1. 简介
Elasticsearch(简称ES)是一个基于Apache Lucene构建的、开源的分布式搜索和分析引擎,以其近实时处理、高扩展性和易用的RESTful API而著称,广泛应用于日志分析、全文检索和实时数据分析等场景
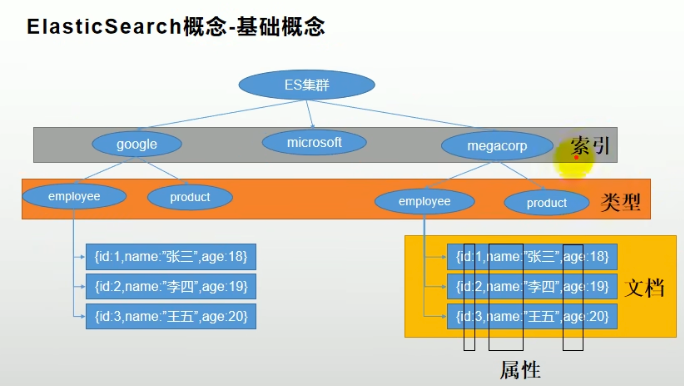
1.1 es的关键对象
- 索引index:类似mysql中的database,一个个的数据库
- 类型type:类似mysql中的表(es8中取消了)
- 文档document:json格式,类似mysql中每一行的数据

1.2 倒排索引:
es在存储数据时,除了会存储一份原始的记录文本,同时还会存储一份倒排索引记录表。
倒排索引表维护了哪个单词在哪个记录中被使用
如下图的5条记录的插入逻辑为:
- 红海行动:插入一份红海记录到记录表,id为1;同时将红海行动分词,插入到倒排索引表,红海-1,行动-1
- 探索红海行动:插入一份探索红海记录到记录表,id为2;同时将探索红海行动分词,插入到倒排索引表,红海-2,行动-2,探索2
- 以下类似。。
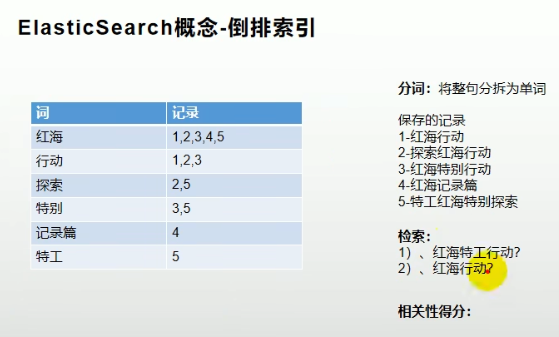
同时查询的时候,会将红海特工行动分为3个词,然后去倒排索引表中找到分词后的词对应的记录,然后根据匹配到的数据量进行得分,进行展示
2. docker安装elasticsearch
- 环境准备
bash
# 设置内核参数(必须,否则ES无法启动)
sudo sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
# 创建数据目录(注意权限)
sudo mkdir -p /home/dockerData/elasticsearch/{data,logs,config,plugins}
sudo chown -R 1000:1000 /home/dockerData/elasticsearch- 拉取镜像:(这里用最新稳定版8.17.0)
bash
docker pull elasticsearch:8.17.0- 启动容器
bash
docker run -d \
--name elasticsearch \
--restart=always \
-p 9200:9200 \
-p 9300:9300 \
-m 1.5g \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \
-e "xpack.security.enabled=true" \
-e "xpack.security.enrollment.enabled=true" \
-v /home/dockerData/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-v /home/dockerData/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/dockerData/elasticsearch/logs:/usr/share/elasticsearch/logs \
elasticsearch:8.17.0- -m 1.5g:限制容器总内存不超过 1.5GB,防止 OOM。
- ES_JAVA_OPTS=-Xms1g -Xmx1g:堆内存固定 1GB,剩余 500MB 给非堆、元空间和操作系统开销。
- 获取初始密码
bash
docker logs elasticsearch 2>&1 | grep "Password for the elastic user"- 如果没有活到密码则重置密码:
bash
docker exec -it elasticsearch bin/elasticsearch-reset-password -u elastic -i- 验证安装
bash
# 使用密码访问
curl -u elastic:你的密码 http://localhost:9200
#输出:
{
"name" : "1fd3fd837397",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "iROLj3ZnTaiWdzh6uu3K4Q",
"version" : {
"number" : "8.17.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2b6a7fed44faa321997703718f07ee0420804b41",
"build_date" : "2024-12-11T12:08:05.663969764Z",
"build_snapshot" : false,
"lucene_version" : "9.12.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}3. kibana安装
- 创建kibana数据目录
bash
sudo mkdir -p /home/dockerData/kibana/{data,logs,config}
sudo chown -R 1000:1000 /home/dockerData/kibana # Kibana 容器内用户 uid=1000- 拉取镜像(版本需要跟ES一致)
bash
docker pull kibana:8.17.0- 准备配置文件:创建 /home/dockerData/kibana/config/kibana.yml,内容如下:
vi
bash
server.host: "0.0.0.0"
server.port: 5601
elasticsearch.hosts: ["http://elasticsearch:9200"] # 注意:这里是容器内服务名,需要网络互通
elasticsearch.username: "elastic"
elasticsearch.password: "你的密码"
xpack.security.enabled: true- 创建docker网络
- 为了容器间通信,创建一个桥接网络:
bash
docker network create myDocNet- 将 Elasticsearch 容器连接到该网络(如果之前未连接):
bash
docker network connect myDocNet elasticsearch- 查看连接状态:
bash
docker inspect elasticsearch | grep -A 5 Networks- 启动kibana容器
bash
docker run -d \
--name kibana \
--restart=always \
-p 5601:5601 \
--network myDocNet \ # 与 ES 同一网络
-m 512m \ # 限制容器最大内存 512MB
-e "NODE_OPTIONS=--max-old-space-size=384" \ # 限制 Node.js 堆内存 384MB
-v /home/dockerData/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
-v /home/dockerData/kibana/data:/usr/share/kibana/data \
-v /home/dockerData/kibana/logs:/usr/share/kibana/logs \
kibana:8.17.0- 启动失败:FATAL Error: config validation of \[elasticsearch.username]: value of "elastic" is forbidden. This is a superuser account that cannot write to system indices that Kibana needs to function. Use a service account token instead. Learn more: https://www.elastic.co/guide/en/elasticsearch/reference/8.0/service-accounts.html
- 问题分析:错误是 Kibana 8.x 的安全策略限制:不再允许使用超级用户 elastic 作为 Kibana 的系统用户。Kibana 需要写入自己的系统索引,而 elastic 用户被禁止对这些索引进行操作。正确的做法是使用服务账户(Service Account)或专用的内置用户(如 kibana_system)
- 使用内置用户kibana_system并设置密码:Elasticsearch 自带一个名为 kibana_system 的内置用户,专门用于 Kibana 连接。你需要为该用户设置一个密码,然后在 Kibana 配置中使用它:
- 重置密码:
bash
docker exec -it elasticsearch bin/elasticsearch-reset-password -u kibana_system -i- 修改配置:
bash
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://elasticsearch:9200"]
elasticsearch.username: "kibana_system"
elasticsearch.password: "你刚设置的密码"4. _cat命令:基本信息查看
GET/_cat/nodes:查看所有节点_
bash
http://192.168.137.14:9200/_cat/nodes :
返回
127.0.0.1 61 91 11 0.08 0.49 0.87 dilm * 0adeb7852e00
注:*表示集群中的主节点GET/_cat/health:查看es健康状况
bash
http://192.168.137.14:9200/_cat/health
返回
1588332616 11:30:16 elasticsearch green 1 1 3 3 0 0 0 0 - 100.0%
注:green表示健康值正常GET/_cat/master:查看主节点_
bash
http://192.168.137.14:9200/_cat/master
返回
vfpgxbusTC6-W3C2Np31EQ 127.0.0.1 127.0.0.1 0adeb7852e00GET/_cat/indicies:查看所有索引 ,等价于mysql数据库的show databases;
json
http://192.168.137.14:9200/_cat/indices
返回
green open .kibana_task_manager_1 KWLtjcKRRuaV9so_v15WYg 1 0 2 0 39.8kb 39.8kb
green open .apm-agent-configuration cuwCpJ5ER0OYsSgAJ7bVYA 1 0 0 0 283b 283b
green open .kibana_1 PqK_LdUYRpWMy4fK0tMSPw 1 0 7 0 31.2kb 31.2kb5. 索引相关命令
- 创建索引:
PUT /my_index - 查看索引:
GET /_cat/indices?v - 查看索引映射:
GET /my_index/_mapping - 删除索引:
DELETE /my_index - 给索引添加别名:
POST /_aliases
6. 文档相关命令(具体某一行数据)
6.1 创建/修改文档:PUT /my_index/_doc/1
注意:这里的_doc是固定的
- Elasticsearch 7.x 开始:一个索引只能有一个类型,官方将默认类型名统一为 _doc,但不再支持多类型。API 路径中的 _doc 变成了固定的部分,表示"文档端点",而不是具体的类型名。
- Elasticsearch 8.x:继续沿用 _doc,并彻底移除了类型的概念。因此 PUT /my_index/_doc/1 是创建或更新文档的标准写法。
bash
# 请求json
{
"title": "Elasticsearch Guide",
"price": 29.99,
"created_at": "2025-03-27"
}
# 返回内容
{
"_index": "my_index",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}返回信息解释:这些返回的JSON串的含义;这些带有下划线开头的,称为元数据,反映了当前的基本信息。
-
"_index": "customer":表明该数据在哪个数据库下;
-
"_type": "external":表明该数据在哪个类型下;
-
"_id": "1":表明被保存数据的id;
-
"_version": 1:被保存数据的版本
- 再次执行上述接口,可以看到version变为了2:
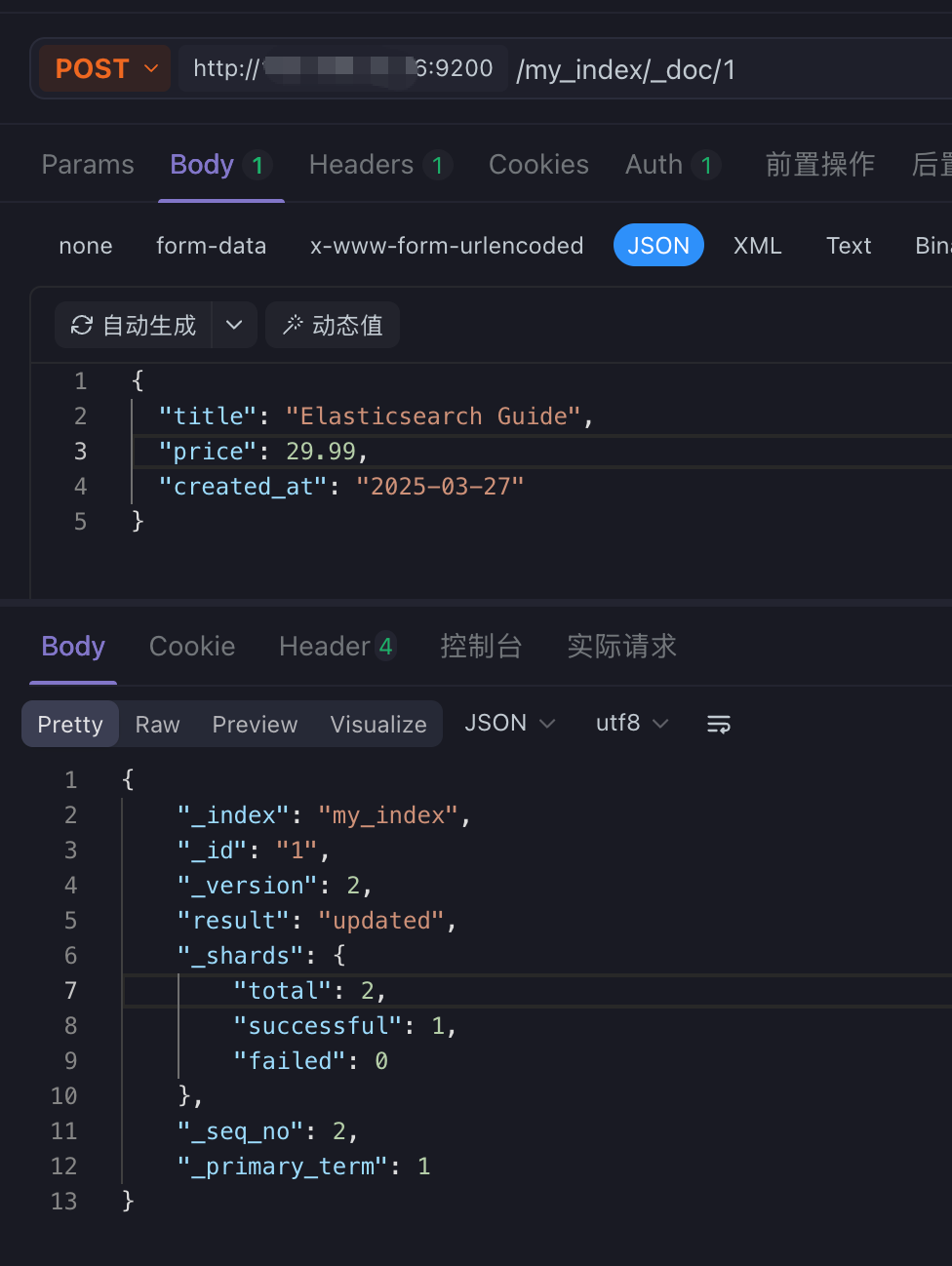
- 再次执行上述接口,可以看到version变为了2:
-
"result": "created":这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。
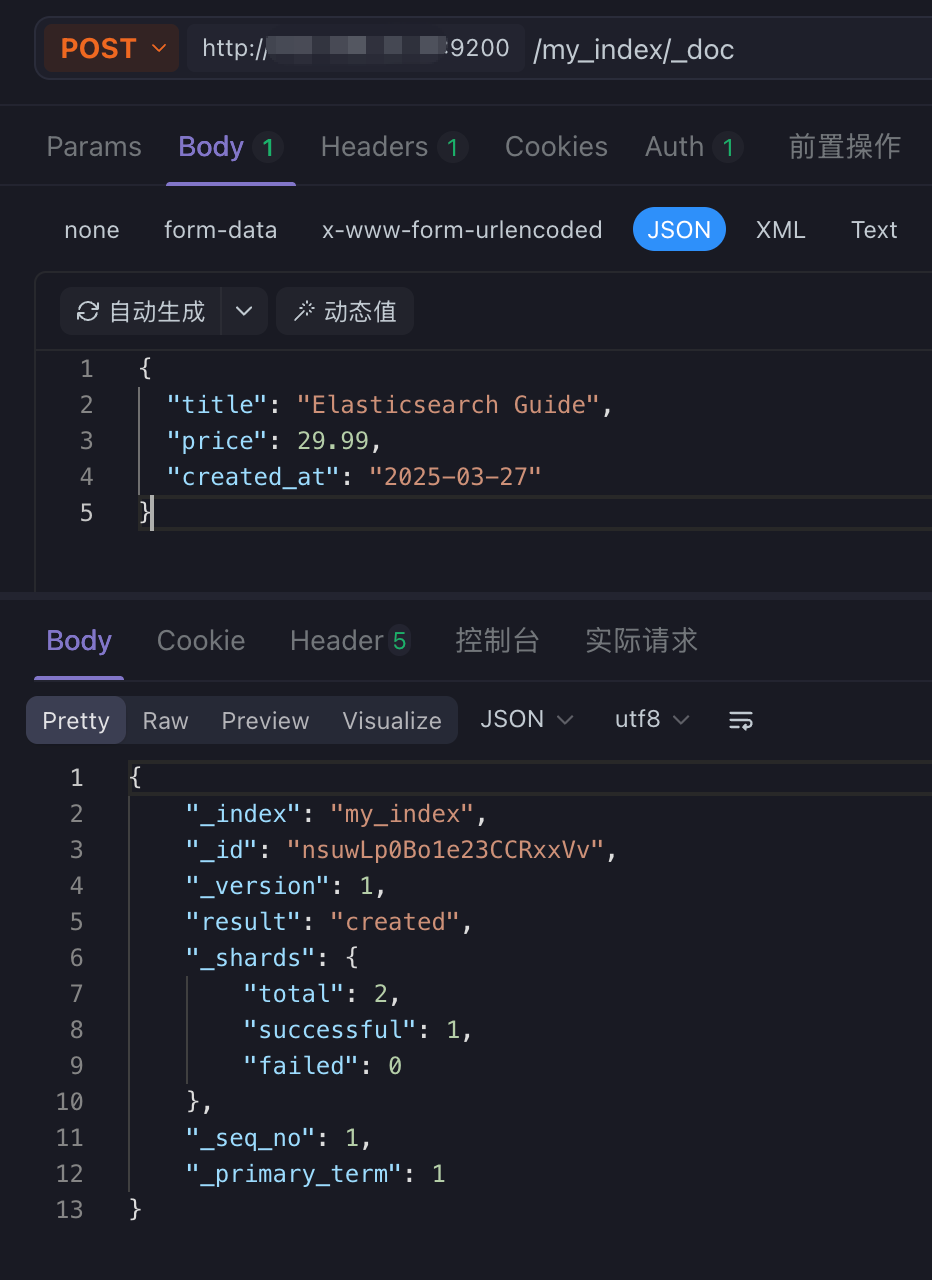
6.1.1 创建随机id文档:POST /my_index/_doc
可以看到_id是随机生成的
6.3 获取文档:GET /my_index/_doc/1
bash
# 返回内容:
{
"_index": "my_index",
"_id": "2",
"found": false
}6.4 更新文档(部分更新):POST /my_index/_update/1
注意:如果更新操作的内容跟原来一致,则seq_no、version等不会变化
bash
#请求内容:
{
"doc": {
"price": 24.99
}
}
# 返回值:
{
"_index": "my_index",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}6.4.1 乐观锁的使用:
在 Elasticsearch 中,_seq_no 和 _primary_term 是文档级别的版本控制字段,用于实现乐观锁并发控制,防止多个客户端同时更新同一文档时发生数据覆盖。
- 基本概念:

- 乐观锁的使用:使用 if_seq_no 和 if_primary_term
在更新、删除文档时,可以指定条件,要求文档当前的 _seq_no 和 _primary_term 必须与给定值匹配,否则操作失败(返回 409 Conflict)。这样可以避免"丢失更新"问题。 - 更新使用:
POST /my_index/_update/1?if_seq_no=5&if_primary_term=2
如果文档的 _seq_no 和 _primary_term 恰好是 5 和 2,则更新成功,并且新的 _seq_no 会变成 6,_primary_term 保持不变(除非主分片切换)。如果不匹配,Elasticsearch 返回:
bash
{
"error": {
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, current seqNo [5], primaryTerm [2] ..."
},
"status": 409
}-
删除使用:
DELETE /my_index/_doc/1?if_seq_no=5&if_primary_term=2 -
为什么需要 _primary_term:单纯使用 _seq_no 还不够,因为分片可能发生主从切换。例如:
- 原始主分片在任期 1 中处理了操作,_seq_no 递增到 5。
- 主分片故障,新主分片在任期 2 中接管,它的 _seq_no 可能从 0 开始重新计数(但实际不会重置,只是新任期会有新的序列号空间)。
- 如果没有 _primary_term,旧的副本(任期 1)可能会用自己旧的 _seq_no 值来更新,造成混乱。加入 _primary_term 后,条件检查会拒绝不同任期的操作,保证数据一致性。
-
实际应用建议:
- 在应用层实现乐观锁:读取文档时保存返回的 _seq_no 和 _primary_term,更新时作为条件带上。
- 避免使用 _version:_version 是遗留的版本号,在 6.x 后已弱化,推荐使用 _seq_no + _primary_term。
- 批量操作:_bulk API 也支持在每个操作中指定 if_seq_no 和 if_primary_term
6.5 删除文档:DELETE /my_index/_doc/1
bash
# 返回内容:
{
"_index": "my_index",
"_id": "1",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}6.6 批量操作:POST /_bulk
第一次执行报错:缺少最后的换行符:确保最后一行后面有一个空行(即两次换行符)
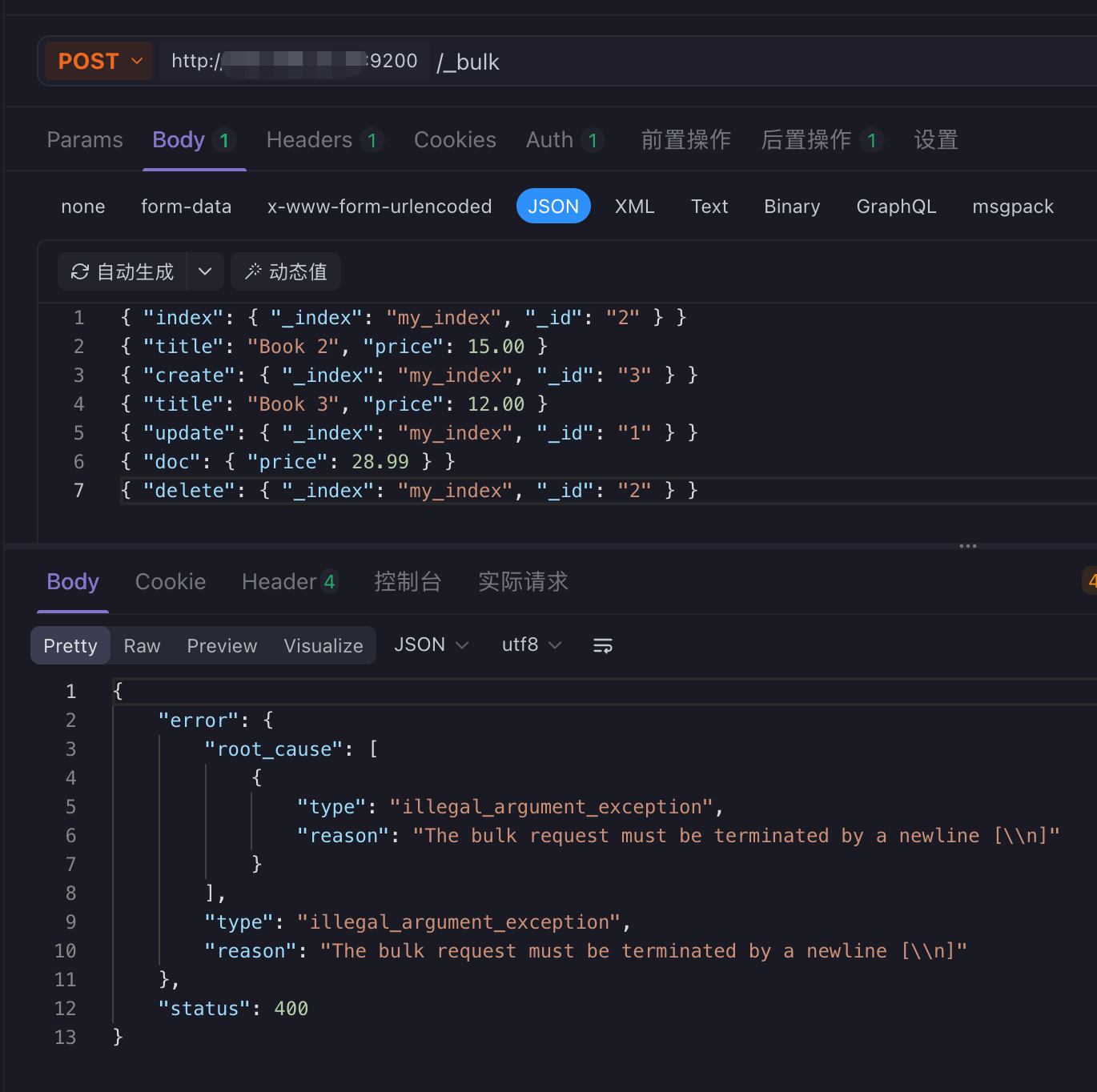
添加了最后一个换行符之后:
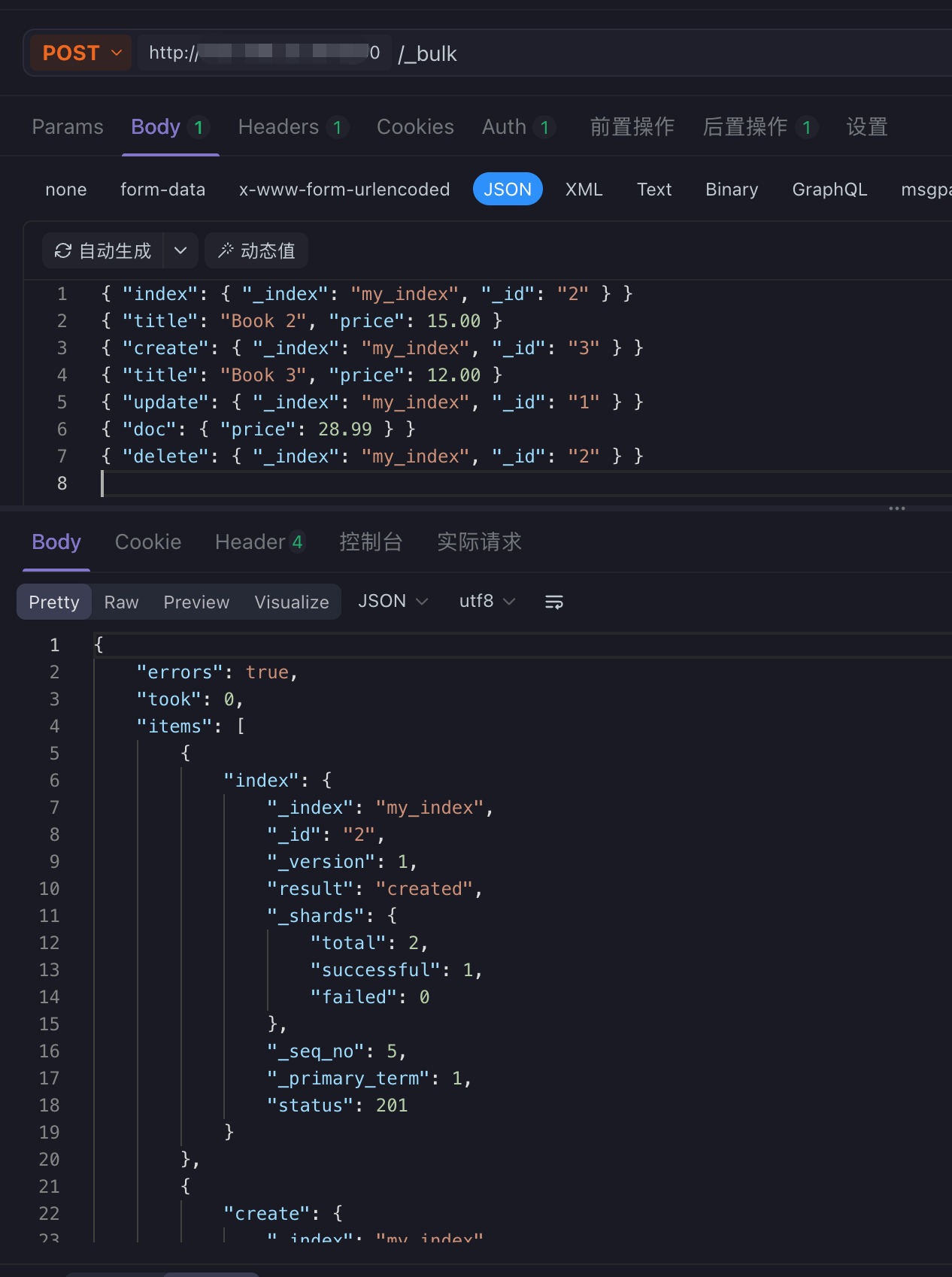
7. 搜索与查询相关命令
7.1 简单搜索(查看所有):/my_index/_search
返回:
json
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_id": "nsuwLp0Bo1e23CCRxxVv",
"_score": 1.0,
"_source": {
"title": "Elasticsearch Guide",
"price": 29.99,
"created_at": "2025-03-27"
}
},
{
"_index": "my_index",
"_id": "3",
"_score": 1.0,
"_source": {
"title": "Book 3",
"price": 12.00
}
}
]
}
}7.2 条件查询
传參均为:/my_index/_search
7.2.1 match全文检索:哪个属性匹配哪个值
- 如果是字符串,则是模糊查询,因为这个匹配的值是分词后的值
- 如果是数字之类的值,就是精确匹配
- 全文检索会按照评分进行排序
bash
# 请求内容:
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
# 返回内容:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "my_index",
"_id": "nsuwLp0Bo1e23CCRxxVv",
"_score": 0.9808291,
"_source": {
"title": "Elasticsearch Guide",
"price": 29.99,
"created_at": "2025-03-27"
}
}
]
}
}
# 请求内容:
{
"query": {
"match": {
"title": "Elasticsear"
}
}
}
# 返回内容
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}7.2.1.1 match_phrase:短语匹配
匹配包括完整短语的数据,不会将查询的短语进行分词后再去查询。
bash
{
"query": {
"match_phrase": {
"address": "Elasticsear Guide"
}
}
}7.2.1.2 multi_match:多字段匹配
匹配多个字段,只要有字段包含这个数据,就可以返回
bash
{
"query": {
"multi_match": {
"query": "Elasticsear",
"fields": ["title","price"] # 只要title或者price能匹配数据,就可以返回
}
}
}7.2.2 term精确匹配(keyword类型)
推荐精确字段使用term进行查询,比如年龄、id、车牌号等。
规范:非字符串类型的数据都使用term来进行查询,字符串类型都使用match。
bash
# 请求内容:
{
"query": {
"term": {
"title.keyword": "Elasticsearch Guide"
}
}
}
# 上述查询等价于:
# 与match_pharse的区别是,match是精确查找,match_pharse还是模糊查询
{
"query": {
"match": {
"title.keyword": "Elasticsearch Guide"
}
}
}
# 返回值:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "my_index",
"_id": "nsuwLp0Bo1e23CCRxxVv",
"_score": 0.9808291,
"_source": {
"title": "Elasticsearch Guide",
"price": 29.99,
"created_at": "2025-03-27"
}
}
]
}
}7.3 范围查询
bash
# 请求内容
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 30
}
}
}
}
# 返回值:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_id": "nsuwLp0Bo1e23CCRxxVv",
"_score": 1.0,
"_source": {
"title": "Elasticsearch Guide",
"price": 29.99,
"created_at": "2025-03-27"
}
},
{
"_index": "my_index",
"_id": "3",
"_score": 1.0,
"_source": {
"title": "Book 3",
"price": 12.00
}
}
]
}
}7.4 布尔组合查询
合并多个查询条件
- must:必须满足的条件
- must_not:必须不匹配的条件
- should:可以满足也可以不满足,满足了最好。
- 不满足的话分数就没有其他的分数高
- filter:结果过滤;跟must一样的功能。
但是filter不会计算相关性得分
bash
# 请求内容
{
"query": {
"bool": {
# must代表必须满足的条件,这里就是必须满足titl包含Guide
"must": [
{ "match": { "title": "Guide" } }
],
# filter和must的用处一样,但是filter不会计算相关性得分
"filter": [
{ "range": { "price": { "lte": 30 } } }
]
}
}
}
# 返回值
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "my_index",
"_id": "nsuwLp0Bo1e23CCRxxVv",
"_score": 0.9808291,
"_source": {
"title": "Elasticsearch Guide",
"price": 29.99,
"created_at": "2025-03-27"
}
}
]
}
}7.5 分页与排序
bash
# 请求:
{
# 分页规则
"from": 0, # 从第几条数据
"size": 10,# 拿多少条数据
# 排序规则,是个数组,可以写多个
"sort": [
{ "price": "asc" }
],
# 查询条件
"query": { "match_all": {} }
# 限制返回的内容
"_source":["title","price"]
}
# 返回:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
# 真正需要的数据
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "my_index",
"_id": "3",
"_score": null,
"_source": {
"title": "Book 3",
"price": 12.00
},
"sort": [
12.0
]
},
{
"_index": "my_index",
"_id": "nsuwLp0Bo1e23CCRxxVv",
"_score": null,
"_source": {
"title": "Elasticsearch Guide",
"price": 29.99,
# 设置_source后不显示此行数据
# "created_at": "2025-03-27"
},
"sort": [
29.99
]
}
]
}
}8. 聚合分析
所有聚合分析的请求方法都为:GET /my_index/_search
8.1 桶聚合(terms)
8.1.1 基于字段值的分桶包括:
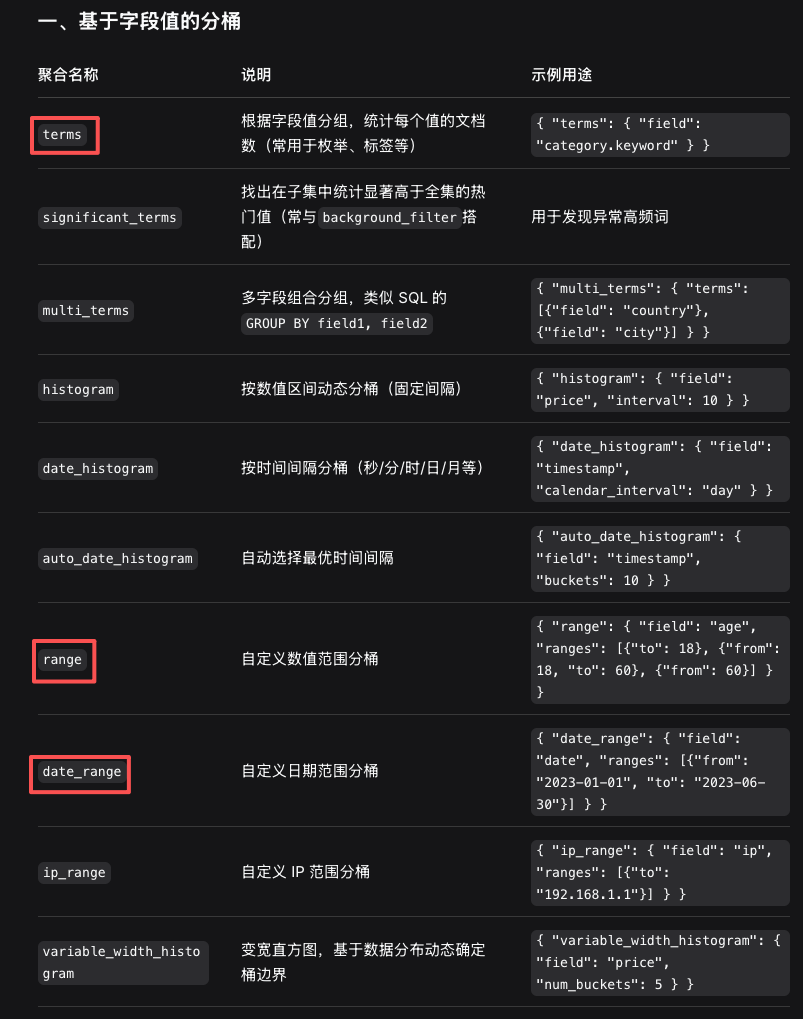
8.1.2 示例1:
bash
# 请求体开始
{
"size": 0, # 不返回原始文档,只返回聚合结果
"aggs": { # 聚合定义开始
"price_ranges": { # 自定义聚合名称,用于在响应中引用
"range": { # 使用 range 聚合,将文档按数值字段分段统计
"field": "price", # 指定要分段的字段名
"ranges": [ # 定义分段区间
{ "to": 10 }, # 第一个区间:价格 < 10
{ "from": 10, "to": 20 }, # 第二个区间:10 ≤ 价格 < 20
{ "from": 20 } # 第三个区间:价格 ≥ 20
]
}
}
}
}
# 请求结束
# 返回:
# 响应体开始
{
"took": 9, # 查询耗时(毫秒)
"timed_out": false, # 查询是否超时
"_shards": { # 分片统计信息
"total": 1, # 查询涉及的总分片数
"successful": 1, # 成功查询的分片数
"skipped": 0, # 跳过的分片数
"failed": 0 # 查询失败的分片数
},
"hits": { # 搜索结果部分
"total": { # 匹配的文档总数
"value": 2, # 文档总数(由于 size=0,不返回文档列表)
"relation": "eq" # 计数关系:eq 表示精确计数,gte 表示大于等于
},
"max_score": null, # 最大相关性评分(聚合查询时无意义)
"hits": [] # 文档列表(因为 size=0 所以为空)
},
"aggregations": { # 聚合结果部分
"price_ranges": { # 对应请求中自定义的聚合名称
# 区间桶数组,每个桶代表一个价格区间,这里和上面定义的桶一一对应
"buckets": [
{ # 第一个桶:价格 < 10
"key": "*-10.0", # 区间标识
"to": 10.0, # 区间上限(不含)
"doc_count": 0 # 落在该区间的文档数
},
{ # 第二个桶:10 ≤ 价格 < 20
"key": "10.0-20.0", # 区间标识
"from": 10.0, # 区间下限(含)
"to": 20.0, # 区间上限(不含)
"doc_count": 1 # 该区间文档数
},
{ # 第三个桶:价格 ≥ 20
"key": "20.0-*", # 区间标识
"from": 20.0, # 区间下限(含)
"doc_count": 1 # 该区间文档数
}
]
}
}
}
# 响应体结束8.1.3 示例2:(在kibana页面中查询)
bash
#按照年龄聚合,并且求这些年龄段的这些人的平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}结果显示的是年龄为31的人有61个,他们的平均薪资是28312
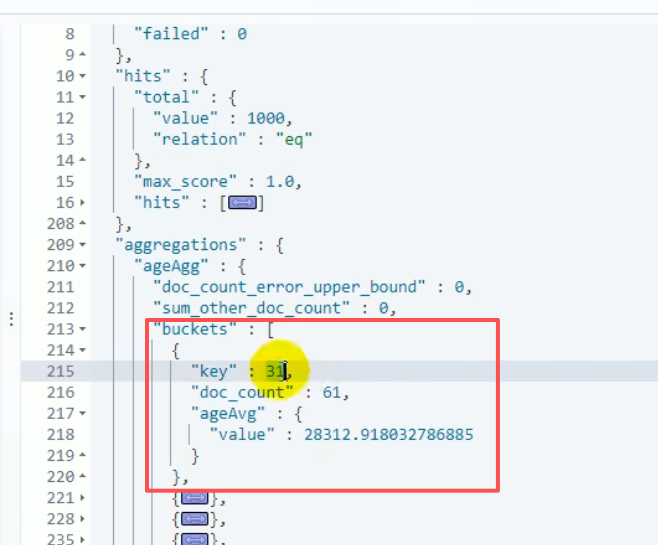
8.1.4 示例3:
bash
# 查出所有年龄分布,
# 并且这些年龄段中M的平均薪资和F的平均薪资
# 以及这个年龄段的总体平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBalanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}结果:
bash
{
"took" : 119,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 35,
"balanceAvg" : {
"value" : 29565.628571428573
}
},
{
"key" : "F",
"doc_count" : 26,
"balanceAvg" : {
"value" : 26626.576923076922
}
}
]
},
"ageBalanceAvg" : {
"value" : 28312.918032786885
}
}
]
.......//省略其他
}
}
}8.2 指标聚合
bash
#请求:
{
"size": 0,
"aggs": {
"avg_price": { "avg": { "field": "price" } },
"max_price": { "max": { "field": "price" } }
}
}
# 返回:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_price": {
"value": 20.994999885559082
},
"max_price": {
"value": 29.989999771118164
}
}
}8.3 嵌套聚合
聚合数据之后,再对聚合的数据进行聚合
bash
#请求:
{
"size": 0,
"aggs": {
"title_keyword": {
"terms": { "field": "title.keyword", "size": 10 },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
#返回:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"title_keyword": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Book 3",
"doc_count": 1,
"avg_price": {
"value": 12.0
}
},
{
"key": "Elasticsearch Guide",
"doc_count": 1,
"avg_price": {
"value": 29.989999771118164
}
}
]
}
}
}9. 集群与节点信息
9.1 集群健康状态
bash
GET /_cluster/health
GET /_cat/health?v9.2 节点信息
bash
GET /_cat/nodes?v
GET /_nodes/stats9.3 索引统计
bash
GET /my_index/_stats
GET /_cat/indices?v10. 安全相关(8以后必须)
10.1 重置 elastic 密码
bash
docker exec -it elasticsearch bin/elasticsearch-reset-password -u elastic -i10.2 查看当前用户
bash
GET /_security/_authenticate10.3 创建 API Key
bash
POST /_security/api_key
{
"name": "my-api-key",
"expiration": "1d",
"role_descriptors": {
"role1": {
"cluster": ["all"],
"indices": [
{ "names": ["my_index"], "privileges": ["all"] }
]
}
}
}返回的 encoded 字段就是 API Key,可在请求头 Authorization: ApiKey 中使用。
11. 映射
Mapping(映射)
Maping是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。比如:使用maping来定义:
-
哪些字符串属性应该被看做全文本属性(full text fields);
-
哪些属性包含数字,日期或地理位置;
-
文档中的所有属性是否都嫩被索引(all 配置);
-
日期的格式;
-
自定义映射规则来执行动态添加属性;
-
查看mapping信息:
GET bank/_mapping
bash
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
}
}
}我的理解:用于给文档的数据字段设置类型,方便es去进行处理
11.1 映射操作
11.1.1 创建一个新的索引并指定映射
bash
PUT /my_index
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
}
}
#输出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
}11.1.2 查看映射
bash
GET /my_index
输出结果:
{
"my_index" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"employee-id" : {
"type" : "keyword",
"index" : false
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1588410780774",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "ua0lXhtkQCOmn7Kh3iUu0w",
"version" : {
"created" : "7060299"
},
"provided_name" : "my_index"
}
}
}
}11.1.3 添加新的字段映射
bash
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
# 这里的 "index": false,表明新增的字段不能被检索,只是一个冗余字段。11.1.4 更新映射
对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移。
11.2 数据迁移
先创建new_twitter的正确映射。然后使用如下方式进行数据迁移。
bash
# [固定写法]
POST reindex
{
"source":{ # 老索引
"index":"twitter"
},
"dest":{ # 新索引
"index":"new_twitters"
}
}更多详情见: https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docs-reindex.html
12. 分词
一个tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。
例如:whitespace tokenizer遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为Quick,brown,fox!。
该tokenizer(分词器)还负责记录各个terms(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的原始word(单词)的start(起始)和end(结束)的character offsets(字符串偏移量)(用于高亮显示搜索的内容)。
elasticsearch提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)。
关于分词器: https://www.elastic.co/guide/en/elasticsearch/reference/7.6/analysis.html
bash
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
# 执行结果:
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<NUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "dog's",
"start_offset" : 45,
"end_offset" : 50,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "<ALPHANUM>",
"position" : 10
}
]
}12.1 安装中文分词器
下载地址:https://release.infinilabs.com/analysis-ik/stable/
注意,要下载跟自己安装的es对应的版本。
将下载好的zip文件放入到es的plugins文件夹下进行解压。然后重启服务
12.2 测试
12.2.1 ik_smart
bash
# 调用:
POST /_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
# 返回:
```bash
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}12.2.2 ik_max_word
bash
# 调用:
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
# 返回:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}12.3 自定义分词器
-
安装nginx,不多说
-
在html文件夹下创建"fenci.txt"文件,内容如下:

-
服务器查看内容:
-
修改/usr/share/elasticsearch/plugins/ik/config中的IKAnalyzer.cfg.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://127.0.0.1/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
~ - 原来的xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>-
修改完成后,需要重启elasticsearch容器,否则修改不生效。
-
更新完成后,es只会对于新增的数据用更新分词。历史数据是不会重新分词的。如果想要历史数据重新分词,需要执行:
shell
POST my_index/_update_by_query?conflicts=proceed- 测试:
bash
{
"analyzer": "ik_smart",
"text": "尚硅谷很不错"
}
# 结果:(如果没有自定义分词器的话,尚硅谷不会是个词)
{
"tokens": [
{
"token": "尚硅谷",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "很不错",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
}
]
}13. 整合springboot使用
在es8之前,普遍使用High Level REST Client。es8之后被弃用。
为什么呢?因为它是基于原生的 REST API,而这些 API 在某些情况下限制了某些功能的性能优化。与此同时,官方也推出了 Elasticsearch Java 客户端(Java 客户端)作为替代方案。这个新客户端旨在提供更好的性能、更好的稳定性,并且更易于维护和开发。
缺点如下:
- 性能损耗:由于是基于 REST API 的封装,可能存在性能上的一些损耗,比如相比原生的 Java 客户端可能有更高的延迟。
- 功能限制:High Level REST Client 对于一些高级或较新的功能可能提供支持不够或者存在一些限制。
es8之后,官方建议使用Elasticsearch Java API。
这里api接口不多说了,详情请看:java api接口
14. 商品内容如何存储
- 需求:
- 上架的商品才可以在网站展示。
- 上架的商品需要可以被检索。(上架的商品就加入到es去被检索)
- 分析sku在es中如何存储 商品mapping
- 分析: 商品上架在es中是存sku还是spu?
- 1)检索的时候输入名字,是需要按照sku的title进行全文检索
- 2)检素使用商品规格,规格是spu的公共属性,每个spu是一样的
- 3)按照分类id进去的都是直接列出spu的,还可以切换。
- 4〕我们如果将sku的全量信息保存到es中(包括spu属性〕就太多字段了
14.1 方案1:时间优先
存储字段包括:
- skuId:1
- spuId:11
- skuTitle:华为xx
- price:999
- saleCount:99
- attrs:{尺寸:5村},{cpu:高通},{分辨率:1080p}
问题:100万的数据大概是100万 x 20kb = 2G
14.2 方案2:空间优先
- sku索引:
- skuId:1
- spuId:11
- attr索引:
- spuId:11
- attrs:{尺寸:5村},{cpu:高通},{分辨率:1080p}
问题:在查询一个商品时,在商品的上方会给你展示相关内容检索是动态计算的:
比如查询小米,带有小米的商品可能有粮食、手机、电池。
- 从中查询出10000个带有小米的商品,10000个商品有4000个spu
- 根据4000个spu,查询出对应的所有可能的属性。就需要查询4000次spuId,每个请求就算8字节,就是32kb,如果有1万个人同时查询就是320mb。网络带宽负载压力太大
14.3 最终方案:
其中
- "type": "keyword" 保持数据精度问题,可以检索,但不分词
- "index":false 代表不可被检索
- "doc_values": false 不可被聚合,es就不会维护一些聚合的信息
- 冗余存储的字段: 不用来检索,也不用来分析,节省空间
- 库存是bool。
- 检索品牌id,但是不检索品牌名字、图片 用skuTitle检索
- nested嵌入式对象
bash
PUT product
{
"mappings": {
"properties": {
"skuId": {
"type": "long"
},
"spuId": {
"type": "long"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": {
"type": "keyword"
},
"skuImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"saleCount": {
"type": "long"
},
"hosStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"brandId": {
"type": "long"
},
"catelogId": {
"type": "long"
},
"brandName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"brandImg": {
"type": "keyword",
"index": false,
"doc_values": false
},
"catelogName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword",
"index": false,
"doc_values": false
},
"attrValue": {
"type": "keyword"
}
}
}
}
}
}15. nested嵌入式对象
数组保存存在的问题:扁平化处理
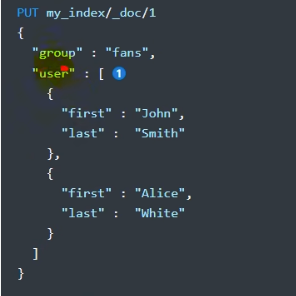
-
存储数据:
-
最后存储的结构:把所有first的值,放到一个数组中存起来,吧所有last的值存储到一个数组中。

-
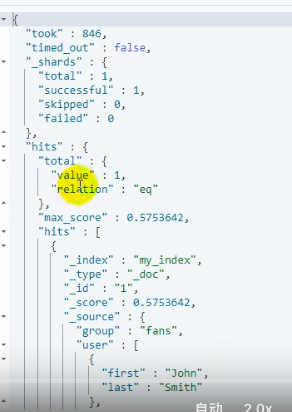
示例查询,first:alice和last:Smith:

-
结果:
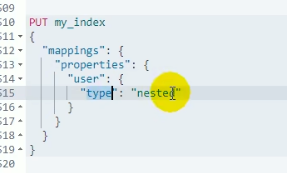
15.1 解决方案:
- 先设置映射,指定user的类型是嵌入式的
- 重新设置数据后,可以看到查不到数据了