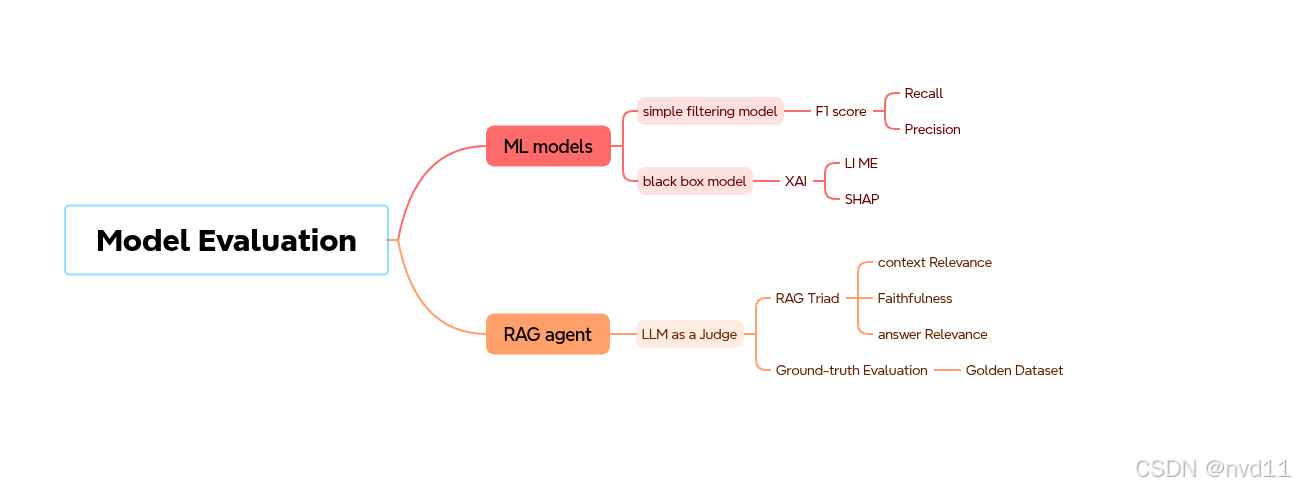
模型评估是量化系统表现的核心基准。本架构基于分类树结构,将系统切分为传统机器学习范式(ML Models)与检索增强生成代理(RAG Agent)两大赛道,并向下延展至具体的评估算子。
1. ML Models (传统机器学习模型)
架构定义
传统机器学习模型依赖统计学习理论,通过构建目标函数并最小化经验风险来求解映射关系。该范式聚焦于数据特征与预测目标之间的数学映射,其评估核心在于考察决策边界的泛化能力、分类精度以及底层特征的重要性归因。
1.1 Simple Filtering Model (简单过滤模型)
架构定义
过滤模型属于强约束下的判别式系统,通常用于异常检测或二分类任务(如垃圾邮件拦截、恶意流量清洗)。其决策机制依赖明确的标量阈值(Threshold),系统输入经过特征提取后映射为置信度得分,超越设定的界限即触发硬性分类输出。此类模型的评估强调精确度(误杀成本)与漏报风险(漏网成本)的精确权衡。
1.1.1 Precision (精确率)
数学原理
度量模型预测为正类的样本中,真实正类样本的比例。
公式:Precision=TPTP+FPPrecision = \frac{TP}{TP + FP}Precision=TP+FPTP
TP (True Positive) 为真阳性,FP (False Positive) 为假阳性。
通俗举例
反洗钱(AML)交易冻结。系统判定为洗钱的交易中,真实属于非法洗钱的比例。为避免过度冻结正常客户资金引发客诉(控制误杀),追求极高的 Precision。
参考提示词
"System: 你是一个模型评估专家。计算以下分类结果的精确率。输入数据包含预测标签和真实标签,输出单一的浮点数结果并说明误报的影响代价。"
例子代码
python
from sklearn.metrics import precision_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 1, 1, 0, 1]
precision = precision_score(y_true, y_pred)
print(f"Precision: {precision:.4f}")代码讲解
引入 sklearn.metrics。y_true 承载真实标签矩阵,y_pred 为模型输出。precision_score 函数执行 TP/(TP+FP)TP / (TP+FP)TP/(TP+FP) 的矢量化运算并返回浮点值。
1.1.2 Recall (召回率)
数学原理
度量所有真实正类样本中,被模型正确预测为正类的比例。
公式:Recall=TPTP+FNRecall = \frac{TP}{TP + FN}Recall=TP+FNTP
FN (False Negative) 为假阴性。
通俗举例
信用卡欺诈检测。所有真实的被盗刷交易中,被风控系统成功拦截的比例。面临高额资金损失风险、要求"宁可错杀不可放过"时,追求极高的 Recall。
参考提示词
"System: 评估当前过滤系统的召回率。比对人工标注的遗漏名单和成功拦截名单,量化系统的漏网之鱼风险。"
例子代码
python
from sklearn.metrics import recall_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 1, 1, 0, 1]
recall = recall_score(y_true, y_pred)
print(f"Recall: {recall:.4f}")代码讲解
调用 recall_score。算法提取 y_true 中所有正例基数,计算预测命中数,实施无偏除法运算量化漏报率。
1.1.3 F1 Score
数学原理
精确率和召回率的调和平均数,用于正负样本不平衡状态下综合评价性能。
公式:F1=2×Precision×RecallPrecision+RecallF1 = 2 \times \frac{Precision \times Recall}{Precision + Recall}F1=2×Precision+RecallPrecision×Recall
通俗举例
零售信贷审批系统。既要保证批出的贷款不发生坏账(Precision),又要保证优质客户尽可能多地被审批通过以抢占市场规模(Recall)。F1 综合评估该审批阈值的全局效能。
参考提示词
"System: 基于给定混淆矩阵,计算 F1 调和平均值。分析当数据分布呈现 1:100 极度不平衡时,F1 分数相比 Accuracy 的评估优势。"
例子代码
python
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 1, 1, 1, 0, 1]
f1 = f1_score(y_true, y_pred)
print(f"F1 Score: {f1:.4f}")代码讲解
执行 f1_score 计算。并行求取 Precision 和 Recall 后应用调和平均公式,对低召回或低精确率实施数值惩罚。
1.2 Black Box Model (黑盒模型) 与 XAI (可解释性AI)
架构定义
- Black Box Model(黑盒模型): 指代深度神经网络(DNN)、随机森林(Random Forest)及梯度提升树(GBDT)等高度非线性的复杂模型。这类模型内部包含数百万乃至数十亿量级的参数,特征交互逻辑高度耦合,导致人类无法直接从模型权重中逆推其决策路径,形成"输入已知、输出已知、内部映射未知"的黑盒状态。
- XAI(Explainable AI / 可解释性人工智能): 应对黑盒模型不透明性的技术集合。XAI 不改变模型本身的推演逻辑,而是通过构建代理模型(Surrogate Models)或特征归因算法(Feature Attribution),以后置分析(Post-hoc)的方式,将高维空间的复杂决策边界映射回人类可理解的低维特征语义空间。
1.2.1 LIME (Local Interpretable Model-agnostic Explanations)
数学原理
通过在特定输入样本的邻域内生成扰动数据,利用简单模型拟合局部决策边界。最小化局部损失:
explanation(x)=argming∈GL(f,g,πx)+Ω(g)explanation(x) = \arg\min_{g \in G} L(f, g, \pi_x) + \Omega(g)explanation(x)=argming∈GL(f,g,πx)+Ω(g)
通俗举例
房贷拒件定性说明。客户申请被黑盒模型秒拒,系统通过局部特征扰动(如假定其收入提高或负债减少),快速向客户经理输出拒件归因:"当前节点决定性因素为近期网贷查询次数过多"。
参考提示词
"System: 你是可解释 AI 专家。解释 LIME 生成的特征权重矩阵。识别出对模型决策产生决定性影响的前 5 个特征词,屏蔽噪声。"
例子代码
python
import lime
import lime.lime_tabular
# 设 predict_fn 为黑盒预测函数
explainer = lime.lime_tabular.LimeTabularExplainer(X_train, mode='classification')
exp = explainer.explain_instance(X_test[0], predict_fn, num_features=5)
exp.show_in_notebook(show_table=True)代码讲解
实例化 LimeTabularExplainer 构建解释器。调用 explain_instance 方法对单个测试样本执行扰动采样,通过 predict_fn 获取预测边界,计算局部特征重要性。
1.2.2 SHAP (SHapley Additive exPlanations)
数学原理
基于合作博弈论中的 Shapley 值,量化每个特征对预测结果的边际贡献。
ϕi=∑S⊆N∖{i}∣S∣!(∣N∣−∣S∣−1)!∣N∣!f(S∪{i})−f(S)\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!(|N|-|S|-1)!}{|N|!} f(S \\cup \\{i\\}) - f(S)ϕi=∑S⊆N∖{i}∣N∣!∣S∣!(∣N∣−∣S∣−1)!f(S∪{i})−f(S)
通俗举例
巴塞尔协议合规审计。监管机构要求解释某信用评分模型评级下调逻辑。严格计算每个风险特征(如宏观经济指标、历史违约记录)的边际贡献,出具具有法律约束力的归因报表。
参考提示词
"System: 给定 XGBoost 模型的 SHAP 值输出数组。提取出正向贡献和负向贡献最大的特征簇,量化解释单个样本预测值与基线期望值的偏差。"
例子代码
python
import shap
import xgboost
model = xgboost.train(params, dtrain)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X)代码讲解
利用 TreeExplainer 针对树模型生成解析器。执行 shap_values 函数计算特征空间的全局/局部沙普利值。通过 summary_plot 输出依赖可视化图谱。
1.2.3 LIME 与 SHAP 差异分析
意义区别
- LIME (局部代理机制): 核心在于"局部保真"。其数学本质是降维与局部线性逼近,放弃对模型全局逻辑的解释,仅在单一样本的极小邻域内构建可理解的简单边界。它回答的是:"在当前特征坐标点周边,模型是基于什么局部规则分类的"。
- SHAP (博弈论分配): 核心在于"公平归因分配"。其数学基石是合作博弈论,确保特征权重的加和严格等于实际输出与基线期望的差额。具备严格的数学一致性(Consistency),它回答的是:"每个特征对当前特定预测结果相较于平均基线水平的净贡献量是多少"。
使用场景区别
- LIME 适用场景: 低延迟的单点异常排查(Ad-hoc Debugging)。适用于工程师需要快速定性解释单个离群预测(如特定自然语言或图像的误判)时。其局部扰动机制计算开销极小、响应快,但存在采样随机性,不保证全局逻辑一致。
- SHAP 适用场景: 严苛监管审查与全局特征工程。在金融风控(如信贷拒件合规解释)、医疗辅助判定等面临外部审计的场景中,SHAP 提供防辩驳的数学基石。同时,聚合全体样本的 SHAP 值能输出全局特征重要度谱系,用于指导降维调优。缺点是对树模型以外的模型计算复杂度极高,耗时巨大。
2. RAG Agent (检索增强生成代理)
架构定义
RAG(Retrieval-Augmented Generation)架构是应对大语言模型知识幻觉和时效性缺陷的复合工程系统。该代理包含信息检索层(对接向量数据库的稠密检索或词频稀疏检索)与文本生成层(大语言模型解码器)。其评估体系从传统的标量比对,升级为同时量化"知识获取的精准度"与"文本生成的鲁棒性"的立体框架。
2.1 LLM as a Judge (语言模型作为裁判) 与 RAG Triad (RAG三元组)
架构定义
- LLM as a Judge(语言模型作为裁判): 放弃传统的启发式文本比对指标(如 BLEU、ROUGE),转而采用经过对齐指令微调的高阶大语言模型(如 GPT-4, Claude 3)作为自动化评估器。利用其语义理解与逻辑推理能力,通过设计严密的提示词范式,使其执行复杂的语义打分任务。
- RAG Triad(RAG三元组): 将 RAG 架构的误差来源解耦为三个相互正交的评估维度。检索模块(Retriever)由"上下文相关性"衡量;生成模块(Generator)由"忠实度"和"回答相关性"衡量。三者构成逻辑闭环,确保系统既不答非所问,也不凭空捏造。
2.1.1 Context Relevance (上下文相关性)
数学原理
度量检索召回上下文(Context)与查询(Query)的语义重合度。基于余弦相似度或判别模型:
Score=Cosine(Emb(Query),Emb(Context))Score = Cosine(Emb(Query), Emb(Context))Score=Cosine(Emb(Query),Emb(Context))
通俗举例
智能客服知识库检索。客户询问"大额存单提前支取如何计息",检索器召回了"大额存单购买门槛与额度"条款。两者同属核心业务,但上下文完全无法支撑回答客户提问,相关性极低。
参考提示词
"System: 评估上下文对查询的有效性,评分 0-1 之间。不要试图回答问题,只评估信息覆盖度。
Query: {query}
Context: {context}"
例子代码
python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
query_emb = model.encode("模型评估指标有哪些?")
context_emb = model.encode("F1分数是机器学习常用指标。")
score = util.cos_sim(query_emb, context_emb).item()代码讲解
加载轻量化模型计算文本稠密向量。调用 cos_sim 提取张量内积以标定量化相关性。
2.1.2 Faithfulness (忠实度)
数学原理
评估生成回答(Answer)是否严格基于检索上下文(Context),采用逻辑蕴含模型限制幻觉:
Faithfulness=∣Claimsentailed∣∣Claimstotal∣Faithfulness = \frac{|Claims_{entailed}|}{|Claims_{total}|}Faithfulness=∣Claimstotal∣∣Claimsentailed∣
通俗举例
理财条款解答。RAG模型依据《稳健型理财产品说明书》回答,但为迎合客户提问,凭空捏造了"承诺保本保息"条款。该脱离 Context 的回答属于严重违规幻觉,将引发合规灾难。
参考提示词
"System: 提取 Answer 中事实断言。严格检查是否能从 Context 中推导得出。如有任何超脱 Context 的捏造,扣除忠实度分数。
Context: {context}
Answer: {answer}"
例子代码
python
from evaluate import load
nli_model = load("evaluate-metric/nli")
context = "今天下午公司召开了评估会议。"
answer = "今天下午召开了会议,并发放了奖金。"
result = nli_model.compute(predictions=[answer], references=[context])代码讲解
加载 NLI 推理模型。回答作预测,上下文作参考。模型前向传播输出蕴含/矛盾/中立类别以判别幻觉。
2.1.3 Answer Relevance (回答相关性)
数学原理
评估回答是否有效解决原问题。通常通过反向问题生成模型计算:
Score=1N∑Cosine(Emb(Query),Emb(GenQueryi))Score = \frac{1}{N} \sum Cosine(Emb(Query), Emb(GenQuery_i))Score=N1∑Cosine(Emb(Query),Emb(GenQueryi))
通俗举例
VIP财富顾问话术。客户询问"这款QDII基金汇率风险多大",模型回答了整页"该基金过往十年的收益曲线"。内容全对且基于事实,但完全规避了核心痛点,相关性极差。
参考提示词
"System: 基于 Answer 逆向生成 3 个可能引出此回答的 Query。计算与原 Query 的语义相似度平均值。
Original Query: {query}
Answer: {answer}"
例子代码
python
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
original_query = "如何提高召回率?"
generated_query = "提升召回率的方法是什么?"
score = util.cos_sim(model.encode(original_query), model.encode(generated_query)).item()代码讲解
针对回答逆向生成查询。计算生成查询与原始查询的高维空间向量相似度,得出指标评分。
2.2 Ground-truth Evaluation (基准事实评估)
架构定义
这是对抗评估器自身缺陷(如 LLM 作为裁判可能存在的大模型幻觉、长度偏好等)的兜底机制。基准事实评估通过直接比对模型输出与经过人工强校验、具备绝对正确性的基准数据集(Ground-truth),提供系统表现的最底层置信度与确定性指标。
2.2.1 Golden Dataset (黄金数据集)
数学原理
构建人工校验的 Ground-truth 集合。计算输出向量 OOO 与基准向量 GGG 的误差矩阵 E=Metric(O,G)E = Metric(O, G)E=Metric(O,G)衡量全局能力。
通俗举例
核心系统测算 UAT 用例库。由资深业务专家(SME)多轮校验后锁定的信贷测算 QA 集。新模型输出的利息结果只要与此基准集存在一分钱偏差,即判定模型发布失败。
参考提示词
"System: 你是数据审查流水线。校验 QA 数据对是否无歧义且事实正确。仅保留置信度超过 0.99 的数据。
QA Pair: {qa_pair}"
例子代码
python
import pandas as pd
data = {
'query': ['Precision定义?'],
'ground_truth': ['预测正例中真实正例比例'],
'metadata': ['source: sklearn']
}
golden_df = pd.DataFrame(data)
golden_df.to_csv('golden_dataset.csv', index=False)代码讲解
定义静态结构体 data,包含硬编码的 query 与无误的 ground_truth,关联溯源元数据。序列化为 CSV 锁定基准版本。