前言
一、Focal Loss
1.1 Focal Loss介绍
Focal Loss 是专为类别不均衡场景设计的损失函数,在目标检测任务中效果突出。该方法由 Facebook AI Research(FAIR)率先提出,被应用于 RetinaNet 等检测模型,有效缓解了正负样本比例严重失衡的问题。
论文链接:https://arxiv.org/pdf/1708.02002
1.2 相关背景
在目标检测等实际落地场景中,类别失衡是普遍存在的技术难题。图像内绝大多数区域均为背景负样本,前景目标正样本占比极低。传统交叉熵损失会使模型过度偏向学习海量负样本特征,进而忽略稀少的正样本,尤其难以挖掘难区分、弱特征的正样本。Focal Loss 则通过聚焦优化难分类样本,从根源上化解这一缺陷。
传统交叉熵 相关的知识,可以参考这篇博文:https://blog.csdn.net/weixin_46200189/article/details/159720059
1.3 公式定义
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) FL(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
其中:
- F L ( ⋅ ) FL(⋅) FL(⋅)是Focal Loss(聚焦损失), 损失函数的整体表示,用于衡量模型预测与真实标签的误差。
- p t p_t pt是模型对真实类别的预测概率。
- α t α _t αt是类别平衡权重(alpha 因子),用于进一步平衡正负样本的数量差异。
- ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ是难样本聚焦因子(调制系数),其作用是让模型自动聚焦难分样本,压制简单背景样本的影响。
1.3.1 交叉熵损失
Focal Loss 是在二分类交叉熵损失(Binary Cross-Entropy Loss)的基础上改进而来的。标准的二分类交叉熵损失可表示为:
B C E ( p t ) = − log ( p t ) BCE(p_t) = -\log(p_t) BCE(pt)=−log(pt)
其中, p t p_t pt是模型对真实类别的预测概率。
1.3.2 类别平衡权重 α t α _t αt
类别平衡权重 α t α _t αt 用于均衡正负样本对损失的贡献,避免海量负样本主导训练过程。
具体而言:
- 正样本对应的权重为 α t = α α _t=α αt=α。
- 负样本对应的权重为 α t = 1 − α α _t=1-α αt=1−α。
其中 α α α 是取值于 0 , 1 0,1 0,1 的超参数,用于表征正负样本的权重分配比例;在目标检测等正负样本失衡的任务中,通常可将 α α α 设为正负样本的数量反比,以实现类别间的权重平衡。
1.3.3 难样本聚焦因子 ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ
聚焦因子 γ γ γ 是 Focal Loss 的核心创新,用于动态调整模型对易分样本与难分样本的学习权重,其作用由调制项 ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ实现:
- 当样本易分类时,模型对真实类别的预测概率 p t p_t pt趋近于 1,此时 ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ取值极小,大幅降低该样本对总损失的贡献,抑制简单样本主导训练;
- 当样本难分类时, p t p_t pt趋近于 0, ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ 取值显著增大,提升该样本的损失权重,强制模型聚焦难分样本的学习。
聚焦因子 γ γ γ 的默认取值为 2,可根据任务特性灵活调整: γ γ γ越大,模型对难分样本的聚焦程度越强。
1.3.4 落地场景
目标检测:Focal Loss 最初被提出并应用于目标检测领域,典型代表为 RetinaNet 网络。由于目标检测任务中前景目标与背景区域数量差距悬殊,正负样本极度不均衡,该损失函数通过强化对难分样本的学习,有效提升了模型对小目标与复杂目标的检测精度。
其它数据不平衡场景:此外,在其他存在严重类别不均衡的分类任务中,Focal Loss 同样具备良好适用性,例如文本情感分类、医学影像病灶识别与工业缺陷检测等场景。
1.4 论文原图
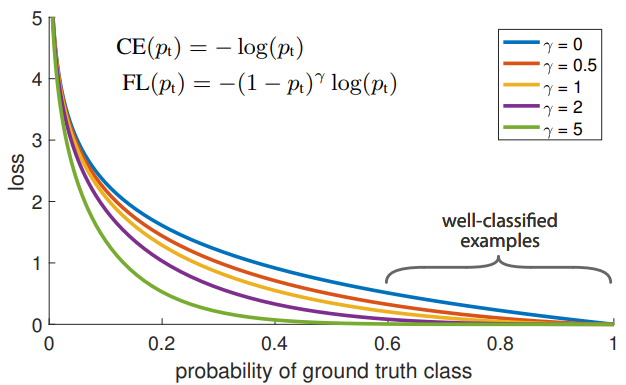
这是 Focal Loss 的核心原理示意图:横轴是模型对真实类别的预测概率 p t p_t pt,纵轴是损失值。 γ = 0 γ=0 γ=0对应标准交叉熵, γ > 0 γ>0 γ>0时加入调制因子 ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ 。对于 p t > 0.5 p_t>0.5 pt>0.5的易分样本, γ γ γ越大,损失被压制得越明显;而 p t p_t pt接近 0 的难分样本,损失基本不受影响。这让模型自动聚焦难分样本,大幅缓解目标检测等任务中的正负样本极度不平衡问题。
1.5 Focal loss代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
# Focal Loss 实现
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
# 计算二分类交叉熵
bce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
# 计算预测概率
p = torch.sigmoid(inputs)
# 计算 p_t
p_t = targets * p + (1 - targets) * (1 - p)
# Focal 核心调制因子
focal_loss = (1 - p_t) ** self.gamma * bce_loss
# 类别平衡 alpha
if self.alpha is not None:
alpha_t = targets * self.alpha + (1 - targets) * (1 - self.alpha)
focal_loss = alpha_t * focal_loss
return focal_loss.mean()
# ==================== main 函数测试 ====================
if __name__ == '__main__':
# 1. 定义损失函数
criterion = FocalLoss(alpha=0.25, gamma=2.0)
# 2. 构造模拟输出(模型预测)
batch_size = 4
outputs = torch.randn(batch_size, 1, 64, 64) # 网络输出 logits
labels = torch.randint(0, 2, (batch_size, 1, 64, 64)).float() # 真实标签
# 3. 计算损失
loss = criterion(outputs, labels)
# 4. 输出结果
print("Focal Loss =", loss.item())输出结果:
python
Focal Loss = 0.17355768382549286二、Dice Loss
2.1 Dice Loss介绍
Dice Loss是深度学习中图像分割任务的核心损失函数之一,核心作用是最大化模型预测掩码与真实标签的重叠度。该损失函数源自Sørensen-Dice相似系数,最早应用于医学影像分割领域,因对类别不平衡场景具有极强鲁棒性,现已广泛应用于各类分割任务,尤其适用于小目标、病灶分割等场景。
论文链接:https://arxiv.org/pdf/1606.04797.pdf(首次将Dice Loss用于医学影像分割的代表性论文)
2.2 相关背景
在图像分割等实际落地场景中,类别不平衡是高频技术难题,尤其在医学影像、遥感图像、工业缺陷检测等领域表现突出。例如,医学影像中肿瘤、病灶等前景区域仅占图像极小比例,绝大多数区域为背景负样本;工业缺陷检测中,缺陷区域往往也只是图像的微小部分。
传统交叉熵损失(CE Loss)采用逐像素独立计算损失的方式,会让模型过度偏向学习海量背景负样本的特征,进而忽略稀少的前景正样本,导致模型分割精度低下、前景区域漏检等问题。Dice Loss通过直接优化预测与标签的重叠度,从根源上缓解类别不平衡带来的缺陷,同时更贴合分割任务的核心评测指标(如Dice系数、mIoU)。
2.3 公式定义
L Dice = 1 − 2 ∑ ( p i t i ) + ϵ ∑ p i + ∑ t i + ϵ \mathcal{L}_{\text{Dice}} = 1 - \frac{2\sum(p_i t_i) + \epsilon}{\sum p_i + \sum t_i + \epsilon} LDice=1−∑pi+∑ti+ϵ2∑(piti)+ϵ
其中:
- L Dice \mathcal{L}_{\text{Dice}} LDice 是Dice Loss(骰子损失),损失函数的整体表示,用于衡量模型分割预测结果与真实标签的误差,取值范围为0,1,损失越小表示分割效果越好。
- p i p_i pi 是模型对第 i i i个像素的预测概率(经sigmoid或softmax激活后,取值范围0,1)。
- t i t_i ti 是第 i i i个像素的真实标签(分割任务中通常为0/1二值标签,0代表背景,1代表前景)。
- ϵ \epsilon ϵ 是平滑项(通常取值为1e-8),核心作用是防止分母为0,同时稳定训练过程,避免因像素总和为0导致的计算异常。
- 分子 2 ∑ ( p i t i ) + ϵ 2\sum(p_i t_i) + \epsilon 2∑(piti)+ϵ 是预测与标签交集的2倍(加平滑项),分母 ∑ p i + ∑ t i + ϵ \sum p_i + \sum t_i + \epsilon ∑pi+∑ti+ϵ 是预测与标签的并集(加平滑项),整体对应Dice系数的计算逻辑。
2.3.1 Dice系数
Dice Loss源自Dice系数(Sørensen-Dice相似系数),该系数是衡量两个集合重叠度的常用指标,也是分割任务中核心的评测指标之一,其公式定义为:
Dice ( X , Y ) = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ \text{Dice}(X,Y) = \frac{2|X \cap Y|}{|X| + |Y|} Dice(X,Y)=∣X∣+∣Y∣2∣X∩Y∣
其中, X X X 代表模型预测掩码(经阈值处理后的二值图像), Y Y Y 代表真实标签掩码, ∣ X ∩ Y ∣ |X \cap Y| ∣X∩Y∣ 是两者的交集(即正确预测的前景像素数量), ∣ X ∣ |X| ∣X∣ 和 ∣ Y ∣ |Y| ∣Y∣ 分别是预测掩码和真实标签掩码的总像素数量。Dice系数取值范围为0,1,系数越接近1,说明预测与真实标签的重叠度越高,分割效果越好。
Dice Loss本质是 1 − Dice系数 1 - \text{Dice系数} 1−Dice系数,通过最小化损失函数,间接最大化Dice系数,实现模型分割精度的提升。
分母计算:预测所有元素求和 + 标签所有元素求和
分子计算:A和B的交集,用点乘,如下图。

2.3.2 平滑项 ϵ \epsilon ϵ
平滑项 ϵ \epsilon ϵ是Dice Loss中不可或缺的组成部分,其核心作用有两点:
- 防止分母为0:当预测掩码和真实标签均为全0(即无前景像素)时, ∑ p i \sum p_i ∑pi 和 ∑ t i \sum t_i ∑ti 均为0,此时分母会变为0,导致计算异常;加入 ϵ \epsilon ϵ后,可确保分母始终大于0,避免训练崩溃。
- 稳定训练过程:在训练初期,模型预测精度较低,可能出现预测与标签几乎无重叠的情况,此时 ϵ \epsilon ϵ可避免损失值出现极端波动,帮助模型平稳收敛。
ϵ \epsilon ϵ的取值通常为1e-8或1e-6,无需过度调参,可根据具体任务的像素精度灵活调整,一般不影响模型最终性能。
2.3.3 核心特性(与交叉熵损失对比)
Dice Loss与传统交叉熵损失(CE Loss)的核心差异的在于损失计算逻辑,其独特特性使其更适配分割任务:
- 全局区域感知:Dice Loss的计算依赖预测与标签的全局像素总和,而非逐像素独立计算,能更好地捕捉前景区域的整体特征,避免局部像素误差对整体分割效果的影响。
- 天然抗类别不平衡:无需额外设置类别权重,即可缓解正负样本比例失衡的问题------由于其聚焦于重叠度,即使前景样本极少,也能通过交集和并集的计算,让前景样本对损失的贡献得到强化,避免被海量背景样本淹没。
- 直接对齐评测指标:训练目标(最小化Dice Loss)与分割任务的核心评测指标(Dice系数)直接相关,相较于交叉熵损失(训练目标与评测指标不一致),能更高效地提升模型的实际分割性能。
2.3.4 落地场景
医学影像分割:这是Dice Loss最核心的应用场景,包括肿瘤分割(如肺癌、肝癌病灶分割)、器官分割(如心脏、肝脏、肾脏分割)、细胞分割(如病理切片细胞计数与分割)、视网膜血管分割等。由于医学影像中前景区域(病灶、器官)占比极低,类别不平衡问题突出,Dice Loss能有效提升前景区域的分割精度,减少漏检和误检。
小目标与缺陷分割 :在工业缺陷检测(如电路板缺陷、金属表面划痕分割)、遥感图像小目标分割(如桥梁、车辆分割)等场景中,目标区域通常仅占图像的5%以下,Dice Loss能聚焦小目标的特征学习,显著提升小目标的分割准确率。
极度类别不平衡场景:除上述场景外,在任何前景样本占比极低(如前景占比<1%)的分割任务中,Dice Loss均具备明显优势,可替代传统交叉熵损失,或与交叉熵损失混合使用,兼顾训练稳定性与分割精度。
Dice Loss二分类代码实现
python
import torch
import torch.nn as nn
class DiceLoss(nn.Module):
def __init__(self, smooth=1e-8, reduction='mean'):
"""
初始化Dice Loss
Args:
smooth: 平滑项,默认1e-8,防止分母为0,稳定训练
reduction: 损失聚合方式,可选'mean'(默认,返回批次平均损失)、'sum'(返回批次总损失)、'none'(返回每个样本的损失)
"""
super(DiceLoss, self).__init__()
self.smooth = smooth
self.reduction = reduction
def forward(self, pred, target):
"""
前向传播计算Dice Loss
Args:
pred: 模型预测概率图,shape为[B, 1, H, W](B为批次大小,H为图像高度,W为图像宽度),需经过sigmoid激活
target: 真实标签,shape与pred一致,值为0(背景)或1(前景),类型为torch.float32
Returns:
loss: 计算得到的Dice Loss
"""
# 将预测图和标签展平为一维(B*H*W, 1),便于计算交集和并集
pred = pred.contiguous().view(-1)
target = target.contiguous().view(-1)
# 计算预测与标签的交集(正确预测的前景像素)
intersection = (pred * target).sum()
# 计算预测与标签的并集
union = pred.sum() + target.sum()
# 计算Dice Loss,加入平滑项避免计算异常
dice_loss = 1 - (2. * intersection + self.smooth) / (union + self.smooth)
# 根据聚合方式处理损失
if self.reduction == 'mean':
return dice_loss.mean()
elif self.reduction == 'sum':
return dice_loss.sum()
else:
return dice_loss
# ===================== 新增 main 函数 =====================
def main():
"""
测试 DiceLoss 的主函数:
1. 随机生成模拟的预测值和标签
2. 初始化损失函数
3. 计算并打印损失
"""
# 设置设备(GPU 优先)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化 Dice Loss
dice_loss = DiceLoss(smooth=1e-8, reduction='mean').to(device)
# 模拟输入:batch=2, channel=1, H=64, W=64
# 预测值:经过 sigmoid 后的概率,范围 [0,1]
pred = torch.sigmoid(torch.randn(2, 1, 64, 64)).to(device)
# 标签:0/1 二值标签,浮点型
target = torch.randint(0, 2, (2, 1, 64, 64)).float().to(device)
# 计算损失
loss = dice_loss(pred, target)
# 打印结果
print("=" * 50)
print(f"设备: {device}")
print(f"预测值 shape: {pred.shape}")
print(f"标签 shape: {target.shape}")
print(f"Dice Loss: {loss.item():.6f}")
print("=" * 50)
if __name__ == "__main__":
# 运行测试
main()输出结果:
python
==================================================
设备: cuda
预测值 shape: torch.Size([2, 1, 64, 64])
标签 shape: torch.Size([2, 1, 64, 64])
Dice Loss: 0.499566
==================================================三、Focal Loss + Dice Loss 组合损失函数
Focal Loss擅长解决类别不平衡场景下的难样本挖掘问题,Dice Loss擅长优化分割任务的重叠度的精度,两者互补性极强。将两者结合形成混合损失函数,可兼顾训练稳定性、难样本学习与分割精度,是当前图像分割(尤其医学影像、小目标分割)领域的工业级标配方案。混合损失通过加权融合两种损失的优势,既避免了Dice Loss训练不稳定的缺陷,又弥补了Focal Loss对分割重叠度优化不足的问题,让模型在类别不平衡、难样本较多的场景中,同时实现精准分割与稳定收敛。
3.1 混合损失公式定义
混合损失的核心是通过超参数α调节两种损失的权重,公式定义如下:
L total = α ⋅ FL ( p t ) + ( 1 − α ) ⋅ L Dice \mathcal{L}{\text{total}} = \alpha \cdot \text{FL}(p_t) + (1-\alpha) \cdot \mathcal{L}{\text{Dice}} Ltotal=α⋅FL(pt)+(1−α)⋅LDice
其中:
- L total \mathcal{L}_{\text{total}} Ltotal 是最终的混合损失,用于模型训练的总损失计算,取值范围为0,1,损失越小表示模型性能越好。
- α \alpha α 是权重超参数(取值范围0,1),用于调节Focal Loss与Dice Loss的贡献比例,核心作用是平衡训练稳定性与分割精度。
- FL ( p t ) \text{FL}(p_t) FL(pt) 是Focal Loss(聚焦损失),公式为 FL ( p t ) = − α t ( 1 − p t ) γ log ( p t ) \text{FL}(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t) FL(pt)=−αt(1−pt)γlog(pt),负责挖掘难样本、缓解类别不平衡。
- L Dice \mathcal{L}_{\text{Dice}} LDice 是Dice Loss(骰子损失),负责优化预测与标签的重叠度,提升分割精度。
3.2 超参数α的取值建议
超参数α的取值直接影响混合损失的效果,需根据具体任务场景灵活调整,核心原则是"平衡稳定性与精度",常用取值范围及适用场景如下:
- α = 0.5~0.75(最常用):适用于大多数分割场景(如医学影像、工业缺陷分割),既能通过Focal Loss保证训练稳定、挖掘难样本,又能通过Dice Loss提升分割重叠度,实现精度与稳定性的兼顾。
- α > 0.75:适用于难样本极多、训练极易不稳定的场景(如小目标密集分割、低对比度影像分割),增大Focal Loss的权重,强化难样本学习,避免模型训练崩溃。
- α < 0.5:适用于分割精度要求极高、难样本较少的场景(如高清晰度影像分割、前景占比相对均衡的场景),增大Dice Loss的权重,重点优化分割重叠度,进一步提升精度。
补充说明:Focal Loss中的 γ γ γ(聚焦因子)可默认取2,无需额外调参;Dice Loss中的ε(平滑项)可默认取1e-8,确保计算稳定。
3.3 核心优势
- 兼顾稳定性与精度:解决了Dice Loss训练初期不稳定、易陷入局部最优的缺陷,同时弥补了Focal Loss对分割重叠度优化不足的问题,训练过程平稳且最终分割精度更高。
- 强抗类别不平衡:Focal Loss的难样本聚焦因子与Dice Loss的重叠度优化逻辑协同作用,既能压制海量简单背景样本的干扰,又能强化前景样本(尤其是小目标、难样本)的学习,适用于各类不平衡分割场景。
- 适配性广:可直接应用于医学影像分割、工业缺陷检测、遥感小目标分割等各类分割任务,无需大幅调整公式结构,仅需微调超参数α即可适配不同场景需求。
3.4 落地场景与实现注意事项
核心落地场景:主要应用于类别不平衡、难样本较多且对分割精度要求高的场景,例如:医学影像肿瘤/病灶分割、工业微小缺陷检测、遥感图像小目标分割、低对比度影像分割等。
实现注意事项:
- 损失计算顺序:需先分别计算Focal Loss与Dice Loss,再按权重 α α α融合,避免直接混合计算导致的梯度异常。
- 梯度归一化:混合损失的梯度可能存在尺度差异,建议在反向传播前对梯度进行归一化处理,避免梯度爆炸或梯度消失。
- 超参数调优:α的取值需结合具体数据集调试,可通过网格搜索(如α取0.5、0.6、0.7、0.8)选择最优值,无需过度复杂调参。
3.5 Focal Loss + Dice Loss组合代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class DiceLoss(nn.Module):
def __init__(self, smooth=1e-8):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, pred, target):
pred = pred.contiguous().view(-1)
target = target.contiguous().view(-1)
intersection = (pred * target).sum()
union = pred.sum() + target.sum()
dice = (2. * intersection + self.smooth) / (union + self.smooth)
return 1 - dice
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, pred, target):
pred = pred.contiguous().view(-1)
target = target.contiguous().view(-1)
# 标准二分类Focal Loss
bce_loss = F.binary_cross_entropy(pred, target, reduction='none')
p_t = pred * target + (1 - pred) * (1 - target)
focal = self.alpha * (1 - p_t) ** self.gamma
loss = focal * bce_loss
return loss.mean()
class DiceFocalLoss(nn.Module):
def __init__(self, lambda_dice=1.0, lambda_focal=1.0, smooth=1e-8, alpha=0.25, gamma=2.0):
"""
Dice Loss + Focal Loss 组合损失函数
Args:
lambda_dice: Dice损失权重
lambda_focal: Focal损失权重
smooth: Dice平滑系数
alpha: Focal损失平衡因子
gamma: Focal损失聚焦因子
"""
super(DiceFocalLoss, self).__init__()
self.dice = DiceLoss(smooth)
self.focal = FocalLoss(alpha, gamma)
self.lambda_dice = lambda_dice
self.lambda_focal = lambda_focal
def forward(self, pred, target):
dice_loss = self.dice(pred, target)
focal_loss = self.focal(pred, target)
total_loss = self.lambda_dice * dice_loss + self.lambda_focal * focal_loss
return total_loss, dice_loss, focal_loss # 返回总损失+各分项,方便监控
# ===================== main 测试函数 =====================
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化组合损失
criterion = DiceFocalLoss(lambda_dice=1.0, lambda_focal=1.0).to(device)
# 模拟分割任务输入 (B, C, H, W)
batch_size = 2
pred = torch.sigmoid(torch.randn(batch_size, 1, 64, 64)).to(device) # 预测概率
target = torch.randint(0, 2, (batch_size, 1, 64, 64)).float().to(device) # 标签
# 计算损失
total_loss, dice_loss, focal_loss = criterion(pred, target)
# 打印结果
print("=" * 60)
print(f"设备: {device}")
print(f"Dice Loss: {dice_loss.item():.6f}")
print(f"Focal Loss: {focal_loss.item():.6f}")
print(f"Total DiceFocal Loss: {total_loss.item():.6f}")
print("=" * 60)
if __name__ == "__main__":
main()输出结果:
python
============================================================
设备: cuda
Dice Loss: 0.501617
Focal Loss: 0.088872
Total DiceFocal Loss: 0.590489
============================================================