一.pip的使用
1.如果你的项目已经安装了所需依赖,可以通过 pip freeze 命令自动生成该文件,包含当前环境中所有第三方库及其版本
python
pip freeze > requirements.txt2.在新环境中(如另一台电脑、服务器),只需执行以下命令,即可自动安装文件中列出的所有依赖
python
pip install -r requirements.txt3.可查看 pip 当前的默认安装源(即从哪个镜像站下载包)
python
pip3 config list4.配置pip的清华镜像源
python
mkdir -p ~/.pip
echo "[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple" > ~/.pip/pip.conf二.创建py项目和项目结构解释
选择Python 解释器的环境类型
1. Project venv
基于 Python 内置的
venv模块创建项目专属的虚拟环境。环境会被创建在项目目录内(如
.venv文件夹),与其他项目和系统全局环境完全隔离。一般我们自己创建项目选择这个
2. Base conda
使用 Anaconda/Miniconda 的全局基础环境
一般不建议使用
3. Custom environment
手动指定一个已存在的 Python 解释器路径(可以是系统全局 Python、其他虚拟环境、Conda 环境,甚至远程环境)。
项目结构解释
.venv(虚拟环境目录):
- 是 Python 的
venv虚拟环境,用于隔离项目依赖,避免与其他项目或系统环境冲突。bin:包含虚拟环境的可执行文件,如激活 / 退出环境的脚本、pip工具等。lib:存放虚拟环境中安装的 Python 库(如你之前安装的selenium就会在这个目录下)。pyvenv.cfg:虚拟环境的配置文件,记录环境的创建信息(如 Python 版本、是否隔离系统包等)。
requirements.txt:Python 项目的依赖清单文件,记录项目需要安装的包及其版本,方便在其他环境中快速复现依赖(可通过pip install -r requirements.txt一键安装所有依赖)。
External Libraries:IDE(如 PyCharm)显示的外部库区域,列出项目可使用的 Python 标准库和已安装的第三方库(如虚拟环境中的selenium会在这里展示)。
Scratches and Consoles:IDE 的临时文件和控制台区域,用于临时代码测试、运行结果输出等。
三.爬虫
爬虫使用的工具
requests:请求工具
BeautifulSoup4+PyQuery:网页数据提取
selenium:自动化控制浏览器,需要浏览器驱动包
scrapy:爬虫框架
反爬常见问题
1.需要执行js脚本才能获取信息
使用selenium
2.别人会验证header中的信息
改header中的user-agent来伪装浏览器
3.栏位登陆(账号密码登录)
可能需要验证码二阶段认证啥的了,会非常麻烦
4.需要登陆验证
放入cookie
5.请求太多封ip
使用proxy改ip
6.csrf token
需要使用selenium先get在post
7.前端出现懒加载情况
使用selenium模拟下滑,在爬取
四.分布式爬虫scrapy
前置知识
安装scrapy
bash
pip install scrapy创建scrapy项目
bash
scrapy startproject demo1cd到spiders文件下创建爬虫文件
bash
scrapy genspider 爬虫名字 网页的域名spiders项目结构解析
bash
spiders
__init__.py
自定义的爬虫文件.py ‐‐‐》由我们自己创建,是实现爬虫核心功能的文件
__init__.py
items.py ‐‐‐》定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares.py ‐‐‐》中间件 代理
pipelines.py ‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后续处理
默认是300优先级,值越小优先级越高(1‐1000)
settings.py ‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent定义等运行爬虫文件
bash
scrapy crawl 爬虫名称
注意:应在spiders文件夹内执行scrapy的工作原理
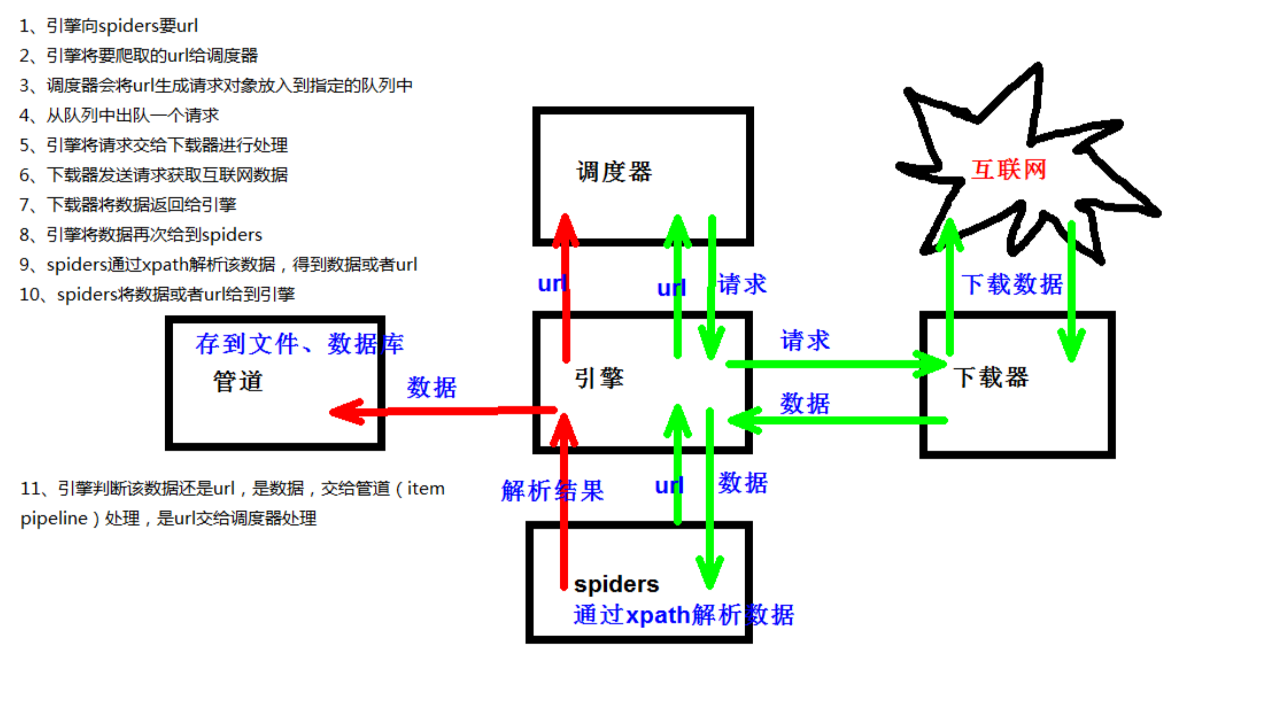
自己的爬虫文件
response的方法
response.text ‐‐‐》响应的是字符串
response.body ‐‐‐》响应的是二进制文件
response.xpath()‐》xpath方法的返回值类型是selector列表
extract() ‐‐‐》提取的是selector对象的是data
extract_first() ‐‐‐》提取的是selector列表中的第一个数据