
目录
[1. 核心公式与逻辑流](#1. 核心公式与逻辑流)
[2. 多粒度工具箱(Toolkit)](#2. 多粒度工具箱(Toolkit))
[3. 智能体工作流:ReAct 范式](#3. 智能体工作流:ReAct 范式)
[1. 惊人的帧数压缩比](#1. 惊人的帧数压缩比)
[2. 对基座模型的显著提升](#2. 对基座模型的显著提升)
[3. 复杂逻辑推理能力](#3. 复杂逻辑推理能力)
理解长视频一直是大模型领域的"硬骨头"。面对动辄一小时的视频,目前的通用做法往往是"暴力抽帧"或者构建庞大的预处理数据库。这种做法不仅耗费巨大的计算资源,效率也低得惊人,更像是一种"力大砖飞"的笨办法。最近,来自 AMD 和美国罗切斯特大学的研究团队提出了一种全新的长时程(Long-Horizon)视频智能体------VideoSeek。
该模型被命名为 "VideoSeek" ,其中 "Seek" 意为"搜寻"或"寻找"。作者的灵感源于人类看视频的直觉:我们很少会从头到尾盯着每一帧看,而是先扫一眼进度条建立初步的故事线,然后根据逻辑推断线索可能出现的位置,最后精准"空降"并仔细观察。VideoSeek 正是模仿了这种"按需搜寻"的行为,它不再穷举解析每一帧,而是利用视频的逻辑流(Video Logic Flow)主动寻找关键证据。

-
代码仓库: https://github.com/jylins/videoseek (已开源)
为什么我们需要"会找重点"的智能体?
在长视频理解任务中,比如经典的 LVBench 基准测试,研究人员发现了一个扎心的事实:超过 80% 的问题其实只需要视频中不到 3% 的内容就能回答。这意味着,如果我们对全片进行 0.2 到 2 FPS 的密集采样,其实是在处理海量的冗余信息。
现有的视频智能体(Video Agents)虽然引入了推理机制,但大多仍依赖于昂贵的预处理,将视频转化为长文档或结构化存储。这在处理小时级视频时,存储和计算成本会迅速失控。VideoSeek 的核心动机就是打破这种"暴力美学",通过构建一个轻量级的多粒度工具箱,让模型学会在长时程对话中,通过不断地"思考-行动-观察(Think-Act-Observe)"循环来高效获取信息。
方法详解:三级跳式的"搜寻"艺术
VideoSeek 的工作流程可以被看作是一个动态的决策过程。它将视频理解定义为一个概率建模问题,目标是预测一个推理轨迹 和最终答案
。
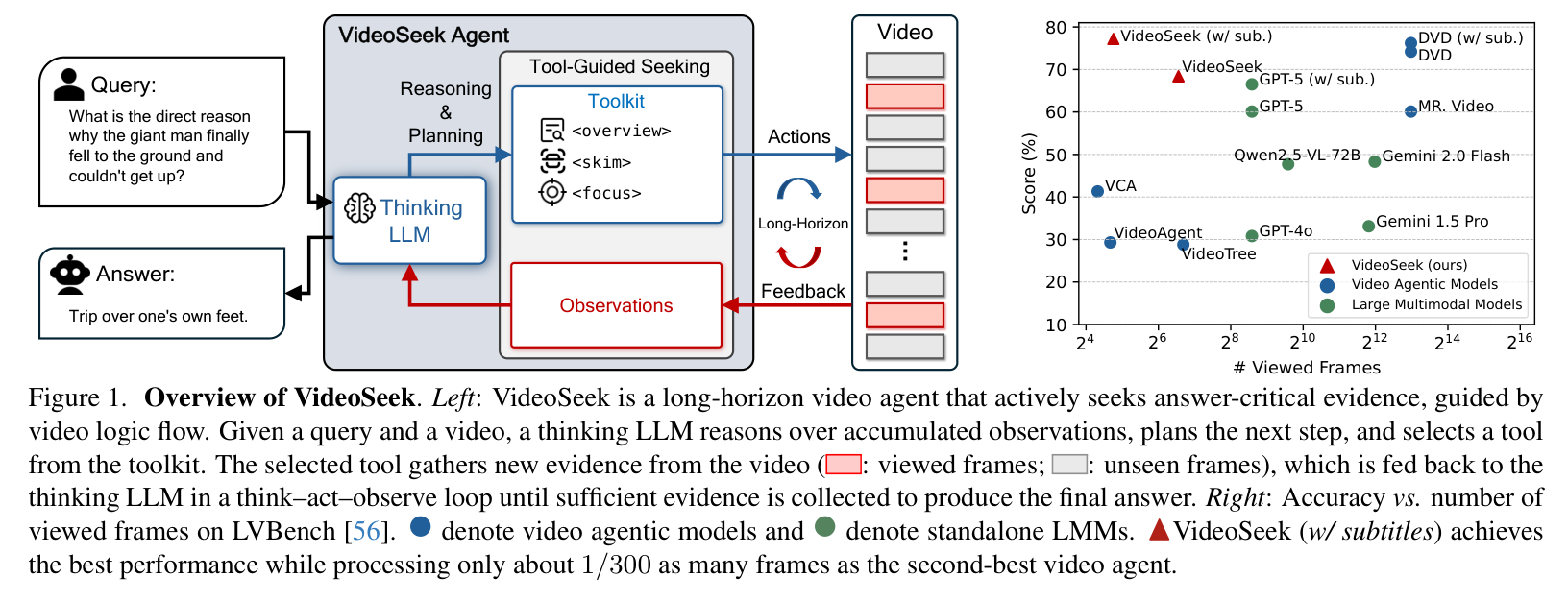
VideoSeek 整体架构与性能对比
1. 核心公式与逻辑流
模型的目标是最大化条件概率:
这里, 代表了由"思考-行动-观察"组成的三元组序列
。智能体每一步都会根据之前的观察结果
,通过内部推理
来规划下一步的行动
。这种设计的精妙之处在于,它将"看视频"变成了一个主动的探索过程,而不是被动的接受。
2. 多粒度工具箱(Toolkit)
这是 VideoSeek 能够实现极致能效比的关键。它设计了三个互补的工具,模拟人类从"粗看"到"精看"的过程:
-
<overview>(全局概览) :这是智能体的"第一眼"。它会均匀采样帧(
-
<skim>(区间扫描) :当智能体锁定某个可能存在线索的较长片段(通常大于 -
<focus>(精细观察):这是最后的"放大镜"。它会以 1 FPS 的高帧率对极短的片段进行深度解析。只有当模型需要确认诸如"演员领带的颜色"或"背景墙上的文字"这类微小细节时,才会动用这个高能耗工具。
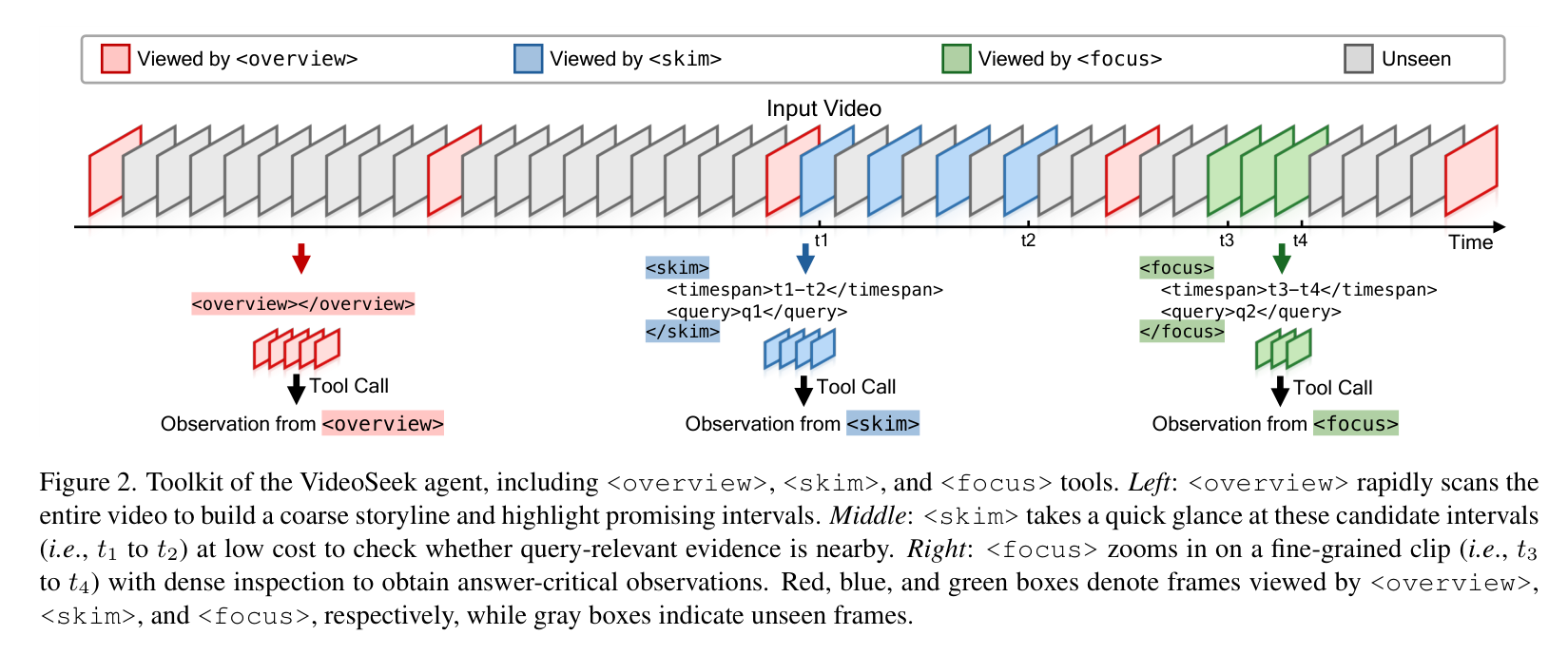
VideoSeek 工具箱示意图
3. 智能体工作流:ReAct 范式
如 Algorithm 1 所示,VideoSeek 采用了一个典型的 ReAct 风格工作流。智能体(由 GPT-5 担任"大脑")在每一轮中执行以下步骤:
-
输入(Input) :用户查询
-
思考(Thought):分析当前已有的信息是否足以回答问题,评估不确定性。
-
行动(Action):如果信息不足,决定调用哪个工具,并指定具体的时间范围。
-
观察(Observation) :工具返回视觉描述,并将其更新到
-
输出(Output) :最终的预测答案

VideoSeek 算法伪代码
实验结果:以一当百的效率
研究团队在四个极具挑战性的榜单上测试了 VideoSeek。
1. 惊人的帧数压缩比
在 LVBench 测试中,VideoSeek 在配合字幕时表现惊人:仅处理 27.2 帧 视觉信息,便达到了 76.7% 的准确率。相比之下,性能接近的 DVD 智能体需处理 8074 帧。VideoSeek 仅用约 1/300 的帧数资源,便在性能上实现了反超(提升 0.7% 并大幅节省计算),这为长视频理解的低成本部署提供了可能。
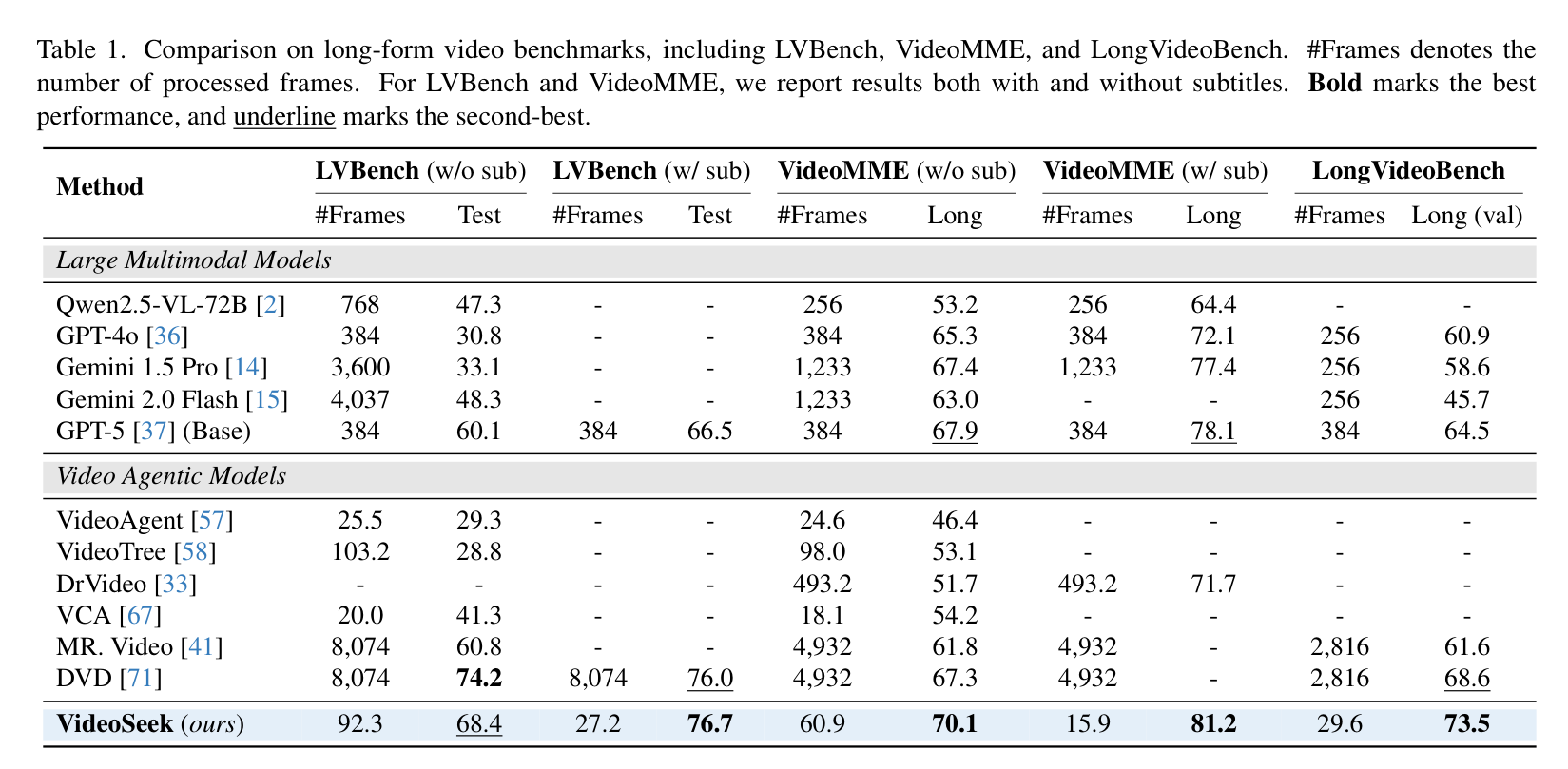
长视频基准测试对比
2. 对基座模型的显著提升
即便使用相同的底层模型 GPT-5,VideoSeek 框架带来的增益也非常可观。在 LVBench 上,它比直接进行 384 帧均匀采样的 GPT-5 基础模型高出了 10.2 个百分点。在 Video-MME 榜单上,它同样以 81.2% 的高分刷新了纪录。
3. 复杂逻辑推理能力
在专门测试复杂推理的 Video-Holmes 榜单上,VideoSeek 展现了极强的"侦探"潜质。该榜单包含社会推理(SR)、因果推断(TCI)等七个维度。VideoSeek 以 47.3% 的总分位居榜首,超越了包括 Gemini 1.5 Pro 和 GPT-4o 在内的众多强劲对手。
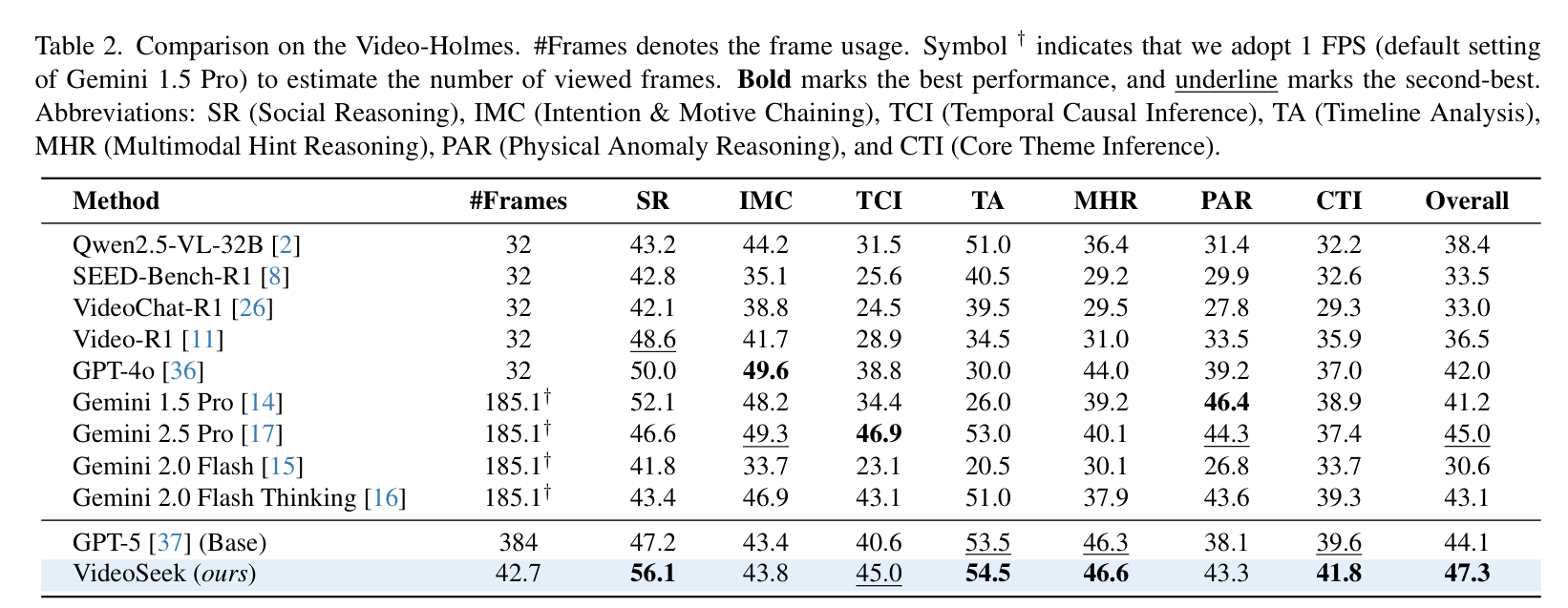
Video-Holmes 复杂推理测试对比
案例演示:它是如何"破案"的?
为了更直观地理解它的工作方式,我们可以看一个 LVBench 中的真实案例。问题是:"当影后上台时发生了什么?"
智能体的第一反应是调用 <overview> 确定颁奖典礼发生的时间点(定位在 4448.4s 附近)。接着,它并没有盲目猜测,而是先用 <focus> 看了下那个时间点,发现没看到明显事故。随后它意识到可能发生在上台的瞬间,于是调用 <skim> 扫描了 4440s 到 4480s 的区间。最终,它观察到演员在 4462.8s 处有调整裙子后部的动作,结合上下文逻辑,从而自信地得出答案:她的裙子破了。这种层层递进的推理,完美复刻了人类的认知路径。

VideoSeek 案例分析
写在最后
VideoSeek 的成功给了我们一个很重要的启示:在多模态理解中,"推理能力"和"观察策略"同样重要。当模型拥有了像人一样的逻辑推断能力时,它就不再需要海量的数据输入。
我个人非常欣赏作者对"逻辑流"的洞察。实验表明,当视频配有字幕时,VideoSeek 的效率会进一步飙升。这是因为字幕本身就包含了显式的逻辑线索,帮助智能体更快地完成定位。这种对多模态信息的有机整合,而非简单的堆砌,才是未来视频 AI 发展的正确方向。
目前该项目已经在 GitHub 上开源,虽然核心"大脑"目前依赖于闭源的高级 LLM,但其工具箱的设计和 Prompt 策略对于想要在本地部署视频智能体的开发者来说,具有极高的借鉴价值。

入群加好友(v:xiao-ma-baoli),请备注你感兴趣的技术方向