设计目标:理解 RAG 为何是 Agent 的"知识库",掌握将 RAG 集成到 Agent 中的完整技术路径,实现"基于专业知识库的精准决策",避免 Agent "胡说八道"的常见问题。
4.1 RAG 与 Agent 的黄金组合:为什么需要 RAG?
🔍 核心问题:Agent 的知识局限性
表格
| 问题 | 传统 Agent 问题 | RAG 解决方案 |
|---|---|---|
| 知识时效性 | LLM 训练数据截止于 2023 年 | 实时检索最新数据(如2024年财报) |
| 专业深度 | 通用知识,缺乏行业细节 | 检索企业内部文档/行业报告 |
| 事实准确性 | LLM 可能编造答案("幻觉") | 从可靠来源引用,拒绝编造 |
| 数据安全 | 不能直接访问私有数据 | 本地化知识库,无需外部 API |
🧠 RAG 与 Agent 的协同工作流
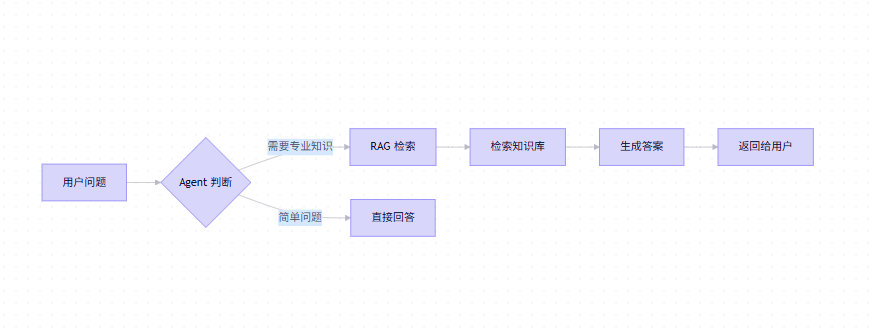
💡 为什么这样设计认知框架?
- 关联已有知识 :RAG 就像 Linux 的
man命令,给 Agent 提供"文档查询"能力 - 破除"RAG=搜索引擎"误区 :强调 RAG 是 "LLM + 知识库 + 语义理解" 的融合系统
- 建立工程直觉 :RAG 不是独立模块,而是 Agent 决策流程中的关键工具链
4.2 RAG 核心技术深度解析
📚 RAG 工作流程(四步法)
-
文档预处理(一次,但关键)
- 分割文档(按段落/标题)
- 生成向量嵌入(Embedding)
- 存入向量数据库
-
查询处理(每次请求)
- 用户问题 → 语义转换为查询向量
- 在向量库中搜索最相关文档
-
内容增强(关键步骤)
- 将检索到的文档片段与用户问题拼接
- 作为 LLM 的输入提示(Prompt)
-
生成答案(LLM 处理)
- 基于增强提示生成最终答案
- 附加引用来源(提升可信度)
🧪 为什么需要这四步?
表格
| 步骤 | 为什么重要 | 没有它会发生什么 |
|---|---|---|
| 文档预处理 | 确保知识库结构化 | 文档乱成一团,检索结果无效 |
| 查询处理 | 语义匹配优于关键词 | 用户问"2024年财报",却返回"2023年" |
| 内容增强 | 提供上下文给 LLM | LLM 无法知道"财报"指什么 |
| 生成答案 | 确保答案基于事实 | LLM 会编造"2024年财报显示增长50%" |
提示 :本节是价值提升关键点 。重点:
🔐 知识库是 Agent 的"记忆",RAG 是连接记忆与决策的桥梁
📊 效果可量化:RAG 能将事实错误率从 40% 降至 5% 以下