页面自动化报错怎么处理
一般考虑是什么问题导致的,报错问题最常见的有:
- 元素找不到
Selenium最常见。
解决方式: 检查element是否定位正确,是否用了动态id或者绝对路径。
定位无问题,则加显式等待,等元素出现再操作。
确认元素是否在iframe里面,不在需要切换。
页面是否加载完成,没有则需要等待加载完成后再操作。
- 等待超时(页面没加载完就操作)
解决方法: 增加显式等待。
优化定位方式,用更稳定的定位(id、data-testid、text)。
检查页面是否卡顿、接口是否慢加载。
避免使用强制等待 Thread.sleep ()。
- 元素不可交互(被遮挡、隐藏、未渲染)
解决方法: 等元素可以点击再操作。
检查是否有遮挡,有的话关闭弹窗之类的遮挡再操作
滚动页面到元素可见的位置
用js执行点击输入操作
- 会话失效(driver 崩溃 / 关闭)
解决方法: 确保driver只初始化一次,不要重复关闭
用例执行完再quit()退出,中途不要关闭浏览器
驱动版本和浏览器版本要匹配
避免多线程同时操作一个driver
- 接口异常(网络、接口异常)
解决方法: 检查环境地址,网络是否通畅
增加请求时间
检查请求头,参数是否正确
失败自动重试
显式等待:让代码专门等待某一个元素,等他满足条件再执行操作。
appium、python八股文
appium:Appium 是一个开源的自动化测试工具,可用于测试原生、混合和移动 Web 应用程序。它支持多种移动平台,如 Android 和 iOS。基于WebDriver协议,支持python/java等语言,跨平台、不侵入源码。
Appium工作原理:启动一个server,脚本发送给server,server调用手机底层驱动(ui automator2/XCUITest),驱动控制手机执行操作。
Appium环境需要什么:JDK,Android SDK,Appium Server(或者Appium Sesktop),python+Appium-python-Client,真机(或模拟器)开启开发者选项+USB调试。
元素定位方法:ID,AccessibilityId(最稳),XPath(不稳定才用),className,AndroidUiAutomator。
常见操作:点击click(),输入send_keys(),滑动、上下拉刷新,截屏,切换H5/原生页面,处理toast、弹窗。
常见报错和解决方式:Session 创建失败(检查包名、手机连接、端口占用、服务启动);无权限(开启USB调试,允许模拟点击);元素找不到(加显示等待,页面是否切换,定位是否正常);driver 崩溃/会话失效(driver不要多次quit,确保appium不中断,检查驱动版本)。
三大等待
- 强制等待
time.sleep(3)死等
-
隐式等待(全局等待元素出现)
driver.implicitly_wait(10)
-
显式等待(等待某一个元素满足条件)。自动化优先显式等待。
WebDriverWait(driver,10).until( EC.presence_of_element_located((By.ID,"id")) )
或
WebDriverWait(driver,10).until( EC. visibility_of_element_located((By.ID,"id")) )
presence_of_element_located:DOM有就可以,元素可以隐藏,只要标签加载出来就可以,最宽松。
visibility_of_element_located:DOM有,并且能看见,最严格。
element_to_be_clickable:元素存在、可见并且可以点击,最最最严格。
PO模式是什么:是page Object,把每个页面封装成一个类,只做元素定位和操作方法,实现页面和用例的分离,页面变了不用改所有的用例,代码易维护,复用性高。
自动化不稳定怎么办:加显式等待;优化定位;加失败重试;处理弹窗、加载;避免使用绝对路径;截图+日志(明白是用例问题还是元素没加载或者页面错了)。
WebDriver理解:W3C 标准协议,提供了统一api,用于找元素(findelment/click/sendkeys),写selenium/appium本质上都是调用webdriver协议,使用chromeDriver、GeckoDriver/IOSDriver等去实现,和浏览器或设备进行通信。WebDriver是规则,Driver是实现操作人。
WebDriver的优点:跨平台、跨浏览器;支持多语言;模拟真实用户的操作;开源免费且生态成熟;W3C标准协议,稳定。
不用WebDriver的有:Playwright,Puppeteer,基于Chrome DevTools Protocol(CDP 协议);sikulix,airtest,PyAutoGUI,不找元素,不看DOM,靠截图,图像匹配去点击。
生成器Generator:函数+yield,可以返回多次的函数,一个函数写多个yield返回值,在外部多次调用next即可按顺序获得yield值。

闭包 Closure:函数里嵌套函数,内部函数引用外部函数变量,外部函数已结束,变量依然存活(跑完还能记住变量)。

浅拷贝:只是赋值,嵌套的还是共用的,改一个,两个都被修改。

深拷贝:两个都是独立的,修改任意一个都不影响另一个。

面向对象OOP:封装、继承、多态(子类对父类同一个方法的不同实现override重写)。
Override(重写) :子类把父类的函数重新写一遍,方法名、参数、返回值都相同。Python 其实不支持,java和C++才有。
Overload(重载):同一个类里面,方法名相同,参数不同,注意:只有返回值不同时,不构成重载。
Overwrite(覆写/重写) :赋值覆盖。
Redefine(重定义):在子类中定义了一个同名但是参数不同的方法,父类的方法会被隐藏不使用。

Selenium核心:web页面自动化工具,通过驱动控制浏览器。
有三部分:
- WebDriver:控制浏览器(核心)
- IDE:录制回放
- Grid:分布式并发执行,一个Hub接收多个电脑/浏览器(Node节点)发来的测试脚本请求,Hub自动找空闲的Node执行。
装饰器、迭代器
装饰器:不改原有代码的情况下,给代码增加额外功能,比如计时、权限判断,用@使用装饰器。

迭代器:只能往前不能往后遍历,可以记住遍历位置的对象,把数据取出来,节约内存,不是一次把所有数据加载到内存,for底层就是用的迭代器。

测试理论、测试金字塔
软件测试是什么:在规定的条件下对程序进行操作,发现缺陷,衡量质量,判断是否满足要求。
软件测试的目的:发现缺陷(bug);保证质量;降低风险;提升用户体验。
测试的原则:测试只表示bug存在,不能证明程序没有bug;100%测试所有bug是不可能的;尽早测试;缺陷集群效应(80%bug集中在20%模块中);杀虫剂悖论(用例要经常更新);依赖环境、场景。
软件的生命周期模型:瀑布模型、V模型、敏捷模型、迭代增量模型。
- 瀑布模型:线性,按照顺序一步一步走,不能回头。编码完再测试,问题容易后期发现,修改成本高。
- V模型:左边开发,右边测试,每个阶段都有对应测试。
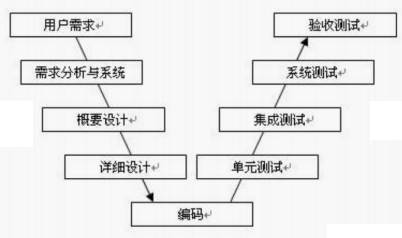
- 敏捷模型:快速迭代,测试全程参与。如果需求变得快,后续容易乱。
- 迭代增量模型:分多次小版本开发,每次迭代交付一部分功能。如果设计不好,后期架构容易乱。
测试的级别:单元测试、集成测试、系统测试、验收测试。
测试类型:性能测试(压力、负载、并发);功能测试;安全测试;兼容性测试;易用性测试;接口测试;ui自动化测试。
测试金字塔 :从下到上分成三层,分别是:单元测试、接口服务测试、ui测试。底层越多越稳定,自动化测试放大单元和接口,ui只做核心用例。
为什么ui要少写自动化:ui频繁变动,维护成本高;运行慢;容易受环境、网络、弹窗影响;稳定性远远不如接口和单元测试。
为什么接口测试是重点:接口比ui稳定;覆盖业务逻辑深;执行速度快;适合持续集成。
行为驱动开发和测试驱动开发
行为驱动开发(BDD) :Behavior_Driven Development,面向业务行为,而不是代码,产品、开发、测试使用同一套语言沟通。先写行为描述->再实现。
测试驱动开发(TDD) :Test_Driven Development,先写测试用例,再写代码,让测试通过。开发自己写测试,面向代码、函数、接口,流程分为红黄绿三步,红(失败的用例)、绿(最少代码,测试通过)、重构(优化代码,测试通过)。
前后端测试策略
前端测试策略:功能测试、兼容性测试(浏览器,分辨率,操作系统)、ui界面测试(字体,颜色,对齐,响应)、交互与易用性(状态,提示,快捷键)、性能体验、前端安全(敏感信息显示,权限)。
后端测试策略:接口功能测试(请求方法,参数校验,返回值),数据库测试(增删改查,字段长度,事件一致性),异常测试,性能测试(接口响应时间,并发量,吞吐量),安全测试(权限操作,sql注入,敏感信息加密)。
并发量:同一时间多少人在用。
吞吐量:系统单位时间内可以处理多少请求/数据。
Sql注入:用户故意在输入框写sql语句,骗过后端直接在数据库执行,从而窃取、篡改、删除数据。
预防sql注入:禁止字符串拼接sql;使用ORM框架;进行参数校验。
ORM框架:对象关系映射,把数据库表映射成一个python类,不写sql也可以操作数据库。常见的框架有Python:Django ORM、SQLAlchemy;Java:MyBatis、Hibernate;Go:GORM。

python实现页面自动化常用方法
python
driver=webdriver.Chrom()
driver.get(http://www.123.com) #打开浏览器
driver.finde_element(By.ID,"id")
driver.find_element(By.NAME, "name")
driver.find_element(By.XPATH, "//input[@id='kw']")
driver.find_element(By.CSS_SELECTOR, "#kw")
ele.send_keys("内容") #输入内容
ele.click()
ele.clear()
text = ele.text
value = ele.get_attribute("value")
is_displayed = ele.is_displayed()
is_enabled = ele.is_enabled()
driver.close() # 关当前窗口
driver.quit() # 关整个驱动
页面加载有问题怎么处理
- 优先加显式等待
python
Driver.implicitly_wait(10) #隐式等待
或
WebDriverWait(driver,15).until(EC.visibility_of_element_located((By.ID,"id"))- 刷新页面
- 判断页面是否加载完成
- 滚动到元素位置
- 清理缓存
持续集成(CI/CD)
CI:continuous integration 持续集成,小批量多次提交代码,编译,进行单元测试,静态检查。
CD:Continuous Delivery/Deployment持续交付/部署,代码提交后,自动打包,自动化测试后部署到生产环境。
流程:
- 提交代码到Git、SVN
- Jenkins、Git Lab 自动拉取代码
- 自动构建、编译
- 自动执行测试用例
- 生成报告、发送通知
- 自动部署到环境
为什么要做CD/CI:提高交付速度;尽快发现bug;减少人工重复操作;发布更稳定可靠。
Sit uat测试区别是什么
SIT(System Integration Testing)系统集成测试 :是开发和测试工程师进行测试,根据设计文档、接口文档 测试模块间的接口,是在搭建的模拟环境下进行测试,在单元测试之后。
UAT(User Acceptance Testing)用户验收测试 :是客户或者最终使用的用户进行测试,是按照需求文档 、业务场景进行的业务流程测试,环境更接近实际使用环境,而不是测试人员搭建的模拟测试环境。
工作流程大概是什么样的
按照V模型回答。
先进行需求评审 ,写测试用例 ,进行用例评审 ,然后准备测试环境 ,开发体测后做冒烟测试 ,通过后进行功能测试 、集成测试 ,发现bug后提交bug并跟踪 ,修复后做回归测试 ,输出测试报告,评估是否可以上线。
冒烟测试:全面开始测之前,快速测一遍核心功能是否能使用,能使用就继续细测,不能使用就是冒烟了,打回不用测了。
回归测试的范围是什么?
- 修改的bug
- 关联模块和关联流程
- 核心主流程
- 容易出问题的地方
谁来界定测试的范围?
测试负责人/测试组长,开发和产品一起根据需求文档、开发改动点和风险点来确认测试范围。最终范围还是以用户需求为准,。如果后期用户有新增或者变更,测试范围也要及时同步,相应扩大,重新评估测试工作量和风险。
测试完成间隙会做些什么?
- 整理之前的bug,补充完善复现步骤,截图和日志,确保开发可以快速定位
- 梳理还没有执行的用例,准备测试数据、配置文件,保证之后可以快速快速进行测试
- 查看之前bug的修复情况,准备回归测试
- 补充一些之前没有覆盖到的异常场景、边界场景用例
- 优化一下自动化测试的脚本
测试管理、迭代管理用什么工具?
bug管理用的jira进行bug提交、跟踪和关闭bug;测试用例管理用的是testrial,在上面编写用例、维护步骤、记录执行情况;代码版本管理和版本提交用的SVN。
比如给你项目如何开展自动化?
如何考虑开展自动化:
- 考虑项目类型
看是桌面客户端、Web还是移动端或者接口?项目技术栈是什么。
Web使用Selenium,桌面用WinAppDriver或者pyAutoGui,接口用pytest或Requests。
- 确定自动化测试范围
先做核心流程,重复执行多,稳定性要求高的,
- 搭建测试框架
- 编写用例
- 集成和持续运行
Requests进行接口自动化:
- 安装requests库,定义接口地址和参数
- 通过get/post发送请求,获取返回值进行断言
- 结合pytest实现用例管理、批量执行和报告输出
可以用使用Allure生成可视化的HTML图形测试报告
安装pytest-allure-adaptor插件:
bash
pip install pytest-allure-adaptor输出报告
python
pytest -s -q --alluredir report
或
pytest -s -q --alluredir [path_to_report_dir]生产html报告
python
allure generate report/ -o report/html- 集成到jenkins
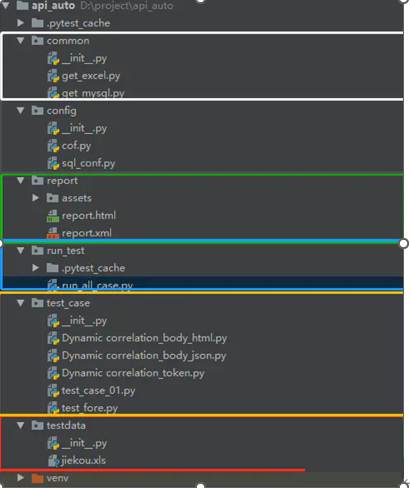
目录结构类似:
- config 配置文件(python package)#directory和python package大同小异
- common 公共的方法(python package)
- testdata 测试数据(python package)
- test_case测试用例(python package)
- report 报告(directory)
- run_case 测试执行(python package)
- log 日志
OPT(短信/邮箱验证码)如何自动化
- 让开发直接提供测试后门/接口**(优先)**
测试环境下,调用接口直接获取当前验证码,或者固定一个测试OPT。
- 邮件OPT可以直接读取邮件接口
- 屏蔽OPT验证
让测试配置白名单,跳过验证。
SQL常见问题
- 查询去重distinct
python
Select distinct name from user_table- 分页limit n offset m
python
Select * from user_table limit 10 offset 20- 联表查询 user_table u join order_table o on u.id=o.id
python
select u.*, o.order_no from user u left join orders o on u.id = o.user_id;- 内联 inner join
像交集,只筛选交集部分。
- 排序 order by DESC(降序)/ASC(升序)
python
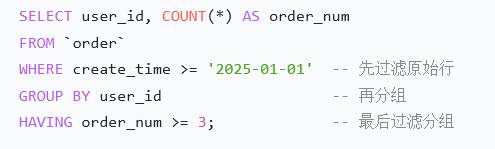
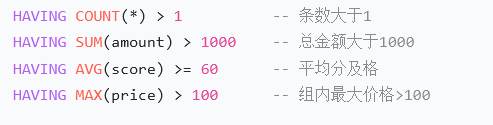
SELECT * FROM user ORDER BY create_time DESC;- 查重复数据 group by having
python
select phone, count(*) from user group by phone having count(*) > 1;having:必须在group by后面,对group by结果过滤。
- 事务的四大特点:原子性、一致性、隔离性、持久性
- 事务隔离级别 :读未提交、读已提交、可重复读、串行化。Mysql默认可重复读。
- 数据库三大范式 :1NF(列不可再分,一个格子里面只能放一个值)、2NF(非主键字段完全依赖主键,一张表只讲一件事)、3NF(不传递依赖)。作用:减少冗余,避免数据不一致。
其他范式:BCNF(所有决定因素都是码)、4NF(消除多值依赖,一张表一个一对多)、5NF(拆到不能再拆)
3NF理解:如图,班级依赖班级Id,不应该在学生表中
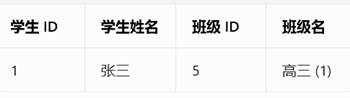
BCNF理解:谁说的算,谁就是主键。
4NF理解:不允许有多个1对多的关系,需要变成学生 ID, 爱好,和学生 ID, 课程
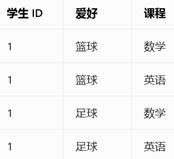
- 几个读
脏读:读到未提交的数据。
不可重复度:同一事务两次查询不一致。
幻读:范围查询突然多了/少了数据。
- 锁
共享锁(读);排它锁(写)。读写互斥,写写互斥,保证并发安全。
你作为管理人员,有组员不认真测试怎么办?
- 私下沟通了解原因
是否是对需求不理解,还是态度问题或者其他困难。
- 明确测试规范和标准、覆盖要求
- 加强检查过程
- 引导责任意识
- 如果还是不改正,就按照流程报给上级
黑盒、灰盒、白盒的区别有哪些?用例设计方法有哪些?
黑盒测试:不看代码,只测功能。
白盒测试:看代码逻辑、分支、路径。
灰盒测试:既看接口又看功能(接口测试常使用)。
黑盒测试用例设计:
- 等价划分法:把相同情况的分成一类,只测代表数据。
- 边界值分析法:最小值、最大值、中间值、略大最大值、略小最小值。
- 场景法:模拟用户真是业务流程。
- 错误推断法:按照经验、常识猜测bug出现位置补充用例。
- 判定表:多个条件组合,列出所有可能性。
- 因果图法:原因->结果的逻辑图,转化为判定表。
白盒测试用例设计 :语句 < 判定 < 条件 < 判定条件 < 路径
- 语句覆盖 (最弱):每一行代码至少执行一次。
- 判定覆盖(分支覆盖):每个判断,真假都要至少走一次。
- 条件覆盖:每个子条件都取真、取假。
- 分支条件覆盖:每个判断真假和子条件真假都覆盖。
- 路径覆盖 (最强):覆盖程序中所有可能执行的路径。
软件的生命周期
- 可行性研究
- 需求分析
- 概要说明
- 详细设计
- 编码
- 测试
- 部署
- 维护
软件测试的生命周期
- 需求分析
- 制定测试计划
- 用例设计
- 测试环境搭建
- 执行测试用例
- 缺陷管理、回归测试
- 测试总结,上线
Bug生命周期:新建->打开->修复->关闭。
多表联查
- inner join

- left join: 以左表为主,全部显示;右表匹配不到就显示 NULL

- group by:一对多关系联表会出现数据重复,使用
- full join:左右表全部保留,匹配不上的一边填 NULL
- 子查询

Union/union all: 把两条独立查询的结果上下拼在一起
*UNION:自动去重,慢一点
*UNION ALL:不去重,更快,推荐用
测试bug的提交注重什么方面
- 复现步骤清晰
- 预期结果和实际结果写清楚
- 环境信息清楚
系统版本、软件版本、设备版本、网络环境
- 添加辅助信息
截图、日志、报错信息、包返回参数
- 严重等级和优先级处理
如果遇到bug开发不认的情况怎么处理
- 先尝试自己复现,确认不是环境、数据、操作导致的,可稳定复现
- 拿需求文档确认规范
- 复现步骤的截图、日志和数据
- 拉上产品仪器确认,是否是bug或者是否变更需求
- 沟通,对事不对人
- 按照流程记录问题与跟进
风控系统的模块有哪些?
- 数据采集
手机用户信息、设备信息、环境信息、交易信息、历史记录
- 规则引擎
短时间多次下单、异地登录、大额交易、异常ip/设备
- 策略管理
对规则进行编排、组合,形成风控策略;支持不同业务、不同场景走不同策略。
- 风险决策引擎
根据规则、模型、名单,综合计算风险分数,输出:通过、拒绝、人工审核、二次验证
- 黑白灰名单
管理高风险用户、欺诈账号、可信用户,快速拦截或放行。
- 特征计算
实时计算风险特征:登录频率、交易频次、地域跳跃、设备相似度
- 风控模型管理(机器学习)
用模型识别复杂欺诈行为,比规则更智能,比如反欺诈模型、信用模型、团伙欺诈识别。
- 实时流处理
高并发下保证低延迟,毫秒级做出风控决策。
- 告警与监控模块
异常规则触发、系统延迟、大量拦截时自动告警。
- 风控后台管理平台
供运营或审核人员使用的:规则配置、策略调整、订单审核、风险报表、日志查询
- 日志与审计
记录每一次决策依据:触发了哪些规则、分数多少、为什么拒绝,便于回溯、申诉、定位问题。
有个保险相关项目,我们应该评估用户的哪些方面
- 用户身份信息
- 健康状况和病史
- 投保行为风险
- 理赔历史与风险
- 财务能力和经济能力
- 职业与生活风险
- 关系风险
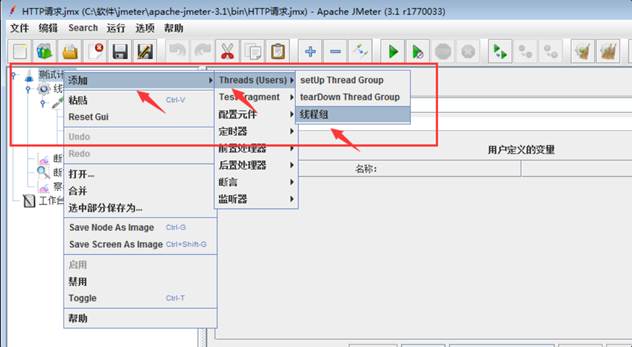
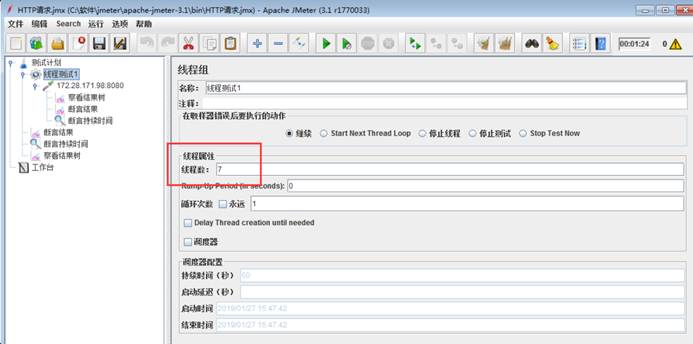
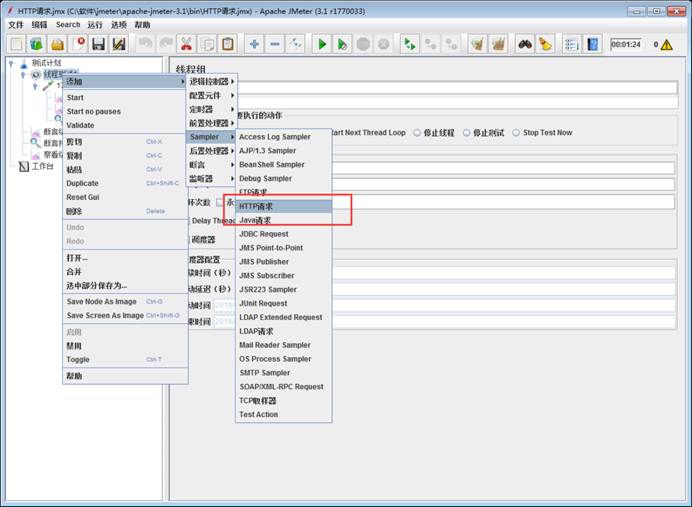
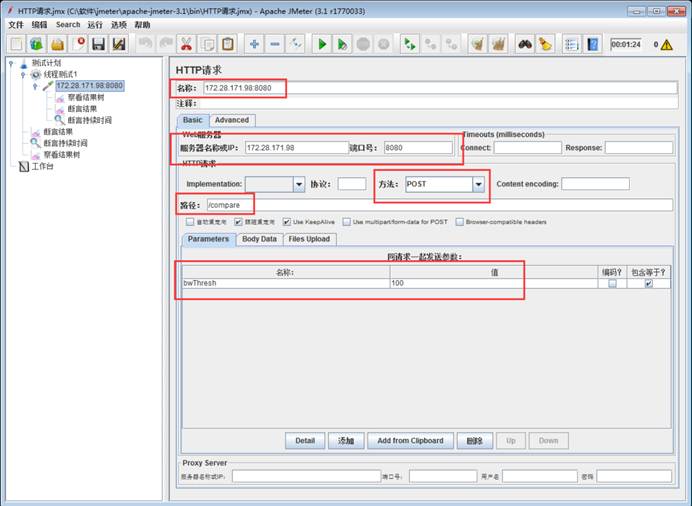
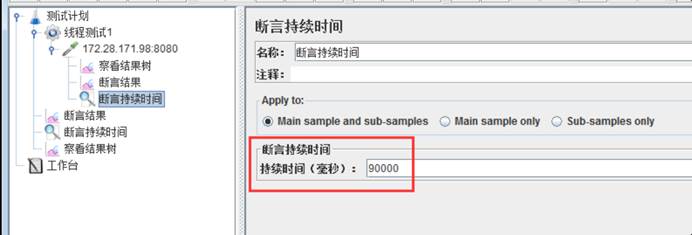
jmeter 3000个用户50分钟同时运行,参数怎么配置
Number of Threads:3000 (3000个用户)
Ramp-Up Period:60(秒)(60s慢慢启动,免得一下启动3000个并发把系统压垮)
Loop Count:Forever(永远循环)(永远循环,保证用户一直运行)
勾选:Scheduler(调度器)
Duration(seconds):30000(50 分钟 = 30000 秒)(到时间自动停止)
Startup delay:0
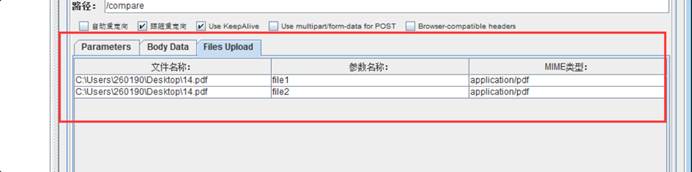
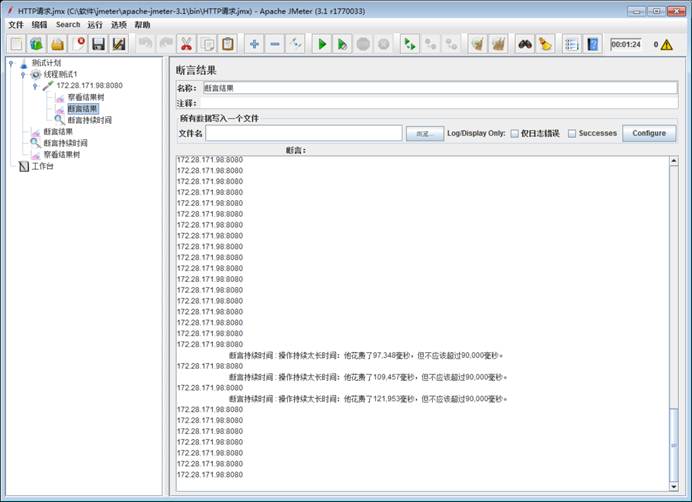
有个数据文件50条记录,设定循环永久,但是只执行了一次就结束了,为什么?
- 数据配置没有设置"Recycle on EOF",没有允许循环读取,不勾的话:数据读完 5 条就不再读取,直接结束。
- Stop thread on EOF(读完停止线程) 设置成了 True,一旦读完 5 条数据,线程直接停止
Content-type支持格式
- application/json(最常用)
传输json,后端现在基本都用这个。
- application/x-www-form-urlencoded
表单默认传输格式,参数格式a=1&b=2。
- multipart/form-data
上传文件使用,传图片和文件必须使用。
- text/plain
纯文本格式。
- application/xml、text/xml
- text/html
- text/css
- application/javascript / text/javascript
- image/jpeg、image/png、image/gif
- application/pdf
- application/octet-stream
未知二进制流,下载文件时常见。
常见的报错代码
|------------|---------------------------|-------------------|-----------------------------------|--------------------|
| 1xx信息类 | 2xx成功 | 3XX重定向 | 4xx客户端错误 | 5xx服务端错误 |
| 100 继续 | 200 ok请求成功 | 301 永久重定向 | 400 请求参数错误 | 500 服务器内部错误 |
| 100 继续 | 201 create 创建成功 | 302 临时重定向 | 401 未登录 / 鉴权失败 | 502 网关错误 |
| 100 继续 | 204 not content 成功无返回 | 304 资源未修改(缓存) | 403 禁止访问(权限不够) | 503 服务不可用 / 过载 |
| 100 继续 | 204 not content 成功无返回 | 304 资源未修改(缓存) | 404 接口不存在 | 504 网关超时 |
| 100 继续 | 204 not content 成功无返回 | 304 资源未修改(缓存) | 405 方法不允许 (GET/POST 用错) | 504 网关超时 |
| 100 继续 | 204 not content 成功无返回 | 304 资源未修改(缓存) | 415 不支持的媒体类型 (Content-Type 错) | 504 网关超时 |
| 100 继续 | 204 not content 成功无返回 | 304 资源未修改(缓存) | 429 请求频率超限 | 504 网关超时 |
xpath语法
- 绝对路径(从根找)
python
/html/body/div- 相对路径(任意位置找)
python
//div- 根据ID定位
python
//*[@id="xxx"]- 根据class定位
python
//*[@class="xxx"]- 根据文本定位
python
//*[text()="登录"]- 包含某段文字(模糊匹配)
python
//*[contains(text(),"提交")- 包含某个属性(模糊)
python
//*[contains(@class,"btn")]- 层级绑定(父->子)
python
//div[@id="a"]/input- Following::* 找当前节点后的所有元素
python
//span[text()="手机号"]/following::input- following-sibling::* 找当前节点的弟弟节点(同级、在后面)
python
//span[text()="手机号"]/following-sibling::input- preceding::* 找当前节点之前的元素
python
//input[@id="phone1"]/preceding::span- preceding-sibling::* 找当前节点的哥哥节点(同级、在前面)
python
//input[@id="phone1"]/preceding-sibling::span- parent::* 或简写 .. 找父节点
python
//span[text()="手机号"]/..- child::* 找子节点(就是普通 /)
python
//div[@class="box"]/child::input