在学习 YOLO 的过程中,mAP 基本是绕不开的指标。在网上看了很多关于mAP的讲解,不是很理解其计算过程,于是总结了各个帖子及自己的理解,给出mAP计算的规律,这样就能很好的记忆。
目录
一、Precision、Recall 和 F1 Score
先把最基本的几个概念搞清楚。
1. TP、FP、FN、TN 是什么
在分类问题里,通常会有四种结果:
-
TP(True Positive):预测为正,实际也为正,预测对了
-
FP(False Positive):预测为正,实际为负,误报了
-
FN(False Negative):预测为负,实际为正,漏掉了
-
TN(True Negative):预测为负,实际也为负
可以简单记:
-
T = True,表示对
-
F = False,表示错
-
P = Positive,表示正类
-
N = Negative,表示负类
在目标检测里,通常不太强调 TN。
因为背景区域太多,TN 很难像分类任务那样明确统计,所以目标检测里更关注的是 TP、FP、FN。
2. Precision 是什么
Precision(精确率、查准率)公式如下:
它表示:
在所有"被模型预测为正类"的结果里,有多少是真的正类。
3. Recall 是什么
Recall(召回率、查全率)公式如下:
它表示:
在所有"真实就是正类"的样本里,到底检测出来了多少。
4. 一个简单例子
假设一张图里实际有 10 只猫。
模型最后检测出了 5 个"猫框",其中:
-
4 个框住的确实是猫
-
1 个框住的其实是狗
那么:
所以:
这两个值的含义分别是:
-
Precision = 0.8 :你检测出来的"猫"里,80% 真的是猫
-
Recall = 0.4 :真实存在的猫,你只找到了 40%
5. 为什么 Precision 和 Recall 往往相互制约
模型对每个预测框都会给出一个置信度分数 。
你需要设一个阈值,比如 0.5:
-
分数高于 0.5,就保留
-
分数低于 0.5,就过滤掉
这时候就会出现一个典型现象:
阈值设高一点
模型会更保守:
只保留特别有把握的框
误检少,Precision 往往更高
但容易漏掉真实目标,Recall 往往更低
阈值设低一点
模型会更"激进":
会保留更多框
不容易漏掉真实目标,Recall 更高
但误检会变多,Precision 会下降
所以一般来说:
想提高 Recall,往往要接受更多误报;
想提高 Precision,往往要接受更多漏检。
这就是为什么 Precision 和 Recall 往往是相互制约的。
6. F1 Score 是什么
F1 Score 的公式如下:
它是 Precision 和 Recall 的调和平均数。
7. 为什么 F1 不用普通平均,而用调和平均
我当时不理解为什么F1要这么设计,求平均值不行么?
为什么不用普通平均?
比如直接写成:
问题在于:
普通平均对"小值"不够敏感。
举个例子。
情况 1
如果用普通平均:
这个结果看起来还可以,
但实际上这个模型并不好,因为虽然它看起来指标很高但是几乎没找出来多少正样本。
再看 F1:
这个结果就更符合直觉:
只要 P 和 R 里有一个很小,乘积就会被迅速拉低。整体表现就不能算好。
二、PR 曲线是怎么生成的
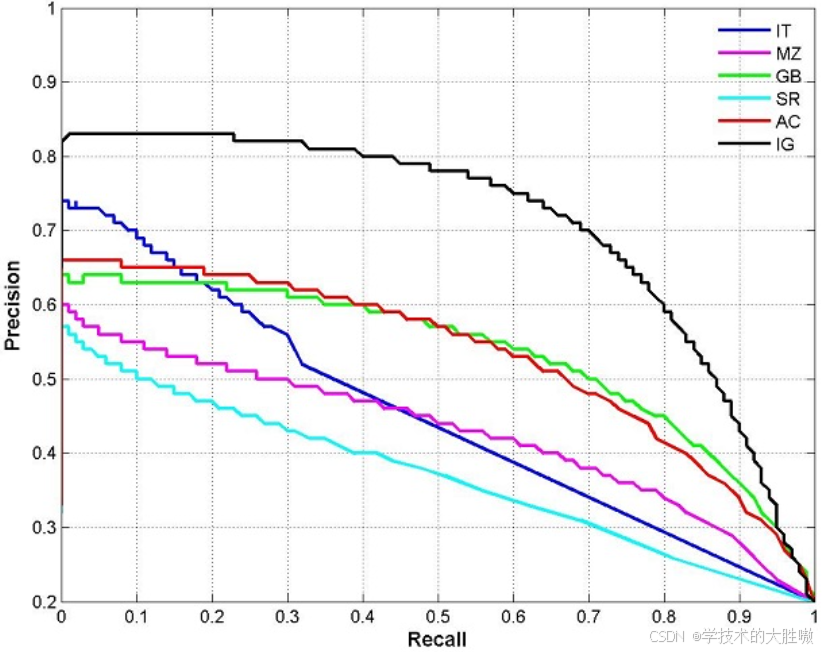
很多人知道 PR 曲线长什么样,
但不太清楚它到底是怎么一步一步出来的。
其实很简单:
PR 曲线不是直接画出来的,而是"扫阈值"扫出来的。
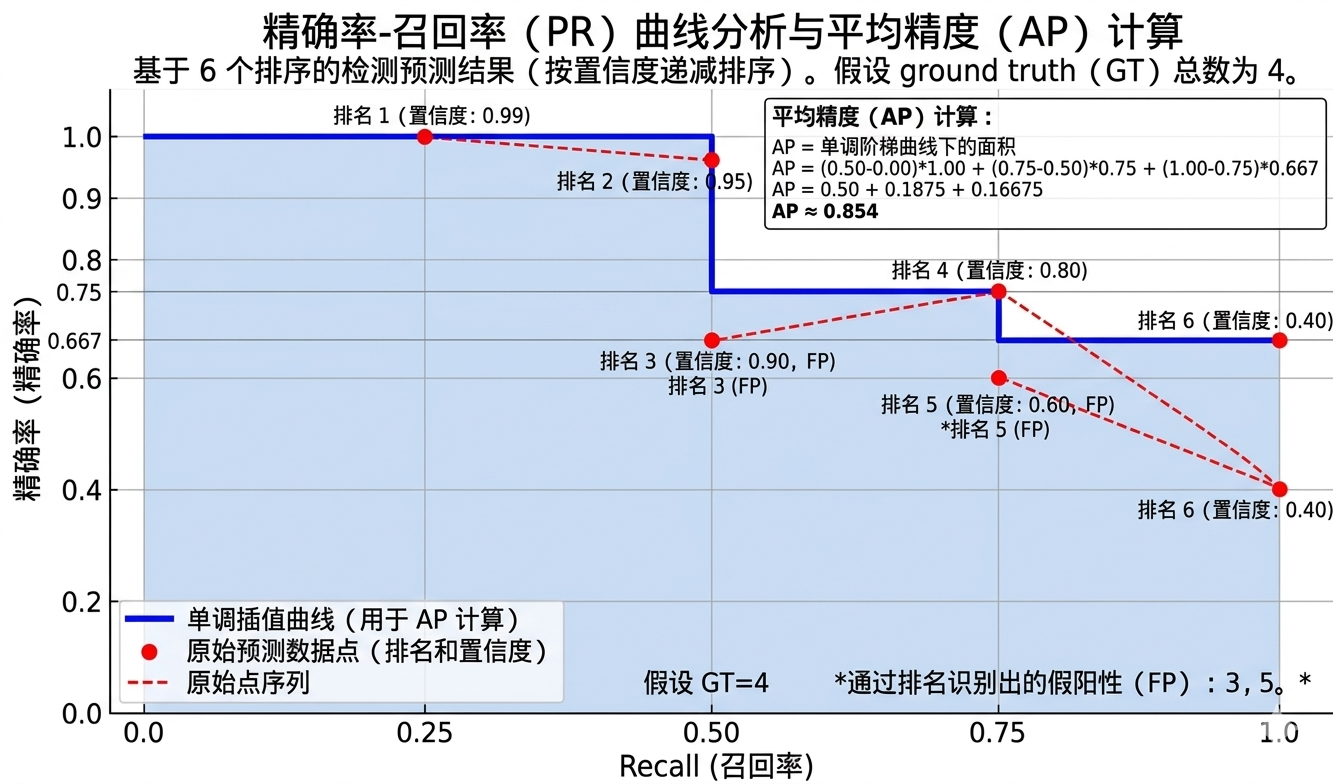
1. 先有一堆预测结果和置信度
假设模型对某一类给出了 6 个预测框,
并且按置信度从高到低排序后如下:
| 排名 | 置信度 | 预测是否正确 |
|---|---|---|
| 1 | 0.99 | 对 |
| 2 | 0.95 | 对 |
| 3 | 0.90 | 错 |
| 4 | 0.80 | 对 |
| 5 | 0.60 | 错 |
| 6 | 0.40 | 对 |
再假设:这一类在真实标注中一共有 4 个目标。
2. PR 曲线的生成过程,本质上就是"逐个加入预测框"
做法可以直接记成一句话:
先按置信度从高到低排序;
然后从前往后一个一个加入预测框;
每加入一个,就重新计算一次 Precision 和 Recall。
3. 第一步:只保留第 1 个框
当前只看第 1 个框,它是对的:
所以:
于是得到第一个点:
4. 第二步:保留前 2 个框
前 2 个框都对:
所以:
得到第二个点:
5. 第三步:保留前 3 个框
第 3 个框是错的:
所以:
得到第三个点:
这里有个很重要的现象:
-
Recall 没变,因为没有新增 TP
-
Precision 降了,因为多了一个 FP
6. 第四步:保留前 4 个框
第 4 个框是对的:
所以:
得到第四个点:
7. 后面继续重复,直到所有框都遍历完
你会得到一串点:
把这些点画在坐标系里:
-
横轴是 Recall
-
纵轴是 Precision
再把这些点连起来,
这条线就是 PR 曲线。
8. 为什么 Recall 整体上升,Precision 会波动
这是 PR 曲线最核心的性质。
Recall 为什么整体上升
因为阈值越来越低,保留下来的预测框越来越多。
真实目标被找出来的数量只会变多,不会变少。
所以:
Recall 整体是上升的。
Precision 为什么会波动
因为每次新加进来的框,有可能是对的,也有可能是错的:
-
加进来的是 TP,Precision 可能上升
-
加进来的是 FP,Precision 可能下降
所以:
Precision 往往不是平滑下降,而是上下波动的。
这也是为什么很多 PR 曲线看起来是锯齿状的。
三、AP 是怎么计算的
PR 曲线能看出模型整体表现,
但一条曲线不方便直接比较模型。
所以我们需要把它压缩成一个数,这个数就是 AP。
1. AP 本质上就是 PR 曲线下面积
AP = 单个类别 PR 曲线下面积
但是 PR 曲线通常是离散的,而且会有锯齿,所以实际计算时,是用"分段求和"的方式近似计算面积。
也就是说,AP 不是直接拿"抖动的原始曲线"去算,
而是先拿一条平滑后的包络线去算。
2. AP 不是把所有 Precision 直接平均
AP 真正做的是:
先按置信度从高到低排序,逐个加入预测框,得到一系列 PR 点。
然后对 Precision 做单调插值:对于某个 Recall,取该 Recall 及其之后所有点中的最大 Precision 。
最后按"Recall 增量 × 插值后的 Precision"求和,就得到该类别的 AP。
公式如下:
其中:
-
:这一小段 Recall 的增量
-
这本质上是在算面积。
在 PR 图里,每一小块面积就是:
把这些小块面积全加起来,
就是整个 PR 曲线下面积,也就是 AP。
四、mAP 是什么
AP 是单个类别 的指标。
比如:
-
猫有一个 AP
-
狗有一个 AP
-
人有一个 AP
那么 mAP 就是:
所有类别 AP 的平均值
公式如下:
其中 表示类别数。
1. mAP@0.5 是什么意思
在目标检测里,
一个预测框到底算不算检测对了,还要看 IoU。
所以经常会看到:
mAP@0.5
它表示:
在 IoU 阈值为 0.5 时计算出来的 mAP
也就是说,只要预测框和真实框的 IoU 大于等于 0.5,
就认为这个检测是对的。
2. mAP@0.5:0.95 是什么意思
这是 COCO 数据集里常见的指标。
它表示:
在多个 IoU 阈值下分别计算 AP,然后再取平均
通常这些阈值是:
所以这个指标比 mAP@0.5 更严格。
因为它不仅要求"检测到了",还要求"框得足够准"。
五、最后总结
其实就几句话:
Precision
预测出来的结果,准不准。
Recall
真实该找出来的目标,找到了多少。
F1
同时看 Precision 和 Recall,而且对小值敏感。
只要其中一个特别低,F1 就会明显下降。
PR 曲线
把预测框按置信度从高到低排序,逐个加入;
每加入一个,就重新计算一次 Precision 和 Recall;
最后把这些点连起来,就是 PR 曲线。
AP
单个类别的 PR 曲线下面积。
mAP
所有类别 AP 的平均值。