OpenVLA 论文精读笔记
系统结构
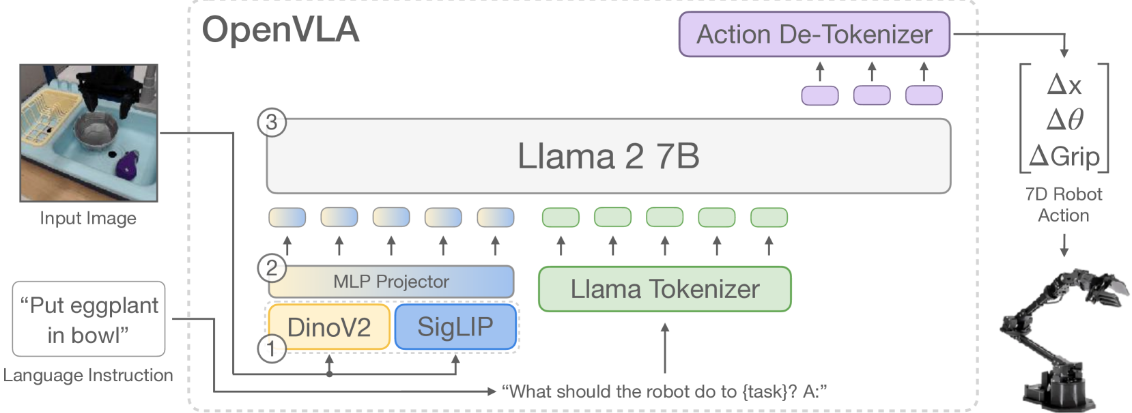
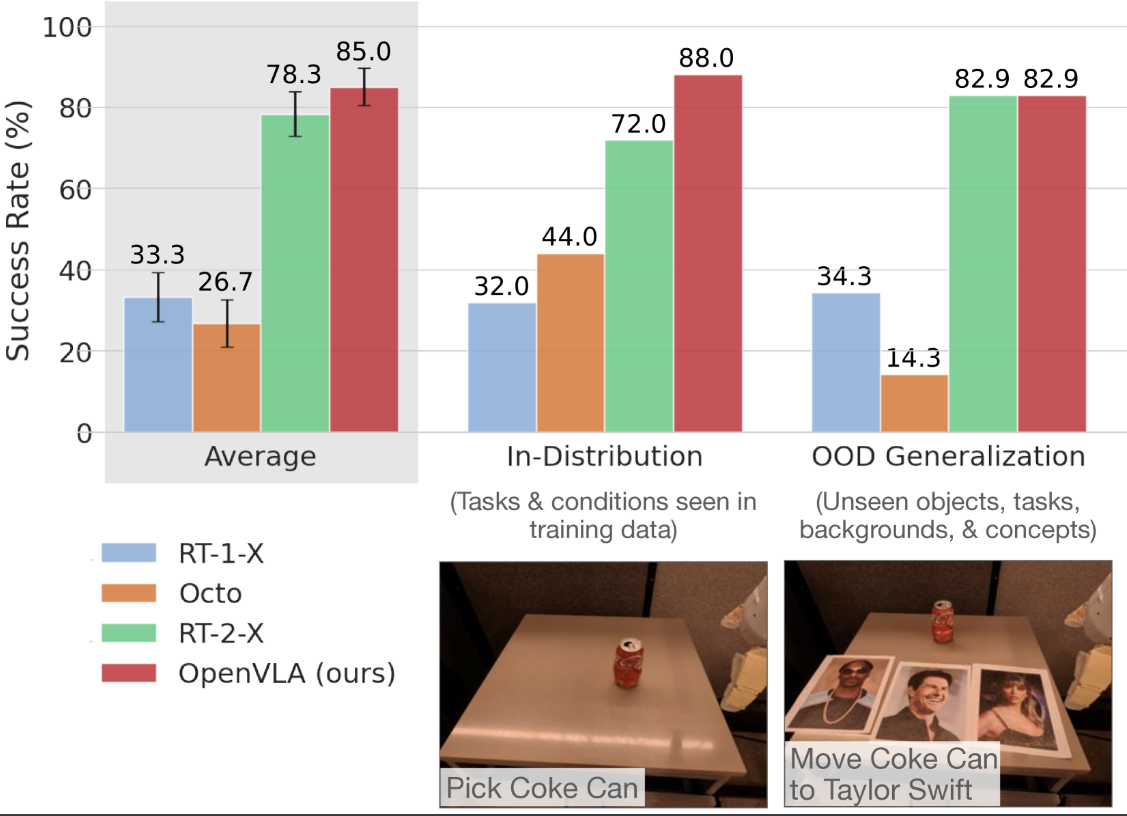
评测结论:OpenVLA 在所有任务上全面优于已有方案。
VLA 的核心优势
将机器人控制动作融合到 VLM 主干中有三个好处:
- 视觉-语言对齐:利用互联网规模图文数据预训练的组件,天然具备语义理解能力
- 通用架构:不需要为机器人控制定制网络,可复用 VLM 训练的基础设施,以最少代码修改训练数十亿参数策略
- 持续受益:VLM 领域的任何进步都能直接惠及 VLA
现有 VLA 工作的局限性:要么只在单一机器人/仿真环境训练评估(缺乏泛化性),要么闭源不支持微调。OpenVLA 是第一个开源的通用 VLA。
与 RT-2-X 的对比
| RT-2-X | OpenVLA | |
|---|---|---|
| 开源 | ❌ 闭源 | ✅ 完全开源 |
| 模型规模 | 55B | 7B(小一个数量级) |
| 训练数据 | 互联网图文 + 机器人数据 | 纯机器人数据(OXE) |
| 性能 | --- | 全面优于 RT-2-X |
胜出的关键:开源 VLM 主干(Prismatic)+ 更丰富的机器人预训练数据(OXE 97 万条)。
Q1:为什么选 Llama-2 7B 而不是更大的模型?
直接原因:实验对比后 Prismatic 最好
作者试了三个 VLM 主干:IDEFICS-1 、LLaVA 、Prismatic。结果:
| 主干 | 单对象任务 | 多对象/语言 grounding 任务 |
|---|---|---|
| IDEFICS-1 | 尚可 | ❌ 差 |
| LLaVA | 尚可 | 比 IDEFICS-1 高 35% |
| Prismatic | 比 LLaVA 再高 ~10% | 比 LLaVA 再高 ~10% |
Prismatic 胜出的原因:
- 融合的 SigLIP + DinoV2 双视觉编码器提供了更强的空间推理能力
- 模块化代码库,易于扩展和实验
深层原因:VLA 不需要堆 LLM 参数
VLA 任务对语言推理的要求远低于纯文本任务,瓶颈在视觉表示而非语言能力。7B 足够,更大的模型只会徒增推理成本。
Q2:Action Token 如何映射到词表?
动作被离散化为 256 个 bin ,借用了 Llama 词表末尾的 256 个 token(ID 范围 31745~32000)。
Llama 词表 (32000 tokens):
┌──────────────────────────────┬──────────────────────┐
│ 0 ~ 31744 正常语言 token │ 31745~32000 罕见 token │
│ "the", "a", "is" ... │ ← 被 OpenVLA "征用" │
└──────────────────────────────┴──────────────────────┘
↑
bin_0 → token 32000
bin_255 → token 31745为什么借末尾的?
- 这些是 BPE 训练出的最罕见片段,几乎不出现在自然语言 prompt 中
- 与正常语言 token 冲突概率极低,不会让模型产生错误的 token 关联
解码流程
LLM 输出 token_id → bin = vocab_size - token_id → bin_centers[bin] → [-1, 1]
↓
反归一化(1st/99th 百分位)
↓
实际动作值百分位反归一化使用第 1 和第 99 分位数而非 min/max,对异常值更鲁棒。
Q3:训练数据与增强策略
- 数据量 :Open X-Embodiment(OXE)数据集中的 97 万条机器人演示轨迹
- 数据增强 :Random Resized Crop(随机裁剪)
这也是为什么 eval 脚本需要设 center_crop=True --- 训练时用了随机裁剪,推理时用中心裁剪对齐。
Q4:为什么用 DINOv2 + SigLIP 双编码器?只用一个行不行?
两个编码器的分工
| 编码器 | 训练方式 | 擅长 |
|---|---|---|
| SigLIP | 图文对独立做二元分类(正例→1,负例→0) | 语义理解、图文对齐 |
| DinoV2 | 自监督学习(iBOT),侧重 dense 特征 | 空间感知、物体分割 |
消融实验结论
论文做了单编码器 vs 双编码器的对比:单用 SigLIP 在 Object 任务上还行但 Spatial 任务差,单用 DinoV2 反过来。两者融合后,两类任务同时提升 ,说明它们的视觉特征互补而非冗余。
Q5:OpenVLA 与 RT-2 的技术路线差异
| RT-2 | OpenVLA | |
|---|---|---|
| 训练数据 | 互联网图文 + 机器人数据混合 | 纯机器人数据(OXE) |
| 核心假设 | "互联网知识能否迁移到机器人?" | "只用机器人数据也能训出强 VLA" |
| 结果 | 验证了迁移可行性 | 纯机器人数据效果更好 |
RT-2 的 co-fine-tuning 混入大量图文数据,试图让模型从互联网学到的常识("碗是什么"、"怎么拿东西")迁移到机器人任务。OpenVLA 证明不需要互联网图文数据,高质量的多样化机器人数据就够了,而且效果更好。
Q6:训练时的 Loss 如何计算?
Loss 只算在 7 个 action token 上,visual token 和 text token 不参与 loss。
实现方式:
序列: [<BOS>] [vision patches...] [text tokens...] ["Out:"] [action₀] [action₁] ... [action₆]
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
label: IGNORE IGNORE IGNORE IGNORE bin₀ bin₁ ... bin₆
(-100) (-100) (-100) (-100)- Vision token 和 text token 的 label 设为
IGNORE_INDEX = -100 - PyTorch 的
CrossEntropyLoss(ignore_index=-100)自动跳过这些位置 - 只有 7 个 action token 参与 loss 计算和梯度回传
微调方法:Sandwich Fine-tuning
"三明治微调"(Sandwich Fine-tuning):解冻视觉编码器 + embedding 层 + 最后一层,冻结 LLM 中间层。
名称来源于解冻层的分布像三明治:首尾解冻,中间冻结。
优势:
- 比全参数微调更强(因为充分微调了视觉编码器,这对新场景的视觉适配至关重要)
- 比全参数微调更省显存(中间 30 层 LLM 不参与梯度计算)
- 对 10~150 条演示数据量级的微调场景尤为有效
量化发现
论文在 A5000 GPU 上测试了量化对推理的影响:
| 精度 | 推理频率 | 显存 | 性能 |
|---|---|---|---|
| bf16 | --- | 基准 | 基准 |
| 8-bit | 1.2 Hz ⚠️ | --- | 大幅下降 |
| 4-bit | 3 Hz | 不到一半 | ✅ 与 bf16 相近 |
关键发现:8-bit 反而比 4-bit 差。原因是 8-bit 推理速度太慢(1.2Hz),与训练时的 5Hz 控制器频率差距过大,改变了系统动力学,导致策略失效。4-bit 虽然压缩更狠,但因为推理速度更快(3Hz),实际表现反而接近 bf16 基准。
对 Week 2 量化的启示:量化不只是精度问题,推理频率也是机器人任务的关键指标。