C++入门(一):第一个 C++ 程序、命名空间、输入输出和缺省参数

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 | 《python基础》 ✨ 数据即知识,压缩即智能
目录
- [C++入门(一):第一个 C++ 程序、命名空间、输入输出和缺省参数](#C++入门(一):第一个 C++ 程序、命名空间、输入输出和缺省参数)
-
- 前言
- [一、第一个 C++ 程序](#一、第一个 C++ 程序)
- [二、`.c` 文件和 `.cpp` 文件有什么区别?](#二、
.c文件和.cpp文件有什么区别?) - [三、C++ 的输入输出库:iostream](#三、C++ 的输入输出库:iostream)
- [四、`<<` 和 `>>` 在 C++ 输入输出中的作用](#四、
<<和>>在 C++ 输入输出中的作用) - [五、C++ 输入输出相比 printf / scanf 的优势](#五、C++ 输入输出相比 printf / scanf 的优势)
- [六、`endl` 和 `\n` 有什么区别?](#六、
endl和\n有什么区别?) - [七、C++ 输入输出的效率](#七、C++ 输入输出的效率)
- 八、为什么需要命名空间?
- [九、namespace 的基本定义](#九、namespace 的基本定义)
- 十、命名空间可以嵌套
- [十一、同名 namespace 会合并](#十一、同名 namespace 会合并)
- [十二、std 命名空间是什么?](#十二、std 命名空间是什么?)
- 十三、命名空间的三种使用方式
-
- [1. 指定命名空间访问](#1. 指定命名空间访问)
- [2. using 展开某个成员](#2. using 展开某个成员)
- [3. using namespace 展开整个命名空间](#3. using namespace 展开整个命名空间)
- 十四、缺省参数是什么?
- 十五、全缺省参数和半缺省参数
-
- [1. 全缺省参数](#1. 全缺省参数)
- [2. 半缺省参数](#2. 半缺省参数)
- 十六、缺省参数必须从右往左给
- 十七、声明和定义分离时,默认值写在哪里?
- 十八、缺省参数适合什么场景?
- 总结
前言
如果你已经学过 C 语言,再来看 C++,第一感觉可能是:
这不就是 C 语言加了一些新语法吗?
C++ 确实兼容 C 语言的大多数语法,所以很多 C 语言程序放到 C++ 文件中依然可以运行。但是 C++ 不只是"更大的 C",毕竟它的名字叫 "c plus plus" ,它在 C 的基础上引入了命名空间、函数重载、引用、类和对象、模板、STL 等一系列机制。
这一篇先从 C++ 入门最基础的几个点开始讲起
一、第一个 C++ 程序
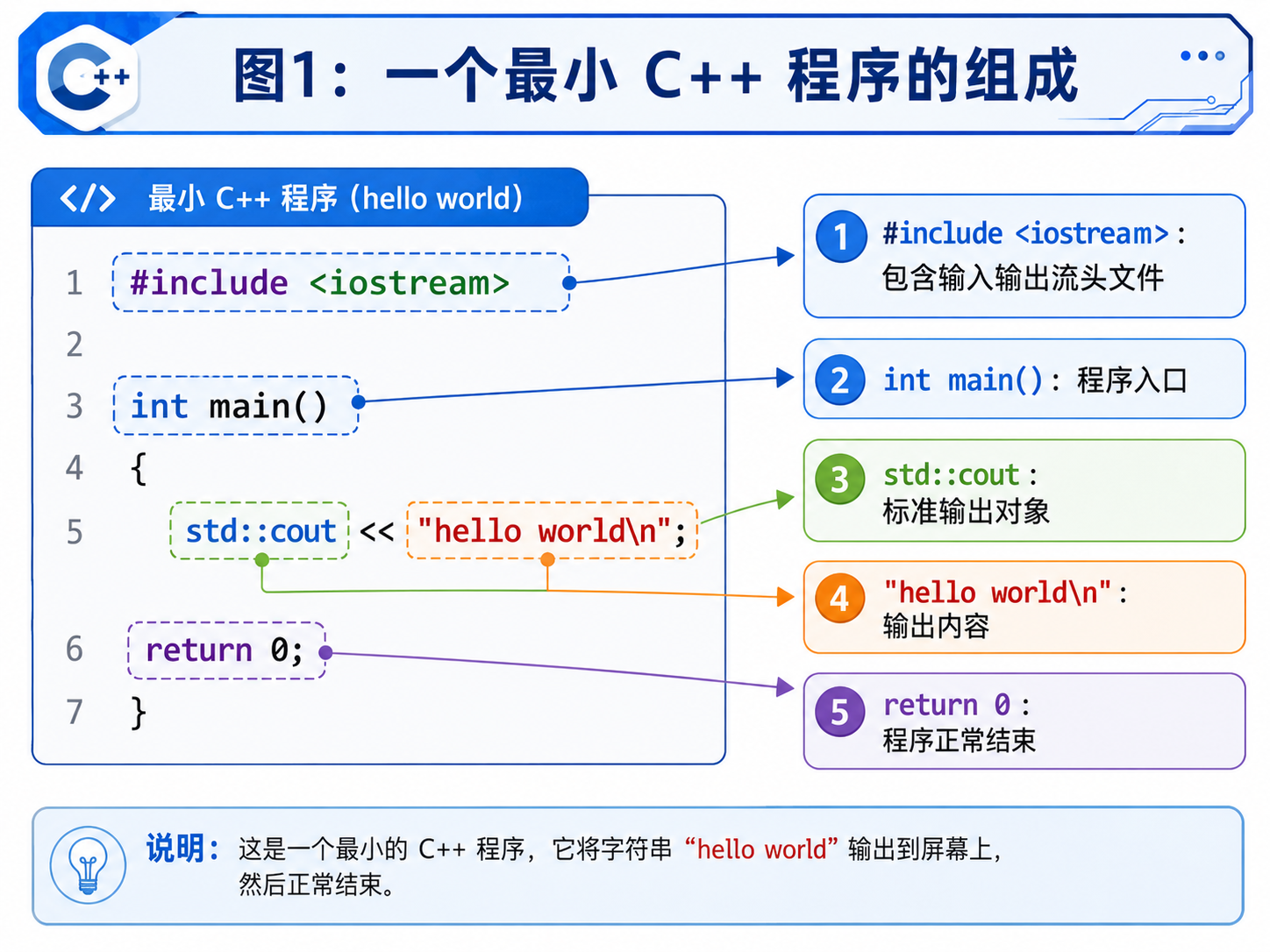
这就是我们c++版本的hellow world。
这里出现了几个新东西:
#include <iostream>std::cout<<endlusing namespace std
先别着急,接下来我们会详细展开。
二、.c 文件和 .cpp 文件有什么区别?
在 C 语言中,源文件通常以 .c 结尾。
在 C++ 中,源文件通常以 .cpp 结尾。
比如:
txt
test.c // 通常按 C 语言规则编译
test.cpp // 通常按 C++ 语言规则编译在 Linux 下,如果编译 C 程序,常用:
bash
gcc test.c -o test如果编译 C++ 程序,常用:
bash
g++ test.cpp -o test三、C++ 的输入输出库:iostream
C 语言中常用:
c
printf()
scanf()C++ 中更常用:
cpp
cout
cin要使用它们,需要包含头文件:
cpp
#include <iostream>iostream 可以理解为:
input output stream,也就是输入输出流。
其中:
| 对象 | 作用 |
|---|---|
std::cout |
标准输出对象,用来向控制台输出 |
std::cin |
标准输入对象,用来从控制台读取输入 |
std::endl |
输出换行,并刷新缓冲区 |
示例:
cpp
#include <iostream>
int main()
{
int a = 10;
double b = 3.14;
char c = 'x';
std::cout << a << " " << b << " " << c << std::endl;
return 0;
}输出:
txt
10 3.14 x四、<< 和 >> 在 C++ 输入输出中的作用
在 C 语言中,<< 和 >> 是位运算符:
c
a << 1
a >> 1但在 C++ 的输入输出中,它们被赋予了新的含义。
在输出中:
cpp
std::cout << a;这里的 << 叫流插入运算符。
可以理解为:
把右边的数据插入到左边的输出流中。
在输入中:
cpp
std::cin >> a;这里的 >> 叫流提取运算符。
可以理解为:
从输入流中提取数据,放入变量 a 中。
示例:
cpp
#include <iostream>
int main()
{
int age = 0;
double score = 0.0;
std::cout << "请输入年龄和成绩:";
std::cin >> age >> score;
std::cout << "年龄:" << age << "\n";
std::cout << "成绩:" << score << "\n";
return 0;
}如果输入:
txt
18 95.5输出:
txt
年龄:18
成绩:95.5五、C++ 输入输出相比 printf / scanf 的优势
C 语言中,使用 printf 和 scanf 时要手动写格式控制符。
例如:
c
int a = 10;
double b = 3.14;
printf("%d %lf\n", a, b);其中:
%d对应int%lf对应double
如果格式写错,可能会出现错误输出甚至未定义行为。
而 C++ 的 cout 和 cin 可以自动识别变量类型:
cpp
int a = 10;
double b = 3.14;
char c = 'x';
std::cout << a << " " << b << " " << c << "\n";不需要你手动写 %d、%lf、%c。
这对初学者非常友好。
不过,C++ IO 流底层涉及类、对象和运算符重载,这些内容后面再深入理解。现在先会用即可。
六、endl 和 \n 有什么区别?
很多时候我们会写:
cpp
cout << "hello" << endl;也可以写:
cpp
cout << "hello\n";它们都能换行,但不完全一样。
endl 做了两件事:
- 输出一个换行;
- 刷新输出缓冲区。
\n 只是换行。
所以在普通输出场景中,尤其是大量输出时,通常更推荐使用:
cpp
cout << '\n';而不是频繁使用:
cpp
cout << endl;因为频繁刷新缓冲区可能降低效率。
不过这里更具体的内容无法过多展开(没事之后会填坑的,可以期待一下)

七、C++ 输入输出的效率
在一些竞赛题或大量输入输出场景中,C++ 的 cin/cout 默认可能比 scanf/printf 慢。
可以在 main 函数开头加入:
cpp
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);完整示例:
cpp
#include <iostream>
using namespace std;
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n = 0;
cin >> n;
cout << n << '\n';
return 0;
}这几行代码的作用可以简单理解为:
- 关闭 C++ IO 和 C IO 的同步;
- 解除
cin和cout的绑定; - 减少不必要的刷新操作。
注意:
使用这几行加速后,不建议混用
cin/cout和scanf/printf。
否则可能出现输入输出顺序异常。
八、为什么需要命名空间?
C++ 项目中会有大量变量、函数、结构体、类。
如果所有名字都放在全局作用域中,很容易发生命名冲突。
比如 C 语言中有一个标准库函数叫 rand。
如果你又定义了一个全局变量:
cpp
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}这就可能和库函数 rand 发生冲突。
C++ 引入 namespace,就是为了解决这种名字冲突问题。
可以把命名空间理解成:
给一批名字套了一个"外壳"或"作用域"。
不同命名空间中可以有同名变量、同名函数,但不会冲突。
九、namespace 的基本定义
定义命名空间的语法:
cpp
namespace 命名空间名
{
// 变量
// 函数
// 类型
}示例:
cpp
#include <iostream>
namespace my_space
{
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
int val;
Node* next;
};
}
int main()
{
std::cout << my_space::rand << '\n';
std::cout << my_space::Add(1, 2) << '\n';
return 0;
}这里:
cpp
my_space::rand
my_space::Add(1, 2)中的 :: 叫作用域解析运算符。
它的意思是:
到 bit 这个命名空间中寻找 rand 或 Add。
十、命名空间可以嵌套
命名空间中还可以继续定义命名空间。
cpp
#include <iostream>
namespace my_space
{
namespace Luna
{
int rand = 1;
int Add(int left, int right)
{
return left + right;
}
}
namespace Lucia
{
int rand = 2;
int Add(int left, int right)
{
return (left + right) * 10;
}
}
}
int main()
{
std::cout << my_space::Luna::rand << '\n';
std::cout << my_space::Lucia::rand << '\n';
std::cout << my_space::Luna::Add(1, 2) << '\n';
std::cout << my_space::Lucia::Add(1, 2) << '\n';
return 0;
}输出:
txt
1
2
3
30这里 Luna 和 Lucia 中都定义了 rand 和 Add,但因为它们处于不同命名空间,所以不会冲突。
十一、同名 namespace 会合并
C++ 中,同一个命名空间可以在多个地方定义。
例如:
cpp
namespace my_space
{
int a = 10;
}
namespace my_space
{
int b = 20;
}这两个 bit 不会冲突,而是会合并成同一个命名空间。
可以理解为:
cpp
namespace my_space
{
int a = 10;
int b = 20;
}这个特性在多文件工程中很常见。
比如一个项目中,栈相关代码放在 Stack.h / Stack.cpp,队列相关代码放在 Queue.h / Queue.cpp,但它们都可以放在同一个项目命名空间中:
cpp
namespace my_space
{
// Stack 相关声明
}
namespace my_space
{
// Queue 相关声明
}十二、std 命名空间是什么?
C++ 标准库中的很多内容都放在 std 命名空间中。
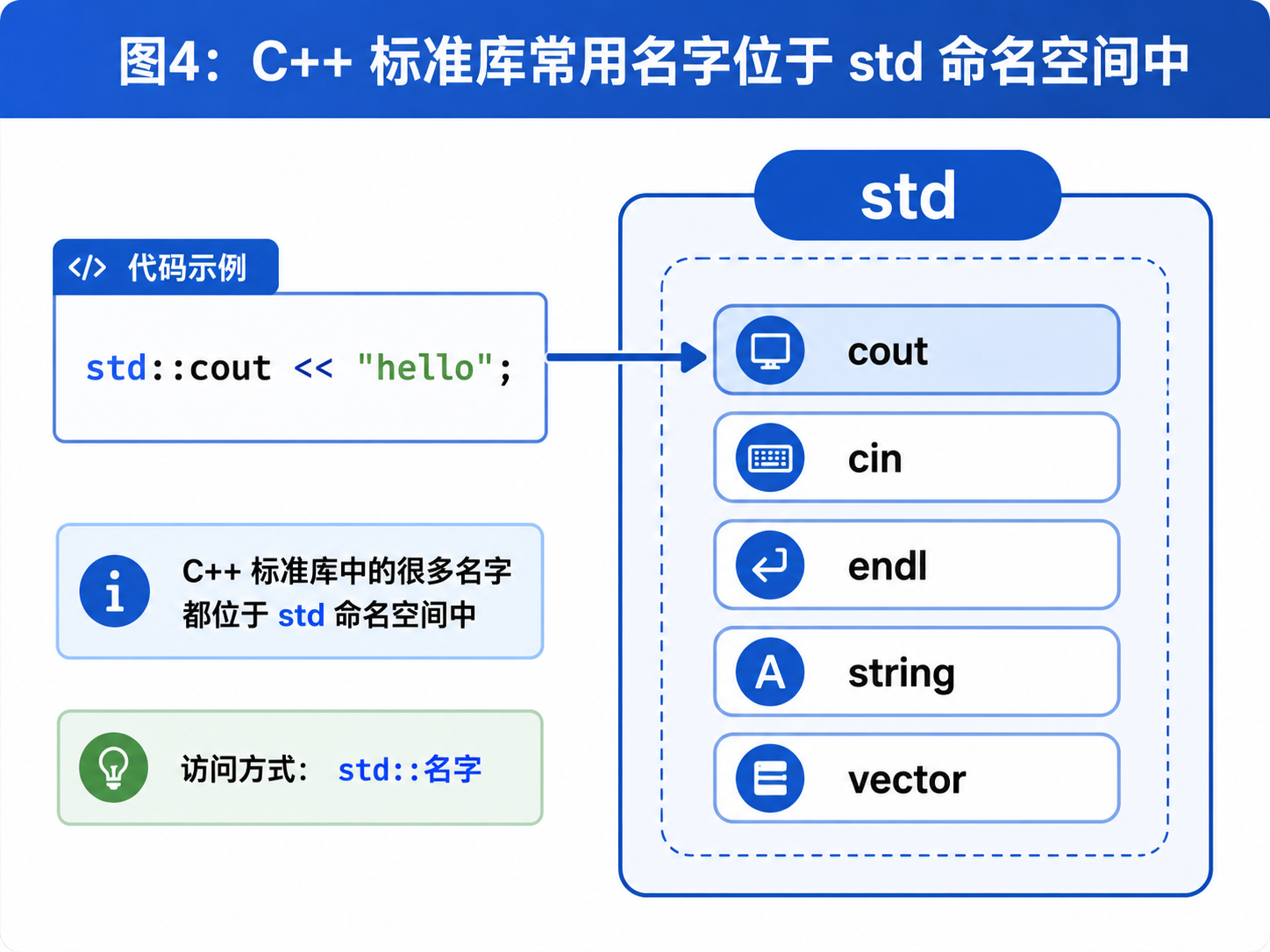
所以如果你写:
cpp
cout << "hello";编译器可能找不到 cout。
因为它真正的名字在 std 命名空间中:
cpp
std::cout这也是为什么最标准的写法是:
cpp
#include <iostream>
int main()
{
std::cout << "hello world\n";
return 0;
}十三、命名空间的三种使用方式
1. 指定命名空间访问
cpp
std::cout << "hello\n";或者:
cpp
my_space::Add(1, 2);这是最推荐的方式。
优点是非常清晰:
这个名字来自哪个命名空间,一眼就能看出来。
实际项目中尤其推荐这种写法。
2. using 展开某个成员
如果某个成员经常用,也可以单独展开:
cpp
#include <iostream>
using std::cout;
using std::cin;
int main()
{
int a = 0;
cin >> a;
cout << a << '\n';
return 0;
}这种方式比 using namespace std; 更安全。
因为它只展开你指定的名字。
3. using namespace 展开整个命名空间
cpp
#include <iostream>
using namespace std;
int main()
{
cout << "hello\n";
return 0;
}这种写法在初学阶段很常见,因为方便。
但是在大型项目中不推荐在头文件或全局范围中随便写:
cpp
using namespace std;原因是它会把 std 中大量名字引入当前作用域,增加命名冲突风险。
简单记:
| 场景 | 建议 |
|---|---|
| 日常小练习 | 可以使用 using namespace std; |
| 正式项目源文件 | 谨慎使用 |
| 头文件 | 不建议使用 |
| 推荐写法 | std::cout 或 using std::cout |
十四、缺省参数是什么?
缺省参数也叫默认参数。
它的意思是:
在函数声明或定义时,给参数指定默认值。调用函数时,如果没有传这个参数,就使用默认值。
示例:
cpp
#include <iostream>
using namespace std;
void Print(int n = 1)
{
cout << "n = " << n << '\n';
}
int main()
{
Print(); // 没有传参,使用默认值 1
Print(10); // 传参,使用 10
return 0;
}输出:
txt
n = 1
n = 10十五、全缺省参数和半缺省参数
1. 全缺省参数
所有参数都有默认值,叫全缺省。
cpp
#include <iostream>
using namespace std;
void Func(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << '\n';
cout << "b = " << b << '\n';
cout << "c = " << c << "\n\n";
}
int main()
{
Func();
Func(1);
Func(1, 2);
Func(1, 2, 3);
return 0;
}调用效果:
cpp
Func(); // a=10, b=20, c=30
Func(1); // a=1, b=20, c=30
Func(1, 2); // a=1, b=2, c=30
Func(1, 2, 3); // a=1, b=2, c=32. 半缺省参数
部分参数有默认值,叫半缺省。
cpp
void Func(int a, int b = 10, int c = 20)
{
cout << a << " " << b << " " << c << '\n';
}调用:
cpp
Func(100); // 100 10 20
Func(100, 200); // 100 200 20
Func(100, 200, 300); // 100 200 300十六、缺省参数必须从右往左给
下面这种写法是正确的:
cpp
void Func(int a, int b = 10, int c = 20);因为默认值从右往左连续给。
但是下面这种写法是错误的:
cpp
void Func(int a = 10, int b, int c = 20);原因是:
C++ 调用函数时,实参是从左往右匹配形参的。
如果中间跳过一个参数不给默认值,编译器就无法判断你传入的参数到底应该匹配谁。

当然各位肯定想问到底为何要这么划定呢?这个具体就得问当年c++的创始人了,大家可以理解为这是一种规范。
十七、声明和定义分离时,默认值写在哪里?
如果函数声明和定义分离,默认参数一般写在函数声明处,不要在声明和定义中重复写。
例如:
Stack.h
cpp
#pragma once
typedef int STDataType;
struct Stack
{
STDataType* a;
int top;
int capacity;
};
void STInit(Stack* ps, int n = 4);Stack.cpp
cpp
#include "Stack.h"
#include <cassert>
#include <cstdlib>
void STInit(Stack* ps, int n)
{
assert(ps);
ps->a = (STDataType*)malloc(sizeof(STDataType) * n);
ps->top = 0;
ps->capacity = n;
}test.cpp
cpp
#include "Stack.h"
int main()
{
Stack s1;
STInit(&s1); // 默认开 4 个空间
Stack s2;
STInit(&s2, 1000); // 明确开 1000 个空间
return 0;
}注意:
cpp
void STInit(Stack* ps, int n = 4);默认值写在声明中。
定义时写:
cpp
void STInit(Stack* ps, int n)不要重复写:
cpp
void STInit(Stack* ps, int n = 4) // 不建议十八、缺省参数适合什么场景?
缺省参数适合:
- 某个参数大多数时候使用固定值;
- 但少数情况下又希望调用者可以自定义;
- 不想写太多重载函数。
例如初始化栈:
cpp
void STInit(Stack* ps, int n = 4);大多数情况下默认开 4 个空间即可。
如果用户明确知道后面要插入大量数据,也可以直接传入更大的初始容量:
cpp
STInit(&s, 1000);这就比强制每次都传参数更灵活。
总结
这一篇从 C++ 第一个程序讲到了命名空间、输入输出和缺省参数。
重点如下:
- C++ 源文件通常使用
.cpp后缀。 - C++ 中可以使用
iostream进行输入输出。 std::cout用于输出,std::cin用于输入。<<在输出流中表示流插入,>>在输入流中表示流提取。endl会换行并刷新缓冲区,普通换行更推荐使用'\n'。- 命名空间用于解决命名冲突和名字污染。
std是 C++ 标准库使用的命名空间。- 项目中更推荐使用
std::cout或using std::cout,不建议在头文件中使用using namespace std;。 - 缺省参数可以让函数调用更灵活。
- 半缺省参数必须从右往左连续给默认值。
- 函数声明和定义分离时,默认值一般只写在声明处。