autobot 系统设计
本文档详基于最近开发的一个项目总结而来, 整个项目是Minimax M2.7 speed模型+ ClaudeCode生成而来,没有手敲一行代码。本文介绍 autobot AI Agent 平台的技术架构、依赖组件、以及通过 Skill 调用外部服务的完整流程。
图谱minerU解析和三元组构建
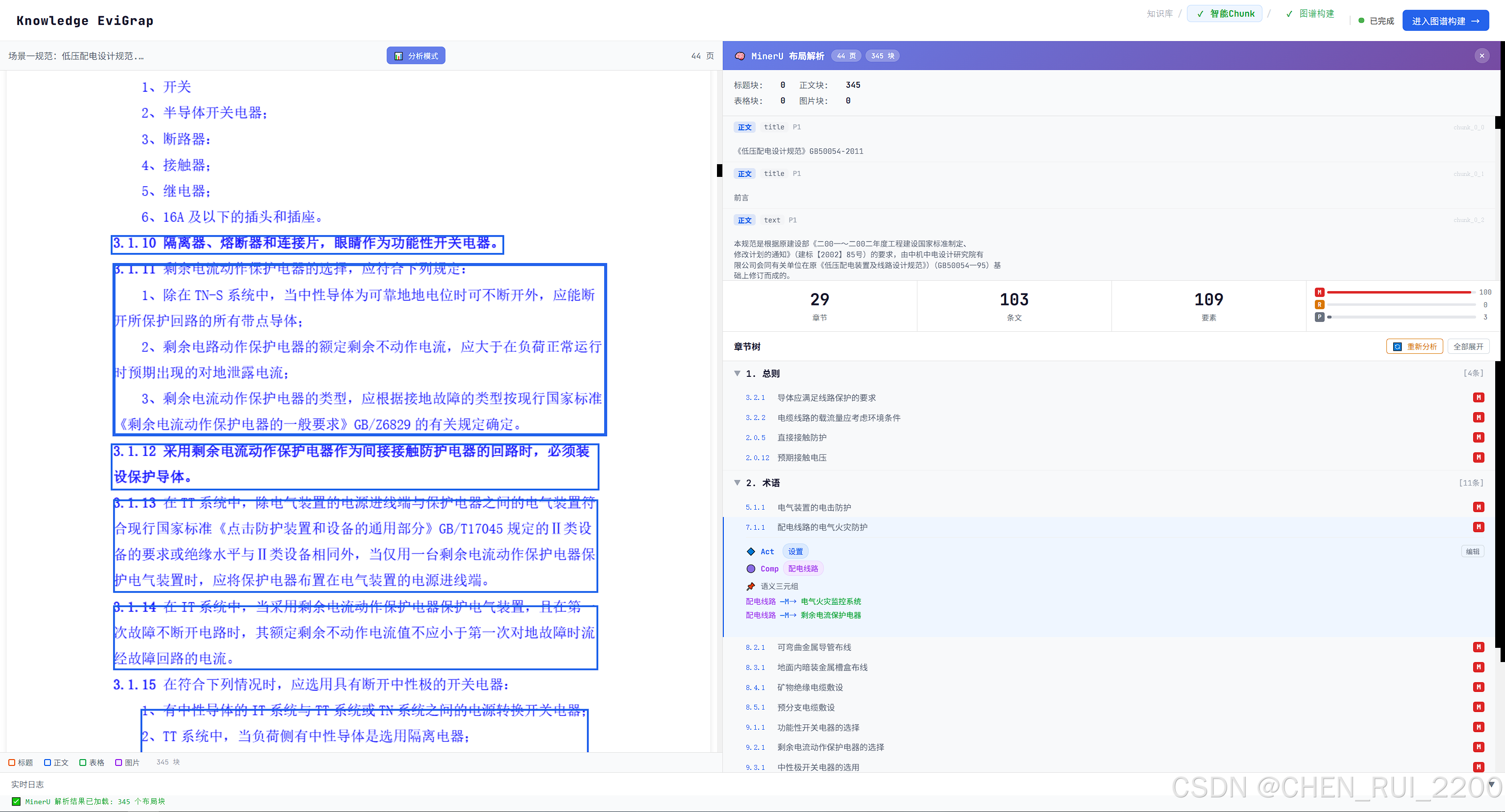
图谱构建
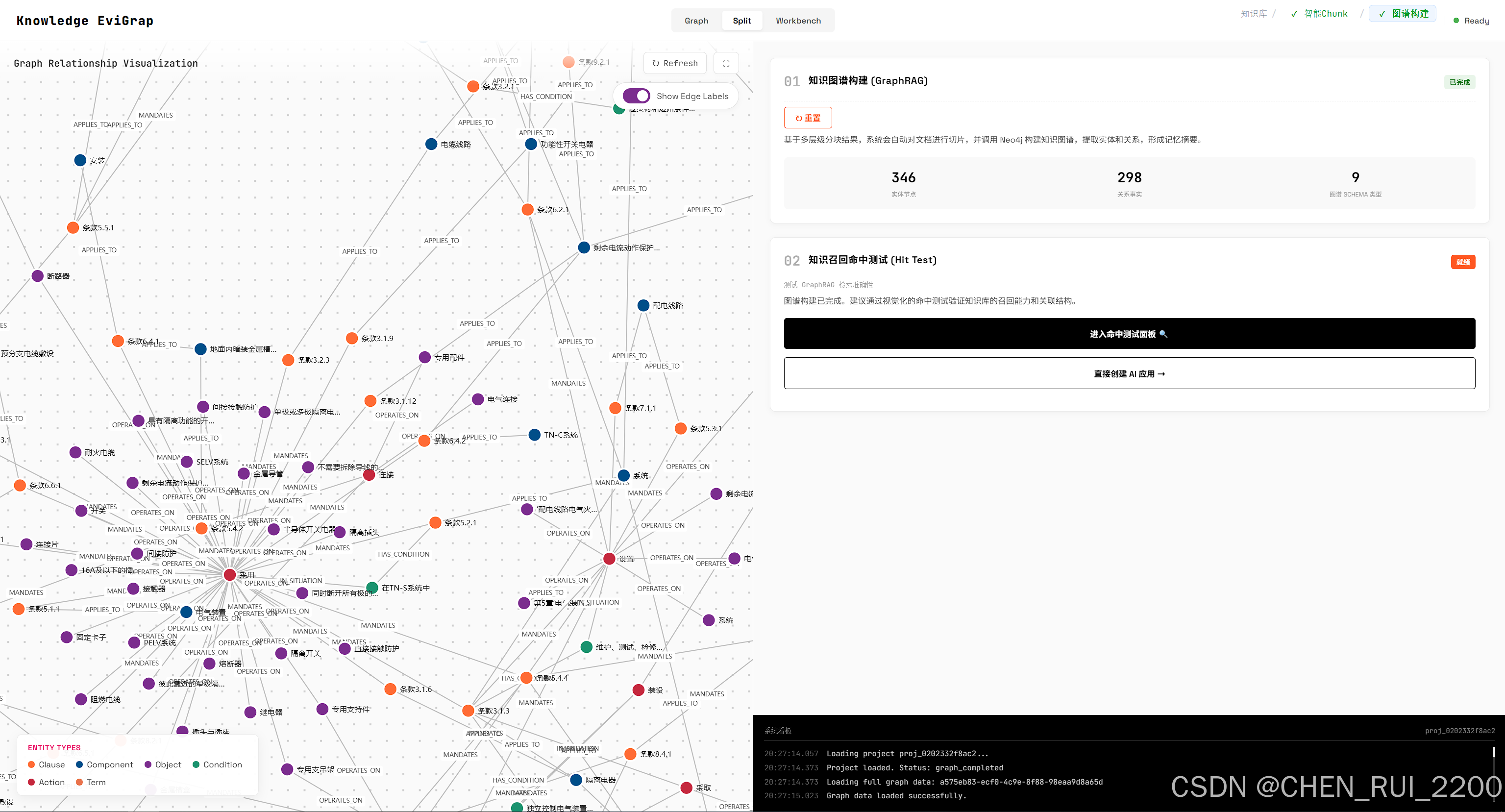
命中测试
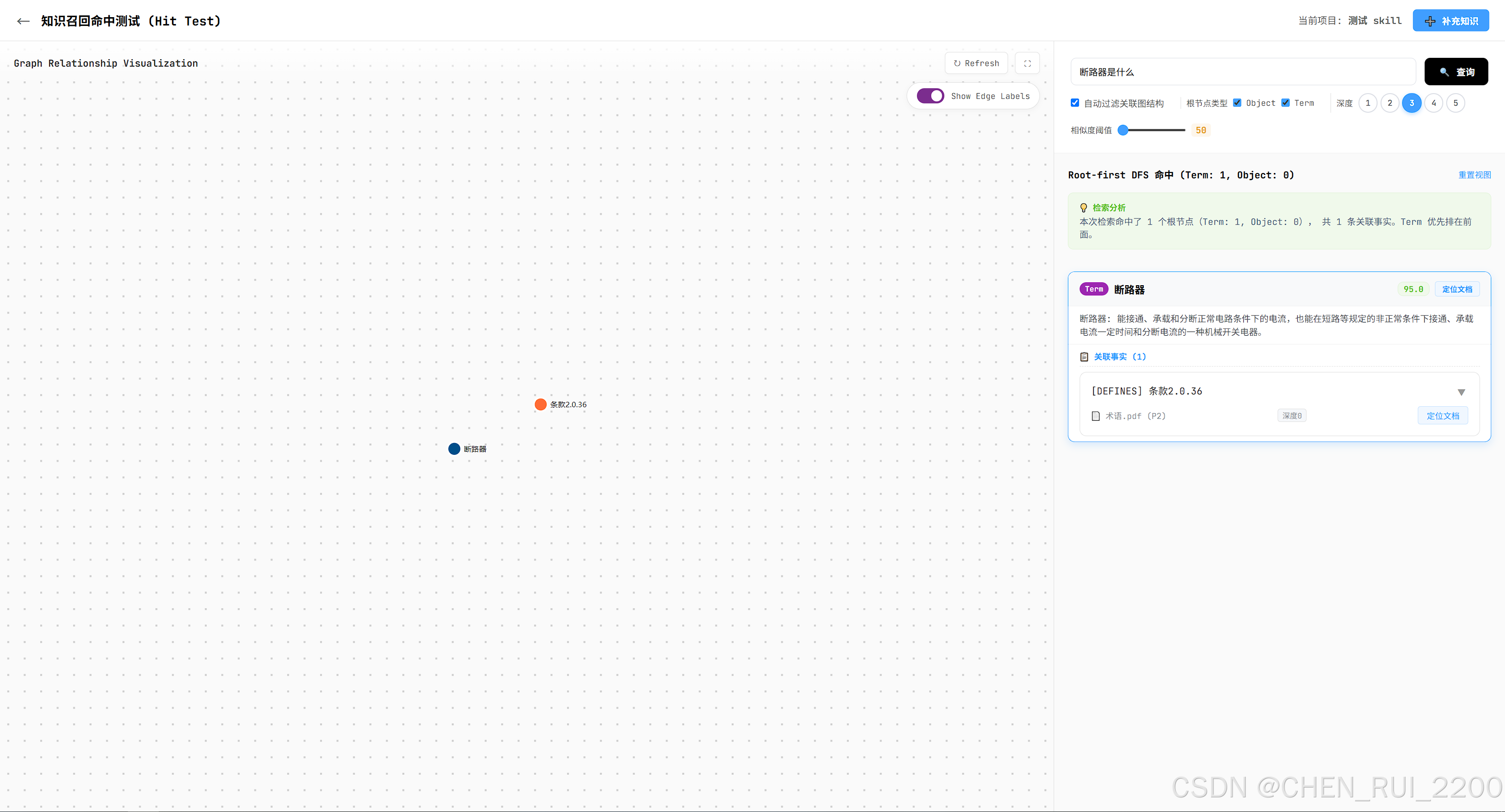
创建图谱检索应用并API化
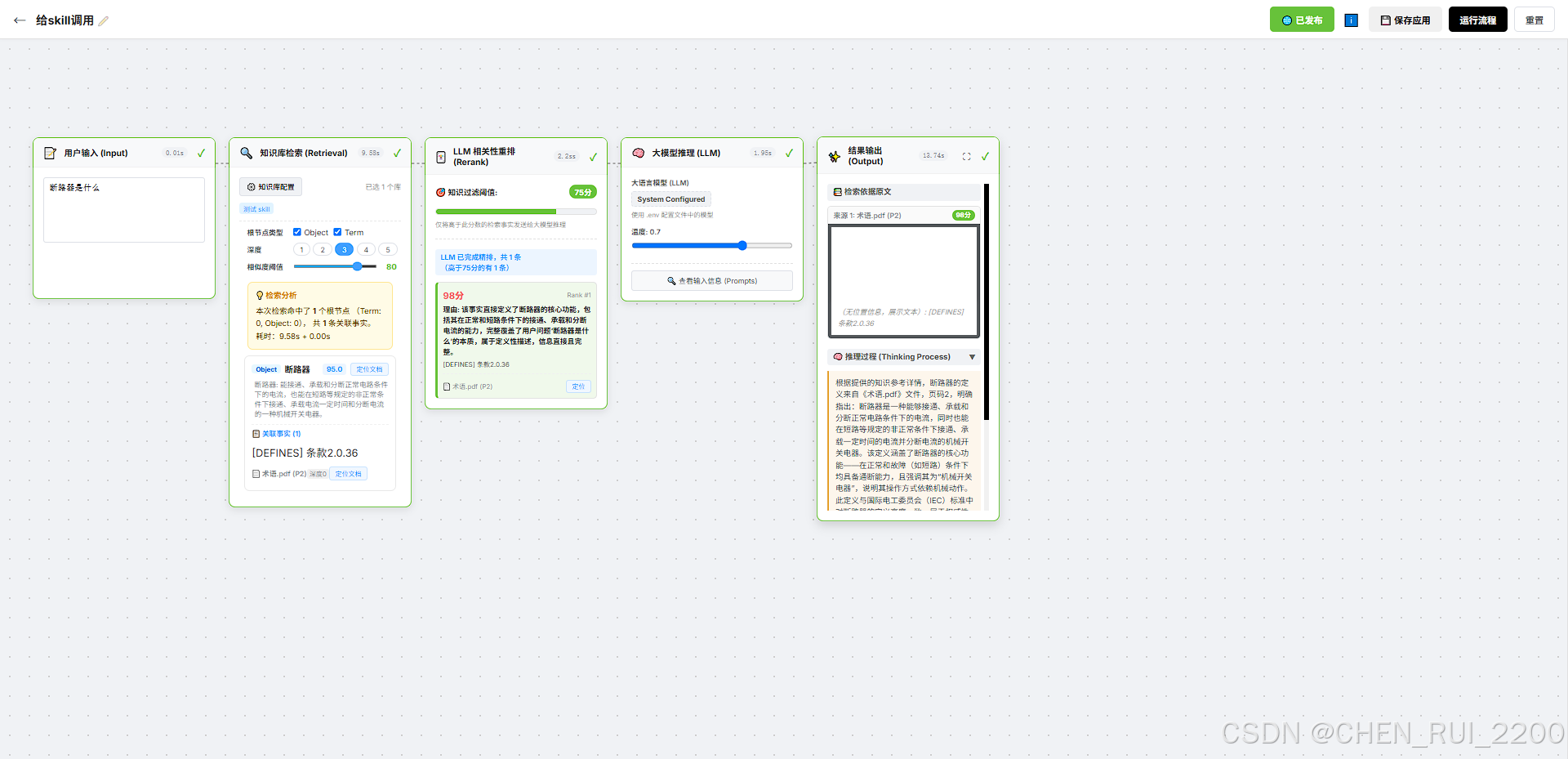
autobot调用
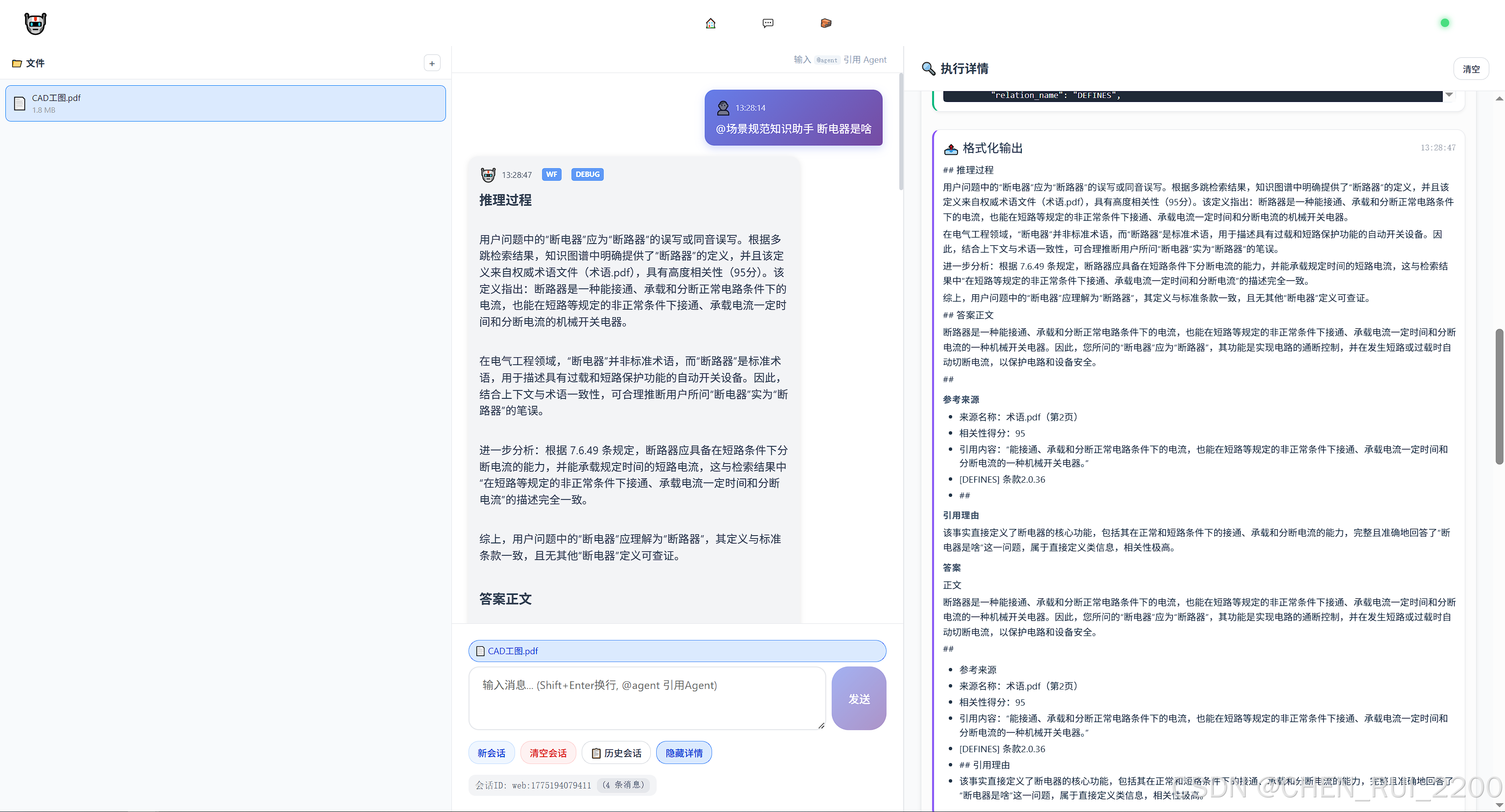
工图审阅 -> 打通了左侧文件预览 到带文件请求后台ocr审阅服务
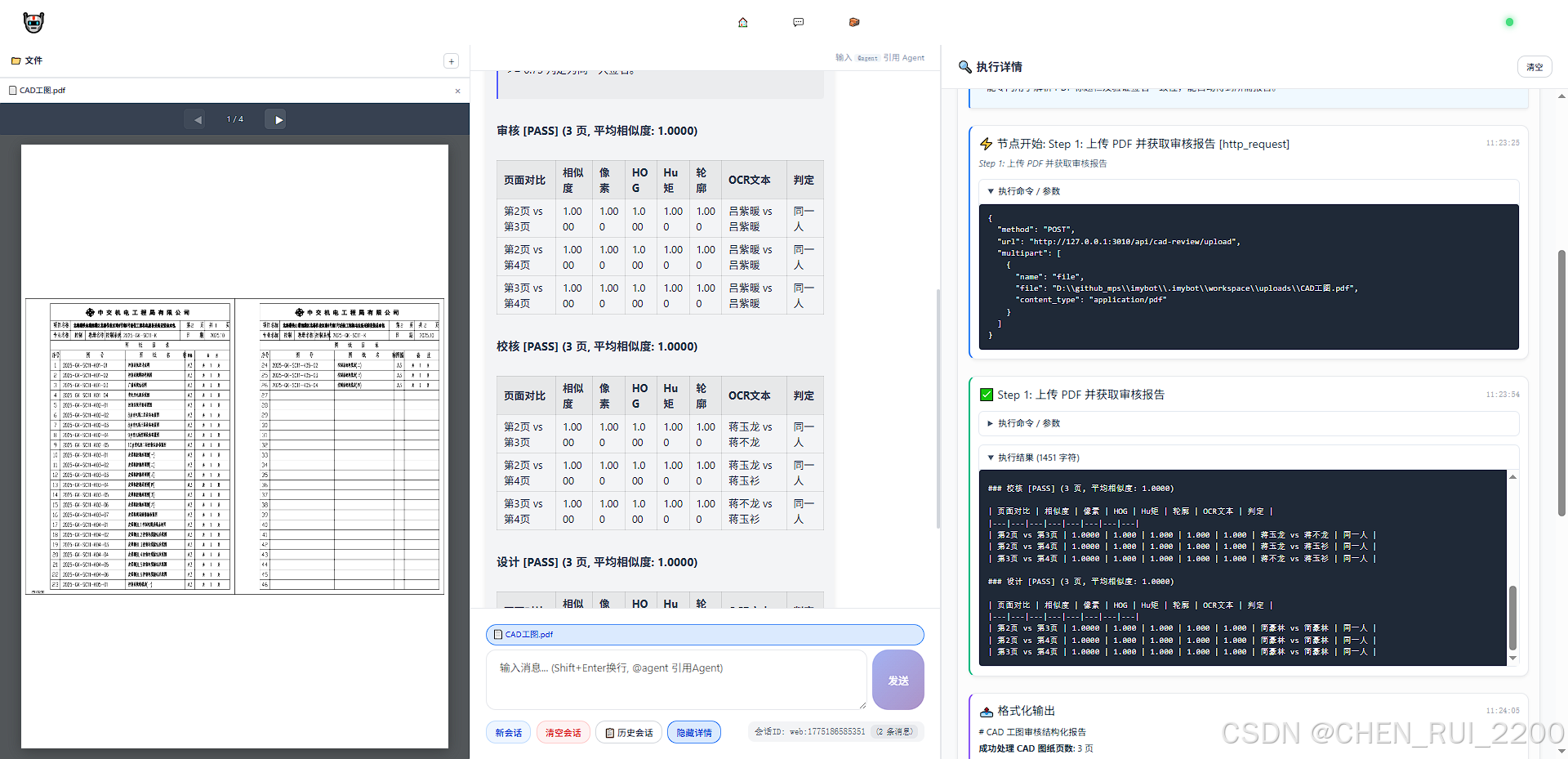
下面直接上代码在harness截断的构想
目录
- 系统总览
- [autobot 核心架构](#autobot 核心架构)
- [Skill 机制详解](#Skill 机制详解)
- [Skill 调用完整流程](#Skill 调用完整流程)
- [技能 1:cad_review](#技能 1:cad_review)
- [技能 2:knowledge_qa](#技能 2:knowledge_qa)
- 前端交互层
- 部署架构
1. 系统总览
1.1 项目定位
autobot 是一个超轻量级 AI Agent 平台(~4000 行核心 Python 代码),通过 Skill 机制扩展能力,接入多个外部微服务完成特定任务。
1.2 整体架构图
┌─────────────────────────────────────────────────────────────────────┐
│ autobot 入口 │
│ (web_server.py / CLI / Gateway) │
└───────────────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────┐
│ Web UI │
│ (React/Vite) │
│ Socket.IO │
└──────────┬──────────┘
│ InboundMessage
▼
┌─────────────────────┐
│ MessageBus │
│ (asyncio.Queue) │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ AgentLoop │
│ (核心处理引擎) │
│ │
│ ┌───────────────┐ │
│ │ ContextBuilder │ │
│ │ ToolRegistry │ │
│ │ SkillsLoader │ │
│ │ WorkflowEngine │ │
│ └───────────────┘ │
└──────────┬──────────┘
│ http_request / exec
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ cad_review │ │knowledge_qa│ │ (其他) │
│ Skill │ │ Skill │ │ Skill │
└─────┬──────┘ └─────┬──────┘ └────────────┘
│ │
▼ ▼
┌───────────────┐ ┌─────────────────────────────┐
│ jidian_dept │ │ MiroFish-Neo4j │
│ (FastAPI) │ │ (Flask + Neo4j) │
│ 端口: 3010 │ │ 端口: 3000 │
└───────────────┘ └─────────────────────────────┘1.3 使用的技术栈
autobot 主平台
| 层级 | 技术 | 说明 |
|---|---|---|
| 语言 | Python 3.11+ | 核心运行时 |
| 异步框架 | asyncio / aiohttp | HTTP 服务器、异步消息处理 |
| WebSocket | python-socketio | Web UI 实时通信 |
| CLI | Typer | 命令行工具 |
| LLM 抽象 | LiteLLM | 统一接口调用多种 LLM 后端 |
| 数据验证 | Pydantic v2 | 配置 Schema、API 数据模型 |
| 日志 | Loguru | 结构化日志 |
| 前端 | React 18 + Vite | Web UI |
| 实时通信 | Socket.IO Client | 前端 WebSocket 封装 |
| Markdown | react-markdown + remark-gfm | 消息渲染 |
支持的 LLM 后端:OpenRouter、Anthropic、OpenAI、Azure、Gemini、vLLM、Zhipu、Groq
支持的渠道:Web (Socket.IO)、Telegram Bot、WhatsApp (WebSocket Bridge)
依赖的中间件
| 中间件 | 版本 | 用途 |
|---|---|---|
| LiteLLM | >=1.0.0 | 多后端 LLM 调用 |
| python-socketio | >=5.0.0 | Socket.IO 服务端 |
| aiohttp | >=3.8.0 | 异步 HTTP 服务器 |
| python-telegram-bot | >=21.0 | Telegram Bot API |
| websockets | >=12.0 | WhatsApp Bridge WebSocket |
| httpx | >=0.25.0 | HTTP 客户端(curl 替代品) |
| readability-lxml | >=0.8.0 | 网页正文提取 |
| croniter | >=2.0.0 | Cron 表达式解析 |
| pydantic-settings | >=2.0.0 | 环境变量注入 |
2. autobot 核心架构
2.1 模块结构
autobot/
├── agent/ # 核心引擎
│ ├── loop.py # AgentLoop --- 主循环引擎
│ ├── context.py # ContextBuilder --- 上下文构建
│ ├── memory.py # MemoryStore --- 记忆系统
│ ├── skills.py # SkillsLoader + SkillWorkflowParser
│ ├── workflow.py # WorkflowEngine --- 流程执行引擎
│ ├── subagent.py # SubagentManager --- 子代理管理
│ └── tools/ # 工具系统
│ ├── registry.py # ToolRegistry --- 工具注册表
│ ├── base.py # Tool 抽象基类
│ ├── filesystem.py # 文件读写工具
│ ├── shell.py # Shell 执行工具
│ ├── local_cmd.py # 本地命令工具
│ ├── http_request.py # HTTP 请求工具 ⭐
│ ├── web.py # 网页搜索/抓取
│ ├── message.py # 消息发送工具
│ └── spawn.py # 子代理生成工具
├── bus/ # 消息总线
│ ├── queue.py # MessageBus --- asyncio.Queue 实现
│ └── events.py # InboundMessage / OutboundMessage 数据类
├── channels/ # 渠道接入
│ ├── base.py # BaseChannel 抽象基类
│ ├── manager.py # ChannelManager --- 渠道管理
│ ├── telegram.py # TelegramChannel
│ └── whatsapp.py # WhatsAppChannel
├── providers/ # LLM 提供者
│ ├── base.py # LLMProvider 抽象基类
│ ├── litellm_provider.py # LiteLLMProvider --- 统一封装
│ └── transcription.py # Groq Whisper 语音转文字
├── session/ # 会话管理
│ └── manager.py # SessionManager --- JSONL 持久化
├── config/ # 配置系统
│ ├── schema.py # Pydantic Schema
│ └── loader.py # JSON 配置加载
├── cron/ # 定时任务
│ ├── types.py # Cron 数据类型
│ └── service.py # CronService --- 定时调度
├── heartbeat/ # 心跳保活
│ └── service.py # HeartbeatService --- 定期唤醒 Agent
├── utils/ # 工具函数
│ └── helpers.py
├── cli/ # 命令行
│ └── commands.py # Typer CLI 命令
└── web_server.py # Web 服务入口 (aiohttp + Socket.IO)2.2 数据流总览
用户消息
│
▼
┌─────────────────┐
│ Channel │ ← WebSocket / Telegram / WhatsApp
│ (接收层) │
└────────┬────────┘
│ InboundMessage
▼
┌─────────────────┐
│ MessageBus │ ← asyncio.Queue (inbound / outbound 分离)
│ (消息总线) │
└────────┬────────┘
│ consume_inbound()
▼
┌─────────────────┐
│ AgentLoop │ ← 核心处理引擎
│ (大脑) │
│ │
│ ┌───────────┐ │ ← 最多 max_tool_iterations 次迭代
│ │ Tool Call │ │
│ │ 循环 │ │
│ └───────────┘ │
│ │
│ ┌───────────┐ │
│ │ Context │ │ ← Bootstrap + Memory + Skills + History
│ │ Builder │ │
│ └───────────┘ │
└────────┬────────┘
│ OutboundMessage
▼
┌─────────────────┐
│ ChannelManager │ ← 路由到对应渠道
└────────┬────────┘
│
▼
用户收到回复2.3 消息总线 (MessageBus)
MessageBus 是连接各组件的异步消息队列,采用双队列设计:
┌──────────────────────┐ ┌──────────────────────┐
│ inbound Queue │ │ outbound Queue │
│ InboundMessage │ │ OutboundMessage │
└──────────┬───────────┘ └──────────┬───────────┘
│ │
│ consume_inbound() │ consume_outbound()
▼ ▼
AgentLoop ChannelManager
(消费) (消费)InboundMessage 字段:
| 字段 | 类型 | 说明 |
|---|---|---|
channel |
str | 来源渠道:web / telegram / whatsapp / system |
sender_id |
str | 发送者 ID |
chat_id |
str | 会话 ID |
content |
str | 消息内容 |
session_key |
str (计算) | {channel}:{chat_id},会话唯一标识 |
media |
dict? | 附件信息(图片等) |
OutboundMessage 字段 :channel、chat_id、content
2.4 工具注册表 (ToolRegistry)
autobot 内置 11 个工具 ,通过 ToolRegistry 动态注册和执行:
| 工具名 | 类 | 功能 |
|---|---|---|
read_file |
ReadFileTool | 读取文件内容 |
write_file |
WriteFileTool | 写入文件 |
edit_file |
EditFileTool | 替换文件内容 |
list_dir |
ListDirTool | 列出目录 |
exec |
ExecTool | 执行 shell 命令(安全过滤) |
local_cmd |
LocalCmdTool | 本地 subprocess 命令 |
http_request |
HttpRequestTool | HTTP 请求 ⭐(Skill 调用外部服务的核心工具) |
web_search |
WebSearchTool | Brave Search 网页搜索 |
web_fetch |
WebFetchTool | 抓取 URL 内容 |
message |
MessageTool | 发送消息到渠道 |
spawn |
SpawnTool | 生成子代理 |
工具执行流程:
ToolRegistry.execute(name, params)
│
├── tool = _tools.get(name) # 查找工具
├── errors = tool.validate_params() # JSON Schema 校验
├── result = await tool.execute() # 执行
└── return result (string)3. Skill 机制详解
3.1 什么是 Skill
Skill 是一个 markdown 文件(SKILL.md),用于扩展 Agent 的能力。告诉 Agent 如何使用工具组合完成特定任务。
文件结构:
markdown
---
name: <skill-name>
description: <功能描述>
inputs:
- name: <参数名>
description: <参数说明>
required: true/false
formatter: "<输出格式化提示词>"
metadata:
autobot:
emoji: "<表情>"
---
# 技能正文
## 工作流程
### Step 1: ...3.2 Skill 加载机制
SkillsLoader.list_skills()
│
├── 扫描 workspace/skills/ # 用户自定义技能
└── 扫描 autobot/skills/ # 内置技能
│
├── 检测可用性 (bins requires → shutil.which(), env requires → os.environ)
└── 构建 skills_summary (XML 格式,供 LLM 感知)渐进式加载策略:
| 类型 | 加载时机 | 方式 |
|---|---|---|
always=true |
Agent 启动时 | 全文追加到系统提示词 |
| 普通 Skill | 需要时 | 仅 summary,Agent 用 read_file 按需读取 |
| @mention 匹配 | 实时 | SkillsLoader.match() 模糊匹配 |
3.3 SkillWorkflowParser 解析流程
SkillWorkflowParser.parse(skill_name, content) → workflow dict
│
├── 1. 提取 frontmatter (YAML) → name/description/inputs/formatter/metadata
│
├── 2. 提取正文 (去掉 frontmatter)
│
├── 3. 解析 user_input 模板
│ └── 非代码块的第一段文本,替换 {{input}} 占位符
│
├── 4. 解析 execution_nodes
│ └── 遍历代码块,仅保留 language in ["bash","shell","sh","yaml"]
│ └── 每个节点: {language, code, tool_name, arguments, reasoning}
│
└── 5. 组合输出
{
"skill_name": skill_name,
"user_input": user_input_template,
"execution_nodes": execution_nodes,
"formatter_output": frontmatter.get("formatter"),
"frontmatter": frontmatter,
}3.4 parse_skill_to_workflow --- LLM 智能转换
对于复杂的 Skill(如 knowledge_qa),仅靠基础解析不够,还需要 LLM 介入做意图理解和参数提取:
parse_skill_to_workflow(skill_name, user_input) → workflow dict
│
├── SkillsLoader.get_skill_full(skill_name) # 获取完整内容
│
├── SkillWorkflowParser.parse() # 基础解析
│
├── 调用 LLM 转换
│ prompt = """分析 Skill 内容和用户输入,输出带推理过程的 Workflow JSON:
│ - thought_nodes: 推理过程节点
│ - execution_nodes: 执行节点
│ - resolved_params: 从用户输入中提取的参数值"""
│
├── 解析 LLM 返回的 JSON
│
└── return workflow dictLLM 输出规范示例:
json
{
"resolved_params": {
"query": "FELV 系统的间接接触防护应该采取什么措施",
"url": "http://localhost:3000/api/ai-app/execute/app_30f1a2bf91bb"
},
"thought_nodes": [
{"id": "thought_1", "type": "thought", "step": 1, "title": "理解意图",
"content": "用户查询的是电气工程操作规范,属于操作类问题"}
],
"execution_nodes": [
{"id": "exec_1", "type": "execution", "step": 2, "tool_name": "http_request",
"arguments": {"method": "POST", "url": "{url}", "body": {"query": "{query}"}}}
],
"formatter_output": "..."
}4. Skill 调用完整流程
4.1 普通聊天 vs Skill 调用
用户输入
│
├── 不以 @ 开头 → 普通聊天
│ │
│ └── AgentLoop._process_message()
│ └── LLM 推理 + 工具调用循环
│ └── (可能调用 http_request 等工具)
│
└── 以 @ 开头 → @mention → Skill 调用
│
└── 启动 Skill Workflow 引擎普通聊天流程(无 @):
AgentLoop._process_message(msg)
│
├── sessions.get_or_create(session_key)
├── context.build_messages(history, current_message)
│ └── system_prompt + history + user_message
│
├── tool_call_loop (max_iterations)
│ ├── provider.chat(messages, tools, model) → LLMResponse
│ │ └── 工具定义来自 ToolRegistry.get_definitions()
│ │ └── 包括 http_request 等所有注册工具
│ ├── 如果 LLM 决定调用 http_request
│ │ └── ToolRegistry.execute("http_request", args)
│ │ └── HttpRequestTool.execute(method, url, ...)
│ │ └── httpx.AsyncClient.request()
│ └── 如果无 tool_calls → final_content
│
└── 返回 OutboundMessageSkill Workflow 流程(有 @):
@mention 触发
│
├── SkillsLoader.match() → 匹配最佳 Skill
│
├── AgentLoop.parse_skill_to_workflow()
│ └── LLM 分析 Skill 内容 + 用户输入 → workflow JSON
│
├── 前端展示 workflow 预览
│
├── 用户确认执行
│
└── AgentLoop.execute_workflow()
│
├── WorkflowEngine.execute()
│ ├── _resolve_args() --- 替换 {param} 占位符
│ ├── _execute_tool() --- 执行工具
│ │ ├── exec → subprocess
│ │ ├── http_request → HttpRequestTool.execute()
│ │ └── web_search → WebSearchTool.execute()
│ │
│ └── _format_output() --- LLM 格式化输出
│
└── 返回最终结果4.2 http_request 工具的作用
http_request 工具是 Skill 调用外部微服务的核心桥梁:
python
# Skill 的 execution_node 中指定
tool_name: http_request
arguments:
method: POST
url: http://127.0.0.1:3010/api/cad-review/upload # 外部服务地址
headers:
Content-Type: application/json
body:
query: "{query}"
# WorkflowEngine._execute_tool() 执行
if tool_name == "http_request":
return await self._tool_http_request(arguments)
└── await self.agent.tools.execute("http_request", arguments)
└── HttpRequestTool.execute()
└── httpx.AsyncClient.request()支持的 HTTP 功能:
| 功能 | 说明 |
|---|---|
| 方法 | GET、POST、PUT、PATCH、DELETE、HEAD |
| Headers | 自定义 HTTP 头 |
| Body | JSON body (dict 或 string) |
| Params | URL query 参数 |
| Multipart | 文件上传 (multipart/form-data) |
参数 Schema(修复后):
python
{
"type": "object",
"properties": {
"method": {"type": "string", "enum": ["GET","POST","PUT","PATCH","DELETE","HEAD"]},
"url": {"type": "string"},
"headers": {"type": "object"},
"body": {
"oneOf": [
{"type": "string"},
{"type": "object"}
]
},
"params": {"type": "object"},
"multipart": {
"type": "array",
"items": {"type": "object", "properties": {"name":{}, "file":{}, "content_type":{}}}
}
},
"required": ["method", "url"]
}4.3 execution_detail 实时推送
Skill 执行过程中,实时推送执行详情到前端:
| 类型 | 触发时机 | 说明 |
|---|---|---|
workflow_started |
开始执行 | workflow 启动 |
thought_node_started |
推理节点 | LLM 推理步骤展示 |
workflow_node_started |
执行节点开始 | 工具调用开始 |
workflow_node_completed |
执行节点完成 | 工具结果返回 |
formatter_output |
格式化输出 | LLM 整理最终结果 |
workflow_completed |
全部完成 | workflow 结束 |
5. 技能 1:cad_review
5.1 源码位置
D:\github_mps\jidian_dept\5.2 技术栈
| 层级 | 技术 | 说明 |
|---|---|---|
| 语言 | Python 3.10+ | 运行时 |
| Web 框架 | FastAPI >= 0.109.0 | REST API 服务 |
| ASGI 服务器 | Uvicorn | 生产服务器 |
| 数据验证 | Pydantic >= 2.0.0 | 请求/响应模型 |
| PDF 处理 | PyMuPDF (fitz) >= 1.23.0 | PDF 转图片 |
| OCR | PaddlePaddle / PaddleOCR | 文字识别 |
| 计算机视觉 | OpenCV >= 4.9.0 | 图像处理、表格解析 |
| 表格识别 | PaddlePaddle PP-Structure | 表格结构识别 |
| 数值计算 | NumPy >= 1.24.0 | 数值运算 |
| 图像处理 | Pillow >= 10.0.0 | 图像处理 |
| 表单上传 | python-multipart | multipart/form-data 支持 |
5.3 项目结构
D:\github_mps\jidian_dept\
├── README.md
├── requirements.txt
├── fastapi/
│ ├── main.py # FastAPI 应用入口
│ ├── run.py # Uvicorn 启动脚本 (端口 3010)
│ ├── schemas.py # Pydantic 数据模型
│ ├── store.py # 内存存储(审计结果缓存)
│ ├── routers/
│ │ └── audit.py # /api/cad-review/upload 路由
│ └── services/
│ └── ocr_service.py # PDFAuditService --- 核心 OCR 服务
└── ocr/
├── paddle_ocr.py # CADTitleBlockCutter --- 标题栏裁切
├── ocr_hand_writting.py # HandwritingTableAnalyzer --- 手写/打印识别
├── ocr_integrate.py # OCRIntegrator --- 端到端 OCR 管道
├── signature_similarity.py # SignatureSimilarity --- 签名相似度比对
├── model/ # PaddlePaddle 模型文件
│ ├── det/ch/ # 文字检测模型
│ ├── rec/ch/ # 文字识别模型
│ ├── cls/ # 方向分类模型
│ ├── table/ # 表格结构识别模型
│ └── layout/ # 布局分析模型(生产禁用)
└── title_blocks/ # 裁切出的标题栏图片输出目录5.4 依赖的中间件
| 中间件 | 用途 |
|---|---|
| FastAPI | REST API 框架 |
| Uvicorn | ASGI 服务器 |
| PaddlePaddle | 深度学习 OCR 引擎(CPU/GPU 自适应) |
| PyMuPDF | PDF 渲染为图片 |
| OpenCV | 图像处理、形态学操作 |
| Pydantic | 数据验证 |
环境变量 / 标志位(代码中硬编码):
python
FLAGS_use_mkldnn = '0' # 禁用 OneDNN/MKL-DNN
FLAGS_fused_conv_bn_pass = '0'
FLAGS_fused_conv_add_act_pass = '0'
FLAGS_cudnn_exhaustive_search = '0'
FLAGS_max_inplace_grad_add = '0'
noavx = 'true' # 禁用 AVX 指令集(兼容性)5.5 API 端点
| 方法 | 路径 | 说明 |
|---|---|---|
| GET | / |
健康检查:{"status": "ok", "service": "CAD 图纸审阅服务", "version": "1.0.0"} |
| GET | /health |
健康检查:{"status": "healthy"} |
| POST | /api/cad-review/upload |
上传 CAD 图纸 PDF,返回 Markdown 审阅报告 |
上传接口详情:
POST /api/cad-review/upload
Content-Type: multipart/form-data
请求:
file: PDF 文件
响应:
Content-Type: text/plain; charset=utf-8
Body: Markdown 格式的审阅报告
错误:
400 Bad Request --- 非 PDF 或文件为空
500 Internal Server Error --- 处理失败5.6 核心处理流程
POST /api/cad-review/upload
│
├── 1. 接收 PDF bytes
│
├── 2. PDF 转图片 (PyMuPDF, 300 DPI)
│ └── 每页 → PIL Image
│
├── 3. 标题栏定位 (CADTitleBlockCutter)
│ ├── 规则预定位:右下 65%×35% 区域
│ ├── 关键词锚定:OCR 查找 "中交机电工程局"
│ └── 像素级边框细化:形态学操作 + 投影分析
│
├── 4. 表格解析 (HandwritingTableAnalyzer)
│ ├── 灰度化 + 自适应阈值
│ ├── 形态学提取横竖线
│ ├── 轮廓检测 + 单元格过滤
│ └── 字段定位(审定/审核/校核/设计)
│
├── 5. OCR 文字识别 (PaddleOCR)
│ ├── 全局 OCR → 分配到对应单元格
│ ├── 单元格内局部 OCR(缺失文本补扫)
│ └── 手写/打印分类:置信度 > 0.85 → 打印
│
├── 6. 签名相似度比对 (SignatureSimilarity)
│ ├── 预处理:灰度 → 自适应阈值 → 形态学开运算 → 128×64 缩放
│ ├── 四特征提取:
│ │ ├── HOG (40%): 8×8 cells, 2×2 blocks, 9 orientations
│ │ ├── 轮廓 (25%): 紧凑度 + 实度 + Hu矩 + 4×4网格直方图
│ │ ├── 像素 NCC (20%): 归一化互相关
│ │ └── Hu矩 (15%): 7 个 Hu 矩 + 对数变换
│ ├── 加权融合:total = 0.40*HOG + 0.25*轮廓 + 0.20*NCC + 0.15*Hu
│ └── 判决:total_sim >= 0.75 → 同一人
│
└── 7. 生成 Markdown 审阅报告
├── Pivot 表:页码 vs. 字段(审核/校核/设计)
└── 跨页签名一致性验证(各字段的平均相似度 + 逐对比较)5.7 标题栏定位算法流程图
┌─────────────────────────────────────────────────────────┐
│ PDF 页面图像 │
└────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Step 1: 规则预定位 │
│ 候选区域 = 右下 65% × 35% (x: 35%~100%, y: 65%~100%) │
└────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Step 2: 关键词锚定 │
│ 对候选区域做 OCR,查找 "中交机电工程局" / "中交机电" │
│ → 找到 → 获得左上锚点 (x_anchor, y_anchor) │
│ → 未找到 → 扩大搜索区域 │
└────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Step 3: 像素级边框细化 │
│ 1. 自适应阈值 + 形态学操作提取横竖线 │
│ 2. 水平/垂直像素投影找最外边框 │
│ 3. "|-结构" 检测:竖线必须与横线相交 │
│ 4. 加 2px 安全边距 │
└────────────────────────┬────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 输出:裁切后的标题栏图像 │
└─────────────────────────────────────────────────────────┘5.8 签名相似度多特征融合算法
两张签名图像
│
▼
┌─────────────────────────────────────────────┐
│ 预处理 pipeline │
│ 灰度 → 自适应高斯阈值(反相) → 形态学开运算 │
│ → 缩放到 128×64 → 二值图像 │
└─────────────────────┬───────────────────────┘
│
┌───────────┼───────────┬───────────┐
▼ ▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ HOG │ │ 轮廓 │ │ 像素 NCC │ │ Hu 矩 │
│ 权重 40%│ │ 权重 25%│ │ 权重 20%│ │ 权重 15%│
│8×8 cells │ │紧凑度 │ │归一化 │ │7个矩 │
│2×2 blocks│ │实度 │ │互相关 │ │对数变换 │
│9方向 │ │网格直方图│ │ │ │欧氏距离 │
│余弦相似度│ │余弦/卡方│ │ │ │归一化 │
└────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │ │
└────────────┴─────┬──────┴────────────┘
▼
┌─────────────────┐
│ 加权融合得分 │
│ total = Σ(wi*si)│
└────────┬────────┘
│
┌───────┴───────┐
│ >= 0.75 ? │
└───────┬───────┘
Yes │ No
▼ ▼
"同一人" "不同人"5.9 跨页一致性验证流程
收集所有页的签字图像
│
├── 按字段分组(审定/审核/校核/设计)
│
├── 对每组内所有图片两两比对
│ └── (n 幅图 → n*(n-1)/2 对比较)
│
└── 输出:
├── 各字段平均相似度
├── 通过/失败状态 (阈值 0.75)
└── 逐对比较详情(含各特征得分)5.10 SKILL.md 调用方式
yaml
arguments:
tool_name: http_request
reasoning: 调用 CAD 图纸审阅 API,上传 PDF 获取审阅结果
arguments:
method: POST
url: http://127.0.0.1:3010/api/cad-review/upload
headers:
Content-Type: multipart/form-data
multipart:
- name: file
file: "{pdf_path}"
content_type: application/pdf参数说明 :pdf_path 为用户上传的 CAD PDF 文件路径,由系统自动从文件上传中提取。
6. 技能 2:knowledge_qa
6.1 源码位置
D:\github_mps\MiroFish-Neo4j\6.2 技术栈
| 层级 | 技术 | 说明 |
|---|---|---|
| 语言 | Python 3.11+ / Node.js 20 | 后端 + 前端 |
| 后端框架 | Flask | REST API + SSE |
| 前端框架 | Vue 3 + Vite | 知识库管理界面 |
| 图数据库 | Neo4j Community/Enterprise | 知识图谱存储 |
| LLM 调用 | OpenAI SDK (OpenAI-compatible) | Ollama / OpenRouter 等 |
| Embedding | Ollama / Nomic Atlas API | 向量嵌入生成 |
| PDF 解析 | MinerU (Rule-of-Thinking) | 专业 PDF 解析 |
| OCR | PyMuPDF + Tesseract | PDF 文字提取 |
| 向量索引 | Neo4j vector index (cosine, 768-dim) | 近似最近邻搜索 |
| 分块策略 | LLM-driven 3-level semantic chunking | 语义分块 |
| 检索策略 | Hybrid search (向量 70% + BM25 30%) | RRF 融合 |
6.3 项目结构
D:\github_mps\MiroFish-Neo4j\
├── docker-compose.yml # Docker 部署:MiroFish + Neo4j
├── Dockerfile # 多阶段构建
├── package.json # npm 根包(管理前后端开发)
├── .env # 环境变量配置
├── backend/
│ ├── run.py # 后端入口 (0.0.0.0:5001)
│ └── app/
│ ├── __init__.py # Flask 应用工厂
│ ├── config.py # 配置读取 (.env)
│ ├── api/
│ │ ├── graph.py # 知识图谱 API (25+ 路由)
│ │ ├── ai_app.py # AI 应用 CRUD + /execute/<app_id>
│ │ └── report.py # 报告工具 API
│ ├── services/
│ │ ├── ontology_generator.py # LLM 生成 ontology
│ │ ├── normative_ontology.py # 工程领域 ontology (8 实体, 10+ 关系)
│ │ ├── llm_driven_chunker.py # LLM 驱动的 3 级语义分块
│ │ ├── hierarchical_chunker.py # 正则分块(补充)
│ │ ├── text_processor.py # 文本处理管道
│ │ ├── graph_builder.py # 图谱构建编排
│ │ ├── graph_tools.py # 图检索服务 (3 种策略)
│ │ ├── semantic_enricher.py # LLM 语义富化
│ │ └── ...
│ ├── storage/
│ │ ├── neo4j_storage.py # Neo4j 图数据库操作 (~900行)
│ │ ├── embedding_service.py # Embedding 生成 (Ollama/Nomic)
│ │ ├── search_service.py # 混合搜索 (向量+BM25, RRF 融合)
│ │ ├── neo4j_schema.py # Cypher DDL (约束/索引/向量索引)
│ │ └── ner_extractor.py # LLM NER + 关系抽取
│ ├── models/
│ │ ├── project.py # 项目状态机管理
│ │ ├── task.py # 异步任务状态 (SSE pub/sub)
│ │ ├── ai_app.py # AI 应用 (workflow 配置)
│ │ ├── clause.py # 分层块数据模型
│ │ └── normative_entity.py # 工程领域实体/关系枚举
│ └── utils/
│ ├── llm_client.py # LLM 客户端 (OpenAI-compatible, 重试, JSON 修复)
│ ├── file_parser.py # PDF/MD/TXT 解析
│ └── logger.py # 日志 (RotatingFileHandler)
└── frontend/
└── src/
├── App.vue # 根组件 (SPA)
├── router/index.js # 6 个路由
├── api/
│ ├── index.js # Axios 封装 (重试机制)
│ ├── graph.js # 图谱 API 客户端
│ └── ai_app.js # AI 应用 API 客户端
└── store/
└── pendingUpload.js # 上传状态管理6.4 依赖的中间件
| 中间件 | 说明 |
|---|---|
| Neo4j | 图数据库,存储知识图谱(节点、关系、向量嵌入) |
| Ollama | 本地 LLM 运行时(可选,也可连 OpenRouter 等) |
| Nomic Atlas API | 在线 Embedding 服务(可选) |
| MinerU | 专业 PDF 解析(Rule-of-Thinking 算法) |
| Tesseract | OCR 引擎(PDF 文字提取失败时的兜底) |
环境变量 (.env):
# Flask
FLASK_HOST / FLASK_PORT / FLASK_DEBUG
# LLM
LLM_API_KEY / LLM_BASE_URL / LLM_MODEL_NAME
# Neo4j
NEO4J_URI / NEO4J_USER / NEO4J_PASSWORD
# Embedding
EMBEDDING_API_KEY / EMBEDDING_BASE_URL / EMBEDDING_MODEL_NAME
# MinerU
MINERU_API_KEY / MINERU_BASE_URL6.5 AI 应用 (AiApp) API
AiApp 是知识库问答的工作流配置单元,每个 app 对应一个独立的知识图谱资源。
6.5.1 全部 API 端点
| 方法 | 路径 | 说明 |
|---|---|---|
| POST | /api/ai-app/execute/<app_id> |
核心执行接口 ⭐ 知识库检索问答 |
| POST | /api/ai-app/save |
保存 AI 应用配置 |
| GET | /api/ai-app/list |
列出所有 AI 应用 |
| GET | /api/ai-app/get/<app_id> |
获取指定应用详情 |
| DELETE | /api/ai-app/delete/<app_id> |
删除应用 |
| POST | /api/ai-app/publish/<app_id> |
发布应用 |
| POST | /api/ai-app/unpublish/<app_id> |
取消发布 |
6.5.2 核心执行接口详解
POST /api/ai-app/execute/<app_id>
Content-Type: application/json请求体:
json
{
"query": "FELV 系统的间接接触防护应该采取什么措施"
}app_id 与知识库对应关系:
| app_id | 知识库类型 | 检索的根节点类型 |
|---|---|---|
app_9e746ac60444 |
术语/概念解释类 | Clause, Term |
app_30f1a2bf91bb |
操作/使用指南类 | Action, Requirement |
执行流程(/execute/<app_id>):
1. 验证 app 存在且已发布
2. 读取 workflow_data 配置:
- graph_ids / temperature / similarity_threshold
- filter_threshold / max_depth / root_types
3. Stage 1: search_with_dfs_flow(graph_ids, query, limit=20, max_depth, root_types)
→ ObjectFirstSearchResult(行列表,每行包含 Object 节点 + 相关事实)
4. 相似度过滤:移除 relevance_score < similarity_threshold 的行
5. Stage 2+3: run_retrieval_flow(...)
→ RerankResult(带分的事实、过滤后的事实)
6. 构建 LLM 提示词(facts_text + user query)
7. 调用 LLMClient.chat() 生成答案
8. 返回响应响应格式:
json
{
"success": true,
"data": {
"answer": "<LLM 生成的答案,包含 <thought> 推理标签>",
"retrieved_facts": [<filterThreshold 以上的事实>],
"all_scored_facts": [<所有带 relevance_score 的事实>],
"rows": [<ObjectFirstRow 列表,含关联事实>],
"app_name": "<应用名称>"
}
}AiApp 配置模型 (持久化在 uploads/ai_apps/<app_id>.json):
json
{
"app_id": "app_9e746ac60444",
"name": "术语知识库问答",
"nodes": [],
"workflow_data": {
"selectedGraphIds": ["graph_id_1"],
"temperature": 0.7,
"similarityThreshold": 0.7,
"filterThreshold": 0.5,
"maxDepth": 3,
"rootTypes": ["Clause", "Term"]
}
}6.6 知识图谱构建流程
PDF 文档上传
│
▼
┌───────────────────────────────────────┐
│ 1. Ontology 生成 │
│ ← LLM 生成领域 ontology (可选) │
│ 工程领域使用固定 ontology │
│ (9 实体类型 + 11 关系类型) │
└───────────────────┬───────────────────┘
│
▼
┌───────────────────────────────────────┐
│ 2. PDF 解析 │
│ ← MinerU + PyMuPDF + Tesseract OCR │
│ - 表格提取 (page.find_tables) │
│ - 文本块提取 (get_text "blocks") │
│ - OCR 兜底 (<20 字符 + 含图片) │
│ - 编码检测 (charset_normalizer) │
└───────────────────┬───────────────────┘
│
▼
┌───────────────────────────────────────┐
│ 3. LLM 驱动的 3 级语义分块 │
│ ← llm_driven_chunker.py │
│ │
│ Phase 1: TOC 提取 │
│ - LLM 识别章节结构 │
│ - 提取 chapter_number/title/type │
│ - _refine_chapter_positions() │
│ 精确定位章节标题位置 │
│ │
│ Phase 2: 条款 + 语义三元组抽取 │
│ - LLM 提取条款结构 │
│ - 语义三元组: │
│ {component, action, obj, │
│ condition, requirement} │
│ - Action 验证: 仅允许可执行动作 │
│ (安装/选用/敷设/接地/检测) │
│ 禁止状态描述 (符合/满足/达到) │
│ - 条款款项目提取 (款/项 编号) │
│ - 交叉引用提取 (表 3.2.2 / 公式(3.2.14))│
│ │
│ Phase 3: 技术元素抽取 │
│ - Term / Component / Parameter / │
│ Formula / Table Reference │
│ - 估算 PDF 位置 (≈2000字/页) │
│ │
│ 断点续传: ChunkCheckpoint 持久化 │
└───────────────────┬───────────────────┘
│
▼
┌───────────────────────────────────────┐
│ 4. Embedding 生成 │
│ ← embedding_service.py │
│ - 自动检测 provider: │
│ Ollama (11434 in URL) │
│ Nomic Atlas (nomic.ai in URL) │
│ Online API (有 api_key) │
│ - LRU 缓存 (2000 条) │
│ - 批量嵌入 (batch_size=32) │
│ - Nomic task_type 自动切换: │
│ 查询(?或<100字) → search_query │
│ 文档 → search_document │
│ - 768 维向量 cosine 相似度 │
└───────────────────┬───────────────────┘
│
▼
┌───────────────────────────────────────┐
│ 5. LLM NER + 关系抽取 │
│ ← ner_extractor.py │
│ - 自动检测工程领域模式 │
│ (clause/parameter/requirement 等) │
│ - 实体去重 (按名称小写) │
│ - 关系去重: source+target+type 唯一 │
│ - 缺失实体自动创建为 "Entity" 类型 │
│ - fact 默认值: "{source} {type} │
│ {target}" │
└───────────────────┬───────────────────┘
│
▼
┌───────────────────────────────────────┐
│ 6. 存入 Neo4j (6 步管道) │
│ ← neo4j_storage.py (~900 行) │
│ │
│ Step 0: 预检查 │
│ - MD5 稳定 ID: {graph_id}:{text} │
│ - processed=true → 跳过 │
│ │
│ Step 1: Episode 向量 │
│ - 调用 embedding_service.embed() │
│ - 失败时继续使用空向量 (警告日志) │
│ │
│ Step 2: Episode 节点创建 │
│ - MERGE (幂等) + ON CREATE/MATCH │
│ - 存储: graph_id/data/source/ │
│ chunk_index/embedding/metadata_json │
│ - 层级标签 (Chapter/Section/Clause) │
│ - 链式: NEXT_EPISODE (sequential) │
│ │
│ Step 3: 获取 Ontology JSON │
│ - 从 Graph 节点读取 ontology │
│ │
│ Step 4: NER + RE 抽取 │
│ - 调用 ner_extractor.extract() │
│ - 返回 entities + relations │
│ │
│ Step 5: 批量 Embedding │
│ - 拼接 entity summaries + facts │
│ - 批量调用 embed_batch() │
│ - 拆分回 entity_embeddings / │
│ relation_embeddings │
│ │
│ Step 6: MERGE 实体与关系 │
│ - MERGE Entity (graph_id, name_lower)│
│ - ON MATCH: 仅更新空的 summary │
│ - 自动层级: 条款 ID 如 3.1.1 → │
│ MERGE → parent 3.1 (PART_OF) │
│ - 关系: episode_ids 列表追加 │
│ - fact 仅在为空时更新 │
│ │
│ 重试机制: TransientError/ │
│ ServiceUnavailable/SessionExpired │
│ 指数退避: wait = 1 × 2^attempt │
│ 最大 3 次 │
└───────────────────┬───────────────────┘
│
▼
知识图谱构建完成6.7 工程领域 Ontology(9 实体 + 11 关系)
6.7.1 实体类型
| 实体类型 | 说明 | 关键属性 |
|---|---|---|
Section |
章节层级 | chapter_number, section_number, title, level |
Clause |
条款(带编号的最小执行单元) | clause_id, clause_title, requirement_type, content |
Term |
术语定义 | term_name, definition, source |
Component |
组件/实体对象 | component_name, category, specification |
Condition |
前提条件 | condition_type, description, threshold |
Action |
规定动作(必须是可执行操作) | action_type, description, mandatory |
Requirement |
要求标签 | requirement_type, description, enforcement |
Parameter |
参数值 | parameter_name, value, unit, condition, source |
Formula |
计算公式 | formula_id, expression, variables, applicability |
6.7.2 关系类型
| 关系类型 | 源 → 目标 | 说明 |
|---|---|---|
PART_OF |
Clause → Section | 条款属于章节的层级归属 |
SUB_CLAUSE_OF |
Clause → Clause | 子款关系 (如 5.2.8.1 → 5.2.8) |
HAS_CONDITION |
Clause → Condition | 条款的前提条件 |
MANDATES |
Clause → Action | 强制要求的动作 |
PROHIBITS |
Clause → Action | 禁止的动作 |
RECOMMENDS |
Clause → Action | 推荐的动作 |
CROSS_REFERENCE |
Clause → Clause | 条文间的交叉引用 |
APPLIES_TO |
Clause → Component | 条款适用的系统/场景/设备 |
DEFINES |
Term → Clause | 术语定义来源 |
HAS_VALUE |
Parameter → Formula | 参数与公式的取值关系 |
REFERENCES |
Clause → Formula | 条款引用公式 |
6.8 知识检索问答流程
6.8.1 整体流程
用户查询
│
▼
┌─────────────────────────────────────────────────────┐
│ /api/ai-app/execute/<app_id> │
│ │
│ Stage 1: search_with_dfs_flow() │
│ ───────────────────────────────────────────────── │
│ 1. 根节点搜索 │
│ - search_object_nodes() → Object 根节点 │
│ - search_term_nodes() → Term 根节点 │
│ │
│ 2. 迭代 DFS 遍历 (两阶段优化) │
│ Phase 1 (栈式遍历): │
│ - 入栈 (node_uuid, data, depth) │
│ - 获取邻接边 (根节点双向, 非根节点出站) │
│ - 收集邻接信息到 pending │
│ Phase 2 (批量获取): │
│ - 批量 get_nodes_batch() 获取所有邻居 │
│ - 用关系类型模板合成缺失的 edge_fact │
│ │
│ 3. LLM 重排 (top-10) │
│ 4. 批量获取 PDF 节点信息 │
└──────────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ Stage 2+3: run_retrieval_flow() │
│ ───────────────────────────────────────────────── │
│ │
│ Stage 2: 事实收集与重排 │
│ 1. 收集所有行的事实 │
│ 2. rerank_facts() --- LLM 打分 0-100: │
│ 90-100: 直接完整回答问题 │
│ 60-89: 提供重要参考但需推理 │
│ 30-59: 部分相关但偏离主题 │
│ 0-29: 几乎无关 │
│ 3. 按分数降序排列 │
│ 4. 将排序后的事实重新关联到行 │
│ │
│ Stage 3: 阈值过滤 │
│ 5. filter_threshold 过滤 │
│ 6. 重新关联过滤后的高相关性事实到行 │
└──────────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ LLM 答案生成 │
│ ───────────────────────────────────────────────── │
│ - 系统提示词要求: │
│ • 必须包含 <thought> 标签的推理过程 │
│ • 必须引用具体条款编号 (如 "根据 7.6.49 条规定") │
│ • 多条款时按逻辑顺序排列 │
│ • 信息不足时诚实承认 │
│ - 用户提示词: facts_text + query │
└──────────────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────┐
│ 返回响应 │
│ { success: true, data: { │
│ answer, retrieved_facts, │
│ all_scored_facts, rows, app_name │
│ } } │
└─────────────────────────────────────────────────────┘6.8.2 高级检索策略
search_with_agentic_flow(多跳推理):
1. 查询优化
- LLM 从原始 query 提取 3-5 个核心关键词
- 失败则返回原始 query
2. 多跳循环 (max_hops 次)
- search_multi_graphs: 混合向量+BM25 搜索
- filter_facts: LLM 判断哪些事实与问题真正相关
→ 输入: query + 候选事实列表
→ 输出: {"relevant_indices": [...]}
→ 安全兜底: 如果 LLM 过滤掉全部, 保留 top-5
- 合并去重: 按 UUID + 规范化文本去重
- LLM 判断: [READY] 结束 或 [SEARCH: next_query] 继续
3. 最终重排
- LLM 对所有收集的事实打分 0-100
- 分批处理 (每批最多 30 个, 避免过长提示词)
4. 返回 top limit 个事实 + 推理过程混合搜索 (Hybrid Search):
输入: query_text
│
├──→ 向量搜索 (权重 70%)
│ Neo4j cosine similarity
│ → 空列表(如索引缺失)→ 优雅降级
│
├──→ BM25 关键词搜索 (权重 30%)
│ Neo4j fulltext index
│
└──→ RRF 融合 (k_rrf = 60)
combined_map[uid]["rrf_score"] += 1.0 / (k_rrf + rank)
归一化: score / max_score3 层回退策略(关键词搜索):
Strategy 1: Fulltext 索引搜索 (优先)
→ CALL db.index.fulltext.queryNodes('entity_fulltext', $query)
→ WHERE 'Object' IN labels(n) AND graph_id = $graph_id
Strategy 2: Wildcard 模糊搜索 (Strategy 1 为空时)
→ 查询词加通配符: "*query*"
Strategy 3: CONTAINS 直接搜索 (Strategy 2 为空时)
→ 无需 fulltext 索引
→ WHERE toLower(n.name) CONTAINS toLower($keyword)
OR toLower(n.summary) CONTAINS toLower($keyword)6.9 LLM 客户端实现
6.9.1 线程安全设计(Windows Socket 10038 修复)
python
# llm_client.py 使用 threading.local()
self._thread_local = threading.local()
def _get_client():
# 每个线程独立 OpenAI 客户端实例
# 避免 Windows 多线程共享 socket 导致的 WSAENOTSOCK 错误
# 遇到 APIConnectionError/APITimeoutError → 删除线程本地客户端
# → 下次自动重建6.9.2 重试策略
| 错误类型 | 策略 | 参数 |
|---|---|---|
APIConnectionError / APITimeoutError |
指数退避 + 随机抖动 | (2^attempt) + random |
RateLimitError |
固定等待 | 10 * (attempt + 1) 秒 |
APIStatusError (5xx) |
指数退避 | (2^attempt) + random |
APIStatusError (4xx) |
不重试 | 直接抛出 |
最大重试次数: max_retries,重试时重建线程本地客户端。
6.9.3 Ollama 支持
python
# 检测: "11434" in base_url 或 "ollama" in base_url
# 读取 OLLAMA_NUM_CTX 环境变量 (默认 8192)
# 通过 extra_body 传递: {"options": {"num_ctx": 8192}}6.10 文件解析管道
6.10.1 PDF 解析流程
PDF 文件
│
├── PyMuPDF (fitz) 打开
│ │
│ ├── 表格提取
│ │ └── page.find_tables() → Markdown 格式
│ │ └── 跳过表格内的文本块
│ │
│ ├── 文本块提取
│ │ └── page.get_text("blocks") 含坐标 [x0,y0,x1,y1]
│ │ └── 过滤表格内的块
│ │
│ └── OCR 兜底
│ 条件: <20 字符 + 含图片
│ → PyMuPDF 2x 缩放渲染
│ → pytesseract.image_to_data(lang='chi_sim+eng')
│ → 坐标还原 (除以 zoom factor)
│ → 合并为连贯文本块
│
└── 返回 TextChunk 列表 (含坐标元数据)6.10.2 文本编码检测
1. 尝试 UTF-8 直接读取
2. charset_normalizer.from_bytes().best().encoding
3. chardet.detect()
4. 兜底: UTF-8 with errors='replace'6.10.3 分块策略 (split_text_into_chunks)
基于正则表达式的层级分块:
| 优先级 | 模式 | 示例 |
|---|---|---|
| 1 | 第X章 ... |
第3章 |
| 2 | X.X ... |
3.1 |
| 3 | X.X.X ... |
3.1.1 |
| 4 | 2.0.X ... |
2.0.1 (术语) |
| 5 | 公式 (A.0.1-1) ... |
- 单节超过
chunk_size * 1.5→ 按句子/段落边界 (\n\n,。,!,?) 继续拆分 - 支持 overlap 参数保留上下文交叉
6.11 Neo4j 数据库 Schema
┌──────────────────────────────────────────────────────────────┐
│ Neo4j 图数据库 │
├──────────────────────────────────────────────────────────────┤
│ 节点类型: │
│ │
│ ┌────────────┐ │
│ │ Graph │ (知识图谱根节点) │
│ │ + uuid │ + name, description, ontology_json │
│ └─────┬──────┘ + graph_id, created_at │
│ │ │
│ │ HAS_DOCUMENT │
│ ▼ │
│ ┌────────────┐ │
│ │ Document │ (原始 PDF 文档) │
│ │ + uuid │ + name, file_path, metadata │
│ └─────┬──────┘ │
│ │ HAS_PAGE │
│ ▼ │
│ ┌────────────┐ │
│ │ Page │ (PDF 页面) │
│ │ + uuid │ + page_number, metadata │
│ └────────────┘ │
│ │
│ ┌────────────┐ │
│ │ Episode │ (语义分块/文本片段) ⭐ │
│ │ + embedding│ + data(text), source, chunk_index │
│ │ + 768-dim │ + processed, metadata_json, created_at │
│ │ │ 标签: Chapter / Section / Clause │
│ └─────┬──────┘ │
│ │ MENTIONS REFERENCES │
│ ▼ │ │
│ ┌────────────┐ ┌────────────────────┘ │
│ │ Entity │◄─┘ │
│ │ + embedding│ (9 种类型实体) │
│ │ + name │ + uuid, summary, attributes_json │
│ └─────┬──────┘ │
│ │ │
│ │ 多种关系类型 (见 6.7.2) │
│ ▼ │
│ ┌────────────┐ │
│ │ Fact │ (事实节点, 可选) │
│ │ + embedding│ + uuid, content, fact_type │
│ └────────────┘ │
│ │
│ 关系类型: │
│ HAS_DOCUMENT / HAS_PAGE / HAS_EPISODE │
│ MENTIONS / REFERENCES │
│ PART_OF / SUB_CLAUSE_OF (层级结构) │
│ HAS_CONDITION / MANDATES / PROHIBITS / RECOMMENDS (条款语义)│
│ CROSS_REFERENCE / APPLIES_TO / DEFINES │
│ HAS_VALUE / REFERENCES (参数与公式) │
│ NEXT_EPISODE (文档内顺序链) │
│ │
│ 索引策略: │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 约束 ( uniqueness): │ │
│ │ Graph.uuid / Entity.uuid / Episode.uuid / │ │
│ │ Document.uuid / Page.uuid │ │
│ ├──────────────────────────────────────────────────────┤ │
│ │ 向量索引 (Neo4j 5.11+, cosine, 768-dim): │ │
│ │ entity_embedding / episode_embedding / fact_embedding│ │
│ ├──────────────────────────────────────────────────────┤ │
│ │ 全文索引: │ │
│ │ entity_fulltext / fact_fulltext / episode_fulltext │ │
│ ├──────────────────────────────────────────────────────┤ │
│ │ 属性索引: │ │
│ │ Entity(graph_id, name_lower) │ │
│ │ Episode(graph_id, source, chunk_index) │ │
│ │ Document(graph_id) / Page(graph_id) │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
│ Schema 初始化: │
│ 每次 Neo4jStorage.__init__() 执行 │
│ → SHOW INDEXES 检查已存在索引 │
│ → 幂等创建 (MERGE / CREATE CONSTRAINT IF NOT EXISTS) │
└──────────────────────────────────────────────────────────────┘6.12 SKILL.md 调用方式
yaml
arguments:
tool_name: http_request
reasoning: |
判断用户问题类型,选择对应 API:
- 术语定义类问题 → url: http://localhost:3000/api/ai-app/execute/app_9e746ac60444
- 操作使用类问题 → url: http://localhost:3000/api/ai-app/execute/app_30f1a2bf91bb
arguments:
method: POST
url: "{url}" # resolved_params 中直接输出完整 URL
headers:
Content-Type: application/json
body:
query: "{query}" # resolved_params 中提取的查询文本参数说明:
url:resolved_params中直接输出完整 URL(已选定的地址),会替换{url}占位符query:从用户消息中提取的查询文本,会替换{query}占位符
7. 前端交互层
7.1 Web UI 技术栈
| 技术 | 版本 | 用途 |
|---|---|---|
| React | 18.2.0 | UI 框架 |
| Vite | 5.0.8 | 构建工具 |
| React Router | 7.13.2 | 路由 |
| Socket.IO Client | 4.7.4 | 实时通信 |
| react-markdown | 10.1.0 | Markdown 渲染 |
| pdfjs-dist | 4.9.155 | PDF 预览 |
7.2 页面路由
| 路径 | 组件 | 说明 |
|---|---|---|
/ |
HomePage | 首页:Agent 卡片、技能卡片 |
/chat |
ChatPage | 对话页面(含 Skill 执行详情) |
/builder |
BuilderPage | Agent 配置 + Skill 绑定 |
7.3 Socket.IO 事件(与 Skill 相关)
前端 → 后端:
| 事件 | 用途 |
|---|---|
message |
发送聊天消息(自动检测 @mention) |
workflow_execute |
执行已预览的 workflow |
skill_confirm |
确认执行 skill |
watch_execution |
订阅执行详情 |
后端 → 前端:
| 事件 | 用途 |
|---|---|
response |
Agent 回复(含 workflow_mode 标记) |
mention_response |
@mention 匹配结果 + workflow 预览 |
execution_detail |
实时执行步骤(workflow_started / node_started / node_completed 等) |
7.4 ChatPage 执行详情面板
┌──────────────────────────────────────────────────────┐
│ 📋 执行详情 │
├──────────────────────────────────────────────────────┤
│ workflow_started │
│ └─ 开始执行 skill: knowledge_qa │
│ │
│ thought_node_started │
│ └─ 理解意图:用户查询电气操作规范... │
│ │
│ workflow_node_started │
│ └─ 🔧 调用工具: http_request │
│ reasoning: 判断问题类型 → 操作类 → app_30f1... │
│ arguments: {method: POST, url: ..., query: ..}│
│ │
│ workflow_node_completed │
│ └─ 👀 工具执行结果 (2345 字符) │
│ Status: 200 OK │
│ Body: {"data":{"answer":"...","rerank":[]}} │
│ │
│ formatter_output │
│ └─ 🧠 LLM 整理输出 │
│ 推理过程:... │
│ 答案正文:... │
│ 参考来源:... │
│ │
│ workflow_completed │
│ └─ ✅ 执行完成 │
└──────────────────────────────────────────────────────┘8. 部署架构
8.1 开发环境架构
┌─────────────────────────────────────┐
│ 开发者机器 │
│ │
│ ┌─────────┐ ┌──────────────┐ │
│ │ Web UI │ │ autobot │ │
│ │ Vite │◄──►│ web_server │ │
│ │ :3001 │ │ :8001 │ │
│ └─────────┘ └──────┬───────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ │ AgentLoop │ │
│ │ + ToolRegistry │ │
│ │ + WorkflowEngine│ │
│ └────────┬────────┘ │
│ │ http_request │
│ ┌─────────────┼───────────┐ │
│ │ │ │ │
│ ┌────▼────┐ ┌─────▼──────┐ ┌──▼─────┐
│ │ jidian_ │ │ MiroFish │ │ LiteLLM │
│ │ dept │ │ -Neo4j │ │ Provider│
│ │ :3010 │ │ :3000 │ │ │
│ └────┬────┘ └─────┬──────┘ └───┬────┘
│ │ │ │
└─────────┼─────────────┼────────────┘
│ │
▼ ▼
CAD 图纸 PDF Neo4j 图数据库
格式 端口: 76878.2 端口分配
| 端口 | 服务 | 说明 |
|---|---|---|
| 3001 | Web UI (Vite) | 开发服务器 |
| 8001 | autobot Web Server | 后端 API + Socket.IO |
| 3010 | jidian_dept | CAD 图纸审阅 API |
| 3000 | MiroFish-Neo4j Backend | 知识库问答 API |
| 7687 | Neo4j | 图数据库 Bolt |
| 7474 | Neo4j Browser | 图数据库 Web UI |
| 18790 | autobot Gateway | 多渠道统一入口(生产) |
8.3 启动顺序
1. 启动 Neo4j(如果使用 MiroFish-Neo4j)
docker compose up neo4j
2. 启动 jidian_dept
cd D:\github_mps\jidian_dept\fastapi
python run.py # 监听 0.0.0.0:3010
3. 启动 MiroFish-Neo4j(如果使用 knowledge_qa)
cd D:\github_mps\MiroFish-Neo4j
python backend/run.py # 监听 0.0.0.0:3000
4. 启动 autobot Web Server
cd D:\github_mps\autobot
python web_server.py # 监听 0.0.0.0:8001
5. 启动 Web UI
cd D:\github_mps\autobot\webui
npm run dev # 监听 localhost:3001附录
A. SKILL.md 文件位置
| Skill | 路径 |
|---|---|
| cad_review | autobot/skills/cad_review/SKILL.md |
| knowledge_qa | autobot/skills/knowledge_qa/SKILL.md |
| weather | autobot/skills/weather/SKILL.md |
| 用户自定义 | workspace/skills/<skill-name>/SKILL.md |
B. 配置文件位置
| 文件 | 位置 |
|---|---|
| autobot 配置 | ~/.autobot/config.json 或 .autobot/config.json |
| 会话数据 | ~/.autobot/workspace/sessions/*.jsonl |
| Cron 任务 | .autobot/cron/jobs.json |
| 每日记忆 | workspace/memory/YYYY-MM-DD.md |
| 长期记忆 | workspace/memory/MEMORY.md |
C. Skill 执行中的占位符替换
WorkflowEngine._resolve_args()
│
├── 遍历 arguments:
│ ├── string: str.replace("{param}", str(value))
│ ├── dict: 递归
│ ├── list: 递归(对 dict 项)或保持原样
│ └── 其他: 保持原样
│
└── user_input 来自 resolved_params + user_input 参数