Python 学习第 26 天,今天进入 "爬虫" 部分的学习与讲解,
一、爬虫的概念
网络爬虫(Web Crawter / Spider / Robot) ,又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者。是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗地说,爬虫就是将我们日常通过浏览网页获取信息的行为自动化赋予机器,让其代替我们进行信息检索、收集乃至操作。如果将 "爬虫" 比作一只蜘蛛,那么每个网页就相当于蜘蛛网上的节点,爬虫会自动化、批量化地在网络资源(如网页、HTML、API接口、APP数据、FTP、文件服务器、数据库、本地文件、日志、邮箱、WebSocket 实时数据、物联网设备数据等)上抓取、解析、递归我们需要的信息。
二、爬虫的应用
1. 搜索引擎与内容索引
- 全网网页抓取、建立搜索库;
- 内容收录、更新快照、关键词索引。
2. 数据聚合与信息整合
- 新闻聚合、资讯整合;
- 行业榜单、排行榜抓取;
- 公开数据汇总(天气、航班、列车、汇率等)
3. 电商与价格类应用
- 商品价格监控、比价;
- 库存、活动、促销信息抓取;
- 商品评论、销量、评分采集。
4. 企业商业情报
- 竞品信息监控;
- 行业数据采集与分析;
- 市场趋势、用户评价、舆情监测。
5. 金融与数据分析
- 股票、基金、期货、财经新闻抓取;
- 财报、公告、宏观数据采集;
- 量化交易基础数据获取。
6. 科研与学术
- 论文、期刊、文献数据采集;
- 公开统计数据抓取;
- 社会调查、网络行为研究。
7. AI 与大数据训练
- 文本、图片、语音素材批量采集;
- 构建训练数据集;
- 标注数据预处理。
8. 网络监测与安全
- 网站漏洞扫描;
- 非法内容监测;
- 站点可用性、更新频率监控。
9. 系统自动化与运维
- 接口数据定时同步;
- 日志抓取、状态采集;
- 跨系统数据迁移、同步。
10. 公共服务类
- 政务公开信息抓取;
- 招聘、房产、车辆等公开信息整合;
- 地图 POI、机构信息采集。
三、爬虫的分类
1. 按「爬取目标 / 数据来源」分类
- 网页爬虫(Web Crawler):
最传统、最常见的爬虫,目标是 HTML 网页,比如爬新闻、商品、论坛内容。
**代表工具:**Scrapy、BeautifulSoup、Requests
- API 接口爬虫:
直接请求后端 API 接口,获取结构化的 JSON/XML 数据,比网页爬虫更高效,是现在 APP、小程序爬虫的主流。
- APP 爬虫(移动端爬虫):
针对手机 APP 的接口进行抓包、模拟请求,爬取 APP 内的用户、商品、内容数据。
**代表工具:**Fiddler、Charles、MitmProxy
- 分布式爬虫:
由多台机器 / 多个节点协同爬取,解决单机爬取速度慢、IP 被封的问题,适合大规模数据采集(如搜索引擎)。
**代表工具:**Scrapy-Redis
- FTP / 文件爬虫:
自动遍历 FTP 服务器目录,批量下载文件、资源。
- 数据库爬虫:
批量查询、导出数据库中的数据,本质是自动化数据采集。
- 社交媒体爬虫:
专门针对微博、小红书、抖音等社交平台,爬取用户、评论、点赞、话题等数据。
- 搜索引擎爬虫(全网爬虫):
巨型分布式爬虫,负责全网网页抓取、索引,是搜索引擎的核心(如 Googlebot、百度蜘蛛)。
2. 按「爬取策略 / 工作方式」分类
- 通用爬虫(全网爬虫):
无特定目标,遍历整个互联网,抓取尽可能多的网页,用于搜索引擎。
**特点:**范围广、深度浅、效率要求高。
- 聚焦爬虫(主题爬虫):
只爬取与特定主题相关的内容,比如只爬电商商品、只爬金融数据。
**特点:**目标明确、精度高、深度可控,是商业爬虫的主流。
- 增量式爬虫:
只爬取新增 / 更新的内容,不重复爬取旧数据,节省资源,适合数据实时更新的场景(如新闻、价格监控)。
- 深度优先爬虫:
沿着一个链接一直往下爬,直到没有新链接,再回溯爬其他分支,适合深度挖掘特定主题。
- 广度优先爬虫:
先爬完当前页面的所有链接,再爬下一层,适合搜索引擎的全网抓取,保证覆盖广度。
- 并行 / 并发爬虫:
同时发起多个请求,提高爬取速度,是现代爬虫的标配。
3. 按「是否需要浏览器渲染」分类
- 静态爬虫(无渲染):
直接请求 HTML 源码,不需要浏览器,适合静态网页。
**代表工具:**Requests、BeautifulSoup
**缺点:**无法爬取 JavaScript 动态渲染的内容。
- 动态爬虫(有渲染):
模拟真实浏览器,执行 JavaScript 代码,渲染页面后再爬取,适合现在的动态网页、SPA 应用。
**代表工具:**Selenium、Playwright、Pyppeteer
**缺点:**速度慢、资源占用高。
4. 按「运行方式 / 部署方式」分类
- 单机爬虫:
运行在单台电脑上,适合小规模数据采集、个人学习、小项目。
- 分布式爬虫:
多台机器 / 多个节点协同工作,适合大规模、高并发的爬取任务(如搜索引擎、大数据采集)。
- 定时爬虫(定时任务):
按固定时间自动运行,比如每天凌晨爬取一次商品价格、新闻数据。
**代表工具:**APScheduler、Linux Crontab
- 实时爬虫:
持续运行,实时监控数据变化,一旦有新数据立即爬取,适合行情监控、舆情监测。
5. 按「用途 / 业务场景」分类
- 数据采集爬虫:
最通用的爬虫,用于批量获取公开数据,做分析、报告、聚合。
- 自动化测试爬虫:
用于接口测试、压力测试、回归测试,验证系统稳定性。
- 网络安全爬虫:
用于漏洞扫描、渗透测试、暗网监控、反爬防护。
- 违规爬虫(高风险 / 违法):
抢票爬虫、刷票 / 刷赞爬虫、恶意攻击爬虫、隐私数据爬虫,这类属于违规 / 违法,绝对禁止使用。
6. 按「是否遵守规则」分类
- 合规爬虫(良民爬虫):
遵守 robots 协议、控制请求频率、不爬取隐私数据、不干扰网站正常运行,是合法的。
- 恶意爬虫(黑客爬虫):
无视 robots 协议、高并发攻击、爬取隐私数据、用于违规用途,属于违法违规。
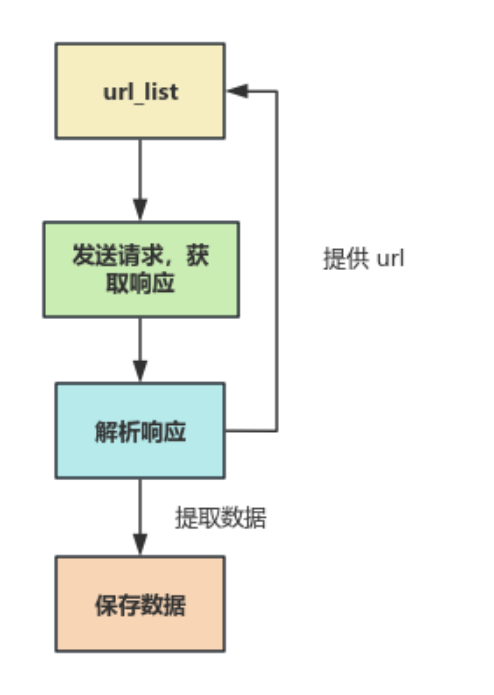
四、爬虫的基本流程