博主介绍:程序喵大人
- 35 - 资深C/C++/Rust/Android/iOS客户端开发
- 10年大厂工作经验
- 嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手
- 《C++20高级编程》《C++23高级编程》等多本书籍著译者
- 更多原创精品文章,首发gzh,见文末
- 👇👇记得订阅专栏,以防走丢👇👇
😉C++基础系列专栏
😃C语言基础系列专栏
🤣C++大佬养成攻略专栏
🤓C++训练营
👉🏻个人网站
先介绍核心要点!
Harness 的定义:Agent 由模型与 Harness 构成,Harness 涵盖模型之外的所有要素,如代码、配置与执行逻辑等,具体包括系统提示词、工具技能、基础设施、编排逻辑、钩子 / 中间件。以这种方式划分系统,能清晰界定模型与其余部分的职责。
-
Harness 的必要性:模型本质是输入输出函数,缺乏记住状态、执行代码、获取实时信息等能力,而 Harness 可补足这些能力。例如实现聊天功能,需借助 Harness 维护对话历史等。
-
Harness 的核心组件:
- 文件系统:提供持久化存储与上下文管理,使 Agent 拥有工作空间,实现信息按需加载、状态跨会话保留等,搭配版本控制功能更完善。
- Bash + 代码执行:赋予 Agent 通用问题解决能力,可自行写脚本、组合工作流,替代预定义工具模式。
- 沙箱环境和工具:确保安全执行与工作验证,解决安全性与可扩展性问题,配备默认工具,形成自我验证循环。
- 记忆与搜索:通过文件系统维护 "记忆文件" 及搜索工具,让 Agent 能记住信息、获取新知识。
- 对抗上下文衰减:运用压缩、工具调用卸载、技能延迟加载等策略,解决上下文衰减问题。
- 长期自主执行:借助文件系统与 Git 记录工作,通过 Ralph 循环防止提前结束,利用规划与自我验证确保执行正确。
-
Harness 与模型共同进化:二者共同进化使模型在特定 Harness 下能力提升,但模型可能对特定工具过拟合。
-
总结:即便未来模型更强大,Harness engineering 对构建高效 Agent 仍至关重要,它不仅弥补模型不足,更是设计系统的方式,类似舞台与演员的关系,助力模型发挥最大效率。
一、先搞懂:Harness到底是什么(行业标准定义)
一句话本质
Agent = Model + Harness
模型只负责推理生成;Harness是模型之外的一切------代码、配置、环境、工具、状态、约束、反馈、编排的总和,是让LLM从"文本函数"变成能自主干活的Agent的控制系统。
行业权威定义(OpenAI + LangChain + W3C)
Harness Engineering是为AI Agent设计标准化运行时、约束护栏、工具链、反馈闭环与生命周期管理的工程方法论,目标是让非确定的大模型,在真实业务中实现确定、可控、可审计、可复现的稳定输出。
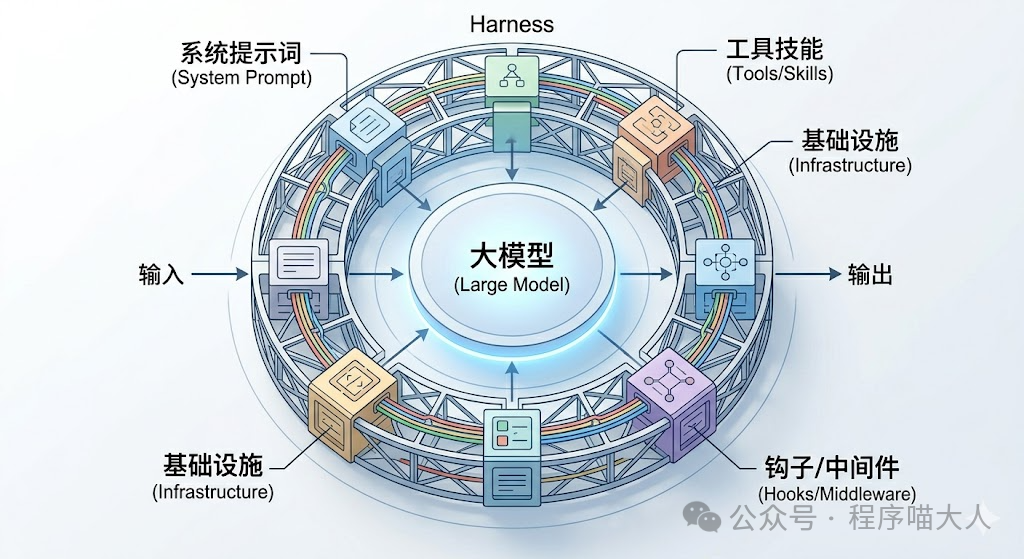
这张图片清晰地展示了 Agent 的构成。中心是作为内核的"大模型",负责基础的推理和生成。而围绕模型的整个外环就是 Harness。Harness 涵盖了模型之外的所有关键要素:系统提示词 (System Prompt)、工具技能 (Tools & Skills)、基础设施 (Infrastructure)、编排逻辑 (Orchestration) 以及 钩子与中间件 (Hooks & Middleware)。这种划分明确界定了模型与其余部分的职责。
二、为什么必须学Harness?模型的天生缺陷
LLM本质是输入→输出的无状态文本函数,自身完全不具备:
- 多轮状态记忆
- 代码执行与环境操作
- 实时信息获取
- 长任务持续推进
- 自我验证与纠错
- 安全边界与权限控制
所有这些能力,必须靠Harness补齐。
一句话:你想要Agent的任何能力,最终都要落在Harness上实现。
三、Harness六大核心组件
上下文管理(Context Manager)------对抗信息过载
模型上下文窗口有限、越长越容易"变笨"(上下文衰减)。Harness用三大策略解决:
- 主动压缩:对话超阈值自动总结,保留关键信息
- 工具输出卸载:长日志/大结果写入文件,只留摘要入上下文
- 渐进式披露:技能/工具描述懒加载,按需注入
实战原则:只给当前步骤必需信息,绝不全量塞prompt。
持久化与状态(Persistence)------跨会话不掉线
模型无状态,Harness用外部存储让Agent"记得住":
- 文件系统:工作空间、读写代码/数据
- Git版本化:记录变更、支持回滚、多Agent协作
- 记忆文件(AGENTS.md):跨会话保存偏好、规范、经验
价值:任务可中断、可恢复、可接力,支持长周期自主执行。
工具与执行引擎(Tool + Execution)------通用能力底座
从"预定义工具列表"升级为通用执行环境:
- Bash + 代码执行:Agent可临时造工具、写脚本
- 沙箱隔离:安全运行、不污染本地、支持并行
- 标准工具链:Git、测试、浏览器、CLI开箱即用
核心逻辑:给Agent一台能干活的机器,而非一堆固定玩具。
任务编排(Orchestration)------复杂任务不跑偏
解决模型"做一半就停、不会拆任务":
- Ralph循环:拦截提前结束信号,重置上下文继续推进
- 规划系统:目标→任务树→步骤→状态更新
- 子Agent路由:主Agent统筹,子Agent专项执行
- 人工介入点:高风险操作强制审核
验证与观测(Verification + Observe)------自我修正闭环
Harness让Agent自己判断对错:
- 自动测试:代码跑单测、日志检查
- 结果校验:输出合规性、格式、业务规则校验
- 可观测:截图、日志、追踪全记录
- 修复回路:失败→反馈→重试→修正
约束与护栏(Constraints)------安全与合规底线
用机器规则替代人工提醒:
- 权限白名单:禁止越权操作
- 行为契约:固定输出格式、禁止违规内容
- 调用限流:防止死循环、成本失控
- 数据脱敏:敏感信息自动遮蔽
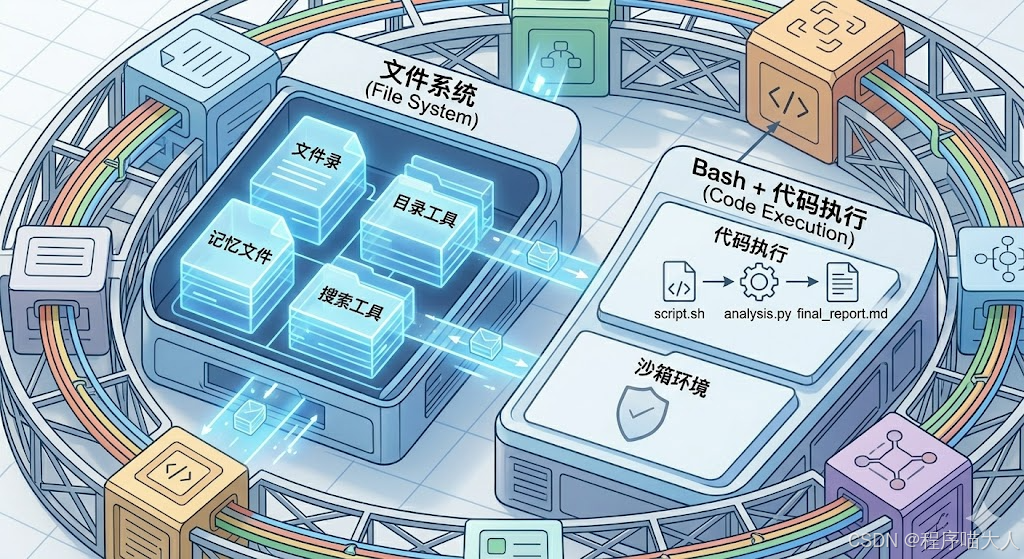
重点介绍Harness 内部的两个最核心组件如何协同工作,解决模型"无状态"和"缺乏执行能力"的问题。
左侧是 文件系统 (File System),它通过持久化存储(如本地磁盘、Git、云存储)管理上下文。模型可以将信息写入"记忆文件",实现状态跨会话保留(例如记住聊天历史),并按需加载信息。
右侧是 Bash + 代码执行 (Code Execution)。这赋予了 Agent 通用问题解决能力。模型不再只能调用预定义的工具,而是可以自行编写脚本、组合工作流(如左侧展示的 script.sh -> analysis.py -> final_report.md),从而灵活应对各种复杂任务。
沙箱提供了一个受限、隔离的执行环境,防止模型编写的代码危害外部系统。
其中有 自我验证循环 (Self-Correction Loop) 过程:
- 执行 (Execution):模型在沙箱中运行代码。
- 验证 (Validation):Harness 使用默认工具捕获执行状态、错误或输出,并与预期结果进行比对。
- 反馈 (Feedback):验证结果(如执行失败、输出错误)被反馈给模型。模型根据反馈,在沙箱内修正代码或工作流,再次进行执行。
这个循环赋予了 Agent 在安全前提下的自我进化能力。
四、Harness核心工作流:ReAct + Harness闭环
标准执行流程(所有爆款Agent通用):
- 感知:Harness注入上下文、记忆、工具描述
- 推理:LLM做决策、拆任务、选工具
- 行动:Harness校验权限、安全执行、拦截风险
- 观察:Harness收集结果、写入状态、压缩上下文
- 验证:自检→通过则继续→失败则修正
- 完成:归档结果、更新记忆、清理环境
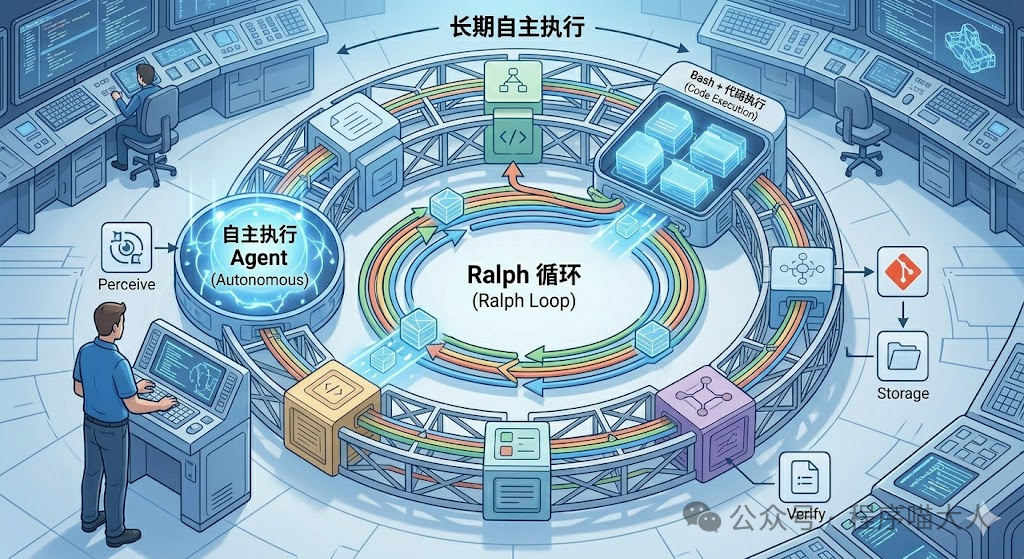
Agent 要实现 长期自主执行 (Long-term Autonomous Execution),离不开 Harness 提供的基础设施和控制逻辑。
上图展示了 Ralph 循环(一个简化的长期规划和执行循环),它由以下部分构成:
- 感知与规划 (Perceive & Plan):Harness 使用文件系统和 Git 记录工作状态,模型感知当前状态并更新规划。
- 执行 (Execute):在沙箱中执行计划(如前图所示,使用代码和工具)。
- 自我验证与Ralph循环 (Self-Verification & Ralph Loop):关键部分,通过内部的验证(Validation)模块,Harness 捕获执行过程,确保执行正确且符合预期,并在发现偏差时触发模型重新感知和感知规划,从而防止执行提前结束。
这整个过程构成了长期自主执行的闭环。
五、工程化实战:Harness落地四步法
Step1:边界定义(模型做什么,Harness补什么)
- 模型:推理、理解、生成
- Harness:状态、执行、安全、校验、编排
Step2:组件选型(最小可用集)
- 必选:上下文管理、状态持久化、沙箱、验证
- 可选:子Agent、技能懒加载、多模型路由
Step3:配置标准化(harness.yaml)
cpp
model: gpt-4o
context:
max_tokens: 128000
compact_threshold: 0.85
persistence:
filesystem: true
git: true
execution:
sandbox: true
bash: true
tools: [search, file_rw, test]
guardrails:
forbidden_cmds: [rm -rf, sudo]
verify_before_write: trueStep4:评估迭代
用Terminal Bench、任务成功率、幻觉率、成本四大指标持续优化Harness配置。
六、行业标杆案例:同样模型,Harness决定上限
- Claude Code
同一Opus 4.6模型,专属Harness让编码能力大幅提升,靠文件系统、验证闭环、沙箱三件套。
- LangChain编码Agent
仅优化Harness(文档结构、验证回路、追踪),Terminal Bench 2.0排名从30→5,得分52.8%→66.5%。
- OpenAI Codex
训练与Harness深度绑定,模型学会用文件、Bash、规划,脱离专属Harness性能下降。
一句话结论:模型决定下限,Harness决定上限。
七、总结:Harness Engineering的核心价值
- 从"调模型"→"造系统",工程化思维升级
- 让Agent可靠、可控、可落地、可商业化
- 降低幻觉、提升长任务成功率、保障安全
- 同样模型,Harness优秀→效果翻倍、成本减半
一句话:未来AI竞争,既在于在模型大小,在于Harness强弱
码字不易,欢迎大家点赞,关注,评论,谢谢