在做RAG的过程中,Embedding前期可以固定设置但是后面要测试验证效果还是要通过不同的模型去测试优化。在一系列操作之后,最后我们的目的可能转向训练自己的大模型,但这都是后话了。

一、为什么需要动态切换?
1.1 业务场景驱动
| 场景 | 模型需求 | 维度需求 |
|---|---|---|
| 精确检索 | BGE-large (1024维) | 高维度保精度 |
| 实时对话 | text-embedding-3-small (1536维) | 平衡速度与效果 |
| 多语言文档 | multilingual-e5 (768维) | 跨语言能力 |
| 代码检索 | codebert (768维) | 代码语义理解 |
| 成本敏感 | lightweight (384维) | 降低存储成本 |
1.2 动态切换的优势
-
✅ A/B测试:对比不同模型效果
-
✅ 灰度发布:新模型逐步替换旧模型
-
✅ 成本优化:根据场景选择性价比模型
-
✅ 故障降级:模型服务异常时自动切换备用
二、核心架构设计
2.1 整体架构图
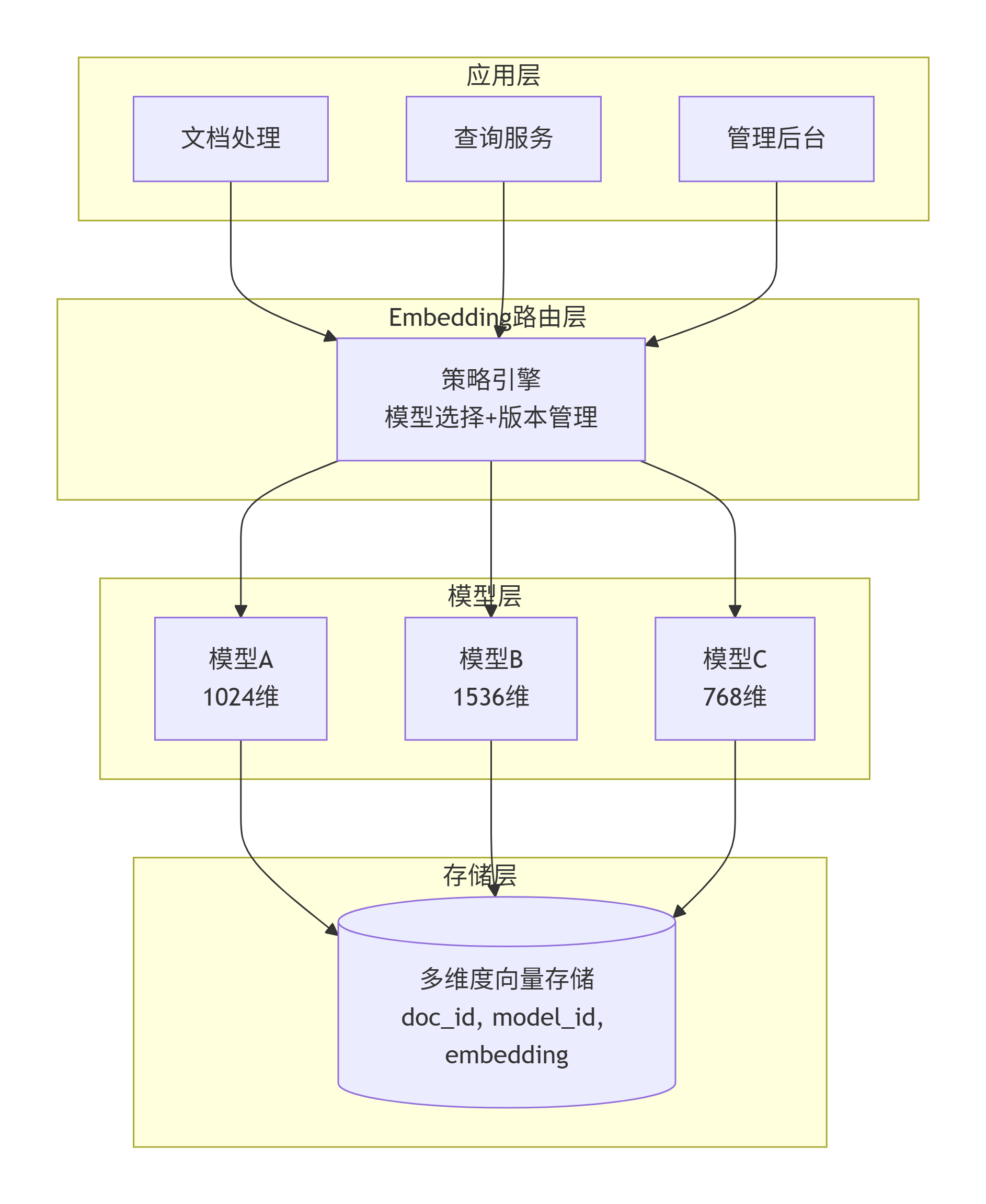
2.2 数据库设计
sql
-- 1. 模型配置表
CREATE TABLE embedding_models (
id VARCHAR(50) PRIMARY KEY,
name VARCHAR(100) NOT NULL,
dimension INT NOT NULL,
endpoint VARCHAR(255),
api_key VARCHAR(255),
enabled BOOLEAN DEFAULT true,
priority INT DEFAULT 0, -- 优先级,数字越小优先级越高
cost_per_1k_tokens DECIMAL(10, 4),
avg_latency_ms INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. 文档向量表(支持多模型)
CREATE TABLE document_embeddings (
id BIGSERIAL PRIMARY KEY,
doc_id VARCHAR(100) NOT NULL,
chunk_id VARCHAR(100) NOT NULL,
model_id VARCHAR(50) NOT NULL,
content TEXT,
embedding vector(1536), -- 按最大维度创建
actual_dimension INT, -- 实际存储的维度
metadata JSONB,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(doc_id, chunk_id, model_id)
);
-- 3. 查询缓存表
CREATE TABLE embedding_cache (
content_hash VARCHAR(64) PRIMARY KEY,
model_id VARCHAR(50) NOT NULL,
embedding vector(1536),
dimension INT,
hit_count INT DEFAULT 0,
last_accessed TIMESTAMP,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_model_hash (model_id, content_hash)
);三、核心代码实现
3.1 模型管理器
java
@Service
public class EmbeddingModelManager {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private ApplicationContext applicationContext;
private final Map<String, EmbeddingProvider> providers = new ConcurrentHashMap<>();
private volatile EmbeddingModelConfig activeConfig;
@PostConstruct
public void init() {
loadModels();
loadActiveConfig();
}
/**
* 加载所有可用模型
*/
private void loadModels() {
String sql = "SELECT * FROM embedding_models WHERE enabled = true ORDER BY priority";
List<EmbeddingModel> models = jdbcTemplate.query(sql, (rs, rowNum) ->
EmbeddingModel.builder()
.id(rs.getString("id"))
.name(rs.getString("name"))
.dimension(rs.getInt("dimension"))
.endpoint(rs.getString("endpoint"))
.apiKey(rs.getString("api_key"))
.priority(rs.getInt("priority"))
.costPer1kTokens(rs.getBigDecimal("cost_per_1k_tokens"))
.avgLatencyMs(rs.getInt("avg_latency_ms"))
.build()
);
for (EmbeddingModel model : models) {
providers.put(model.getId(), createProvider(model));
}
}
/**
* 动态切换模型
*/
@Transactional
public void switchModel(String modelId, SwitchStrategy strategy) {
EmbeddingModel newModel = getModelById(modelId);
EmbeddingModel oldModel = activeConfig.getModel();
switch (strategy) {
case IMMEDIATE:
// 立即切换,新数据使用新模型
activeConfig = new EmbeddingModelConfig(newModel);
log.info("立即切换到模型: {}", modelId);
break;
case GRACEFUL:
// 优雅切换,保留旧模型查询能力
activeConfig = new EmbeddingModelConfig(newModel, oldModel);
scheduleOldModelCleanup(oldModel.getId());
log.info("优雅切换到模型: {}, 旧模型: {} 将逐步淘汰", modelId, oldModel.getId());
break;
case CANARY:
// 金丝雀发布,新模型只处理部分流量
activeConfig = new EmbeddingModelConfig(newModel, oldModel, 0.1); // 10%流量
log.info("金丝雀发布: 新模型 {} 承接 10% 流量", modelId);
break;
}
// 更新配置版本
updateActiveConfig(activeConfig);
}
/**
* 根据文档ID获取使用的模型
*/
public String getModelForDocument(String docId) {
// 根据文档类型、业务场景选择模型
DocumentMetadata metadata = getDocumentMetadata(docId);
if (metadata.isLegalDocument()) {
return "bge-large-zh"; // 法律文档用高精度模型
} else if (metadata.isCodeDocument()) {
return "codebert"; // 代码文档专用模型
} else {
return activeConfig.getDefaultModel().getId();
}
}
private EmbeddingProvider createProvider(EmbeddingModel model) {
switch (model.getType()) {
case "openai":
return new OpenAIEmbeddingProvider(model);
case "huggingface":
return new HuggingFaceEmbeddingProvider(model);
case "custom":
return new CustomEmbeddingProvider(model);
default:
throw new IllegalArgumentException("Unknown model type: " + model.getType());
}
}
}3.2 动态Embedding服务
java
@Service
public class DynamicEmbeddingService {
@Autowired
private EmbeddingModelManager modelManager;
@Autowired
private EmbeddingCacheService cacheService;
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 生成向量(自动路由)
*/
public EmbeddingResult generate(String content, String modelId) {
// 1. 检查缓存
EmbeddingResult cached = cacheService.get(content, modelId);
if (cached != null) {
return cached;
}
// 2. 获取模型Provider
EmbeddingProvider provider = modelManager.getProvider(modelId);
EmbeddingModel model = modelManager.getModel(modelId);
// 3. 生成向量
long startTime = System.currentTimeMillis();
float[] embedding = provider.embed(content);
long latency = System.currentTimeMillis() - startTime;
// 4. 验证维度
if (embedding.length != model.getDimension()) {
throw new DimensionMismatchException(
String.format("模型 %s 期望维度 %d,实际生成 %d",
modelId, model.getDimension(), embedding.length)
);
}
// 5. 缓存结果
EmbeddingResult result = new EmbeddingResult(embedding, modelId, model.getDimension());
cacheService.put(content, modelId, result);
// 6. 记录指标
recordMetrics(modelId, latency, embedding.length);
return result;
}
/**
* 批量生成(支持不同模型)
*/
public Map<String, List<EmbeddingResult>> batchGenerate(
List<String> contents,
String modelId,
BatchStrategy strategy) {
Map<String, List<EmbeddingResult>> results = new HashMap<>();
switch (strategy) {
case SEQUENTIAL:
// 串行处理
for (String content : contents) {
results.computeIfAbsent(content, k -> new ArrayList<>())
.add(generate(content, modelId));
}
break;
case PARALLEL:
// 并行处理
results = contents.parallelStream()
.collect(Collectors.toMap(
content -> content,
content -> List.of(generate(content, modelId))
));
break;
case BATCH_API:
// 使用批量API
List<float[]> batchEmbeddings = provider.batchEmbed(contents);
for (int i = 0; i < contents.size(); i++) {
results.computeIfAbsent(contents.get(i), k -> new ArrayList<>())
.add(new EmbeddingResult(batchEmbeddings.get(i), modelId, model.getDimension()));
}
break;
}
return results;
}
/**
* 智能路由:根据内容选择最佳模型
*/
public EmbeddingResult generateWithRouting(String content) {
// 1. 分析内容特征
ContentFeatures features = analyzeContent(content);
// 2. 选择模型
String selectedModel = selectModelByFeatures(features);
// 3. 生成向量
return generate(content, selectedModel);
}
private ContentFeatures analyzeContent(String content) {
return ContentFeatures.builder()
.length(content.length())
.language(detectLanguage(content))
.hasCode(containsCode(content))
.hasLegalTerms(containsLegalTerms(content))
.build();
}
private String selectModelByFeatures(ContentFeatures features) {
if (features.isHasCode()) {
return "codebert";
} else if (features.isHasLegalTerms()) {
return "bge-large-zh";
} else if (features.getLength() < 100) {
return "text-embedding-3-small"; // 短文本用小模型
} else {
return modelManager.getDefaultModelId();
}
}
}3.3 多维度存储策略
java
@Service
public class MultiDimensionVectorStore {
/**
* 存储文档向量(支持多模型)
*/
@Transactional
public void store(PolicyDocument doc, List<String> chunks, List<String> modelIds) {
for (String modelId : modelIds) {
// 1. 为每个模型生成向量
List<EmbeddingResult> embeddings = embeddingService.batchGenerate(chunks, modelId);
// 2. 批量存储
String sql = """
INSERT INTO document_embeddings
(doc_id, chunk_id, model_id, content, embedding, actual_dimension, metadata)
VALUES (?, ?, ?, ?, ?::vector, ?, ?::jsonb)
""";
List<Object[]> batchArgs = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
EmbeddingResult result = embeddings.get(i);
batchArgs.add(new Object[]{
doc.getId(),
generateChunkId(doc.getId(), i),
modelId,
chunks.get(i),
arrayToString(result.getEmbedding()),
result.getDimension(),
buildMetadata(doc, i)
});
}
jdbcTemplate.batchUpdate(sql, batchArgs);
}
}
/**
* 多模型混合检索
*/
public List<SearchResult> hybridSearch(String query, List<String> modelIds, int topK) {
Map<String, List<SearchResult>> resultsByModel = new HashMap<>();
// 1. 使用不同模型检索
for (String modelId : modelIds) {
float[] queryEmbedding = embeddingService.generate(query, modelId);
List<SearchResult> results = searchByModel(queryEmbedding, modelId, topK);
resultsByModel.put(modelId, results);
}
// 2. 结果融合(RRF算法)
return fuseResults(resultsByModel, topK);
}
/**
* 结果融合:Reciprocal Rank Fusion
*/
private List<SearchResult> fuseResults(Map<String, List<SearchResult>> resultsByModel, int topK) {
Map<String, Double> scoreMap = new HashMap<>();
for (Map.Entry<String, List<SearchResult>> entry : resultsByModel.entrySet()) {
List<SearchResult> results = entry.getValue();
for (int i = 0; i < results.size(); i++) {
String chunkId = results.get(i).getChunkId();
double rrfScore = 1.0 / (i + 60); // 60是常数,避免除零
scoreMap.merge(chunkId, rrfScore, Double::sum);
}
}
return scoreMap.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.limit(topK)
.map(entry -> getSearchResultById(entry.getKey()))
.collect(Collectors.toList());
}
}3.4 缓存与性能优化
java
@Service
public class EmbeddingCacheService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private JdbcTemplate jdbcTemplate;
private final Cache<String, EmbeddingResult> localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(Duration.ofHours(1))
.recordStats()
.build();
/**
* 多级缓存
*/
public EmbeddingResult get(String content, String modelId) {
String key = buildKey(content, modelId);
// L1: 本地缓存
EmbeddingResult result = localCache.getIfPresent(key);
if (result != null) {
return result;
}
// L2: Redis缓存
String cached = redisTemplate.opsForValue().get(key);
if (cached != null) {
result = JsonUtils.fromJson(cached, EmbeddingResult.class);
localCache.put(key, result);
return result;
}
// L3: 数据库缓存
result = loadFromDatabase(content, modelId);
if (result != null) {
redisTemplate.opsForValue().set(key, JsonUtils.toJson(result), Duration.ofDays(7));
localCache.put(key, result);
}
return result;
}
/**
* 预热缓存
*/
@Async
public void warmupCache(List<String> frequentQueries, List<String> modelIds) {
for (String query : frequentQueries) {
for (String modelId : modelIds) {
CompletableFuture.supplyAsync(() ->
embeddingService.generate(query, modelId)
).thenAccept(result -> {
cache.put(query, modelId, result);
});
}
}
}
}3.5 配置管理
yaml
# application.yml
embedding:
strategy: dynamic # static, dynamic, hybrid
default-model: bge-large-zh
fallback-model: text-embedding-3-small
models:
bge-large-zh:
dimension: 1024
endpoint: http://localhost:8080/embed/bge
priority: 1
enabled: true
text-embedding-3-small:
dimension: 1536
endpoint: https://api.openai.com/v1/embeddings
api-key: ${OPENAI_API_KEY}
priority: 2
enabled: true
multilingual-e5:
dimension: 768
endpoint: http://localhost:8080/embed/e5
priority: 3
enabled: false
routing:
enabled: true
rules:
- pattern: ".*(代码|函数|class).*"
model: codebert
- pattern: ".*(第[零一二三四五六七八九十]+条|法规|政策).*"
model: bge-large-zh
- pattern: ".*"
model: text-embedding-3-small3.6 API接口
java
@RestController
@RequestMapping("/api/embedding")
public class EmbeddingController {
@Autowired
private DynamicEmbeddingService embeddingService;
@Autowired
private EmbeddingModelManager modelManager;
/**
* 生成向量(指定模型)
*/
@PostMapping("/generate")
public Result<EmbeddingResponse> generate(@RequestBody GenerateRequest request) {
EmbeddingResult result = embeddingService.generate(
request.getContent(),
request.getModelId()
);
return Result.success(new EmbeddingResponse(result));
}
/**
* 智能路由生成
*/
@PostMapping("/route")
public Result<EmbeddingResponse> generateWithRoute(@RequestBody String content) {
EmbeddingResult result = embeddingService.generateWithRouting(content);
return Result.success(new EmbeddingResponse(result));
}
/**
* 动态切换模型
*/
@PostMapping("/switch")
public Result<Void> switchModel(@RequestBody SwitchRequest request) {
modelManager.switchModel(request.getModelId(), request.getStrategy());
return Result.success();
}
/**
* 模型对比测试
*/
@PostMapping("/compare")
public Result<CompareResult> compareModels(@RequestBody CompareRequest request) {
List<ModelPerformance> performances = new ArrayList<>();
for (String modelId : request.getModelIds()) {
long startTime = System.currentTimeMillis();
List<EmbeddingResult> results = embeddingService.batchGenerate(
request.getTestQueries(),
modelId,
BatchStrategy.PARALLEL
);
long latency = System.currentTimeMillis() - startTime;
performances.add(ModelPerformance.builder()
.modelId(modelId)
.avgLatencyMs(latency / request.getTestQueries().size())
.dimension(results.get(0).getDimension())
.build());
}
return Result.success(new CompareResult(performances));
}
}四、运维与监控
4.1 监控指标
java
@Component
public class EmbeddingMetrics {
private final MeterRegistry meterRegistry;
// 记录各模型的使用情况
public void recordModelUsage(String modelId, long latency, boolean success) {
Timer.Sample sample = Timer.start(meterRegistry);
meterRegistry.counter("embedding.requests.total",
"model", modelId,
"status", success ? "success" : "failure"
).increment();
meterRegistry.timer("embedding.latency",
"model", modelId
).record(Duration.ofMillis(latency));
}
// 记录维度转换
public void recordDimensionTransform(int fromDim, int toDim) {
meterRegistry.counter("embedding.dimension.transform",
"from", String.valueOf(fromDim),
"to", String.valueOf(toDim)
).increment();
}
}4.2 降级策略
java
@Component
public class EmbeddingFallback {
@Autowired
private EmbeddingModelManager modelManager;
@Bean
public CircuitBreaker embeddingCircuitBreaker() {
return CircuitBreaker.of("embedding-service",
FailureRateThreshold.of(50),
SlowCallRateThreshold.of(50),
SlowCallDurationThreshold.of(Duration.ofSeconds(5)),
WaitDuration.of(Duration.ofSeconds(30)),
PermittedNumberOfCallsInHalfOpenState.of(5)
);
}
@CircuitBreaker(name = "embedding-service", fallbackMethod = "fallbackEmbed")
public float[] embedWithFallback(String content, String modelId) {
return embeddingService.generate(content, modelId).getEmbedding();
}
private float[] fallbackEmbed(String content, String modelId, Exception e) {
log.warn("模型 {} 调用失败,切换到备用模型", modelId, e);
String fallbackModel = modelManager.getFallbackModelId();
return embeddingService.generate(content, fallbackModel).getEmbedding();
}
}五、最佳实践总结
5.1 实施步骤
-
阶段一(准备)
-
评估业务场景,选择合适的模型组合
-
设计支持多维度的数据库表结构
-
实现基础的模型管理功能
-
-
阶段二(灰度)
-
新模型与旧模型并行运行
-
对比检索效果和性能指标
-
小流量验证
-
-
阶段三(切换)
-
全量切换到新模型
-
逐步淘汰旧数据
-
持续监控效果
-
5.2 注意事项
| 要点 | 说明 |
|---|---|
| 维度转换 | 不同维度向量不能直接比较,需要转换或重新生成 |
| 存储成本 | 多模型存储会增加存储成本,需评估必要性 |
| 缓存策略 | 不同模型的向量不能混用缓存key |
| 一致性 | 同一文档的不同模型版本要能关联 |
| 兼容性 | 旧数据需要平滑迁移到新模型 |
5.3 适用场景判断
强烈推荐动态切换:
-
✅ 需要A/B测试不同模型效果
-
✅ 业务场景多样,需要不同模型处理
-
✅ 需要灰度发布新模型
-
✅ 对成本敏感,需要按场景选择模型
不需要动态切换:
-
❌ 单一业务场景,模型固定
-
❌ 资源有限,维护多模型成本高
-
❌ 对延迟极度敏感(多模型增加复杂度)
六、总结
动态切换Embedding模型和向量维度是一个高投入、高回报的架构设计。它能让你的RAG系统具备:
-
灵活性:随时切换最优模型
-
可靠性:故障自动降级
-
可观测性:对比不同模型效果
-
成本可控:按场景选择性价比模型
但也要注意,这会增加系统复杂度。建议从双模型并行开始,验证效果后再逐步扩展。
关于作者
Java资深开发工程师架构师。目前正在建设企业级RAG平台,欢迎交流探讨。
互动话题
你在构建RAG系统时遇到过哪些坑?欢迎在评论区分享你的经验。