摘要 :本文基于 Qwen2 Technical Report(arXiv:2407.10671),在 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍、Decoder Only Transformer 与 LLaMA 架构 的叙述框架下,说明 Qwen2 的 Tokenizer、稠密模型结构(全系列 GQA 、SwiGLU / RoPE / RMSNorm / Pre-Norm / QKV bias )、长上下文(RoPE 基频、YARN、Dual Chunk Attention) 、按规模变化的 Embedding 绑权策略 ,以及 MoE 变体(细粒度专家、共享专家 + 路由专家) 的公式与数据流。读者宜先读 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍 再读本篇。
关键词:Qwen2;GQA;YARN;Dual Chunk Attention;RoPE;SwiGLU;RMSNorm;MoE;长上下文;大语言模型
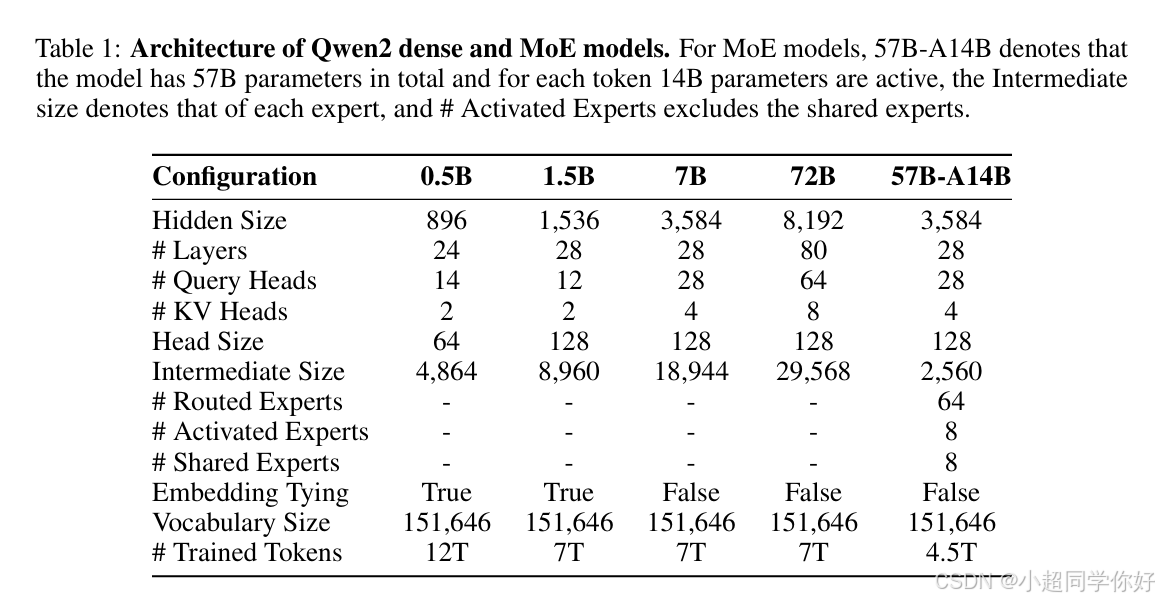
💡 理解要点 :Qwen2 仍是 Decoder-only Transformer ,骨干与 Qwen 1 一脉相承(Pre-Norm + RMSNorm + RoPE + SwiGLU + QKV bias ),但报告强调的结构性变化 主要有四方面:(1) 稠密模型全面采用 GQA (不再以 MHA 为默认);(2) 长上下文训练到 32K,配合 RoPE 基频 10 4 → 10 6 10^4\to 10^6 104→106、YARN 与 DCA,可扩展到约 128K ;(3) 小模型(0.5B/1.5B)启用 Embedding Tying,7B/72B/MoE 不绑权 ;(4) 提供 MoE 型号(57B 总参、每 token 激活约 14B) 。FFN 中间维 不再沿用 Qwen1 报告中的 8 3 d \frac{8}{3}d 38d 统一比例,而以表 1 的 Intermediate Size 为准。
1. 概述:Qwen2 在系列中的位置
Qwen2 Technical Report 将 Qwen2 定位为在 Transformer + 因果自注意力 上的新一代开源系列:包含 0.5B、1.5B、7B、72B 四个稠密 模型,以及 57B-A14B(MoE,每 token 激活约 14B) 等。预训练数据规模提升至 7T tokens 量级(0.5B 使用 12T 实验管线;MoE 另有 4.5T 等设定,见报告表 1),后训练采用 SFT + DPO 等偏好对齐。
与 Qwen 1 相比:Qwen2 默认 GQA 、长上下文与 RoPE/YARN/DCA 的训练期 方案更系统,并明确给出 MoE 路由与专家设计。
🔍 实际例子(Qwen2-7B,报告表 1) :Hidden size 3584 ,层数 28 ,Query heads = 28 ,KV heads = 4 ,Head size 128 ,故 d k = 128 d_k=128 dk=128, d model = 3584 d_{\text{model}}=3584 dmodel=3584。单序列长度 L = 4096 L=4096 L=4096 时,每层主路径张量仍为 L × 3584 L\times 3584 L×3584 ;但 KV Cache 只随 4 个 KV 头 增长,而非 28。
2. Tokenizer 与词表
报告 §2.1 说明:Tokenizer 与 Qwen(Bai et al., 2023a) 一致,为 byte-level BPE ,强调压缩率与多语效率。
- 词表 :151,643 个常规 token + 3 个控制 token → 合计 151,646(表 1 中 Vocabulary Size)。
- 分布式训练 :文中指出因分布式实现,Embedding 实际占用维度可能大于词表行数(padding 对齐),属工程细节。
💡 与 Qwen 1 对比 :Qwen1 报告给出约 152K 量级词表;Qwen2 在报告中写为 151,646 固定配置,全体尺寸共用同一套词表。
3. 进入 Decoder 的嵌入与「绑权」(Weight Tying)
本节说明:词嵌入如何把 token 变成向量 、最后一层如何变成词表 logits 、以及 「绑权」在数学上指什么;Qwen2 各尺寸是否绑权以报告表 1 为准。
3.1 词嵌入与输入矩阵 X X X
Qwen2 词表大小记为 V V V(报告中为 151646,即 151643 个常规 token 与 3 个控制 token 之和)。嵌入矩阵
E ∈ R V × d model . E \in \mathbb{R}^{V \times d_{\text{model}}}. E∈RV×dmodel.
第 i i i 个位置的 token ID 为 w i w_i wi。将 E E E 的第 w i w_i wi 行 (长度为 d model d_{\text{model}} dmodel 的行向量)转置为列向量 ,记为 e w i \mathbf{e}_{w_i} ewi,则
e w i = E w i , : ⊤ ∈ R d model . \mathbf{e}{w_i} = Ew_i,\\,:^\top \in \mathbb{R}^{d{\text{model}}}. ewi=Ewi,:⊤∈Rdmodel.
整段序列共 L L L 个位置,按行堆叠成送入第一层 Decoder 的矩阵:
X = e w 0 ⊤ ⋮ e w L − 1 ⊤ ∈ R L × d model . X = \begin{bmatrix} \mathbf{e}{w_0}^\top \\ \vdots \\ \mathbf{e}{w_{L-1}}^\top \end{bmatrix} \in \mathbb{R}^{L \times d_{\text{model}}}. X= ew0⊤⋮ewL−1⊤ ∈RL×dmodel.
(与「逐行是 e w i ⊤ \mathbf{e}{w_i}^\top ewi⊤」的写法等价,仅强调 e w i \mathbf{e}{w_i} ewi 为列向量,避免「 E w i Ew_i Ewi 是行还是列」歧义。)
3.2 最后一层输出:从 h \mathbf{h} h 到 logits
预测下一个 token 时,取最后一层输出矩阵 H ∈ R L × d model H \in \mathbb{R}^{L \times d_{\text{model}}} H∈RL×dmodel 的最后一个位置,得到列向量
h = H L − 1 , : ⊤ ∈ R d model . \mathbf{h} = HL-1,\\,:^\top \in \mathbb{R}^{d_{\text{model}}}. h=HL−1,:⊤∈Rdmodel.
未绑权(untied) 时,单独有可学习矩阵 W out ∈ R d model × V W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} Wout∈Rdmodel×V 与可选偏置 b out ∈ R V \mathbf{b}_{\text{out}} \in \mathbb{R}^V bout∈RV,logits 列向量 s ∈ R V \mathbf{s} \in \mathbb{R}^V s∈RV 为
s = W out ⊤ h + b out . \mathbf{s} = W_{\text{out}}^\top \mathbf{h} + \mathbf{b}_{\text{out}}. s=Wout⊤h+bout.
等价地( h ⊤ \mathbf{h}^\top h⊤ 为 1 × d model 1 \times d_{\text{model}} 1×dmodel):
s ⊤ = h ⊤ W out + b out ⊤ . \mathbf{s}^\top = \mathbf{h}^\top W_{\text{out}} + \mathbf{b}_{\text{out}}^\top. s⊤=h⊤Wout+bout⊤.
下一 token 分布为 P = s o f t m a x ( s ) P = \mathrm{softmax}(\mathbf{s}) P=softmax(s)。这里的 W out W_{\text{out}} Wout 专指整个模型栈末尾、接词表的那一层线性映射,与中间各层的输出无关。
3.3 「绑权」是什么
绑权(weight tying / tied embedding):令
W out = E ⊤ , W_{\text{out}} = E^\top, Wout=E⊤,
即 输出线性层与嵌入矩阵共用参数 (不再单独存放 W out W_{\text{out}} Wout)。此时第 w w w 个 logit 为
s w = h ⊤ e w + ( b out ) w , s_w = \mathbf{h}^\top \mathbf{e}w + (b{\text{out}})_w, sw=h⊤ew+(bout)w,
也就是 当前上下文表示 h \mathbf{h} h 与 该词嵌入向量 e w \mathbf{e}_w ew 的内积 (再加 bias),与「输入端用来表示词 w w w 的向量」同一套方向。
💡 理解要点 :绑权 = 强制 「输入:词 → 向量」与「输出:向量 → 各词分数」在词表维上共享 同一组 V V V 个 d model d_{\text{model}} dmodel 维方向;省约一整块 d model × V d_{\text{model}} \times V dmodel×V 的输出权重,并带来更强归纳偏置。实证上 Press & Wolf (2017) 等工作表明 tying 常能改进困惑度;模型变大后 untied 有时更灵活,故 Qwen2 按规模切换策略。
3.4 Qwen2 是否绑权(报告表 1)
| 模型 | Embedding Tying |
|---|---|
| Qwen2-0.5B | True |
| Qwen2-1.5B | True |
| Qwen2-7B | False |
| Qwen2-72B | False |
| Qwen2-57B-A14B (MoE) | False |
小结 :0.5B / 1.5B 偏部署与参数预算,用 tied ;7B / 72B / MoE 用 untied,与 Qwen 1 报告对大规模模型「不绑权以换表现」的取向一致 来源:Qwen2 Technical Report 表 1;Qwen1 arXiv:2309.16609 §2.3。
3.5 位置编码(与嵌入的关系)
本节说明:送入第一层的 X X X 是否已含绝对位置 、以及 Qwen2 与经典 Decoder-only / LLaMA / Qwen 1 在位置注入上的同异。与 §3.1 衔接: X X X 仅由词嵌入堆叠而成;长上下文上的 RoPE 基频、YARN、DCA 另见 §5。
3.5.1 经典做法:与词嵌入相加的绝对位置
在 Decoder Only Transformer 一类经典 Decoder-only 叙述中,位置编码常在 Embedding 之后、进第一层之前 只做一次 :每个位置 p o s pos pos 取向量 P E ( p o s ) ∈ R d model \mathrm{PE}(pos)\in\mathbb{R}^{d_{\text{model}}} PE(pos)∈Rdmodel(正弦/余弦或可学习),与词嵌入相加:
I n p u t p o s = E m b e d p o s + P E ( p o s ) . \mathrm{Input}pos = \mathrm{Embed}pos + \mathrm{PE}(pos). Inputpos=Embedpos+PE(pos).
正弦形式常用( i i i 为维度下标):
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d model ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d model ) . \mathrm{PE}{(pos,\,2i)} = \sin\Big(\frac{pos}{10000^{2i/d{\text{model}}}}\Big), \quad \mathrm{PE}{(pos,\,2i+1)} = \cos\Big(\frac{pos}{10000^{2i/d{\text{model}}}}\Big). PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos).
此时 进入第一层的矩阵已混合语义与绝对位置。
3.5.2 Qwen2(及 LLaMA / Qwen 1):RoPE 旋 Q、K
不在 X X X 上做「词嵌入 + 绝对位置向量」相加;送入第一层的 X X X 仅为 §3.1 的嵌入 (无额外位置向量项)。位置信息在 每一层 、计算注意力分数 之前 ,对当前层的 Query、Key (按位置、按维度对)施加 旋转 (RoPE)。记第 p o s pos pos 行经旋转后的向量为 Q ′ p o s , K ′ p o s Q'pos,\,K'pos Q′pos,K′pos,则注意力 logits 仍写为
S i j = Q ′ i ⋅ K ′ j d k . S_{ij} = \frac{Q'i \cdot K'j}{\sqrt{d_k}}. Sij=dk Q′i⋅K′j.
RoPE 使 S i j S_{ij} Sij 能体现 i i i 与 j j j 的相对位置 (如依赖 i − j i-j i−j),对外推更长序列 往往比「只在输入端加一次绝对 PE」更友好。推导与实现细节见 LLaMA 架构、 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍 。
与 Qwen 1 的连续性 来源:Qwen2 Technical Report §2.2.1:仍采用 RoPE 、QKV bias 等与 Qwen 1 一致的设定;Qwen 1 报告中关于 RoPE 频率缓冲(如 FP32 存 inverse frequency)等实现注记 ,在「旋 Q、K、不改变张量形状」意义上同样适用于理解 Qwen2 主干。Qwen2 报告单独强调的 是预训练阶段将上下文扩至 32K ,并配合 RoPE 基频由 10 4 10^4 104 调至 10 6 10^6 106 、YARN 、Dual Chunk Attention(DCA) 等以支持约 128K 量级扩展------机制要点集中写在 §5 ,本节只钉住「 X X X 无绝对 PE、相对位置进 Q , K Q,K Q,K」这一数据流事实。
3.5.3 对比小结(三列)
| 维度 | 经典Decoder-only | LLaMA / Qwen1 ) | Qwen2(本报告) |
|---|---|---|---|
| 注入时机 | 进网络前 一次 | 每层注意力内 | 同 LLaMA / Qwen 1 |
| 注入对象 | 与 Embedding 相加 | 只旋 Q、K | 同左 |
| 位置类型 | 偏 绝对 位置向量 | 相对 关系进 Q K ⊤ QK^\top QK⊤ | 同左 |
| 进入第一层的 X X X | Emb + PE \text{Emb}+\text{PE} Emb+PE | 仅 Emb(如 §3.1) | 仅 Emb |
| 长上下文扩展 | 依实现 | Qwen1 侧重推理期技巧等 | 训练 32K + 基频 / YARN / DCA(§5) |
4. 稠密 Decoder 单层:GQA + SwiGLU + Pre-Norm
单层流程仍为:
RMSNorm → 因果 GQA(RoPE、QKV bias)→ 残差 → RMSNorm → SwiGLU FFN → 残差。
4.1 GQA:相对 Qwen 1 的 MHA 默认
Qwen2 Technical Report 写明:稠密 Qwen2 以 GQA(Grouped-Query Attention)替代常规 MHA (Ainslie et al., 2023),在保持多头输出形状不变 的前提下,减少 K、V 的投影参数 与推理时 KV Cache 体积,提高吞吐。各尺寸的 # Query Heads 与 # KV Heads 见报告表 1(例如 7B:28 / 4 ;72B:64 / 8 )。Qwen 1 技术报告中的基线仍以 MHA ( h q = h kv h_q=h_{\text{kv}} hq=hkv)为主;Qwen1.5 起部分规格引入 GQA,Qwen2 稠密全系默认 GQA。
4.1.1 MHA 与 GQA 是什么、为何省 KV
MHA(Multi-Head Attention)
- Query / Key / Value 头数相同 ,记为 h h h。第 t t t 个头各有投影 W Q ( t ) , W K ( t ) , W V ( t ) W_Q^{(t)}, W_K^{(t)}, W_V^{(t)} WQ(t),WK(t),WV(t),得到 Q ( t ) , K ( t ) , V ( t ) ∈ R L × d k Q^{(t)}, K^{(t)}, V^{(t)} \in \mathbb{R}^{L\times d_k} Q(t),K(t),V(t)∈RL×dk,常取 d k = d model / h d_k = d_{\text{model}}/h dk=dmodel/h。
- 直觉 : h h h 个子空间各算一遍注意力,再拼回 d model d_{\text{model}} dmodel 维。
- 推理代价 :自回归每步缓存历史位置的 K、V ;缓存量正比于 KV 头数 。MHA 下 每头各有一份 K、V → 头数大则 KV Cache 显存与带宽压力大。
GQA(Grouped-Query Attention)
- 将 Query 头数 h q h_q hq 与 Key/Value 头数 h kv h_{\text{kv}} hkv 拆开 ,满足 h kv < h q h_{\text{kv}} < h_q hkv<hq (实现上常要求 h q h_q hq 为 h kv h_{\text{kv}} hkv 的整数倍 ,记 分组大小 g = h q / h kv g = h_q / h_{\text{kv}} g=hq/hkv)。
- g g g 个 Query 头共用同一组 K、V :每个 Q 头仍用自己的 Q ( t ) Q^{(t)} Q(t) 算自己的 注意力权重 A ( t ) A^{(t)} A(t),但 从同一组 K ( u ) , V ( u ) K^{(u)}, V^{(u)} K(u),V(u) 上做点积与加权 ( u u u 由 t t t 决定,见下)。
- 直觉 :「查询角度」可以很多,「供检索的键值槽」少开几份,在表达力与显存/带宽之间折中。
- 相对 MHA :C o n c a t \mathrm{Concat} Concat 与 W O W_O WO 之后 输出仍为 L × d model L\times d_{\text{model}} L×dmodel ;变的是 W K , W V W_K,W_V WK,WV 的输出通道数 (由 h q d k h_q d_k hqdk 变为 h kv d k h_{\text{kv}} d_k hkvdk)及 KV Cache ,约按 h kv / h q h_{\text{kv}}/h_q hkv/hq 缩小。
极端对照
- MHA : h kv = h q h_{\text{kv}} = h_q hkv=hq。
- MQA : h kv = 1 h_{\text{kv}} = 1 hkv=1,所有 Q 头共享一份 K、V。
- GQA:介于两者之间。
| 项目 | MHA | GQA |
|---|---|---|
| Q 头数 / KV 头数 | h q = h kv = h h_q = h_{\text{kv}} = h hq=hkv=h | h q > h kv h_q > h_{\text{kv}} hq>hkv |
| 每头 d k d_k dk | 常取 d model / h q d_{\text{model}}/h_q dmodel/hq | 同左,保证 h q d k = d model h_q d_k = d_{\text{model}} hqdk=dmodel |
| 单层 Attn 输出形状 | L × d model L\times d_{\text{model}} L×dmodel | 同左 |
| 推理 KV Cache(粗) | 正比于 h q h_q hq 份 K、V | 正比于 h kv h_{\text{kv}} hkv 份 K、V |
配置里常写 num_attention_heads = h q = h_q =hq,num_key_value_heads = h kv = h_{\text{kv}} =hkv;二者相等即为 MHA。
4.1.2 记号与分组规则
- d k d_k dk:Head size(报告表 1 中 Head size)。
- d model = h q d k d_{\text{model}} = h_q\, d_k dmodel=hqdk(与本文 §1 中 Qwen2-7B 示例一致:3584 = 28×128)。
- 分组 :令 g = h q / h kv g = h_q / h_{\text{kv}} g=hq/hkv。将 Query 头编号为 t = 1 , ... , h q t = 1,\ldots,h_q t=1,...,hq,则第 t t t 个 Q 头使用第 u u u 组 KV,其中
u = ⌊ t − 1 g ⌋ + 1 ∈ { 1 , ... , h kv } . u = \left\lfloor \frac{t - 1}{g} \right\rfloor + 1 \in \{1,\ldots,h_{\text{kv}}\}. u=⌊gt−1⌋+1∈{1,...,hkv}.
(例如 h q = 28 , h kv = 4 , g = 7 h_q=28,\,h_{\text{kv}}=4,\,g=7 hq=28,hkv=4,g=7:头 1 1 1-- 7 7 7 共用 K ( 1 ) , V ( 1 ) K^{(1)},V^{(1)} K(1),V(1),头 8 8 8-- 14 14 14 共用 K ( 2 ) , V ( 2 ) K^{(2)},V^{(2)} K(2),V(2),依此类推。)
4.1.3 单层 GQA 子层:逐步数据流
步骤 0:子层入口
输入上一层残差流 X in ∈ R L × d model X_{\text{in}}\in\mathbb{R}^{L\times d_{\text{model}}} Xin∈RL×dmodel。先 Pre-Norm:
X ~ = R M S N o r m ( X in ) . \tilde{X} = \mathrm{RMSNorm}(X_{\text{in}}). X~=RMSNorm(Xin).
下文用 X X X 表示 X ~ \tilde{X} X~,形状 L × d model L\times d_{\text{model}} L×dmodel。
步骤 1:线性投影得到 Q Q Q( h q h_q hq 组)
用一块 W Q ∈ R d model × ( h q d k ) W_Q\in\mathbb{R}^{d_{\text{model}}\times (h_q d_k)} WQ∈Rdmodel×(hqdk)(及 Qwen 的 bias ,形状对齐 h q d k h_q d_k hqdk)得到扁平输出,再按头切开:对每个 t = 1 , ... , h q t=1,\ldots,h_q t=1,...,hq,
Q ( t ) ∈ R L × d k . Q^{(t)} \in \mathbb{R}^{L\times d_k}. Q(t)∈RL×dk.
(与 MHA 写法一致,只是此处头数为 h q h_q hq。)
步骤 2:线性投影得到 K K K、 V V V(仅 h kv h_{\text{kv}} hkv 组)
各用 W K , W V ∈ R d model × ( h kv d k ) W_K,\,W_V\in\mathbb{R}^{d_{\text{model}}\times (h_{\text{kv}} d_k)} WK,WV∈Rdmodel×(hkvdk)(及对应 bias),得到 h kv h_{\text{kv}} hkv 个头:对每个 u = 1 , ... , h kv u=1,\ldots,h_{\text{kv}} u=1,...,hkv,
K ( u ) , V ( u ) ∈ R L × d k . K^{(u)},\, V^{(u)} \in \mathbb{R}^{L\times d_k}. K(u),V(u)∈RL×dk.
这是相对 MHA 的核心差别 :MHA 中 K ( t ) , V ( t ) K^{(t)},V^{(t)} K(t),V(t) 与 Q ( t ) Q^{(t)} Q(t) 一一对应 ;GQA 中 KV 只有 h kv h_{\text{kv}} hkv 份 ,被 g g g 个 Q 头复用。
步骤 3:RoPE 作用于 Q Q Q、 K K K
对每个 Q ( t ) Q^{(t)} Q(t)、 K ( u ) K^{(u)} K(u) 的每一行 (每个 token 位置)在 d k d_k dk 维内做 RoPE 旋转;形状不变 ,数值更新。与 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍、本文 §3.5 一致。
步骤 4:缩放点积、因果掩码、softmax、乘 V V V(按头、按组配对)
对 每个 Query 头 t t t,取 u u u 为 §4.1.2 的映射,用 同一组 K ( u ) , V ( u ) K^{(u)},V^{(u)} K(u),V(u) 计算:
S ( t ) = Q ( t ) ( K ( u ) ) ⊤ d k ∈ R L × L . S^{(t)} = \frac{Q^{(t)} (K^{(u)})^\top}{\sqrt{d_k}} \in \mathbb{R}^{L\times L}. S(t)=dk Q(t)(K(u))⊤∈RL×L.
加因果掩码 M M M( j > i j>i j>i 处为 − ∞ -\infty −∞ 或极大负数),行内 softmax 得 A ( t ) A^{(t)} A(t),再
h e a d ( t ) = A ( t ) V ( u ) ∈ R L × d k . \mathrm{head}^{(t)} = A^{(t)} V^{(u)} \in \mathbb{R}^{L\times d_k}. head(t)=A(t)V(u)∈RL×dk.
即单头链仍为:Q K ⊤ / d k QK^\top/\sqrt{d_k} QK⊤/dk → +mask → softmax → ×V ;MHA 与 GQA 的公式形式相同 ,差别仅是 K ( u ) , V ( u ) K^{(u)},V^{(u)} K(u),V(u) 的 u u u 由分组规则决定 ,且 u u u 的个数少于 t t t。
步骤 5:多头拼接与输出投影
C o n c a t = h e a d ( 1 ) ∥ ⋯ ∥ h e a d ( h q ) ∈ R L × d model , \mathrm{Concat} = \big\\mathrm{head}\^{(1)} \\,\\\|\\, \\cdots \\,\\\|\\, \\mathrm{head}\^{(h_q)}\\big \in \mathbb{R}^{L\times d_{\text{model}}}, Concat=head(1)∥⋯∥head(hq)∈RL×dmodel,
A t t n O u t = C o n c a t W O , W O ∈ R d model × d model . \mathrm{AttnOut} = \mathrm{Concat}\, W_O, \quad W_O\in\mathbb{R}^{d_{\text{model}}\times d_{\text{model}}}. AttnOut=ConcatWO,WO∈Rdmodel×dmodel.
步骤 6:残差
X mid = X in + A t t n O u t . X_{\text{mid}} = X_{\text{in}} + \mathrm{AttnOut}. Xmid=Xin+AttnOut.
GQA 维度小结(在 31 文 MHA 表基础上的增量信息)
| 步骤 | 张量 | 形状 |
|---|---|---|
| RMSNorm 后 | X X X | L × d model L\times d_{\text{model}} L×dmodel |
| 各 Q 头 | Q ( t ) Q^{(t)} Q(t) | L × d k L\times d_k L×dk,共 h q h_q hq 份 |
| 各 K/V 头 | K ( u ) , V ( u ) K^{(u)},V^{(u)} K(u),V(u) | L × d k L\times d_k L×dk,共 h kv h_{\text{kv}} hkv 份(少于 h q h_q hq) |
| 每头 logits | S ( t ) S^{(t)} S(t) | L × L L\times L L×L |
| 每头输出 | h e a d ( t ) \mathrm{head}^{(t)} head(t) | L × d k L\times d_k L×dk |
| 子层输出 | A t t n O u t \mathrm{AttnOut} AttnOut | L × d model L\times d_{\text{model}} L×dmodel |
训练/推理可用 Flash Attention 在不显式物化完整 L × L L\times L L×L 的前提下等价完成上述计算;GQA 实现中只需对 h kv h_{\text{kv}} hkv 组 K、V 建 cache(自回归每步追加当前位置的 K ( u ) , V ( u ) K^{(u)},V^{(u)} K(u),V(u)),不是 h q h_q hq 组全份------这是相对 Qwen 1 报告默认 MHA 的主要工程收益。
4.2 QKV bias、RoPE、RMSNorm
与 Qwen 1 一致 来源:报告 §2.2.1:保留 QKV bias (Su, 2023)、RoPE 、RMSNorm 、Pre-Norm。
4.3 SwiGLU 与 Intermediate Size
仍采用 SwiGLU 作为 FFN 激活形式。与 Qwen1 报告将中间维写为 8 3 d model \frac{8}{3}d_{\text{model}} 38dmodel 不同,Qwen2 各尺寸的中间维以表 1「Intermediate Size」为准 (例如 7B 为 18,944 ,72B 为 29,568 ),由架构搜索与规模共同决定,不宜 再套用单一的 8 3 d \frac{8}{3}d 38d 经验式。
矩阵形状 (与 LLaMA 架构 §3.3 同型,记 d ff d_{\text{ff}} dff 为表中间维):
- Z 1 = X ~ W 1 Z_1 = \tilde{X} W_1 Z1=X~W1, W 1 ∈ R d model × d ff W_1\in\mathbb{R}^{d_{\text{model}}\times d_{\text{ff}}} W1∈Rdmodel×dff; Z 3 = X ~ W 3 Z_3 = \tilde{X} W_3 Z3=X~W3 同形。
- Z = σ swish ( Z 1 ) ⊙ Z 3 Z = \sigma_{\text{swish}}(Z_1)\odot Z_3 Z=σswish(Z1)⊙Z3; F F N O u t = Z W 2 \mathrm{FFNOut} = Z W_2 FFNOut=ZW2, W 2 ∈ R d ff × d model W_2\in\mathbb{R}^{d_{\text{ff}}\times d_{\text{model}}} W2∈Rdff×dmodel。
4.4 规格速查(稠密,报告表 1)
| 配置 | Hidden | Layers | Q heads | KV heads | Head size | Intermediate | Tying |
|---|---|---|---|---|---|---|---|
| 0.5B | 896 | 24 | 14 | 2 | 64 | 4,864 | True |
| 1.5B | 1,536 | 28 | 12 | 2 | 128 | 8,960 | True |
| 7B | 3,584 | 28 | 28 | 4 | 128 | 18,944 | False |
| 72B | 8,192 | 80 | 64 | 8 | 128 | 29,568 | False |
各列含义 (与上文 §3、§4.1 记号一致):
| 列名 | 含义 |
|---|---|
| 配置 | 报告中的稠密 型号名称(参数量级为约数;不含 MoE 变体)。 |
| Hidden | 隐藏维度 d model d_{\text{model}} dmodel(与 config.json 中 hidden_size 同义):每层主路径上每个 token 的向量宽度;满足 d model = ( Q heads ) × ( Head size ) d_{\text{model}} = (\text{Q heads})\times(\text{Head size}) dmodel=(Q heads)×(Head size)。 |
| Layers | Transformer Decoder 层数(堆叠块个数)。 |
| Q heads | Query 头数 h q h_q hq(num_attention_heads):注意力里独立的 Query 投影份数;§4.1 中每个 Q ( t ) Q^{(t)} Q(t) 对应一头。 |
| KV heads | Key/Value 头数 h kv h_{\text{kv}} hkv(num_key_value_heads):实际计算的 K ( u ) , V ( u ) K^{(u)},V^{(u)} K(u),V(u) 组数 ;GQA 下 h kv < h q h_{\text{kv}} < h_q hkv<hq ,推理 KV Cache 体积大致按 h kv / h q h_{\text{kv}}/h_q hkv/hq 相对 MHA 缩减。 |
| Head size | 每头维度 d k d_k dk(head_dim):每个注意力头的 Q / K / V Q/K/V Q/K/V 向量长度;h q × d k = d model h_q \times d_k = d_{\text{model}} hq×dk=dmodel。 |
| Intermediate | SwiGLU 分支的中间宽度 d ff d_{\text{ff}} dff(报告表 1 的 Intermediate Size ):§4.3 中 W 1 , W 3 W_1,W_3 W1,W3 的输出列数、 W 2 W_2 W2 的输入行数;不再 等于 Qwen1 常用的单一 8 3 d model \frac{8}{3}d_{\text{model}} 38dmodel 经验式。 |
| Tying | Embedding Tying (§3.3--3.4 ):True 表示 W out = E ⊤ W_{\text{out}}=E^\top Wout=E⊤ (输出层与词嵌入绑权);False 表示 untied ,单独学习 W out W_{\text{out}} Wout。 |
5. 长上下文:训练期延长 + RoPE 基频 + YARN + DCA
本节对应 Qwen2 Technical Report §3.2 Long-context Training 与 §2.2.1 中与 DCA、YARN 并列的架构说明:在 §3.5 已约定「位置由 RoPE 注入 Q , K Q,K Q,K」的前提下,这里说明 如何把「可稳定训练的上下文」拉长 、以及 如何在更长序列上做外推 。四件事分工不同:32K 训练 解决「模型是否见过长依赖」;RoPE 基频 调节旋转频率谱以适配长距;YARN 在注意力侧做与长度相关的缩放 以缓和外推失真;DCA 用 chunk 组织超长序列,显式利用 块内 / 块间 相对位置。
5.1 预训练末段:上下文由 4,096 扩至 32,768
报告写明:在预训练的 收尾阶段 ,将 单条序列的训练上下文 从 4,096 token 提高到 32,768 token,并 同步引入更多高质量长文本数据。
这样做的意义(与仅靠推理期技巧对比):
- 优化目标与梯度 直接作用在 最长 32K 的因果掩码自注意力 上,模型在训练分布内就学习 跨万级 token 的依赖与检索,而不是只在短上下文上拟合、再靠推理时插值/缩放去「猜」长行为。
- 与 §4.1 GQA 结合:长上下文推理时 KV Cache 体积随序列长度与 h kv h_{\text{kv}} hkv 增长;Qwen2 用 GQA 降低每 token 的 KV 占用 ,使 32K 级训练与部署在工程上更可承受。
注意 :32K 是报告描述的 预训练阶段采用的训练窗口 ;超过 32K 的更长输入(如 约 128K )还依赖下文 RoPE 基频 + YARN + DCA 等机制,并在 Instruct 产品与评测中分规格启用(报告 §5.2.3)。
5.2 RoPE 基频:由 10 4 10^4 104 调至 10 6 10^6 106
RoPE 在每一维对上使用一组与位置 m m m 相关的旋转角;实现上常通过 底数(base) θ 0 \theta_0 θ0 (报告中 base frequency )生成 逆频率 ω i \omega_i ωi,从而决定 各维旋转随位置变化的快慢 (等价于不同维度上的 「波长」 )。Qwen2 将 RoPE 的 base 从常见的 10 4 10^4 104 (与原始 Transformer 正弦 PE 中 10000 同量级)改为 10 6 10^6 106。
直观理解(不求替代 RoPE 原文的严格推导):
- θ 0 \theta_0 θ0 更大 → 相邻 token 在多数频率分量上的 相位差更小 ,极长距离上仍保留可分的相对位置信息,减轻「训练长度之外位置编码退化」一类问题。
- 报告引用 Xiong et al. (2023) 等关于 长上下文下 RoPE / 位置编码缩放 的讨论,说明该修改服务于 长上下文场景下的优化。
这与 §3.5 一致:不改变 「在注意力里旋 Q , K Q,K Q,K」的流程,只改 RoPE 超参 ;与 QKV bias(§4.2)仍可并存,报告亦将二者同列为 Qwen2 注意力设计的一部分。
5.3 YARN:对注意力权重重缩放以做长度外推
YARN (Peng et al., 2023;论文标题常写作 YaRN )在 超出训练所见上下文 或需要 平滑拉长有效窗口 时,对注意力中的 权重 / logits 尺度 做 与目标长度相关的重缩放(rescaling) ,使模型在 更长序列 上仍能保持合理的注意力分布,从而改善 长度外推(length extrapolation)。
报告中的表述是:rescaling the attention weights for better length extrapolation 。实现上属于 推理或前向路径上的修改 (具体形式依官方实现版本而定),与 换数据再训 正交:可在 已训好的权重 上配合 更长上下文 使用。
与 Qwen2 产品线的关系 (报告 Figure 1 说明):凡宣称支持超过 32K 上下文的 Instruct 型号,均集成了 YARN 。因此:≤32K 的用法可主要依赖 32K 训练 + RoPE 基频 ;>32K 往往显式依赖 YARN(及下文 DCA)。
5.4 Dual Chunk Attention(DCA):分块与块内/块间相对位置
DCA (An et al., 2024)把 超长序列 划成若干个长度可控的 chunk(块):
- 若整条输入可被单个 chunk 容纳 ,DCA 不产生与标准全序列自注意力不同的结果 (报告:produces the same result as the original attention )------即 短于 chunk 阈值时行为与 vanilla 一致 ,便于兼容原有评测与 32K 内 行为。
- 若序列长于单块容量 ,则在块内保持常规 token--token 相对位置建模,并 额外 引入对 跨 chunk 的相对位置信息的利用,使模型在 块边界 处仍能建立连贯的长程依赖,从而 提升极长上下文下的表现。
报告在 §2.2.1 与 §3.2 中把 DCA 与 YARN 并列为扩展窗口的手段:DCA 偏 结构上分块 + 位置关系 ;YARN 偏 注意力尺度上的外推修正 。二者可与 GQA、RoPE 同栈使用。
5.5 组合效果、规模差异与「32K 内行为不变」
报告 §3.2 称:在 YARN + DCA 等策略下,模型可处理 至多约 131,072 token 的序列,初步实验 中 困惑度劣化较小 (preliminary experiments 、minimal perplexity degradation )。这是 机制上限与实验观测 的表述;实际产品默认上下文 仍以各型号 技术说明 / config.json / 推理框架 为准。
报告 §5.2.3 对 Instruct 系列的 Needle-in-a-Haystack 等评测给出 分长度、分尺寸 结论(例如 Qwen2-7B-Instruct 在 约 128K 上下文上仍保持较高检索准确率;更大与更小型号的上限不同)。此外,报告 Table 12 有一条对部署很重要的注记:在集成 YARN + DCA 后,长度不超过 32K 时,模型行为与不集成时一致 (does not change the model behavior within 32k tokens )------即 长文扩展补丁不会在「已训练的 32K 以内」随意改变注意力形态。
💡 与 Qwen 1 对比 :Qwen1 技术报告侧重 推理期 NTK-aware RoPE 、LogN 、窗口注意力 等组合做长文;Qwen2 把 32K 训练末段 、RoPE 基频 10 4 → 10 6 10^4\to 10^6 104→106 与 YARN + DCA 写进 预训练与架构主线 ,长文能力更偏 「先训长、再辅以可证明不破坏 32K 内行为的扩展算子」 。细节仍可与 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍 中推理期技巧对照阅读。
6. Qwen2 MoE(57B-A14B):FFN 层的稀疏替换
Qwen2 Technical Report §2.2.2 中,MoE 仅替换每个 Decoder 层里的 FFN 子层 ;自注意力子层 (GQA、RoPE、QKV bias 等)与稠密 Qwen2 同型 (见 §4 )。因此:稀疏性只发生在「RMSNorm 之后的 FFN 段」 ,同一层内仍是 Attn → 残差 → RMSNorm →(MoE FFN)→ 残差。
6.1 与稠密 SwiGLU FFN 对照(单 token 记号)
稠密模型中,经 Pre-Norm 后的隐向量记为 x ∈ R d model x\in\mathbb{R}^{d_{\text{model}}} x∈Rdmodel (每个 token 一行 ;批处理时为 L × d model L\times d_{\text{model}} L×dmodel,以下按单 token 写)。§4.3 的 SwiGLU FFN 可抽象为一个非线性映射
y = F dense ( x ) ∈ R d model , y = F_{\text{dense}}(x) \in \mathbb{R}^{d_{\text{model}}}, y=Fdense(x)∈Rdmodel,
内部是 两路线性 + SiLU 门控 + 再线性 (中间维 d ff d_{\text{ff}} dff 由表 1 Intermediate Size 给出)。
MoE 层 把 F dense F_{\text{dense}} Fdense 换成 n n n 个结构相同、参数独立的「专家」 E 1 , ... , E n E_1,\ldots,E_n E1,...,En(每个 E i E_i Ei 仍是 SwiGLU 形 FFN ,但中间维常小于 同宽度稠密模型的 d ff d_{\text{ff}} dff,见 §6.4 细粒度 )。对当前 x x x,只让其中少数专家参与计算 ,从而在 总参数量可以很大 的同时,每个 token 的激活参数量 可控------这是 MoE 与「宽而稠密的单层 FFN」的本质差别。
6.2 门控、softmax 与 top- k k k 稀疏求和(报告式 (1)(2))
门控网络 G G G 与 x x x 同维输入 ,输出 n n n 个 logits ( n n n 为路由专家 个数,不含共享专家时的记法见 §6.3):
ℓ = G ( x ) ∈ R n , p = s o f t m a x ( ℓ ) ∈ R n . \boldsymbol{\ell} = G(x) \in \mathbb{R}^n, \qquad p = \mathrm{softmax}(\boldsymbol{\ell}) \in \mathbb{R}^n. ℓ=G(x)∈Rn,p=softmax(ℓ)∈Rn.
向量 p = ( p 1 , ... , p n ) ⊤ p=(p_1,\ldots,p_n)^\top p=(p1,...,pn)⊤ 可理解为「路由器认为当前 token 与各专家的匹配程度」的可微软分配 ;训练时 梯度可经 p p p 回传到 G G G 与被选中的专家。
Top- k k k 路由 :设 k ≪ n k\ll n k≪n,令 t o p k ( p ) \mathrm{topk}(p) topk(p) 表示 p p p 中分量最大的 k k k 个下标 构成的集合(实现上通常对并列情况有固定 tie-break)。仅对这 k k k 个专家 计算 E i ( x ) E_i(x) Ei(x)(其余专家本步不算,节省算力)。报告的聚合式为
y route = ∑ i ∈ t o p k ( p ) p i E i ( x ) . y_{\text{route}} = \sum_{i\,\in\,\mathrm{topk}(p)} p_i\, E_i(x). yroute=i∈topk(p)∑piEi(x).
(上式即报告中的路由支路聚合;§6.3 在加入共享专家后写全层输出。)
逐项理解:
- E i ( x ) E_i(x) Ei(x) :第 i i i 个专家与稠密 FFN 同型,把 d model d_{\text{model}} dmodel 映回 d model d_{\text{model}} dmodel。
- p i p_i pi :来自全局 softmax ,但 只对 top- k k k 下标求和 ;因此一般 ∑ i ∈ t o p k ( p ) p i < 1 \sum_{i\in\mathrm{topk}(p)} p_i < 1 ∑i∈topk(p)pi<1 (除非其余分量恰为 0)。部分实现会对 top- k k k 的 p i p_i pi 再归一化 使权重和为 1,与上式略有出入 ;读代码时以 Hugging Face / vLLM 中 Qwen2-MoE 实现为准。
- 推理 :每个 token、每一层只算 k k k 个 E i E_i Ei,总计算量 随 k k k 线性增长,而不是随 n n n。
💡 与「硬路由」对比 :上式仍用 软权重 p i p_i pi 乘专家输出,梯度可穿过;有的系统用 straight-through 或 离散选路 + 负载均衡损失 ;Qwen2 报告给出的即是上述 可微 top- k k k 加权和 形式。
6.3 共享专家 + 路由专家(Qwen2 路由设计)
报告 Expert Routing :除 由 G G G 选择的专家 外,再设 共享专家(shared experts) ------每个 token、每一层都参与计算 ,不经过 top- k k k 裁剪,用于提供 稳定、跨样本的表示基底 ;路由专家(routed experts) 则由 G G G 按 token 动态挑选,承担 专业化、稀疏组合。
记 n s n_s ns 个共享专家为 S 1 , ... , S n s S_1,\ldots,S_{n_s} S1,...,Sns,n r n_r nr 个路由专家为 R 1 , ... , R n r R_1,\ldots,R_{n_r} R1,...,Rnr,门控 G G G 只对路由支路输出 n r n_r nr 维 logits,得到 p ∈ R n r p\in\mathbb{R}^{n_r} p∈Rnr ,在 t o p k ( p ) \mathrm{topk}(p) topk(p) 上聚合路由支路。一层 MoE FFN 的常见写法为
y = ∑ j = 1 n s S j ( x ) + ∑ i ∈ t o p k ( p ) p i R i ( x ) . y = \sum_{j=1}^{n_s} S_j(x) \;+\; \sum_{i\,\in\,\mathrm{topk}(p)} p_i\, R_i(x). y=j=1∑nsSj(x)+i∈topk(p)∑piRi(x).
第一项 对全体共享专家求和(若实现中带可学习标量或权重,可吸收进 S j S_j Sj 定义);第二项 与 §6.2 同构。报告表 1 注明:# Activated Experts 不计共享专家 ------即表中 「每 token 激活路由专家数」 只统计 top- k k k 的路由支路。
Qwen2-57B-A14B(表 1) 来源:报告 §2.2.2、表 1:
- Hidden 3584 ,28 层,28 Q / 4 KV(与稠密 7B 同宽同深,便于 upcycling 叙述)。
- 每个专家 Intermediate 2,560 (远小于稠密 7B 的 18,944 ,体现 细粒度)。
- 64 个 routed experts;每 token 激活其中 8 个 (k = 8 k=8 k=8)。
- 8 个 shared experts(每 token 必算)。
- Embedding Tying = False (与 §3.4 大模型一致)。
「57B-A14B」含义 (报告表 1 脚注):总参数量约 57B ;每个 token、每层在 MoE FFN 段实际参与乘加的参数量 (激活量)约 14B 量级------远小于把 64 个专家全部算满,也小于同 hidden 的纯稠密 28 层巨型 FFN,体现 稀疏激活 的工程目标。
6.4 细粒度专家(fine-grained experts)
相对 Mixtral 8×7B 一类「每个专家 ≈ 原模型整段 FFN 」的 粗粒度 ,Qwen2 MoE 采用 更小中间维的专家 + 每 token 激活更多个专家 (在 总专家参数 与 每 token 激活参数 预算约束下)。直觉上:同样激活算力 下,多专家小组合 比 少专家大整块 有 更丰富的专家组合空间 ,有利于 动态分工 与 利用率 。报告引用 Dai et al., 2024 等关于细粒度专家的讨论 来源:§2.2.2。
6.5 专家初始化:类 upcycling 的步骤(报告 §2.2.2)
Qwen2 MoE 由稠密模型演化 时,采用接近 upcycling (Komatsuzaki et al., 2023)的流程,并强调 细粒度专家之间的差异化:
- 记 每个小专家 的中间维为 h E h_E hE,专家个数为 n n n,源稠密 FFN 中间维为 h FFN h_{\text{FFN}} hFFN。先将稠密 FFN 沿中间维复制 约 ⌈ n ⋅ h E / h FFN ⌉ \lceil n\cdot h_E / h_{\text{FFN}} \rceil ⌈n⋅hE/hFFN⌉ 份,使「可切分的中间维总量」够覆盖 n n n 个 h E h_E hE。
- 对每一份副本,在 中间维 上做 shuffle(打乱) ,让切出的各专家 即使来自同一副本也不完全相同。
- 从副本中 切出 n n n 个中间维为 h E h_E hE 的专家,丢弃多余维度。
- 每个 细粒度专家中 50% 参数 随机重初始化 ,进一步增大专家间差异,利于训练早期 探索不同专长。
Qwen2-57B-A14B 明确写为 由 Qwen2-7B upscale 得到(报告 §2.2.3),与上述初始化叙事一致。
6.6 维度与实现小结
| 对象 | 稠密 FFN(§4.3) | MoE 层(本节) |
|---|---|---|
| 单 token 输入/输出 | x , y ∈ R d model x,\,y\in\mathbb{R}^{d_{\text{model}}} x,y∈Rdmodel | 同左 |
| 非线性主体 | 单个 F dense F_{\text{dense}} Fdense | 多个 E i E_i Ei / S j S_j Sj / R i R_i Ri,稀疏调用 |
| 门控 | 无 | G ( x ) → p G(x)\to p G(x)→p,top- k k k 选路由专家 |
| 表 1 Intermediate | 全层共享一个 d ff d_{\text{ff}} dff | MoE 表中指 每个专家 的中间维 |
训练时 MoE 常辅以 负载均衡(expert balance) 等辅助目标,避免「少数专家包揽所有 token」;Qwen2 报告 §2.2.2 未展开损失细节,实现以官方代码为准。
7. 输出层(与 §3 呼应)
本节把 LM Head (语言模型头)单独收束一遍:最后一层隐状态如何映射到词表维度 、untied / tied 两套参数化 、以及 Qwen2 各尺寸 在报告表 1 中的策略。记号与 §3.1--3.4 一致,便于从「嵌入进栈」到「logits 出栈」对照阅读;与 Qwen 1 更一般的对比见 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍。
7.1 在整栈中的位置与 h \mathbf{h} h 的定义
Decoder 堆叠 N N N 层后,得到最后一层输出矩阵
H ∈ R L × d model . H \in \mathbb{R}^{L \times d_{\text{model}}}. H∈RL×dmodel.
自回归生成「下一个 token」 (推理时最常见):只关心 前缀 w 0 , ... , w L − 1 w_0,\ldots,w_{L-1} w0,...,wL−1 条件下的分布,取 最后一个有效位置 的隐向量(列向量)
h = H L − 1 , : ⊤ ∈ R d model . \mathbf{h} = HL-1,\\,:^\top \in \mathbb{R}^{d_{\text{model}}}. h=HL−1,:⊤∈Rdmodel.
**训练(教师强制)**时,对位置 i i i 常要预测 w i + 1 w_{i+1} wi+1,则取 h i = H i , : ⊤ \mathbf{h}_i = Hi,\\,:^\top hi=Hi,:⊤,同一套 LM Head 对每个 i i i 各算一遍 logits;本节为写公式简洁,仍用 h \mathbf{h} h 表示「当前要用来预测下一词的那一列」,在实现上对应 最后一格 或 批量中某一位置的切片。
**MoE 型号(§6)**不改变上述流程:稀疏性在 FFN ;输出层与稠密栈末尾的线性头同型。
7.2 未绑权(untied): W out W_{\text{out}} Wout、偏置与 softmax
词表大小记为 V V V (Qwen2 报告 151646 ,见 §3.1 )。未绑权时单独有可学习矩阵与偏置
W out ∈ R d model × V , b out ∈ R V . W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V}, \qquad \mathbf{b}_{\text{out}} \in \mathbb{R}^V. Wout∈Rdmodel×V,bout∈RV.
logits 列为 s ∈ R V \mathbf{s} \in \mathbb{R}^V s∈RV,第 w w w 个分量 s w s_w sw 表示「下一词为词表第 w w w 个 token」的未归一化分数:
s = W out ⊤ h + b out . \mathbf{s} = W_{\text{out}}^\top \mathbf{h} + \mathbf{b}_{\text{out}}. s=Wout⊤h+bout.
等价地,把 h ⊤ \mathbf{h}^\top h⊤ 看成 1 × d model 1 \times d_{\text{model}} 1×dmodel 行向量:
s ⊤ = h ⊤ W out + b out ⊤ . \mathbf{s}^\top = \mathbf{h}^\top W_{\text{out}} + \mathbf{b}_{\text{out}}^\top. s⊤=h⊤Wout+bout⊤.
下一 token 的类别分布为
P ( w ∣ context ) = exp ( s w ) ∑ v = 1 V exp ( s v ) = ( s o f t m a x ( s ) ) w . P(w \mid \text{context}) = \frac{\exp(s_w)}{\sum_{v=1}^{V} \exp(s_v)} = \big(\mathrm{softmax}(\mathbf{s})\big)_w. P(w∣context)=∑v=1Vexp(sv)exp(sw)=(softmax(s))w.
参数量 (相对绑权):除 E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel (§3.1)外,另需 约 d model ⋅ V d_{\text{model}} \cdot V dmodel⋅V 的 W out W_{\text{out}} Wout(及 V V V 维 bias,相对可忽略)。Qwen2-7B / 72B / MoE 在表 1 中为 untied (§3.4)。
7.3 绑权(tied): W out = E ⊤ W_{\text{out}} = E^\top Wout=E⊤ 与内积形式
绑权时令
W out = E ⊤ ∈ R d model × V , W_{\text{out}} = E^\top \in \mathbb{R}^{d_{\text{model}} \times V}, Wout=E⊤∈Rdmodel×V,
即 输出投影与嵌入矩阵共用 :不再有独立的 W out W_{\text{out}} Wout 存盘。记 §3.1 中词 w w w 的嵌入列为 e w = E w , : ⊤ \mathbf{e}_w = Ew,\\,:^\top ew=Ew,:⊤,则
s w = h ⊤ e w + ( b out ) w . s_w = \mathbf{h}^\top \mathbf{e}w + (b{\text{out}})_w. sw=h⊤ew+(bout)w.
无偏置 时, s w s_w sw 就是 h \mathbf{h} h 与 e w \mathbf{e}w ew 的内积 ------「上下文表示」与「该词在输入端的语义方向」共用同一组 V V V 个方向 。省参 :相对 untied 少一整块 **d model × V d{\text{model}} \times V dmodel×V** 权重(§3.3 理解要点)。Qwen2-0.5B / 1.5B 表 1 为 True。
7.4 Qwen2 配置对照与小结
| 模型 | Embedding Tying | 输出层参数化 |
|---|---|---|
| Qwen2-0.5B / 1.5B | True | W out = E ⊤ W_{\text{out}}=E^\top Wout=E⊤,约省一块 d model × V d_{\text{model}}\!\times\!V dmodel×V |
| Qwen2-7B / 72B / 57B-A14B | False | 独立 W out W_{\text{out}} Wout(及常见 bias) |
小结 :输出层只做 一次线性映射 +(可选)bias + softmax ;与中间各层 FFN/Attn 的输出维 相同,都是 d model d_{\text{model}} dmodel 进、V V V 出。§3 侧重「嵌入与绑权概念」;§7 侧重「整栈末端 LM Head 的数据流与 Qwen2 按规模选 tied/untied 」。更细的 Qwen 1 untied 动机与公式排版可与 Transformer 17. Qwen 1 / Qwen 1.5 架构介绍 对照。
8. Qwen2 相对 Qwen 1 / Qwen 1.5 的小结表
| 维度 | Qwen 1 | Qwen 1.5 | Qwen2(本报告) |
|---|---|---|---|
| 注意力 | 报告基线 MHA | 部分规格 GQA(如 32B) | 稠密全系 GQA |
| FFN 中间维 | 报告 8 3 d \frac{8}{3}d 38d | 依配置 | 表 1 Intermediate Size |
| 词表 | \\sim152K 叙述 | 与生态一致 | 151,646(文内固定) |
| Embedding | untied | 多 untied | 小模型 tied,大模型 untied |
| 长上下文 | 推理技巧为主 + 1.5 的 32K 产品化 | 统一 32K 等 | 训练 32K + RoPE 10 6 10^6 106 + YARN + DCA → 约 128K |
| MoE | --- | 有 Qwen1.5-MoE 线 | Qwen2-57B-A14B 等,细粒度 + 共享专家 |
9. 参考文献与链接汇总
| 主题 | 链接 |
|---|---|
| Qwen2 Technical Report | https://arxiv.org/pdf/2407.10671 |
| Qwen(Qwen1)Technical Report | https://arxiv.org/pdf/2309.16609 |
| Qwen 1 / Qwen 1.5 博客 | https://blog.csdn.net/zyctimes/article/details/159692526 |
| Decoder Only Transformer 博客 | https://blog.csdn.net/zyctimes/article/details/158771582?spm=1001.2014.3001.5501 |
| LLaMA 架构 博客 | https://blog.csdn.net/zyctimes/article/details/158923114?spm=1001.2014.3001.5501 |
| Qwen2 代码与权重 | https://github.com/QwenLM/Qwen2 、 https://huggingface.co/Qwen |