1987年,日立总工程师牧本次生提出"牧本波动",指出芯片的发展大约每十年会在"通用硬件"和"专用硬件"之间交替演进。过去十年,通用服务器和软件定义方案主导市场,超融合(HCI)也正是在这一背景下诞生,提供高效、便捷且低成本的基础设施方案。而随着摩尔定律逐渐放缓,通用硬件的性能增长受到限制,专用硬件再次成为提升系统性能的重要手段,这一趋势也体现在"极致低延时"的专用网卡层面。
为进一步优化虚拟化环境的性能,SmartX 榫卯超融合引入多种专用硬件技术的支持能力,在网卡层面,通过 SR-IOV 与 PCI 直通技术,使虚拟机能够直接访问 kernel bypass 网卡,从而实现高速、低延迟的网络传输。本文将简述 kernel bypass 网卡的诞生背景,并介绍如何以超融合架构支持 kernel bypass 网卡,以及其在超融合架构中的真实性能表现------以榫卯超融合支持 Solarflare 低延时网卡,延迟可降低至 2-3 us。
为什么需要 kernel bypass 网卡
传统 TCP/IP 网络的问题
在目前绝大多数计算机系统中,网络通信都依赖于一个成熟且通用的架构------操作系统内核协议栈。当应用程序需要发送或接收数据时,数据包必须穿越这条"标准路径":它首先抵达网卡,通过硬件中断通知 CPU,随后被送入内核空间,经过 TCP/IP 协议栈的复杂处理,包括分组校验、排序、拥塞控制等,最终还需跨越用户与内核空间的边界,通过一次内存拷贝交付给应用程序。
这条路径虽然稳定可靠,但其设计初衷是为了通用性和兼容性,而非极致性能。其瓶颈在于频繁的上下文切换(在用户态和内核态之间来回切换)、多次的内存拷贝以及沉重的内核处理开销。这些操作会消耗大量的 CPU 时钟周期,并引入不可忽视的延迟,使得网络通信的响应时间通常停留在毫秒级别。
对于网页浏览或文件传输等普通应用,这种开销无伤大雅。**然而,在高频交易、实时金融行情、高性能计算等前沿领域,网络延迟每增加一微秒都可能意味着巨大的损失或性能落差。**正是传统 TCP/IP 网络的固有缺陷,催生了 kernel bypass 技术。
kernel bypass 技术:避免内核协议栈开销,大幅降低延迟
传统网络延迟较高的根本原因在于操作系统内核过多地参与了网络传输过程。kernel bypass(内核旁路)技术通过构建一条从网卡直达用户态应用的"高速通道",有效避开内核协议栈的处理瓶颈。
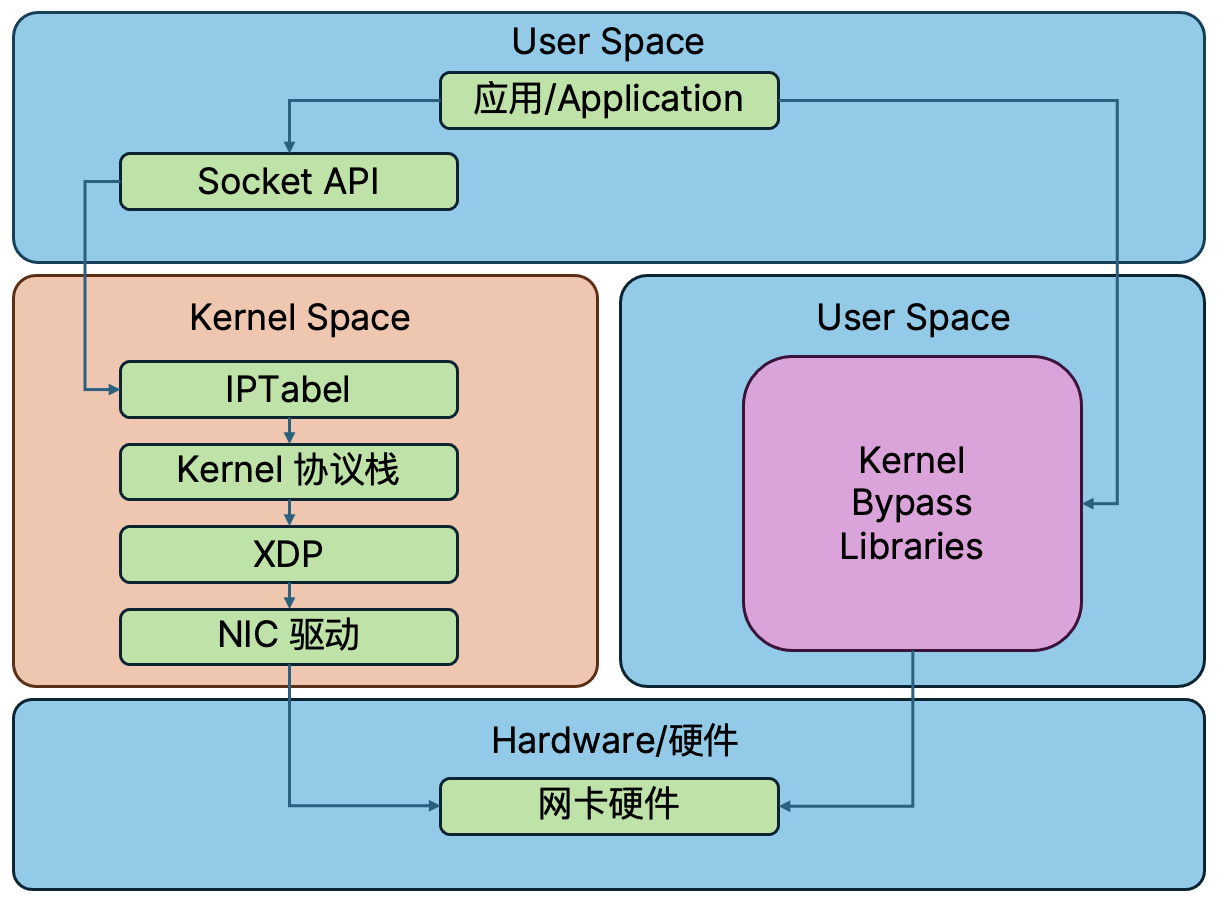
传统 TCP/IP 处理方式对比 kernel bypass
其核心机制包括:
- 用户态轻量驱动:在用户空间实现驱动,直接管理网卡;通过内存映射(mmap)让应用能够高效收发数据。
- 零拷贝 DMA:利用网卡 DMA 功能,将数据直接读写到用户态预分配的内存池;消除了内核与用户空间之间的数据搬运开销。
- 轮询驱动模式:采用高效轮询代替中断;CPU 主动处理数据,避免中断延迟和抖动。
基于这三大机制,kernel bypass 技术将网络处理延迟从毫秒级降至微秒级,同时减少了网络处理过程中内核态的占用,使 CPU 计算周期更多用于用户态应用逻辑,从而保障高性能网络处理。
kernel bypass 网卡:避免应用改造与 CPU 高占用,进一步优化性能和抖动
尽管 kernel bypass 技术能够显著优化系统网络性能,但仍存在两类核心问题:
- 应用改造要求:纯软件实现的内核旁路通常需要对应用程序的网络逻辑进行重构,以支持用户态网络调用。
- CPU 占用高:内核旁路仅将网络处理从内核态迁移至用户态,网络任务仍需大量 CPU 参与,占用关键计算资源。
kernel bypass 网卡是将内核旁路技术和硬件卸载技术结合起来的技术方案,目前主流的产品包括 AMD Solerflare 系列网卡的 Onload 技术、Nvidia Mellanox 系列网卡的 VMA 技术,以及 Cisco Exablaze 系列网卡的 ExaNIC Software 技术等等。这类解决方案在 kernel bypass 的基础上,实现了部分网络功能在网卡硬件上的卸载,从而进一步增强了其网络能力。
针对之前的问题,kernel bypass 网卡及配套解决方案的主要思路为:
- 采用用户态 TCP/IP 协议栈避免应用改造:应用可继续使用标准 socket API,无需改动现有代码。通过操作系统侧的网卡卸载组件,实现对流量的透明劫持。
- 硬件 offload:CPU 只进行协议面的管理,由网卡硬件进行数据面的管理,大幅降级了网络 I/O 过程中 CPU 的参与。
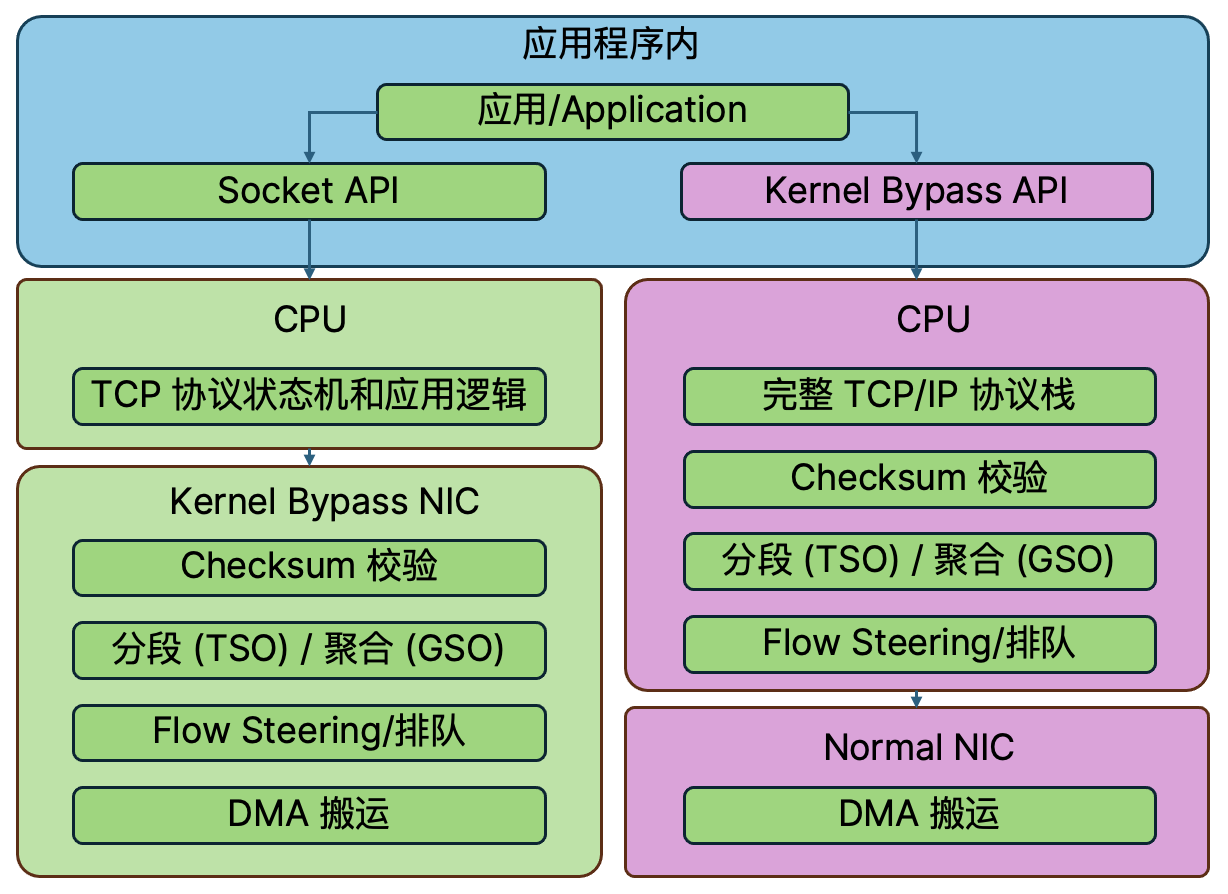
kernel bypass 硬件卸载方案对比软件方案
上述改进提升了 kernel bypass 技术的可用性,通过"绕过内核、零拷贝、减少上下文切换、硬件offload"等手段,kenel bypass 网卡将微秒级延迟和抖动降至最低,使其成为低延迟应用场景的理想技术方案。
kernel bypass 网卡在超融合架构的性能表现:基于榫卯超融合,延迟低至 2-3 us
如何以超融合架构支持 kernel bypass 网卡
在期货、证券等行业,一些客户通过自定义交易策略进行量化交易。其中,高频交易对市场波动极为敏感,毫秒级甚至微秒级的延迟都可能显著影响交易收益。针对这类场景,业界通常会采用以 Solarflare 的 kernel bypass 网卡为代表的方案来降低网络延迟。
传统部署方案中,这类网卡通常安装在物理服务器上,并为每台服务器配备独立网卡,从而大幅增加硬件成本。虚拟化技术的引入,可以有效降低硬件投入,实现更灵活的资源利用。
然而,传统虚拟化网络一般使用 virtio 或类似虚拟网卡为虚拟机提供网络接口,并不具备物理服务器上 Kernel Bypass 网卡的高性能特性。为解决这一问题,榫卯超融合支持了网卡直通功能,能够将 PCI 网卡与 SR-IOV 网卡直通给虚拟机使用。
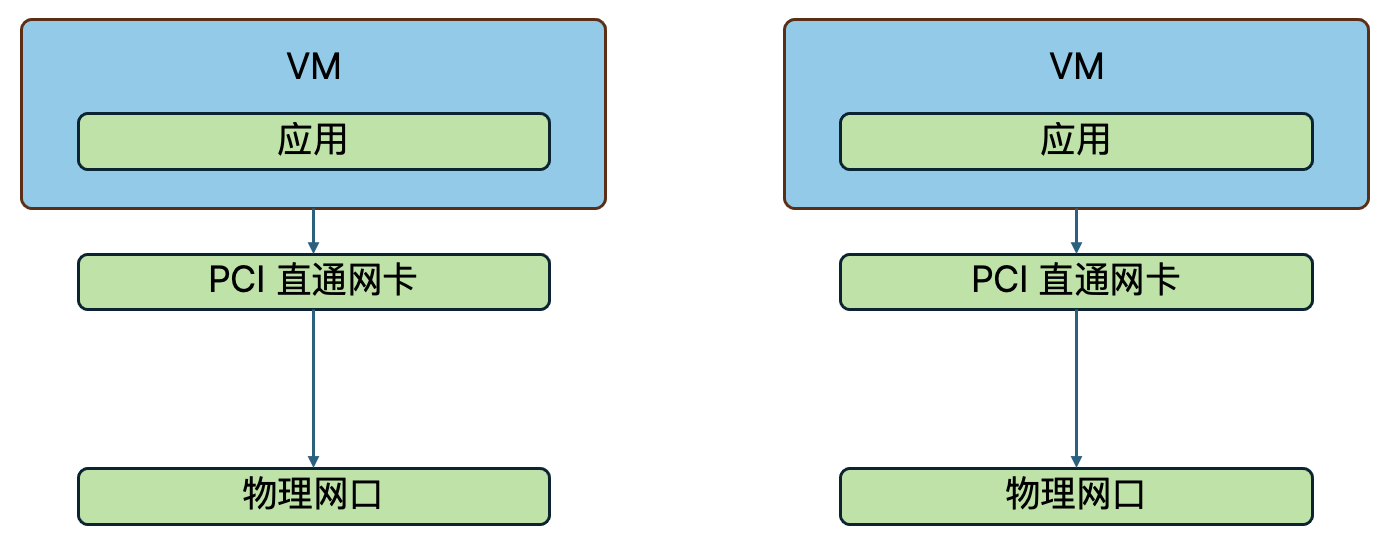
- PCI 网卡直通:将主机上的网卡作为 PCI 直通网卡透传给虚拟机使用,该网卡由这台虚拟机独占。
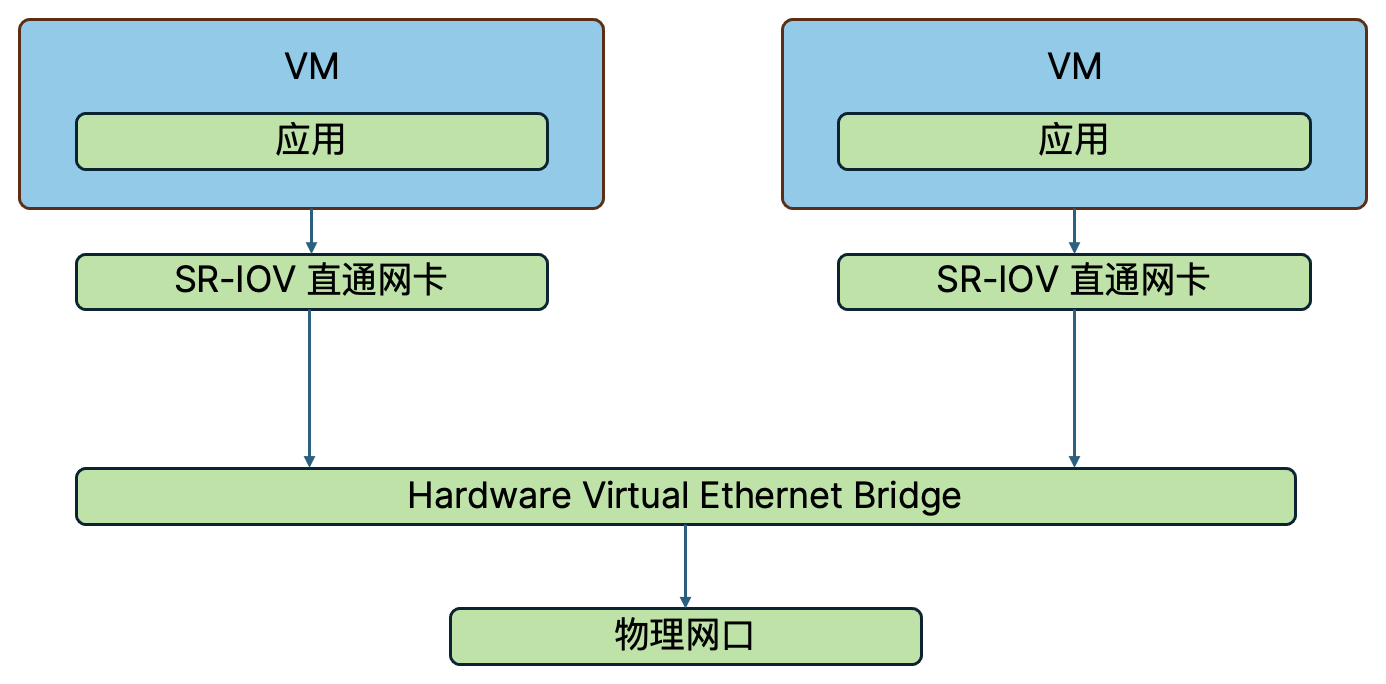
- SR-IOV 直通:将一个支持 SR-IOV 的物理网卡虚拟化出多个 VF (Virtual Function),作为 SR-IOV 直通网卡直接挂载给虚拟机使用,可实现多个虚拟机共享同一个物理网卡的通信能力。
欢迎获取《超融合技术原理与特性解析合集》三册电子书,了解更多网络 I/O 虚拟化相关功能特性。
网卡直通可将物理网卡的全部特性直接映射至虚拟机中,实现虚拟机对物理网卡的完全访问。通过该功能,虚拟机可以使用包括 PTP 精准对时、Onload 卸载等在内的硬件加速功能,从而满足期货交易、高性能计算等高网络性能场景的需求。
kernel bypass 网卡在超融合架构的性能表现实测
在基于榫卯超融合和 Solarflare 低延迟网卡的测试用例中,我们借助 sfnettest 工具进行点对点延迟测试,分别测试了五种场景下的延迟情况:
- VM to VM(虚拟网卡):在超融合平台上跨节点部署两台虚拟机,虚拟机挂载虚拟网卡,测试延迟情况,该测试结果作为基准值,对比其他方案的延迟下降情况。
- VM to Host(SR-IOV):在超融合平台上部署一台虚拟机,挂载 SR-IOV 网卡,测试和物理机的延迟情况。
- VM to VM(SR-IOV 网卡):在超融合平台上跨节点部署两台虚拟机,虚拟机挂载 SR-IOV,测试延迟情况。
- VM to Host(onload 加速方案):在超融合平台上部署一台虚拟机,虚拟机挂载 SR-IOV,物理服务器使用物理网卡,两者正确识别网卡后启动加速方案,测试延迟情况。
- VM to VM(onload 加速方案):在超融合平台上跨节点部署两台虚拟机,虚拟机挂载 SR-IOV,正确识别网卡后启动加速方案,测试延迟情况。
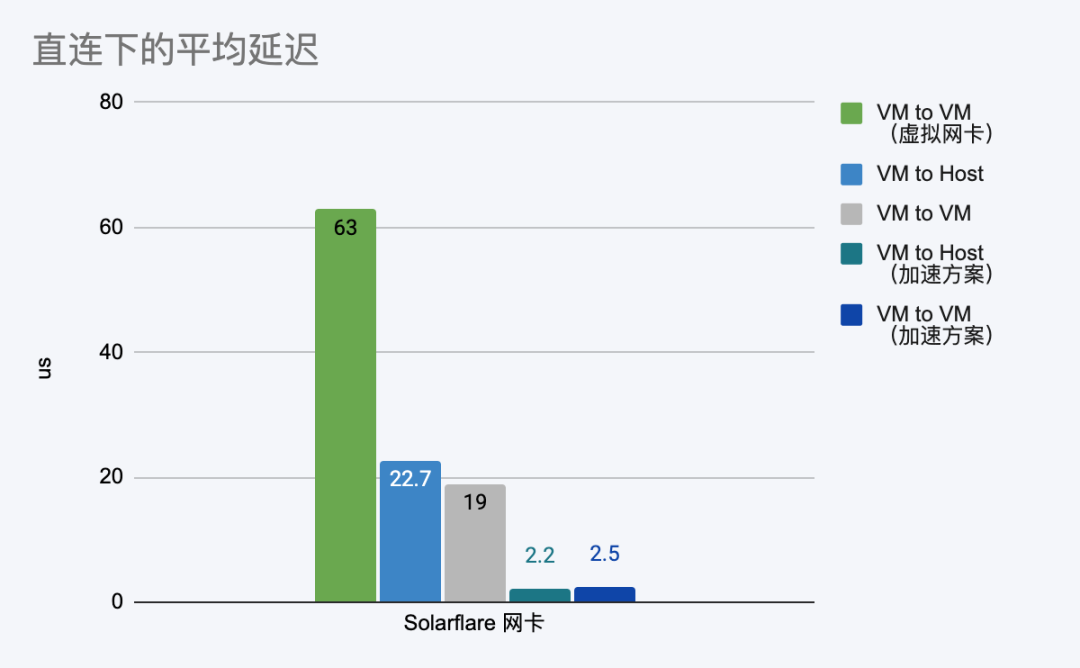
测试结果表明,在点对点直连方式下(不经过中间交换机),仅使用虚拟网卡,延迟情况并不能满足低延迟应用的使用需要。而采用 SR-IOV 直通网卡,即使是在不使用加速方案的情况下,VM to VM 和 VM to Host 场景下均可大幅降低延迟。在启用了网络加速方案后,Solarflare 网卡结合onload 加速方案,在各场景下还可进一步降低延迟至 2-3 us。
目前,某证券机构已在极速交易生产环境验证了榫卯超融合+Solarflare 低延迟网卡的性能表现,并以低延时虚拟机支持客户策略机,成本相较物理机降低 50% 以上,电量消耗降低约 50%。
总结
为应对现代应用对于基础设施的更高要求,SmartX 榫卯超融合通过 SR-IOV 以及 PCI 网卡直通技术,把 kernel bypass 网卡引入到虚拟化环境中,实现了虚拟化网络性能的提升和成本的下降,为企业用户构建基于超融合架构的高性能云化数据中心提供了可落地的技术方案。
附录:测试物理机配置

作者:SmartX 金融团队技术工程师 陈瑞川
推荐阅读:
一文解读 SmartX 超融合虚拟化下的网络 I/O 虚拟化技术
榫卯超融合6.3高可用能力解读|SR-IOV/vGPU/HCT设备虚拟机HA,更全面的高可用覆盖