【AI大模型入门】B02:Stable Diffusion------开源绘图,让AI绘画飞入寻常百姓家
📖 阅读时长 :约9分钟
🎯 适合人群 :对AI绘画感兴趣、想了解开源AI图像生成的新手
💡 你将学到:Stable Diffusion是什么、和Midjourney有什么区别、能做什么、怎么上手
一、AI绘图的"两条路"
在AI绘图领域,存在两种截然不同的产品路线:
路线A:云端闭源(Midjourney)
优点:简单好用,质量稳定
缺点:需要付费,上传数据到云端,受内容限制
路线B:开源可本地(Stable Diffusion)
优点:免费,数据留本地,可完全定制
缺点:需要一定技术门槛,初次配置麻烦Stable Diffusion 就是路线B的代表,而且是目前最重要的开源AI绘图模型。
二、Stable Diffusion 是什么?
Stable Diffusion 是由德国公司 Stability AI 开发,并于2022年8月完全开源发布的AI图像生成模型。
📄 核心论文 :High-Resolution Image Synthesis with Latent Diffusion Models(Rombach et al., CVPR 2022)
📄 论文解读专栏:敬请期待 《LDM论文解读:潜空间扩散模型如何生成高清图像》
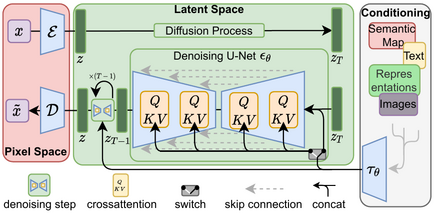
▲ 图1:Latent Diffusion Model(LDM,潜在扩散模型)架构图。关键创新是将扩散过程从像素空间移到压缩的潜在空间(Latent Space),大幅降低计算成本。图片来源:原论文 / CompVis GitHub
"Diffusion(扩散)"这个名字来自它的工作原理:
图像生成过程(扩散模型):
纯噪声图像(随机像素点)
↓ 一步步去噪
↓ 根据文字描述引导去噪方向
↓ 每一步让图像更清晰
最终生成符合描述的图像可以想象成:从一张布满雪花的电视屏幕开始,一步步把"雪花"变成你描述的画面。
三、为什么 Stable Diffusion 的开源意义重大?
2022年8月,Stable Diffusion 开源发布,整个AI绘图领域发生了地震。
之前:AI绘图要么需要昂贵的专业服务,要么只有大公司才能玩。
之后 :只要有一台有不错显卡的电脑,任何人都可以免费、本地运行AI绘图。
开源之后1个月内发生的事:
• 数千名开发者下载研究
• 各种界面工具(WebUI)涌现
• 用户开始训练自定义风格模型
• 出现了专门用于"画人物"的模型
• 出现了风景、建筑、产品设计等垂直方向模型现在,基于Stable Diffusion的生态已经有了数万个各种风格的模型可以下载使用。
四、Stable Diffusion 能做什么?
🎨 文生图(Text to Image)
提示词:a fantasy castle on a floating island,
surrounded by clouds, sunset lighting,
digital art style, highly detailed
(输出:一张精美的奇幻城堡插画)🔄 图生图(Image to Image)
上传一张图,告诉它你想改成什么风格或内容:
输入:你的一张照片
提示:"把这张照片转成水彩画风格"
输出:水彩画风格的同一场景🖊️ 局部重绘(Inpainting)
圈出图片的一部分,让AI重新绘制那个区域:
原图:一张室内照片,墙上有难看的裂缝
操作:圈选裂缝区域
提示:"完整的白色墙面"
结果:裂缝消失,被完好的墙面取代🔍 图像超分辨率(Upscaling)
把模糊的小图变成清晰的大图。
🎭 人物一致性(LoRA微调)
训练一个专门的小模型,让AI"认识"某个特定的人或风格,之后就能持续生成该人物/风格的图像。
五、Stable Diffusion 的版本进化
Stable Diffusion v1.4/1.5 (2022)
├── 最经典版本,生态最丰富
└── 大量LoRA和自定义模型基于此版本
Stable Diffusion 2.0/2.1 (2022年底)
├── 分辨率提升到768×768
└── 改变了训练数据(过滤了部分内容)
SDXL(Stable Diffusion XL,2023)
├── 参数量增大,图像质量大幅提升
├── 默认分辨率1024×1024
└── 对提示词的理解更准确
SD 3.0/3.5 (2024)
├── 采用全新架构,质量再次大幅提升
├── 文字生成更准确(AI生成图片中文字一直是难题)
└── 支持更复杂的场景构图六、使用 Stable Diffusion 的三种方式
方式一:在线体验(零门槛)
很多网站提供免费的SD在线体验:
- Hugging Face 的各类SD演示空间
- Civitai (专门的AI绘图社区,也有在线生成功能)
- LiblibAI 哩布哩布 (国内最大的SD模型社区,支持在线生成)
方式二:本地部署(功能最全)
推荐使用 AUTOMATIC1111 WebUI 或 ComfyUI:
硬件要求:
推荐:NVIDIA 显卡,显存 ≥ 8GB(RTX 3060或以上)
最低:显存 4GB(质量较差,速度慢)
CPU模式:理论可行,但每张图要等几分钟
安装步骤(概要):
1. 安装 Python 3.10
2. 下载 AUTOMATIC1111 WebUI
3. 下载模型文件(.safetensors,几GB大小)
4. 运行,浏览器打开即可使用方式三:使用整合包(最适合国内新手)
国内有很多开发者做好了"整合包"------下载解压就能用,不需要自己配置环境。
在B站搜索"Stable Diffusion整合包"可以找到很多教程。
七、Civitai:AI绘图的"应用商店"
civitai.com 是全球最大的AI绘图模型分享社区,就像是SD的"应用商店":
Civitai 上有什么:
• 数万个风格各异的基础模型(Checkpoint)
• LoRA微调模型(特定人物、特定风格)
• 提示词(Prompt)分享
• 社区用户的作品展示
• 模型使用教程比如你想要一个专门生成"浮世绘风格"插画的模型,或者一个擅长画"赛博朋克城市"的模型,都能在Civitai上找到。
八、AI绘图的提示词(Prompt)入门
Stable Diffusion 非常依赖提示词的质量。
基本结构
[主题内容], [风格关键词], [质量关键词], [镜头/光线]质量提升关键词(常用咒语)
正向提示词(加这些提高质量):
masterpiece, best quality, ultra detailed,
8K, HDR, photorealistic, sharp focus
反向提示词(排除这些避免糟糕结果):
lowres, bad anatomy, bad hands, ugly,
blurry, worst quality, text, watermark实战示例
正向提示词:
"1girl, solo, long hair, blue dress,
standing in a garden, cherry blossoms,
soft sunlight, anime style,
masterpiece, best quality, detailed"
反向提示词:
"lowres, bad anatomy, blurry,
worst quality, ugly"九、Stable Diffusion vs. Midjourney
| 对比项 | Stable Diffusion | Midjourney |
|---|---|---|
| 费用 | 完全免费(本地运行) | 约$10/月起 |
| 上手难度 | ⭐⭐⭐⭐(需要配置) | ⭐(超简单) |
| 画面质量 | 取决于模型和提示词 | 稳定高质量 |
| 可定制性 | 极高(训练LoRA等) | 较低 |
| 数据隐私 | 完全本地,安全 | 上传到云端 |
| 生态丰富度 | 极其丰富 | 封闭生态 |
| 商用限制 | 视具体模型协议 | 付费版可商用 |
十、总结
Stable Diffusion 是AI绘图领域的"民主化"力量:
- 🆓 完全免费:本地运行无需付费
- 🔓 完全开源:可修改、可商用(看具体模型协议)
- 🎨 极高可定制性:数万个风格模型,训练专属LoRA
- 🔒 数据安全:本地运行,隐私有保障
- 🌍 最大的开源社区:全球最活跃的AI绘图社区
如果你有一台带独立显卡的电脑,愿意花几个小时折腾配置,Stable Diffusion 会给你打开一扇新世界的大门。
🔔 下一篇预告
【AI大模型入门】B03:Midjourney------最惊艳的AI绘图工具,无需任何技术背景
本文为【AI大模型百科专栏】第B02篇 · 爆发时代
作者:孤岛站岗
更新时间:2026年4月