基于多模态大模型的城市道路积水智能检测系统实战
摘要
随着城市化进程加速,极端天气频发导致的城市内涝问题日益严峻。传统的人工巡检方式效率低下、响应滞后,难以满足现代城市防汛需求。本文将深入探讨如何利用多模态大模型技术构建一套智能积水检测系统,实现从图像采集到风险预警的全流程自动化。我们将以通义千问 Qwen-VL-Max 为核心,详细讲解系统架构设计、Prompt 工程、结构化输出控制等关键技术,并分享实际开发中的经验与最佳实践。
1. 背景与问题分析
1.1 城市内涝治理的挑战
城市内涝是困扰现代城市管理的重大难题。据统计,我国每年因城市内涝造成的直接经济损失超过千亿元,更严重威胁市民生命财产安全。传统的人工巡查模式面临以下痛点:
| 痛点 | 具体表现 | 影响 |
|---|---|---|
| 响应滞后 | 依赖人工上报,从发现险情到处置往往需要数小时 | 错过最佳抢险时机 |
| 覆盖不足 | 巡检人员有限,无法实现全域实时监控 | 盲区多,隐患难以及时发现 |
| 标准不一 | 不同人员判定标准差异大,主观性强 | 决策依据不可靠 |
| 数据孤岛 | 历史数据难以有效利用,无法形成知识积累 | 经验传承困难 |
1.2 AI 技术的破局之道
近年来,以 GPT-4V、Qwen-VL 为代表的多模态大模型展现出强大的图像理解能力,为城市积水智能检测带来了新的可能:
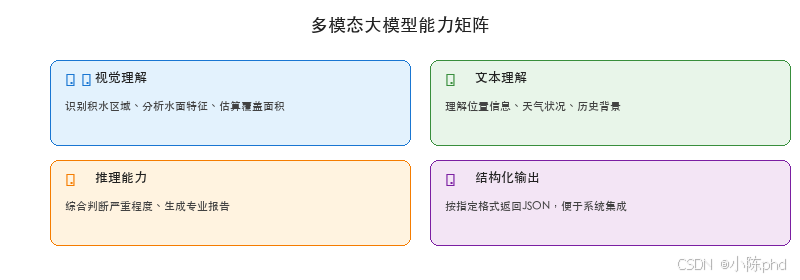
通过构建基于多模态大模型的智能体(Agent),我们可以实现:
- 7×24小时不间断监控:对接城市摄像头网络,实时分析
- 标准化判定:统一判定标准,消除人为差异
- 秒级响应:从图像上传到结果返回仅需数秒
- 知识沉淀:每次判定结果存入数据库,形成可查询的历史记录
2. 系统架构设计
2.1 整体架构
本系统采用分层架构设计,各层职责清晰,便于维护和扩展:
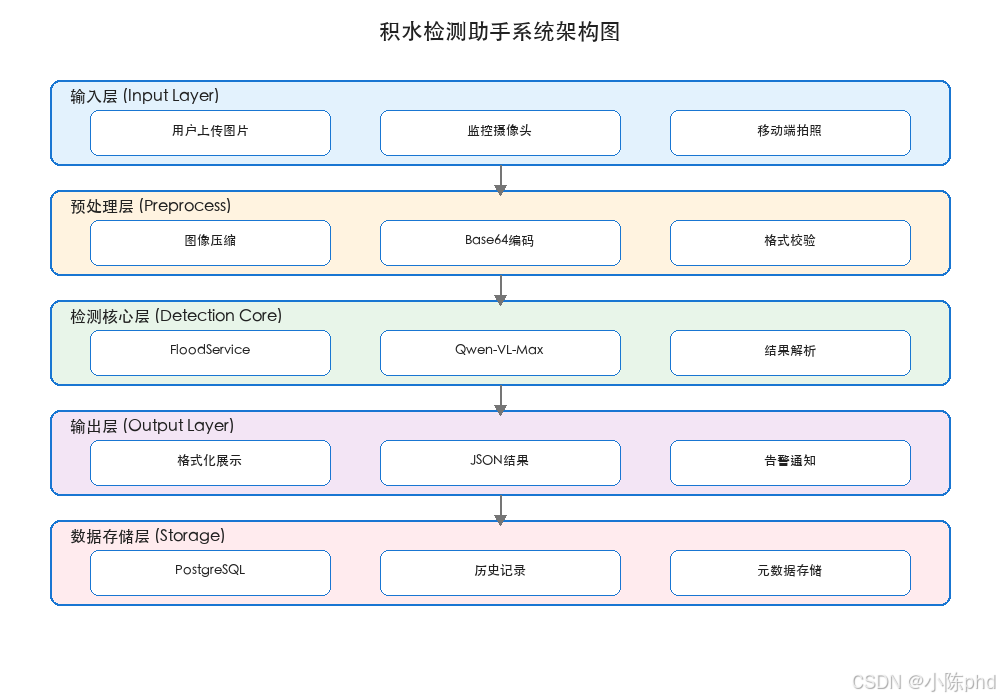
2.2 核心组件说明
2.2.1 FloodService - 积水检测服务
这是系统的核心服务,负责协调图像处理和模型推理:
python
@inject
@dataclass
class FloodService:
"""积水检测服务
使用 Qwen-VL-Max 多模态模型分析图片,判定积水情况。
Attributes:
llm_provider: LLM Provider(注入)
"""
llm_provider: QwenProvider核心能力:
| 能力 | 实现方式 | 技术要点 |
|---|---|---|
| 图像压缩 | PIL 库动态调整尺寸和质量 | 自适应压缩,平衡清晰度与传输效率 |
| 多模态推理 | OpenAI-compatible API 调用 | 支持文本+图像混合输入 |
| 结构化输出 | JSON Schema 约束 + Prompt 工程 | 确保输出格式稳定可解析 |
| 错误处理 | 多层 try-catch + 降级策略 | 提升系统健壮性 |
2.2.2 ChatService - 智能会话服务
为了实现记忆功能,我们将积水检测集成到聊天系统中:
3. 技术方案选型:YOLO vs 多模态大模型
在构建积水检测系统时,我们面临一个重要的技术选型问题:使用传统的计算机视觉目标检测算法(如 YOLO),还是采用新兴的多模态大模型技术?本章将详细对比两种方案的优劣,并解释为什么选择多模态大模型。
3.1 方案对比总览

3.2 YOLO 方案分析
YOLO (You Only Look Once) 是工业界广泛应用的目标检测算法,以其速度快、精度高著称。
YOLO 优势:
| 优势 | 说明 | 适用场景 |
|---|---|---|
| 实时性强 | 单张图片推理仅需毫秒级 | 需要实时视频监控的场景 |
| 部署成本低 | 模型可在边缘设备运行 | 算力受限的环境 |
| 确定性高 | 输出边界框坐标,易于验证 | 需要精确定位的场景 |
YOLO 局限性:
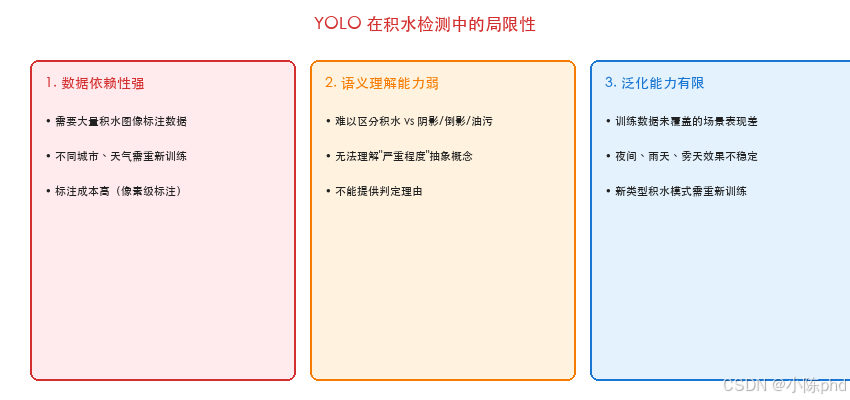
3.3 多模态大模型方案分析
多模态大模型(如 Qwen-VL-Max、GPT-4V)通过海量数据预训练,具备强大的视觉理解和推理能力。
核心优势:
| 优势 | 技术原理 | 业务价值 |
|---|---|---|
| 零样本学习 | 预训练获得通用视觉知识 | 无需准备训练数据,开箱即用 |
| 语义理解 | 跨模态对齐 + 上下文推理 | 准确区分积水与干扰物 |
| 可解释性 | 生成自然语言描述 | 提供判定理由,便于人工审核 |
| 严重程度评估 | 理解"轻度/中度/重度"概念 | 直接输出业务所需分级结果 |
技术代价:
- 推理延迟:API 调用需要 1-3 秒(可通过异步处理缓解)
- 成本问题:按调用量计费,高频场景成本较高
- 网络依赖:需要稳定的网络连接
3.4 为什么我们选择大模型方案
综合考虑城市积水检测的业务特点,我们选择多模态大模型方案:
1. 业务匹配度高
城市积水检测的核心需求:
- ✅ 严重程度分级:大模型原生支持,YOLO 无法实现
- ✅ 复杂环境适应:大模型对阴影、夜晚、雨天有更好鲁棒性
- ✅ 快速部署:无需收集训练数据,2 周即可上线
2. 数据成本考量
YOLO 方案数据成本估算:
├── 数据收集:10,000 张积水图片
├── 人工标注:每张 5 分钟 × 50元/小时 = 4.2元/张
├── 标注成本:10,000 × 4.2 = 42,000 元
├── 模型训练:GPU 算力 500 元
├── 迭代优化:3 轮 × 10,000 = 30,000 元
└── 总计:约 72,500 元,耗时 2-3 个月
大模型方案成本:
├── API 调用:0.02 元/张 × 10,000 = 200 元
├── 开发成本:2 周 × 2人 = 4 人周
└── 总计:开发成本 + 200 元,耗时 2 周3. 长期演进能力
大模型方案具备更好的演进空间:
- 可通过 Prompt 工程快速调整判定标准
- 支持多模态输入(图像 + 文本描述 + 地理位置)
- 随着模型升级,检测能力自动提升
3.5 结论
| 评估维度 | YOLO | 多模态大模型 | 推荐 |
|---|---|---|---|
| 实时性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | YOLO |
| 准确率 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 大模型 |
| 部署速度 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 大模型 |
| 可解释性 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 大模型 |
| 成本(低频) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 大模型 |
| 成本(高频) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | YOLO |
最终选择:多模态大模型方案
理由:城市积水检测属于低频但高价值的场景(仅在暴雨期间高频),对实时性要求不极端,但对准确率、可解释性、快速部署有强需求,大模型方案更符合业务特点。
4. 多模态大模型原理详解
4.1 什么是多模态大模型
多模态大模型(Multimodal Large Language Model, MLLM)是能够同时理解和生成多种模态数据(文本、图像、音频、视频)的人工智能模型。与传统单模态模型相比,它具有以下特点:
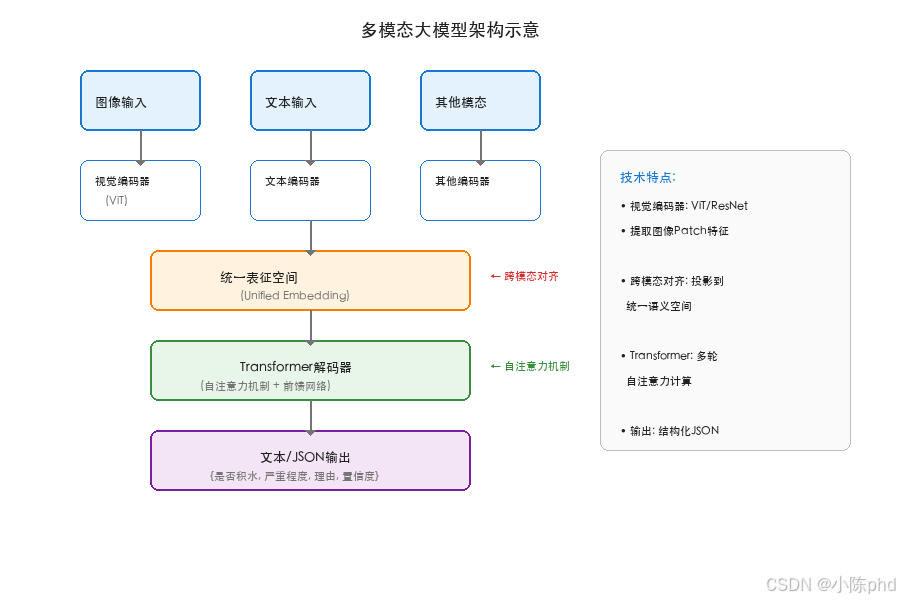
4.2 Qwen-VL-Max 技术特点
Qwen-VL-Max 是阿里云通义千问系列的多模态旗舰模型,在积水检测场景中表现优异:
| 特性 | 说明 | 对积水检测的价值 |
|---|---|---|
| 高分辨率支持 | 支持高分辨率图像输入 | 能看清细节,准确识别小面积积水 |
| 细粒度理解 | 能识别图像中的细节特征 | 区分积水与阴影、油污等干扰 |
| 中文优化 | 针对中文场景深度优化 | 理解中文提示词更准确 |
| 结构化输出 | 支持 JSON 格式输出 | 便于系统集成和数据处理 |
4.3 视觉理解的核心机制
大模型理解图像的核心在于视觉编码器 (Vision Encoder)和跨模态对齐(Cross-modal Alignment):
python
# 伪代码示意:多模态模型如何处理图像输入
class MultimodalProcessor:
def process_image(self, image: Image) -> Tensor:
"""图像编码过程"""
# 1. 图像分块(Patch Embedding)
# 将图像切分为 14x14 或 16x16 的小块
patches = self.patchify(image) # [H, W, C] -> [N, D]
# 2. 添加位置编码(Positional Encoding)
# 让模型知道每个 patch 在原图的位置
patches_with_pos = patches + self.positional_embedding
# 3. 视觉 Transformer 编码
# 通过多层自注意力提取特征
visual_features = self.vision_transformer(patches_with_pos)
return visual_features
def align_with_text(self, visual_features: Tensor) -> Tensor:
"""跨模态对齐"""
# 将视觉特征投影到与文本相同的表征空间
aligned_features = self.projection_layer(visual_features)
return aligned_features5. Prompt 工程与结构化输出
5.1 系统提示词设计
Prompt 是与大模型交互的核心,精心设计的 Prompt 能显著提升输出质量。我们的积水检测 Prompt 采用角色设定 + 任务定义 + 标准规范 + 输出格式的四段式结构:
python
FLOOD_DETECTION_SYSTEM_PROMPT = """你是一位专业的城市积水识别AI判定专家,精通计算机视觉和城市防汛业务。你将基于提供的城市监控视频帧/图片,严格按照给定的规则进行判定。
# 判定任务
请严格执行以下三步任务:
1. **积水存在性判定**:判断画面中是否存在积水。必须符合"与路面/地面存在明显视觉差异、具有液体反光特性、连续分布、不随行人/车辆移动而消失"的特征。需明确排除阴影、倒影、洒水、油污等干扰。
2. **严重程度分级**:如果存在积水,请根据面积占比和视觉特征判定其严重程度。
3. **输出结构化结果**:严格按照指定格式输出,无需任何额外的闲聊或解释。
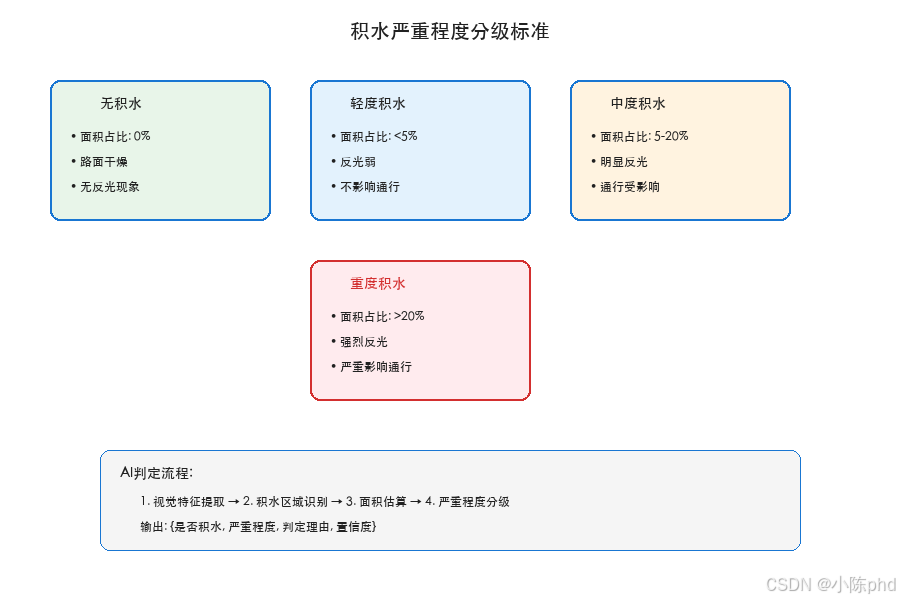
# 严重程度判定标准
- **轻度积水**:面积占比 < 5%。反光弱,路面纹理清晰,不影响通行。
- **中度积水**:面积占比 5% - 20%。有明显反光或边界模糊,部分路面被覆盖,通行受轻微影响。
- **重度积水**:面积占比 > 20%。反光强烈或大面积覆盖路面,纹理完全被遮挡,严重影响通行,可能漫过路沿石。
# 输出格式要求
请严格遵循以下JSON格式输出,不要包含任何其他内容:
{
"isFlooded": "是", // 枚举值:是 / 否
"severity": "轻度", // 枚举值:轻度 / 中度 / 重度 / 无
"reason": [
"理由1:描述判断是否积水的视觉依据",
"理由2:描述判断严重程度的依据,包括面积占比、反光、纹理等"
],
"confidence": 0.92 // 置信度,0-1之间
}"""4.2 Prompt 设计技巧解析
5.2.1 角色设定(Role Prompting)
❌ 普通写法:
"请分析这张图片是否有积水"
✅ 角色设定写法:
"你是一位专业的城市积水识别AI判定专家,精通计算机视觉和城市防汛业务"原理:大模型通过海量文本训练,学习到了不同领域的专业知识和表达习惯。明确角色能激活模型相关的知识区域,使回答更专业。
5.2.2 思维链(Chain-of-Thought)
我们将判定过程分解为三步:
- 积水存在性判定
- 严重程度分级
- 输出结构化结果
这种分步指导让模型按逻辑顺序思考,减少遗漏和错误。
5.2.3 少样本示例(Few-shot Learning)
虽然我们的 Prompt 中没有显式给出示例,但通过详细的判定标准描述,实际上提供了隐式的样本特征:
- **轻度积水**:面积占比 < 5%。反光弱,路面纹理清晰,不影响通行。
↑ 特征描述 = 隐式正样本5.3 结构化输出控制
大模型的输出本质上是概率采样,如何确保输出格式稳定?我们采用多层保障机制:

后处理代码示例:
python
def _parse_response(self, content: str) -> FloodDetectResult:
"""解析 LLM 响应为结构化结果"""
# 1. 尝试从 Markdown 代码块中提取 JSON
json_str = content
if "```json" in content:
json_str = content.split("```json")[1].split("```")[0].strip()
elif "```" in content:
json_str = content.split("```")[1].split("```")[0].strip()
try:
data = json.loads(json_str)
# 2. 字段映射(支持中英文)
is_flooded = data.get("isFlooded") or data.get("is_flooded") or "否"
severity = data.get("severity") or data.get("积水程度") or "无"
# 3. 标准化枚举值
if is_flooded not in ["是", "否"]:
is_flooded = "是" if is_flooded in ["yes", "true"] else "否"
return FloodDetectResult(
is_flooded=is_flooded,
severity=severity,
reason=reason,
confidence=float(confidence)
)
except json.JSONDecodeError:
# 4. 降级策略:返回默认结果
return FloodDetectResult(
is_flooded="否",
severity="无",
reason=["解析失败,无法判定"],
confidence=0.0
)6. 图像处理与优化
6.1 图像压缩策略
大模型 API 通常有图像大小限制(如 Qwen-VL-Max 限制 base64 编码后不超过 10MB)。我们需要在保证识别精度的前提下,对图像进行智能压缩:
python
def _compress_image(self, image_base64: str) -> str:
"""压缩图片以适应 API 限制
策略:先检查大小,超过则压缩尺寸和质量
"""
original_length = len(image_base64)
# 如果已经小于限制,直接返回
if original_length <= MAX_BASE64_LENGTH:
return image_base64
# 解码 base64
image_data = base64.b64decode(image_base64)
img = Image.open(io.BytesIO(image_data))
# 逐步压缩直到满足大小要求
current_size = MAX_IMAGE_SIZE # 1920px
quality = JPEG_QUALITY # 85
while current_size >= 640: # 最小尺寸限制
# 调整尺寸
img_resized = img.copy()
img_resized.thumbnail((current_size, current_size),
Image.Resampling.LANCZOS)
# 转换为 JPEG
buffer = io.BytesIO()
if img_resized.mode in ('RGBA', 'LA', 'P'):
img_resized = img_resized.convert('RGB')
img_resized.save(buffer, format='JPEG',
quality=quality, optimize=True)
compressed_base64 = base64.b64encode(
buffer.getvalue()).decode('utf-8')
if len(compressed_base64) <= MAX_BASE64_LENGTH:
return compressed_base64
# 降低质量再试
quality -= 10
if quality < 60:
quality = JPEG_QUALITY
current_size = int(current_size * 0.8)6.2 压缩策略对比
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 固定尺寸 | 简单可控 | 小图被放大,大图压缩过度 | 图像尺寸相对统一 |
| 自适应压缩(我们的方案) | 平衡质量与大小 | 实现稍复杂 | 图像尺寸差异大 |
| 智能裁剪 | 保留关键区域 | 可能丢失上下文 | 已知 ROI 位置 |
6.3 图像预处理建议
对于积水检测场景,以下预处理能提升识别准确率:
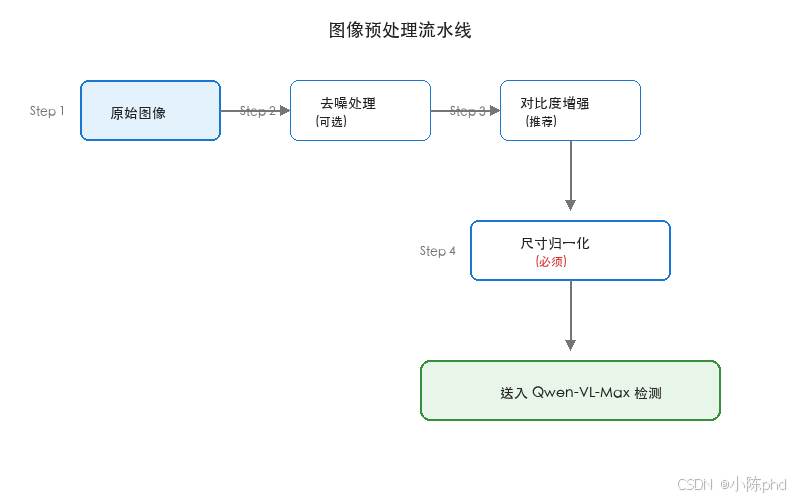
7. 记忆功能与会话管理
7.1 为什么需要记忆功能
积水检测不是一次性任务,需要:
- 历史追溯:查看某地点过去是否发生过积水
- 趋势分析:分析积水频率和严重程度变化
- 决策支持:为防汛调度提供数据依据
7.2 记忆功能实现方案
我们将积水检测集成到聊天系统中,复用现有的 ChatSession 和 ChatMessage 模型:
python
class ChatSession(Base):
"""会话模型"""
__tablename__ = "chat_sessions"
session_id: Mapped[str] # 会话唯一标识
user_id: Mapped[str] # 用户 ID
title: Mapped[str] # 会话标题
template_id: Mapped[str] # 模板 ID(flood_detection)
system_prompt: Mapped[str] # 系统提示词
model: Mapped[str] # 使用的模型
# ... 其他字段
class ChatMessage(Base):
"""消息模型"""
__tablename__ = "chat_messages"
session_id: Mapped[str] # 关联会话
role: Mapped[str] # user / assistant
content: Mapped[str] # 消息内容
meta: Mapped[dict] # 元数据(存储检测结果)
created_at: Mapped[datetime]7.3 检测结果存储结构
json
{
"message_type": "flood_detection",
"has_image": true,
"flood_result": {
"is_flooded": "是",
"severity": "中度",
"reason": [
"画面中央区域有明显积水反光",
"积水面积约占画面15%,属于中度积水"
],
"confidence": 0.89
},
"latency_ms": 2345
}7.4 会话类型路由
python
async def chat(self, user_id, session_id, message, image_base64=None):
# 获取会话配置
config = await self._get_session_config(session_id)
# 检查是否为积水检测会话
is_flood_detection = config.get("template_id") == "flood_detection"
if is_flood_detection and image_base64:
# 走积水检测流程
return await self._handle_flood_detection(...)
else:
# 走普通对话流程
return await self._handle_normal_chat(...)8. 模板配置与快速启动
8.1 预设模板设计
为了让用户快速创建积水检测会话,我们在 templates.yaml 中定义了专门的模板:
yaml
- id: flood_detection
name: 积水检测助手
description: 城市道路积水识别专家,支持图片分析和历史记录查询
icon: "🌊"
model: qwen-vl-max
temperature: 0.1
max_tokens: 2048
sort_order: 6
system_prompt: |
你是一位专业的城市积水识别AI判定专家...8.2 模板参数说明
| 参数 | 值 | 说明 |
|---|---|---|
model |
qwen-vl-max |
必须使用多模态模型 |
temperature |
0.1 |
低温度确保输出稳定 |
max_tokens |
2048 |
足够容纳 JSON 输出 |
sort_order |
6 |
在模板列表中的排序 |
9. 实战演示
9.1 创建积水检测会话
bash
# 1. 创建会话
curl -X POST http://localhost:5000/api/v1/chat/sessions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_TOKEN" \
-d '{
"title": "监控点A-积水检测",
"template_id": "flood_detection"
}'
# 返回
{
"session_id": "flood-001",
"title": "监控点A-积水检测",
"message": "会话创建成功"
}9.2 上传图片进行检测
bash
# 2. 发送图片进行检测
curl -X POST http://localhost:5000/api/v1/chat/stream \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_TOKEN" \
-d '{
"session_id": "flood-001",
"message": "请检测这张图片",
"image_base64": "/9j/4AAQSkZJRgABAQ..."
}'
# 流式返回
data: ## 积水检测结果
data: **是否存在积水**: 是
data: **严重程度**: 中度
data: **置信度**: 89%
data: **判定理由**:
data: 1. 画面中央区域有明显积水反光
data: 2. 积水面积约占画面15%,属于中度积水
data: [DONE]9.3 查询历史记录
bash
# 3. 获取历史检测记录
curl http://localhost:5000/api/v1/chat/history/flood-001 \
-H "Authorization: Bearer YOUR_TOKEN"
# 返回
{
"messages": [
{
"id": "msg-001",
"role": "user",
"content": "[图片上传]",
"created_at": "2024-01-15 14:30:00"
},
{
"id": "msg-002",
"role": "assistant",
"content": "## 积水检测结果...",
"created_at": "2024-01-15 14:30:05",
"meta": {
"flood_result": {
"is_flooded": "是",
"severity": "中度",
"confidence": 0.89
}
}
}
],
"total": 2
}10. 性能优化与最佳实践
10.1 性能指标
| 指标 | 目标值 | 优化手段 |
|---|---|---|
| 响应时间 | < 3s | 异步处理、连接池 |
| 并发处理 | 100+ QPS | 模型调用异步化 |
| 准确率 | > 90% | Prompt 优化、后处理 |
| 可用性 | 99.9% | 降级策略、重试机制 |
10.2 最佳实践总结
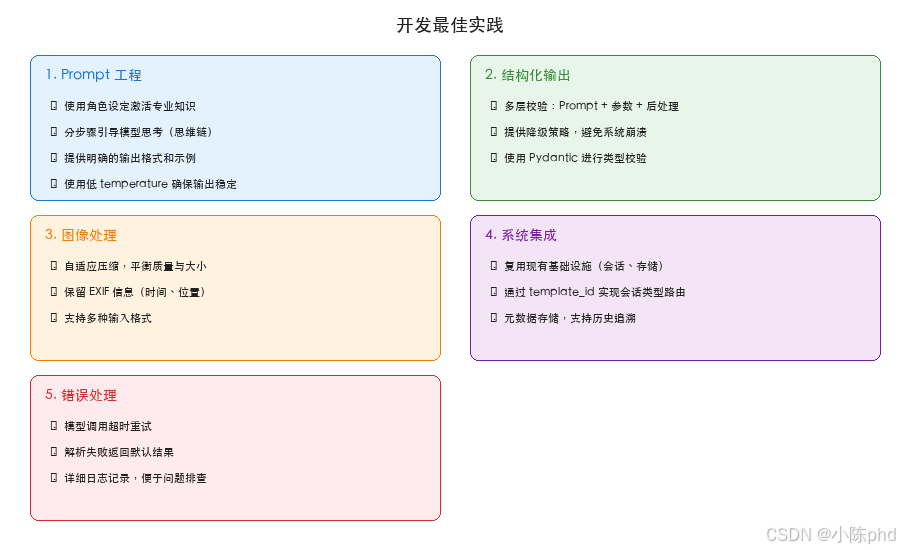
11. 总结与展望
11.1 项目成果
本文详细介绍了基于多模态大模型的城市道路积水智能检测系统的完整实现,包括:
- 系统架构:分层设计,职责清晰,易于扩展
- 多模态技术:深入讲解视觉理解原理和 Qwen-VL-Max 特点
- Prompt 工程:角色设定、思维链、结构化输出等技巧
- 工程实践:图像压缩、记忆功能、模板配置等实现细节
11.2 未来展望
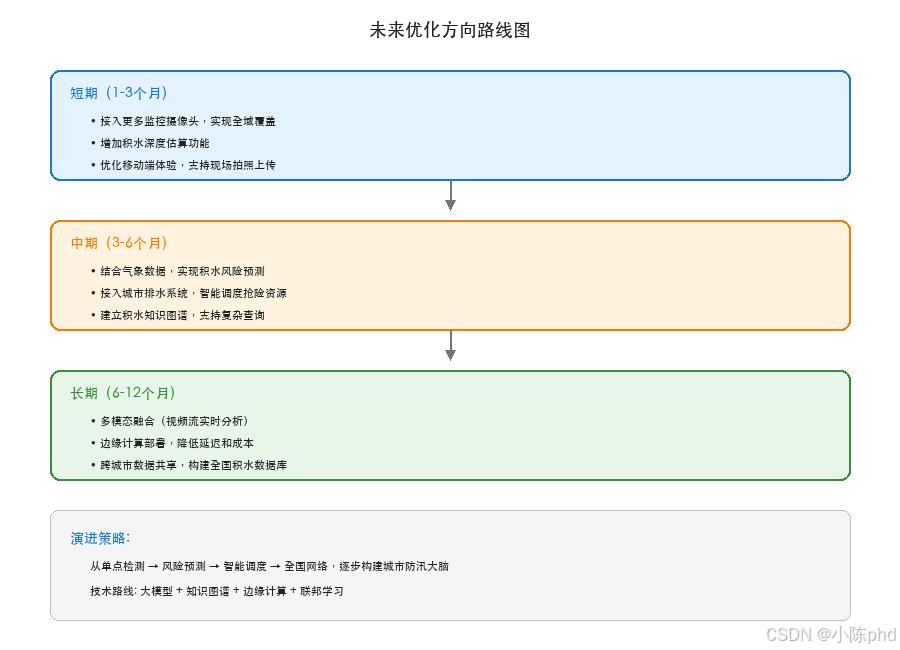
11.3 写在最后
大模型技术正在深刻改变各行各业的运作模式。在智慧城市建设中,多模态大模型为传统视觉检测任务带来了全新的解决思路。希望本文的实践经验能为读者提供有价值的参考,共同推动 AI 技术在城市治理中的落地应用。