文章目录
-
- [0810逻辑总览 The 8B/10B coding map](#0810逻辑总览 The 8B/10B coding map)
- [5B/6B encoding](#5B/6B encoding)
- [3B/4B encoding](#3B/4B encoding)
- [Special characters 略](#Special characters 略)
0810逻辑总览 The 8B/10B coding map
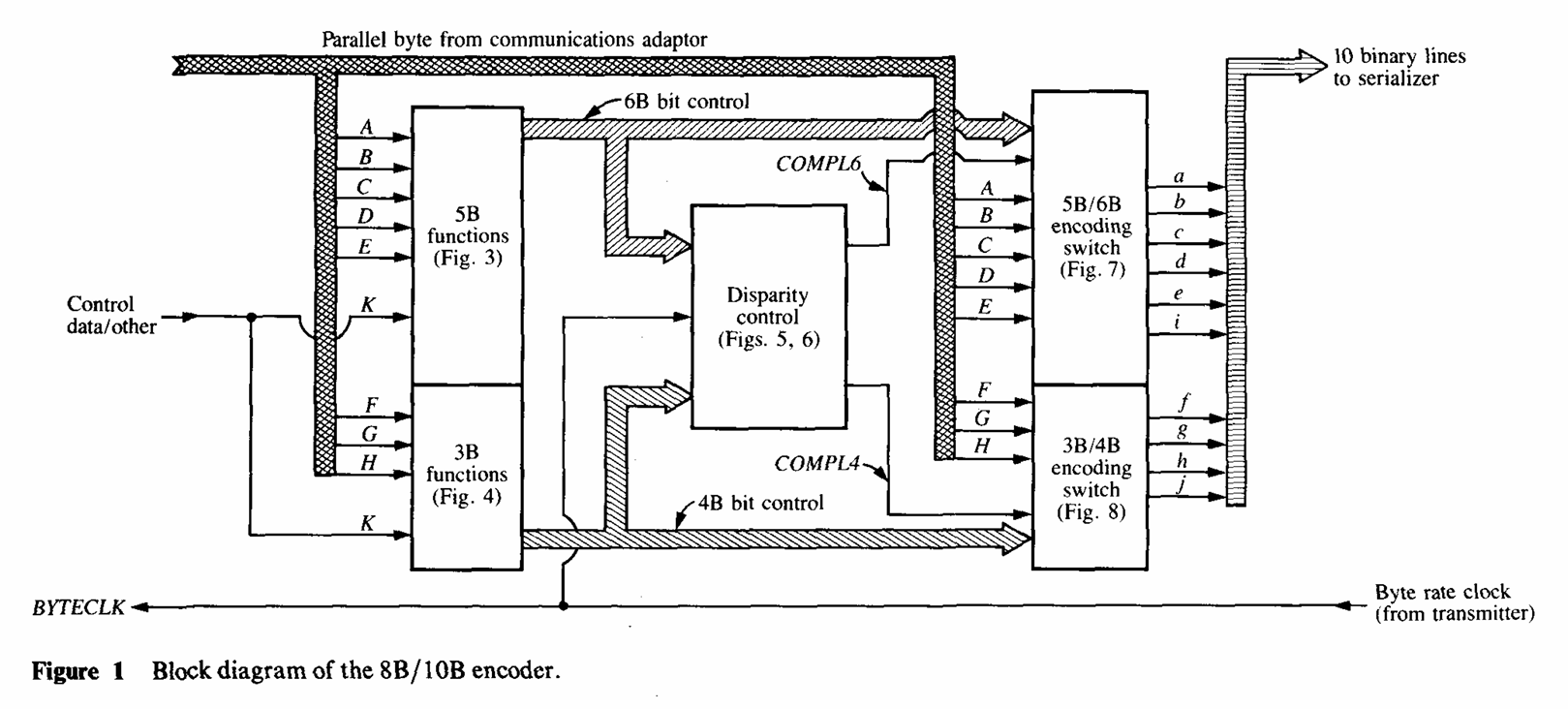
- 由八条数据线 A、B、C、D、E、F、G、H (注意:使用大写字母表示)、一条控制线 K ,以及一条以字节速率运行的时钟线 BYTECLK 组成。只编码数据的情况下控制线 K 被简化。
-
基于LUT的8B/10B编码器;RD初始为0;
-
先进行5B/6B编码,并更新RD信号;
-
再根据更新后的RD信号进行3B/4B编码,且产生下次编码的RD信号;
-
这十条(
data_10b <= {data_4b,data_6b};)编码后的数据线 abcdeifghj 通常与串行 接口;其中,a 位 必须首先传输,而 j 位最后传输。
-
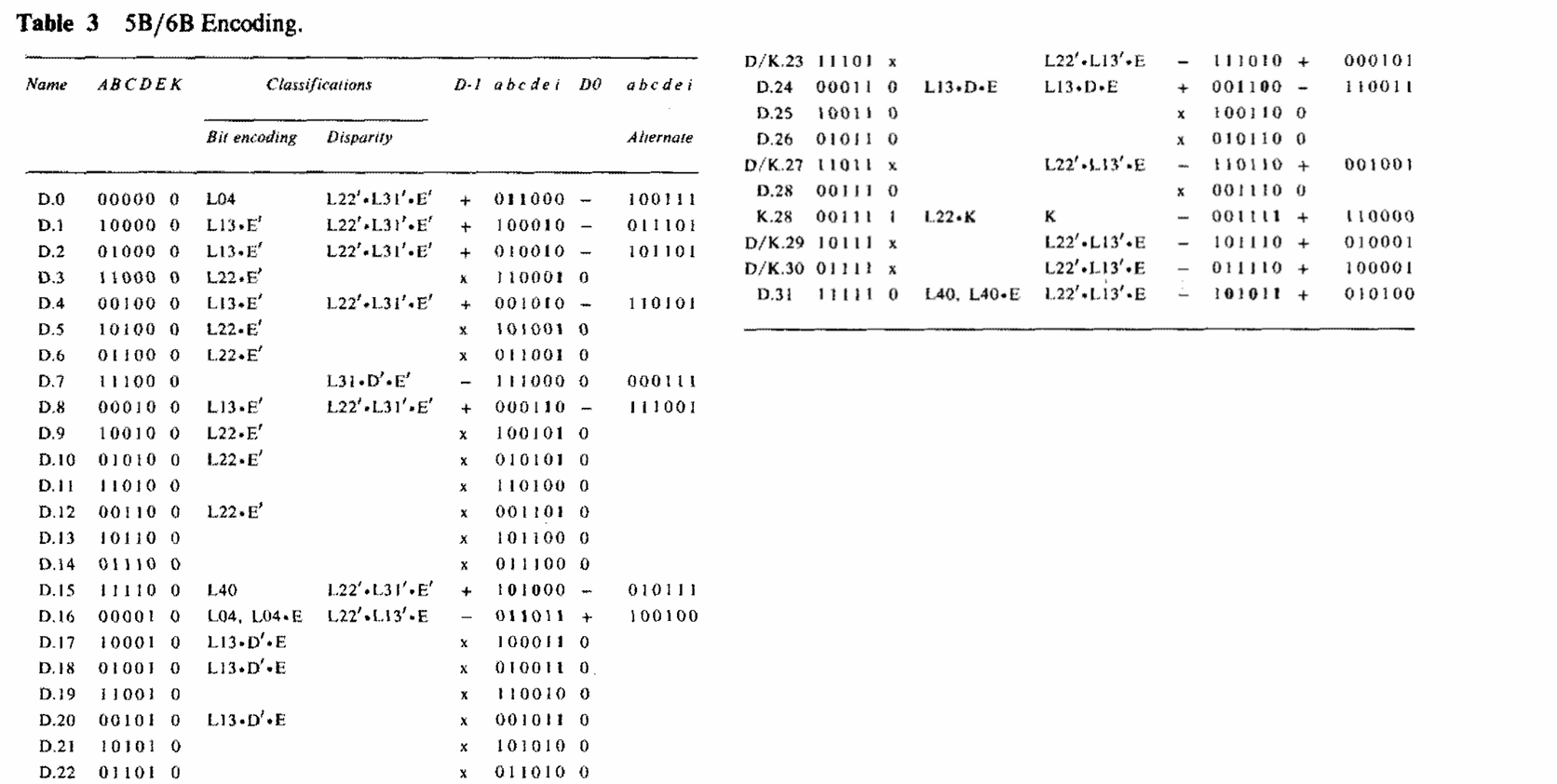
5B/6B encoding
-
表格中像18、19、20、21、22这样的数据编码后是平衡的(0、1个数相同),使用rd <= rd; 转换规则;其他数据则使用rd <= ~rd; 转换规则。
encode_5b_6b: begin
encode_load_data_flag <= 1'b0;
case (data_5b)
5'd0: begin
data_6b <= rd ? 6'b000110 : 6'b111001;
rd <= ~rd;
end
5'd1: begin
data_6b <= rd ? 6'b010001 : 6'b101110;
rd <= ~rd;
end
5'd2: begin
data_6b <= rd ? 6'b010010 : 6'b101101;
rd <= ~rd;
end
5'd3: begin
data_6b <= 6'b100011;
rd <= rd;
end
5'd4: begin
data_6b <= rd ? 6'b010100 : 6'b101011;
rd <= ~rd;
end
5'd5: begin
data_6b <= 6'b100101;
rd <= rd;
end
5'd6: begin
data_6b <= 6'b100110;
rd <= rd;
end
5'd7: begin
data_6b <= rd ? 6'b111000 : 6'b000111;
rd <= rd;
end
5'd8: begin
data_6b <= rd ? 6'b011000 : 6'b100111;
rd <= ~rd;
end
5'd9: begin
data_6b <= 6'b101001;
rd <= rd;
end
5'd10: begin
data_6b <= 6'b101010;
rd <= rd;
end
5'd11: begin
data_6b <= 6'b001011;
rd <= rd;
end
5'd12: begin
data_6b <= 6'b101100;
rd <= rd;
end
5'd13: begin
data_6b <= 6'b001101;
rd <= rd;
end
5'd14: begin
data_6b <= 6'b001110;
rd <= rd;
end
5'd15: begin
data_6b <= rd ? 6'b000101 : 6'b111010;
rd <= ~rd;
end
5'd16: begin
data_6b <= rd ? 6'b001001 : 6'b110110;
rd <= ~rd;
end
5'd17: begin
data_6b <= 6'b110001;
rd <= rd;
end
5'd18: begin
data_6b <= 6'b110010;
rd <= rd;
end
5'd19: begin
data_6b <= 6'b010011;
rd <= rd;
end
5'd20: begin
data_6b <= 6'b110100;
rd <= rd;
end
5'd21: begin
data_6b <= 6'b010101;
rd <= rd;
end
5'd22: begin
data_6b <= 6'b010110;
rd <= rd;
end
5'd23: begin
data_6b <= rd ? 6'b101000 : 6'b010111;
rd <= ~rd;
end
5'd24: begin
data_6b <= rd ? 6'b001100 : 6'b110011;
rd <= ~rd;
end
5'd25: begin
data_6b <= 6'b011001;
rd <= rd;
end
5'd26: begin
data_6b <= 6'b011010;
rd <= rd;
end
5'd27: begin
data_6b <= rd ? 6'b100100 : 6'b011011;
rd <= ~rd;
end
5'd28: begin
data_6b <= 6'b011100;
rd <= rd;
end
5'd29: begin
data_6b <= rd ? 6'b100010 : 6'b011101;
rd <= ~rd;
end
5'd30: begin
data_6b <= rd ? 6'b100001 : 6'b011110;
rd <= ~rd;
end
5'd31: begin
data_6b <= rd ? 6'b001010 : 6'b110101;
rd <= ~rd;
end
default: ;
endcase
end
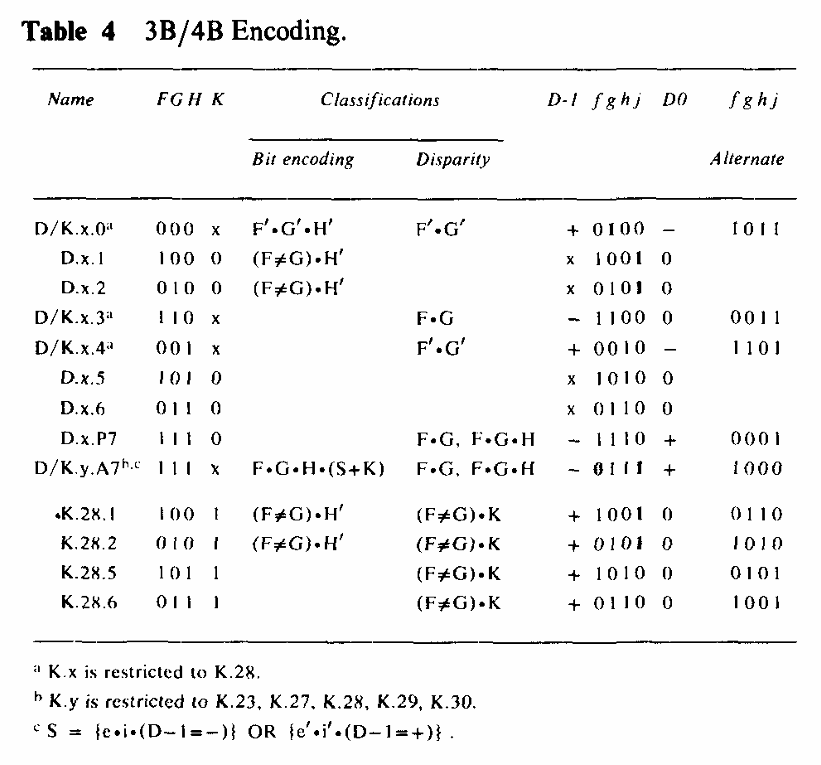
3B/4B encoding
encode_3b_4b: begin
case (data_3b)
3'd0: begin
data_4b <= rd ? 4'b0010 : 4'b1101;
rd <= ~rd;
end
3'd1: begin
data_4b <= 4'b1001;
rd <= rd;
end
3'd2: begin
data_4b <= 4'b1010;
rd <= rd;
end
3'd3: begin
data_4b <= rd ? 4'b1100 : 4'b0011;
rd <= rd;
end
3'd4: begin
data_4b <= rd ? 4'b0100 : 4'b1011;
rd <= ~rd;
end
3'd5: begin
data_4b <= 4'b0101;
rd <= rd;
end
3'd6: begin
data_4b <= 4'b0110;
rd <= rd;
end
3'd7: begin
if (((rd = 1'b1) && ~data_6b[5] && ~data_6b[4]) || ((rd == 1'b0) && data_6b[5] && data_6b[4])) begin
data_4b <= rd ? 4'b0001 : 4'b1110; // D.x.A7 (Alternate)
end
else begin
data_4b <= rd ? 4'b1000 : 4'b0111; // D.x.P7 (Primary)
end
rd <= ~rd;
end
default: ;
endcase
end-
编码完成后组合输出时,低 6 位(
data_6b)的结尾可能会和当前 4 位的开头组合出太长的连续 0 或 1。 -
在表 3 中,D.7 行 ,一对零失衡的 6B 子块 (111000 和 000111 )被分配给单个数据点,并具有类似于适用于非零失衡子块的失衡约束。这个编码特性将最大数字和变化(DSV )从 8 降低到 6 ,并结合表 4 中 3B/4B 编码器 对 D/K.X.3 (1100 和 0011 )的类似规则,消除了所有 运行长度为 6 的序列,以及大多数 运行长度为 5 的序列。
-
D/K.y.A7 编码可以在 ghjab 位的尾部字符边界生成一个 运行长度 为5的序列;引入 D/K.y.A7 编码点是为了消除 eifgh 中的运行长度为 5 的序列。每当需要时,A7 编码会替换 P7 编码。
verilog
3'd7: begin
if (((rd = 1'b1) && ~data_6b[5] && ~data_6b[4]) || ((rd == 1'b0) && data_6b[5] && data_6b[4])) begin
data_4b <= rd ? 4'b0001 : 4'b1110; // D.x.A7 (Alternate)
end
else begin
data_4b <= rd ? 4'b1000 : 4'b0111; // D.x.P7 (Primary)
end
rd <= ~rd;
endSpecial characters 略
- 特殊字符在此定义为超出编码一个数据字节所需的 256 个编码点。它们通常用于建立字节同步、标记数据包的开始和结束,有时也用于信号控制功能,如 ABORT 、RESET 、SHUT-OFF 、IDLE 和链路诊断。表 5 中显示的十二个特殊字符可以通过表 3 和表 4 中定义的编码规则生成。它们都符合一般编码约束,即最大运行长度为 5 和最大数字和变化为 6。

- 在该编码中,有三个字符(K.28.1 、K.28.5 、K.28.7 )具有逗号特性。它们在表 5 中以星号标记,并用粗体字突出显示其唯一的逗号序列。这三个字符也是最适合作为信息包起始和结束标记的分隔符。