LLM×MapReduce: Simplified Long-Sequence Processing using Large Language Models
目录
[②案例任务(World Count)](#②案例任务(World Count))
这篇文章提出了一种叫LLM×MapReduce的无需训练的长文本处理框架,旨在解决大预言模型因上下文长度限制而难以处理超长文本的问题。
一、问题背景
①大多数大语言模型的上下文长度有限,难以处理远超其窗口长的上下文;
②现有的扩展上下文方法为基于训练和无需训练两种。
A.基于训练的方法:通过额外的训练,直接修改模型内部参数,使其能够理解和处理更长的文本序列。
++++具体的做法:++++准备大量的长文本数据(长度超过模型原有限制),在这些长文本数据上对模型进行继续与训练或微调,训练过程中,模型会学习到长距离依赖关系。
++++优点:++++模型从数据中直接学习了长文本的内在规律,理论上对长上下文的理解更深刻。
++++缺点:++++成本,不灵活(一旦训练完成,模型的上下文长度就固定了。如果想要再次扩展,需要重新训练)
B.****无需训练的方法:****不改变模型本身的任何参数,而是通过外部策略、算法或框架, 让一个"短上下文"模型能够处理远超其训练长度的文本。
++++具体的做法:++++采用"分而治之"的策略,这正是本文所采用的方法。
①将长文本分割成多个短的、模型可以处理的"块"
②设计一个流程(MapReduce)来分别处理每个块,最后聚合所有块的信息,形成最终答案
③关键之处在于如何设计这个流程,以解决跨块依赖 和跨块冲突的问题(也就是本文的创新点)
注++a.跨块依赖:++回答问题的关键证据分散在不同的块中,彼此依赖;
注++++b.跨块冲突:++++不同块中的信息可能相互矛盾,模型需要有能力分辨和解决这些冲突。
++++优点:++++成本低,灵活
++++缺点:++++可能不是最优解,由于模型本身没有见过长文本,它可能无法像经过专门训练的模型那样完美的捕捉所有长距离依赖。
二、MapReduce(是一种分布式并行的编程模型。)
①技术实现:
++++工作流程:++++
1.大数据集被切分成多个小数据集;
2.小数据集以<key,value>方式输入Map函数中,
3.Map函数进行预处理,以<key,value>方式输出结果,并处理成<key,list(value)>结果;
4.以<key,list(value)>数据输入到Reduce函数中,最终汇总计算输出<key,value>结果。
②案例任务(World Count)
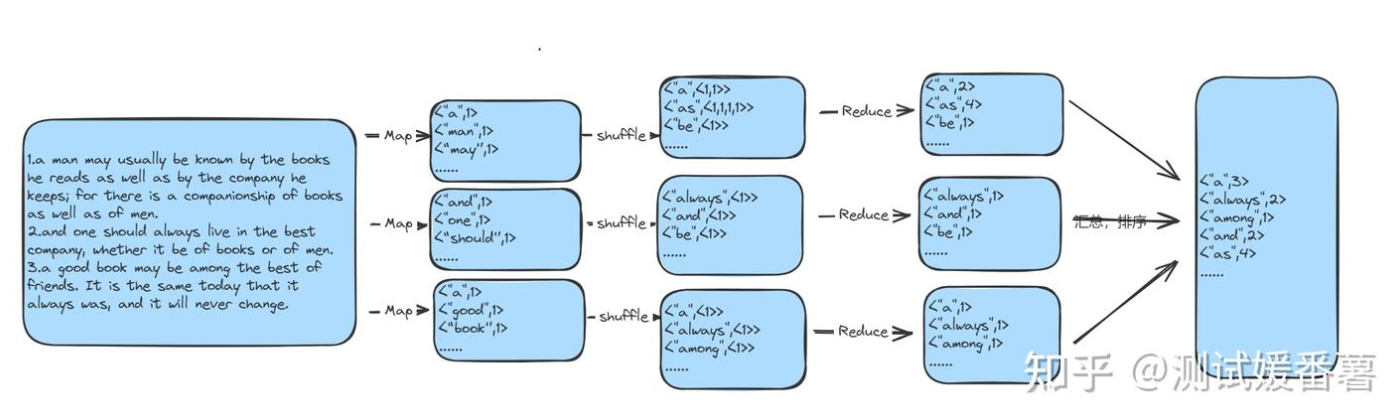
一个文本文件,包含大量单词,要求对文本中的单词进行频次统计,输出格式为(单词,频次),每一行一个单词。
-
判断任务是否满足MapReduce框架实现的前提条件:数据集可以分解成小的数据集,小的数据集可以完全独立并行处理。这里将一个文件进行分片,逻辑切分,以行号为主,如:行号为1--100分配给机器1的Map任务执行,行号101--200给机器2的Map任务执行。
-
设计Map任务的自定义规则:解析各自负责的分片内容以<key,value>形式输出中间结果,这里也就是<单词,1>的中间结果。并shuffle合并相同键值对,输出<key,List(value)>结果。
-
设计Reduce任务的自定义规则:汇总统计,排序,按照设定规则"单词 频次"输出。
-
文本详细处理的过程如图所示:
三、LLM×MapReduce框架
"分工"+"聚合"
每个工作节点只处理分配给自己的数据分块(或中间结果);X→{x_1,x_2,...x_n}
每个工作节点通过访问同一个LLM模型来执行任务。(通过中央服务器共享1个LLM)
阶段一:Map阶段(映射)
++++核心目标:++**++**对长文本的每个独立分块进行初步信息提取,为后续聚合准备结构化的、高质量的中间结果。
++++①输入++++:
a.长文本分块x_i
b.用户查询Q:需要回答的问题或需要执行的任务指令
++++②处理过程与函数++++:
a.处理函数:s_i = f_map(x_i , Q , theta)
b.实现方式:f_map()不是一个传统的编程函数,而是一个精心设计的提示词,用于引导与训练的LLM(参数为theta)执行特定任务。
++++③输出:++++
输出s_i是一个结构化的对象,包含四个强制性字段:
1.提取的信息:从当前分块x_i中提炼出的、与查询Q直接相关的关键事实或数据。
目的:保留原始证据,作为解决跨块依赖的基石。它确保了在后续阶段,即使不能访问全文,也能基于这些提取的信息进行推理。
****2.推理过程:****LLM从"提取的信息"推导出"答案"的思维链或逻辑解释。
目的:增加可解释性,辅助Reduce阶段(为最终的聚合提供更丰富的上下文,说明明每个中间结论是如何得到的)
****3.答案:****基于当前分块x_i的信息,对查询Q给出的直接回答。
特殊处理:如果经过推理,认为当前分块完全不包含相关信息,则输出NO Information,有助于在后续阶段快速过滤无效信息。
****4.置信度:****一个量化的分数。代表模型对当前"答案"的可靠性和完整性的自我评估。
目的:为解决跨块冲突提供关键的、可比较的量化依据。它是后续阶段进行决策权衡的"权重"。
阶段二:Collapse阶段(压缩)
核心目标: 当Map阶段输出的所有结构化结果{ s_1 , ... , s_N }的总长度仍然超过LLM的上下文窗口L时,对其进行中间层级的压缩和聚合,这是一个可选的、迭代的过程。
++++①输入:++++
a.一组Map输出g_j : 将N个s_i 分成K组。分组策略通常是顺序连接s_i ,直到加入下一个s_i会导致总长度超过L.
b.用户查询Q:与Map阶段相同的查询.
++++②处理过程与函数:++++
a.处理函数:c_j = f_collapse( g_j , Q ,theta )
b.实现方式:同样通过一个特定的Prompt来实现。这个Prompt会指导LLM如何整合一组Map的输出
c.处理逻辑:LLM需要阅读并理解组内所有的 s_i 的内容,然后生成一个新的、浓缩的结构化输出 c_j 。它不是重复Map的工作,而是在概括、去重、整合组内信息。例如:如果两个Map输出都提到了同一个事实,它可能会合并它们并综合其置信度。
++++③输出:++++
输出 c_j 的格式与Map阶段的输出 s_i 完全一致。同样包含:
a.提取的信息:对整个组 g_j 内关键信息的概括性总结;
b.推理过程:对整合过程的说明;
c.答案:基于整个组信息得出的中间答案;
d.置信度:对整合后答案的总体置信度。
阶段三:Reduce阶段(聚合)
核心目标: 整合所有中间信息,解决跨块依赖和冲突,生成最终答案。这是整个框架的决策中心。
①输入
- 所有的中间结果 { c_1 , ... , c_K } : 这些是经过Map和(可能多次)Collapse后得到的K个结构化信息对象。他们的总长度 ≤ L.
- 用户查询Q:原始的用户查询
②处理过程与函数:
a.处理函数: a = f_reduce({ c_1 , ... , c_K } , Q , theta )
b.实现方式:通过一个复杂的、旨在引导的批判性思维和整合推理的Prompt来 实现.
c.处理逻辑:Prompt会明确指导LLM执行以下操作:
1)全面审视:逐一阅读每个输入c_j中的四个组成部分。
2)解决跨块依赖:(利用各个c_j的推理过程来理解信息之间的逻辑关联)
3)解决跨块冲突:决策规则(当不同的c_j的答案出现矛盾时,优先采用告知新都来源的证据)
③输出:最终答案
四、数据流:
原始长文本→分块文本→结构化中间表示→压缩的中间表示→最终答案