文章目录
- 什么是JVM?
- 学习路线
- [JVM 内存结构](#JVM 内存结构)
-
-
- 程序计数器:
- 虚拟机栈
- 本地方法栈:
- 堆:
- 方法区:
-
- 定义:
- 组成:
- 方法区内存溢出:
- 运行常量池:
- 常量池、运行常量池、StringTable
- StringTable特性
- [StringTable 的位置](#StringTable 的位置)
- [StringTable 垃圾回收机制](#StringTable 垃圾回收机制)
- [StringTable 调优](#StringTable 调优)
- [直接内存:Direct Memory](#直接内存:Direct Memory)
- 垃圾回收
-
- [1. 如何判断对象可以回收](#1. 如何判断对象可以回收)
- [2. 垃圾回收算法](#2. 垃圾回收算法)
- [3. 分代垃圾回收](#3. 分代垃圾回收)
- [4. 垃圾回收器](#4. 垃圾回收器)
-
- 串行
- 吞吐量优先
- 响应时间优先
- 经典组合(历史常用)
- [工作原理 + 区别 + 优劣势](#工作原理 + 区别 + 优劣势)
-
- [1. Serial / Serial Old](#1. Serial / Serial Old)
- [2. ParNew](#2. ParNew)
- [3. Parallel Scavenge / Parallel Old](#3. Parallel Scavenge / Parallel Old)
- [4. CMS(Concurrent Mark Sweep)老年代](#4. CMS(Concurrent Mark Sweep)老年代)
- [5. G1(Garbage-First)](#5. G1(Garbage-First))
- [6. ZGC](#6. ZGC)
- 对比
- 生产环境如何选择?
- [G1 垃圾回收器详解:](#G1 垃圾回收器详解:)
-
- 适用场景:
- region区域
- [相关 JVM 参数:](#相关 JVM 参数:)
- 回收阶段:
- [Young Collection:](#Young Collection:)
- [Young Collection + CM:](#Young Collection + CM:)
- [Mixed Collection](#Mixed Collection)
- [Remark 重新标记](#Remark 重新标记)
- [JDK 8u20字符串去重](#JDK 8u20字符串去重)
- [JDK8u40 并发标记类卸载](#JDK8u40 并发标记类卸载)
- JDK8u60回收巨型对象
- JDK9并发标记起始时间的调整
- [5. 垃圾回收调优](#5. 垃圾回收调优)
- 案列:
- 类加载:
- 编译期处理
- 类加载阶段
- 类加载器:
- 双亲委派机制
- 线程上下文类加载器
-
- [一、基本概念与 API](#一、基本概念与 API)
-
- [1. 定义](#1. 定义)
- [2. 核心方法](#2. 核心方法)
- [3. 默认规则](#3. 默认规则)
- [二、为什么需要 TCCL?(双亲委派的缺陷)](#二、为什么需要 TCCL?(双亲委派的缺陷))
-
- 双亲委派的天然限制
- [典型矛盾:JDBC(SPI 经典场景)](#典型矛盾:JDBC(SPI 经典场景))
- [TCCL 如何解决?](#TCCL 如何解决?)
- 三、工作原理(面试重点)
-
- [1. 类加载的两个 "加载器"](#1. 类加载的两个 “加载器”)
- [2. 执行流程(SPI 为例)](#2. 执行流程(SPI 为例))
- [3. 本质](#3. 本质)
- 四、典型应用场景
-
- [1. SPI 服务发现(JDBC、JNDI、JCE、JAXB)](#1. SPI 服务发现(JDBC、JNDI、JCE、JAXB))
- [2. Web 容器(Tomcat/Jetty)](#2. Web 容器(Tomcat/Jetty))
- [3. 插件化 / OSGi / 热部署](#3. 插件化 / OSGi / 热部署)
- [4. 框架内部(Spring、Dubbo、MyBatis)](#4. 框架内部(Spring、Dubbo、MyBatis))
- 五、面试高频问答
-
- [Q1:TCCL 是不是破坏双亲委派?](#Q1:TCCL 是不是破坏双亲委派?)
- [Q2:什么时候用 TCCL?](#Q2:什么时候用 TCCL?)
- [Q3:TCCL 有什么坑?](#Q3:TCCL 有什么坑?)
- 六、一句话总结
- 自定义类加载器:
- 运行期优化:
- java内存模型:
-
- [定义:JVM 定义了一套在多线程读写共享数据时(成员变量,数组)时,对数据可见性、有序性、和原子性的规则保障](#定义:JVM 定义了一套在多线程读写共享数据时(成员变量,数组)时,对数据可见性、有序性、和原子性的规则保障)
- [原子性: synchronized](#原子性: synchronized)
- [可见性: volatile (可见性+防止指令重排序)](#可见性: volatile (可见性+防止指令重排序))
- 有序性:
- CAS:
-
- 关键点
- [Java 中基于 CAS 实现的工具类(JUC 原子包)](#Java 中基于 CAS 实现的工具类(JUC 原子包))
-
- [1. 基础原子类型](#1. 基础原子类型)
- [2. 引用类型](#2. 引用类型)
- [3. 数组类型](#3. 数组类型)
- [4. 字段更新器](#4. 字段更新器)
- 二、我在项目中实际使用场景(真实、可直接说)
-
- [1. `AtomicInteger` / `AtomicLong` ------ 高频使用](#1.
AtomicInteger/AtomicLong—— 高频使用) - [2. `AtomicBoolean` ------ 控制单次执行](#2.
AtomicBoolean—— 控制单次执行) - [3. `AtomicReference` ------ 原子更新对象](#3.
AtomicReference—— 原子更新对象) - [4. `AtomicStampedReference` ------ 解决 ABA 问题](#4.
AtomicStampedReference—— 解决 ABA 问题)
- [1. `AtomicInteger` / `AtomicLong` ------ 高频使用](#1.
- ABA问题:
- synchronized:
-
- 锁升级完整流程(必考)
-
- [1. 无锁状态](#1. 无锁状态)
- [2. 偏向锁(默认开启)](#2. 偏向锁(默认开启))
- [3. 轻量级锁(自旋锁)](#3. 轻量级锁(自旋锁))
- [4. 重量级锁](#4. 重量级锁)
-
什么是JVM?
定义:
java Virtual Machine
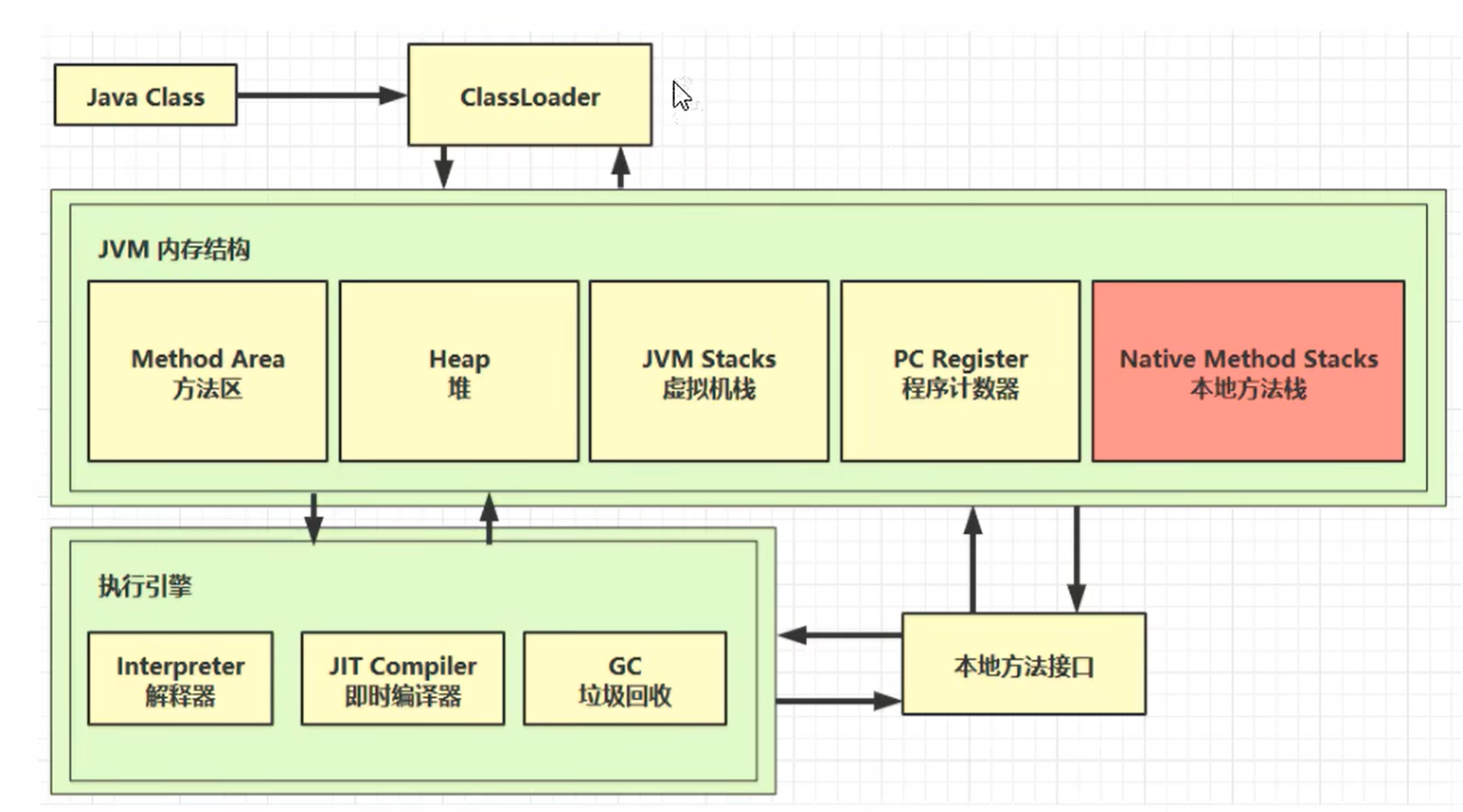
jvm 本质就是 java 二进制字节码的运行环境,JVM 主要包含类加载子系统、运行时数据区、执行引擎、垃圾回收器、本地方法接口,是 Java 程序的运行环境与内存管家。
优点:
-
一次编写到处运行保障
-
自动内存管理
-
数组下边越界检查
-
多态
比较:
jvm jre jdk

学习路线
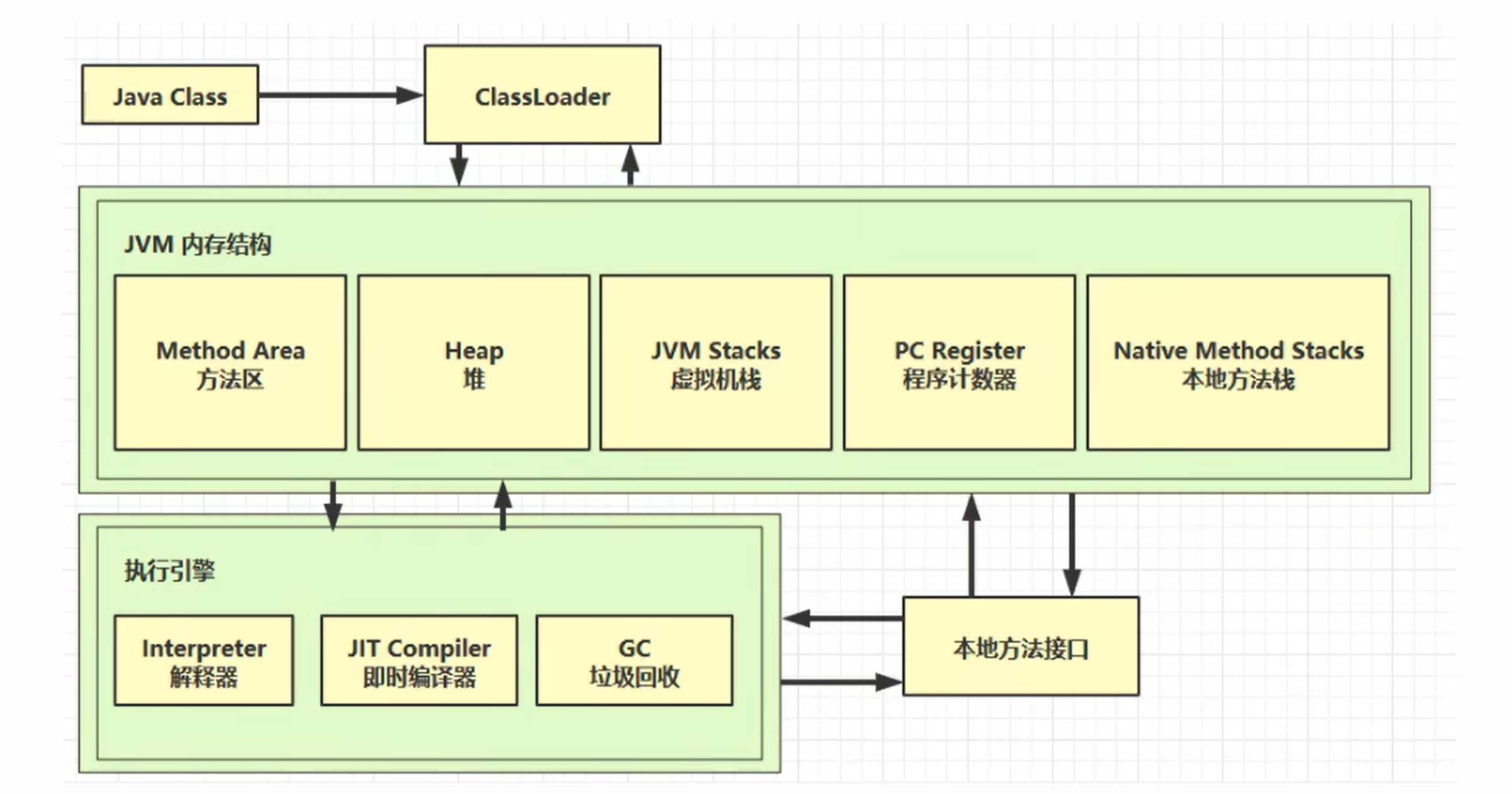
JVM 内存结构
程序计数器:
Program Counter Register程序计数器(寄存器)
作用:
记住下一条 jvm指令的而执行地址 , 将下一条需要调用的地址存入到 程序计数器 ,是基于寄存器实现的。
特点:
-
每个线程都有自己的程序计数器 ,cpu调度器给线程分配时间片,线程1 、线程2 来回切换调用自己的程序计数器后执行。
-
不会存在内存溢出
虚拟机栈
栈数据结构特点: 先进后出 ,一个线程一个栈,一个栈帧对应一个方法运行时需要的内存
定义:
- 每个线程运行时所需要的内存,成为虚拟机栈
- 每个栈由多个栈帧(Frames)组成,对应着每次方法调用时所暂用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
问题辨析:
-
垃圾回收是否设计栈内存? 答:不需要, 方法每次调用完都会被弹出,无需回收
-
栈内存的分配越大越好吗? 答:不是,栈内存越大,线程数就越小,物理地址是固定的,栈内存大了只能提升递归调用的效率
-
方法内的局部变量是否线程安全?
答:方法内局部变量 没有逃离方法作用范围,在每次方法调用时会在自己的栈帧存储一个私有的变量x,线程安全的
方法内局部变量 逃离方法作用范围,存在线程安全问题
栈内存溢出 (java.lang.StackOverflowError)
-
栈帧过多导致栈内存溢出 (递归调用)
-
栈帧过大
启动的虚拟机中可以设置栈的大小 : -Xss256k
如 idea 的VM options
线程运行诊断:
-
cpu占用过高
top : 实施检测cpu的运行进程情况
ps : 查看线程对cpu的占用情况 , 参数: H 打印进程中所有的线程数 ,-eo 需要查看的参数 (pid,tid,%cpu),(进程数,线程数,cpu占用率)
jstack + 进程id : 查看 对应进程下 每个线程的情况列出来,在根据线程的16进制定位到代码源码的行数
-
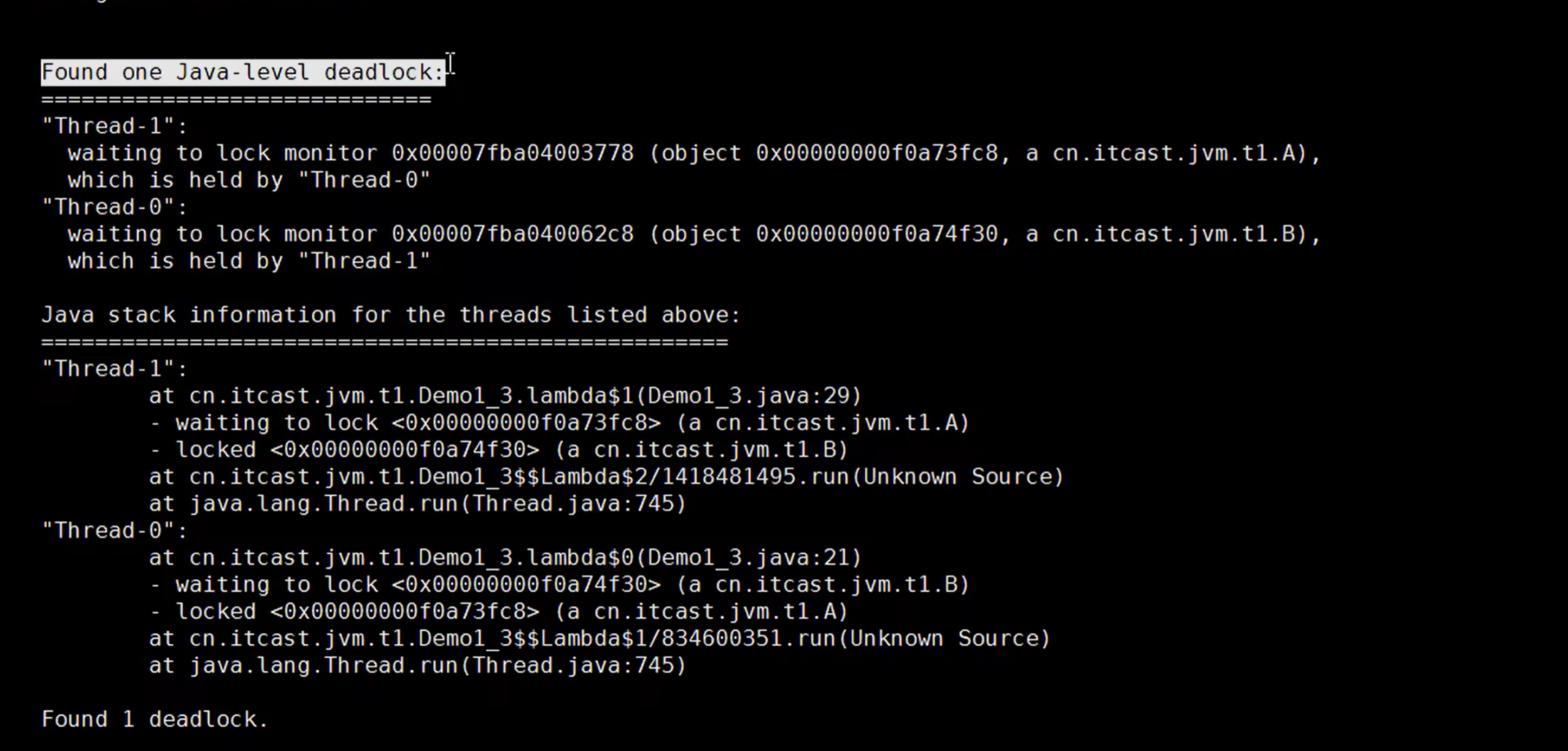
程序运行很长时间没有结果
线程死锁排查: jstack + 进程id ,查看最后几行内容信息
本地方法栈:
使用native修饰的方法:
如:Object 中的clone(),wait()等等 , 给本地方法运行的空间
堆:
定义:
Heap 堆 :
- 通过new关键字,创建的对象都会使用堆内存
特点:
- 他是线程共享的,堆中对象都需要考虑线程安全问题
- 有垃圾回收机制
堆内存溢出问题:(java.lang.OutOfMemoryError:Java heap space)
设置堆内存大小:-Xmx8m
堆内存诊断工具
-
jps 工具
- 查看当前系统中哪些java进程
-
jmap工具 jmap -heap
- 查看堆内存占用情况
堆的配置
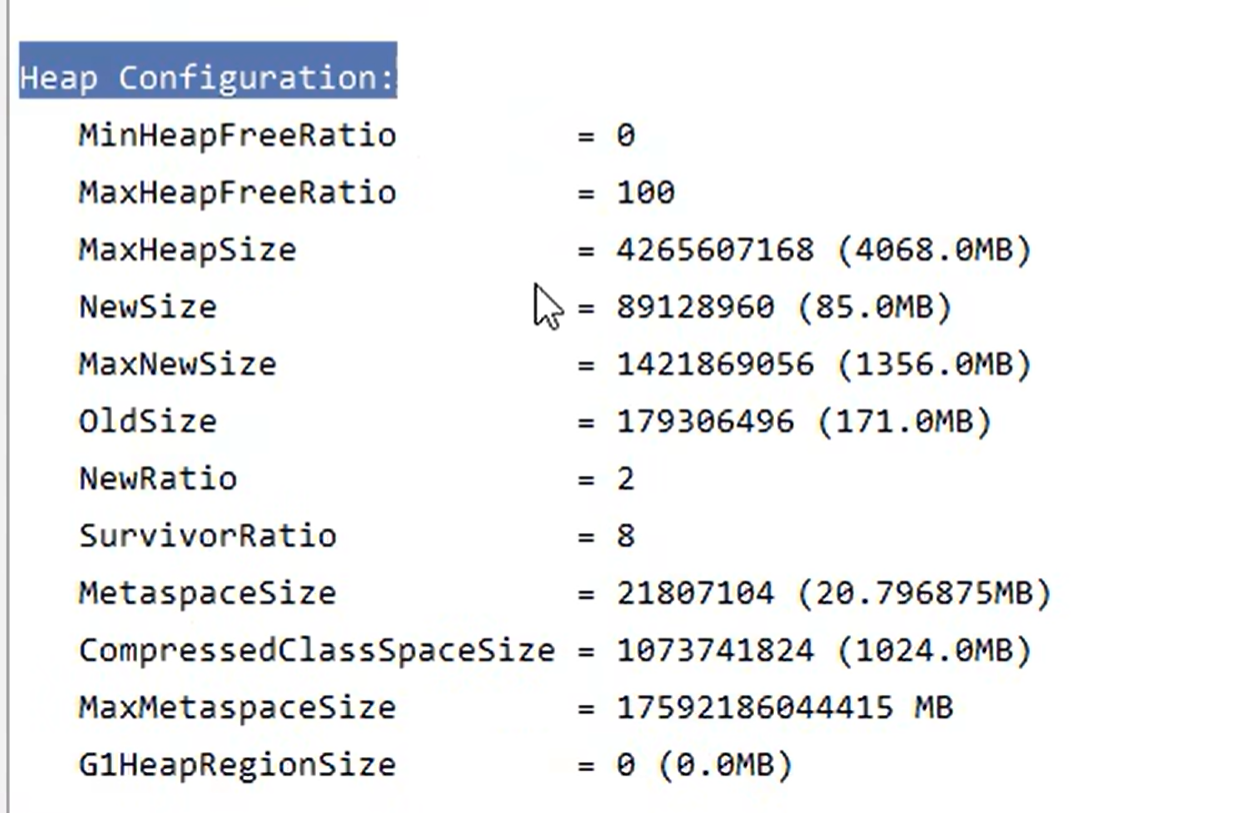
堆的使用
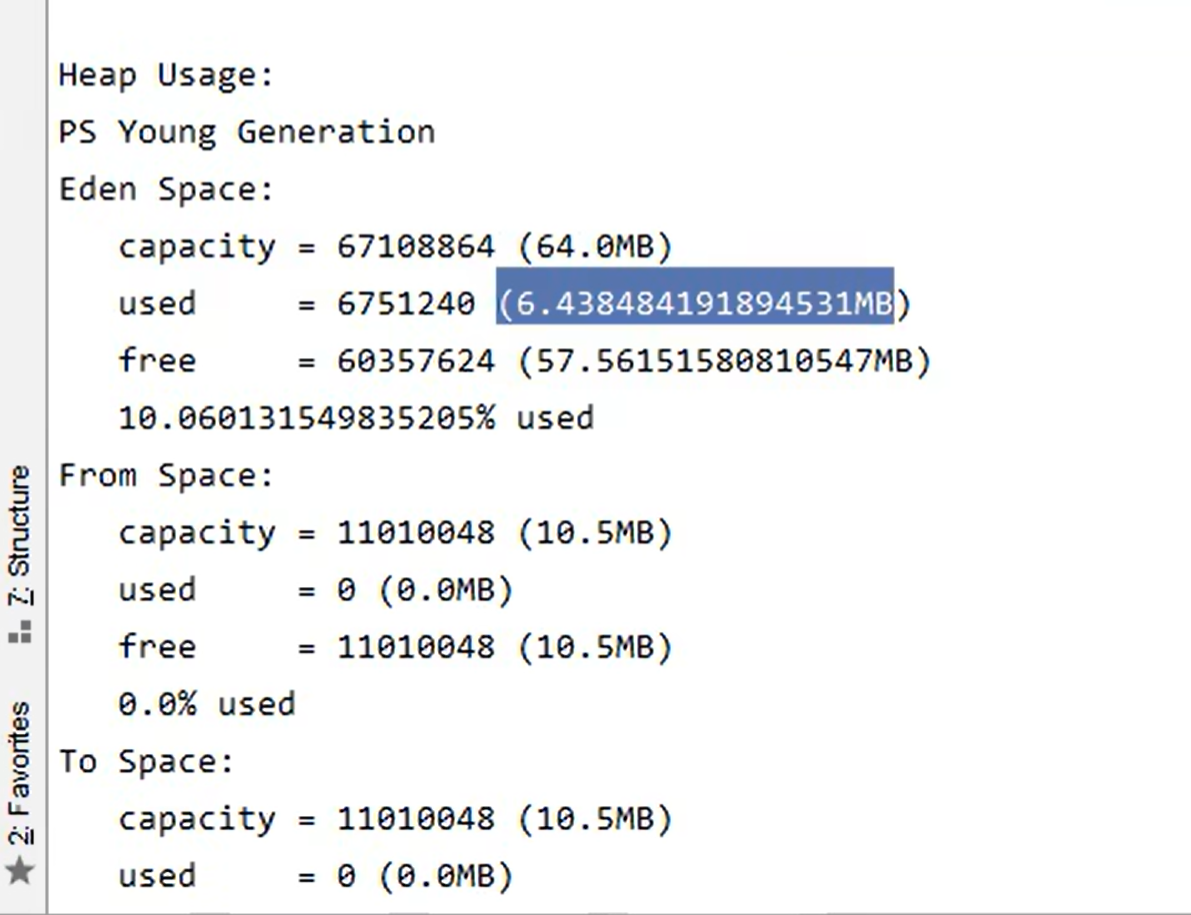
- jconsole工具
- 图形界面的,多功能的监测工具,可以连续监测
问题诊断:
- 垃圾回收后,内存占用任然很高
通过jmap 查看各个区 占用的情况,具体看是哪个区的占用率高 ,使用 jvisualvm 命令展示可视化的虚拟机窗口 , 查找最大的类并查看详细信息
方法区:
方法区也会导致OOM问题
设置最大元空间大小 : -XX:MaxMetaspaceSize=8m
设置永久代大小:-XX:MaxPermSize=8m
定义:
方法区是 JVM 规范中定义的一块线程共享的内存区域 ,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
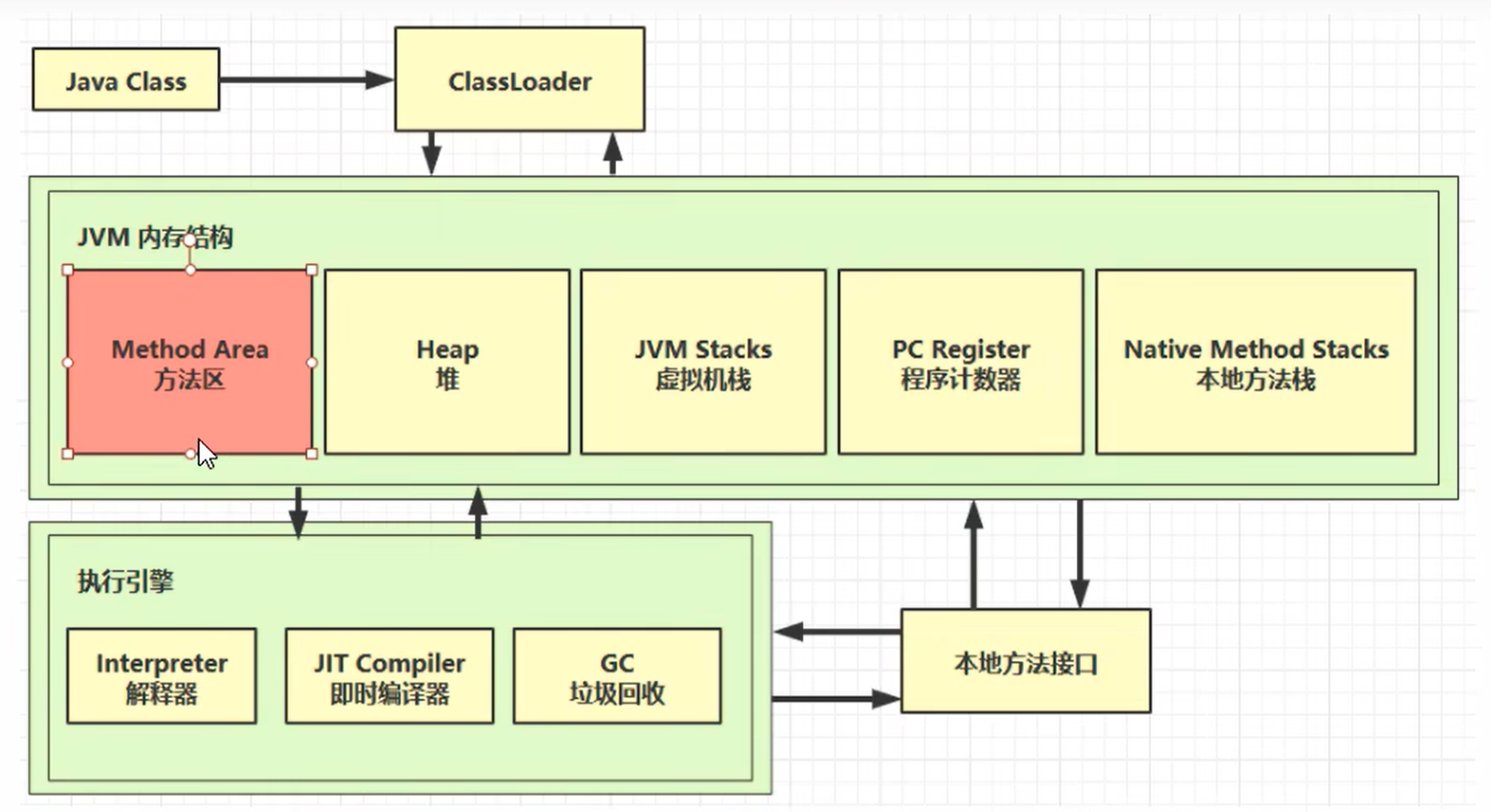
组成:
在HotSpot jvm 1.6中 用一个永久代作为方法区的实现 ,在1.8后永久代的实现 废弃,方法区变成 元空间,串池移入了堆内存中
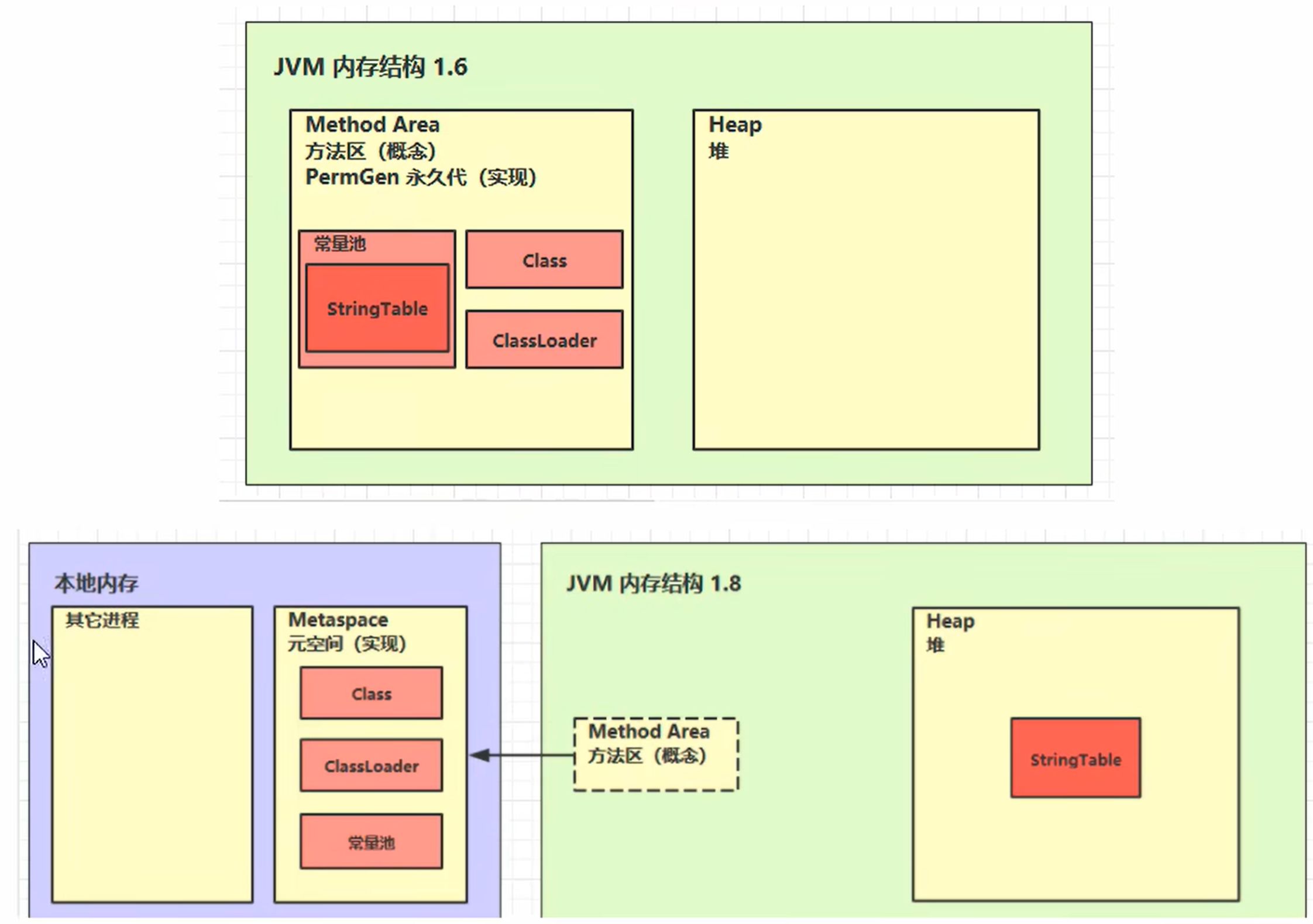
方法区内存溢出:
1.8以前 会导致 永久代 内存溢出:(java.lang.OutOfMemoryError: PermGen space) (注:读音 喷鹃)
1.8以后 会导致 元空间 内存溢出:(java.lang.OutOfMemoryError:Metaspace)
实际场景:
- spring : 代理 cglib 依赖,asm包 ClassVisitor 运行期间动态生成类的字节码(字节码的动态生成技术)
- mybatis :
运行常量池:
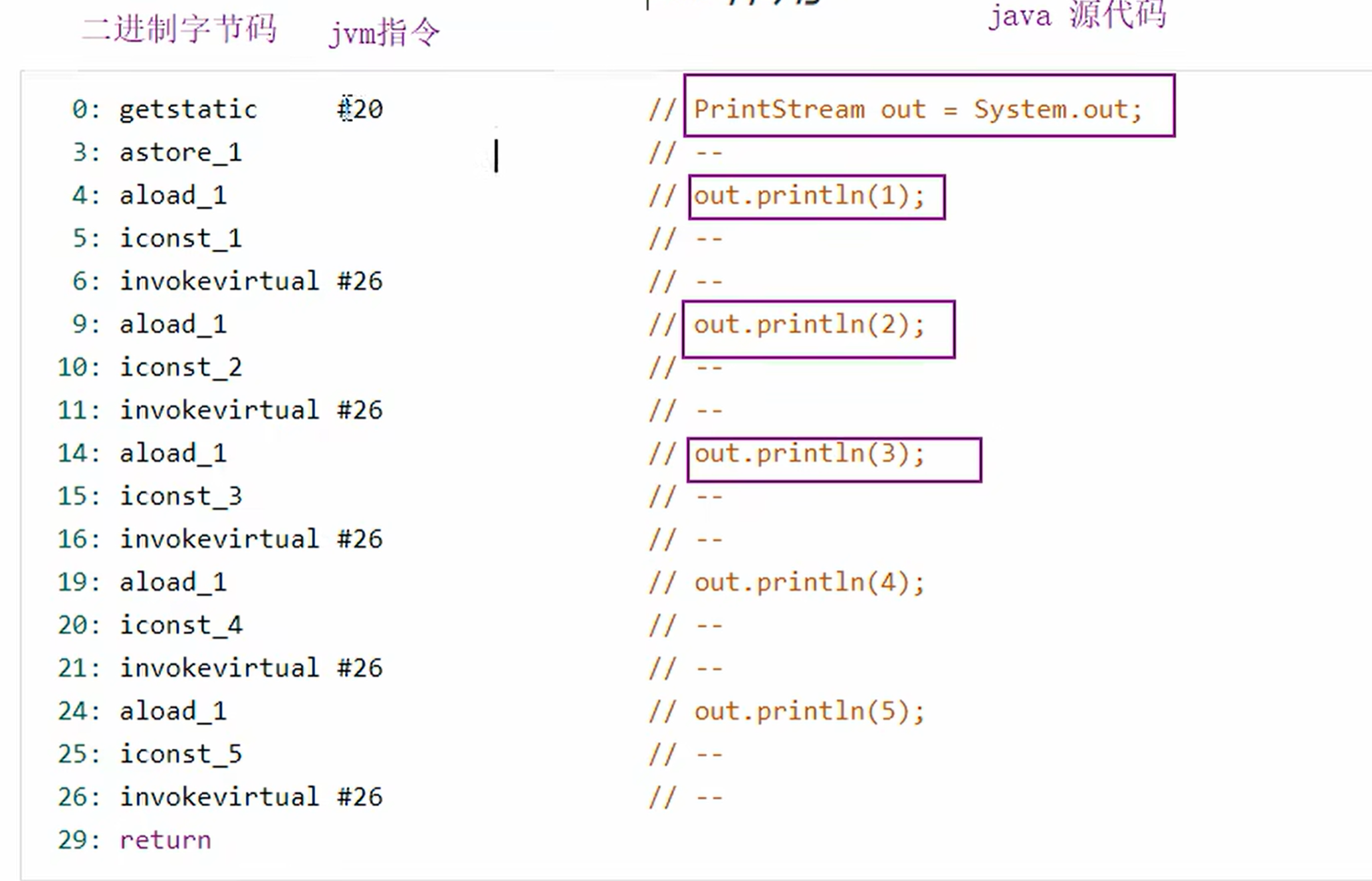
首先: 二进制字节码 (类的基本信息、类的常量池、类中的方法定义,包含了虚拟机指令)
常量池的做旧就是为了给下面图片中 #数字 指令或者符号,存储
定义:
- 常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
- 运行时常量池,常量池是*.class 文件中的,当该类被加载,他的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
常量池、运行常量池、StringTable
定义:
常量池: Class 文件里存常量和符号引用的地方,是静态数据。(编译期就确定的字面量 和符号引用)
运行时常量池:Class 常量池被加载到内存后的版本,属于方法区,动态可扩展。(类加载时,把 Class 常量池加载进内存,就是运行时常量池)
StringTable:JVM 专门缓存字符串引用的全局哈希表,实现字符串享元模式。(串池,字符串对象的引用)
StringTable特性
在jdk8下设置 -Xmx10m(修改虚拟机内存)-XX:+PrintStringTableStat(打印串池状态) -XX:+PrintGCDetails - verbose:gc(GC回收日志详细信息,次数、时间) -XX:-UseGcoverheadlimit(设置堆内存限制)
在jdk6下设置 -XX:MaxPermSize=10m(设置永久代空间大小)
- 常量池的字符串仅是符号,第一次用到是才变成对象
- 利用串池的机制,来避免重复创建字符串对象
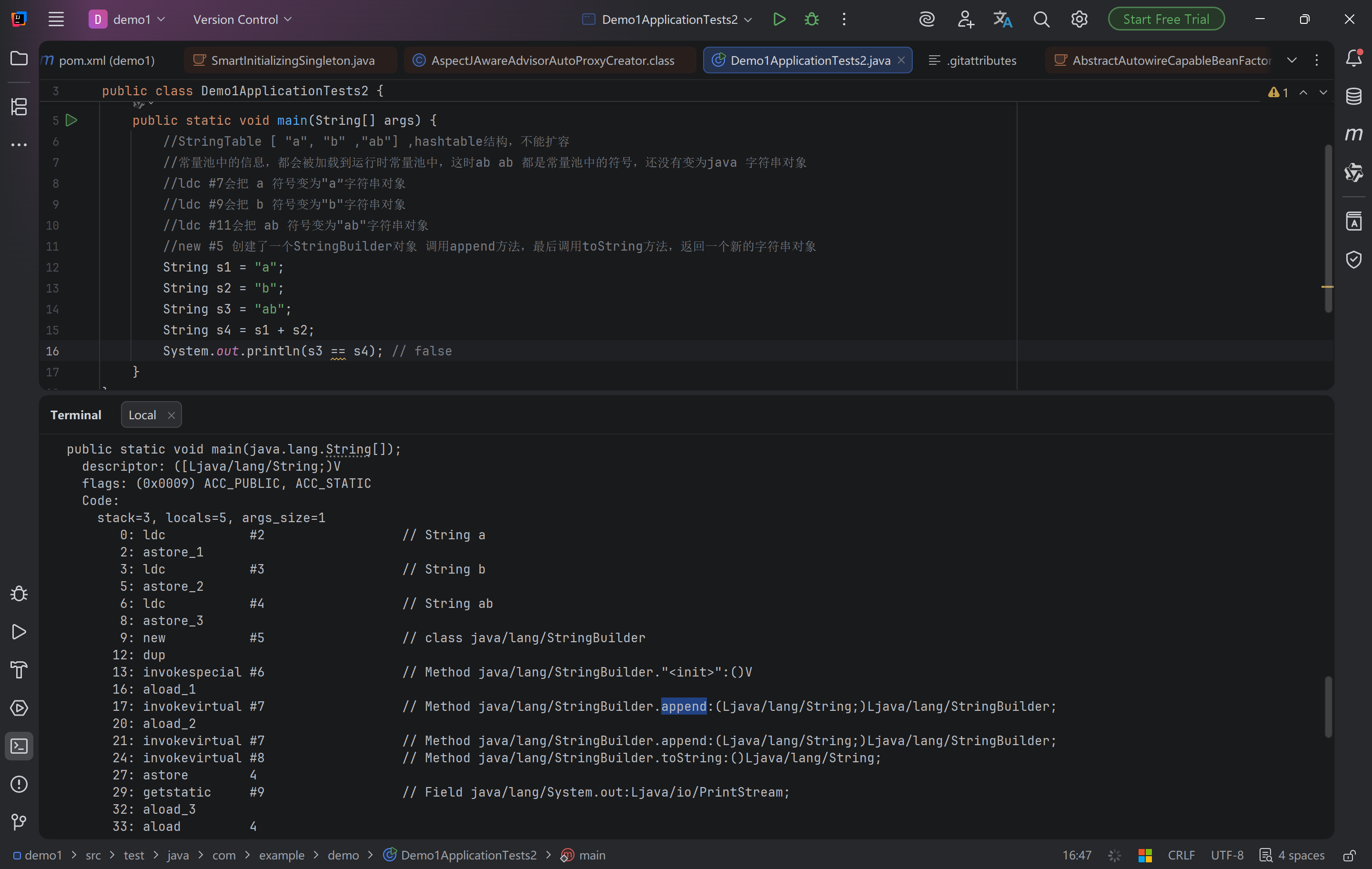
- 字符串变量拼接的原理是StringBuilder(1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用intern方法主动将串池中还没有的字符串对象放入串池
- jdk1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
- jdk1.6将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池的中的对象返回

StringTable 的位置
-
在jdk1.8以后在堆中存储
-
在jdk1.6之前在永久代中常量池中存储
StringTable 垃圾回收机制
- 在串池空间不足时会触发一次垃圾回收
StringTable 调优
-XX:StringTableSize=200000(设置StringTable桶大小) -XX:+PrintStringTableStatistics(打印StringTable信息)
- SringTable 本质就时一个hash表,性能的大小和桶的数量有关,桶越多,数据越分散,减少哈希冲突
- 考虑将字符串对象入池,减少重复的字符串存储
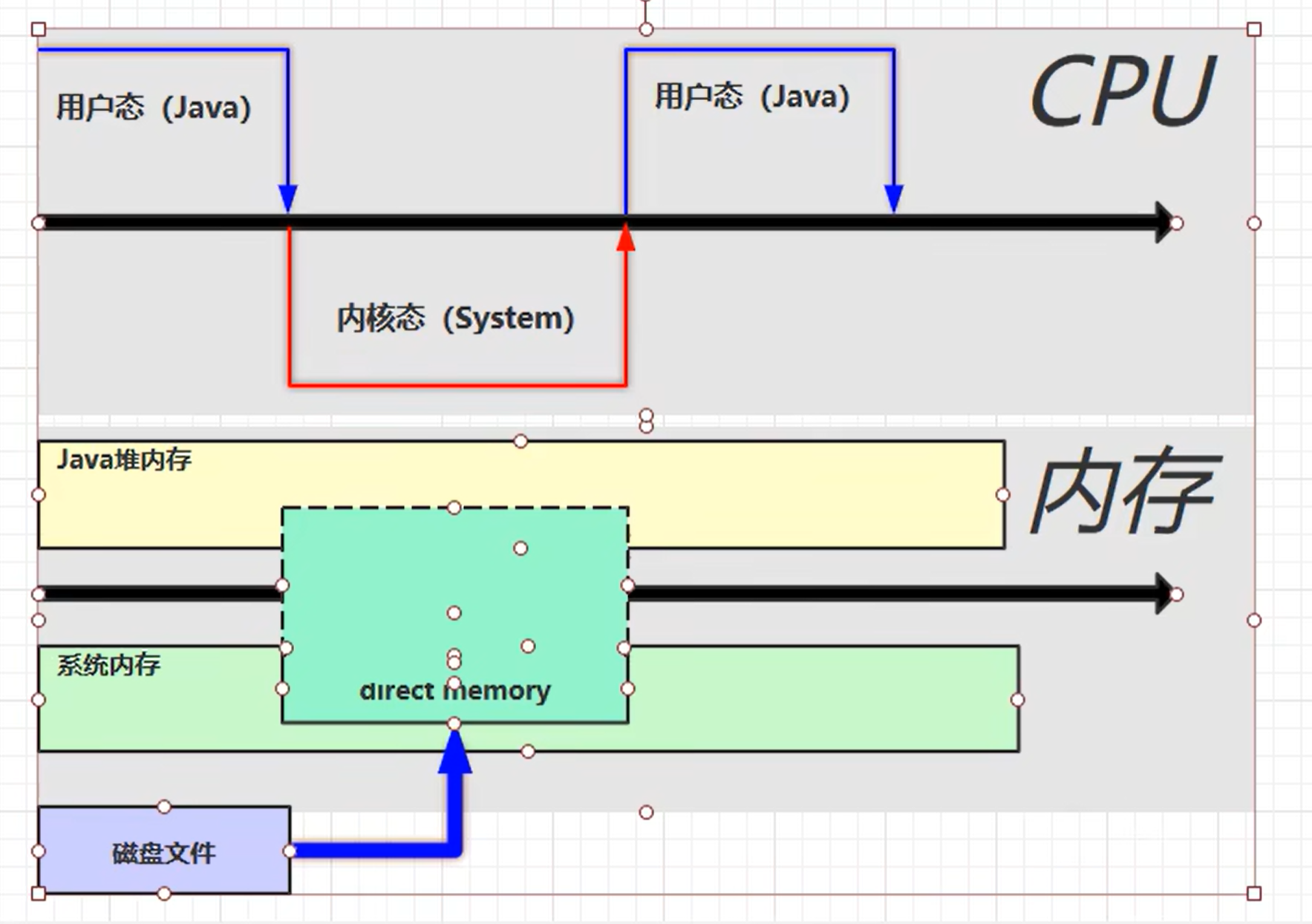
直接内存:Direct Memory
定义:
- 操作系统内存,常见于NIO操作,用于数据缓冲区,大文件读写要考虑使用缓冲流
- 分配和回收成本高,但读写性能高
- 不受JVM内存回收管理
传统调用,存入两份缓冲区,java代码无法直接访问系统内存
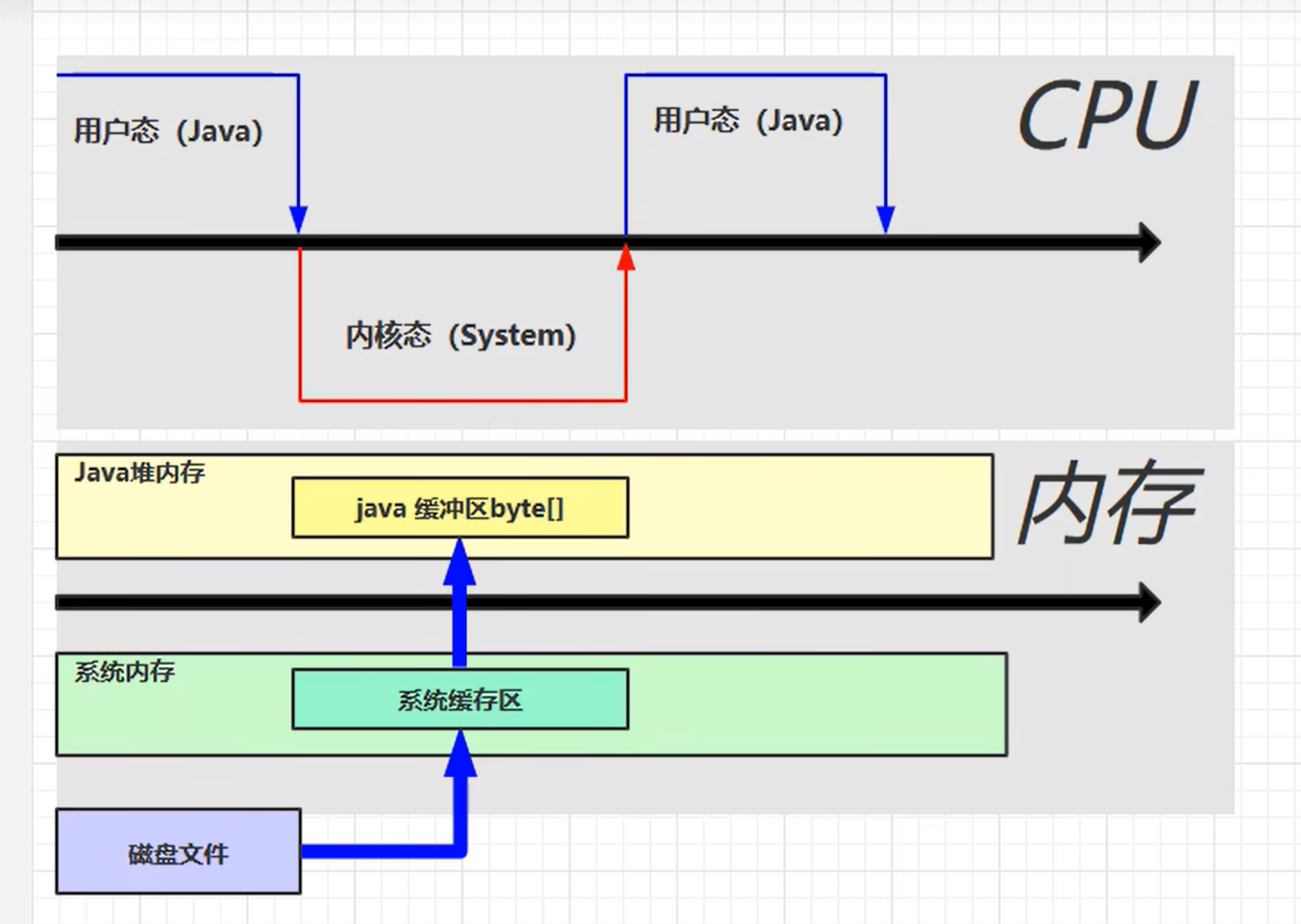
使用了直接内存后,java代码可以直接访问
内存溢出:
java.lang.OutOfMemoryError:Direct buffer memory
释放原理:
- 使用了Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法
- ByteBuffer的实现类内部,使用了Cleaner(虚引用)来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner 的clean方法调用freeMemory来释放直接内存
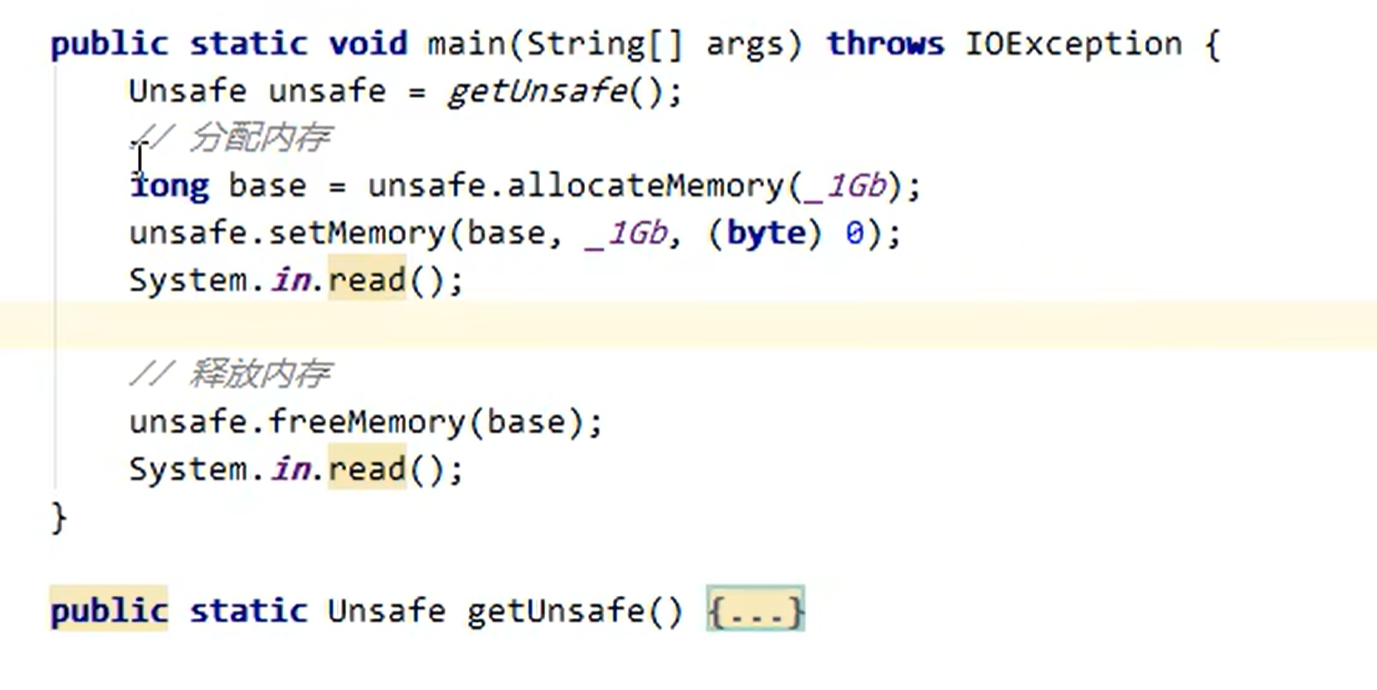
举例: ByteBuffer. allocateDirect(int)

直接内存分配
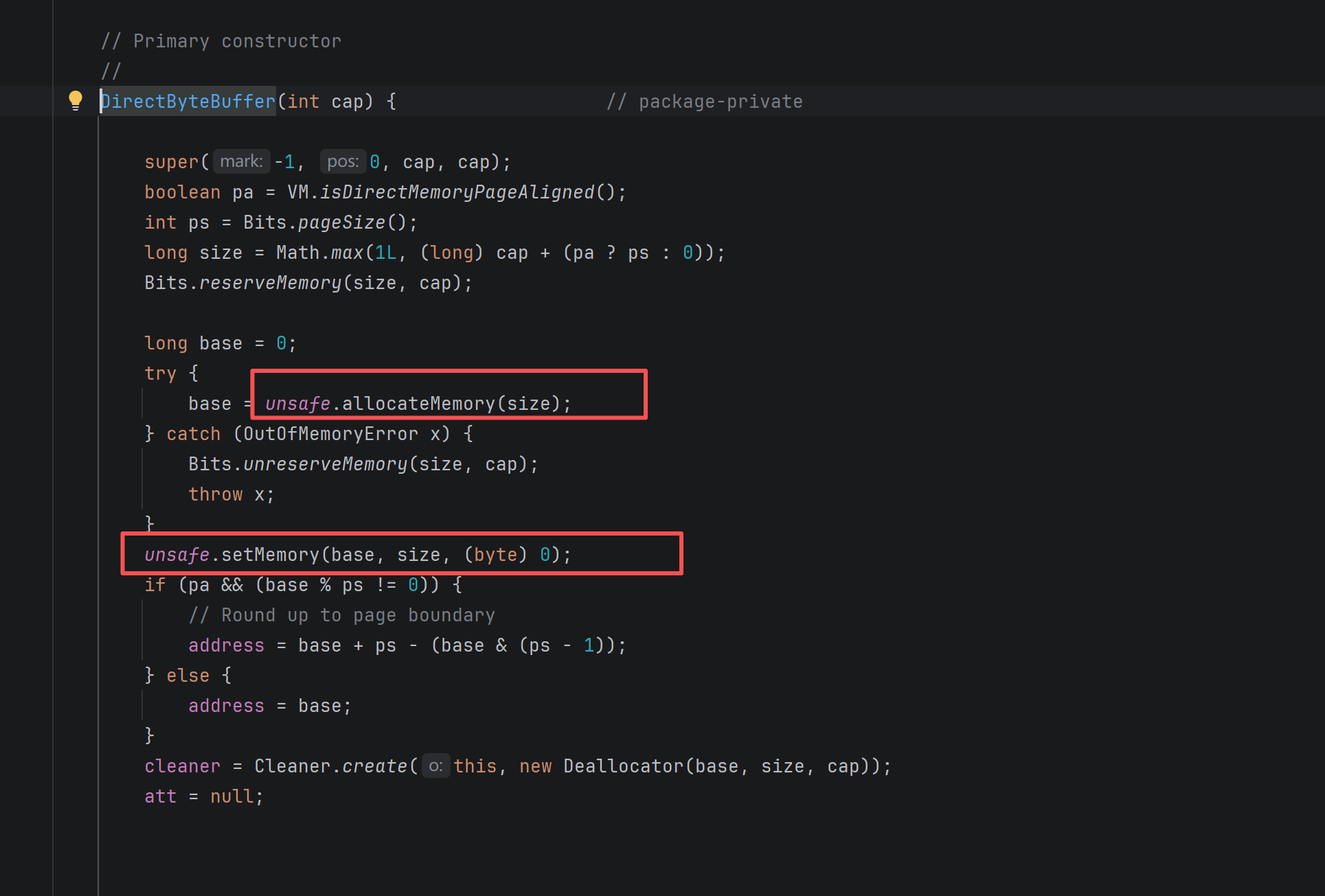
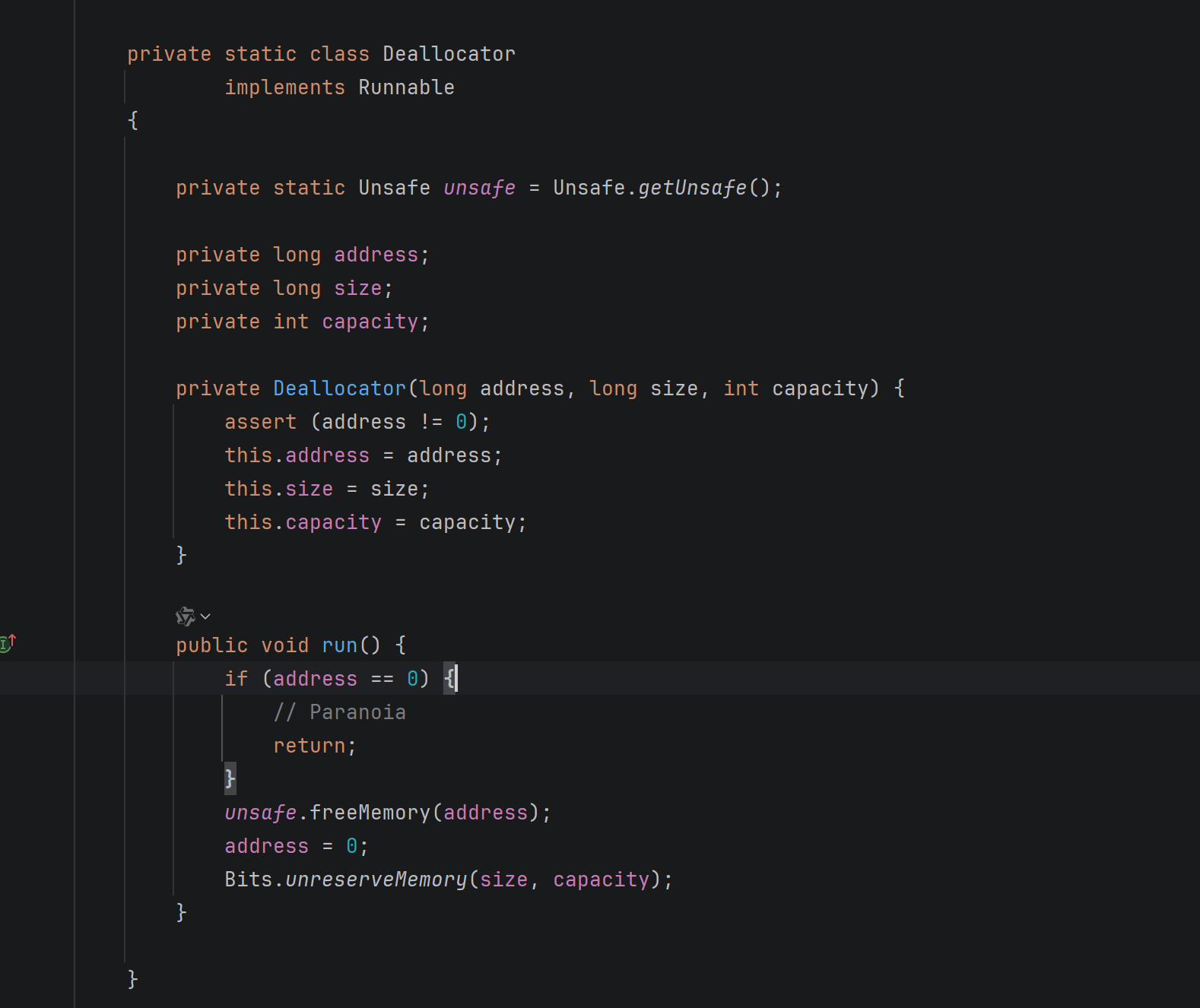
直接内存释放 Cleaner, this 代表ByteBuffer , 如果ByteBuffer 被垃圾回收回收了,那么就会调用new Deallocator构造方法,而这个对象实现了Runnable 在run方法中存在 unsafe.freeMemory(address) 释放方法
直接内存_禁用显式回收对直接内存的影响
-XX:+DisableExplicitGC 禁用显示的垃圾回收 (System.gc()方法无效 , FULL GC 不但回收新生代 还有 老年代, 时间较长)
- 禁用后代码写的回收方法无法使用,只能等真正的垃圾回收,直接内存才会一起释放,所以可以使用 Unsafe 类调用方法直接释放内存
垃圾回收
1. 如何判断对象可以回收
引用计数法:
当对象的引用计数变成0 那么就会被回收掉
弊端: 循环引用 A <--> B , 但是无人引用A,B , 导致A,B一直无法被回收,造成内存泄漏
可达性分析算法:
分析根对象(肯定不能被回收的对象),判断某个类是否直接或间接被 根对象引用,如有那么他也不能被回收
- Java虚拟机中的垃圾回收器采用可达性分析来探索所有的存活对象
- 扫描堆中对象,看是否能够沿着GC Root对象为起点的引用链找到该对象,找不到,表示可以回收
- 哪些对象可以作为CG Root?
可达性分析算法查看
Eclipse MAT(Memory Analyzer) 专门做堆内存的分析,查看堆内存泄露等等
jmap -dump:format=b,live,file=1.bin 进程id (将存活的对象抓取一次快照,存放路径当前路径取名1.bin)
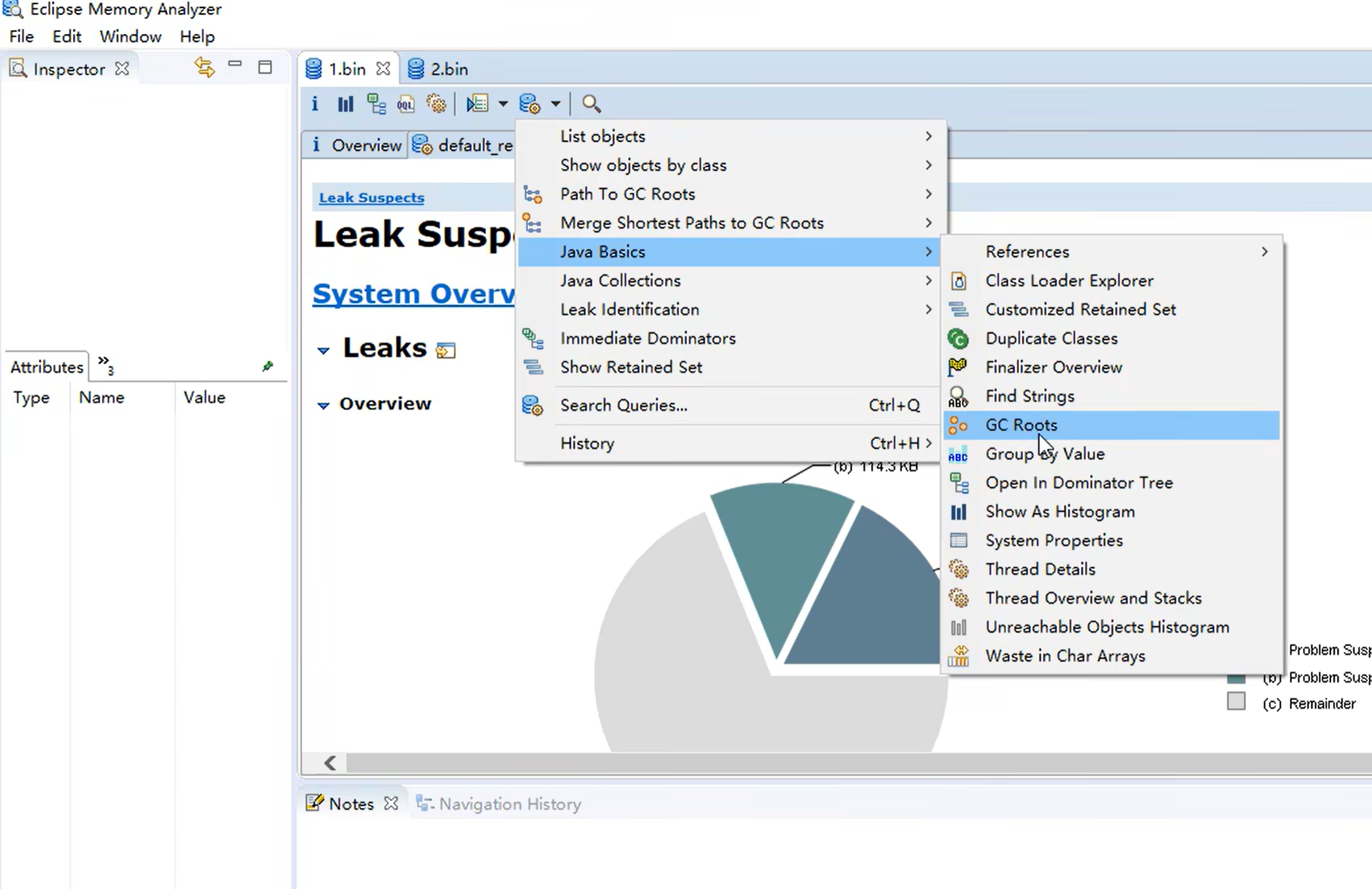
根对象:
System Class 系统类 (Object 、 HashMap 、List等)
Native Stack 操作系统方法引用的类
Busy Monitor 正在加锁的对象,无法被回收
Thread 活动线程的对象无法被回收
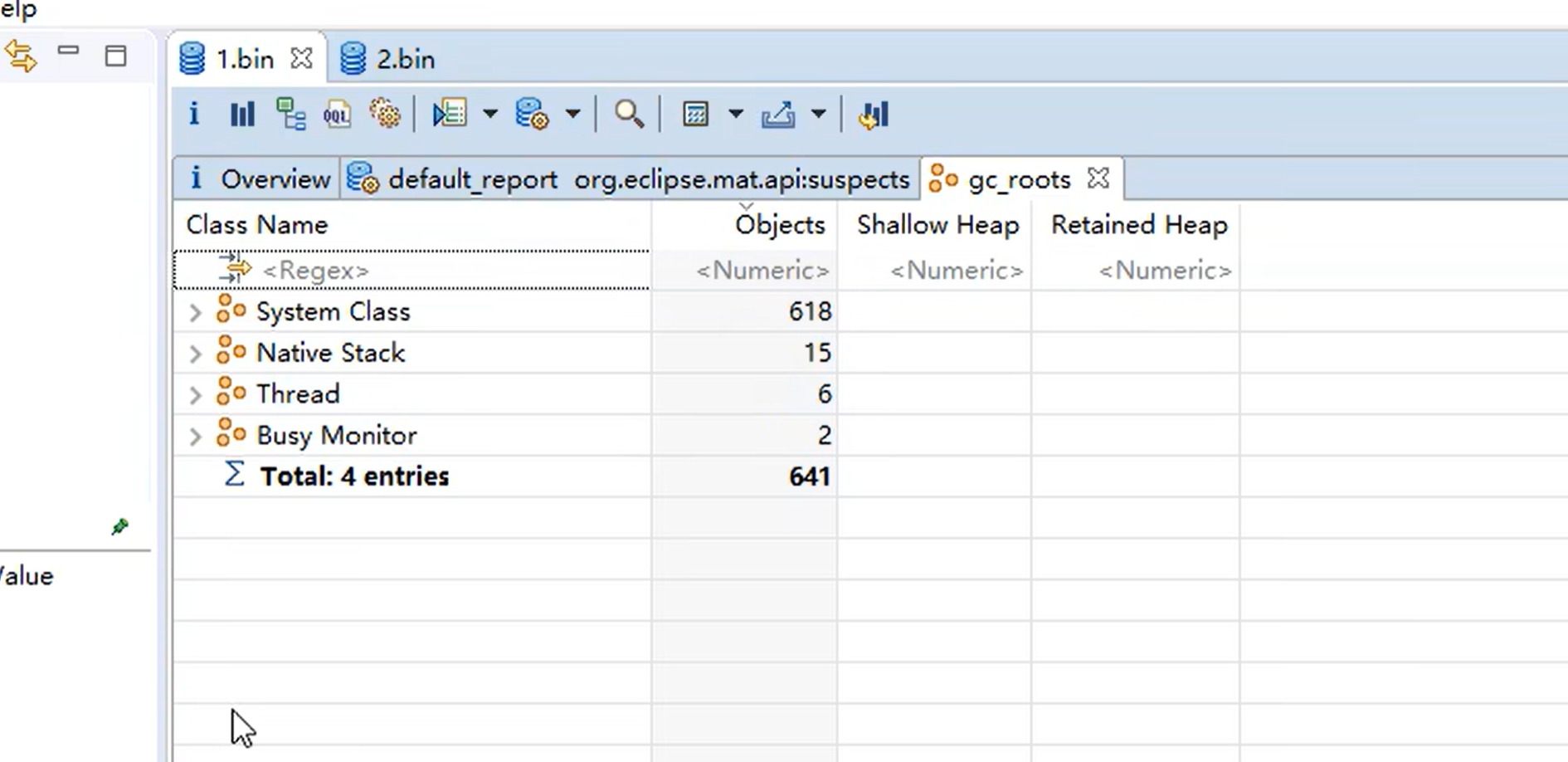
四种引用
-XX:+PrintGCDetails -verbose:gc 添加垃圾回收的打印日志 详细参数
强引用
只要沿着 GC Root 引用链能够找到的对象就是强引用,不会被回收
软引用
当垃圾回收时,内存不够时,会把软引用引用的对象释放掉,间接引用的对象
java
// 软引用
ReferenceQueue queue = new ReferenceQueue();
SoftReference<Object> softRef = new SoftReference<>(new Object(),queue);
// new ReferenceQueue() 引用队列,当软引用被回收时置为null,然后加入到这个队列中,
// 从队列弹出一个值
Reference<? extends Object > poll = queue.poll();
// 判断改值是不是为空,如果不是存在软引用,操作业务逻辑移除后继续弹出下一个,直到弹出的数据为null弱引用
只要发生垃圾回收,就会把弱引用引用的对象释放掉
java
// 弱引用
WeakReference<Object> weakRef = new WeakReference<>(new Object());虚引用
不能通过它获取对象实例,唯一作用是在对象被回收时收到通知。直接内存 里 Clearner 里面 Unsafe.freeMemory() 释放直接内存方法
终结器引用
重写Object.finalize()方法
2. 垃圾回收算法
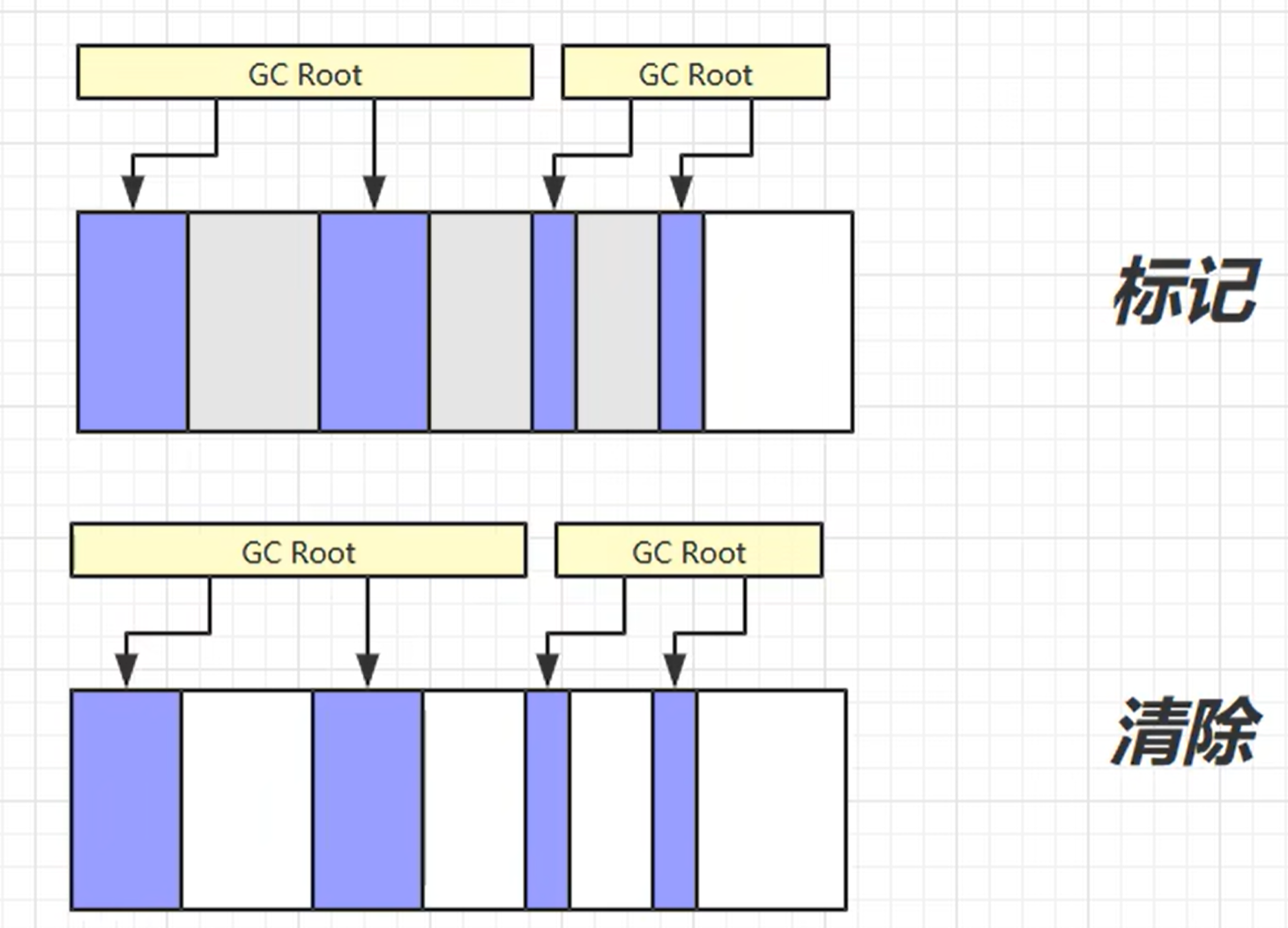
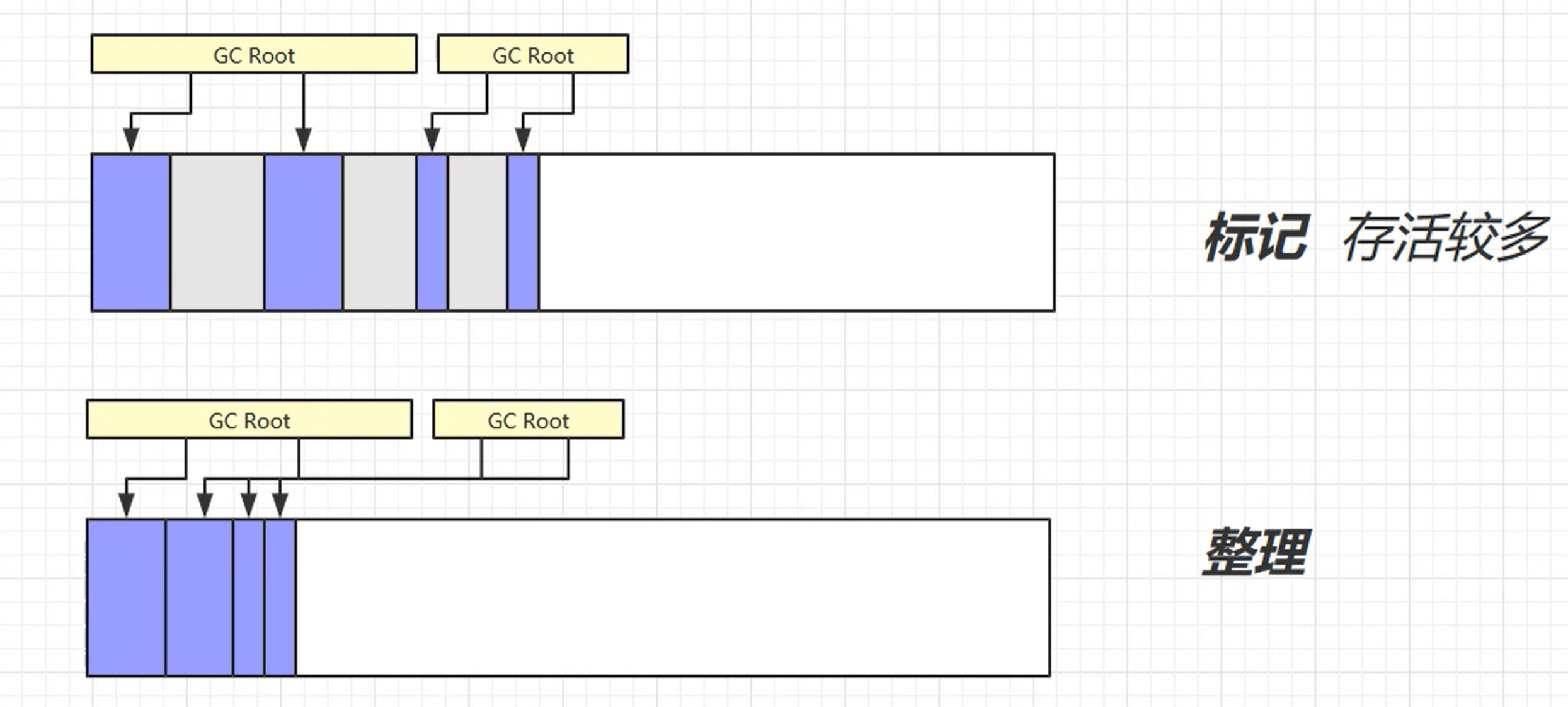
标记清除法
标记没有被 GC Root 引用的对象 ,最后将新的对象引用到这些被标记的对象中,替换这些标记的对象空间
缺点:容易产生内存碎片
标记整理
标记没有被 GC Root 引用的对象 ,先整理,移动可以使用的 内存地址
缺点 : 整理牵扯到了对象的移动,需要改变对象的引用地址,改动耗时
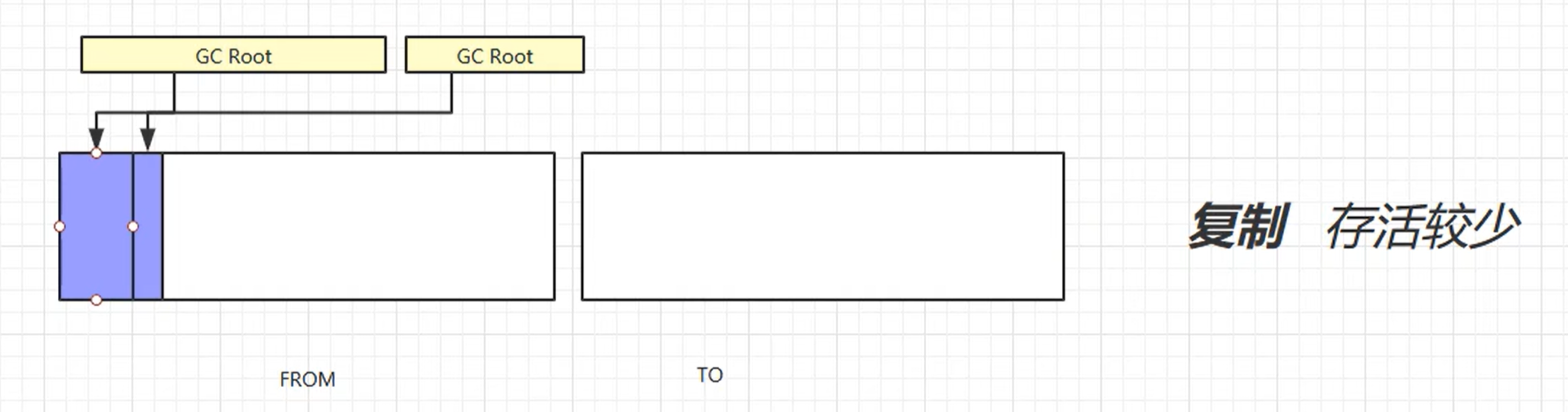
复制算法
先做标记、再把被CG Root引用的地址赋值到 TO 空间,而之前的From控制清空, 最后在换回去得出新的整理后的空间地址
缺点:占用双倍的内存空间
3. 分代垃圾回收
针对不同的代,使用不同的垃圾回收机制
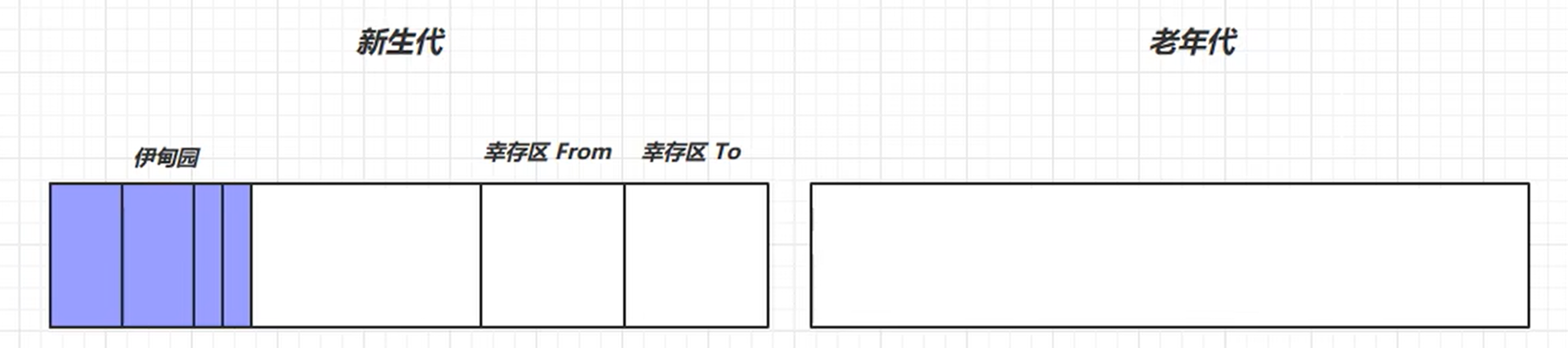
新生代:(用完可以丢弃)
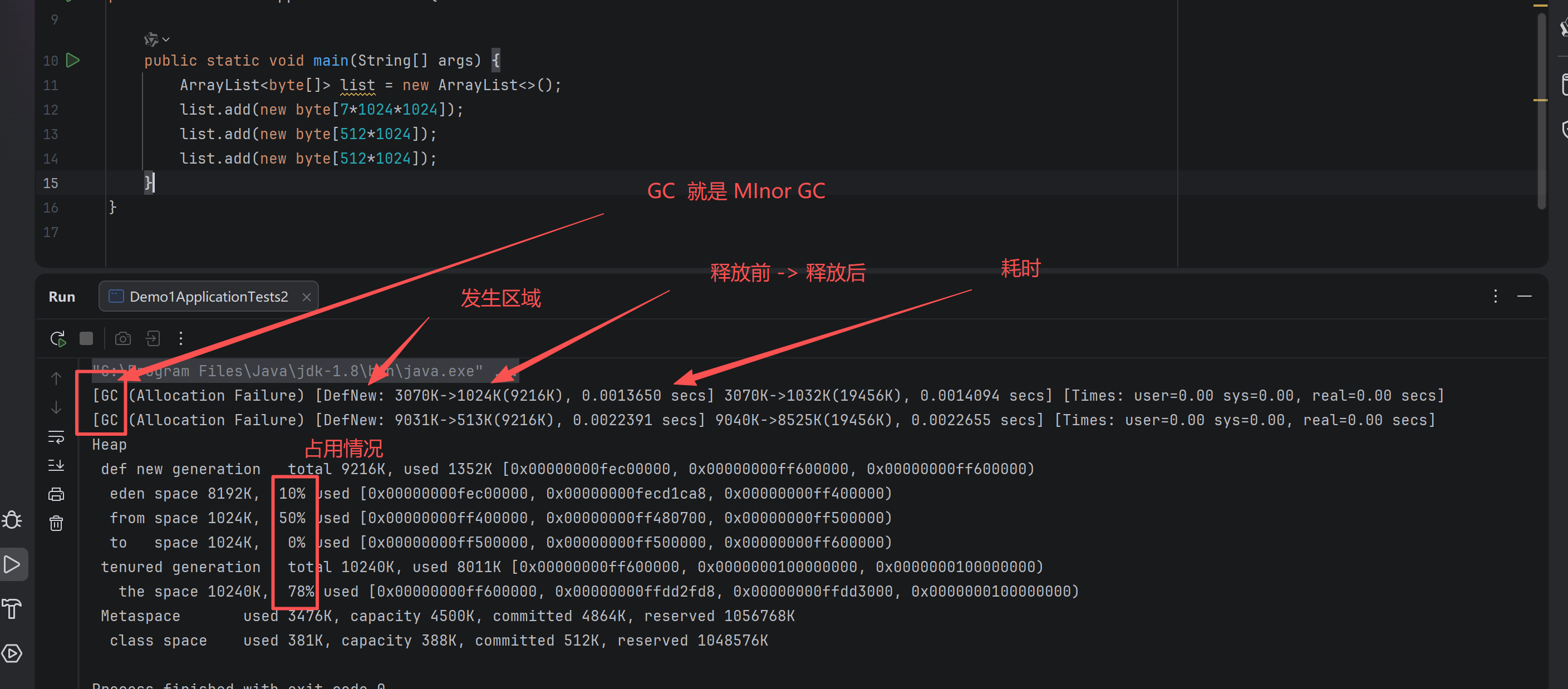
新生代垃圾回收 (Minor GC) 根据标记算法,根据引用的情况清除数据,最后把存活的数据放入到幸存区To , 经历一次垃圾回收后,寿命+1,完成Minor GC后 ,最后交换幸存区From 与 幸存区To。 Minor GC 会引发 stop the world ,触发垃圾回收后会暂停其他的用户线程,等垃圾回收结束,才恢复运行(时间短)
以此类推,再次启动 Minor GC 后 查找伊甸园 与 幸存区From 数据, 找到不可回收的对象放入到幸存区To中,清除标记的垃圾,完成Minor GC后,最后交换幸存区From 与 幸存区To。寿命+1 。
当寿命超过默认阈值 ,15(4bit : 1111 ) 寿命后,晋升到老年代
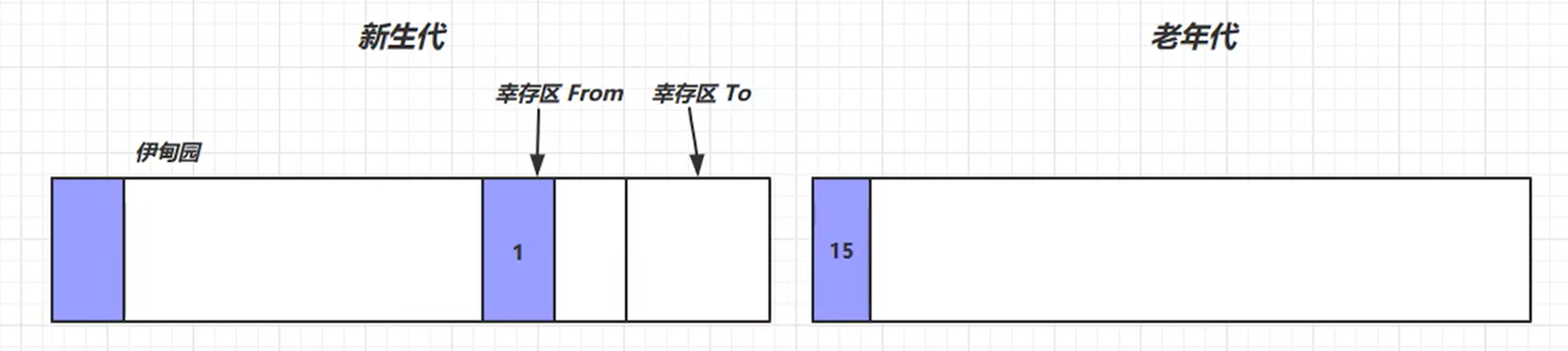
老年代:(长时间使用)
当老年代的空间不足时,先尝试一次Minor GC ,还是不足会触发一次FULL GC (同样也会触发一次 stop the world 时间长)
相关VM参数
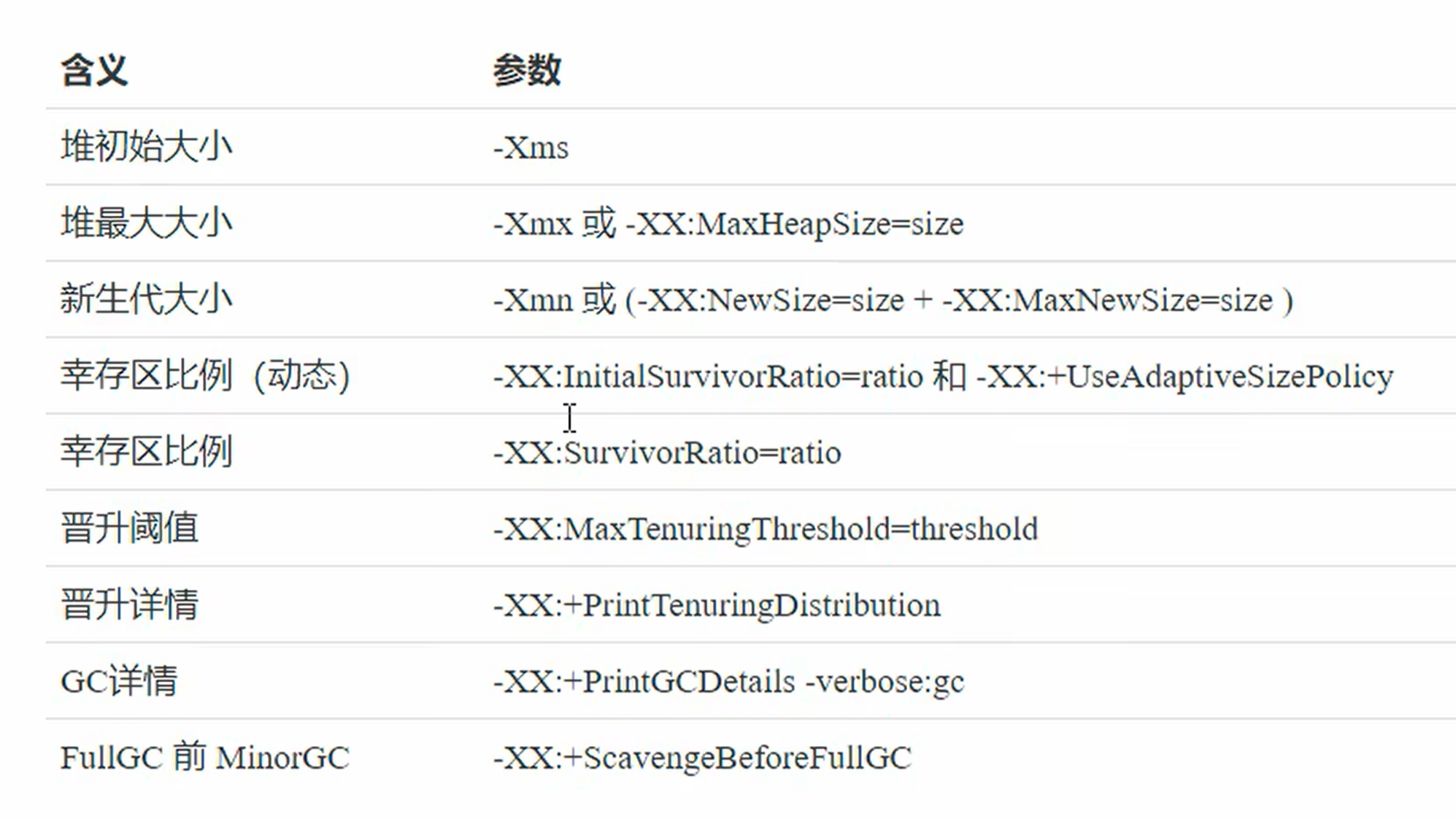
GC分析:
shell
-Xms20M -Xmx20M -Xmn10M -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc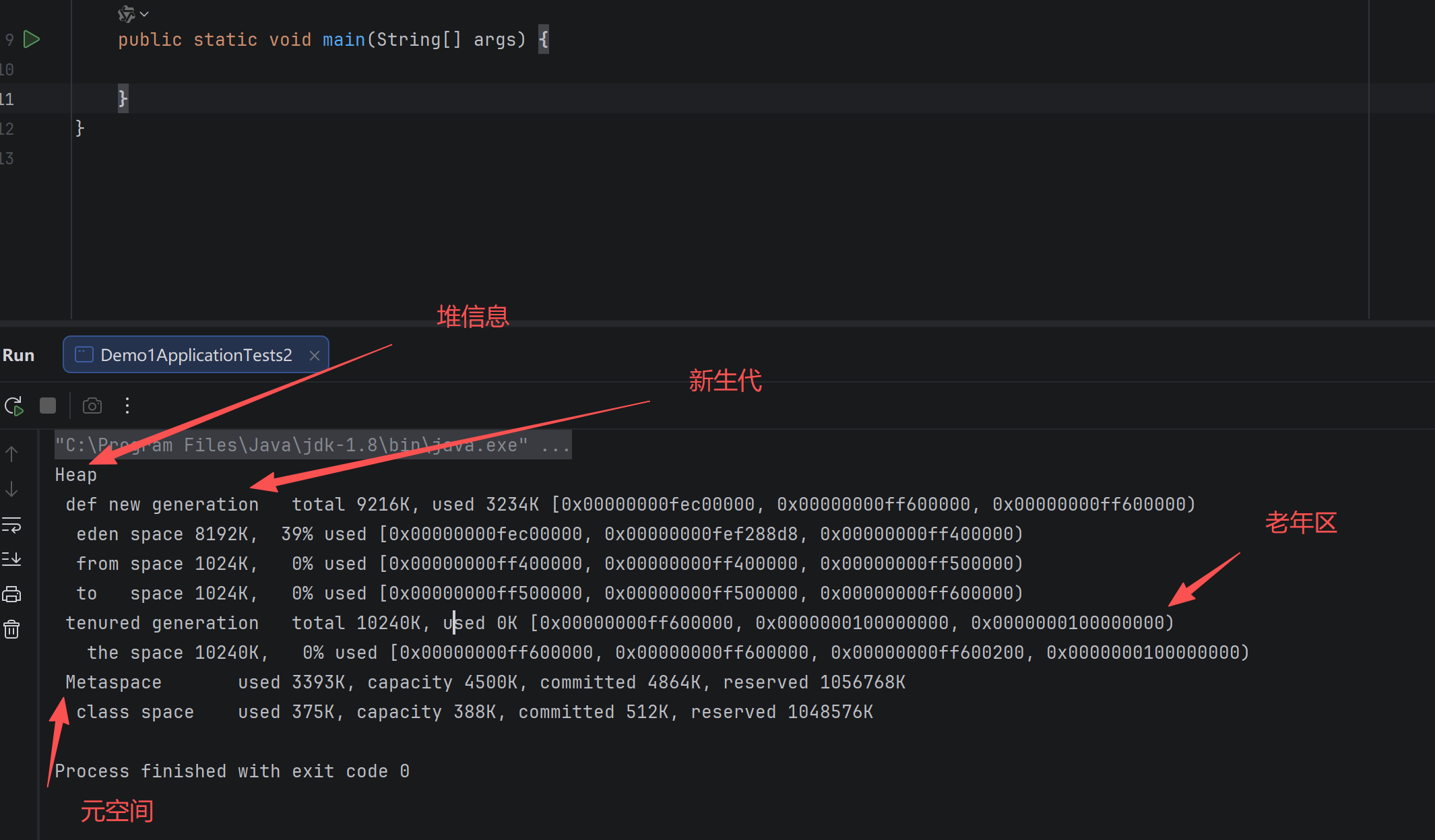
添加资源后: 可以看到,当存储容量超过了新生代,这时就不会判断寿命是否超过阈值,直接放入到老年代
4. 垃圾回收器
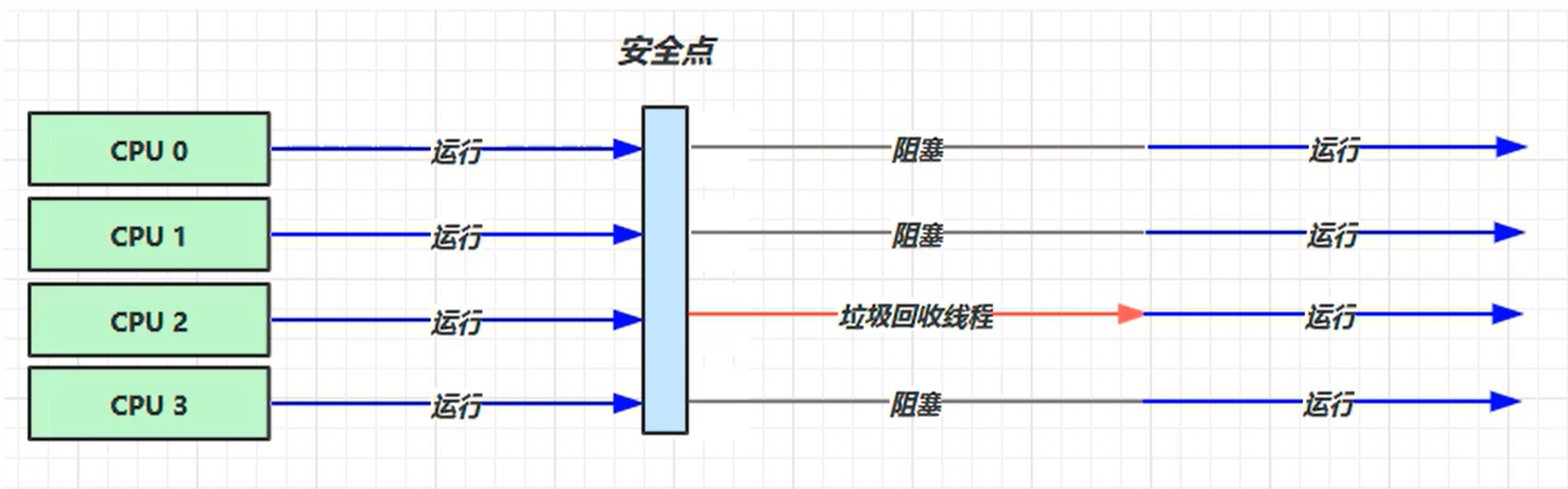
串行
- 单线程垃圾回收器
- 堆内存较小,适合个人电脑
-XX:+UseSerialGC = Serial + SerialOld (Serial 新生代算法, 复制 。 SerialOld 老年代算法,标记+ 整理)
当线程进入到安全点后,等待垃圾回收线程处理完毕后才能继续运行
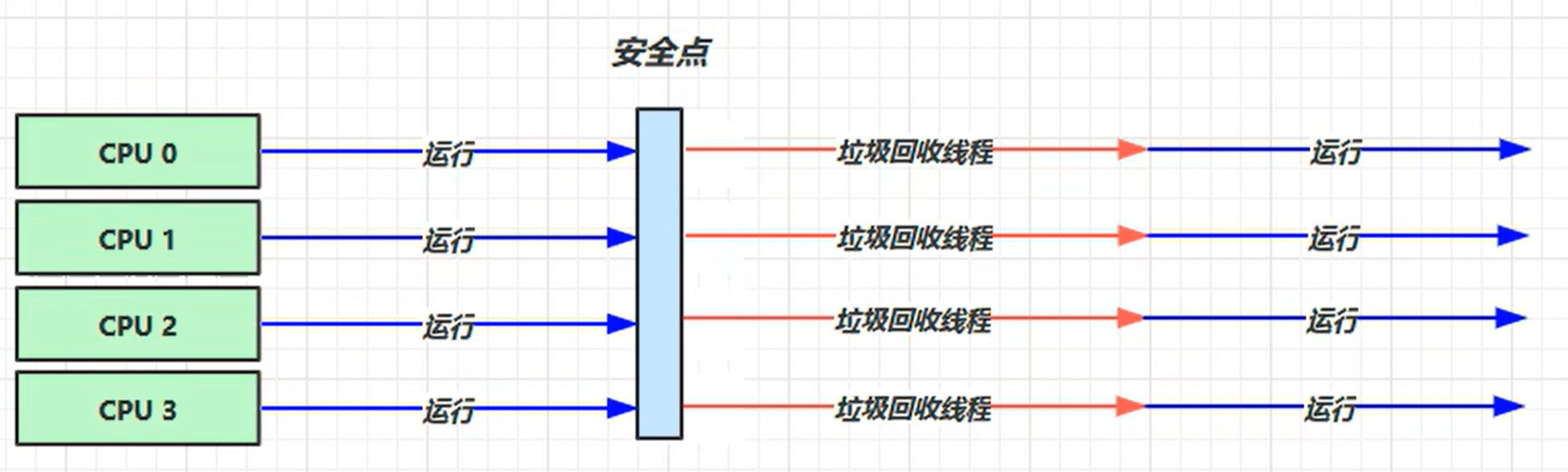
吞吐量优先
- 多线程
- 堆内存较大场景,多核cpu
- 让单位时间内,STW的时间最短 0.2 + 0.01 = 0.3
-XX:+UseParallelGC ~ -XX:+UseParallelOldGC
-XX:+UseAdaptiveSizePolicy (使用自适应的大小策略)
-XX:GCTimeRatio=ratio (调整吞吐量的目标 : 1 / 1+ratio )
-XX:MaxGCPauseMillis=ms ( 最大暂停毫秒数,默认200ms )
-XX:ParallelGCThreads=n (启动时指定并行 GC 线程为 n)
当线程运行到安全点后所有线程都进行垃圾回收后再继续运行
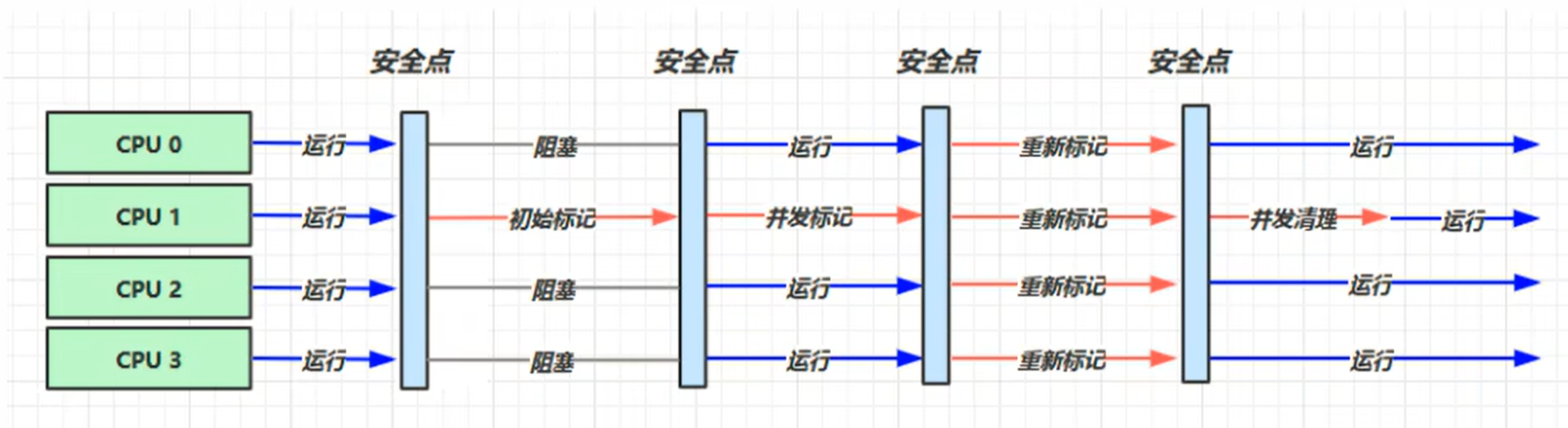
响应时间优先
- 多线程
- 堆内存较大场景,多核cpu
- 尽可能让单词STW的时间最短 0.1 + 0.1 + 0.1 = 0.3
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ Serial0ld
-XX:ParallelGCThreads=n ~ -XX:ConcGCThreads=threads
-XX:CMSInitiatingOccupancyFraction=percent (执行CMS垃圾回收的内存占比 为 percent 后回收)
-XX:+CMSScavengeBeforeRemark
| 分类 | 代表回收器 | 核心目标 | 特点 |
|---|---|---|---|
| 串行回收 | Serial、Serial Old | 简单轻量 | 单线程、STW 长、开销小 |
| 吞吐量优先 | Parallel Scavenge、Parallel Old | 高吞吐量 | 多线程并行、总 GC 耗时少 |
| 响应时间优先 | CMS、G1、ZGC、Shenandoah | 低延迟、短 STW | 并发回收、停顿短、体验好 |
经典组合(历史常用)
-
Serial/SerialOld:单线程、简单、延迟高
-
ParNew + CMS:低延迟、交互友好、碎片多
-
PS + ParallelOld:高吞吐量、计算型服务
-
G1:平衡吞吐与延迟,可设停顿目标,现在主流
-
ZGC:极致低延迟,超大堆专用
工作原理 + 区别 + 优劣势
1. Serial / Serial Old
原理
- 单线程 STW 回收
- 新生代:复制算法
- 老年代:标记 - 整理
优势
- 简单、额外开销极小
- 单核环境下效率最高
劣势
- STW 时间长,多核浪费
- 不适合服务端
适用
- 客户端、小内存、嵌入式
2. ParNew
原理
- Serial 的多线程并行版本
- 只作用于新生代,复制算法
- 唯一能和 CMS 配合的新生代回收器
优势
- 多核下比 Serial 快
- 配合 CMS 实现低延迟
劣势
- 依旧会全程 STW
- 不能和 Parallel Scavenge 混用
3. Parallel Scavenge / Parallel Old
原理
- 多线程并行 STW
- 新生代:复制
- 老年代:标记 - 整理
- 目标是最大化吞吐量
优势
- 高吞吐、CPU 利用率高
- 适合计算密集、批处理、后台任务
劣势
- STW 时间可能较长,不适合低延迟接口
4. CMS(Concurrent Mark Sweep)老年代
原理(4 步)
- 初始标记:STW,标记 GC Roots
- 并发标记:和业务线程一起跑,耗 CPU
- 重新标记:STW,修正并发期间变动
- 并发清除:和业务线程一起清除
优势
- STW 极短,低延迟
- 适合互联网 Web 服务
劣势
- 内存碎片(标记清除算法)
- 浮动垃圾
- 并发抢占 CPU
- 会发生 Concurrent Mode Failure,退化为 Serial Old,导致长 STW
关键区别
CMS 是最早追求低延迟的并发回收器,但不整理内存,老年代容易炸。
5. G1(Garbage-First)
原理
- 堆划分为多个 Region
- 局部收集,优先回收垃圾最多的区域
- 初始标记 → 并发标记 → 最终标记 → 筛选回收
- 支持设置预期停顿时间
优势
- 平衡吞吐量 + 延迟
- 可预测停顿
- 空间整合好,无明显碎片
- JDK8 及以后服务端首选
劣势
- 堆非常大时,停顿仍可能超出预期
- 比 CMS 复杂,调参多
与 CMS 核心区别
- CMS:整个老年代一起回收
- G1:按 Region 回收,可控、更稳定
6. ZGC
原理
- 全并发
- 染色指针 + 读屏障
- 几乎所有工作都和业务线程并行
优势
- 停顿亚毫秒级
- 停顿时间不随堆变大而增加
- 无碎片,极强稳定性
劣势
- JDK11+ 才稳定
- 吞吐量略低于 G1
- 调试工具生态不如 G1 成熟
与 G1 区别
- G1 仍有短暂 STW
- ZGC 几乎无 STW,面向超大堆 + 极低延迟
对比
CMS vs G1
CMS:低延迟但碎片多、不稳定
G1:区域回收、无碎片、可控停顿,更适合现代服务
G1 vs ZGC
G1:通用、稳定、生态好
ZGC:延迟更低,适合金融 / 支付 / 网关
ParNew vs Parallel Scavenge
ParNew:配合 CMS
Parallel:配合 Parallel Old,追求吞吐量
生产环境如何选择?
-
小内存、单机应用
→ Serial / SerialOld
-
追求高吞吐量、后台计算、批处理
→ Parallel Scavenge + Parallel Old
-
互联网 Web 服务,要求响应快、延迟低
→ CMS(传统),现在逐步被 G1 替代
-
中大型项目、微服务、云原生应用
→ G1(JDK 8+ 标配,平衡易用性与性能)
-
金融、支付、网关,要求极低延迟、超大堆
→ ZGC(JDK 11+ 稳定)
G1 垃圾回收器详解:
适用场景:
- 同时注重吞吐量 和 低延迟,默认的暂停目标时200ms
- 超大堆内存,会导致处理慢,而G1会将堆划分对各大小相等的region
- 整体上时标记+整理算法,连个区域之间时复制算法
region区域
| 类型 | 作用 | 回收时机 |
|---|---|---|
| Eden | 新对象分配区(新生代) | Young GC 回收 |
| Survivor | 存活对象暂存区(新生代) | Young GC 后晋升 |
| Old | 长期存活对象(老年代) | Mixed GC 回收 |
| Humongous | 大对象区(>50% RegionSize) | 直接按老年代回收 |
| Free | 空闲区,等待分配 | 随时可被复用 |
相关 JVM 参数:
-XX:+UseG1GC
-XX:G1HeapRegionSize=size
-XX:MaxGCPauseMillis=time
回收阶段:
Young Collection -> Young Collection + Concurrrnt Mark -> Mixed Collection
(新生代收集 -> 新生代收集 + 并发标记 -> 混合收集)
Young Collection:
- 新生代回收的跨代引用(老年代引用新生代)问题,引出"卡"的概念,出现了一个老年代对象引用了新生代对象,这个对应的卡就标记为脏卡
- 卡表与Remembered Set(新生代) 会记录外部 过来的引用,通过此知道外部的脏卡
- 在引用变更时通过post-write barrier+dirty card queue
- concurrent refinement threads更新Remembered Set
Young Collection + CM:
- 在Young GC时会进行GC Root 的初始标记
- 老年代占用堆空间比例达到阈值时,进行并发标记(不会STW),由下面的JVM参数决定 (-XX:InitiatingHeapOccupancyPercent=percent (默认45%), 意思是老年代占用了堆空间的45%开始并发标记)
Mixed Collection
会对E、S、O进行全面垃圾回收
- 最终标记会 STW
- 拷贝存活会 STW
-XX:MaxGCPauseMillis=ms (最大暂停时间)
G1 会根据最大暂停时间 , 有选择的去选择一部分老年代区域 去 回收
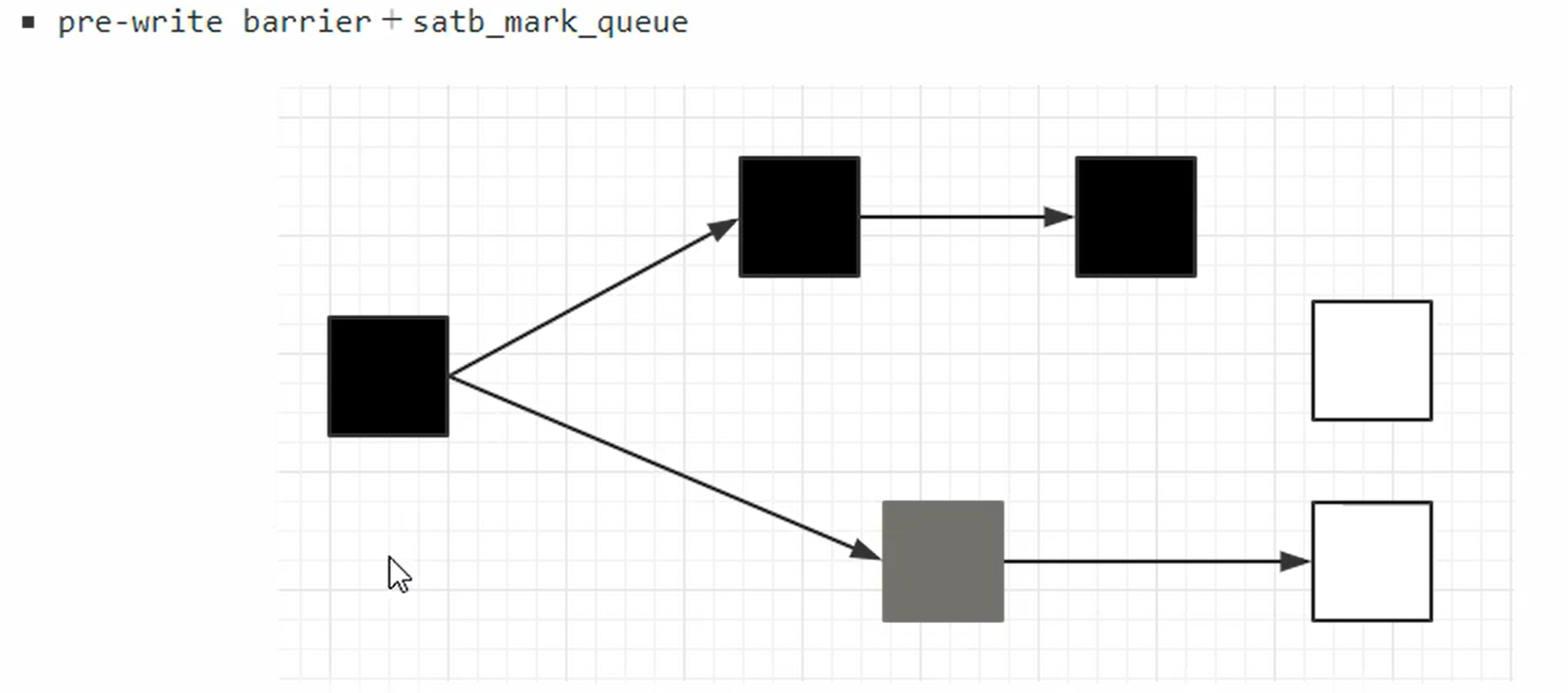
Remark 重新标记
并发标记阶段时对象的处理状态,黑色的表示处理完成会被保留下来的,灰色是处理中,白色未处理
A -> B
A -> C
D 从 最开始的被标记为白色垃圾,在并发标记阶段 ,又被 A 引用了, 那么就触发写屏障保护,会被放入到队列中,到了重新标记阶段发生STW后标记为黑色
JDK 8u20字符串去重
- 优点:节省大量内存
- 缺点:略微多占用了cpu时间,新生代回收时间略微增加
-XX:+UseStringDeduplication
java
String s1 = new String("hello");// char[]{'h','e','l','l','o'}
String s2 = new String("hello");// char[]{'h','e','l','l','o'}
// 问题 在jdk8时候 String 对象是以 char数组形式存储来多少创建多少 造成浪费- 将所有新分配的字符串放入一个队列
- 当新生代回收时,G1并发检查是否有字符串重复
- 如果他们值一样,让它们引用同一个char\[\]
- 注意,与String.intern()不一样
- String.intern()关注的是字符串对象
- 而字符串去重关注的是char\[\]
- 在 JVM 内部,使用了不同的字符串表
JDK8u40 并发标记类卸载
所有对象都经过并发标记后,就能知道道哪些类不再被使用,当一个类加载器的所有类都不再使用,则卸载它所加载的所有类
-XX:+ClassUnloadingWithConcurrentMark 默认启动
JDK8u60回收巨型对象
- 一个对象大于region的一半时,称之为巨型对象
- G1不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1会跟踪老年代所有incoming引用,这样老年代incoming引用为0的巨型对象就可以在新生代垃圾回收时处理掉
JDK9并发标记起始时间的调整
- 并发标记必须在堆空间占满前完成,否则退化为Full GC
- JDK9之前需要使用-XX:InitiatingHeapOccupancyPercent
- JDK9可以动态调整
- -XX:InitiatingHeapOccupancyPercent用来设置初始值
- 进行数据采样并动态调整
- 总会添加一个安全的空档空间
5. 垃圾回收调优
调优领域
内存:
锁竞争:
cpu占用:
io:
确定目标:
低延迟还是高吞吐量? 选择适合的垃圾回收器
最快的GC是不发生GC :
如果经常发生 FULL GC 考虑是否有其他问题
- 数据是不是太多了
- 数据是否太臃肿了 : 能用基本类型就不用包装类型
- 是否存在内存泄漏 : static Map map = , 软引用, 弱引用 , 第三方缓存
新生代调优:
新生代特点
- 所有的new操作的内存分配非常廉价
- tlab thread-local allocation buffer
- 死亡对象回收代价是零
- 大部分对象用过即死
- Minor GC 的时间远远低于Full GC
新生代设置与大越好吗?
不对,如果新生代越大那么对应的老年代就越小,从而引发Full GC ,耗时更长。分配的过大,新生代的的标记复制算法耗时也会更长。大小一般处于堆内存的1/3
-
幸存区的大到需要能够保留【当前活跃对象+需要晋升对象】
-
晋升阈值配置的当,让长时间存活对象尽快晋升 【-XX:MaxTenuringThreshold=threshold -XX:+PrintTenuringDistribution】
老年代调优:
以CMS为例:
- CMS的老年代内存越大越好
- 先尝试不做调优,如果没有Full GC 那么一句...,或者现场时调优新生代
- 观察发生Full GC 时,老年代内存占用,将老年代内存预设调大1/4~1/3
- -XX:CMSInitiatingOccupancyFraction=percent
案列:
- Full GC 和Minor GC 频繁
分析 : 业务高峰期来了,大量对象创建,导致幸存区晋升阈值降低,直接放入到老年代,导致老年代大量 垃圾对象从而导致Full GC 频繁,可能的原因时因为 新生代内存太小了
- 请求高峰期发生Full GC ,单次暂停时间特别长(CMS)
分析: 需要分析哪一步耗时长,已知用的垃圾回收器时CMS 那么出现问题在 初始标记 和 重新标记 两个阶段,可以查看GC日志判断具体是在哪一步耗费时间长,在重新标记耗时长,重新标记会扫描新生代 + 老年代 的情况在高峰情况下会变得慢,在重新标记前,先处理新生代的对象GC清理,减少处理数量 。-XX:+CMSScavengeBeforeRemark
- 老年代充裕情况下发生Full GC
分析:考虑是否使用的jdk1.8以前的版本,如果是那么有可能是永久代的空间不足导致了Full GC,而1.8以后元空间用的是操作系统的空间,空间还是很充裕的。
类加载:
定义:类加载器,将字节码文件加载到jvm中
类文件结构
执行 javac -parameters -d . xxx.class 可以查看到class文件的二进制文件
魔数
0~3字节,表示它是否是【class】类型的文件
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
版本
4~7字节,表示类的版本00 34(52)表示是Java 8
0000000 ca fe ba be 00 0 00 34 00 23 0a 00 06 00 15 09
常量池
8~9字节,表示常量池长度,00 23 (35)表示常量池有#1~#34项,注意#0项不计入,也没有值
0000000 ca fe ba be 00 00 00 34 00 23 0a 0006 00 15 09
第#1项0a表示一个Method信息,0006和0015(21) 表示它引用了常量池中#6和#21 项来获得这个方法的【所属类】和【方法名】
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
javap工具
原始java代码
public class Demo1ApplicationTests2 {
public static void main(String[] args) {
int a = 10;
int b = Short.MAX_VALUE + 1 ;
int c = a + b;
System.out.println(c);
}
}编译后的字节码文件
shell
javap -v target/test-classes/com/example/demo/Demo1ApplicationTests2.class
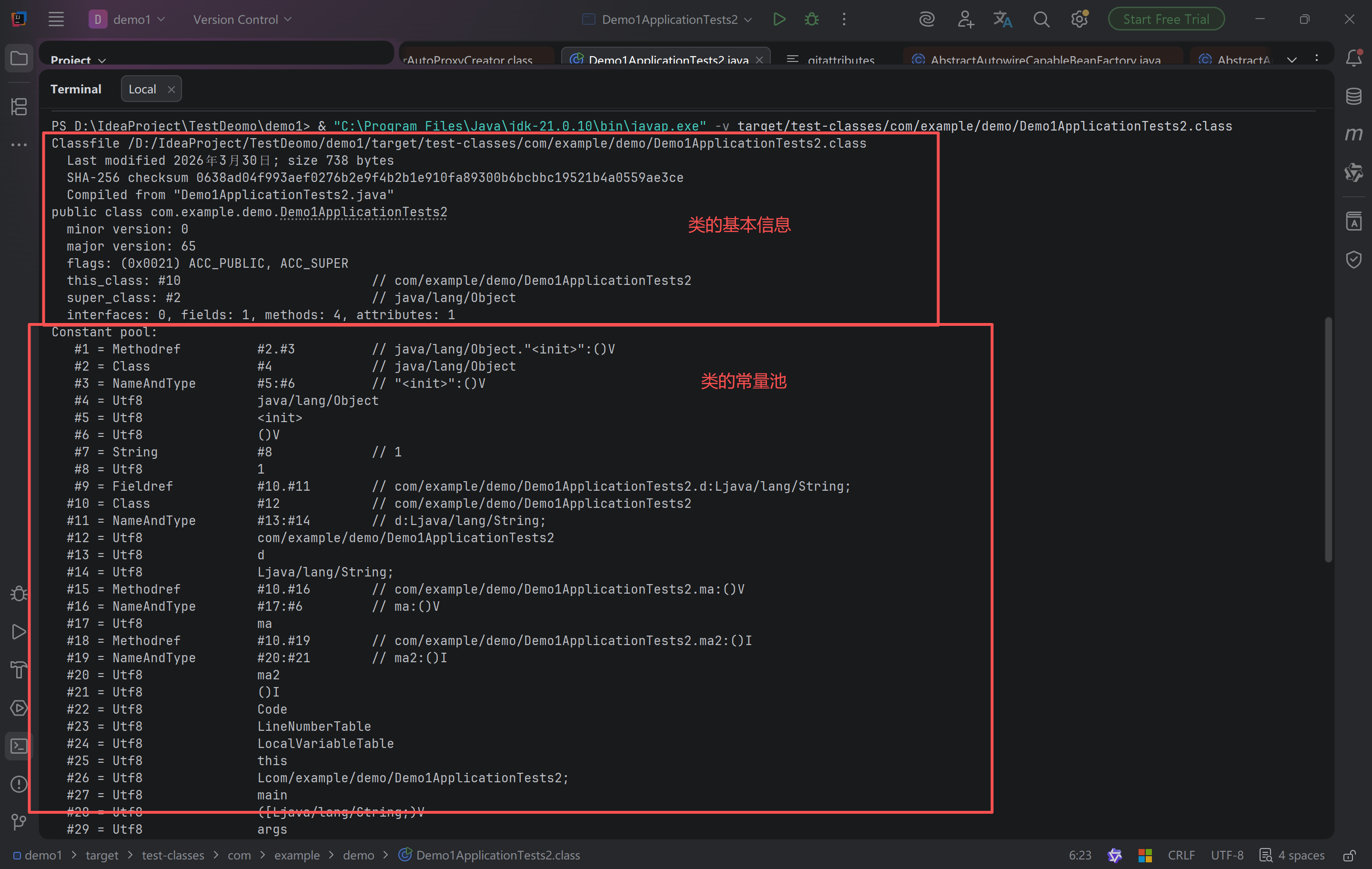
Classfile /D:/IdeaProject/TestDeomo/demo1/target/test-classes/com/example/demo/Demo1ApplicationTests2.class
Last modified 2026年4月1日; size 692 bytes
SHA-256 checksum 217b2977a258893e12d173279fff7f98fac8bcca83ad216bfdc0fc56e1476c5e
Compiled from "Demo1ApplicationTests2.java"
public class com.example.demo.Demo1ApplicationTests2
minor version: 0
major version: 52
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #6 // com/example/demo/Demo1ApplicationTests2
super_class: #7 // java/lang/Object
interfaces: 0, fields: 0, methods: 2, attributes: 1
Constant pool:
#1 = Methodref #7.#26 // java/lang/Object."<init>":()V
#2 = Class #27 // java/lang/Short
#3 = Integer 32768
#4 = Fieldref #28.#29 // java/lang/System.out:Ljava/io/PrintStream;
#5 = Methodref #30.#31 // java/io/PrintStream.println:(I)V
#6 = Class #32 // com/example/demo/Demo1ApplicationTests2
#7 = Class #33 // java/lang/Object
#8 = Utf8 <init>
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 LocalVariableTable
#13 = Utf8 this
#14 = Utf8 Lcom/example/demo/Demo1ApplicationTests2;
#15 = Utf8 main
#16 = Utf8 ([Ljava/lang/String;)V
#17 = Utf8 args
#18 = Utf8 [Ljava/lang/String;
#19 = Utf8 a
#20 = Utf8 I
#21 = Utf8 b
#22 = Utf8 c
#23 = Utf8 MethodParameters
#24 = Utf8 SourceFile
#25 = Utf8 Demo1ApplicationTests2.java
#26 = NameAndType #8:#9 // "<init>":()V
#27 = Utf8 java/lang/Short
#28 = Class #34 // java/lang/System
#29 = NameAndType #35:#36 // out:Ljava/io/PrintStream;
#30 = Class #37 // java/io/PrintStream
#31 = NameAndType #38:#39 // println:(I)V
#32 = Utf8 com/example/demo/Demo1ApplicationTests2
#33 = Utf8 java/lang/Object
#34 = Utf8 java/lang/System
#35 = Utf8 out
#36 = Utf8 Ljava/io/PrintStream;
#37 = Utf8 java/io/PrintStream
#38 = Utf8 println
#39 = Utf8 (I)V
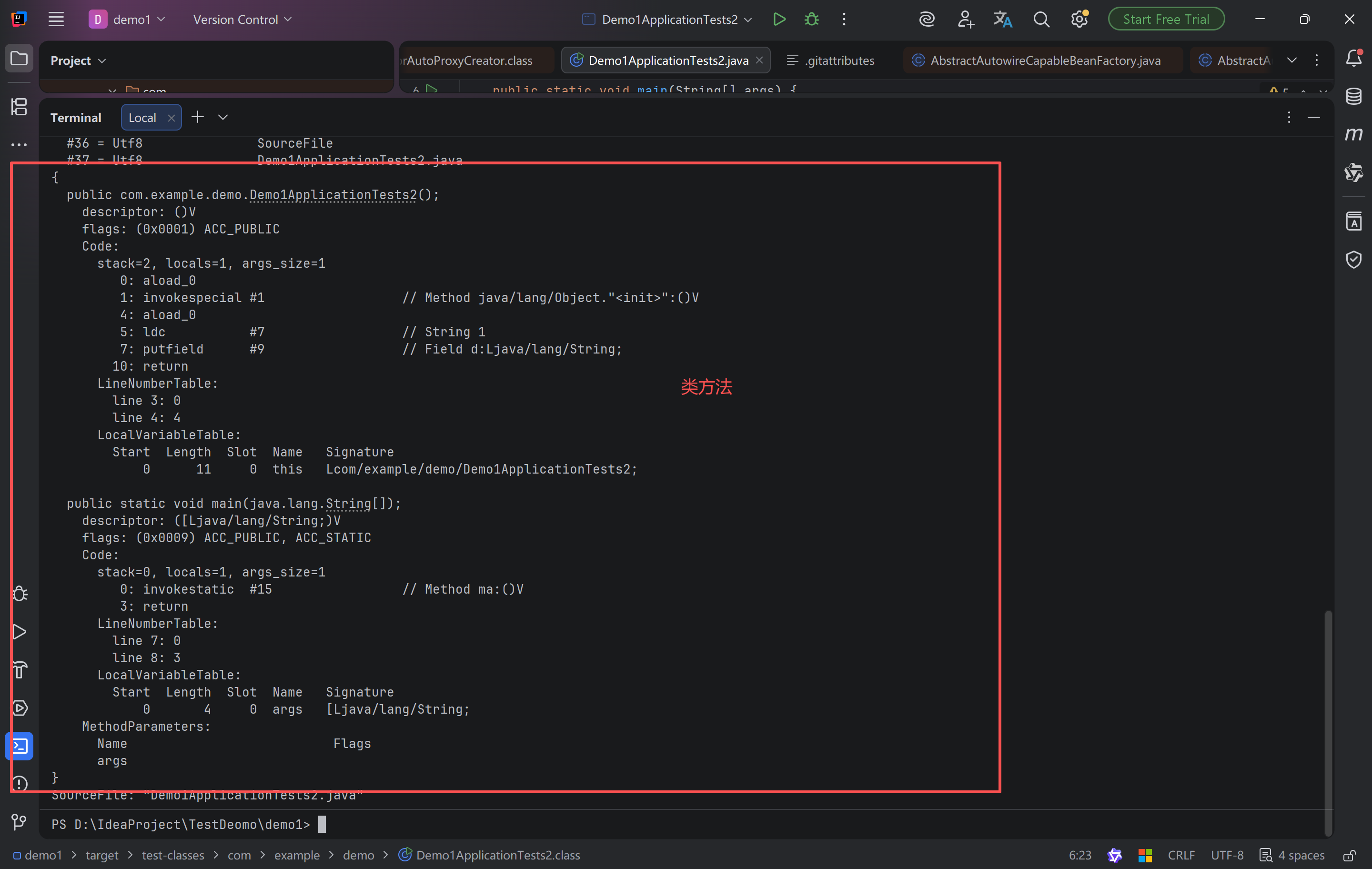
{
public com.example.demo.Demo1ApplicationTests2();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/example/demo/Demo1ApplicationTests2;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 10
2: istore_1
3: ldc #3 // int 32768
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
13: iload_3
14: invokevirtual #5 // Method java/io/PrintStream.println:(I)V
17: return
LineNumberTable:
line 11: 0
line 12: 3
line 13: 6
line 14: 10
line 15: 17
LocalVariableTable:
Start Length Slot Name Signature
0 18 0 args [Ljava/lang/String;
3 15 1 a I
6 12 2 b I
10 8 3 c I
MethodParameters:
Name Flags
args
}
SourceFile: "Demo1ApplicationTests2.java"常量池载入运行时常量池
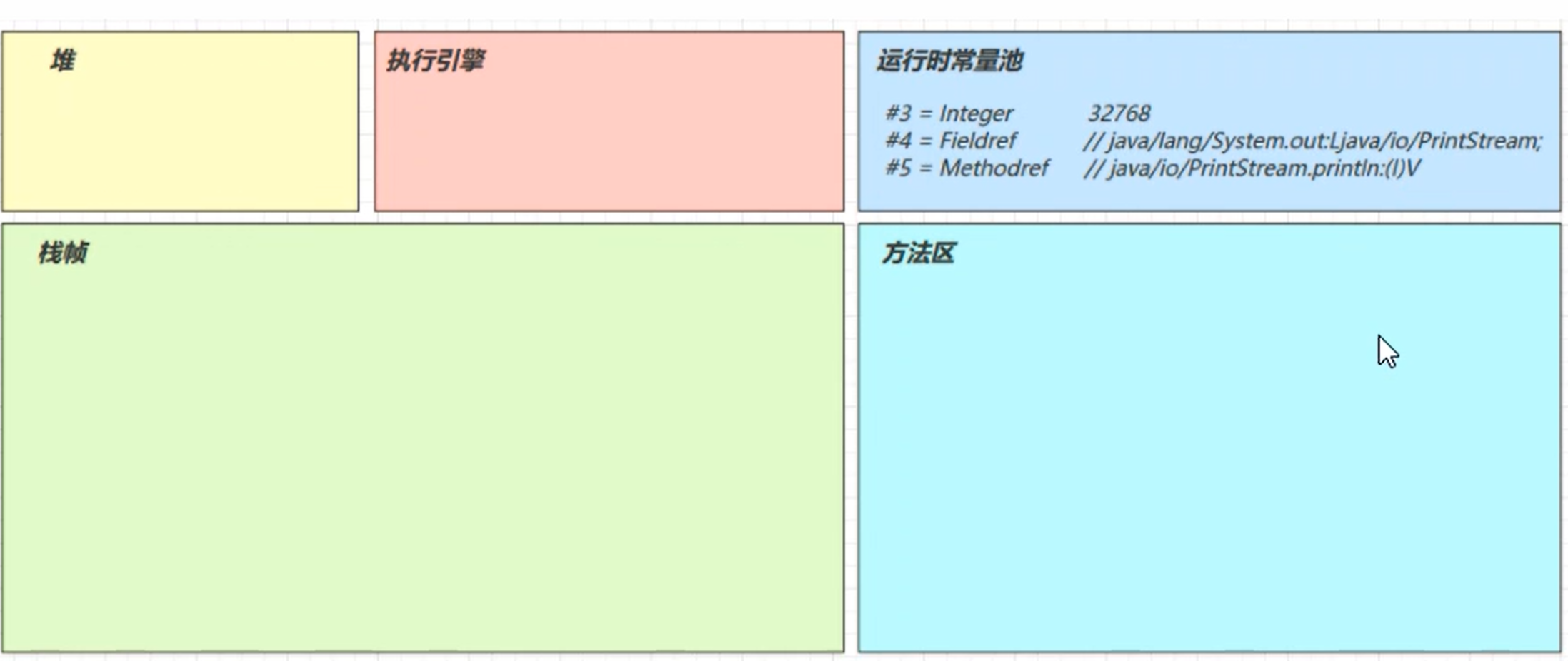
方法字节码载入方法区
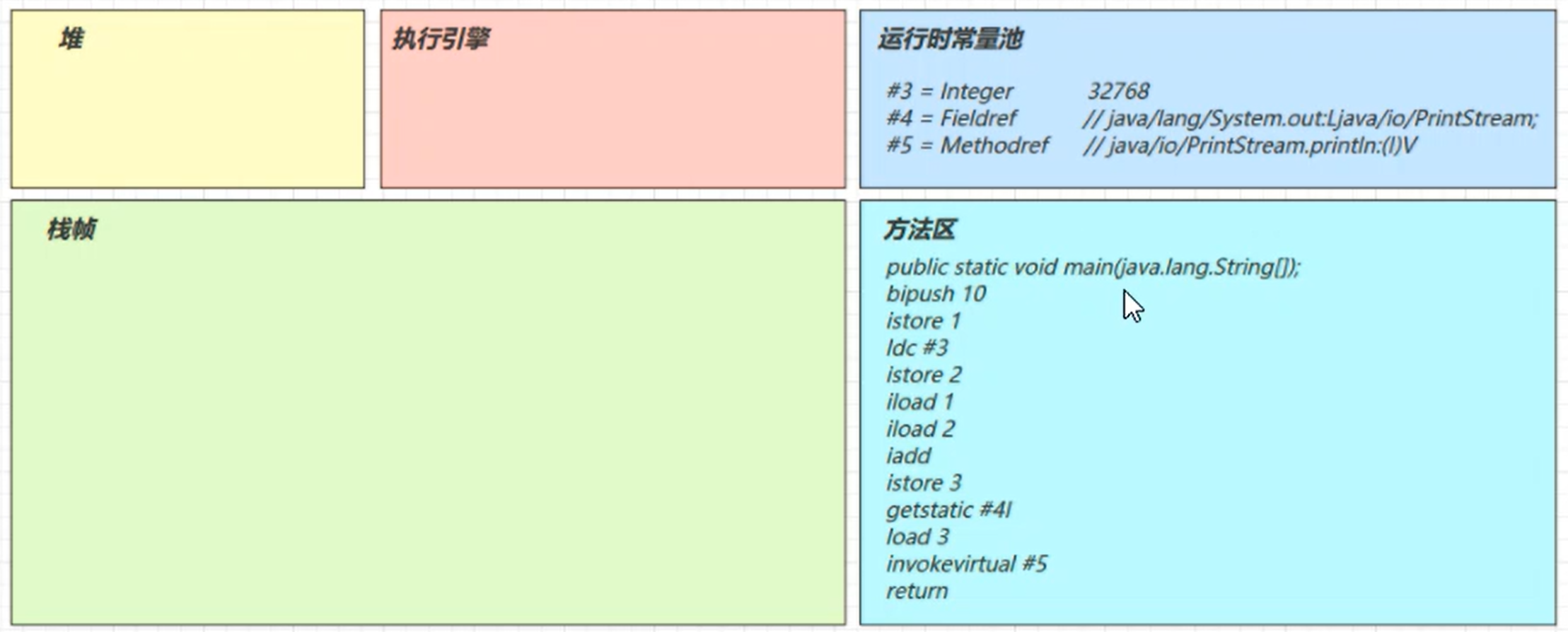
main线程开始运行,分配栈帧内存
执行引擎开始执行字节码 (读取方法区的字节开始执行)
bipush 10
- 将一个byte压入操作数栈(其长度会补齐4个字节),类似的指令还有
- sipush将一个short压入操作数栈(其长度会补齐4个字节)
- ldc将一个int压入操作数栈
- ldc2_w将一个long压入操作数栈(分两次压入,因为long是8个字节)
- 这里小的数字都是和字节码指令存在一起,超过short范围的数字存入了常量池
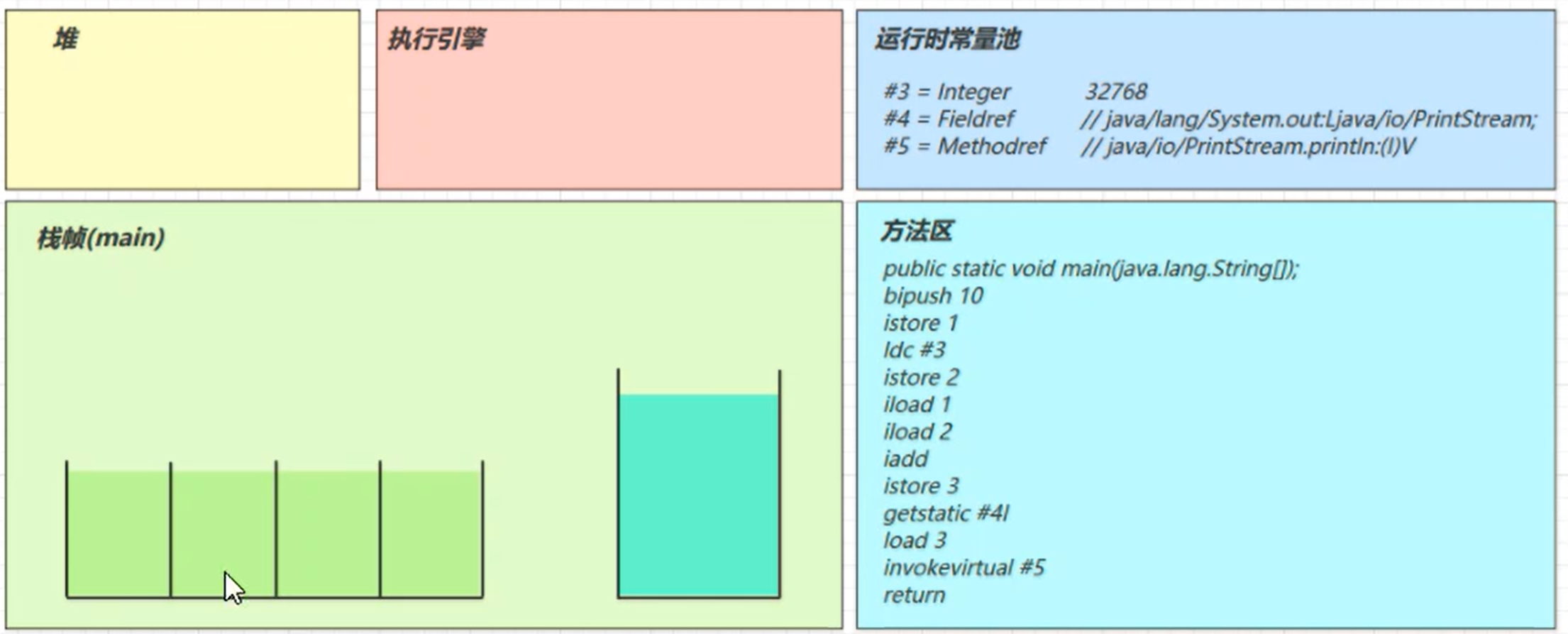
istore_1
将操作数栈顶数据弹出,存入局部变量表的slot! 结果就是 a = 10
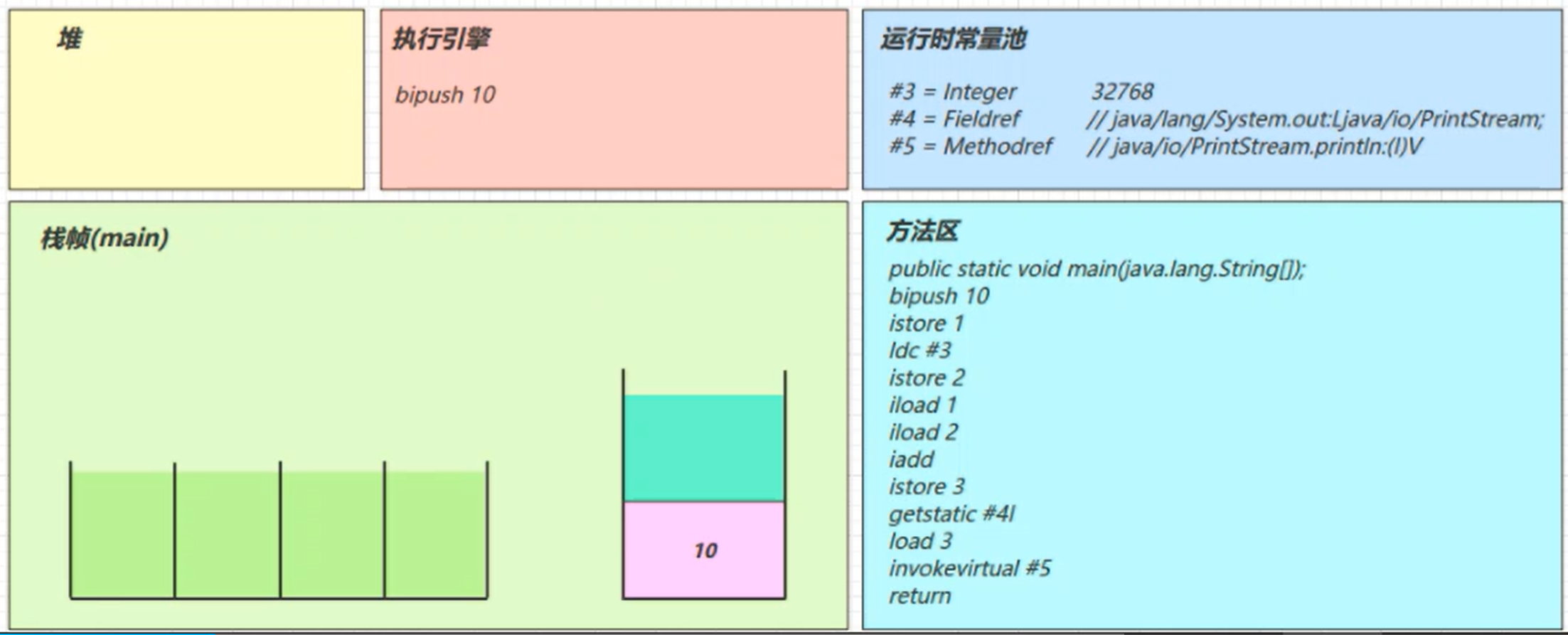
ldc #3
从常量池加载#3数据到操作数栈
注意Short.MAX_VALUE是32767,所以32768= Short.MAX_VALUE+1实际是在编译期间计算好的
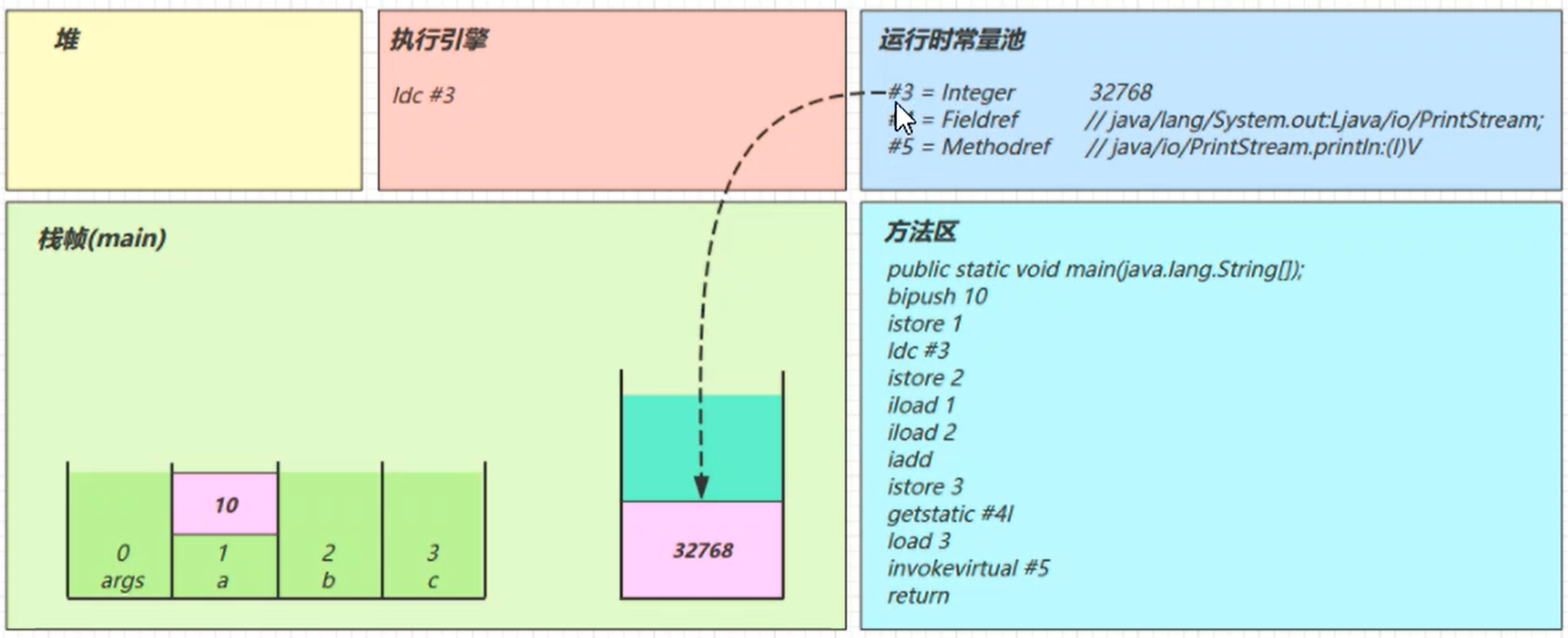
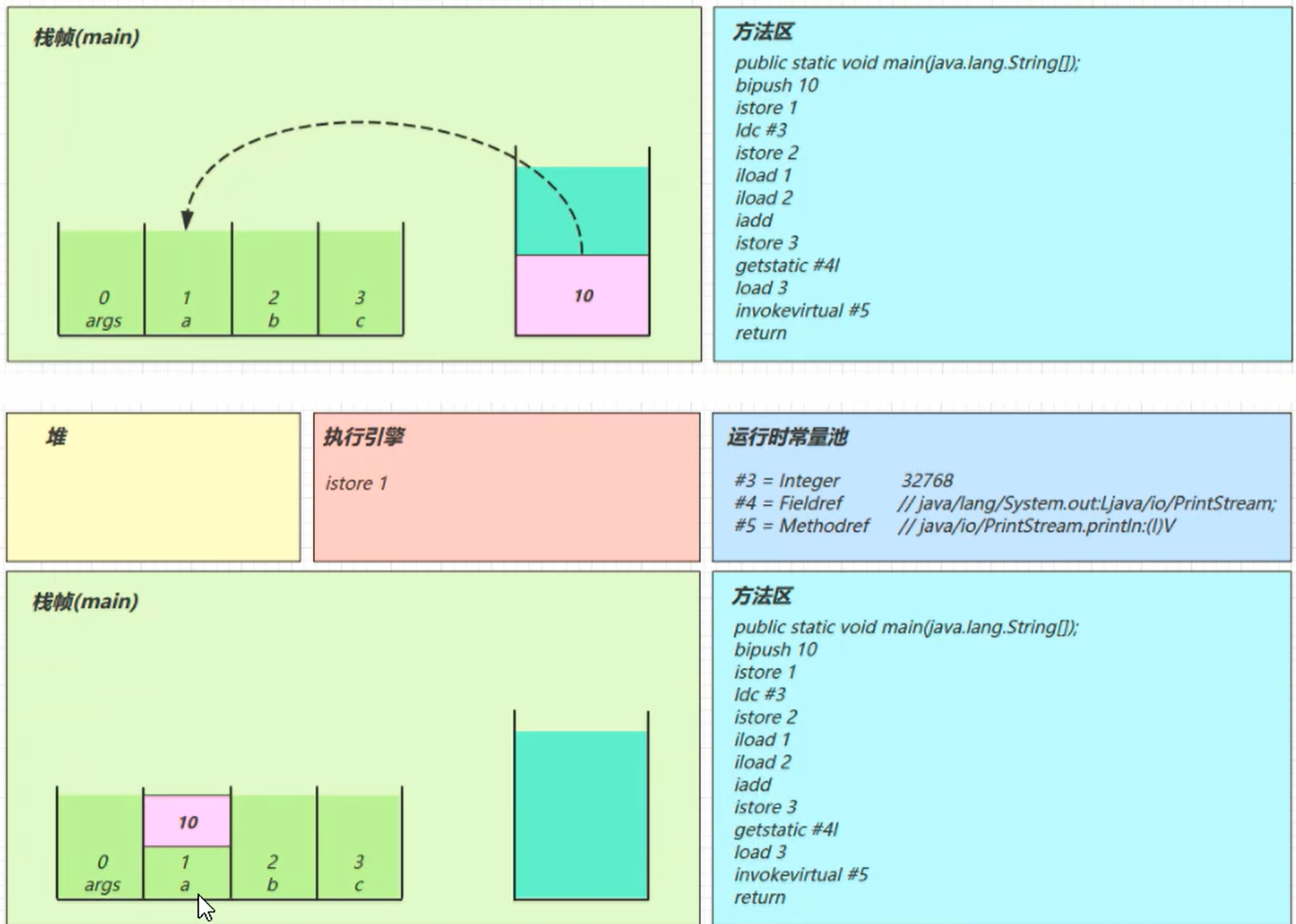
istore_2
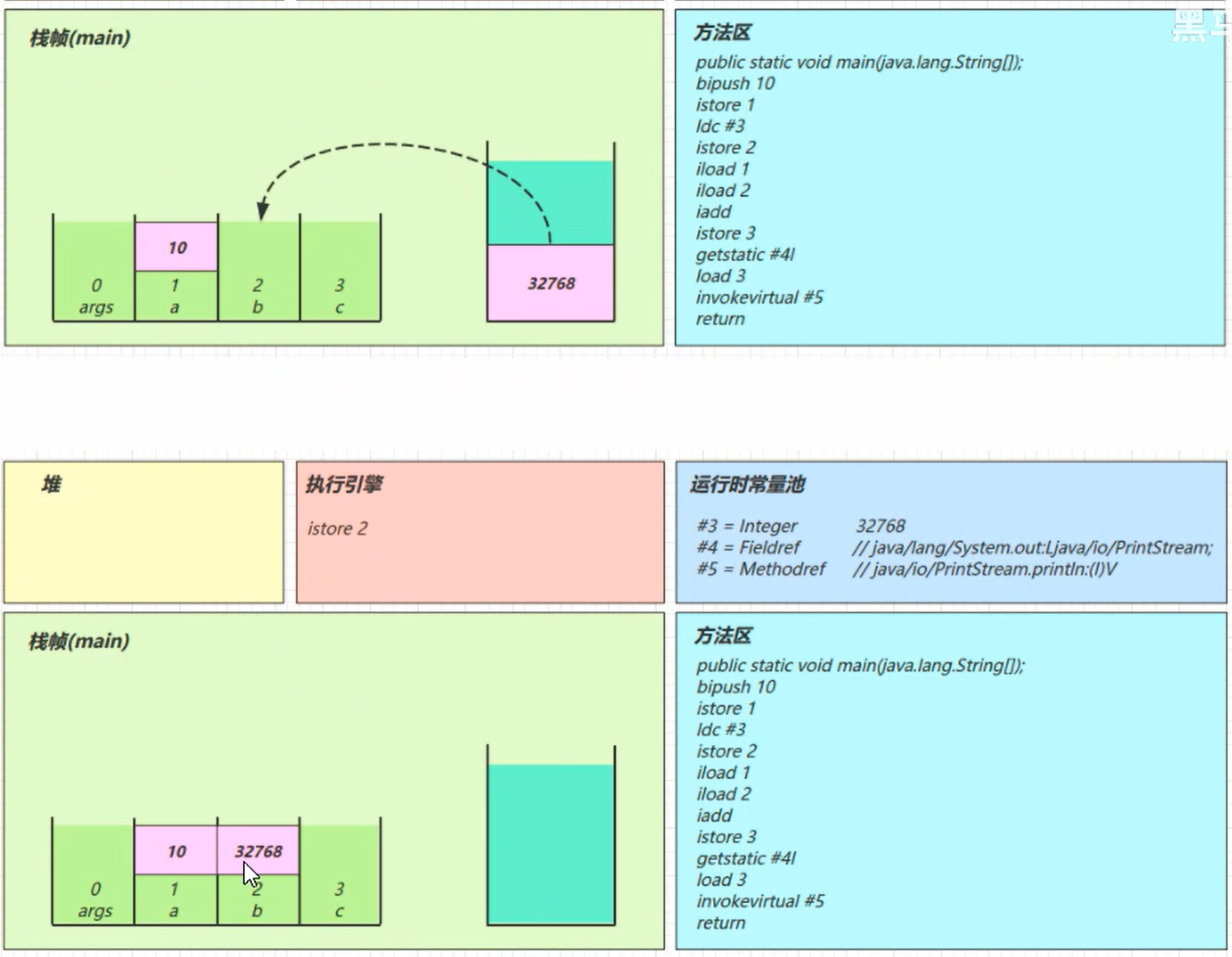
:
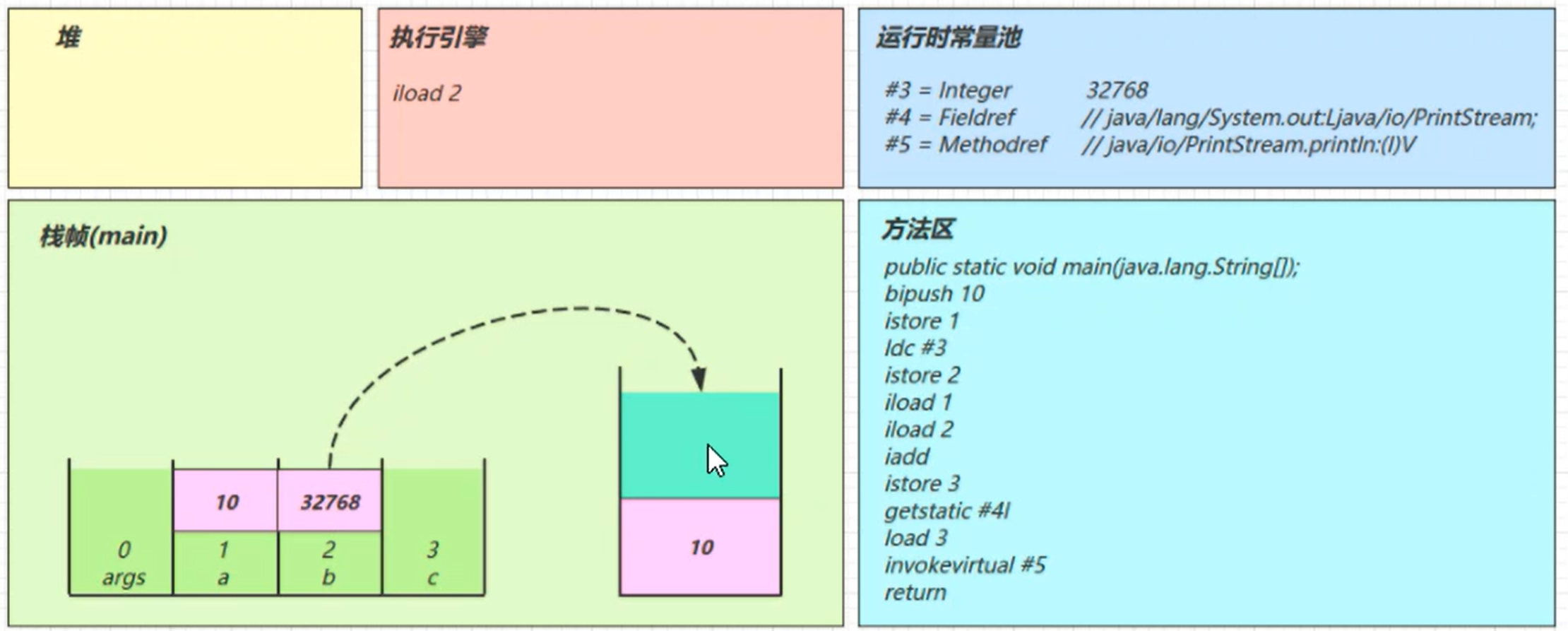
iload_2
分别把 局部变量 1 和 2 号槽位 的 10 和 32768 读到栈里
iadd
将栈中的数据弹出计算后存入新的结果值
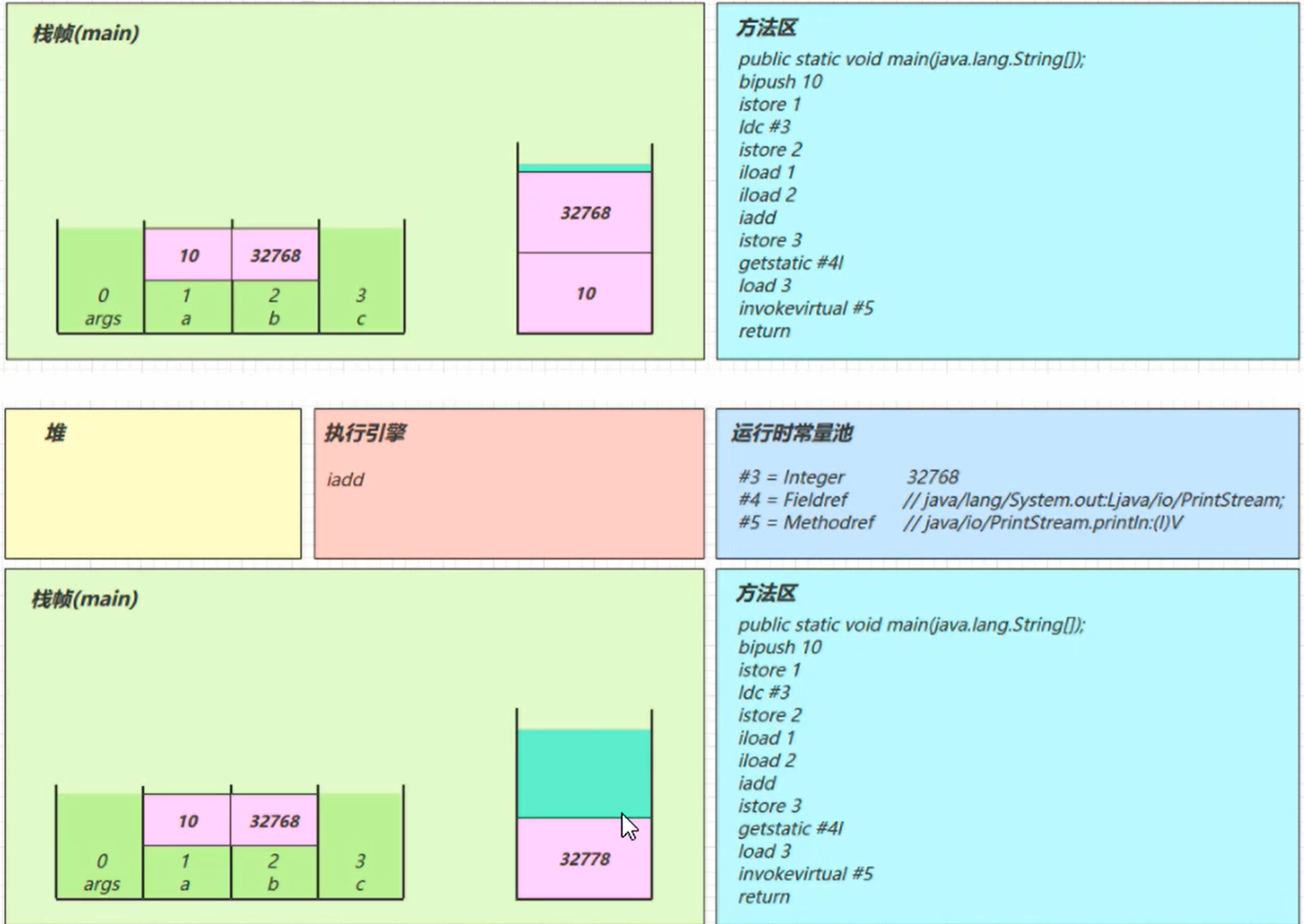
istore_3
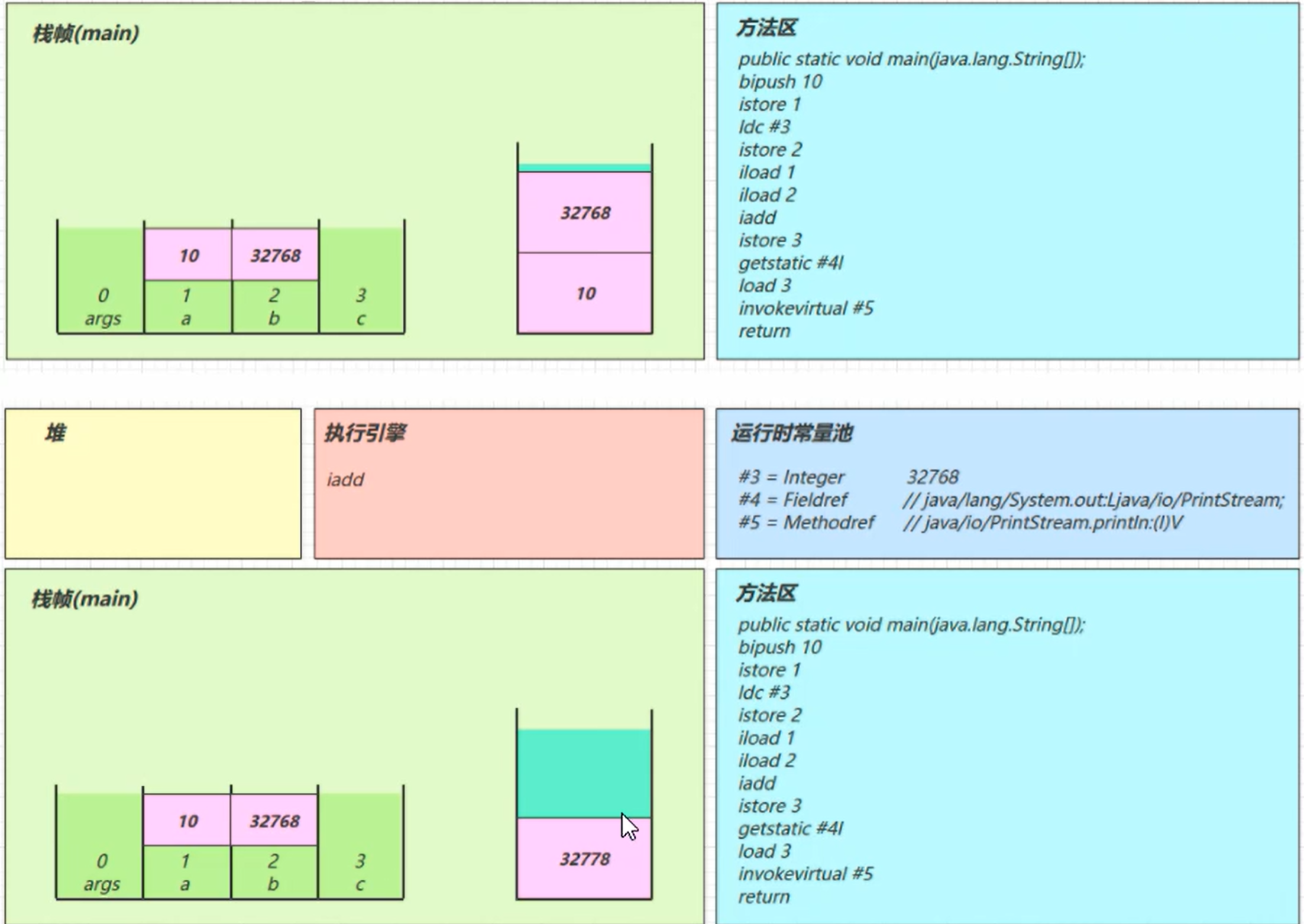
getstatic #4
从常量池获取 #4 的引用对象 放入堆和栈中
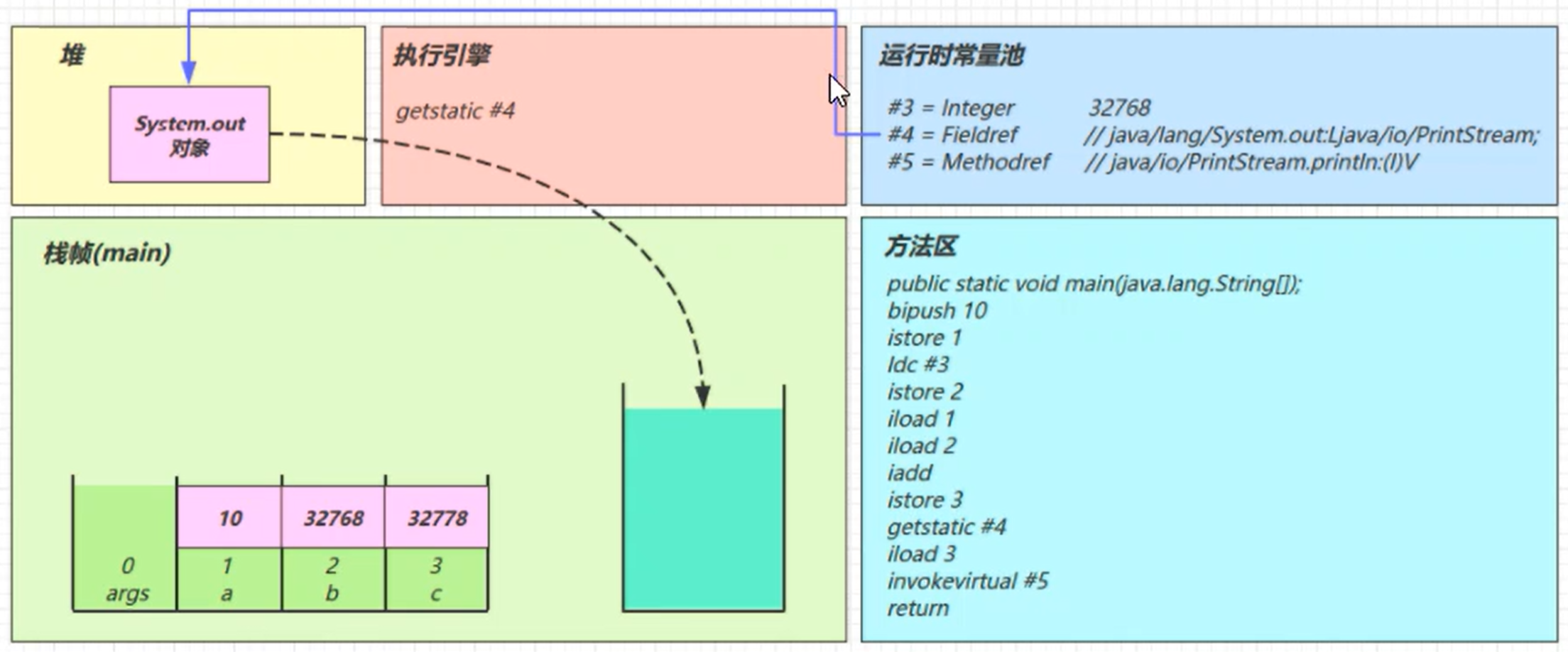
iload_3
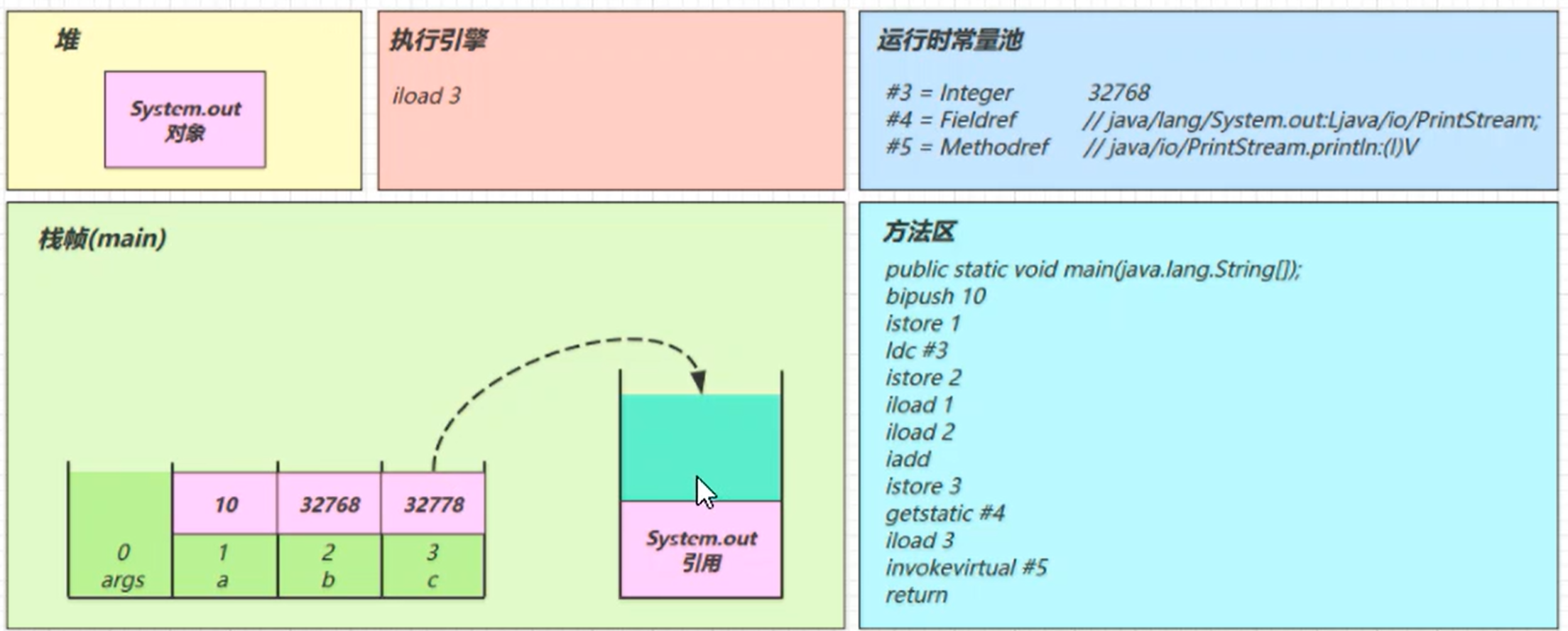
invokevirtual #5
找到常量池#5项
定位到方法区java/io/PrintStream.println:(I)V方法
生成新的栈帧(分配locals、stack等)
传递参数,执行新栈帧中的字节码
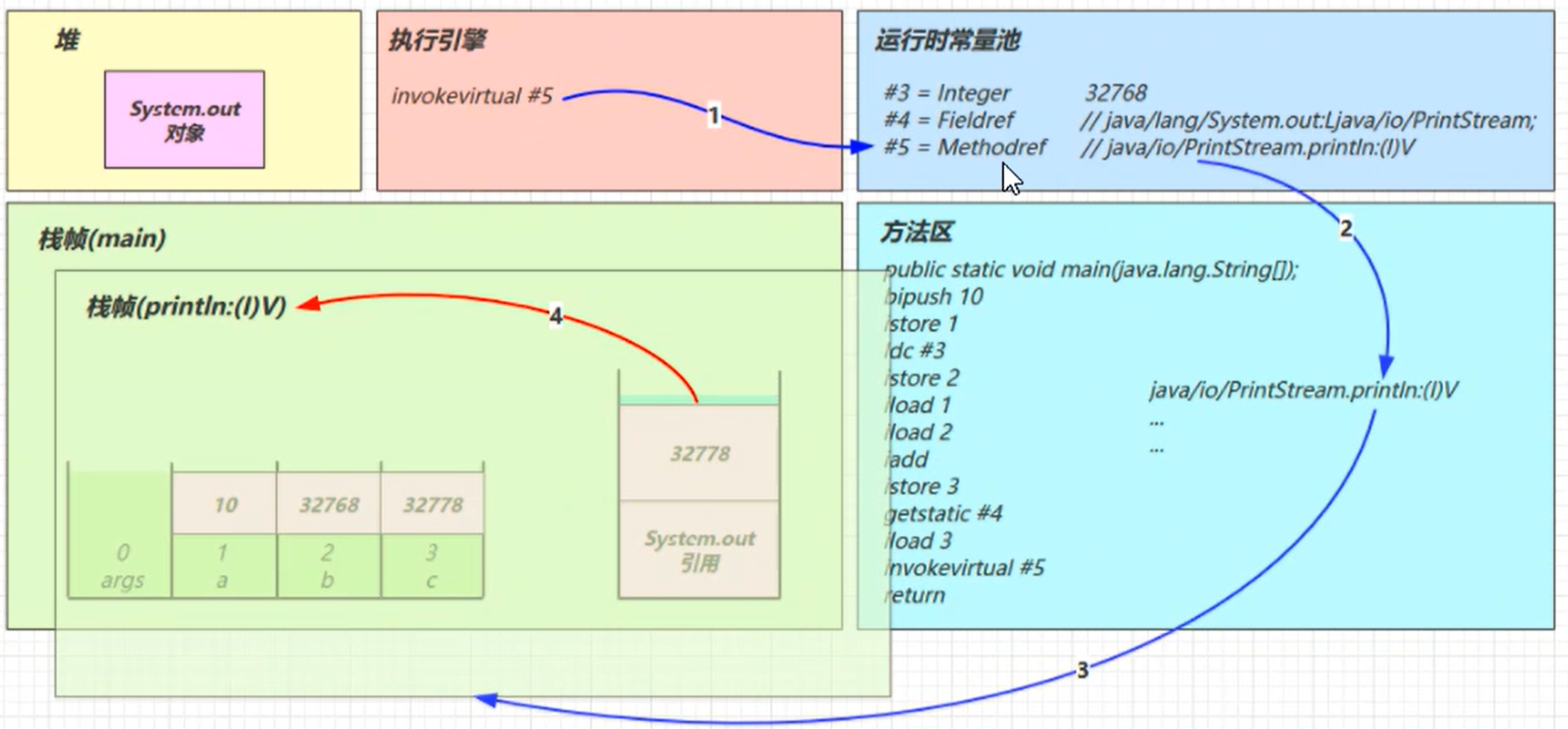
执行完毕后,弹出栈帧
清除main操作数栈内容
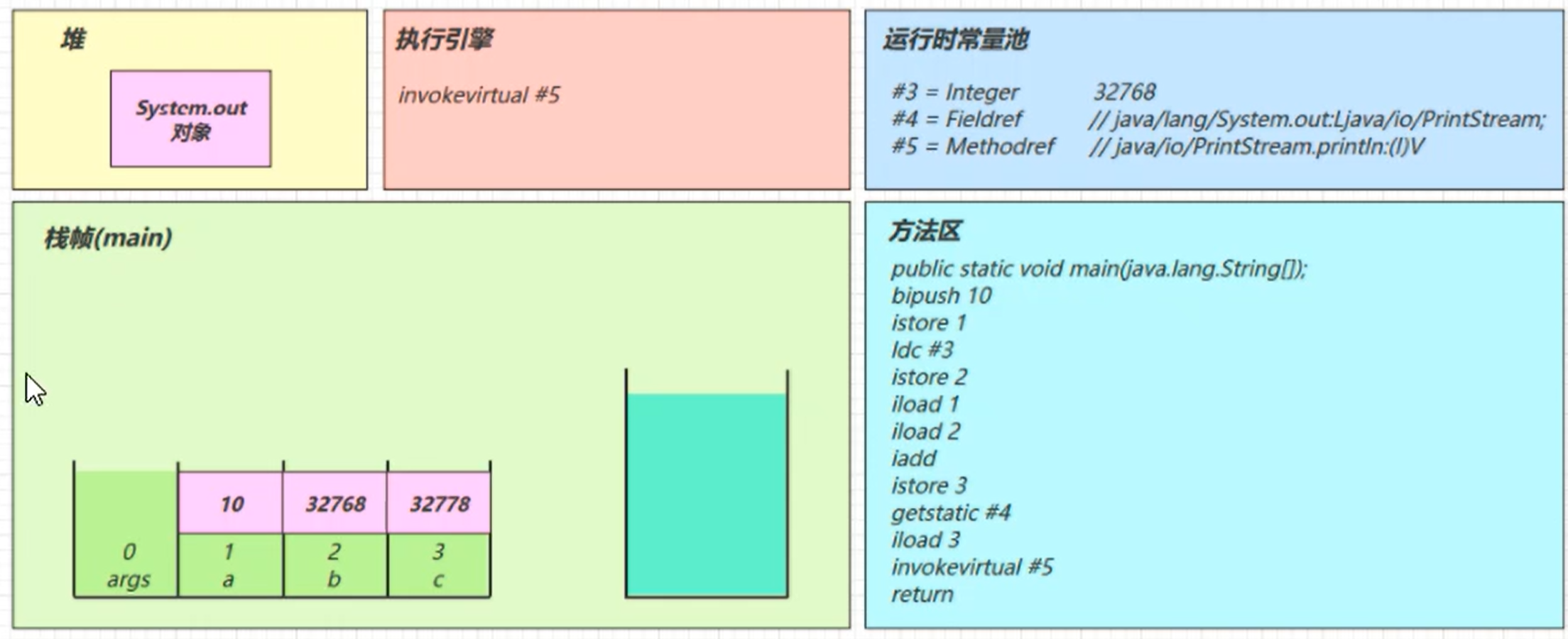
retrun
完成整个执行,退出
案例:
结果判断 x = x+1
java
main(){
int i = 0 ;
int x = 0 ;
while(i < 10 ){
x = x++;
i++;
}
sout(x) // 结果是0
}分析:
10: iload_2
11: iinc 2, 1
14: istore_2
先执行了 iload_2 将 x = 0 放入栈中 , 在执行了 iinc 自增操作, 最后 istore_2 将栈中的 x = 0 的值赋值给 x,最终 x = 0
构造方法:
< cinit >
java
public class Demo1{
static i = 10 ;
static {
i = 20;
}
static {
i = 30;
}
}编译器会从上之下顺序,收集所有的static静态代码块和静态成员变量赋值的代码,合并为一个特殊的方法,所以 i = 30
< cinit >()v:
shell
0: bipush 10
2: putstatic #2 // FileId i = I
5: bipush 20
7: putstatic #2 // FileId i = I
10: bipush 30
12: putstatic #2 // FileId i = I
15: return< init >
java
public class Demo1ApplicationTests2 {
private String a = "s1";
{
b = 20;
}
private int b = 10;
{
a = "s2";
}
public Demo1ApplicationTests2(String a, int b) {
this.a = a;
this.b = b;
}
public static void main(String[] args) {
Demo1ApplicationTests2 d = new Demo1ApplicationTests2("s3", 30);
System.out.println(d.a); // 结果是s3;
System.out.println(d.b); // 结果是30;
}
}分析:编译器会按从上至下的顺序,收集所有 { } 代码块和成员变量赋值的代码形成新的构造方法,但原始构造方法内的代码总是在最后
执行main方法,创建对象,先给a = s1 、b = 20、b = 10、a = s2 最后调用构造方法 a = s3 、b = 30
shell
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: ldc #2 // String s1
7: putfield #3 // Field a:Ljava/lang/String;
10: aload_0
11: bipush 20
13: putfield #4 // Field b:I
16: aload_0
17: bipush 10
19: putfield #4 // Field b:I
22: aload_0
23: ldc #5 // String s2
25: putfield #3 // Field a:Ljava/lang/String;
28: aload_0
29: aload_1
30: putfield #3 // Field a:Ljava/lang/String;
33: aload_0
34: iload_2
35: putfield #4 // Field b:I
38: return方法调用:
java
public class Demo3_9 {
public Demo3_9() { }
private void test1() { }
private final void test2() { }
public void test3() { }
public static void test4() { }
public static void main(String[] args) {
Demo3_9 d = new Demo3_9();
d.test1();
d.test2();
d.test3();
d.test4();
Demo3_9.test4();
}
}分析:构造方法、私有方法、私有final、都是invokespecial ,普通的调用test3() 是invokevirtual , 两次静态调用时 invokestatic。
因为public 发方法 可能被重写,在编译期间无法判断调用的是自身的方法还是 父类/子类 的重写方法 invokevirtual 成为动态绑定,需要程序运行的时候才能确定,其他两个都是静态绑定,效率肯定快。
shell
0: new #2 // class com/example/demo/Demo3_9
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokespecial #4 // Method test1:()V
12: aload_1
13: invokespecial #5 // Method test2:()V
16: aload_1
17: invokevirtual #6 // Method test3:()V
20: aload_1
21: pop
22: invokestatic #7 // Method test4:()V
25: invokestatic #7 // Method test4:()V
28: return多态原理:
java
public class Demo3_9 {
public static void test(Animal animal) {
animal.eat();
System.out.println(animal);
}
public static void main(String[] args) throws IOException {
test(new Dog());
test(new Cat());
System.in.read();
}
}
abstract class Animal {
public abstract void eat();
@Override
public String toString() {
return "我是"+ this.getClass().getSimpleName();
}
}
class Dog extends Animal {
@Override
public void eat() {
System.out.println("吃骨头");
}
}
class Cat extends Animal {
@Override
public void eat() {
System.out.println("吃鱼");
}
}当执行invokevirtual指令时,
1.先通过栈帧中的对象引用找到对象
2.分析对象头,找到对象的实际Class
3.Class结构中有vtable,它在类加载的链接阶段就已经根据方法的重写规则生成好了
4.查表得到方法的具体地址。
5.执行方法的字节码
异常处理:
java
public class Demo3_9 {
public static void main(String[] args) throws IOException {
int i = 0;
try{
i = 10;
}catch (Exception e){
i = 20;
}
}
}分析:可以看到多出来一个Exceptiontable的结构,**[from,to)**是前闭后开的检测范围,一旦这个范围内的字节码执行出现异常,则通过type匹配异常类型,如果一致,进入target所指示行号。
8行的字节码指令astore_2是将异常对象引用存入局部变量表的slot2位置
shell
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: iconst_0
1: istore_1
2: bipush 10
4: istore_1
5: goto 12
8: astore_2
9: bipush 20
11: istore_1
12: return
Exception table:
from to target type
2 5 8 Class java/lang/Exception
LocalVariableTable:
Start Length Slot Name Signature
9 3 2 e Ljava/lang/Exception;
0 13 0 args [Ljava/lang/String;
2 11 1 i I
# 可以看到Exception table 监听了 2 到 5 行的代码,如果有异常进入到第8行执行逻辑,astore_2 将 e 存入到局部变量表 LocalVariableTable 然后处理bipush 赋值为20 最后 istore_1 存储到i中多个cath情况
java
public static void main(String[] args) throws Exception {
int i = 0;
try{
i = 10;
}catch (NumberFormatException e){
i = 20;
}catch (NullPointerException e){
i = 30;
}catch (Exception e){
i = 40;
}
}分析:Exception table 会增加,但是根据异常类型跳转不同的执行行数,在局部变量表中,因为多catch情况也只会进入一种catch的Ex,所以存储的位置都为Slot=2 ,共用一个槽位
shell
Code:
stack=1, locals=3, args_size=1
0: iconst_0
1: istore_1
2: bipush 10
4: istore_1
5: goto 26
8: astore_2
9: bipush 20
11: istore_1
12: goto 26
15: astore_2
16: bipush 30
18: istore_1
19: goto 26
22: astore_2
23: bipush 40
25: istore_1
26: return
Exception table:
from to target type
2 5 8 Class java/lang/NumberFormatException
2 5 15 Class java/lang/NullPointerException
2 5 22 Class java/lang/Exception
LocalVariableTable:
Start Length Slot Name Signature
9 3 2 e Ljava/lang/NumberFormatException;
16 3 2 e Ljava/lang/NullPointerException;
23 3 2 e Ljava/lang/Exception;
0 27 0 args [Ljava/lang/String;
2 25 1 i Itry catch finally 情况
java
public static void main(String[] args) throws Exception {
int i = 0;
try{
i = 10;
}catch (NumberFormatException e){
i = 20;
}finally {
i = 30;
}
}分析:finally其实在成功 、异常、结尾都会做一遍bipush操作,确保一定会执行finally方法。
shell
Code:
stack=1, locals=4, args_size=1
0: iconst_0
1: istore_1
2: bipush 10 # try
4: istore_1
5: bipush 30 # finally
7: istore_1
8: goto 27 # retrun
11: astore_2
12: bipush 20 # catch
14: istore_1
15: bipush 30 # finally
17: istore_1
18: goto 27 # 跳转到return
21: astore_3
22: bipush 30
24: istore_1
25: aload_3
26: athrow
27: return
Exception table:
from to target type
2 5 11 Class java/lang/NumberFormatException # 如果有异常跳转到11 行往下走
2 5 21 any # 监听try 方法有没有异常,并且不是 NumberFormatException 异常catch监听不到
11 15 21 any # 监听catch 方法有没有异常synchronized
java
public static void main(String[] args) throws Exception {
Object lock = new Object();
synchronized (lock){
System.out.println("hello world");
}
}分析:monitorenter 对指令加锁 、 monitorexit 对指令解锁
shell
Code:
stack=2, locals=4, args_size=1
0: new #2 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."<init>":()V
7: astore_1
8: aload_1
9: dup
10: astore_2
11: monitorenter // lock锁引用 加锁
12: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
15: ldc #4 // String hello world
17: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
20: aload_2
21: monitorexit // lock锁引用 解锁
22: goto 30
25: astore_3
26: aload_2
27: monitorexit
28: aload_3
29: athrow
30: return
Exception table:
from to target type
12 22 25 any
25 28 25 any
LocalVariableTable:
Start Length Slot Name Signature
0 31 0 args [Ljava/lang/String;
8 23 1 lock Ljava/lang/Object;编译期处理
默认构造器
默认的无参构造器
自动拆装箱
在jdk5后会自动处理拆装箱操作
泛型集合取值
在jdk5以后特性,在编译后不管你的List< Integer >是什么存储类型,编译后都作为Object处理 , 最后通过checkcast指令转换实际类型,LocalVariableTypeTable 局部变量类型表 存储了泛型的信息
可变参数
方法中的(String... args)其实就是一个String\[\]
foreach循环
forech 编译后本质就是 fori , 如果是List 就会用Iterator 迭代器处理
switch字符串
switch(String) 编译后 , 先将case的结果转为 String对应的hashCode ,再通过hashCode匹配,switch(String.hashCode) 最后通过匹配到的case 给 临时变量 x 赋值 = 1 ,在通过 x 去另一个 switch (x) 中找到对应的流程
switch(String.hashCode){ int x = -1; case 1111: x = 1 break ; case 2222: x = 2 break; switch(x) {case 1 retrun a ; case 2 return b ;} }
switch枚举
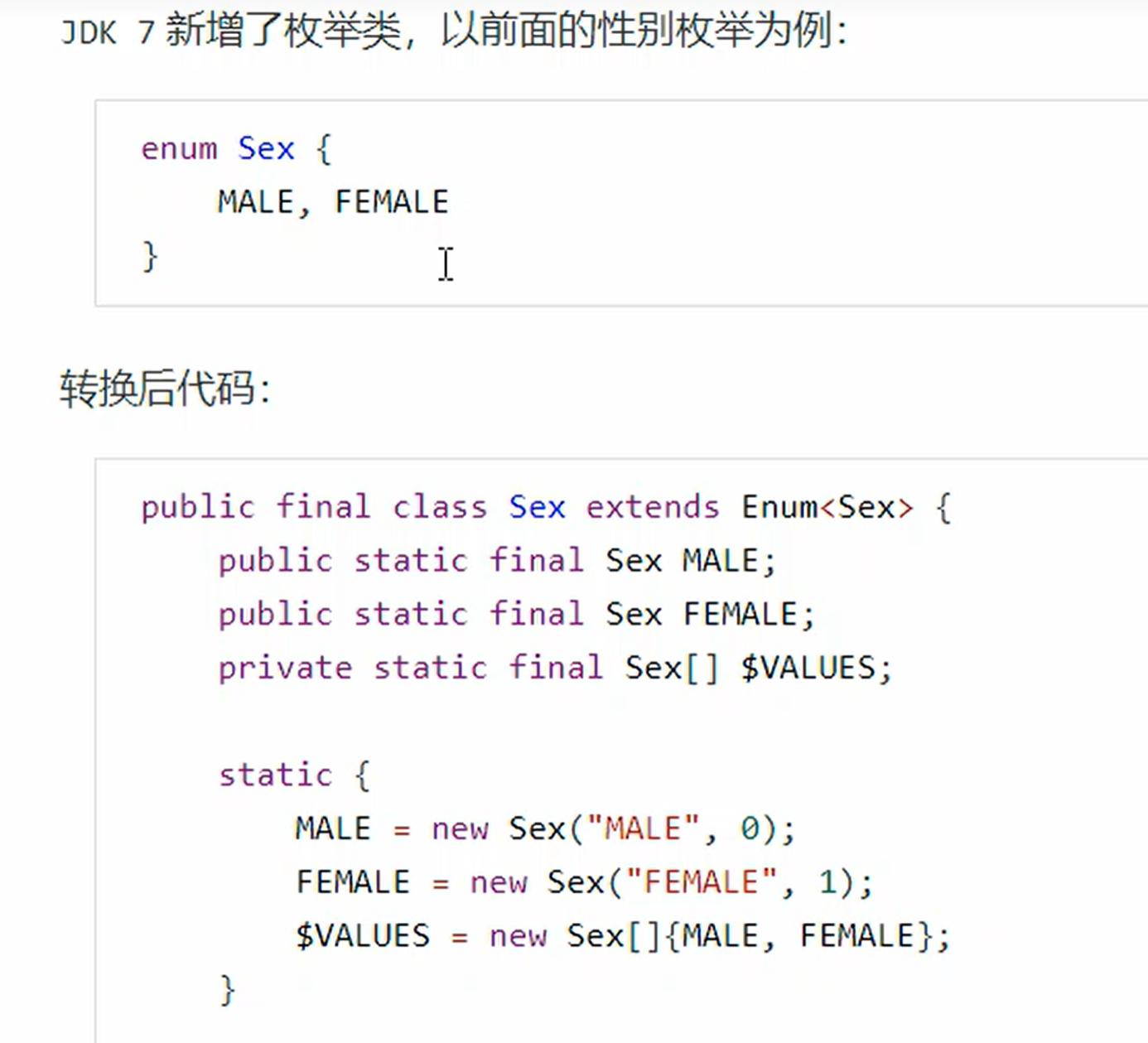
switch( enum )

枚举类
try-with-resources
java
try(InputStream is = new FileInputStream("d:\\1.txt")){
xxxx....
}catch(Exception x){
}
// 这个会自动关闭流,前提是实现了AutoCloseable 接口
// addSuppressed(Throwable e) 添加被压制异常,防止异常丢失方法重写时桥接方法
方法返回值可以分两种情况
- 父子类的返回值完全一致
- 子类返回值可以是父类返回值的子类
java
class A{
public Number m(){}
}
class B extends A{
@Override
public Integer m(){} // 子类 m 方法的返回值是Integer 是父类m方法返回值Number的子类
}对于子类java编译器会
java
class B extends A{
public Integer m(){
}
public synthetic bridge Number m(){
return m();
}
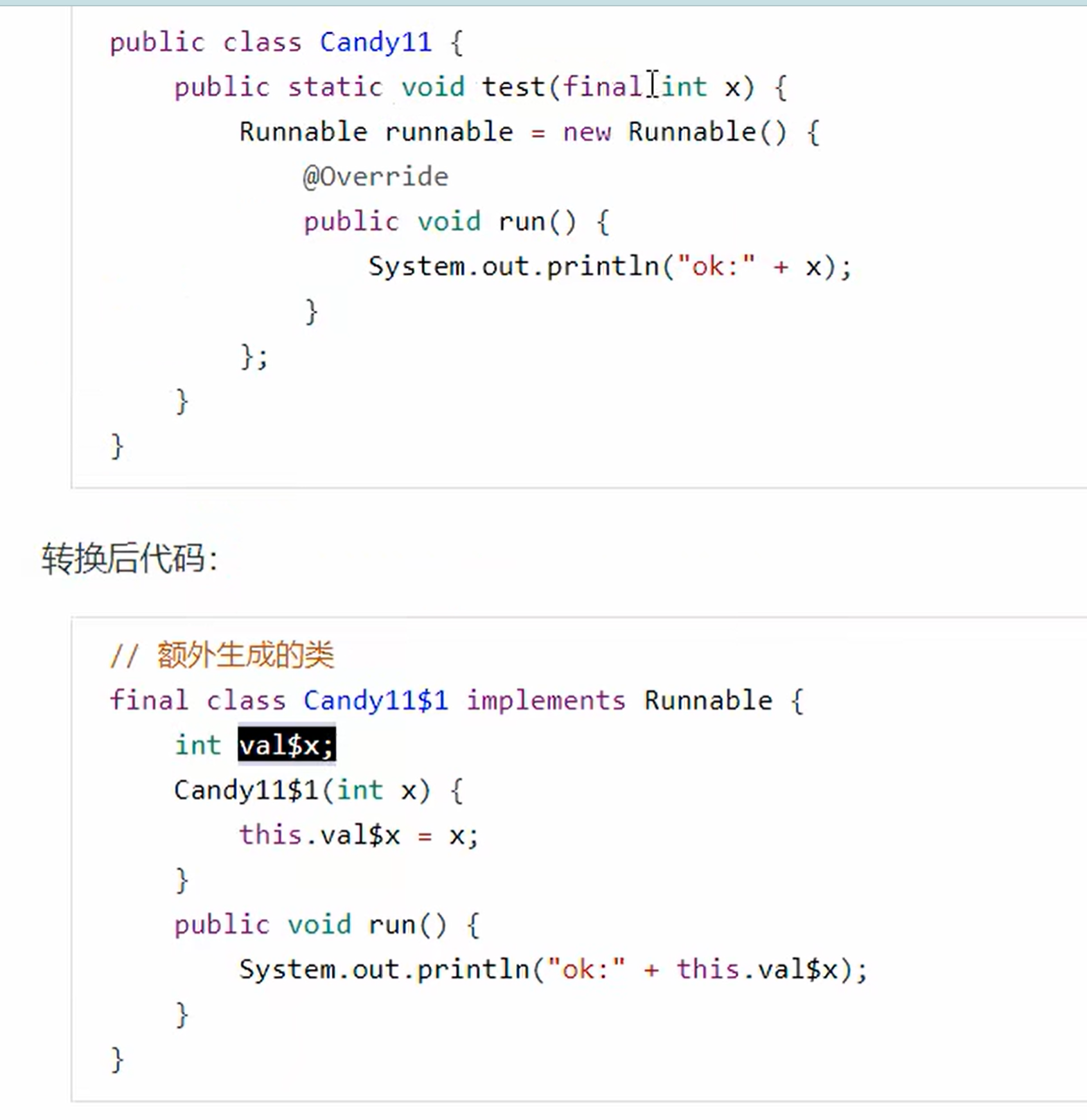
}匿名内部类
内部类的变量必须是final的是因为转义后在内部类自己创建了一个变量存储,不会跟着外部一起变,保持一致
类加载阶段
加载 -> 链接 -> 验证 -> 准备 -> 解析->初始化
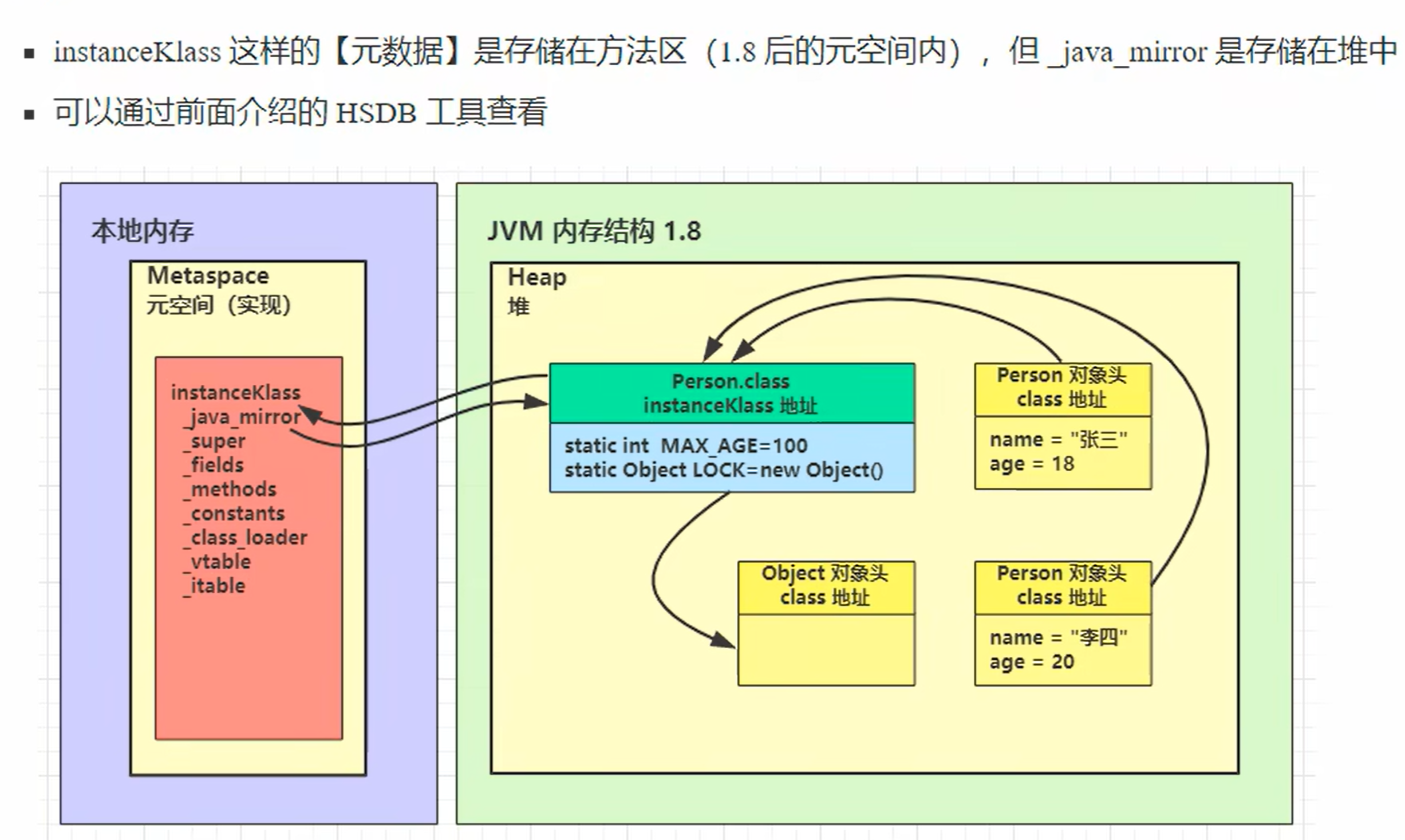
加载:
-
将类的字节码载入方法区中,内部采用C++的instanceKlass描述java类,它的重要field有:
-
-java_mirror 即java 的类镜像,例如对 String来说,就是 String.class,作用是把 klass 暴露给java使用
-
_super即父类
-
_fields 即成员变量
-
_methods即方法
-
_constants即常量池
-
_class_loader即类加载器
-
_vtable虚方法表
-
-itable接口方法表
-
-
如果这个类还有父类没有加载,先加载父类
-
加载和链接可能是交替运行的
链接:
java
class a{
static a;
static b = 10 ; // 先分配对象空间, 在后续初始化 构造方法中赋值
static final int c = 20 ; // final 修饰的在准备阶段就赋值了 , 不可修改
static final String d = "d"; // 也是在准备阶段就赋值了,基本类型 或 字符串常量 在编译阶段就确定le
static final Object e = new Object(); // 必须等到类初始化好了才能赋值 ,无法在准备阶段就赋值
}初始化:
概括得说,类初始化是【懒惰的】
- main方法所在的类,总会被首先初始化
- 首次访问这个类的静态变量或静态方法时
- 子类初始化,如果父类还没初始化,会引发
- 子类访问父类的静态变量,只会触发父类的初始化
- Class.forName
- new会导致初始化
不会导致类初始化的情况
- 访问类的static final静态常量(基本类型和字符串)不会触发初始化
- 类对象.class不会触发初始化
- 创建该类的数组不会触发初始化
- 类加载器的loadClass方法
- Class.forName 的参数2为false 时
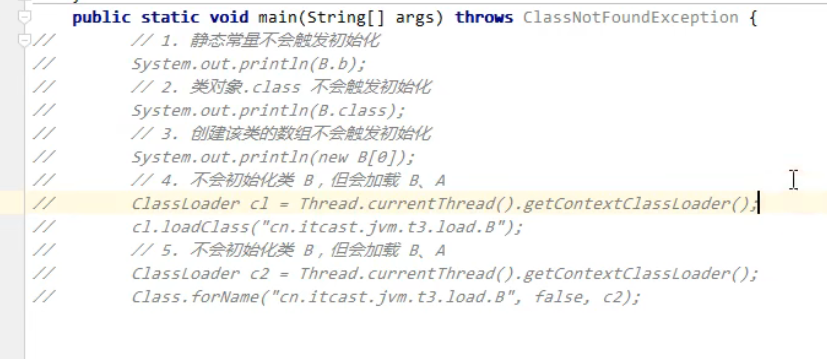
会初始化:
main的方法执行 会访问 当前类的静态代码块

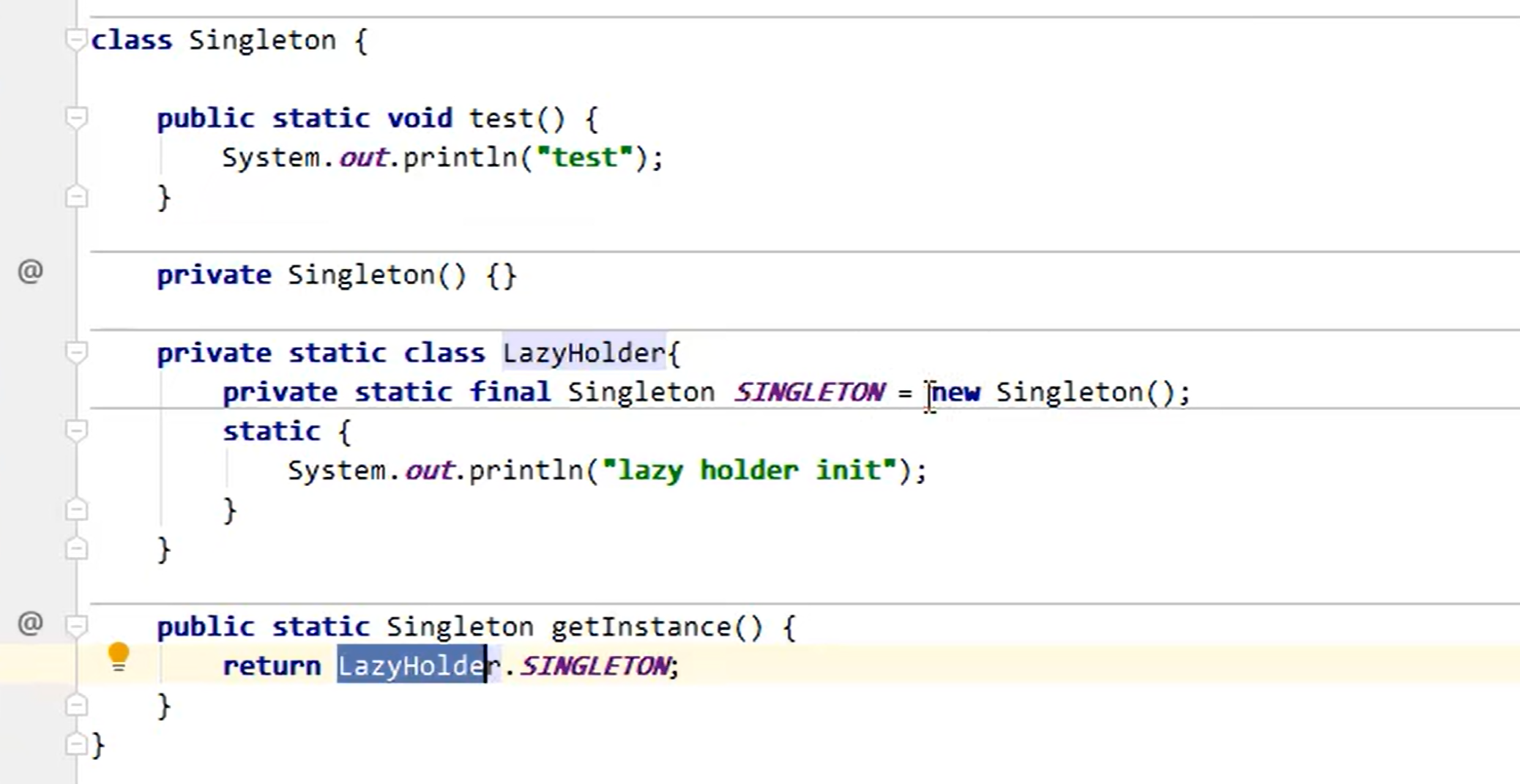
练习:
懒惰式初始化: 只有当调用了getInstance 才会触发类加载,
类加载器:
查看类加载器
class.getClassLoader()
双亲委派机制
定义:
就是指调用类的加载器loadClass方法时,查找类的规则(这里的双亲翻译为上级更合适,因为他们没有继承关系)
当一个类加载器收到类加载请求时,自己先不尝试加载 ,而是把请求向上委托给父类加载器,一直递归到顶层启动类加载器。
只有当父加载器无法加载时,子加载器才会自己去加载。
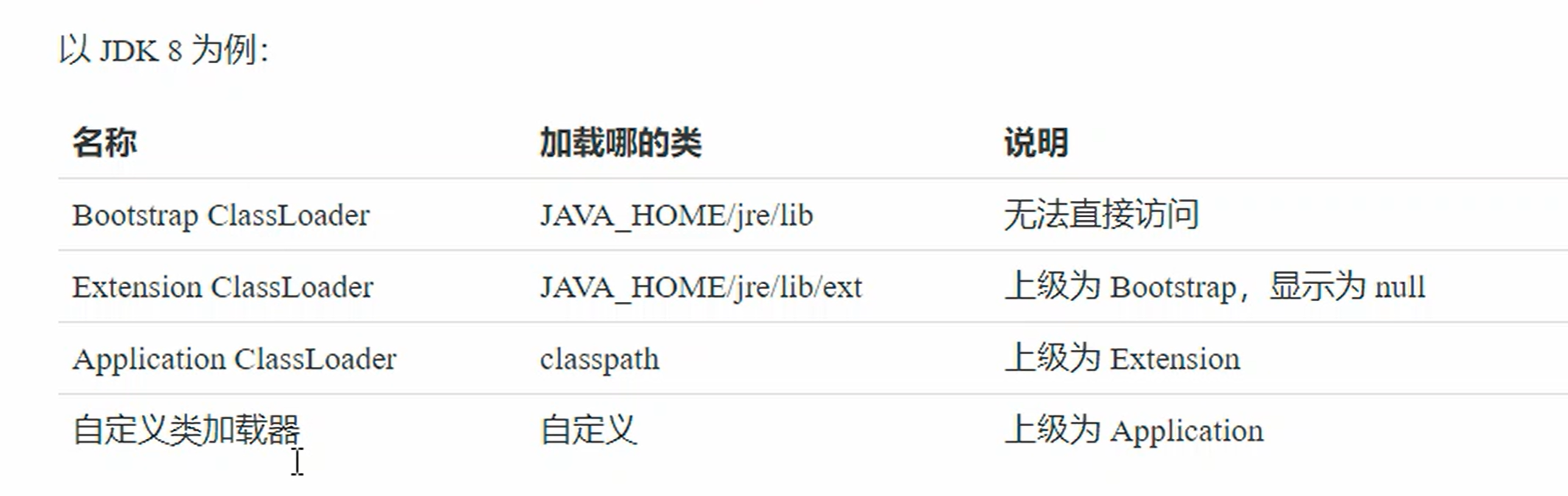
类加载器层级(从上到下)
-
BootstrapClassLoader(启动类加载器)
C++ 实现,加载
JAVA_HOME/jre/lib下的核心类(rt.jar 等)。 -
ExtensionClassLoader(扩展类加载器)
加载
jre/lib/ext下的扩展包。 -
ApplicationClassLoader(应用类加载器)
加载我们项目 classpath 下的类。
-
自定义类加载器
继承 ClassLoader 实现。
执行流程(一句话说清)
- 自定义类加载器 → 交给应用类加载器
- 应用类加载器 → 交给扩展类加载器
- 扩展类加载器 → 交给启动类加载器
- 启动类加载器能加载就加载,不能就返回给下一层
- 一层层往下尝试,都加载不到则抛
ClassNotFoundException
java
// 查看源码 ClassLoader.getSystemClassLoader().loadClass();
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name); // 获取当前类加载器
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) { // 委托上级加载器
c = parent.loadClass(name, false);
} else { // 找到启动类加载器 , 查看启动类加载器是否已经加载过了
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}线程上下文类加载器
线程上下文类加载器(Thread Context ClassLoader, TCCL) 是 JDK 1.2 引入的、绑定在 Thread 对象上的类加载器,核心作用是 打破双亲委派的单向性,让父加载器能调用子加载器的类 ,专门解决 SPI(服务发现) 与 多层类加载器架构(Tomcat、OSGi、插件化)的问题。
在使用 JDBC 时候 : Class.forName("com.mysql.jdbc.Driver") 也可以正确加载
一、基本概念与 API
1. 定义
每个线程都有一个 可独立设置 / 获取 的类加载器,与 "当前类的加载器" 无关。
2. 核心方法
// 获取当前线程的上下文类加载器
ClassLoader cl = Thread.currentThread().getContextClassLoader();
// 设置(框架/容器常用)
Thread.currentThread().setContextClassLoader(myClassLoader);3. 默认规则
- 未手动设置时:继承父线程的 TCCL
- 主线程(main)默认 TCCL = 应用类加载器(AppClassLoader)
- 本质:把类加载权交给 "线程上下文",而不是固定的类加载器链
二、为什么需要 TCCL?(双亲委派的缺陷)
双亲委派的天然限制
子加载器能看见父加载器的类,但父加载器看不见子加载器的类。
典型矛盾:JDBC(SPI 经典场景)
- JDK 接口 :
java.sql.Driver、DriverManager→ 由 Bootstrap 类加载器加载 - 厂商实现 :
com.mysql.cj.jdbc.Driver→ 在应用 classpath,由 AppClassLoader加载
按双亲委派:
DriverManager(Bootstrap)想加载 com.mysql.Driver → 找不到(父看不见子)。
TCCL 如何解决?
-
DriverManager内部不使用自己的类加载器(Bootstrap) -
改用:
javaClass.forName("com.mysql.cj.jdbc.Driver", true, Thread.currentThread().getContextClassLoader()); -
TCCL 默认是 AppClassLoader → 成功加载驱动。
一句话:TCCL 让顶层类库能 "反向" 使用应用层的类加载器。
三、工作原理(面试重点)
1. 类加载的两个 "加载器"
- 当前类加载器 :加载
.class文件的那个加载器(双亲委派) - 线程上下文加载器 :线程自带、可动态替换的加载器(打破委派)
2. 执行流程(SPI 为例)
- 应用代码:
DriverManager.getConnection(...) DriverManager(Bootstrap 加载)- 内部:获取 TCCL(AppClassLoader)
- 用 TCCL 加载并实例化 MySQL Driver
- 完成接口与实现的绑定
3. 本质
双亲委派是 "向上委托",TCCL 提供了 "向下 / 跨加载器" 的后门。
四、典型应用场景
1. SPI 服务发现(JDBC、JNDI、JCE、JAXB)
- 接口在 JDK(Bootstrap)
- 实现在应用 / 第三方包(App / 自定义)
- 必须用 TCCL 加载实现
2. Web 容器(Tomcat/Jetty)
- 容器类:Common 类加载器
- 每个 WebApp:独立 WebAppClassLoader(隔离)
- 执行应用代码时:把 TCCL 设为当前 WebAppClassLoader
- 容器代码就能正确加载应用内的类(Servlet、Spring Bean)
3. 插件化 / OSGi / 热部署
- 每个插件一个独立类加载器
- 执行插件代码前:TCCL.set (插件类加载器)
- 框架代码可加载插件内的类与资源
4. 框架内部(Spring、Dubbo、MyBatis)
- 大量 SPI、动态代理、配置加载
- 统一用 TCCL 作为默认加载器,保证跨容器兼容
五、面试高频问答
Q1:TCCL 是不是破坏双亲委派?
是,但可控。
- 不是废掉双亲委派,而是 增加一条加载路径
- 依然保护
java.*核心类(Bootstrap 优先) - 只是 允许父加载器借用子加载器
Q2:什么时候用 TCCL?
- 你在 JDK 核心类 / 框架层 ,要加载 应用层 / 插件层 的类
- 类加载器层级是 自上而下可见,但自下而上不可见
Q3:TCCL 有什么坑?
-
线程池污染
线程复用,TCCL 没重置 → 类加载错乱、ClassCastException
-
多层框架互相覆盖
Spring、Dubbo、ShardingSphere 都改 TCCL → 谁最后设谁生效
-
Java 9+ 模块系统
模块化下 TCCL 行为变化,SPI 优先走模块层
六、一句话总结
线程上下文类加载器是 Thread 上的可动态设置的类加载器,用来打破双亲委派的单向可见性,让父加载器能调用子加载器的类,是 JDBC/SPI、Tomcat、插件化、框架热部署的核心技术。
自定义类加载器:
Java 自带 3 个类加载器:
- Bootstrap
- Extension
- AppClassLoader
但它们只能加载 指定目录 里的 class。
如果你想从别的地方加载类,比如:
- 从网络加载
- 从加密的 jar 加载
- 从数据库加载
- 热更新、热部署
- 同一个类要加载多份,互相隔离
自带的加载器做不到,就需要自己写一个类加载器。
继承 ClassLoader,重写 findClass() 方法即可
java
class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) {
// 自己去读取字节码:网络、DB、加密文件...
byte[] bytes = ...;
return defineClass(name, bytes, 0, bytes.length);
}
}比如项目中:
-
两个模块依赖同一个 jar 的不同版本
-
如果用默认加载器,会冲突(类冲突、NoSuchMethod)
-
每个插件用
自己的类加载器
→ 互相看不见,互不干扰。
典型:Tomcat、SPI、插件平台、SAAS 系统。
你可以直接这样说,非常真实、非常像大厂经验:
我们项目里有一个规则引擎 / 动态配置中心,业务规则经常变化,不能频繁重启服务。
所以我们使用了自定义类加载器:
规则以字节码或 class 文件形式存储在数据库中;
规则更新时,后台重新上传新逻辑;
服务端新建一个自定义类加载器,重新加载新的规则类;
旧的类加载器被释放,新逻辑直接生效,实现
热更新。
同时,为了避免新旧类冲突,每次更新都使用
新的类加载器,做到类隔离,不会出现 jar 冲突或旧代码干扰。
如果做过 Web 项目,也可以说:
类似 Tomcat 的 WebAppClassLoader,每个应用一个类加载器,实现应用隔离,避免不同 war 包之间的类冲突。
运行期优化:
JVM将执行状态分成了5个层次:
- 0层,解释执行(Interpreter)
- 1层,使用C1即时编译器编译执行(不带profiling)
- 2层,使用C1即时编译器编译执行(带基本的profiling)
- 3层,使用C1即时编译器编译执行(带完全的profiling)
- 4层,使用C2即时编译器编译执行
Interpreter < C1 < C2
逃逸分析:
运行时会自动过滤无意义的代码
方法内联:
将方法内的代码直接拷贝在调用的地方
字段优化:
fori 中使用成员变量时先转为 局部变量 int\[\] nums= this.arrays
反射优化:
java内存模型:
定义:JVM 定义了一套在多线程读写共享数据时(成员变量,数组)时,对数据可见性、有序性、和原子性的规则保障
原子性: synchronized
两个线程对int i 操作; 一个操作+ 1 一个 操作 -1 ,各自都循环1000 次但是结果不一定为0 ,所以需要加锁保障其原子性
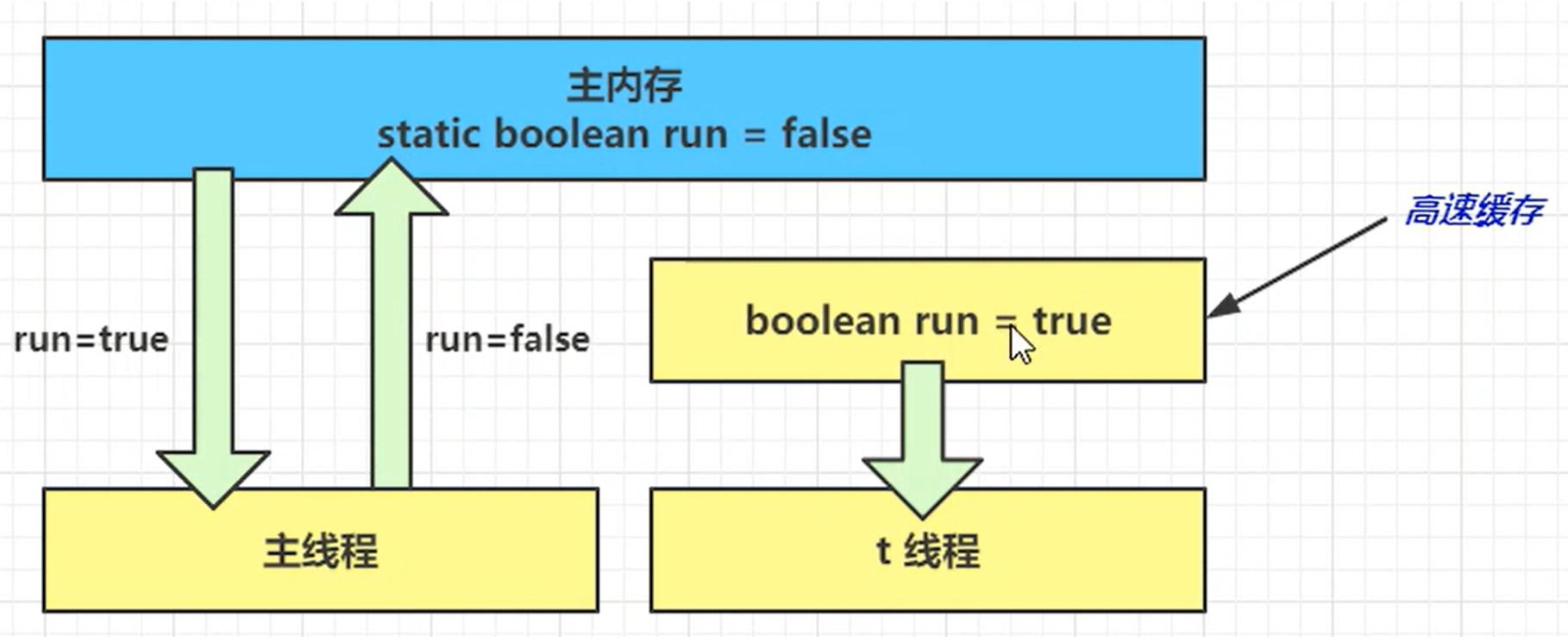
可见性: volatile (可见性+防止指令重排序)
避免线程从高速缓存中读取数据,而是每次都需要冲主内存获取,一个线程对volatile修改对另一个线程是可见的,但是不能保障原子性
有序性:
有序性,指程序代码的执行顺序按照我们编写的代码顺序来执行,不被 CPU 或编译器重排序。
核心点
- 为了优化性能 ,编译器、CPU 会在不影响单线程结果的前提下,对指令进行重排序。
- 但在多线程环境下,重排序会导致结果不符合预期,出现线程安全问题。
- Java 内存模型(JMM)通过 volatile、synchronized、final 等机制来限制重排序,保证多线程下的有序性。
典型场景:单例双重校验锁(DCL)
java
public class Singleton {
private static Singleton instance; // 没加 volatile
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}CAS:
CAS 是基于 CPU 提供的原子指令(CMPXCHG)
实现的无锁原子操作,Java 层通过 Unsafe 类提供 native 方法调用,全程不加锁、不阻塞线程。
AtomicInteger 这些原子类,底层全是靠 Unsafe.compareAndSwapInt() 实现的。
java
public class AtomicInteger extends Number implements java.io.Serializable {
// value 用 volatile 保证可见性
private volatile int value;
// Unsafe 实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
// value 字段在内存中的偏移地址
private static final long valueOffset;
static {
// 获取 value 字段的内存地址偏移量
valueOffset = unsafe.objectFieldOffset(
AtomicInteger.class.getDeclaredField("value")
);
}
// 核心方法:自增
public final int incrementAndGet() {
// 自旋 + CAS
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
}关键点
- value 用 volatile 修饰 → 保证多线程可见性
- 保存字段内存偏移量 valueOffset
- 自旋(循环)+ CAS 实现无锁更新
CAS 底层是 CPU 的 CMPXCHG 原子指令。
Java 通过 Unsafe 类提供 native 方法直接调用,Atomic 原子类基于 Unsafe + 自旋实现无锁安全更新。
全程不加锁,只靠硬件指令保证原子性,高并发下性能远超锁。
Java 中基于 CAS 实现的工具类(JUC 原子包)
主要在 java.util.concurrent.atomic 包下,常用分为四类:
1. 基础原子类型
AtomicIntegerAtomicLongAtomicBoolean
2. 引用类型
AtomicReferenceAtomicStampedReference(解决 ABA)AtomicMarkableReference
3. 数组类型
AtomicIntegerArrayAtomicLongArrayAtomicReferenceArray
4. 字段更新器
AtomicIntegerFieldUpdaterAtomicLongFieldUpdaterAtomicReferenceFieldUpdater
二、我在项目中实际使用场景(真实、可直接说)
1. AtomicInteger / AtomicLong ------ 高频使用
场景:接口限流、计数器、并发下单次数统计、分布式 ID 生成
- 实现接口 QPS 限流:统计单位时间内请求次数,达到阈值拒绝
- 订单 幂等防重:同一用户短时间多次提交,用原子计数控制只执行一次
- ID 生成器:简单本地自增 ID(非分布式场景)
为什么用 CAS:
高并发下无锁,比 synchronized 性能高很多,避免线程阻塞和上下文切换。
2. AtomicBoolean ------ 控制单次执行
场景:系统初始化、资源一次性加载、服务停机标记
- 项目启动时只执行一次初始化
- 多线程下确保某个任务只执行一次
- 服务关闭时标记
stop状态,拒绝新请求
3. AtomicReference ------ 原子更新对象
场景:配置热更新、动态规则、缓存原子替换
- 动态规则引擎:规则更新时,原子替换规则对象
- 配置中心:配置变更后,原子引用替换,保证多线程读到最新配置
4. AtomicStampedReference ------ 解决 ABA 问题
场景:扣减库存、资金变动、状态流转
- 库存扣减:避免 ABA 导致超卖 / 重复扣减
- 资金、积分操作:保证值变化过程可追溯,防止隐蔽问题
总结:
CAS 相关类主要在 java.util.concurrent.atomic 包下,常用有
AtomicInteger、AtomicLong、AtomicBoolean、AtomicReference、AtomicStampedReference。
项目中我主要用:
-
AtomicInteger/AtomicLong 做接口限流、计数器、ID 生成;
-
AtomicBoolean 控制一次性初始化任务;
-
AtomicReference 实现配置、规则的热更新与原子替换;
-
AtomicStampedReference
在库存、资金等场景解决 ABA 问题。
它们基于 CAS 无锁实现,高并发下性能优于锁,且避免死锁风险。
ABA问题:
ABA 问题是指变量值从 A 改成 B 又改回 A,CAS 无法感知而误更新。
解决方案是引入版本号机制,每次修改变量同时递增版本,CAS 同时校验值和版本号。
Java 提供 AtomicStampedReference 实现该机制,也可以用 AtomicMarkableReference 做简化版标记。
synchronized:
synchronized 基于对象头 MarkWord 实现锁状态存储,通过 monitorenter/monitorexit 完成加解锁。
JDK1.6 后引入锁升级:无锁 → 偏向锁 → 轻量级锁 → 重量级锁。
偏向锁适用于单线程重复加锁;轻量级锁用 CAS 自旋,适合短时间竞争;竞争激烈升级为重量级锁,依赖系统互斥锁。整个过程只升级不降,大幅提升了高并发下的性能。
锁升级完整流程(必考)
无锁 → 偏向锁 → 轻量级锁 → 重量级锁
只会升级,不会降级。
1. 无锁状态
- 没有线程竞争
- MarkWord 标记为无锁
2. 偏向锁(默认开启)
- 场景:一个线程反复获取同一把锁,无竞争
- 原理:MarkWord 记录当前线程 ID
- 加锁:只需对比线程 ID,一致直接进入
- 目的:消除无竞争时的 CAS 操作,提升效率
3. 轻量级锁(自旋锁)
-
触发:出现第二个线程竞争,偏向锁撤销升级
-
原理:
- 线程在栈帧中创建 Lock Record
- 用 CAS 尝试替换 MarkWord 为锁记录指针
- 失败则自旋(循环重试)
-
场景:竞争不激烈,持有锁时间短
-
优点:避免线程阻塞切换,吞吐高
4. 重量级锁
- 触发:自旋一定次数仍失败,或竞争激烈
- 原理:向操作系统申请 Mutex Lock
- 线程阻塞、挂起、唤醒,涉及用户态 / 内核态切换
- 缺点:开销大、性能差
- 场景:高并发、锁持有时间长