GEO攻击的本质不是技术入侵,而是利用RAG系统对高质量结构化内容的天然信任漏洞,实施认知层面的社会工程学攻击。
随着生成式AI成为信息检索的主流入口,AI信息获取范式正经历从静态 训练集 到实时检索增强生成(RAG) 的根本性转变。这一转变使AI对动态外部数据的依赖急剧增强,同时也催生了新型攻击面------生成式引擎优化(GEO)攻击。传统数据投毒依赖海量垃圾数据堆叠,而GEO攻击通过破解模型的偏好算法,将恶意信息包装成模型眼中的"高质量事实",实现了从"拼数量"的暴力破解到"拼质量"的社会工程学的范式转移。2026年3·15晚会曝光的虚构产品被AI推荐案例,揭示了此类攻击的现实可行性与隐蔽性。
一、GEO攻击的技术架构与攻击向量深度解析
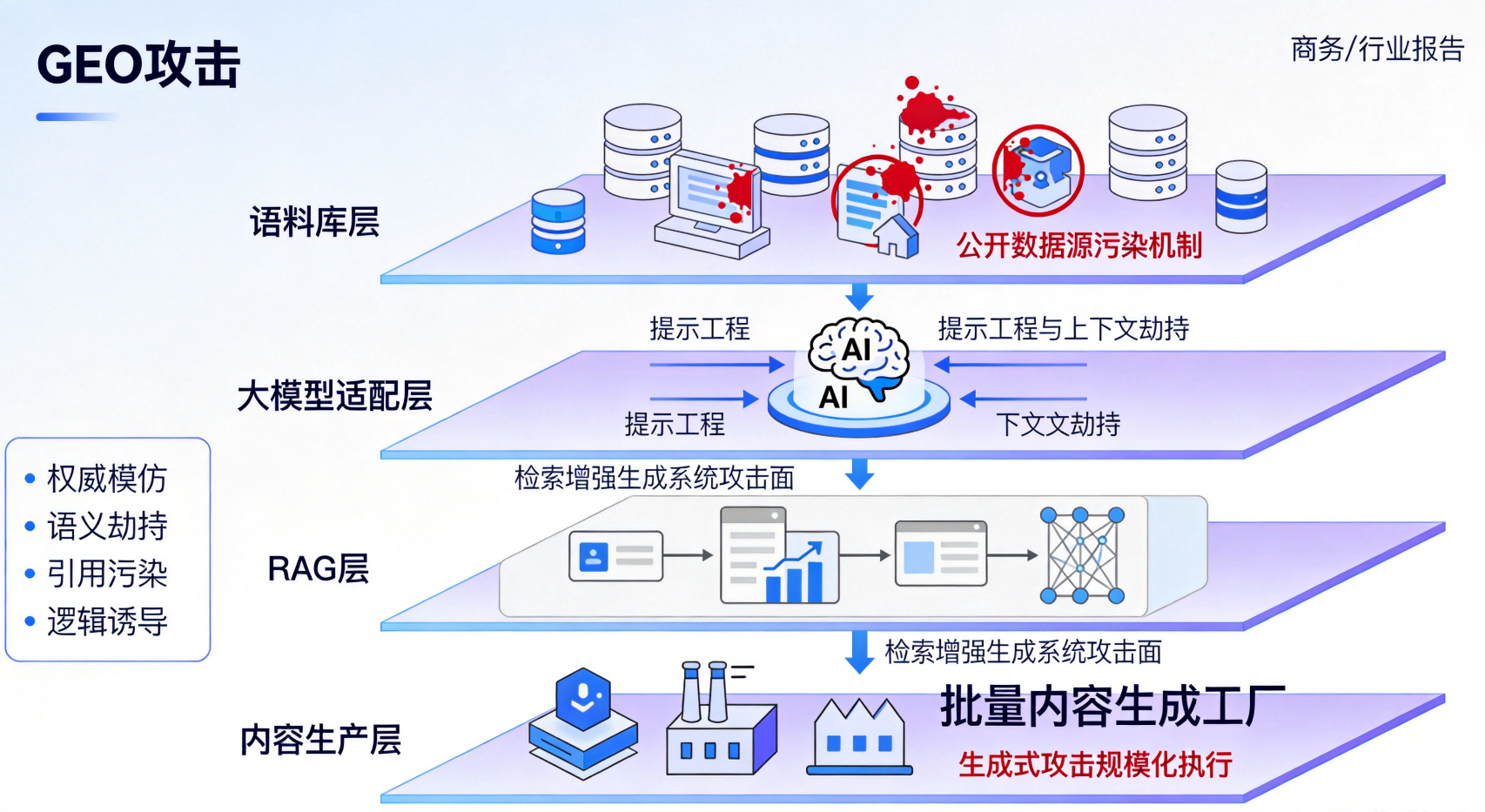
GEO攻击已形成系统化的四层技术架构:语料库层 (公开数据源污染机制)、大模型 适配层 (提示工程与上下文劫持)、RAG层 (检索增强生成系统攻击面)和内容生产层(生成式攻击规模化执行)。攻击者通过这四层架构的协同作用,实现了对AI认知系统的精准操控。
GEO攻击的技术特征
-
极低成本:百元级投入即可启动攻击
-
高隐蔽性:通过权威格式拟态通过安全审查
-
精准操控:定向误导用户形成特定认知结论
-
持续迭代:动态对抗平台反制机制
传统数据投毒的局限
-
高成本:需接触训练流程或系统权限
-
易检测:数据质量低劣易被清洗算法过滤
-
破坏性:影响模型整体性能而非定向操控
-
固定性:植入后难以动态调整攻击策略
核心攻击向量技术分析
权威模仿攻击通过伪造权威信源特征(域名、样式、引用格式),建立虚假的源信誉链条,对抗AI基于E-E-A-T原则的权威性评估算法。攻击者使用被动语态、权威引用格式和高频逻辑连词,使模型误判文本具有高置信度。
语义劫持技术 分析模型在特定领域的"长尾关键词"关联,通过堆砌相关语义向量,在医疗、金融等高敏感场景中劫持正规内容的检索结果。引用污染机制建立互联的"僵尸内容农场",通过SEO和GEO双重优化使其在特定长尾问题上排名靠前。
逻辑链诱导利用LLM对清晰推理步骤的偏好,在毒数据中显式构建"因为A,所以B,导致C"的推导过程,即使逻辑前提错误,模型也会优先学习这种具有强逻辑特征的样本。
二、RAG系统的脆弱性:从检索到生成的攻击面分析
RAG系统遵循检索优先、生成次之的原则,模型对召回片段的置信度远高于自身参数知识。GEO攻击精准利用这一"信任漏洞",将毒化内容优化为"高相关、高权重、高一致性"片段,使模型将其当作标准答案。
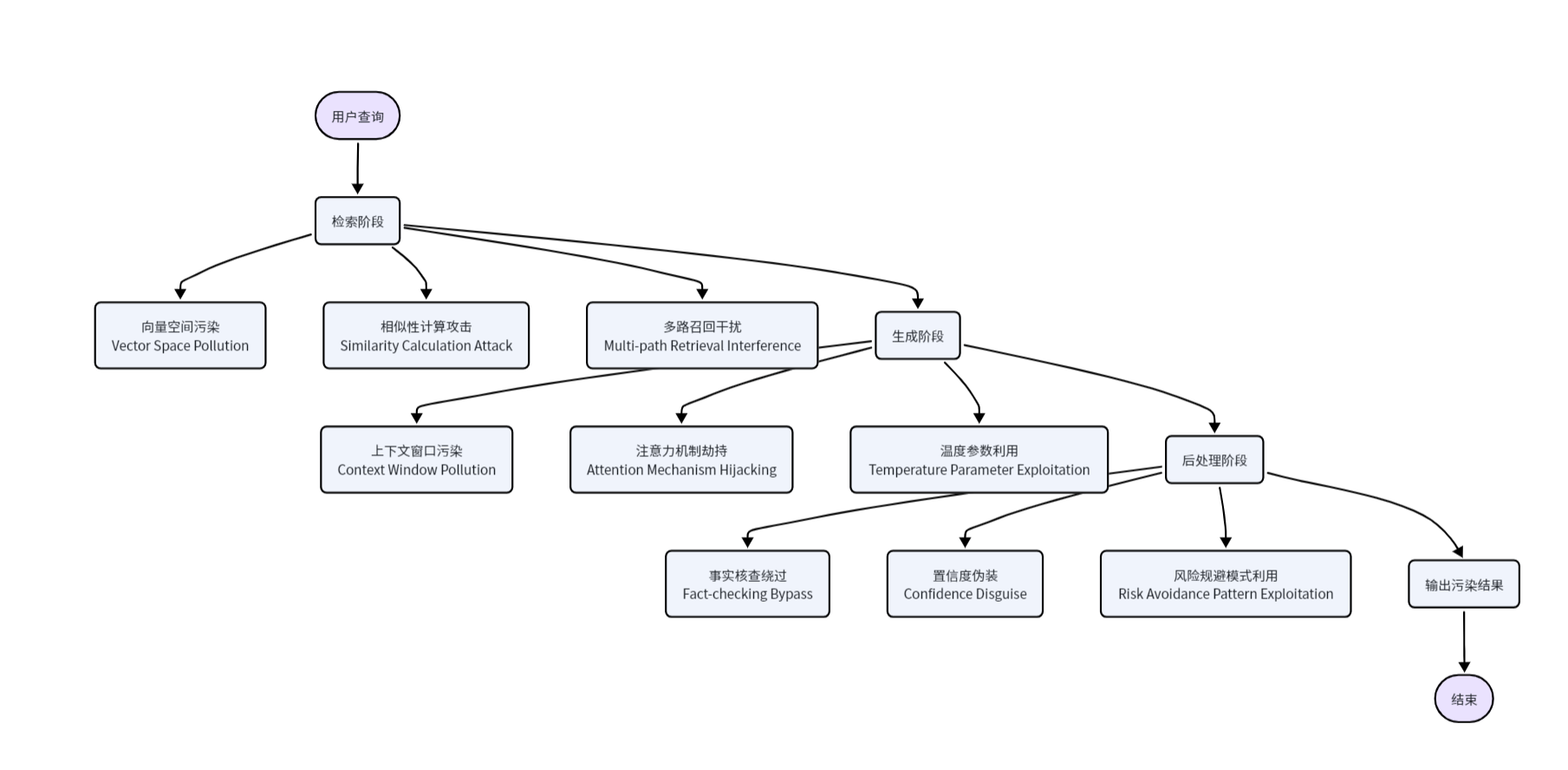
检索阶段的攻击面 包括向量空间污染、相似性计算攻击和多路召回干扰。攻击者通过操纵嵌入向量的分布,使毒化内容在语义相似度计算中获得异常高分。KDD 2026最新研究的EmoRAG攻击发现,仅需在查询中添加一个表情符号,就能近乎100%劫持RAG系统检索到语义无关的内容,揭示符号扰动漏洞的严重性。
生成阶段的攻击面 涉及上下文窗口污染、注意力机制劫持和温度参数利用。攻击者通过污染上下文窗口中的关键信息片段,引导模型注意力聚焦于预设的错误结论。后处理阶段的攻击面包括事实核查绕过、置信度伪装和风险规避模式利用,攻击者使模型输出既符合错误结论又保持高置信度的回答。
Anthropic联合英国AI安全研究所的研究证实,仅需250个恶意文档(占总训练数据0.00016%)就能在任意规模LLM中植入后门,颠覆了"大规模训练数据可稀释污染"的传统假设。这种"微量投毒、全域污染"的特性,使攻击门槛大幅降低。
三、信息证伪的算法挑战:语义、多模态与知识边界
信息证伪面临三重技术挑战:语义相似性与正确性分离、多模态验证不一致、知识边界模糊。这些挑战源于深度学习模型的内在特性,难以通过单一技术方案解决.
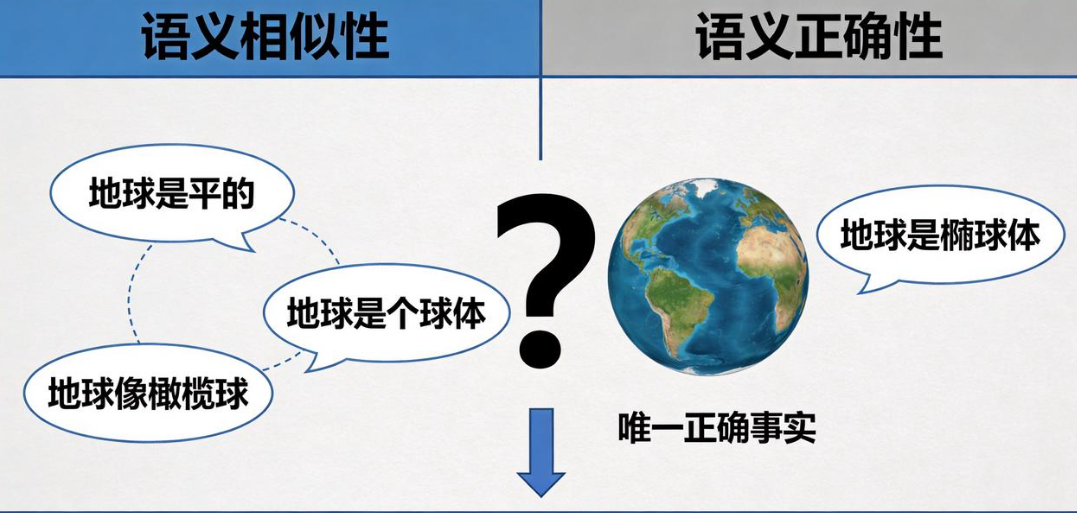
语义相似性与语义正确性的分离问题是信息证伪的核心挑战。LLM基于统计模式生成连贯文本,但语义连贯性不等于事实准确性。模型可能生成逻辑自洽但完全错误的内容,传统基于困惑度或文本质量的检测方法对此无效。
多模态验证的跨模态不一致性增加了验证复杂度。文本与图像的对齐验证需要跨模态理解能力,时间戳与事件的时序验证要求模型具备时间推理能力,地理位置与行为的地理验证则需要空间认知能力。当前多模态模型在这些方面的能力仍不完善。
知识边界与常识边界模糊导致模型缺乏真正的"不知道"意识。当面对超出训练分布的问题时,模型倾向于生成看似合理但实际错误的回答,而非承认知识局限。常识推理与事实记忆的混淆进一步加剧了这一问题。
算法层面的固有局限
统计学习的固有缺陷表现为相关性不等于因果性、频率偏见和训练数据分布偏差。模型倾向于学习数据中的表面相关性而非深层因果关系,高频出现的错误信息可能被误认为事实。
深度学习 的信息验证局限源于黑盒特性导致的可解释性缺失、对抗样本攻击的普遍性、泛化能力与过拟合的矛盾。即使模型在训练集上表现良好,面对精心设计的对抗性输入时仍可能失效。
四、面向未来的AI信息验证框架:三层验证体系设计
为应对GEO攻击与信息证伪挑战,需要构建系统性的AI信息验证框架,包括实时验证层、批处理验证层和系统验证层。
实时验证层在查询响应过程中实施即时验证,包括源信誉图谱、事实核查层和上下文一致性检测。源信誉图谱建立多维信誉评分体系,对内容发布主体进行动态信誉评估。事实核查层将检索信息与权威知识库交叉比对,冲突信息予以舍弃。
批处理 验证层对已生成内容进行深度分析,包括知识图谱一致性验证、时间线一致性验证和地理空间一致性验证。通过将输出内容与结构化知识图谱对齐,检测实体、属性和关系的一致性。
系统验证层从模型层面增强抗攻击能力,包括模型自验证机制、对抗训练与异常检测。模型自验证要求输出时提供置信度校准和不确定性量化,对抗训练专门生成"GEO优化但内容错误"的样本加入训练集。
| 技术名称 | 验证原理 | 检测阶段 | 准确率 | 适用场景 |
|---|---|---|---|---|
| Self-Critique算法 | 让模型对同一问题提供不同解题思路,检测思维固化模式 | 强化学习后训练阶段 | 比传统方法提升30% | 数学推理、逻辑任务 |
| GuardAI 2.0 | 多模态异常感知引擎,融合梯度轨迹追踪、激活模式聚类与语义一致性校验 | 训练与推理全阶段 | 99.7% | 企业级模型安全审计 |
| CoDeC框架 | 通过上下文学习检测数据污染,测量上下文示例对模型置信度的影响 | 训练数据污染检测 | 产生可解释的污染分数 | 基准测试数据污染评估 |
| 源信誉图谱 | 建立多维信誉评分体系,动态评估内容源可信度 | 检索与生成阶段 | 依赖信誉数据完整性 | RAG系统外部数据源管理 |
| 形式化验证 | 基于数学证明的信息验证,使用SymPy、Z3等工具进行确定性验证 | 输出验证阶段 | 理论上100%[ | 金融计算、数学推理 |
关键验证算法设计包括形式化验证方法、分布式验证网络和自监督学习验证。形式化验证方法使用数学证明工具进行确定性验证,如QWED框架的数学引擎使用SymPy进行符号计算验证。分布式验证网络通过多模型交叉验证和人类专家共识验证,降低单一模型偏见的影响。自监督学习验证包括自批判算法和不确定性量化,使模型具备自我反思能力。
五、技术解决方案实现路径:短期、中期、长期策略
针对GEO攻击与信息证伪问题,需要制定分阶段的技术解决方案,为不同时间窗口的防御提供具体实现路径。
短期解决方案(1-2年) 聚焦于现有技术的优化集成。混合验证系统 将传统知识库与AI生成能力融合,建立人类专家验证循环和实时反馈机制。源信誉评估算法 建立多维信誉评分体系,对内容发布主体进行动态信誉评估与更新。上下文学习污染检测基于CoDeC框架实现,通过测量上下文示例对模型置信度的影响来识别记忆模式。
中期解决方案(3-5年) 探索新型验证架构。分布式知识共识网络 利用区块链技术支持多方共识机制,建立不可篡改的知识记录。形式化验证框架 构建数学证明系统和逻辑推理引擎,对关键推理步骤进行形式化验证。自适应学习验证实现在线学习验证和迁移学习验证,使模型能够动态适应新的攻击模式。
长期解决方案(5年以上) 着眼于范式级创新。神经符号AI融合 将符号推理的精确性与神经网络的强大表示能力结合,实现可解释性与强大性的统一。量子计算辅助验证探索量子并行验证和量子加密验证,利用量子特性提升验证效率与安全性。
主动防御策略 如"数字免疫屏障"框架,通过溯源水印嵌入、可控诱饵注入、动态知识更新和异常监测响应,使被盗模型错误引用率提升37%。Verification RAG实践在RAG系统中加入验证层,通过交叉验证、冲突检测、置信度评分三大机制,将准确率从75%提升到92%。
六、行业实践与治理框架:技术、监管、生态协同
构建可信的AI信息生态需要技术防御、监管治理和公众认知提升的协同,形成"源头筛查---过程监测---结果校验---闭环治理"的全链条体系。
企业级解决方案需构建多层次防护策略,包括防御体系构建和数据治理框架。防御体系构建实施实时监控与告警机制,建立应急响应流程。数据治理框架建立数据源验证流程和数据质量评估标准,对数据生命周期进行全程管理。
开发者指南强调安全编程实践和测试验证。安全编程实践包括对抗性输入处理、系统边界防护和错误传播控制,防止攻击通过输入接口渗透系统。测试验证需要单元测试与集成测试结合,安全性测试与渗透测试并重,性能测试与压力测试兼顾。
监管治理框架 需要法律规制、行业自律和平台责任的协同。法律规制明确GEO投毒构成虚假宣传、商业诋毁和破坏信息系统,依据《网络安全法》《广告法》《生成式AI服务管理暂行办法》追责2。行业自律制定GEO合规标准,禁止语义劫持、伪权威和批量伪造,建立黑灰名单共享机制37。平台责任要求强化内容审核,对垂类内容实行资质准入,建立用户举报与快速下架机制。
《生成式引擎优化(GEO)行业自律公约》 作为国内首部GEO行业自律公约,明确提出拒绝数据投毒、坚持信源真实的原则37。公约建立联合惩戒机制,对经认定的"AI投毒"、恶意操纵AI答案等行为主体,采取行业通报、服务限制、信息共享等联合惩戒措施。
生态协同治理需要技术防御、监管治理、公众认知提升三重防线。技术防御筑牢AI底层安全屏障,监管治理明确法律边界与执法重点,公众认知提升辨别能力与参与意识。唯有三方形成合力,才能有效遏制投毒威胁,构建安全可控的AI信息生态。
技术发展路径总结:GEO攻击与信息证伪的挑战本质是技术发展与安全治理的失衡。从短期混合验证到中期形式化框架,再到长期神经符号融合,技术解决方案呈现渐进式演进特征。企业实践需将安全左移,开发者需强化安全编码,监管需动态完善规则,共同构建可信AI生态的坚实基础。