本篇学习目标
本篇是全书的起点。第1章从宏观视角出发,帮助我们建立对大语言模型(LLM)的基础认知。本篇(上半部分)将完整覆盖:
- 大语言模型背后基本概念的高层次解释
- LLM 的能力边界和"理解"的真正含义
- LLM 在现实世界中的广泛应用
- 构建 LLM 的两阶段训练范式:预训练 + 微调
引言:LLM 开启 NLP 新时代
大语言模型(LLMs),例如 OpenAI 的 ChatGPT 中使用的模型,是过去几年间发展起来的深度神经网络模型。它们为自然语言处理(Natural Language Processing, NLP)开启了一个全新时代。
在大语言模型出现之前,传统方法在某些任务上表现出色,比如邮件垃圾分类 这样的分类任务,以及可以用手工规则或简单模型捕捉的直接模式识别任务。然而,在需要复杂理解和生成能力的语言任务中,传统方法通常力不从心------例如解析详细指令、进行上下文分析、或者创建连贯且符合上下文的原创文本。举个具体的例子:以前的语言模型无法根据一组关键词来写一封邮件------而这对当代 LLM 来说轻而易举。
LLM 具有理解、生成和解释人类语言的卓越能力。但这里有一个重要的澄清:当我们说语言模型"理解"语言时,我们的意思是它们能够以看起来连贯且符合上下文的方式 处理和生成文本------并非说它们拥有类似人类的意识或理解力。
LLM 的能力得益于深度学习的进步。深度学习是机器学习和人工智能(AI)中专注于神经网络的一个子领域。LLM 在海量文本数据上进行训练,这使得它们能够比以往的方法捕捉到更深层次的上下文信息和人类语言的微妙之处。因此,LLM 在各种 NLP 任务上显著提升了性能,包括文本翻译、情感分析、问答系统等等。
当代 LLM 与早期 NLP 模型之间还有一个重要的区别:早期 NLP 模型通常是为特定任务 而设计的------虽然它们在各自的狭窄应用领域表现出色,但 LLM 展现出了跨越广泛 NLP 任务的综合能力。
LLM 的成功可以归因于两个关键因素:
- Transformer 架构------作为许多 LLM 的基础架构
- 海量训练数据------让模型能够捕获大量的语言细微差别、上下文和模式,这些是很难通过人工方式编码的
这种向基于 Transformer 架构和大型训练数据集的转变,从根本上改变了 NLP 领域,为理解和与人类语言交互提供了更强大的工具。
从本章开始,我们将为完成本系列的核心目标奠定基础:通过在代码中逐步实现一个基于 Transformer 架构的类 ChatGPT 的 LLM,来深入理解 LLM 的工作原理。
1.1 什么是 LLM?
基本定义
LLM(Large Language Model,大语言模型)是一种设计用来理解、生成和回应类人文本的神经网络 。这些模型是在海量文本数据上训练的深度神经网络,有时训练数据涵盖了互联网上几乎所有公开可用文本的很大一部分。
"大"的双重含义
"大语言模型"中的"大"同时指向两层含义:
- 模型的参数规模:这些模型通常拥有数百亿甚至数千亿个参数。参数就是网络中的可调权重,它们在训练过程中被优化,目标是预测序列中的下一个词。
- 训练数据的规模:训练所用的数据集极其庞大。
核心训练任务:下一词预测
下一词预测(Next-word prediction)是 LLM 训练的核心方法。为什么选择这个任务?因为它利用了语言天然的顺序性质(sequential nature),让模型在训练过程中学会理解文本中的上下文、结构和关系。
令人惊讶的是,这个任务本身非常简单------仅仅是预测一段文本中接下来会出现哪个词------但它却能训练出如此强大的模型。这让许多研究人员都感到意外。我们将在后续章节中逐步讨论和实现这个下一词训练过程。
Transformer 架构
LLM 采用一种叫做 Transformer 的架构(将在 1.4 节中更详细讨论),这种架构允许模型在进行预测时选择性地关注输入的不同部分,这使得它们特别擅长处理人类语言中的细微差别和复杂性。
LLM 与生成式 AI
由于 LLM 能够生成文本,它们也常常被称为**生成式人工智能(generative AI 或 GenAI)**的一种形式。
AI 领域的层级关系
AI 涵盖了创造能够执行需要类人智能任务的机器的更广泛领域,包括理解语言、识别模式和做出决策,并包含机器学习和深度学习等子领域。
正如这幅不同领域之间关系的层级图所示,LLM 代表了深度学习技术的一种特定应用,利用其处理和生成类人文本的能力。深度学习是机器学习的一个专门分支,专注于使用多层神经网络。而机器学习和深度学习都是旨在实现让计算机从数据中学习并执行通常需要人类智能的任务的算法。
用层级结构来理解它们的关系:

什么是机器学习?
实现 AI 的算法是机器学习领域的重点。具体来说,机器学习涉及开发能够从数据中学习 并基于数据做出预测或决策的算法,而无需被显式编程。
为了说明这一点,请想象一个垃圾邮件过滤器。与其手动编写规则来识别垃圾邮件,不如给机器学习算法提供被标记为垃圾邮件和合法邮件的样本。通过在训练数据集上最小化预测误差,模型随后学会识别表明垃圾邮件特征的模式,使其能够将新邮件分类为垃圾邮件或合法邮件。
深度学习 vs 传统机器学习
深度学习是机器学习的一个子集,专注于使用三层及以上的神经网络 (也称为深度神经网络)来对数据中的复杂模式和抽象进行建模。与深度学习不同,传统机器学习需要手动特征提取------这意味着人类专家需要为模型识别和选择最相关的特征。
虽然如今 AI 领域主要由机器学习和深度学习主导,但它还包括其他方法,例如基于规则的系统、遗传算法、专家系统、模糊逻辑或符号推理。
垃圾邮件分类:传统 ML vs 深度学习的详细对比
回到垃圾邮件分类的例子,两种方法的差异非常明显:
传统机器学习方式:人类专家可能手动从邮件文本中提取特征,例如某些触发词(如"奖品""中奖""免费")的出现频率、感叹号的数量、全大写单词的使用、以及可疑链接的存在。然后基于这些专家定义的特征创建数据集来训练模型。
深度学习方式:不需要手动特征提取。人类专家不需要为深度学习模型识别和选择最相关的特征------模型直接从原始数据中自动学习特征表示。
但需要注意:无论是传统机器学习还是深度学习,在垃圾邮件分类中你仍然需要收集标签(如"垃圾邮件"或"非垃圾邮件"),这些标签需要由专家或用户来收集。
接下来的各节将涵盖 LLM 当前能解决的一些问题、LLM 所应对的挑战,以及本书将实现的通用 LLM 架构。
1.2 LLM 的应用
由于具备解析和理解非结构化文本数据的高级能力,LLM 在各个领域有着广泛的应用。如今 LLM 被用于机器翻译、新文本生成、情感分析、文本摘要以及许多其他任务。LLM 近年来还被用于内容创作,例如撰写小说、文章,甚至计算机代码。
LLM 界面实现了用户和 AI 系统之间的自然语言沟通。图中的截图展示了 ChatGPT 按照用户的规格要求来写诗的过程。
LLM 还可以驱动复杂的聊天机器人和虚拟助手,例如 OpenAI 的 ChatGPT 或 Google 的 Gemini(原名 Bard),它们可以回答用户查询并增强 Google Search 或 Microsoft Bing 等传统搜索引擎。
此外,LLM 可用于从医学或法律等专业领域的海量文本中进行有效的知识检索。这包括筛选文档、总结长篇段落以及回答技术性问题。
总之,LLM 对于自动化几乎任何涉及解析和生成文本的任务都非常有价值。它们的应用几乎是无限的,随着我们不断创新和探索使用这些模型的新方法,LLM 有潜力重新定义我们与技术的关系,使其更具对话性、更直观、更易于访问。
本书的重点 :我们将专注于理解 LLM 从底层如何工作,编写一个能够生成文本的 LLM。我们还将学习让 LLM 执行查询的技术------从回答问题到总结文本、将文本翻译成不同语言等等。换句话说,我们将通过逐步构建来学习像 ChatGPT 这样复杂的 LLM 助手是如何工作的。
1.3 构建和使用 LLM 的各阶段
为什么要自己构建 LLM?
从头编写 LLM 是理解其机制和局限性的绝佳练习。同时,它还让我们具备了在自己的领域特定数据集或任务上预训练或微调现有开源 LLM 架构所需的知识。
研究已经表明,在建模性能方面,定制构建的 LLM------那些为特定任务或领域量身定制的模型------可以超越通用型 LLM(如 ChatGPT 提供的那些为广泛应用设计的模型)。相关例子包括:
- BloombergGPT:专门用于金融领域
- 医学问答 LLM:专门针对医学问答进行训练
两阶段训练过程
创建 LLM 的一般过程包括预训练(pretraining)和微调(finetuning)。
"预训练"中的"预(pre)"指的是初始阶段,在这个阶段中,像 LLM 这样的模型在一个大型的、多样化的数据集上进行训练,以发展对语言的广泛理解。这个预训练后的模型随后作为基础资源,可以通过微调进一步精炼------微调是指模型在一个更窄的、更针对特定任务或领域的数据集上进行专门训练的过程。这个由预训练和微调组成的两阶段训练方法如 Figure 1.3 所示。
Figure 1.3 说明:预训练 LLM 涉及在大型文本数据集上进行下一词预测。预训练后的 LLM 可以使用较小的标注数据集进行微调。
阶段一:预训练
创建 LLM 的第一步是在大量文本数据语料库上训练它,有时称为原始文本(raw text) 。这里的"原始"指的是这些数据只是普通文本,没有任何标注信息。(可能会进行过滤,例如去除格式字符或未知语言的文档。)
注释 1 :具有机器学习背景的读者可能会注意到,传统机器学习模型和通过传统监督学习范式训练的深度神经网络通常需要标注信息。然而,LLM 的预训练阶段并非如此。在这个阶段,LLM 利用自监督学习(self-supervised learning),模型从输入数据本身生成自己的标签。这个概念将在本章后面介绍。
LLM 的第一个训练阶段也被称为预训练,产生一个初始的预训练 LLM,通常称为基座模型(base model)或基础模型(foundation model) 。一个典型的例子是 GPT-3 模型(ChatGPT 中最初提供的模型的前身)。这个模型能够进行文本补全(text completion) ,即完成用户提供的半写句子。它还具有有限的少样本能力(few-shot capabilities),意味着它可以基于少量示例学习执行新任务,而不需要大量训练数据。这将在下一节"使用 LLM 执行不同任务"中进一步说明。
阶段二:微调
在通过大型文本数据集训练获得预训练 LLM 后(LLM 被训练预测文本中的下一个词),我们可以在**标注数据(labeled data)**上进一步训练 LLM,这就是所谓的微调。
微调 LLM 最流行的两个类别包括:
1. 指令微调(Instruction-finetuning) :标注数据集由指令和回答对组成,例如一个翻译文本的查询,附带正确翻译的文本。
2. 分类微调(Classification finetuning) :标注数据集由文本和关联的类别标签组成,例如与"垃圾邮件"和"非垃圾邮件"标签关联的邮件。
可以用一个流程图来理解整个两阶段过程:

本书将涵盖预训练和微调 LLM 的代码实现,并在预训练基座 LLM 之后深入探讨指令微调和分类微调的细节。
关键概念深度解析
自监督学习:LLM 预训练的精妙之处
传统的监督学习需要人工标注数据------这既昂贵又耗时。LLM 的预训练巧妙地绕过了这个问题:
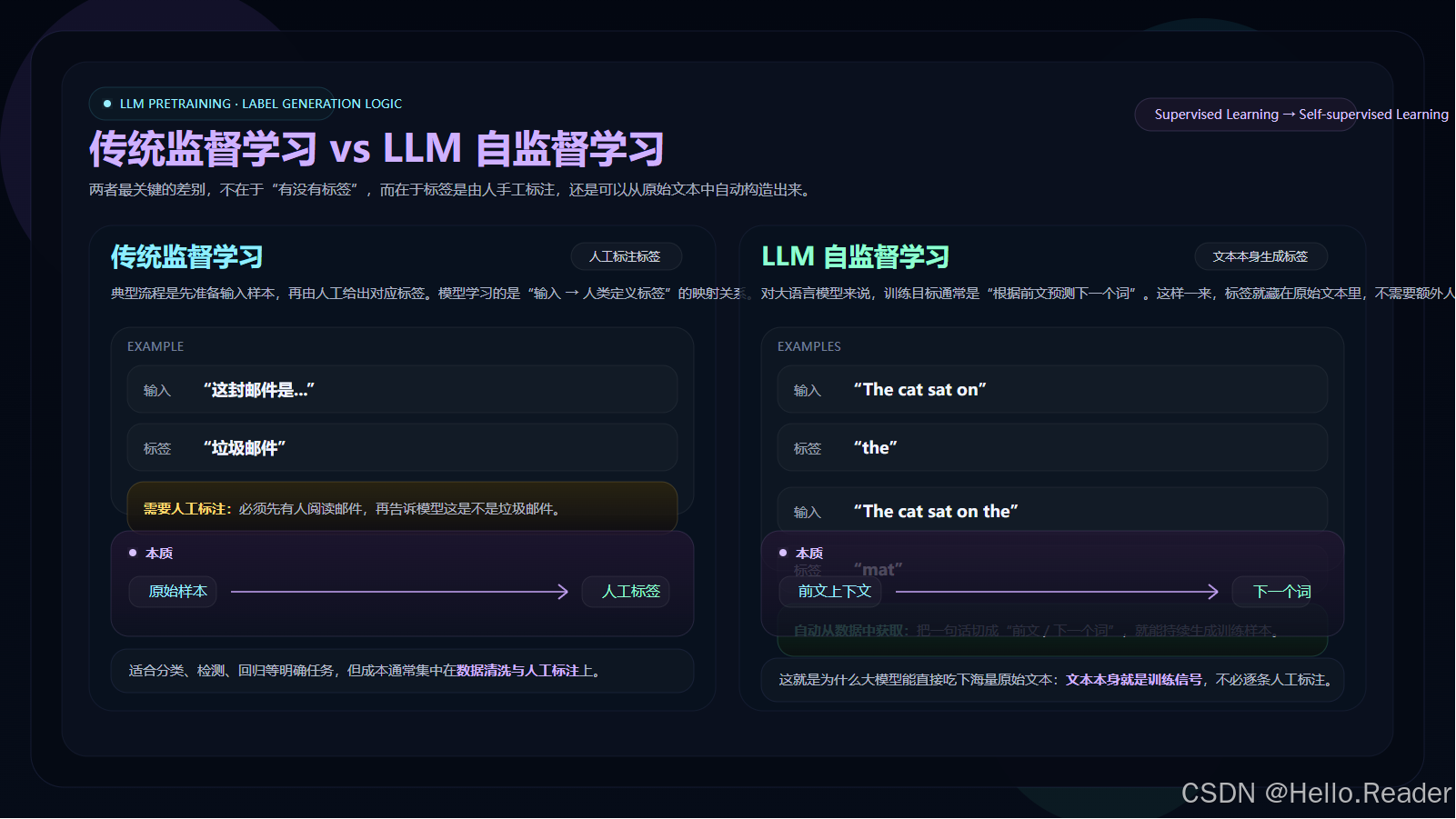
因为文本中每个词的"下一个词"天然就是训练标签,所以可以利用几乎无限的未标注文本数据来训练 LLM------这就是为什么 LLM 能在互联网规模的数据上进行训练。
基座模型 vs 微调模型:为什么需要两个阶段?
基座模型(如原始 GPT-3)虽然能力惊人,但它本质上只是一个"文本补全机器"------你给它半句话,它会续写下去。但它不擅长遵循指令、回答问题或进行对话。
微调解决了这个问题。通过在精心构建的指令-回答对数据集上微调,模型学会了"当用户问问题时,应该给出回答"这种交互模式。ChatGPT 正是通过在 GPT-3 基础上进行指令微调而诞生的。
为什么定制 LLM 能超越通用 LLM?
通用 LLM(如 ChatGPT)是"样样通"------它在大量多样化数据上训练,对各种主题都有一定了解。但在特定领域(如金融、医学),它可能不如专门在该领域数据上训练的模型。
原因在于数据分布的差异:金融文本有独特的术语、表达方式和推理模式,通用训练数据中这些内容可能占比很小。而 BloombergGPT 在大量金融数据上训练,自然更能理解金融语境。
本篇小结
| 概念 | 要点 |
|---|---|
| LLM 定义 | 在海量文本上训练的深度神经网络,能理解和生成类人文本 |
| "大"的含义 | 参数规模(数百亿-数千亿)+ 训练数据规模 |
| 核心训练任务 | 下一词预测------简单的任务产出强大的模型 |
| LLM "理解" 的含义 | 以连贯、符合上下文的方式处理文本,而非拥有人类意识 |
| AI→ML→DL→LLM | 层级关系,LLM 是深度学习的一种特定应用 |
| 传统 ML vs DL | 手动特征提取 vs 自动学习特征 |
| LLM 应用 | 翻译、生成、摘要、代码、聊天机器人、专业知识检索 |
| 两阶段训练 | ①预训练(海量无标签数据,自监督)→ ②微调(标注数据,指令/分类) |
| 基座模型 | 预训练产物,能文本补全和少样本学习(如 GPT-3) |
| 微调的两种类型 | 指令微调(→助手)、分类微调(→分类器) |
| 定制 LLM 的优势 | 在特定领域可超越通用 LLM(BloombergGPT、医学 QA) |
预习思考
在进入下一篇之前,可以思考以下问题:
- 为什么"下一词预测"这么简单的任务能训练出如此强大的模型? 提示:要准确预测下一个词,模型必须理解语法、语义、常识和逻辑。
- 自监督学习相比传统监督学习的核心优势是什么? 提示:想想标注成本和数据规模。
- 基座模型已经很强大了,为什么还需要微调? 提示:文本补全≠遵循指令。
- 如果你要为自己的行业构建一个专用 LLM,你会选择从头预训练还是微调一个现有模型?为什么? 提示:考虑计算成本和数据量。