本文是 《新兴数据湖仓架构搭建与开发规范全攻略》 系列第 8 篇,也是整个系列的收官篇。前面的内容已经系统梳理了湖仓架构、调度体系、DataOps 开发规范、工作流设计、资源隔离与稳定性治理等核心内容,而本篇则聚焦数据平台最基础的一层------数据集成。
文章重点围绕离线与实时同步、同步任务设计、Source/Sink 参数、实时断点、虚拟表治理以及上线发布规范展开,进一步补齐"数据入口治理"这一关键环节,帮助数据平台从"任务能跑"走向"全链路稳定运行"。
数据集成并不只是"把数据从 A 搬到 B"这么简单。真正进入生产环境之后,团队很快会发现,影响系统稳定性的关键,往往不是同步功能本身,而是任务模型是否合理、同步链路是否清晰、实时任务是否具备恢复能力,以及上线过程是否可控。
很多平台在早期阶段,往往只关注"任务能不能跑通",但当任务规模越来越大、链路越来越复杂之后,问题会逐渐转向另外几个方向:同步任务越来越多、实时链路越来越难维护、字段变更无法感知、上线容易漏资源、生产故障无法快速恢复。
因此,一个成熟的数据集成规范,重点从来不是功能堆叠,而是如何让同步任务具备长期可维护性、可扩展性与可治理性。本章将围绕离线批同步、实时同步、同步管道设计、实时断点机制、虚拟表治理以及上线发布规范,系统整理一套适用于企业级数据平台的数据集成开发建议。
数据集成任务:离线批同步 vs 实时同步
在数据平台建设过程中,数据集成通常会分为两类核心场景。第一类是离线批同步,主要解决周期性数据加工问题;第二类是实时同步,主要解决持续增量与 CDC 数据流转问题。两者虽然本质上都是数据搬运,但运行模式、资源模型、故障恢复方式以及调度机制完全不同,因此开发规范也必须区分设计。
离线同步更偏向"定时跑批",强调任务稳定完成与周期性交付。实时同步则更偏向"持续运行",强调低延迟、断点恢复与长期稳定性。
两大模块
数据集成主要分为离线批同步与实时同步两大模块。
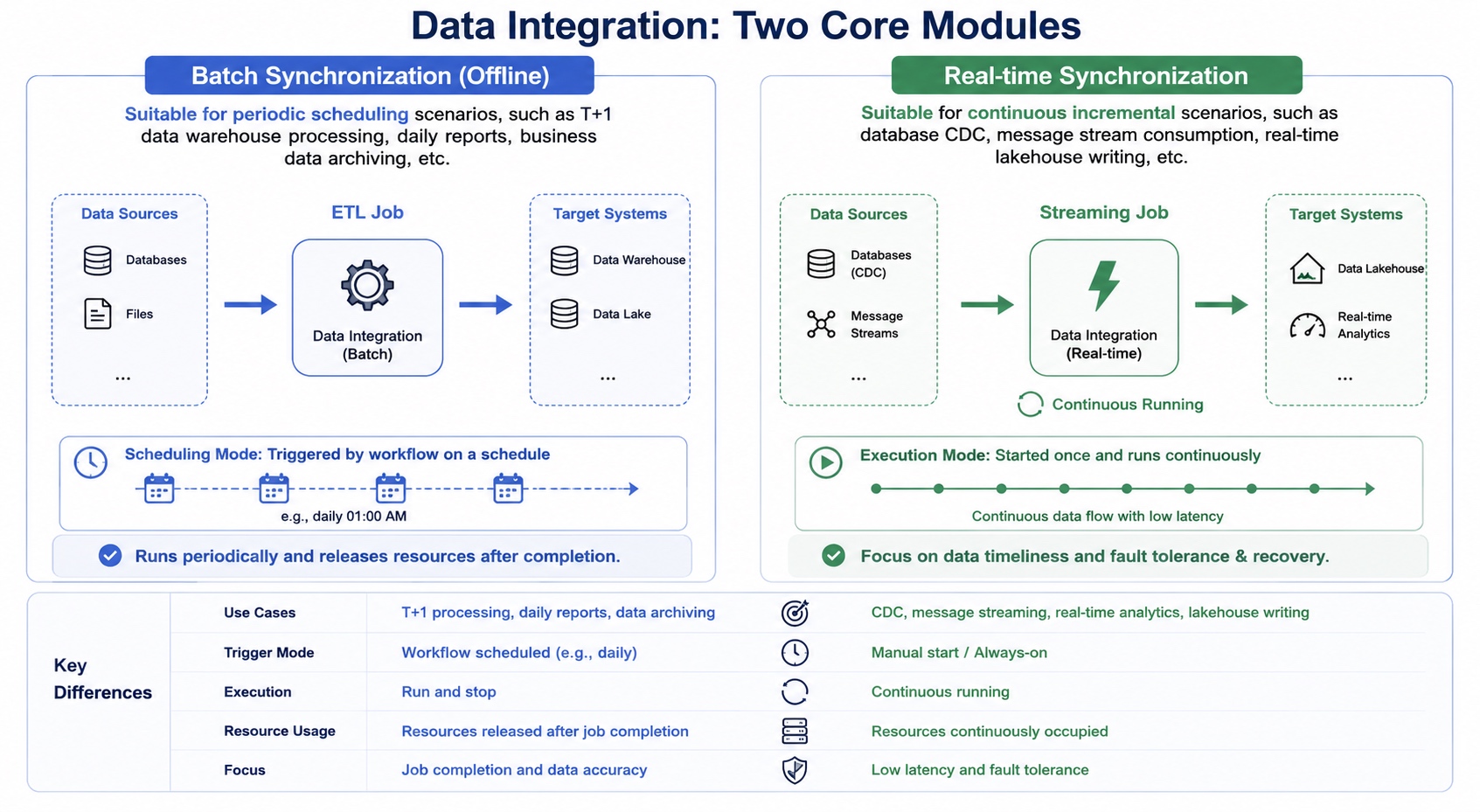
离线同步适用于周期性调度场景,例如 T+1 数仓加工、日报统计、业务数据归档等。任务通常由工作流定时触发,运行结束后释放资源。
实时同步则适用于持续增量场景,例如数据库 CDC、消息流消费、实时湖仓写入等。任务启动后会持续运行,更关注数据时效性与异常恢复能力。
开发同步任务三步走
一个标准的数据集成任务,建议统一按照固定流程开发。这样不仅可以降低开发差异,也更方便后期治理与排障。
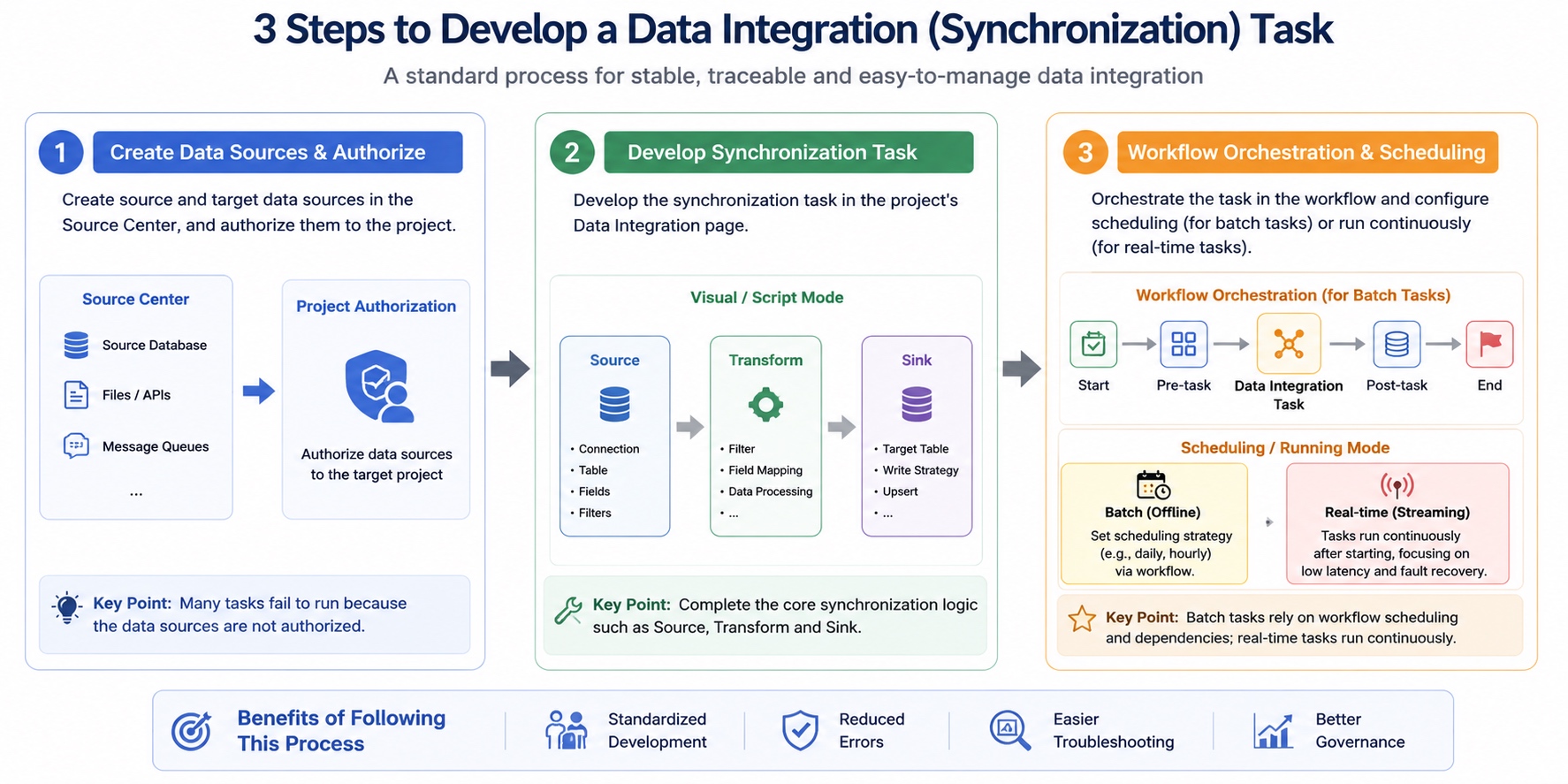
第一步是在源中心创建源数据源与目标数据源,并将数据源授权给对应项目。很多同步任务无法运行,并不是任务配置问题,而是数据源没有完成项目授权。
第二步是在项目的数据集成页面开发同步任务。在这里完成 Source、Transform、Sink 等核心同步逻辑配置。
第三步是在工作流中完成任务编排与调度配置。离线同步任务需要通过工作流配置依赖关系与定时策略,而实时任务则采用持续运行模式。
创建同步任务,画布模式优先,多表同步优先
同步任务的开发方式,会直接影响后续维护成本。很多团队在初期为了追求开发速度,会大量使用脚本模式或者"一张表一个任务"的开发方式,但随着任务规模扩大,很快就会出现任务爆炸、逻辑重复、排障困难等问题。
因此,规范更推荐采用画布模式与多表同步模型,以降低长期运维复杂度。
入口区分
离线同步任务与实时同步任务,需要进入各自对应页面创建。
这是因为两类任务属于不同运行模型,参数体系与运行机制也完全不同。离线任务强调调度与依赖控制,而实时任务更关注 checkpoint、恢复与限速能力。
任务名称与描述
任务名称必须保证项目内唯一。
任务描述不能简单填写"同步任务"或者"测试任务"这类无意义信息,而应该明确写清业务含义、同步范围与目标用途。因为后续无论是故障排查、任务交接、运维巡检还是审计分析,最终都会依赖这些描述信息。
很多团队后期维护困难,本质上并不是技术问题,而是早期缺乏规范化命名。
开发模式选择
默认推荐使用画布模式。
画布模式更容易标准化,更适合多人协作,也更方便可视化排障与后期治理。对于大型数据平台来说,统一开发方式远比"个人开发习惯"更重要。
只有在以下场景中,才建议使用脚本模式:
开发者本身更习惯脚本开发,或者需要使用开源 SeaTunnel 已支持、但商版页面暂未覆盖的数据源。
业务模型推荐
多表同步(推荐)
规范优先推荐多表同步模型。
一个任务同步多张表,不仅可以统一同步逻辑,也能显著降低任务数量与调度复杂度。对于 JDBC 类数据源,该模式通常支持 where 条件读取与批量同步能力,非常适合企业级批量集成场景。
多表同步最大的价值,并不只是"少建几个任务",而是后续统一治理会更加容易。增量逻辑、字段规则、调度策略都可以统一维护。
单表同步
单表同步是一次只同步一张表。
该模式兼容性最好,适配所有类型数据源,因此对于 MongoDB、Elasticsearch、S3、Hive、Kafka 等非结构化或虚拟表数据源,更推荐采用单表同步。
因为这些数据源往往不存在统一结构,强行做多表治理反而会增加复杂度。
离线增量同步
离线增量同步支持基于时间字段或自增字段进行数据抽取。
对于 JDBC 类数据源,通常都支持这种模式。相比全量同步,增量同步能够显著降低源库压力与同步耗时,因此在生产环境中更推荐优先采用。
同步管道设计:Source → Transform(可选)→ Sink
同步任务的本质,是一条标准化的数据流转链路。规范建议所有同步任务都采用统一结构,而不要在单个任务中堆叠大量复杂逻辑,否则后期维护难度会迅速上升。
基本结构固定
所有同步任务,都建议采用固定结构:
Source → Transform(可选)→ Sink
其中,Source 负责读取数据,Transform 负责过滤、字段修改、表转换等处理逻辑,Sink 负责写入目标端。
统一结构最大的价值,在于后期任何人接手任务时,都能快速理解同步链路。
配置顺序强约束(非常重要)
规范要求必须先配置 Source,再配置 Sink。
因为 Sink 的表结构与字段映射,会基于 Source 自动生成。如果顺序错误,后续会出现大量人工字段映射问题,最终导致开发效率下降。
正确配置顺序应该是:
先配置来源数据源,再配置数据库、同步表与字段,最后再配置 Sink。
这是同步开发中的硬约束。
不建议一个任务中配置多条管道
虽然画布支持一个任务中绘制多条同步管道,但规范明确不建议这样做。
原因并不在于平台能力不足,而是后期问题定位会变得极其困难。一个任务中同时存在多条同步链路时,日志分析、异常排查、依赖定位与任务复用都会迅速复杂化。
从长期治理角度来看,"一个任务只做一件事"会更加稳定。
编排与调度
离线同步任务需要加入工作流画布,配置上下游依赖关系,并通过工作流配置定时运行。对应任务类型为:
数据集成 - WHALETUNNEL_BATCH
实时同步任务对应:
数据集成 - WHALETUNNEL_STREAM
但规范特别强调,实时任务无法在工作流中运行,必须回到实时同步列表手动点击"运行"。这是很多开发者最容易踩坑的地方。
节点与任务参数速查:Source / Sink / 实时断点
任务真正进入生产环境之后,决定稳定性的往往不是"功能是否正确",而是参数是否合理。
特别是并行度、分片大小、断点保存、重试机制与限速策略,这些参数都会直接影响源库压力、网络稳定性、目标端写入能力以及实时恢复效率。
因此,参数规范必须统一。
Source 关键点(读取端)
Source 的核心目标,是稳定读取数据,同时控制对源端系统的影响。
- 通用 where 条件
where 条件默认允许为空。
如果需要做过滤或增量同步,则必须满足两条规则。
第一,过滤字段必须是所有待同步表的共通字段。否则多表同步时无法统一下推过滤逻辑。
第二,条件必须以 where 开头。
例如:
sql
where date > ${biz_date}这里支持参数变量替换。
- 分片大小
分片大小通常保持默认即可。
该参数用于限制每个分片读取的数据规模。分片越细,并行能力越强,但连接与调度开销也会同步增加。因此建议从默认值开始,通过压测逐步微调。
- 并行度
并行度默认即可,不建议盲目提高。
规范建议,并行度一般不要超过机器 CPU 核心数的 80%。
因为并行度过高时,很容易导致源库连接数暴涨、锁竞争加剧、网络抖动增加,最终反而影响整体稳定性。
- 待同步字段
默认情况下采用全表同步。
如果需要指定同步字段,则需要关闭"全表同步"配置,再手动选择目标字段。
Sink 关键点(写入端)
Sink 的核心目标,是在保障稳定性的前提下完成数据写入。相比"写得快",规范更强调"写得稳"。
- 目标表名策略
单表同步模式下,可以直接选择已有目标表。
多表同步模式下,推荐开启"自定表名"。系统会基于源表名自动映射,并支持在:
text
${table_name}前后增加前缀或后缀,实现统一命名规则。
- 已有表结构处理
通常推荐采用以下策略:
当目标表不存在时自动创建;目标表存在时直接跳过。
这样既能降低初始化成本,也能避免误覆盖生产表结构。
- 已有数据处理
一般推荐保留表结构并保留已有数据。
相比直接覆盖,这种方式风险更低,也更适合生产环境。
- 批量写入 / 重试 / 写入线程
批量写入最大行数、最大重试次数以及写入线程数,通常保持默认即可。
规范建议先保障稳定运行,再根据压测结果逐步优化参数,而不是一开始就盲目追求高性能。
- Upsert 保一致性(建议默认开启)
当目标表存在主键时,建议默认开启 Upsert。
通过覆盖同主键数据,可以保障目标端最终一致性。
实时任务执行参数:断点是硬要求
实时同步最大的风险,并不是任务失败,而是失败后无法恢复。
因此,Checkpoint(断点机制)是实时任务的生命线。
- 作业失败重试次数
该参数用于设置同步任务自动重试上限。
它能够给短暂异常留出自动恢复空间,避免因为一次网络抖动导致任务长期停摆。
- 断点保存频率 / 超时(实时必须填写)
断点保存频率,参考值通常为:
text
30000也就是每 30 秒保存一次断点。
断点保存操作超时时长,参考值通常为:
text
3600000也就是 1 小时超时。
Checkpoint 保存越频繁,任务恢复速度越快,但状态存储压力也会同步增加,因此需要结合业务场景平衡。
- 限速与同步告警(可选增强)
平台支持配置每并行度每秒最大行数(rows/s)以及每并行度每秒最大字节数(bytes/s),用于限制同步速度。
限速的核心目标,并不是降低性能,而是保护源库、网络以及目标端系统,避免同步任务把生产环境打满。
如果需要监控实时任务运行状态,可以开启同步告警。
但在开启之前,必须确保告警组已经完成配置,并且已经授权给对应项目,否则即使开启告警,也不会有人收到通知。
同步配置常见参数解释
很多同步任务的问题,本质上并不是功能错误,而是参数理解错误。
因此,团队内部必须统一对关键参数的理解。
并行度
并行度不是越高越快。
过高的并行度会导致数据库连接数飙升、锁竞争增加以及网络抖动加剧。规范建议并行度不要超过 CPU 核心数的 80%。
分片大小
分片大小用于控制每个并行分片读取的数据规模。
分片更细时,并行能力更强,但连接与调度开销也会同步增加。因此建议从默认值开始压测微调。
限速参数
限速参数包括每并行度每秒最大行数(rows/s)以及每并行度每秒最大字节数(bytes/s)。
这些参数主要用于保护生产系统稳定性。
失败重试次数
失败重试用于给短暂异常预留恢复空间。
例如网络抖动、目标端瞬时压力升高、短暂写入失败等问题,都可以通过自动重试完成恢复。
断点保存
Checkpoint 是实时同步任务的生命线。
断点保存频率越高,恢复速度越快;但状态存储成本也会同步增加。
断点保存超时,则用于避免状态保存过程卡死。
同步告警
实时任务关注的重点,并不是"今天是否执行成功",而是:
是否出现积压、是否断点失败、是否频繁重试。
因此,告警体系必须真正可达,而不是"配置了但没人收到"。
非结构化数据变成"虚拟表"
在企业数据平台中,最大的治理难点之一,就是非结构化数据。
数据库天然具备表结构、字段定义与类型信息,但文件、消息流与对象存储通常没有这些能力。因此,如果没有统一结构定义,后期很容易演变成"脚本人肉解析"。
虚拟表机制,本质上就是为非结构化数据补齐 Schema 能力。
痛点:为什么直接同步不行
对于文件、FTP、SFTP、Kafka 这类数据源,平台通常无法像数据库一样完成字段映射、类型校验与结构治理。
最终结果往往是:
每个人都在写自己的解析逻辑,后期无法复用,也无法治理。
虚拟表的本质
虚拟表本质上是先把非结构化数据定义成一张"有字段、有类型、有顺序"的逻辑表。
这样之后,数据就可以进入统一湖仓治理体系。
字段解释、映射规则、类型约束以及变更影响分析,都能够统一管理。
虚拟表可以理解成"接口合同"
后续同步任务、Transform 以及 SQL,都以这份结构合同为准。
当数据格式发生变化时,需要先修改合同,再进行发布,从而避免"悄悄变更导致全链路口径漂移"。
- 用法1:为文件 / Kafka 定义结构(Schema First)
先定义字段、类型、顺序以及主键或业务键,然后在同步任务中直接选择该虚拟表作为源表。
这是最推荐的治理方式。
- 用法2:通过 SQL Query 生成虚拟表结构(Result as Table)
如果需要做宽表抽取、主题抽取或者多表联合抽取,可以通过用户自定义 SQL Query 获取结果集。
系统能够基于查询结果自动生成虚拟表结构,从而把"一次性查询结果"沉淀成可长期复用的数据资产。
上线发布清单:上线的是"资源集合",不是只有工作流
很多团队认为"工作流上线了,任务就上线了"。
但真正进入生产环境后会发现,数据平台上线的从来不只是工作流,而是一整套资源集合。
数据源、告警组、资源池、环境变量、权限体系、定时策略,任何一个资源遗漏,都可能导致生产事故。
因此,上线必须 Checklist 化。
上线两种形态
对于网络隔离环境,通常采用"导出 → 审批 → 导入"方式上线。
对于网络联通环境,则支持一键部署,但必须具备 Diff、审批与审计能力,确保上线内容可追溯。
同名策略:降低上线风险
规范强烈建议 dev 与 prod 使用同名资源。
包括数据源、告警组、资源池、定时策略以及环境变量。
环境差异应该通过配置隔离,而不是通过修改引用名称隔离。否则上线过程中非常容易出现资源引用断裂问题。
发布包 Checklist
上线前必须逐项确认。
- 数据源
需要确认数据源是否已经授权项目,dev 与 prod 是否保持同名,以及权限是否符合最小化原则。
- 告警
需要确认告警实例、告警组以及项目授权是否全部配置完成。
- 资源池
需要确认资源池并发上限是否合理,以及关键链路是否使用独立资源池。
- 定时 / 日历
需要确认调度策略是否绑定、工作流是否已上线,以及未完成时间告警是否已经配置。
- 实时任务
需要确认断点、重试、限速与告警是否全部配置完成。
- 回滚方案
上线前必须明确版本回退点与恢复方案。因为上线规范真正的核心目标,从来不是"成功上线",而是出现问题之后,系统仍然能够快速恢复。
结束语
整个《新兴数据湖仓架构搭建与开发规范全攻略》系列核心并不是介绍某一个组件如何使用,而是希望建立一套真正适用于企业级场景的数据平台工程规范。从架构设计、调度治理,到开发标准、稳定性建设,再到本篇的数据集成规范,整个系列实际上都在解决同一个问题:如何让数据平台长期稳定、可治理、可演进。
本篇作为收官篇,也为整个系列补上了最后一块关键拼图------数据如何稳定进入平台。至此,系列正式完结,但数据平台的规范化建设,才是真正长期持续的开始。欢迎关注白鲸开源,获取更多数据平台建设经验和干货。
往期精彩回顾:
(一)新兴数据湖仓架构搭建与开发规范全攻略:数据仓库与数据湖概述
(二)燃爆!AI 加持下,新兴数据湖仓架构与开发规范全解析!
(三)ODS/明细层落地设计要点:把数据接入层打造成"稳定可运维"的基础设施
(四)为什么你的数据仓库总在 ADS 层失控?DWS 才是关键答案
(五)数据仓库越做越乱?问题可能出在"命名"上
(六)以 WhaleStudio 三层开发管理框架为例,分享一套可落地的 DataOps 开发规范
(七)数据调度开发设计不踩坑!3 大处理模式,1 套规范搞定全链路稳定