前言
一、Softmax
1.1 核心定义
Softmax 是一种归一化函数,它能将一组任意大小的原始分数(Logits),转换为总和为 1 的概率分布。它的作用就像 "分配器",确保所有类别的概率加起来等于 100%,让模型能直接读出每个类别的置信度。
1.2 公式
σ(zi)=ezi∑k=1Cezk\sigma(z_i) = \frac{e^{z_i}}{\sum_{k=1}^C e^{z_k}}σ(zi)=∑k=1Cezkezi
- ziz_izi:模型输出的原始得分(Logits),可以是任意实数。
- ezie^{z_i}ezi:对每个得分做指数运算,将负数转为正数,同时放大差异。
- CCC:表示类别数目。
- 分母:所有类别的指数得分之和,做归一化,保证总和为 1。
1.3 通俗理解
- 保留差异:通过指数运算,得分大的会被放大,得分小的会被抑制。
- 归一化:将所有得分缩放到 0~1 之间,且总和为 1,转化为直观的概率。
1.4 简单例子
假设模型输出 3 个类别的得分:1, 3, 2
计算指数:e1≈2.72e_1≈2.72e1≈2.72,e3≈20.09e_3≈20.09e3≈20.09,e2≈7.39e_2≈7.39e2≈7.39
总和:2.72+20.09+7.39=30.22.72+20.09+7.39=30.22.72+20.09+7.39=30.2
归一化得到概率:
- 类别 1:2.72/30.2≈0.092.72/30.2≈0.092.72/30.2≈0.09
- 类别 2:20.09/30.2≈0.6720.09/30.2≈0.6720.09/30.2≈0.67
- 类别 3:7.39/30.2≈0.247.39/30.2≈0.247.39/30.2≈0.24
可以看到,原本得分最高的类别 2,概率被放大到了 67%,模型明确认为它是最可能的类别。
1.5 Softmax输入输出示意图
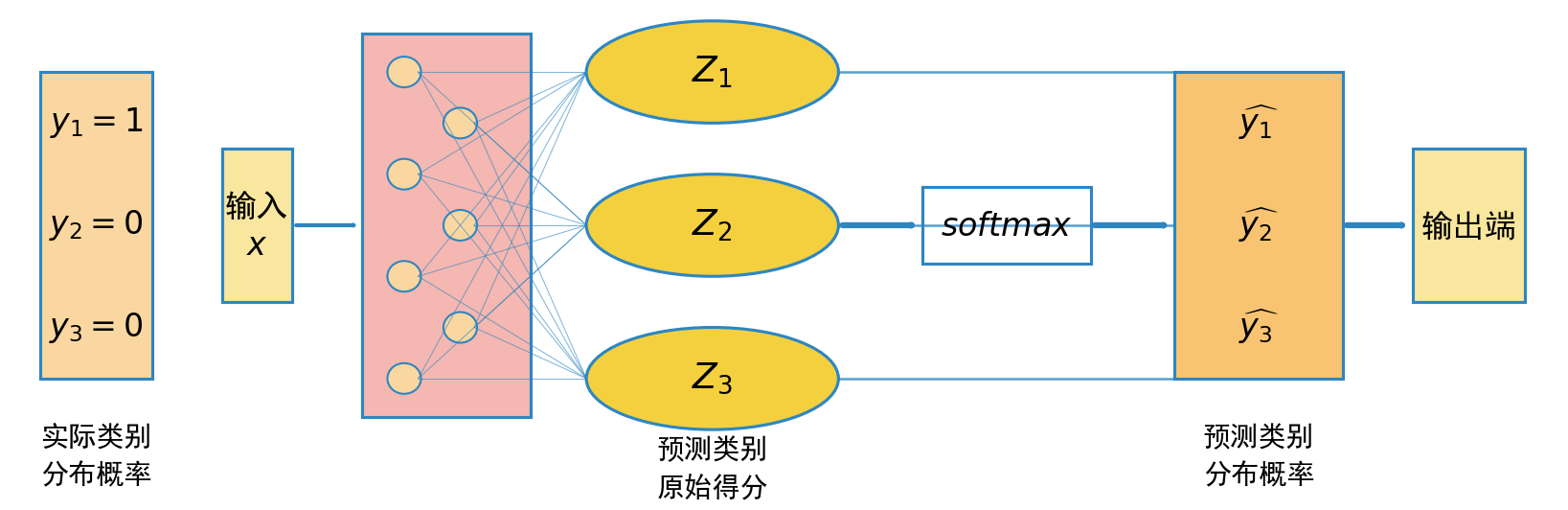
图1:结合神经网络,Softmax在单选多分类的输入输出示意图
1.6 优缺点
Softmax 优点:
- 引入指数映射特性,能够放大输入向量间的数值差异,强化类别区分度,让优势特征对应的概率更突出,贴合分类任务的决策逻辑。
- 函数求导形式简洁规整,搭配交叉熵损失后梯度计算极简、效率高,极大适配深度学习反向传播流程,便于梯度下降快速更新网络参数。
Softmax 缺点:
- 依托指数运算,若模型输出的原始 logits 数值过大,指数结果会急剧激增,极易出现浮点数值溢出,引发计算异常、产生无效 NaN
数据,破坏模型推理与梯度求解稳定性。
1.7 Softmax多分类代码实现
python
import torch
import torch.nn as nn
# K个输出节点,K分类
model = nn.Linear(10, 5) # 5分类
x = torch.randn(3, 10)
logits = model(x) # 原始得分 (3,5)
prob = torch.softmax(logits, dim=1) # 转为概率分布 (3,5)
print("原始得分:",logits)
print("转为概率分布:",prob)输出为3行5列的矩阵,转为概率分布后,所有值加起来等于1
python
原始得分: tensor([[ 0.4793, -0.6187, 0.3023, 0.6503, -0.8960],
[-0.4129, -0.4438, -1.0532, -0.7444, 0.0594],
[ 0.1236, 0.5579, -1.0544, 0.3092, -0.0416]],
grad_fn=<AddmmBackward0>)
转为概率分布: tensor([[0.2770, 0.0924, 0.2320, 0.3286, 0.0700],
[0.2075, 0.2012, 0.1094, 0.1490, 0.3328],
[0.2039, 0.3149, 0.0628, 0.2455, 0.1729]], grad_fn=<SoftmaxBackward0>)二、Sigmoid
2.1 Sigmoid简介
Sigmoid 函数也常被称作 Logistic 函数,常被用于神经网络隐藏层的神经元输出。它能把任意实数映射到 (0,1) 区间内,非常适合处理二分类任务;尤其在特征差异复杂、区分度不算悬殊的场景下,适配效果更佳。作为神经网络经典激活函数,它具备光滑、严格单调的特性,同时属于饱和型激活函数,标准表达式为:
σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1
2.2 Sigmoid与Softmax对比
运算逻辑差异:
- Softmax 本质是对一整组向量做全局归一化,单个元素的输出结果会关联向量内所有其他元素,数值之间存在相互制约、此消彼长的关系。
- Sigmoid属于独立的非线性变换算子,多用于神经网络内部搭建非线性表达能力,每个输入元素都会单独完成运算,元素与元素之间互不干扰、没有数值关联。
落地应用差异:
-
Sigmoid(独立概率、多标签、二分类、中间激活)常充当网络中间层激活函数,赋能模型拟合复杂非线性特征;也可适配多标签分类场景,对各类别概率单独判定。比如识别图片内含有的多种物体,网络输出对应类别向量后,经Sigmoid 映射得到每个类别的独立概率,再结合自定义阈值,就能判定该物体是否存在。
-
Softmax(全局互斥、单选、多分类)基本固定用作输出层激活函数,专攻单选多分类任务,常规搭配交叉熵损失协同优化;主流深度学习框架大多会将其内嵌至交叉熵损失模块中,简化分类任务的搭建流程。
Sigmoid落地举例:
- 多标签:一张图片里同时有「猫、狗、汽车、树」,不是只能选一个。每个类别单独判概率,互不冲突;阈值 0.5,超了就判定存在该物体。
- 二分类:邮件垃圾拦截 ------ 单独判定「是垃圾邮件 / 不是」。
- 中间激活:早期 CNN、简易全连接网络,用 Sigmoid 引入非线性;现在多被 ReLU 替代,但轻量化小模型仍会用。
Softmax落地举例:
- 单选多分类:一张图只能是「猫 / 狗 / 飞机 / 汽车」其中一类。所有输出概率相加=1,A 概率高,其他类概率必然降低。
2.3 Sigmoid函数图像
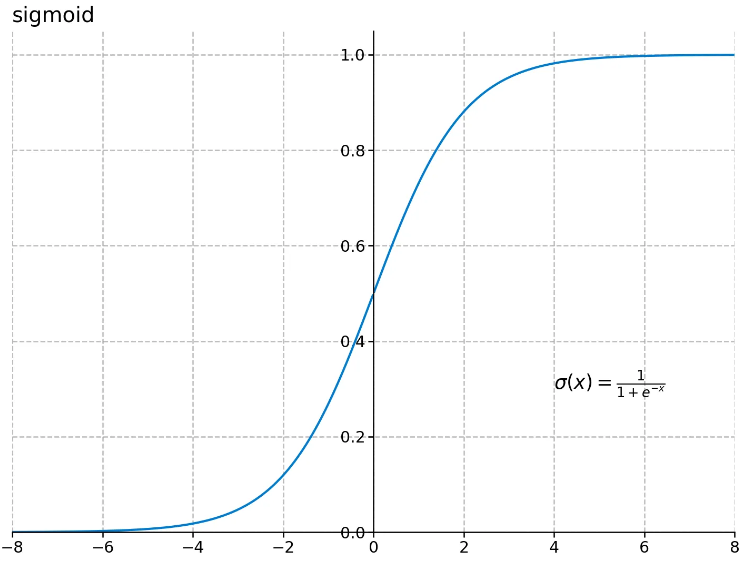
图2:Sigmoid函数示意图
图像特点:
- 线性区:在 x 接近 0 的区域(−2∼2 左右),曲线斜率较大,输入的微小变化会引起输出的剧烈变化,此时对输入数据非常敏感。
- 饱和区: 负半轴(左图):x 很小时,y 趋近于 0,曲线变得平缓。 正半轴(右图):x 很大时,y 趋近于 1,曲线也变得平缓。
- 影响:在饱和区,函数的导数(斜率)接近 0 。在神经网络训练中,如果输入落入饱和区 ,梯度消失现象容易发生,导致模型难以更新。
饱和区梯度消失的本质:
- 当输入x落入正负饱和区 时,Sigmoid 的导数无限趋近于 0 ,反向传播时,梯度会逐层乘以这个趋近于0的数,经过多层网络后,梯度会被稀释到几乎为 0,导致深层网络的参数无法更新,模型训练停滞。
- 这是 Sigmoid 被 ReLU 等激活函数替代的核心原因之一。
2.4 Sigmoid输入输出示意图
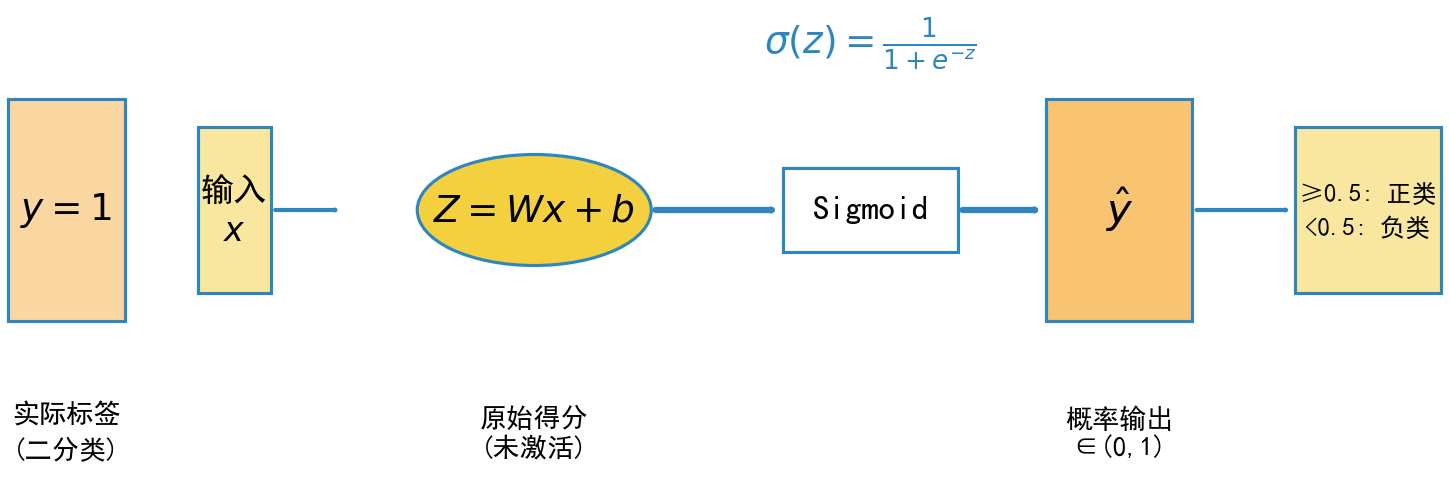
图3:Sigmoid函数的输入输出示意图
三、Cross Entropy Loss(CE 交叉熵损失)
3.1 交叉熵简介
物理学里,熵用于刻画热力学系统的混乱、无序程度;香农借鉴这一思想,将熵引入信息论,依托对数函数建立信息熵理论,以此量化信息本身的不确定性与未知程度。
H(p,q)=−∑xp(x)logq(x)H(p, q) = -\sum_{x} p(x) \log q(x)H(p,q)=−x∑p(x)logq(x)
其中:p(x)p(x)p(x) 是真实分布(目标分布),q(x)q(x)q(x) 是模型预测的近似分布,求和∑x\sum_x∑x遍历所有离散取值 x
交叉熵刻画的是两个概率分布之间的距离,或可以说它刻画的是通过概率分布q(0−1)q(0-1)q(0−1)来表达概率分布p(0−1)p(0-1)p(0−1)的困难程度,ppp代表正确答案,qqq代表的是预测值,交叉熵越小,两个概率的分布约接近。
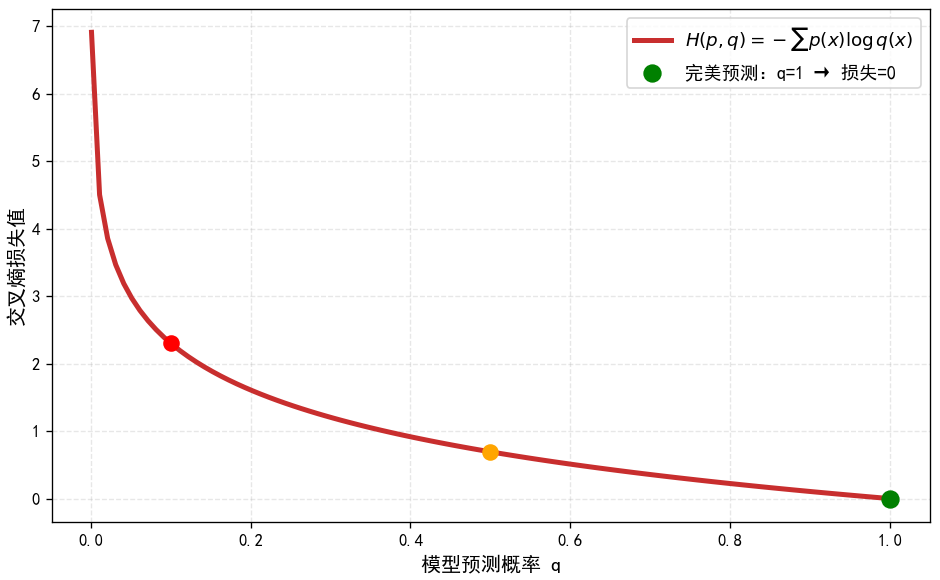
图2:交叉熵公式直观理解:预测越准确,损失越小
3.2 Softmax + Cross Entropy Loss
Softmax 映射(将向量转为概率分布):
pi=Softmax(z)i=ezi∑j=1Cezjp_i = \text{Softmax}(\mathbf{z})i = \frac{e^{z_i}}{\sum{j=1}^{C} e^{z_j}}pi=Softmax(z)i=∑j=1Cezjezi
(注:CCC为类别数,ziz_izi是模型原始输出 Logit)
Cross Entropy Loss(负对数似然):
LCE=−∑i=1Cyi⋅log(pi)L_{\text{CE}} = -\sum_{i=1}^{C} y_i \cdot \log(p_i)LCE=−i=1∑Cyi⋅log(pi)
(注:yiy_iyi是真实标签,通常是 One-hot 编码。例如真实是第 0 类,y=1,0,0y=1,0,0y=1,0,0)
3.3 代码实现
pytorch官网的函数接口nn.CrossEntropyLoss()其实是Softmax+Cross Entropy,因此输入的logits无需经过Softmax变换
python
import torch
import torch.nn as nn
# ---------------------------
# 手动实现:Softmax + CrossEntropyLoss(One-Hot 直接输入)
# ---------------------------
def manual_cross_entropy_loss(logits, target_one_hot):
"""
logits : 模型原始输出 [batch, 类别数]
target_one_hot: 直接输入 One-Hot 标签 [batch, 类别数]
"""
# 1. Softmax:把 logits 转成概率
exp_logits = torch.exp(logits)
sum_exp = torch.sum(exp_logits, dim=1, keepdim=True)
softmax = exp_logits / sum_exp
# 2. 取对数概率 log(p)
log_p = torch.log(softmax)
# 3. 标准交叉熵公式
loss = -torch.sum(target_one_hot * log_p, dim=1).mean()
return loss
# ---------------------------
# 测试代码
# ---------------------------
if __name__ == "__main__":
# 2 个样本,3 个类别
logits = torch.tensor([
[1.0, 2.0, 3.0],
[2.0, 1.0, 0.0]
])
# 直接定义 One-Hot 标签
target_one_hot = torch.tensor([
[0., 0., 1.], # 第1个样本 → 类别 2
[0., 1., 0.] # 第2个样本 → 类别 1
])
# 官方 CrossEntropyLoss 需要类别索引(从 one_hot 提取)
target_idx = torch.argmax(target_one_hot, dim=1)
# 计算损失
manual_loss = manual_cross_entropy_loss(logits, target_one_hot)
official_loss = nn.CrossEntropyLoss()(logits, target_idx)
# 输出对比
print("手动实现损失:", manual_loss.item())
print("官方PyTorch损失:", official_loss.item())运行结果:
python
手动实现损失: 0.9076060056686401
官方PyTorch损失: 0.9076058864593506