1. 为什么 GPT、Llama、 Qwen 这三条线特别重要?
1.1 它们基本覆盖了当下大语言模型面试里的核心脉络
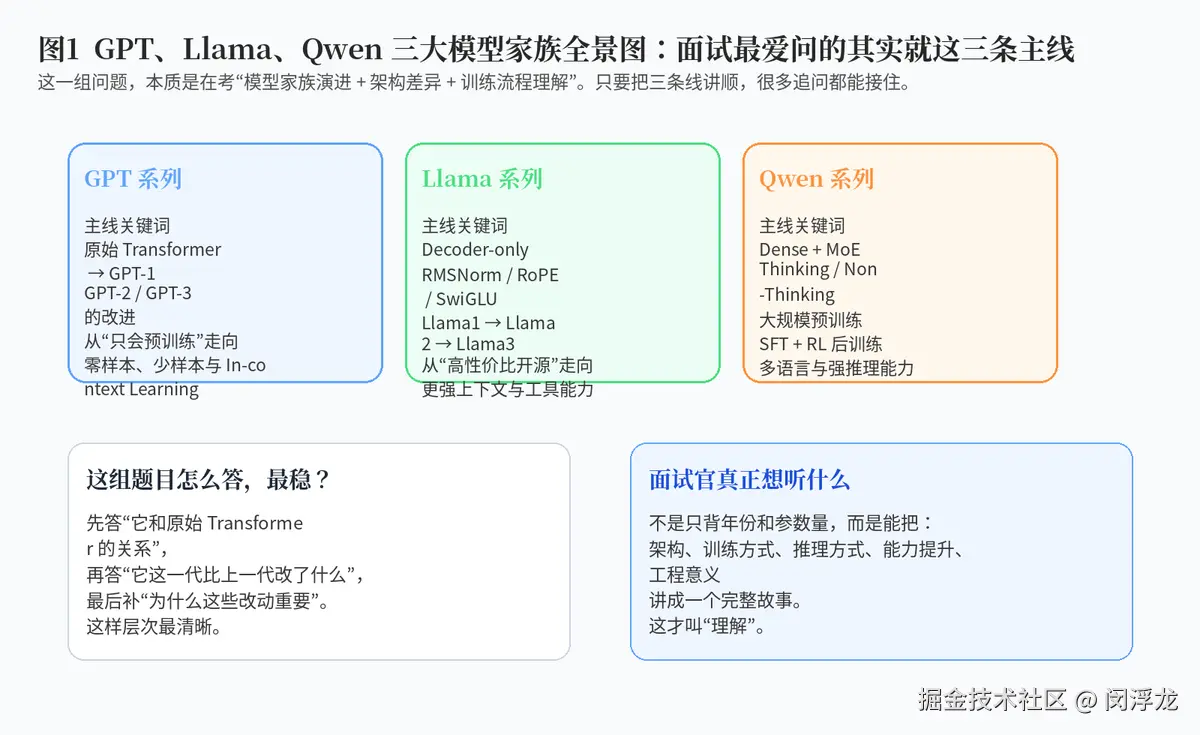
如果说 Transformer 是大模型世界的祖师爷,那么 GPT、Llama、Qwen 可以理解成三条最常被问、也最能体现理解深度的主线。GPT 代表"从原始语言建模走向大模型时代"的经典路线;Llama 代表"开源高性价比大模型如何把 Transformer 做得更适合实际训练与推理";Qwen 则代表"新一代模型如何把多语言、推理模式和后训练体系做得更统一"。
所以,面试里一旦问到模型家族,不要只背参数量。更好的做法,是围绕" 架构 怎么变、训练怎么变、能力为什么变强"这三个层次来回答。
2. GPT 系列
2.1 GPT-1 与原始 Transformer 有什么区别?
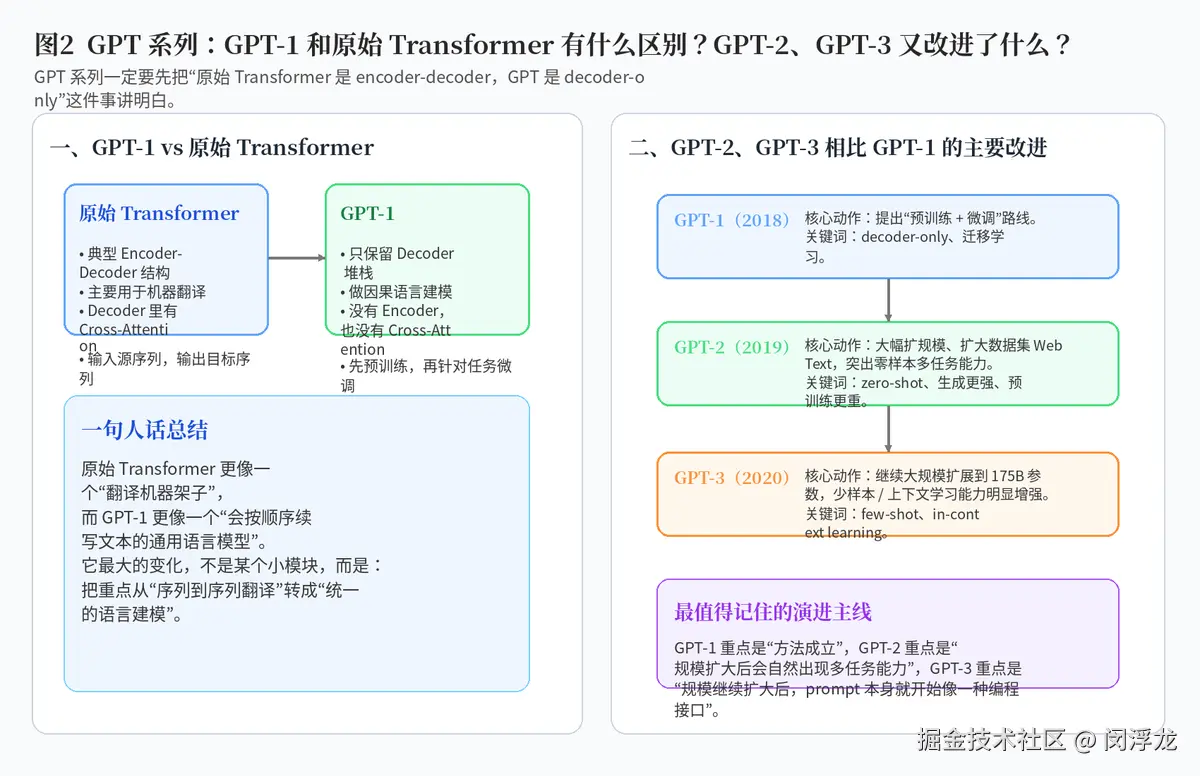
原始 Transformer 是为机器翻译这类序列到序列任务设计的,核心是 Encoder-Decoder 架构。输入一段源语言文本,通过 Encoder 编成中间表示,再让 Decoder 结合这些表示去生成目标语言文本。所以它天然有 Cross-Attention,因为解码时需要"看见"编码器输出。
而 GPT-1 则做了一次非常关键的"取舍":它只保留 Decoder 堆栈,让模型专心做一件事------根据前文预测后文。也就是说,GPT-1 的重点不是翻译,而是通用语言建模。
你可以把它理解成:原始 Transformer 更像一套适合翻译任务的双塔工作流,而 GPT-1 更像一个统一的"续写机器"。它先在大规模无标注文本上预训练,再针对具体任务做微调,这就是后来非常经典的"预训练 + 下游适配"路线。
2.2 这道题面试里最该答出的关键词
第一,GPT-1 是 Decoder-only;第二,它做的是因果语言建模;第三,它删除了原始 Transformer 中面向 Encoder-Decoder 的那部分设计;第四,它把重点从"特定 seq2seq 任务"转到了"通用语言建模底座"。
2.3 GPT-2、GPT-3 相比 GPT-1 的主要改进
GPT-2 最大的变化,并不是架构上彻底换了一套,而是把"规模化预训练"这条路线推得更远。它用了更大的数据集、更大的模型规模,并展示出非常有标志性的零样本多任务能力。也就是说,不重新微调参数,只通过输入不同提示,模型就能表现出翻译、摘要、问答等能力。
GPT-3 则是在这条路上继续大幅放大规模,把参数扩展到 175B,并把 few-shot 和 in-context learning 推到了更醒目的位置。所谓 in-context learning,本质上就是:把几个示例放进 prompt 里,模型就能在当前上下文中"学会"任务格式,而不需要显式重新训练。
如果用一句话概括 GPT 三代演进:GPT-1 证明了"预训练 + 微调"可行;GPT-2 证明了"规模变大以后,多任务能力会自然涌现";GPT-3 进一步证明了"prompt 本身可以变成一种新型接口"。
3. Llama 系列
3.1 Llama 系列和原始 Transformer 架构的差异
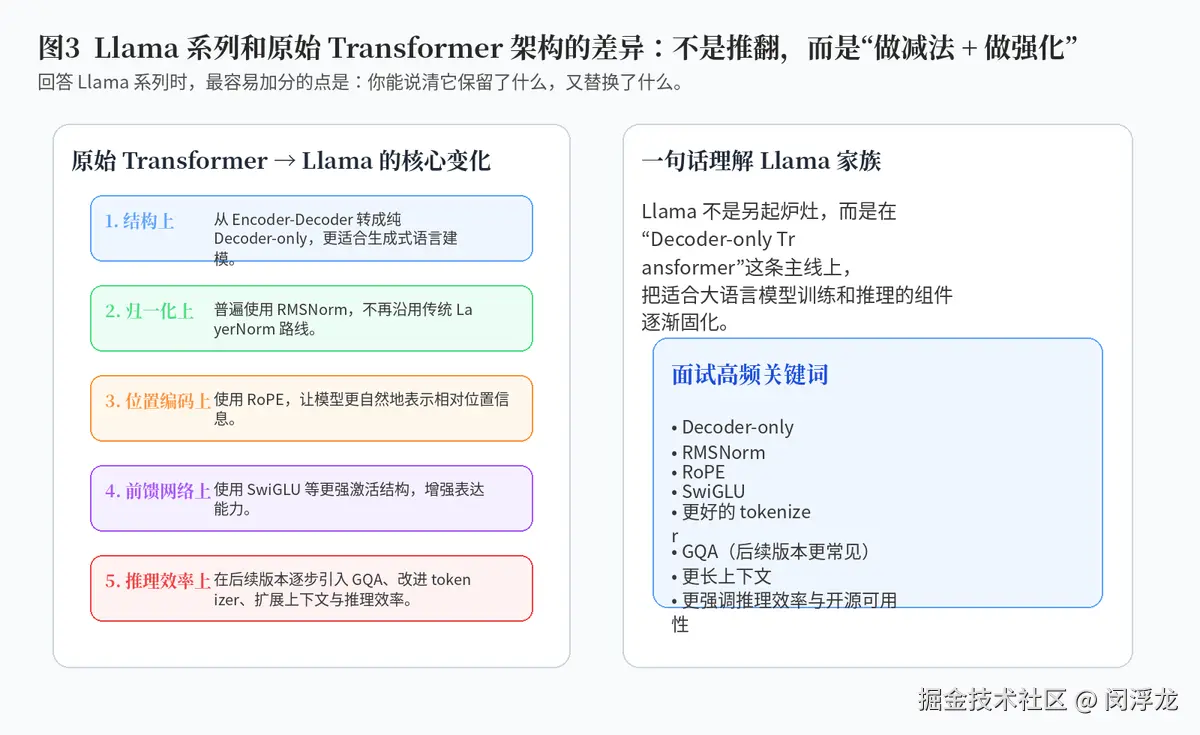
Llama 这条线,本质上还是建立在 Decoder-only Transformer 的主干之上,但它在一些关键组件上做了更适合大语言模型的选择。比如,在归一化上更常见地使用 RMSNorm;在位置编码上用 RoPE;在前馈网络上使用更强的门控激活结构,如 SwiGLU。
这些改动看似不如"从 Encoder-Decoder 变成 Decoder-only"那样大,但它们的意义非常现实:训练更稳、表达更强、推理更合适、上下文建模更自然。
所以面试时不要把 Llama 讲成"完全新模型"。更准确的说法是:Llama 是在 GPT 这类 decoder-only 路线之上,进一步把适合大模型训练和推理的一整套组件逐步标准化。
3.2 Llama2、Llama3 和 Llama1 的差别
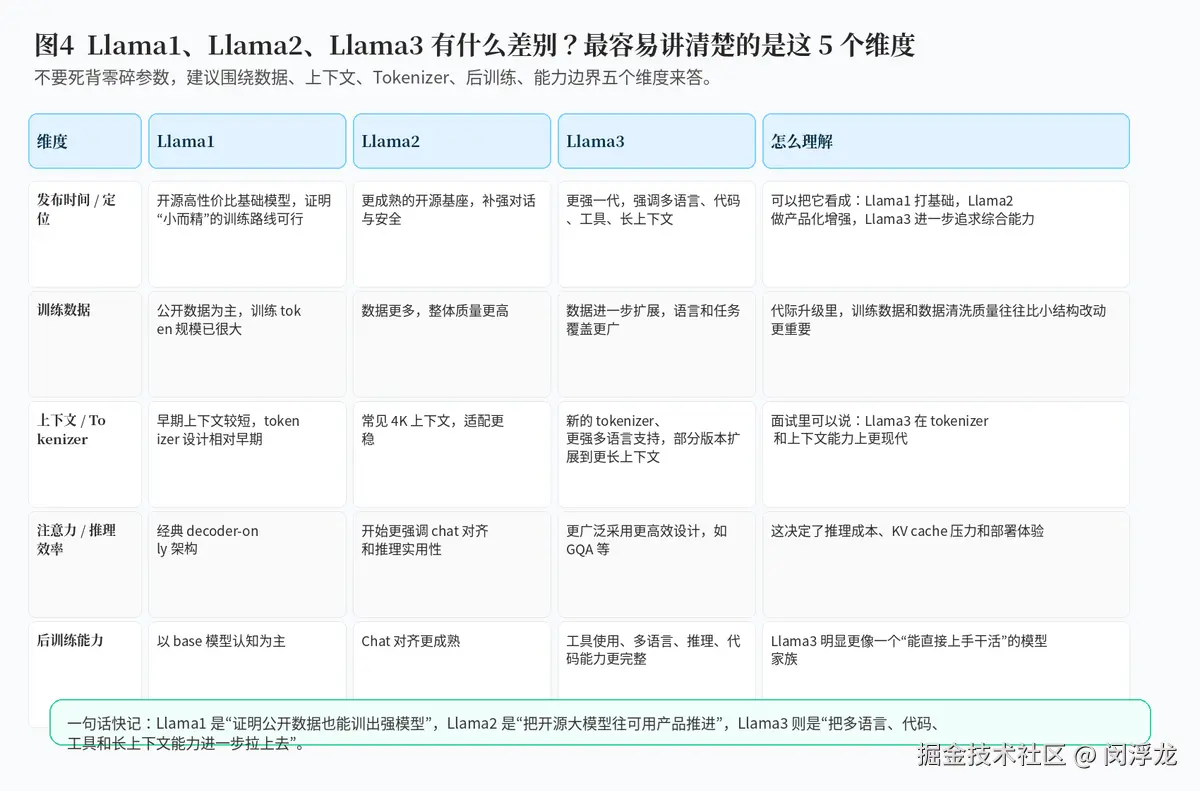
Llama1 的意义,在于它用公开可得数据训练出了非常强的基础模型,证明了"高质量数据 + 合理训练策略"足以做出非常有竞争力的开源模型。
Llama2 则更进一步走向成熟:数据更多、上下文更长,且有更完整的聊天对齐版本,更适合直接拿来做对话类应用。它让很多人第一次感受到"开源模型也能比较直接地进入产品场景"。
Llama3 则继续强化几个方向:更现代的 tokenizer、更强的多语言与代码能力、更好的后训练体系、以及更长的上下文能力。在很多人的感受里,Llama3 比前两代更像一个"真正完整的基础能力平台",不只是一个开源学术模型。
如果面试官追问"到底怎么答差别",你最稳的组织方式是:从训练数据、上下文长度、tokenizer、后训练和推理效率五个维度来比较。
4. Qwen 系列
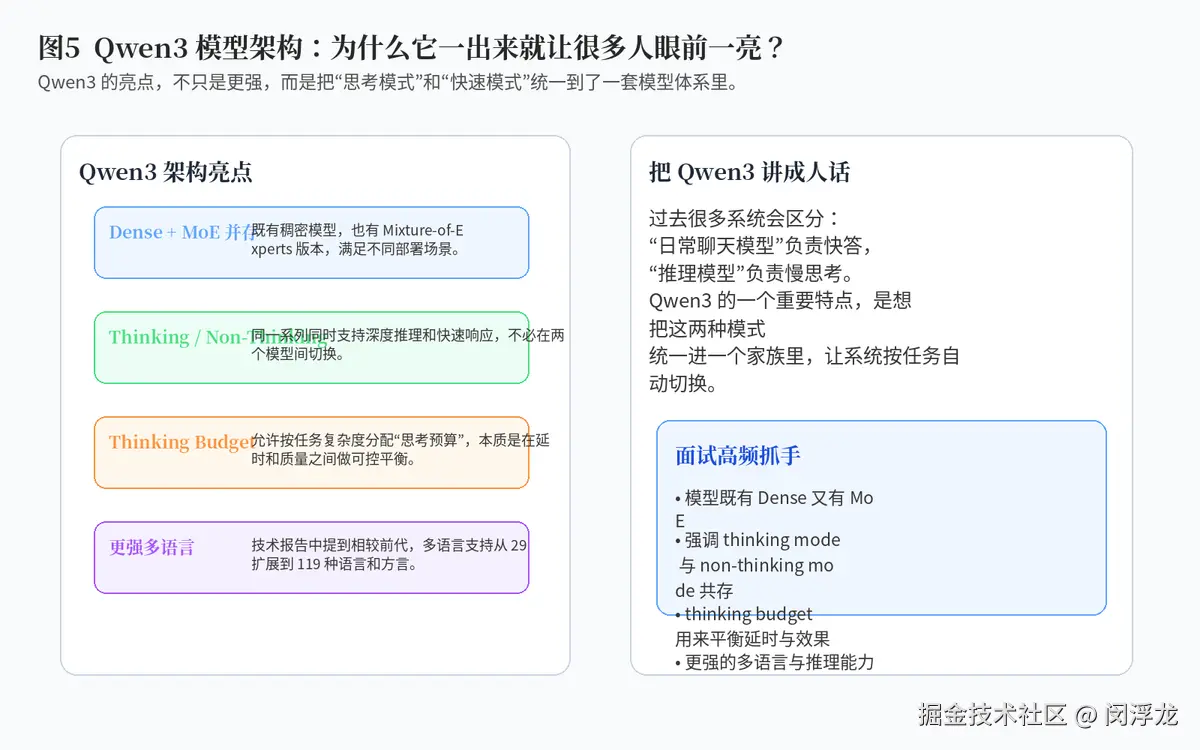
4.1 Qwen3 模型架构
Qwen3 的一个鲜明特点,是它不只是一串参数更大的模型,而是试图把不同使用模式统一进同一个家族。根据官方技术报告,Qwen3 既有 Dense 模型,也有 MoE 模型,并且强调 thinking mode 与 non-thinking mode 共存。
这意味着什么?意味着系统不必总在"快速聊天模型"和"深度推理模型"之间来回切换。同一条模型家族可以根据问题复杂度,在更快回答和更深思考之间动态调节。
官方还提出了 thinking budget 这一概念。你可以把它理解成:给模型一个可控的"思考额度",问题复杂时让它多思考一点,问题简单时让它少思考一点,从而在效果和延时之间做更灵活的平衡。
另外,Qwen3 相比前代在多语言支持上也明显增强。技术报告提到,它把支持的语言和方言从 29 扩展到了 119,这个变化说明它的目标并不只是一个中文或英文强模型,而是一个更全球化的多语言系统。
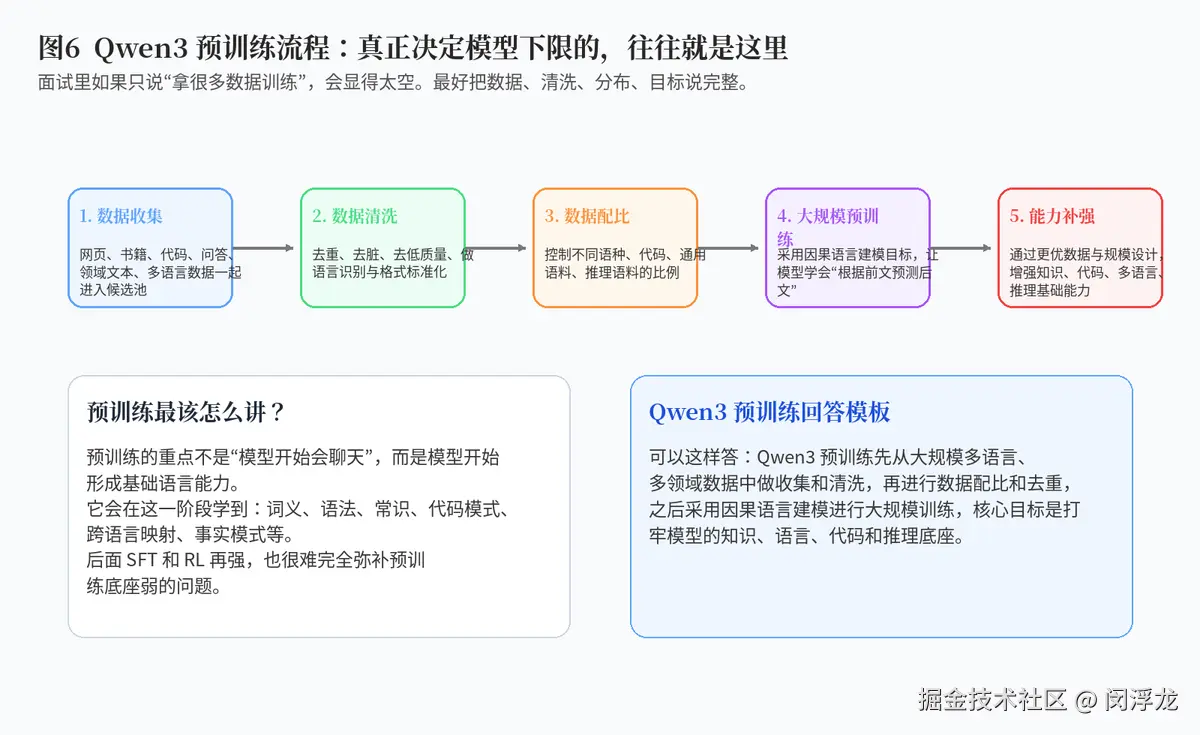
4.2 Qwen3 预训练流程
说到预训练,最忌讳的答法是"就是拿很多数据去训练"。真正好的回答,至少要说出四件事:数据从哪里来、怎么清洗、怎么配比、训练目标是什么。
Qwen3 的预训练可以概括为:先收集大规模、多语种、多领域、多类型的数据,然后做去重、清洗、低质量过滤、格式统一与语言识别,再设计合理的数据配比,最后采用因果语言建模目标做大规模预训练。
这一阶段的重点,不是让模型"会聊天",而是让模型形成扎实的底层能力:语言理解、常识知识、跨语种映射、代码模式、推理基础等。换句话说,预训练更像在打地基。
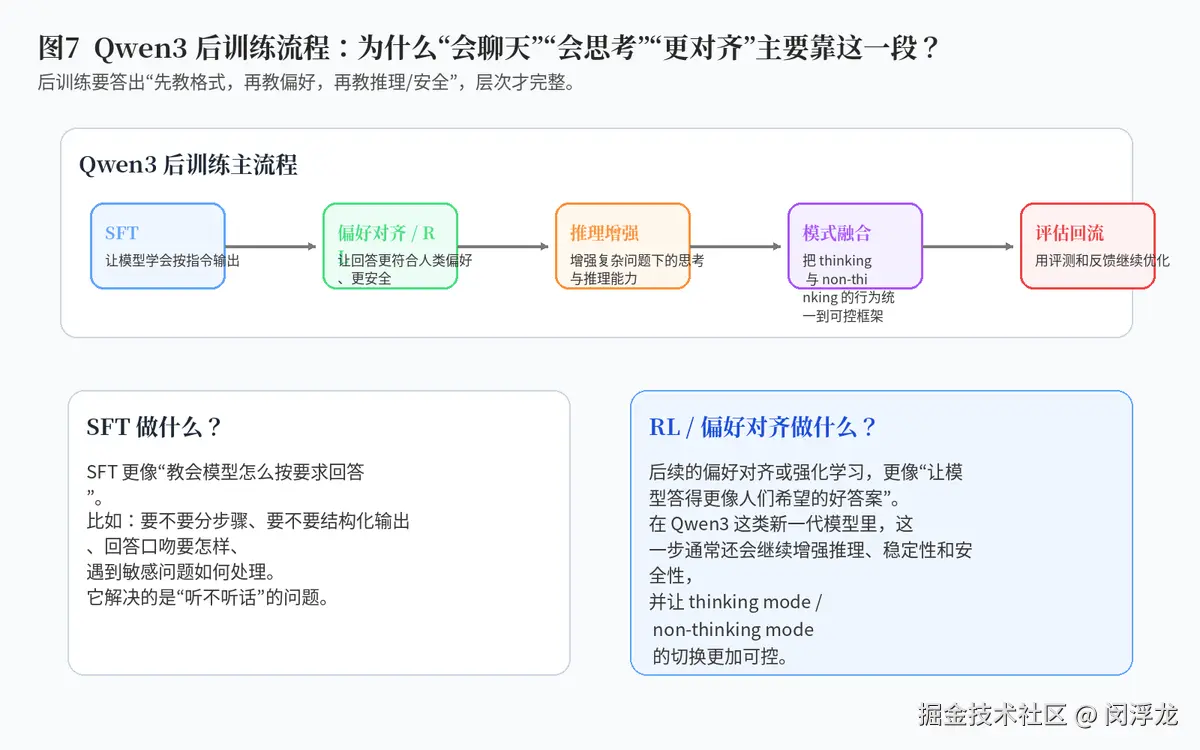
4.3 Qwen3 后训练流程
后训练阶段,重点则从"会不会"转向"好不好用"。一般来说,第一步会是 SFT,也就是监督微调,让模型学会按指令回答、按指定格式输出、遵循更明确的行为边界。
之后会进入偏好对齐或强化学习阶段,目标是让模型回答更符合人类偏好,表现得更安全、更稳定,也更有用。对于 Qwen3 这类强调 thinking mode 的模型,这一步还会承担一个额外任务:把深度推理行为与快速响应行为统一进一套可控框架。
因此,后训练不是简单"让模型更礼貌",而是把模型从一个有能力的底座,变成一个更适合真实交互和产品环境的系统。
5. 面试高频追问,建议这样回答
5.1 GPT-1 与原始 Transformer 有什么区别?
答:原始 Transformer 是 Encoder-Decoder 结构,主要服务于翻译等序列到序列任务;GPT-1 则只保留 Decoder 堆栈,专注做因果语言建模,也就是根据前文预测后文,并采用"预训练 + 微调"路线。
5.2 GPT-2、GPT-3 相比 GPT-1 的主要改进
答:主要改进在规模、数据和能力形态上。GPT-2 把大规模预训练和 zero-shot 多任务能力做强;GPT-3 则进一步放大规模,使 few-shot 和 in-context learning 更突出。
5.3 Llama 系列和原始 Transformer 架构的差异
答:Llama 继承了 decoder-only Transformer 主线,但在关键组件上做了更适合大语言模型的优化,比如 RMSNorm、RoPE、SwiGLU 等。
5.4 Llama2、Llama3 和 Llama1 的差别
答:可以从训练数据、上下文长度、tokenizer、后训练能力和推理效率几个维度来比。总体上,Llama1 打基础,Llama2 更成熟,Llama3 更全面。
5.5 Qwen3 模型架构
答:Qwen3 既有 Dense 也有 MoE 模型,并把 thinking mode 和 non-thinking mode 统一进同一家族,同时提供 thinking budget 来平衡效果和延时。
5.6 Qwen3 预训练流程
答:Qwen3 预训练先做大规模数据收集、清洗、配比,再通过因果语言建模进行大规模训练,核心目的是构建知识、语言、代码和推理底座。
5.7 Qwen3 后训练流程
答:后训练一般包括 SFT、偏好对齐或强化学习、推理增强与评估回流,目标是让模型更听话、更安全、更会思考,也更适合真实使用。
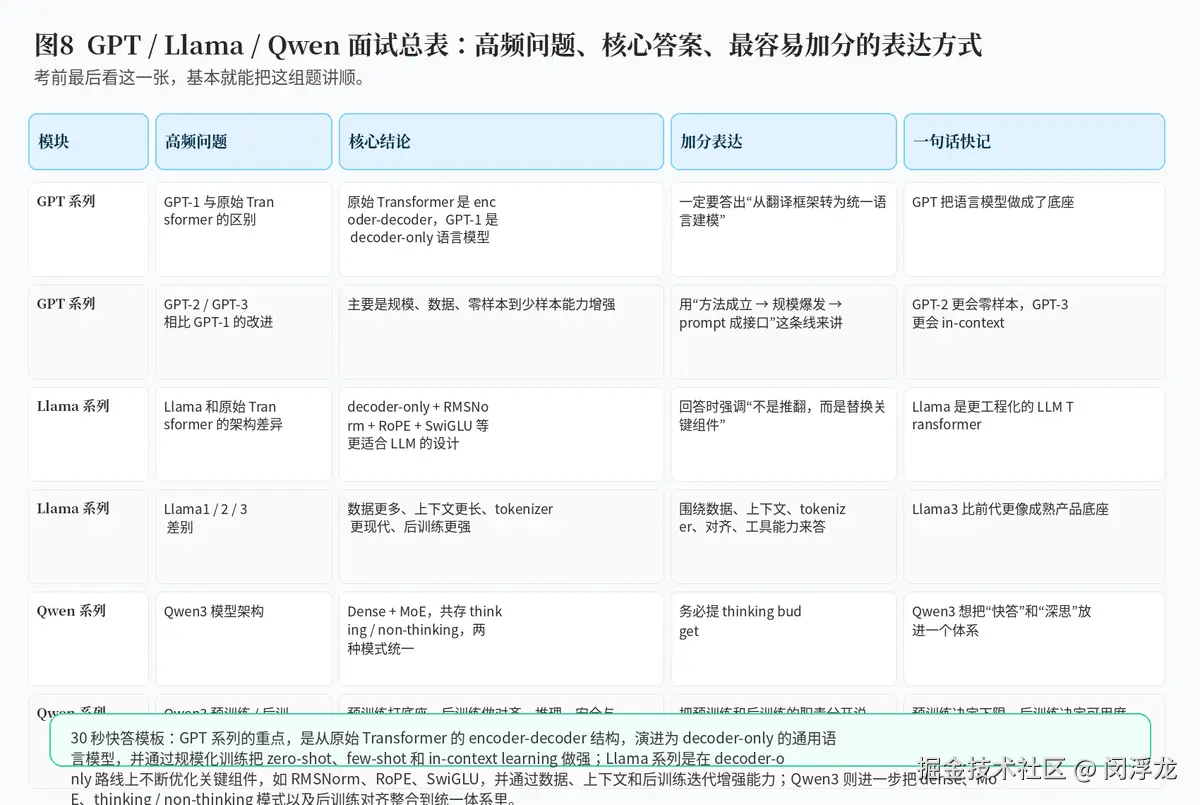
6. 总结:真正高质量的回答,是把"模型家族演进"讲成一条清晰主线
如果把整篇文章浓缩成一句话,那就是:GPT 这条线告诉我们,语言模型如何从原始 Transformer 中抽出一条"decoder-only 通用底座"的路线,并通过规模化训练让 zero-shot、few-shot 和 prompt 驱动能力不断增强;Llama 这条线告诉我们,开源模型如何在这条路线之上,通过更适合大模型的组件和训练策略,把性能与可用性一起做高;Qwen 则进一步展示了新一代模型如何把多语言、思考模式、Dense / MoE 和后训练体系整合到更统一的产品能力框架中。
面试里最能体现理解深度的,不是你能背出多少版本号,而是你能否讲清:它和上一代相比改变了什么,这个改变为什么重要,以及它给训练、推理和产品使用带来了什么意义。只要这三件事能讲顺,这组题就算真正吃透了。
附:30 秒面试快答模板
"GPT 系列的核心,是把原始 Transformer 从 encoder-decoder 路线收敛成 decoder-only 的通用语言模型,并通过规模化训练把 zero-shot、few-shot 和 in-context learning 做强;Llama 系列是在这条主线上进一步优化关键组件,比如 RMSNorm、RoPE、SwiGLU,并通过更多数据、更长上下文和更成熟的后训练增强能力;Qwen3 则进一步把 dense、MoE、thinking mode、non-thinking mode 和后训练对齐整合成统一体系,强调在延时、推理深度和多语言能力之间做更灵活的平衡。"