用Python获取网络数据
网络数据采集是Python语言极具优势的应用领域,上节课我们提到过,实现自动化网络数据采集的程序,通常被称作网络爬虫或蜘蛛程序。即便身处大数据时代,数据获取依旧是绝大多数中小企业的短板,部分数据可以通过开放接口或是付费接口获取,而大量行业数据、竞品数据,依旧需要通过网络数据采集的方式来获取。无论选用哪种方式获取网络数据,Python都是十分优质的选择,得益于完善的标准库与丰富的第三方库,Python对网络数据采集全流程都提供了全面且便捷的支持。
requests库
使用Python实现网络数据获取,首选第三方库为requests,该库在之前的课程中我们已经有过基础使用。根据官方定义,requests基于Python内置标准库深度封装,极大简化了HTTP、HTTPS协议下的网络资源访问操作。上节课我们讲到,HTTP是典型的请求-响应式协议,在浏览器中输入正确的URL(统一资源定位符,也就是日常所说的网址)并按下回车键,就会向对应Web服务器发送一条HTTP请求,服务器接收并处理请求后,会返回对应的HTTP响应。在Chrome浏览器中,通过菜单栏打开开发者工具,切换至Network选项卡,即可直观查看完整的HTTP请求与响应报文,效果如下图所示。
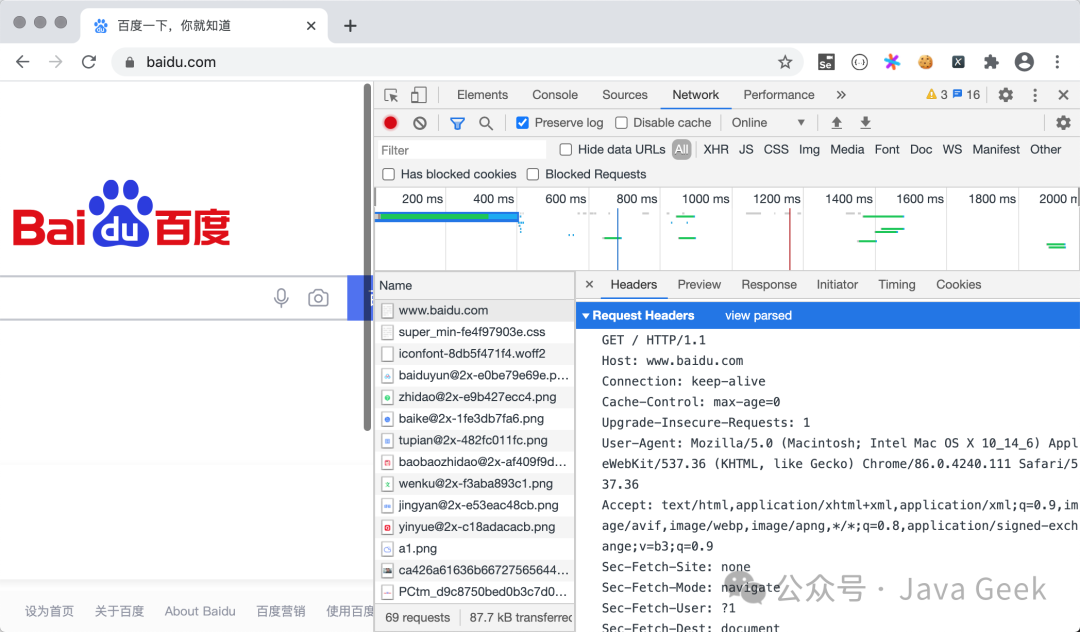
借助requests库,Python程序可以模拟浏览器行为,向Web服务器发起网络请求、接收服务器返回的响应数据,进而从响应结果中提取目标信息。我们日常浏览的网页,均由HTML超文本标记语言编写而成,浏览器相当于HTML的解析渲染环境,页面内所有展示内容,都嵌套在各类HTML标签之中。获取到完整的HTML源码后,就能从标签属性或者标签文本中提取所需数据。下方代码示例,演示了通过requests库的get方法,获取搜狐首页HTML源码的完整流程。
import requests
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
print(resp.text)说明 :上面代码中的变量
resp是一个Response对象,由requests库封装而成。通过该对象的status_code属性可以获取服务器返回的响应状态码,以此判断请求是否成功;而该对象的text属性,可以直接获取页面解析后的HTML文本代码。
Response对象的text属性返回值为字符串格式,我们可以结合之前学习的正则表达式知识,从页面HTML源码中提取新闻标题、链接等目标信息,具体实现代码如下所示。
import re
import requests
pattern = re.compile(r'<a.*?href="(.*?)".*?title="(.*?)".*?>')
resp = requests.get('https://www.sohu.com/')
if resp.status_code == 200:
all_matches = pattern.findall(resp.text)
for href, title in all_matches:
print(href)
print(title)除了文本类网页数据,requests库也可以通过URL,直接获取图片、音频等二进制资源。下方示例演示了获取百度Logo图片,并将其保存为本地baidu.png文件的操作,大家可以在百度首页右键点击Logo,选择"复制图片地址"菜单项,即可获取对应的图片URL。
import requests
resp = requests.get('https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png')
with open('baidu.png', 'wb') as file:
file.write(resp.content)说明 :
Response对象的content属性,可以获取服务器返回的二进制响应数据,专门用于处理图片、文件等非文本类资源。
requests库使用便捷、功能全面,后续我们会结合实操场景,逐步剖析它的核心用法。如果想学习requests库的更多知识点,可以查阅它的官方文档,系统掌握各项用法。
编写爬虫代码
接下来我们以豆瓣电影平台为例,实操讲解基础爬虫代码的编写逻辑。沿用前面讲解的方法,先通过requests库获取页面HTML源码,将完整源码看作一个长字符串,再利用正则表达式的捕获组,精准提取所需内容。下方代码实现了从豆瓣电影Top250页面,获取上榜电影信息的功能,豆瓣电影Top250的页面结构与对应源码如下图所示。
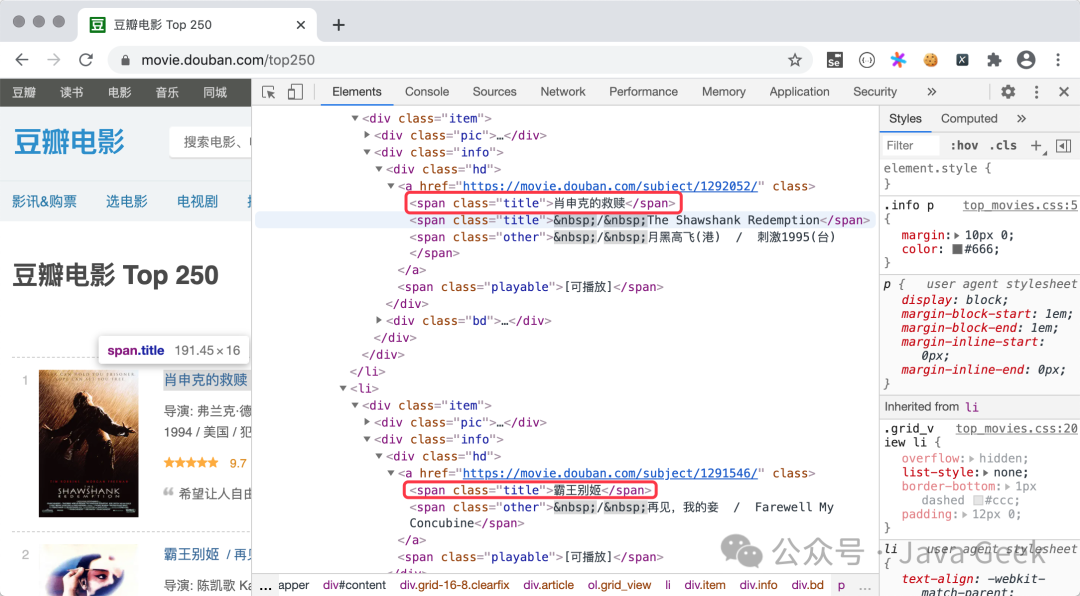
可以看到,豆瓣电影Top250页面,单页展示25部电影,想要获取全部250条数据,需要遍历访问10个页面,对应请求地址格式为https://movie.douban.com/top250?start=xxx,这里的xxx为数据起始位置参数,参数为0时对应第一页,参数为100时对应第五页。为了让代码简洁易懂,本次实操只提取电影标题和评分两项核心数据。
import random
import re
import time
import requests
for page inrange(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 如果不设置HTTP请求头中的User-Agent,豆瓣会检测出非浏览器访问,直接拦截请求
# 通过get函数的headers参数设置User-Agent,参数值可在浏览器开发者工具中查看
# 爬虫访问大部分网站时,伪装成浏览器请求都是规避反爬的关键步骤
headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
)
# 通过正则表达式,匹配class为title、且内容不含&的span标签,提取电影标题
pattern1 = re.compile(r'<span class="title">([^&]*?)</span>')
titles = pattern1.findall(resp.text)
# 通过正则表达式,匹配class为rating_num的span标签,提取电影评分
pattern2 = re.compile(r'<span class="rating_num".*?>(.*?)</span>')
ranks = pattern2.findall(resp.text)
# 使用zip合并两个列表,循环遍历输出电影标题与对应评分
for title, rank inzip(titles, ranks):
print(title, rank)
# 随机休眠1-5秒,控制请求频率,避免频繁请求触发网站反爬机制
time.sleep(random.random() * 4 + 1)说明 :分析豆瓣网的robots协议可知,豆瓣并不拒绝百度爬虫抓取站内公开数据,因此也可以将爬虫伪装成百度爬虫,将
get函数的headers参数简化修改为:headers={'User-Agent': 'BaiduSpider'}。
使用 IP 代理
编写爬虫程序时,隐匿真实请求身份是核心环节。大部分网站对大规模爬虫请求都较为抵触,因为爬虫会消耗大量服务器带宽,产生大量无效流量,甚至影响正常用户访问。想要彻底隐匿爬虫真实身份,通常需要使用商业IP代理(如蘑菇代理、芝麻代理、快代理等),让被爬取网站无法获取爬虫的真实IP地址,也就无法通过IP封禁的方式拦截爬虫。
下面以蘑菇代理为例,为大家讲解商业IP代理的实操使用方法。首先需要在该平台注册账号,注册完成后购买对应套餐,即可获取IP代理使用权限。如果是商业爬虫使用,建议选购不限量套餐,能根据实际需求获取充足的代理IP;如果是学习测试使用,可以选购包时套餐,或是根据自身需求灵活选择。蘑菇代理提供两种接入方式,分别是API私密代理和HTTP隧道代理,前者通过请求官方API接口获取代理服务器地址,后者直接使用统一入口域名接入,操作更简便。
接下来以HTTP隧道代理为例,讲解IP代理的接入方式,大家也可以直接参考蘑菇代理官网提供的示例代码,适配自己的爬虫项目。
import requests
# 替换为个人代理订单对应的AppKey
APP_KEY = 'Wnp******************************XFx'
PROXY_HOST = 'secondtransfer.moguproxy.com:9001'
for page inrange(1, 11):
resp = requests.get(
url=f'https://movie.douban.com/top250?start={(page - 1) * 25}',
# 请求头中配置代理认证信息与浏览器伪装
headers={
'Proxy-Authorization': f'Basic {APP_KEY}',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4'
},
# 配置HTTP与HTTPS代理服务器
proxies={
'http': f'http://{PROXY_HOST}',
'https': f'https://{PROXY_HOST}'
},
verify=False
)
# 提取电影标题与评分数据
pattern1 = re.compile(r'<span class="title">([^&]*?)</span>')
titles = pattern1.findall(resp.text)
pattern2 = re.compile(r'<span class="rating_num".*?>(.*?)</span>')
ranks = pattern2.findall(resp.text)
for title, rank inzip(titles, ranks):
print(title, rank)说明 :使用上述代码时,需要将
APP_KEY替换为个人代理订单对应的AppKey,该参数可在平台用户中心的订单列表中查看。蘑菇代理提供免费的API代理与HTTP隧道代理试用,但试用版代理接通率无法保证,学习测试建议选购性价比合适的正规代理套餐体验。
总结
Python语言的应用场景十分广泛,单论网络数据采集这一领域,Python几乎占据绝对优势,大量企业和开发者都使用Python从互联网上获取所需数据,这也会成为大家日后日常开发工作的常用技能。
另外,虽然正则表达式可以实现网页数据提取,但编写一套精准、适配需求的正则表达式难度并不小,对于新手来说尤为明显。下一节课,我们会讲解另外两种网页数据提取方法,这类方法虽说性能略逊于正则表达式,但大幅降低了编码复杂度,上手更轻松,相信大家学习后会十分受用。