一、RAG介绍
RAG(Retrieval AUgmented Generation)检索增强生成技术,利用外部文档提升生成结果的质量。为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。可以总结为一个公式:RAG=检索技术+LLM提示。
基本原理: 在生产回答时,先从知识库中检索相关文档,将检索到的文档与原始问题一起输入LLM,LLM基于文档内容生成最终答案。
通用的基础大模型存在一些问题:
- LLM的知识
不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后。 - LLM领域知识是
缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。 - 幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息问题
- 数据安全性
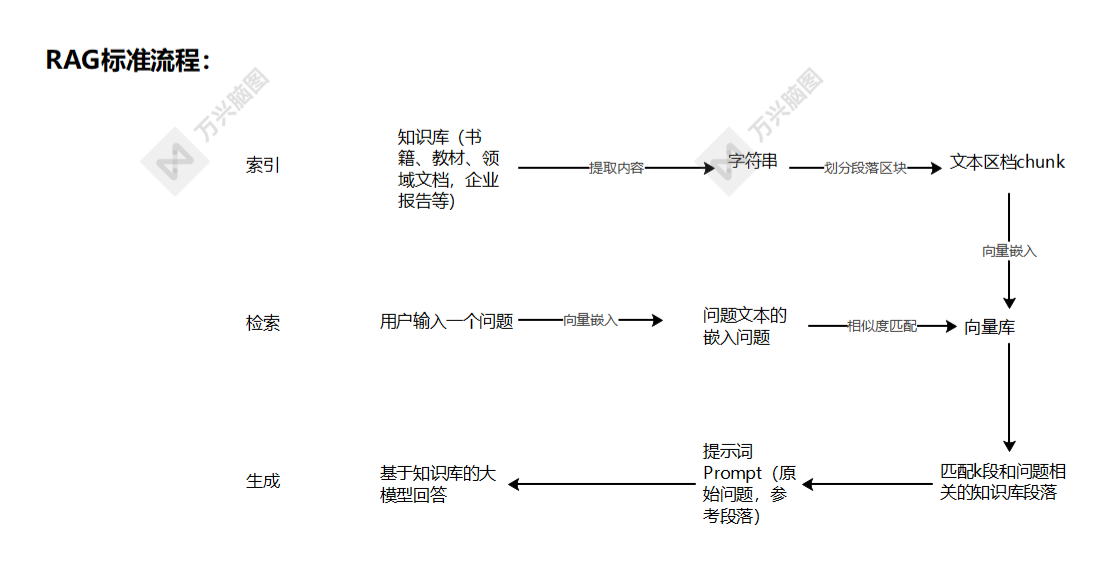
二、RAG标准流程
RAG标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
1.索引阶段: 通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化。
- 加载文件
- 内容提取
- 文本分割,形成chunk
- 文本向量化
- 存向量数据库
2.检索阶段: 用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
- query向量化
- 在文本向量中匹配出与问句向量相似的top_k个。
3.生成阶段: 检索相关文本与原始查询共同构成提示词(Prompt),输入大语言模型,生成精确且具备上下文关联的回答。
- 匹配出的文本作为上下文和问题一起添加到Prompt中
- 提交给LLM生成答案。
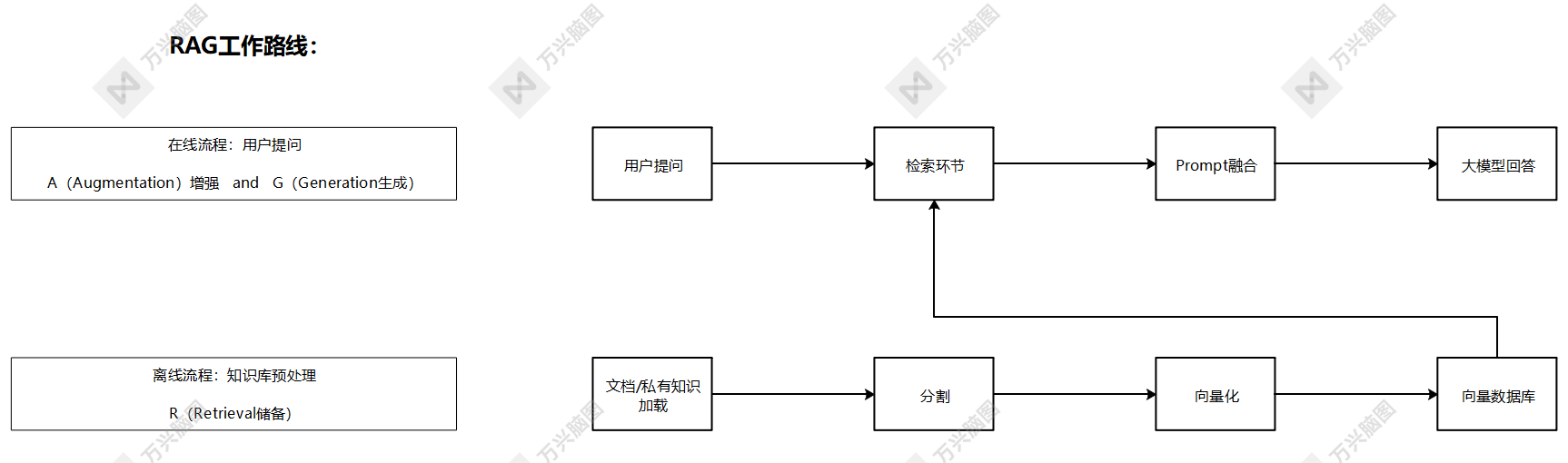
RAG工作分为两条线:
- 离线准备路线
- 在线服务路线
三、知识库构建
1.文档准备
文档预处理建议:
- 清理无关内容(广告、水印)
- 按主题分类整理
- 文档命名规范(含关键信息)
2.文档切片: 为了适应大模型语言模型的上下文昌都限制,并提升检索的精确度和效率。
切片方式:
- 按字符切分:固定长度
- 按符号切分:按照句号、换行符、感叹号符
- 按语义分:识别主题变化点智能切分
一般选择方式: 按照符号和字符长度一块切分,一般200-500字/段,长度太小,上下文不完整,检索不准,长度太大,无关信息过度,干扰判断。
3.文档向量化: 将将切分后的文本进行向量数字化,便于计算问题和文档的相似性。
四、总结
- 模型本质上就是
用户输入,模型给出输出,用户能够做的就是在输入上做功夫。 - RAG就是在向模型提问之前基于已有的知识库或文档内容做检索,确保向模型提问的内容更精确以及包含足够的信息量用以提供给模型。
RAG的核心价值:
- 解决知识实效性问题:大模型的训练数据有
截止时间,RAG可以接入最新文档(如公司财报、政策文件),让模型输出"与时俱进"。 - 降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅
减少编造信息的概率。 - 无需重新训练模型:相比微调(Fine-tuning),RAG只需要更新知识库,成本更低,效率更高。