控制语句使用:
- LEAVE label:退出整个循环(类似 break);
- ITERATE label:跳过当前循环,进入下一次(类似 continue)。
语法:
sql
标签名: LOOP
循环体语句;
IF 退出条件 THEN
LEAVE 标签名; -- 退出循环
END IF;
IF 跳过条件 THEN
ITERATE 标签名; -- 跳过当前循环
END IF;
END LOOP 标签名;示例 1:1 累加到 n
sql
DELIMITER //
CREATE PROCEDURE p9(IN n INT)
BEGIN
DECLARE total INT DEFAULT 0;
sum_label: LOOP -- 定义循环标签
IF n <= 0 THEN
LEAVE sum_label; -- n≤0时退出循环
END IF;
SET total := total + n;
SET n := n - 1;
END LOOP sum_label;
SELECT total;
END //
DELIMITER ;
-- 调用
CALL p9(100); -- 输出5050示例 2:累加 1-n 中的偶数
sql
DELIMITER //
CREATE PROCEDURE p10(IN n INT)
BEGIN
DECLARE total INT DEFAULT 0;
sum_label: LOOP
IF n <= 0 THEN
LEAVE sum_label; -- 退出循环
END IF;
-- 奇数则跳过当前循环
IF n % 2 = 1 THEN
SET n := n - 1;
ITERATE sum_label; -- 不执行后续累加,直接进入下一次循环
END IF;
-- 偶数则累加
SET total := total + n;
SET n := n - 1;
END LOOP sum_label;
SELECT total;
END //
DELIMITER ;
-- 调用:计算1-100的偶数和
CALL p10(100); -- 输出25503.4 游标:逐行处理查询结果集
游标是数据库对象,允许在存储过程 / 函数中逐行读取查询结果集,适合需要遍历数据的场景(如批量处理、数据迁移)。
核心特点
- 只读:只能读取结果集,不能修改;
- 单向:只能向前移动,不能回退;
- 必须配合条件处理程序使用,避免遍历越界报错。
语法步骤(4 步)
- 声明变量:用于接收游标每行的数据;
- 声明游标:绑定查询语句,定义结果集;
- 打开游标:执行查询语句,生成结果集;
- 读取游标:逐行读取数据到变量;
- 关闭游标:释放资源。
sql
-- 1. 声明变量(需在游标前声明)
DECLARE 变量1 类型, 变量2 类型...;
-- 2. 声明游标
DECLARE 游标名 CURSOR FOR 查询语句;
-- 3. 打开游标
OPEN 游标名;
-- 4. 读取游标(存入变量)
FETCH 游标名 INTO 变量1, 变量2...;
-- 5. 关闭游标
CLOSE 游标名;示例:按班级查询学生并写入新表
需求:传入班级 ID,查询该班级学生信息,写入 t_student_class 表
sql
DELIMITER //
CREATE PROCEDURE p12(IN class_id INT)
BEGIN
-- 步骤1:声明变量(接收学生姓名、班级名)
DECLARE student_name VARCHAR(20);
DECLARE class_name VARCHAR(20);
DECLARE is_done BOOLEAN DEFAULT FALSE; -- 游标结束标识
-- 步骤2:声明游标(绑定查询语句)
DECLARE s_cursor CURSOR FOR
SELECT s.name, c.name
FROM student s, class c
WHERE s.class_id = c.id AND s.class_id = class_id;
-- 步骤3:声明条件处理程序(解决游标越界报错)
-- NOT FOUND表示无数据时触发,设置is_done为TRUE
DECLARE CONTINUE HANDLER FOR NOT FOUND SET is_done := TRUE;
-- 步骤4:创建目标表(存在则删除重建)
DROP TABLE IF EXISTS t_student_class;
CREATE TABLE IF NOT EXISTS t_student_class (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
student_name VARCHAR(20),
class_name VARCHAR(20)
);
-- 步骤5:打开游标
OPEN s_cursor;
-- 步骤6:遍历游标(循环读取)
read_loop: LOOP
-- 读取当前行数据到变量
FETCH s_cursor INTO student_name, class_name;
-- 无数据时退出循环
IF is_done THEN
LEAVE read_loop;
END IF;
-- 写入新表
INSERT INTO t_student_class VALUES (NULL, student_name, class_name);
END LOOP read_loop;
-- 步骤7:关闭游标
CLOSE s_cursor;
END //
DELIMITER ;
-- 调用:查询class_id=1的学生并写入新表
CALL p12(1);
-- 查看结果
SELECT * FROM t_student_class;关键说明 :条件处理程序(DECLARE CONTINUE HANDLER FOR NOT FOUND)是必选项,否则游标遍历完所有数据后继续读取会报错(ERROR 1329)。
3.5 条件处理程序:处理异常的 "安全网"
条件处理程序用于定义存储过程 / 函数中遇到警告或错误时的处理方式,避免程序异常终止,提升代码健壮性。
语法
sql
DECLARE 处理方式 HANDLER FOR 异常类型 [, 异常类型...]
处理语句;核心参数说明
处理方式:
- CONTINUE:继续执行后续程序;
- EXIT:终止当前程序(默认)。
异常类型:
- mysql_error_code:具体错误码(如 1062 表示主键冲突);
- SQLSTATE VALUE 状态码:如 '23000' 表示约束冲突;
- SQLWARNING:所有以 01 开头的 SQLSTATE 代码(警告);
- NOT FOUND:所有以 02 开头的 SQLSTATE 代码(无数据);
- SQLEXCEPTION:未被 SQLWARNING 或 NOT FOUND 捕获的其他错误。
常用示例
捕获无数据异常(游标遍历常用):
sql
DECLARE CONTINUE HANDLER FOR NOT FOUND SET is_done := TRUE;捕获主键冲突错误,输出提示:
sql
DECLARE EXIT HANDLER FOR 1062
SELECT '主键冲突,插入失败' AS error_msg;3.6 存储函数:有返回值的存储过程
存储函数是特殊的存储过程,必须有返回值,参数只能是 IN 类型(默认,无需显式声明),可直接作为函数在 SELECT 语句中使用。
语法(MySQL 8.0+)
sql
DELIMITER //
CREATE FUNCTION 函数名 ([参数名 参数类型])
RETURNS 返回值类型 [特性选项] -- 特性选项在binlog开启时必选
BEGIN
-- 函数逻辑
变量声明;
业务语句;
RETURN 返回值; -- 必须有RETURN语句
END //
DELIMITER ;特性选项(binlog 开启时必选)
- DETERMINISTIC:相同输入参数始终返回相同结果;
- NO SQL:函数中不包含 SQL 语句;
- READS SQL DATA:函数中包含读取数据的 SQL(如 SELECT);
- MODIFIES SQL DATA:函数中包含修改数据的 SQL(如 INSERT、UPDATE)。
示例:计算 1 累加到 n 的和
sql
DELIMITER //
CREATE FUNCTION fun1(n INT)
RETURNS INT DETERMINISTIC -- 声明为确定性函数(binlog开启时必填)
BEGIN
DECLARE total INT DEFAULT 0;
WHILE n > 0 DO
SET total := total + n;
SET n := n - 1;
END WHILE;
RETURN total; -- 返回累加结果
END //
DELIMITER ;
-- 调用:直接在SELECT中使用
SELECT fun1(100); -- 输出5050
SELECT name, fun1(score) AS total FROM student; -- 结合表数据使用存储函数与存储过程的区别(面试必考)
| 对比项 | 存储函数 | 存储过程 |
|---|---|---|
| 返回值 | 必须有返回值(通过 RETURN) | 可选(可通过 OUT/INOUT 参数返回) |
| 参数类型 | 只能是 IN 类型(默认,无需声明) | 支持 IN、OUT、INOUT 三种类型 |
| 调用方式 | 可在 SELECT 语句中直接使用 | 必须用 CALL 语句调用 |
| 特性选项 | binlog 开启时需指定特性(如 DETERMINISTIC) | 无需指定特性选项 |
| 适用场景 | 简单计算、数据转换(需返回单个值) | 复杂业务逻辑、多语句执行、事务处理 |
四、触发器:自动执行的 "数据库监听器"
4.1 什么是触发器?
触发器是与表关联的数据库对象,当对表执行 INSERT、UPDATE、DELETE 操作时,会自动触发并执行预设的 SQL 语句。
核心作用:实现数据同步、日志记录、数据验证等自动化逻辑,无需手动调用。
4.2 核心概念
触发器类型【根据触发事件分为 3 类】:
- INSERT 触发器:插入数据时触发;
- UPDATE 触发器:修改数据时触发;
- DELETE 触发器:删除数据时触发。
触发时间
- BEFORE:在 INSERT/UPDATE/DELETE 操作执行前触发(适合数据验证);
- AFTER:在操作执行后触发(适合日志记录、数据同步)。
OLD 与 NEW 关键字
用于引用触发事件中变化的数据:
| 触发器类型 | OLD(旧数据) | NEW(新数据) |
|---|---|---|
| INSERT | 无(无旧数据) | 将要 / 已经插入的数据 |
| UPDATE | 修改前的数据 | 将要 / 已经修改的数据 |
| DELETE | 将要 / 已经删除的数据 | 无(无新数据) |
行级与语句级触发器
- 行级触发器:对表中每一行数据操作时都触发(如 UPDATE 语句影响 10 行,触发 10 次);
- 语句级触发器:整个 SQL 语句执行时只触发一次(无论影响多少行);
- MySQL 仅支持行级触发器 (FOR EACH ROW)。
4.3 核心语法
创建触发器
sql
DELIMITER //
CREATE TRIGGER [IF NOT EXISTS] 触发器名
触发时间(BEFORE/AFTER) 触发事件(INSERT/UPDATE/DELETE)
ON 表名 FOR EACH ROW -- 行级触发器(MySQL必选)
BEGIN
触发执行的SQL语句; -- 可包含多句
END //
DELIMITER ;查看触发器
sql
SHOW TRIGGERS; -- 查看当前数据库所有触发器删除触发器
sql
DROP TRIGGER [IF EXISTS] [数据库名.]触发器名; -- 不指定数据库则默认当前库4.4 实战案例:学生表变更日志记录
需求:创建触发器,自动记录 student 表的 INSERT/UPDATE/DELETE 操作日志,包含操作类型、时间、数据变更前后的值。
步骤 1:创建日志表
sql
CREATE TABLE student_log (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
operation_type VARCHAR(10) NOT NULL COMMENT '操作类型:insert/update/delete',
operation_time DATETIME NOT NULL COMMENT '操作时间',
operation_id BIGINT NOT NULL COMMENT '操作的记录ID',
operation_data VARCHAR(500) COMMENT '操作数据(旧数据|新数据)'
);步骤 2:创建 INSERT 触发器(记录新增数据)
sql
DELIMITER //
CREATE TRIGGER trg_student_insert
AFTER INSERT ON student FOR EACH ROW
BEGIN
INSERT INTO student_log (
operation_type,
operation_time,
operation_id,
operation_data
) VALUES (
'insert',
NOW(), -- 当前时间
NEW.id, -- 新增记录的ID
-- 拼接新增数据的所有字段
CONCAT(NEW.id, ',', NEW.name, ',', NEW.sno, ',', NEW.age, ',', NEW.gender, ',', NEW.enroll_date, ',', NEW.class_id)
);
END //
DELIMITER ;步骤 3:创建 UPDATE 触发器(记录修改前后数据)
sql
DELIMITER //
CREATE TRIGGER trg_student_update
AFTER UPDATE ON student FOR EACH ROW
BEGIN
INSERT INTO student_log (
operation_type,
operation_time,
operation_id,
operation_data
) VALUES (
'update',
NOW(),
NEW.id, -- 修改后记录的ID(与旧ID一致)
-- 拼接旧数据和新数据,用|分隔
CONCAT(
OLD.id, ',', OLD.name, ',', OLD.sno, ',', OLD.age, ',', OLD.gender, ',', OLD.enroll_date, ',', OLD.class_id,
'|',
NEW.id, ',', NEW.name, ',', NEW.sno, ',', NEW.age, ',', NEW.gender, ',', NEW.enroll_date, ',', NEW.class_id
)
);
END //
DELIMITER ;步骤 4:创建 DELETE 触发器(记录删除数据)
sql
DELIMITER //
CREATE TRIGGER trg_student_delete
AFTER DELETE ON student FOR EACH ROW
BEGIN
INSERT INTO student_log (
operation_type,
operation_time,
operation_id,
operation_data
) VALUES (
'delete',
NOW(),
OLD.id, -- 删除记录的ID
-- 拼接删除的数据
CONCAT(OLD.id, ',', OLD.name, ',', OLD.sno, ',', OLD.age, ',', OLD.gender, ',', OLD.enroll_date, ',', OLD.class_id)
);
END //
DELIMITER ;步骤 5:测试触发器
sql
-- 1. 插入数据(触发INSERT触发器)
INSERT INTO student VALUES (NULL, '曹操', '300001', 28, 1, '2024-09-01', 3);
-- 2. 修改数据(触发UPDATE触发器)
UPDATE student SET age = 20, class_id = 2 WHERE name = '曹操';
-- 3. 删除数据(触发DELETE触发器)
DELETE FROM student WHERE name = '曹操';
-- 查看日志表
SELECT * FROM student_log;日志表结果示例:
| id | operation_type | operation_time | operation_id | operation_data | |
|---|---|---|---|---|---|
| 1 | insert | 2024-09-19 11:38:25 | 13 | 13, 曹操,300001,28,1,2024-09-01,3 | |
| 2 | update | 2024-09-19 11:47:21 | 13 | 13, 曹操,300001,28,1,2024-09-01,3 | 13, 曹操,300001,20,1,2024-09-01,2 |
| 3 | delete | 2024-09-19 11:56:10 | 13 | 13, 曹操,300001,20,1,2024-09-01,2 |
五、面试高频题汇总(含答案)
**存储过程的作用是什么?**答:封装复杂 SQL 逻辑,实现代码复用;提升执行效率(编译后存储);增强安全性(限制直接访问表);简化事务管理;降低应用程序与数据库的耦合。
**MySQL 中的变量有哪几种?区别是什么?**答:分为系统变量(全局 / 会话,控制数据库配置)、用户自定义变量(会话级,无需声明)、局部变量(存储过程 / 函数内,需 DECLARE 声明,作用域仅限块内)。
**存储函数与存储过程的核心区别?**答:存储函数必须有返回值,参数只能是 IN 类型,可在 SELECT 中调用;存储过程可选返回值(通过 OUT 参数),支持三种参数类型,必须用 CALL 调用。
**触发器的使用场景有哪些?**答:数据日志记录(如操作审计);数据同步(如主表更新后同步从表);数据验证(如插入前校验字段合法性);自动计算(如更新订单后自动修改库存)。
**行级触发器与语句级触发器的区别?**答:行级触发器对每一行数据操作都触发(影响 n 行触发 n 次),支持访问 OLD/NEW 数据;语句级触发器对整个 SQL 语句触发一次(无论影响多少行)。MySQL 仅支持行级触发器。
如何查看数据库中创建的存储过程 / 触发器? 答:查看存储过程:SHOW CREATE PROCEDURE 存储过程名; 或 SELECT * FROM information_schema.ROUTINES WHERE ROUTINE_SCHEMA='数据库名';;查看触发器:SHOW TRIGGERS;。
**游标的作用是什么?使用步骤?**答:作用是逐行读取查询结果集,适合遍历数据批量处理。步骤:声明变量→声明游标→打开游标→读取游标→关闭游标→配合条件处理程序避免越界。
六、总结
本文覆盖了 MySQL 存储过程和触发器的全部核心知识点,从基础概念、语法规则到实战案例,再到面试高频题,确保内容不遗漏且通俗易懂。关键要点如下:
- 存储过程:封装 SQL 逻辑,提升复用性和安全性,核心掌握创建、调用、变量和流程控制;
- 变量:区分三类变量的作用域和用法,避免使用误区;
- SQL 编程:灵活运用条件判断、循环、游标和条件处理程序,实现复杂逻辑;
- 触发器:自动响应表操作,适合日志、同步等场景,掌握 OLD/NEW 关键字和三种触发类型。
建议结合本文案例动手实操,尤其是存储过程的循环、游标和触发器的日志记录案例,实际操作后能更快掌握核心用法。