当前环境下AI数据中心对于存储的需求近乎贪婪,而且是几乎无休止的需求。
在大家的固有印象中,数据中心的内存标配是DDR,而高性能AI训练的标配是HBM高带宽内存。
然而,在DesignCon 2026的现场,Cadence的Frank Ferro抛出了一个极具颠覆性的观点:LPDDR6正在杀入数据中心,成为AI推理甚至部分训练场景的黑马。
这听起来似乎有些反直觉------毕竟,LPDDR通常是手机和平板的御用内存,主打省电;而数据中心追求的是极致性能,不计功耗。但当你看完这份来自Cadence的深度技术分析,你会发现:在生成式AI的浪潮下,数据中心的架构正在发生剧变,而LPDDR6恰好卡在了性能与成本的sweet spot上。
在2026年DesignCon上,Cadence的Frank Ferro带来了一场干货满满的演讲,主题就是:LPDDR6,正在成为AI数据中心的新选择。今天我们就来深挖这篇演讲中的技术细节,看看LPDDR6到底凭啥能杀进AI数据中心这个高端局。
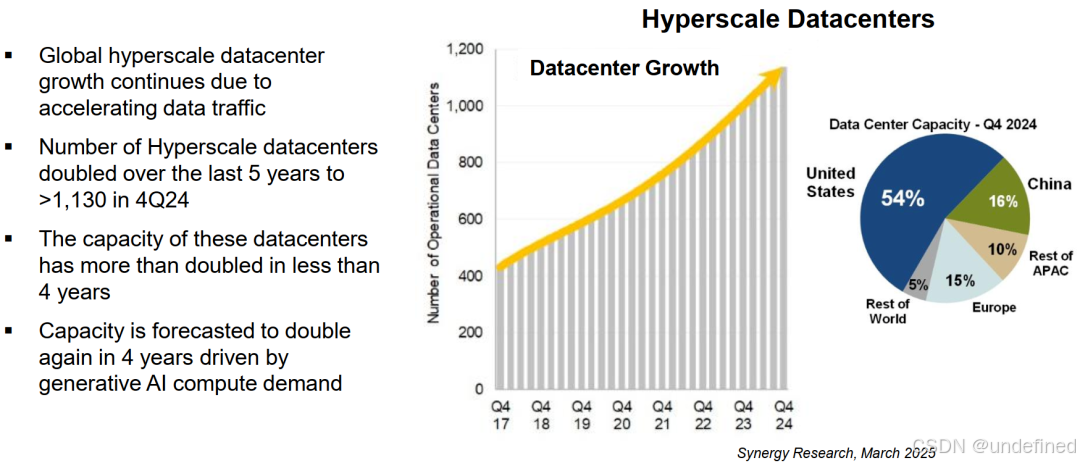
数据中心的容量,美国第一,中国第二。欧洲第三。
过去5年,全球超大规模数据中心的数量翻了一倍,截至2024年第四季度,数量已超过 1,130个。这些数据中心的容量在不到4年的时间里增长了不止一倍,且预测在未来4年内,受生成式AI算力需求的驱动,容量将再次翻倍。
一、算力贪婪需求和内存墙
AI数据中心剧增,背后是物理空间的极度紧缺。在寸土寸金的机房里和机架上,如何在有限的空间里塞进更多的算力,同时不让功耗电力需求暴涨,是每一个架构师和硬件工程师的噩梦。
AI对内存的胃口有多大?
为什么我说AI对内存的需要近乎贪婪呢?我们先看几组数据,感受一下AI内存需求的野蛮增长:
GPT-3:1750亿参数
GPT-4:1.8万亿参数
模型规模两年增长 410倍,相比之下,内存硬件的容量在过去两年里仅增长了 2倍。
这意味着什么?意味着你即使有钱买H100、H200,内存带宽和容量也可能成为训练的瓶颈。更别提推理阶段,部署一个千亿参数的模型,光是把参数加载进内存,就已经让DDR5系统毫无招架之势。对于热门的大模型,最小的内存需求如下,注意纵轴单位是大B, 而不是小b. FP16下,DeepSeek R1或LLaMA 3.3级别的模型,最低内存需求已经超过了传统DDR5系统单节点能提供的上限。
这种巨大的剪刀差,迫使行业必须开发定制化的加速器,通过降低精度Quantization、稀疏性Sparsity等技术来优化性能和内存子系统的效率。目前FP16已成为LLM大语言模型的主流选择,这对内存的带宽提出了极高的要求,但对绝对容量的依赖在某些推理场景下相对灵活。
所以,AI硬件工程师们不得不面对一个现实:内存,正在成为系统性能的新瓶颈。
在AI硬件设计中,内存子系统一直是个很难权衡的活儿。你要带宽,HBM给得起,但价格贵得飞起;你要容量,DDR5 DIMM撑得住,但功耗高、带宽低;你要功耗低,LPDDR可以满足,但以前又只能在手机里跑,容量和可靠性都不够看。
直到LPDDR6的出现,这个不可能三角tradeoff终于有了一个接近完美的解。
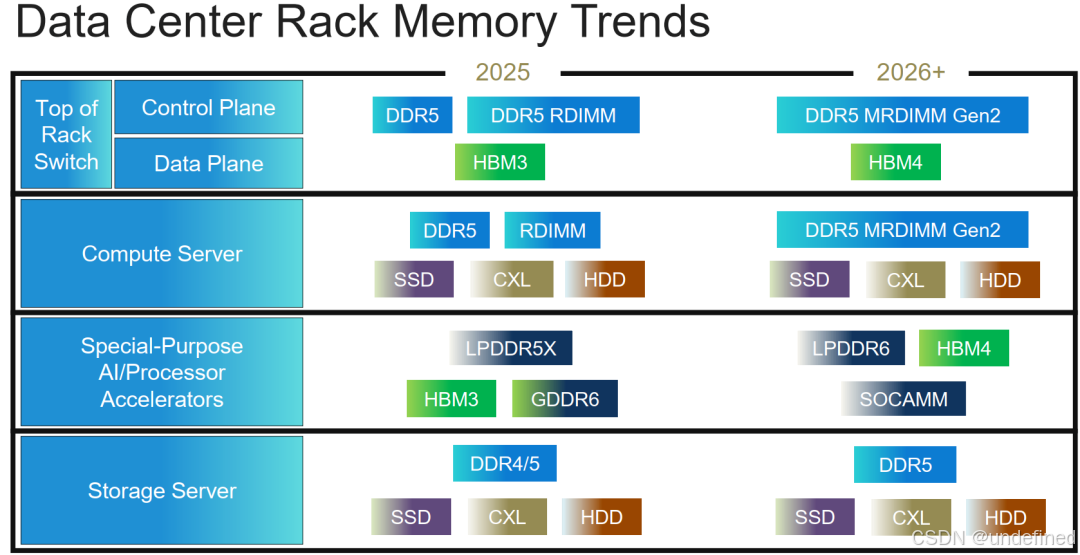
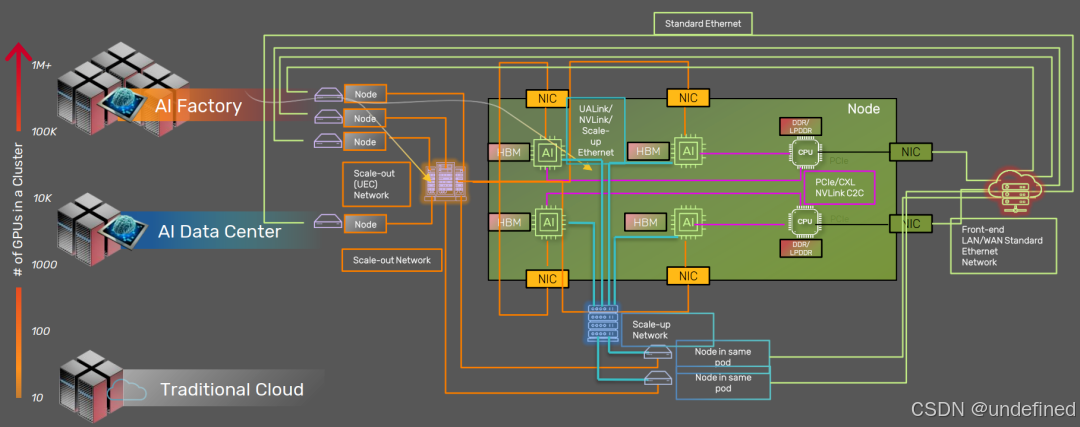
数据中心正在经历一场异构化革命。不再是单一的DDR通吃,而是根据任务类型Training vs Inference和功耗预算,分层部署不同的内存技术。
二、LPDDR6可能是为AI推理量身打造的黄金平衡点
目前主要的存储方案如下,HBM, DDR, GDDR, LPDDR, 以及SSD等。
1-LPDDR6带宽炸裂:691Gbps per device
LPDDR6的单器件带宽达到了 691Gbps,这是什么概念?
--比LPDDR5X提升了约 2倍
--接近初代HBM的带宽水平
--支持双子通道架构(Dual Sub-channel),访问粒度小至 32字节
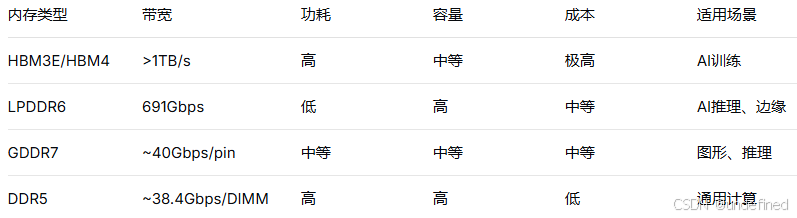
这意味着什么?在AI推理中,尤其是batch size较小、延迟敏感的场景下,LPDDR6可以做到既快又灵活,不像HBM那样大炮打蚊子,不划算;也不像DDR5那样老牛拉破车,干不动。

2-LPDDR6功耗优化:DVFS-LP + 自适应刷新
LPDDR6引入了 动态电压频率缩放DVFS-LP,支持:
--更低的工作电压
--部分自刷新Partial Self Refresh
--主动刷新Active Refresh优化
相比DDR5 RDIMM,LPDDR6的功耗降低了 75% 以上, 这些都是基于Micron案例实际数据。对于动辄成千上万节点的AI数据中心,这意味电费、散热、机架密度的全面优化。

3-LPDDR6容量与可靠性全面优化
AI推理不仅需要快,更需要稳。LPDDR6重点引入了:
首先是PRAC,即Per Row Activation Counting,主要作用是每行激活计数,防止Row Hammer攻击或故障
其次是Carve-out Meta Mode可以为关键任务分配专用内存区域,提高系统可靠性
这两项特性,让LPDDR6不再是"手机内存改个名",而是真正具备数据中心级RAS能力的解决方案。

4-实际案例分析基于Micron + ARM案例
演讲中引用了Micron的一个案例,其方案是DDR5 + x86架构 vs LPDDR5X + ARM架构
LPDDR5X系统在Llama 3 8B模型上的表现非常炸裂,吞吐量提升 5倍,推理延迟降低 80%,并且能效比提升 10%
注意,这还是LPDDR5X,LPDDR6只会更强。但上面的数据足以证明LPDDR6的巨大潜力

三、Cadence的LPDDR6 IP方案设计
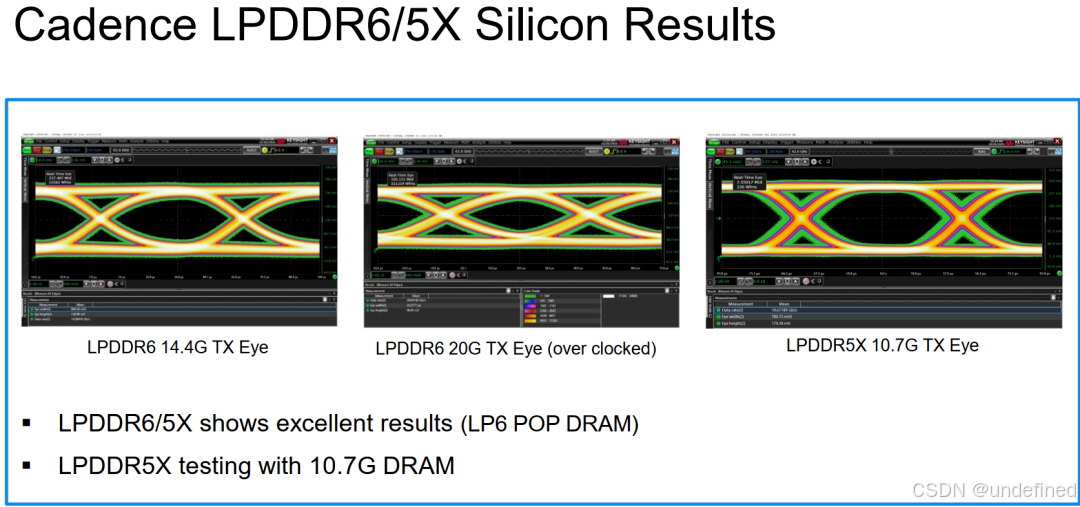
其硬件PHY:14.4Gbps起步,20Gbps可超频
Cadence在LPDDR6标准发布的同时,就推出了 14.4Gbps的LPDDR6 PHY IP。
实测眼图显示:
14.4Gbps TX眼图干净,张开度良好,说明信号质量优异。甚至展示了 20Gbps 的超频眼图,证明了该IP架构具有极大的性能冗余和未来升级潜力。具体来说20Gbps超频状态仍有可用眼宽
LPDDR5X 10.7Gbps RX/TX眼图同样优秀
这说明Cadence的PHY架构设计非常稳健,留足了余量。
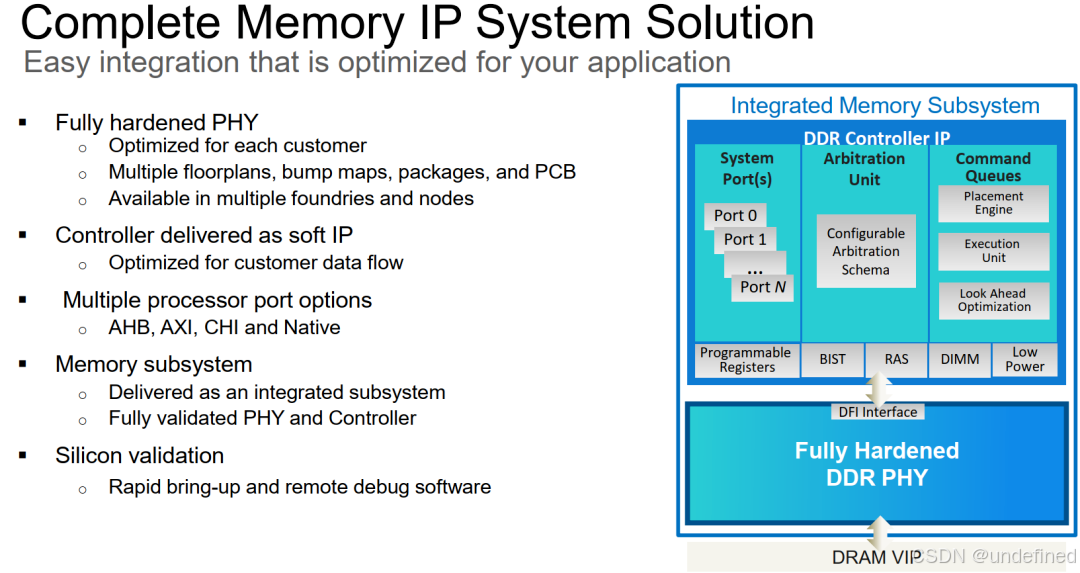
Bring-Up软件是硅后验证的隐藏王牌
Cadence的一大优势是其高效的硅后bring-up软件,能加快验证流程。
首先可以预配置寄存器值,无需SoC固件即可启动,可以独立运行,通过JTAG接口直接读写寄存器。
其次,支持2D眼图扫描、训练步骤调试、暂停/恢复/修改,,让工程师能直观看到每一个数据引脚的信号质量窗口。
最后,可导出配置给SoC固件
演讲中引用了客户反馈:"只用了一个小时,我们就完成了LPDDR接口的训练和BIST测试,大大缩短了产品上市时间。
这种快速bring-up能力,对于AI芯片公司快速迭代应用需求来说,简直是救命稻草。


小结
虽然HBM能提供恐怖的带宽,但其成本和封装难度让很多非头部的AI应用望而却步。LPDDR6的出现,让高性能不再等于天价。对于边缘AI、推荐系统、以及部分大模型推理场景,LPDDR6 SOCAMM方案可能是比HBM更具性价比的选择。
曾经泾渭分明的"手机用LPDDR,电脑用DDR,AI用HBM"的格局,正在被生成式AI的需求打破。LPDDR6可能是那个刚刚好的方案:带宽够高、功耗够低、容量够大、成本可控。LPDDR6,或许就是让高性能AI算力普及到更广阔数据中心的关键拼图。