前言
本文是我近期学习MCP相关的知识并结合AI整理总结而来,一是为了记录,二是用于日后的回顾,三也是希望能其给他初学者带来一点点帮助。
目录
[MCP Host](#MCP Host)
[MCP Client](#MCP Client)
[MCP Server](#MCP Server)
[MCP与Function Calling的区别](#MCP与Function Calling的区别)
在大模型应用越来越普及之后,一个问题变得越来越明显:模型本身很强,但它和外部世界之间的连接方式并不统一。
MCP,正是在这样的背景下出现的。
什么是MCP
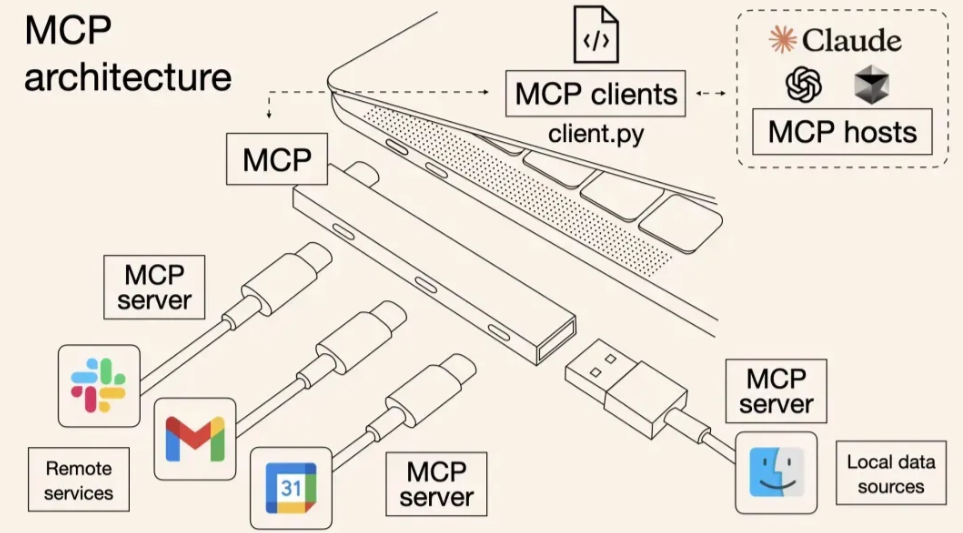
MCP,中文一般翻译为模型上下文协议。它是一个开放协议,目的是为大模型应用与外部数据源、工具、工作流之间的连接提供统一标准。只要双方都遵循 MCP,就能以更标准化的方式进行连接。
简单来说,MCP 解决的是这样一个问题:
如何让 AI 不仅会说,还能够标准化地获取上下文和调用外部能力。
它并不是某一个具体的模型,也不是某一家公司的专属框架,而更像一套协议规范。只要一个 AI 客户端支持 MCP,它就可以接入不同的 MCP Server;只要一个外部系统实现成 MCP Server,它就能被不同的 AI 应用复用。
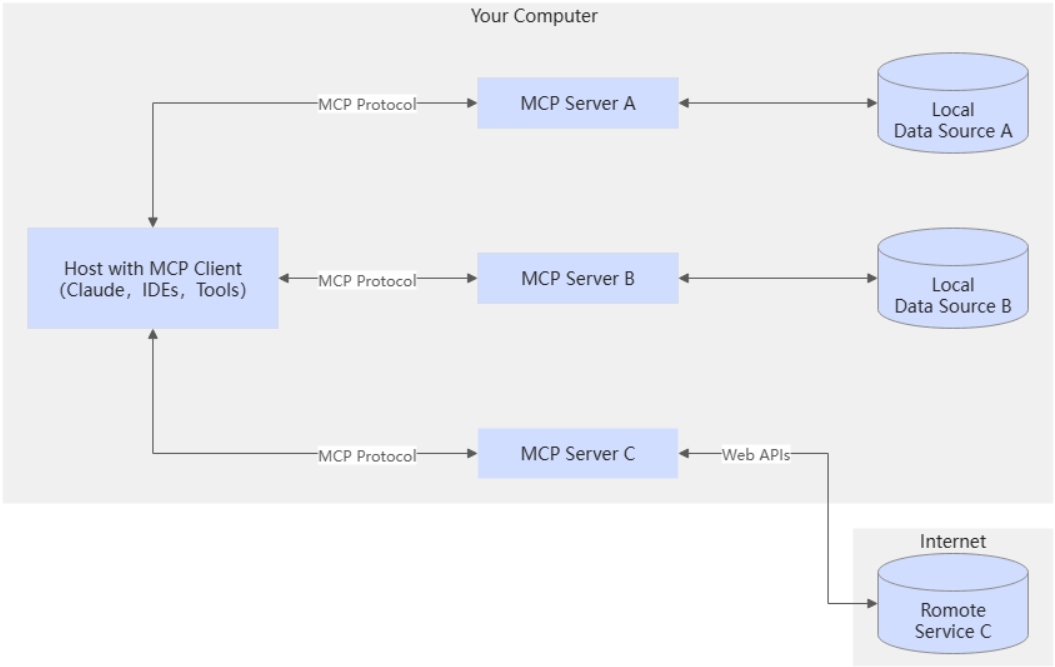
MCP的核心架构
MCP Host
MCP Host 就是承载大模型能力的宿主程序,也可以理解为用户真正接触到的 AI 应用。
比如 Claude Desktop、Cursor、一些带 AI 能力的 IDE,或者其他智能助手类产品,都可以看作 MCP Host。
它主要负责几件事:
- 接收用户输入
- 触发模型处理任务
- 在内部调用 MCP Client
- 把最终结果返回给用户
所以 Host 更像是整个 MCP 体系的入口,用户并不会直接接触到底层 Server,而是先通过 Host 发起请求。
MCP Client
MCP Client 位于 Host 内部,主要作用是负责和 MCP Server 建立连接,并完成双方之间的通信。
它相当于大模型和外部能力之间的桥梁。
通常情况下,一个 MCP Client 会和一个 MCP Server 保持 1:1 的连接关系。Client 不负责业务逻辑本身,它更像一个协调者,负责把用户请求、模型决策和服务调用串起来。
它的大致工作流程可以概括为下面几步:
- 先从 MCP Server 获取当前可用的工具、资源和提示信息
- 再把用户的问题和这些能力描述一起交给大模型
- 由大模型判断当前是否需要调用工具
- 如果需要,Client 就向 MCP Server 发起对应调用
- Server 返回结果后,Client 再把结果交回给模型
- 最后由模型生成自然语言结果,展示给用户
也就是说,MCP Client 本身并不提供能力,它主要负责连接、转发、执行、回传这一整套过程。
从实际落地来看,很多支持 MCP 的产品,本质上都内置了 MCP Client。比如 Claude Desktop 和 Cursor,它们能够接入各种 MCP Server,本质上就是因为内部具备这层能力。
MCP Server
MCP Server 是整个架构里真正提供能力的一端。
它负责向 Client 暴露可用的资源、工具以及提示模板,让大模型在需要的时候可以调用。
从功能上看,MCP Server 主要可以提供三类内容:
- 资源:类似文件的数据,可以被客户端读取,如 API 响应或文件内容。
- 工具:可以被 LLM 调用的函数。
- 提示:预先编写的模板,帮助用户完成特定任务。
MCP的工作原理
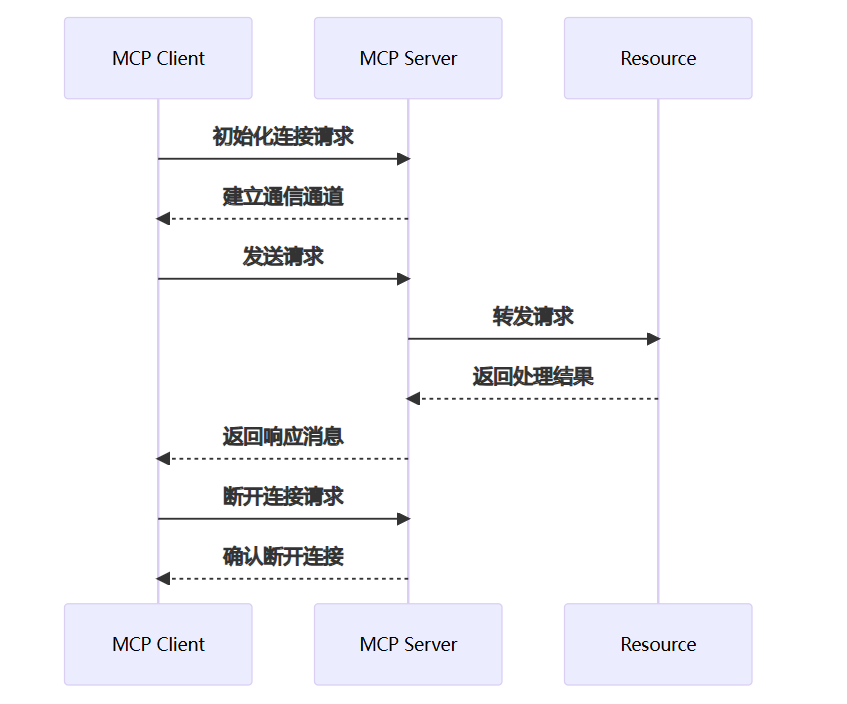
1. 初始化连接
客户端首先会向服务器发起连接请求,用来建立双方之间的通信通道。
只有连接建立完成之后,后续的请求和响应才能正常进行。
2. 发送请求
当用户发出指令,或者模型判断需要调用某种外部能力时,客户端就会按照协议格式构建请求消息,并将其发送给服务器。
这个请求里通常会包含操作类型、参数信息以及目标资源等内容。
3. 处理请求
服务器接收到请求之后,会先解析请求内容,再根据具体需求执行对应操作。比如有的请求是读取本地文件,有的是查询数据库,还有的可能是调用某个远程 API。也就是说,Server 本身更像一个统一调度层,负责把请求分发到真正的资源侧去执行。
4. 返回结果
当请求处理完成后,服务器会把结果按照统一格式封装成响应消息,再返回给客户端。客户端拿到这些结果之后,可以继续交给大模型进行理解、总结和生成,最后输出成自然语言内容。
5. 断开连接
等当前任务执行完成之后,客户端可以选择主动断开连接;如果没有继续通信,服务器也可以在超时后自动关闭连接。这样做有助于释放资源,也方便管理整个通信生命周期。
MCP与Function Calling的区别
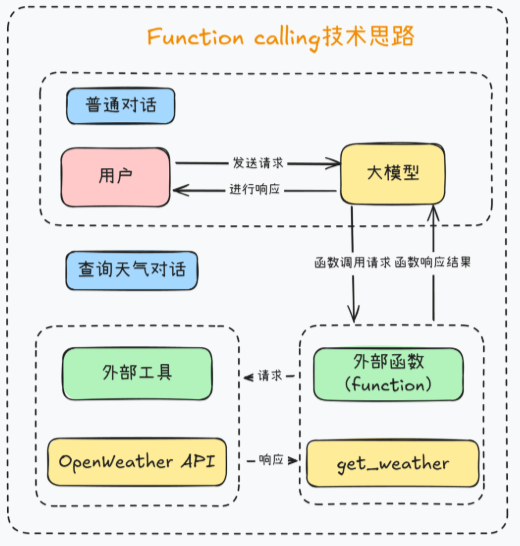
Function Calling 和 MCP 都是在解决大模型调用外部工具的问题,但两者的定位并不一样。Function Calling 更像是一种具体的工具调用机制,重点在于让大模型判断当前是否需要调用某个函数,并返回对应参数来完成单次任务。它实现起来相对直接,但通常更依赖模型本身具备稳定的工具调用能力,而且很多时候缺少统一标准,往往需要跟着厂商接口或者自己做适配,扩展到多个工具、多个系统时,定制化成本会比较高。相比之下,MCP 更像是一套统一的连接协议,不只是管工具调用,还把资源访问、提示模板、上下文传递这些能力一起纳入进来,让大模型和外部服务之间的交互方式更标准化。
从使用场景来看,Function Calling 更适合简单、明确的单步调用场景,比如调用某个函数查一次天气、查一次订单,重点是把这一次任务执行完;而 MCP 更适合更复杂的系统接入场景,它可以统一连接不同的工具和数据源,也更方便支撑多轮对话、组合调用和后续扩展。你也可以把两者理解成:Function Calling 解决的是"模型怎么调用某个函数",而 MCP 解决的是"模型怎么用统一方式接入外部世界"。所以前者更偏具体能力,后者更偏底层协议和生态组织能力,在项目规模变大、工具变多之后,MCP 的优势通常会更明显。
代码示例
java
@Slf4j
public abstract class BaseMcpService {
protected final WebClient webClient;
protected final ObjectMapper objectMapper;
protected final int timeout;
protected BaseMcpService(String serverUrl, int timeout) {
this.timeout = timeout;
this.objectMapper = new ObjectMapper();
if (serverUrl != null && !serverUrl.isBlank()) {
this.webClient = WebClient.builder()
.baseUrl(serverUrl)
.codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(10 * 1024 * 1024))
.build();
} else {
this.webClient = null;
}
}
protected boolean isServerAvailable() {
return webClient != null;
}
protected Mono<Map> callTool(String toolName, Map<String, Object> arguments) {
if (!isServerAvailable()) {
log.warn("MCP server not available for tool: {}", toolName);
return Mono.empty();
}
Map<String, Object> request = Map.of(
"jsonrpc", "2.0",
"method", "tools/call",
"params", Map.of(
"name", toolName,
"arguments", arguments
)
);
return webClient.post()
.uri("/mcp")
.bodyValue(request)
.retrieve()
.bodyToMono(Map.class)
.timeout(Duration.ofSeconds(timeout))
.doOnError(e -> log.error("Error calling MCP tool {}: {}", toolName, e.getMessage()));
}
protected Mono<Map> listTools() {
if (!isServerAvailable()) {
return Mono.empty();
}
Map<String, Object> request = Map.of(
"jsonrpc", "2.0",
"method", "tools/list"
);
return webClient.post()
.uri("/mcp")
.bodyValue(request)
.retrieve()
.bodyToMono(Map.class)
.timeout(Duration.ofSeconds(timeout));
}
public abstract String getServiceName();
public abstract boolean isEnabled();
}
java
public SearchResult search(String query, int maxResults) {
log.info("Tavily MCP search for: {}", query);
if (!isEnabled()) {
log.warn("Tavily MCP is disabled");
return SearchResult.empty("Tavily MCP is disabled");
}
if (!isServerAvailable()) {
log.info("Tavily MCP server not available, using direct API");
return searchDirect(query, maxResults);
}
try {
Map<String, Object> arguments = new HashMap<>();
arguments.put("query", query);
arguments.put("max_results", maxResults);
if (apiKey != null && !apiKey.isBlank()) {
arguments.put("api_key", apiKey);
}
Map result = callTool("tavily-search", arguments)
.block(Duration.ofSeconds(timeout));
return parseSearchResult(result);
} catch (Exception e) {
log.error("Tavily MCP search failed: {}", e.getMessage());
return searchDirect(query, maxResults);
}
}上述是我的深度搜索个人项目里面使用到的MCP部分代码。
具体流程是,我先抽了一个 BaseMcpService,把所有 MCP 相关的公共逻辑都放进去,比如 WebClient 初始化、超时控制,还有 JSON-RPC 请求的封装。这样后面不管接 Tavily、Jina 还是 Obsidian,都走同一套调用方式,代码会比较整齐。
使用的时候,我是按工具类型分别封装服务的。比如要做网页搜索,就走 TavilyMcpService;要读取网页正文,就走 JinaMcpService;研究完成后要把内容存进知识库,就走 ObsidianMcpService。本质上都是后端主动发 tools/call 请求,只是调用的 tool name 不一样,比如 tavily-search、jina-read、obsidian-create-note。
上述内容也同步在我的飞书,欢迎访问
https://my.feishu.cn/wiki/QLauws6lWif1pnkhB8IcAvkhncc?from=from_copylink
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,你们的支持就是我坚持下去的动力!