小肥柴的Hadoop之旅 快速实验篇(A1)干旱气象数据上传至HDFS
-
- 目录
- [0. 概要](#0. 概要)
- [1. 前置准备](#1. 前置准备)
-
- [1.1 数据集来源](#1.1 数据集来源)
- [1.2 环境准备](#1.2 环境准备)
- [1.3 必要的前置知识回顾](#1.3 必要的前置知识回顾)
-
- [1.3.1 数据结构分类回顾](#1.3.1 数据结构分类回顾)
- [1.3.2 侦查数据结构特征](#1.3.2 侦查数据结构特征)
- [1.3.3 数据格式转换](#1.3.3 数据格式转换)
- [1.3.4 理解格式转换的ETL本质(阶段性复盘)](#1.3.4 理解格式转换的ETL本质(阶段性复盘))
- [2. 实验过程](#2. 实验过程)
-
- [2.1 HDFS目录创建与文件上传](#2.1 HDFS目录创建与文件上传)
- [2.2 观察Block分块与分布](#2.2 观察Block分块与分布)
-
- [2.2.1 在master上执行 fsck 命令](#2.2.1 在master上执行 fsck 命令)
- [2.2.2 在WebUI中查看HDFS](#2.2.2 在WebUI中查看HDFS)
- [2.2.3 详细解读 fsck 命令输出结果](#2.2.3 详细解读 fsck 命令输出结果)
- [2.3 深入DataNode查看物理Block文件](#2.3 深入DataNode查看物理Block文件)
- [3 拓展探索](#3 拓展探索)
- [4 常见问题(不断更新)](#4 常见问题(不断更新))
目录
0. 概要
(1)本实验是Hadoop完全分布式集群的入门操作,目标是理解HDFS的存储原理。
(2)业务背景是将US Drought & Meteorological Data测试集(2012-2020年)的原始JSON数据转换为结构化CSV,上传至HDFS,并观察分布式存储的物理实现。
(3)前置条件是集群已启动(实验0),登录master节点执行相关操作。
(4)【实验目标】
a. 掌握hdfs dfs基本命令(-mkdir、-put、-ls、-cat、-du)
b. 理解HDFS Block分块机制(默认128 MB/Block)
c. 通过fsck和WebUI观察Block分布与副本放置
d. 深入DataNode本地文件系统,验证物理Block文件存在
e. 建立"逻辑文件 => Block => 物理文件"的完整映射认知
1. 前置准备
1.1 数据集来源
- 阿里天池中的美国干旱气象数据
下载其中的:test_set.json。数据大小为1.07GB,模拟入门操作可用。
1.2 环境准备
【问题瓶颈】
物理机只有16GB内存,每台虚拟机仅2GB。Hadoop DataNode默认堆内存1000MB,NodeManager也是1000MB,加上操作系统开销,上传大文件时DataNode必然OOM,虚拟机直接卡死。必须先把堆内存降下来。
【具体操作】
在所有节点(除master)的$HADOOP_HOME/etc/hadoop/hadoop-env.sh中添加:
bash
export HADOOP_DATANODE_HEAPSIZE=512
export YARN_NODEMANAGER_HEAPSIZE=512同步配置并重启:
bash
for node in standby worker1 worker2 worker3; do
scp $HADOOP_HOME/etc/hadoop/hadoop-env.sh hadoop@$node:$HADOOP_HOME/etc/hadoop/
done
stop-yarn.sh && stop-dfs.sh
start-dfs.sh && start-yarn.sh各节点jps确认DataNode和NodeManager进程正常。
1.3 必要的前置知识回顾
1.3.1 数据结构分类回顾
《数据科学与大数据技术导论》和《数据采集与预处理》都曾提及过数据作业中,可将原始数据划分为三种类型:
| 数据类型 | 特征 | 典型格式 |
|---|---|---|
| 结构化数据 | 固定模式(Schema),行×列的表格形态 | MySQL表、CSV |
| 半结构化数据 | 有标签和结构,但模式灵活可变 | JSON、XML |
| 非结构化数据 | 无固定格式,难以直接查询 | 图片、视频、日志文本 |
(1)JSON之所以是半结构化,因为它有key:value的标签结构,但每个站点的字段可以不同,数组长度可以变化。
(2)这带来灵活性,但牺牲了查询效率。
(3)接下来要做的就是把半结构化的JSON变成结构化的CSV------这是典型的ETL操作。在大数据工程中,70%以上的工作量都在做这种"格式归一化"。
1.3.2 侦查数据结构特征
【问题场景】数据工程师收到一份1GB的JSON文件(test_set.json)。但他并不知道:每行一个独立JSON对象,或是一个巨大的嵌套对象,不知道里面有哪些字段,不知道数组长度。因此在动手转换之前,先用命令行工具探查。在test_set.json所在目录下执行如下脚本:
bash
# 侦察1:查看文件前2000个字符,初步判断结构类型
head -c 2000 test_set.json
# 侦察2:用 jq 探测根节点结构
head -n 1 test_set.json | jq 'keys'
# → ["root"] → 确认是嵌套大JSON,根键为"root"
# 侦察3:查看 root 下的前5个键(站点ID)
jq '.root | keys | .[0:5]' test_set.json
# → 长数字字符串 → root下是站点ID字典
# 侦察4:查看第一个站点内部的键
jq '.root | .[keys[0]] | keys' test_set.json
# → ["class", "meta", "values"]
# 侦察5:查看meta内容
jq '.root | .[keys[0]] | .meta' test_set.json
# → {"date": "2019-08-20", "fips": 47169}
# 侦察6:查看values的键(气象指标)
jq '.root | .[keys[0]] | .values | keys' test_set.json
# → 18个气象指标字段名
# 侦察7:确认观测天数
jq '.root | .[keys[0]] | .values.PRECTOT | length' test_set.json
# → 90 → 每个指标有90天观测数据【注】jq工具需要提前安装在Linux上,安装过程自助。
如下是侦查结论:
| 侦查项 | 结论 |
|---|---|
| 文件结构类型 | 半结构化 → 单个嵌套大JSON,根节点为root |
| 数据粒度 | root下以站点ID为键,包含数千个站点 |
| 每个站点结构 | class(干旱等级)+ meta(日期/FIPS)+ values(18个气象指标×90天) |
| 转换目标 | 结构化CSV:每个时间点一行,展开后约百万行 |
1.3.3 数据格式转换
借助jq工具完成了对数据结构的侦查,确认了数据集中有:18个气象指标字段名、90天观测周期、嵌套层级关系。接下来需要用Python将这些嵌套数组展开成CSV,可是作为新手问题来了:
鉴于文件是单个大JSON,全量载入内存有风险(1GB JSON加载后可能占用3-5GB内存),推荐采用流式+逐行转换的策略:先用 jq 将大JSON拆分为每行一个站点的 JSON Lines,再用流式 Python 脚本展开,从而避免全量加载所产生的内存压力。
bash
jq -c '.root | to_entries[]' test_set.json > test_set_lines.json【相关解释】
(1).root | to_entries[] 将 root 下的每个站点转换为
{"key":"站点ID","value":{ "class":..., "meta":..., "values":... }} 格式。
(2)-c 确保每个站点占一行。
(3)输出的 test_set_lines.json 每行是一个独立JSON,可被流式脚本逐行读取。对应的,可以古法手工编写脚本处理上述业务,也能依靠AI直接生成流式转换脚本(参考下方):
python
#!/usr/bin/env python3
"""
基于 jq 拆分的 JSON Lines 流式转换工具
输入:test_set_lines.json(每行一个站点)
输出:test_set.csv(每个站点展开为90行)
"""
import json
import csv
import sys
import logging
from datetime import datetime
logging.basicConfig(level=logging.INFO, format='%(asctime)s [%(levelname)s] %(message)s')
logger = logging.getLogger('stream_converter')
# 列定义(与MR程序匹配,注意添加干旱等级字段)
COLUMNS = [
"station_id",
"date",
"fips",
"class",
"WS10M_MIN", "QV2M", "T2M_RANGE", "WS10M", "T2M",
"WS50M_MIN", "T2M_MAX", "WS50M", "TS", "WS50M_RANGE",
"WS50M_MAX", "WS10M_MAX", "WS10M_RANGE", "PS",
"T2MDEW", "T2M_MIN", "T2MWET", "PRECTOT"
]
# 观测值字段映射(JSON字段名 -> 列索引)
OBSERVATION_FIELDS = {
"WS10M_MIN": 4, "QV2M": 5, "T2M_RANGE": 6, "WS10M": 7,
"T2M": 8, "WS50M_MIN": 9, "T2M_MAX": 10, "WS50M": 11,
"TS": 12, "WS50M_RANGE": 13, "WS50M_MAX": 14, "WS10M_MAX": 15,
"WS10M_RANGE": 16, "PS": 17, "T2MDEW": 18, "T2M_MIN": 19,
"T2MWET": 20, "PRECTOT": 21
}
def convert_stream(input_file, output_file):
processed_stations = 0
processed_records = 0
skipped_stations = 0
with open(input_file, 'r', encoding='utf-8') as f_in, \
open(output_file, 'w', newline='', encoding='utf-8') as f_out:
writer = csv.writer(f_out)
writer.writerow(COLUMNS)
for line_num, line in enumerate(f_in, 1):
line = line.strip()
if not line:
continue
try:
# 解析单行JSON
station_obj = json.loads(line)
station_id = station_obj['key']
data = station_obj['value']
meta = data.get('meta', {})
date_str = meta.get('date', '')
fips = meta.get('fips', '')
drought_class = data.get('class', '')
values = data.get('values', {})
if not values:
skipped_stations += 1
continue
# 确定观测次数(取第一个字段的数组长度)
first_key = next(iter(values))
num_observations = len(values[first_key])
# 展开每个观测点
for obs_index in range(num_observations):
row = [""] * len(COLUMNS)
row[0] = station_id
row[1] = date_str
row[2] = fips
row[3] = drought_class
# 填充气象值
for field, col_idx in OBSERVATION_FIELDS.items():
field_data = values.get(field, [])
if obs_index < len(field_data):
val = field_data[obs_index]
# 处理空值
if val in [None, "", "NaN", "NA", "N/A"]:
row[col_idx] = "0.0"
else:
try:
row[col_idx] = str(float(val))
except (TypeError, ValueError):
row[col_idx] = "0.0"
else:
row[col_idx] = "0.0"
writer.writerow(row)
processed_records += 1
processed_stations += 1
if processed_stations % 100 == 0:
logger.info(f"已处理 {processed_stations} 个站点,{processed_records} 条记录...")
except json.JSONDecodeError as e:
logger.error(f"第 {line_num} 行JSON解析失败: {e}")
continue
except Exception as e:
logger.error(f"第 {line_num} 行处理异常: {e}")
continue
logger.info(f"转换完成! 站点: {processed_stations}, 记录: {processed_records}")
logger.info(f"跳过站点: {skipped_stations}")
return processed_records
if __name__ == "__main__":
# 直接指定文件名,无需命令行参数
input_path = "test_set_lines.json"
output_path = "test_set.csv"
logger.info(f"开始流式转换: {input_path} -> {output_path}")
start_time = datetime.now()
logger.info(f"开始流式转换: {input_path} -> {output_path}")
start_time = datetime.now()
try:
count = convert_stream(input_path, output_path)
elapsed = (datetime.now() - start_time).total_seconds()
logger.info(f"成功生成 {count} 条记录,耗时 {elapsed:.2f} 秒")
except Exception as e:
logger.exception("转换失败")
sys.exit(1)【注】依靠AI辅助实现脚本的思路如下:
(1)人工作是侦查数据结构、定义约束条件(字段名、嵌套层级、输出格式)。
(2)AI根据**明确的数据约束和规则定义**的要求下生成初版Python脚本代码,并不断迭代优化。
(3)再次验证输出结果、调试修正。
(4)关键原则:人定义问题,AI生成初稿,人验证结果。
(5)题词参考:输入是一个JSON Lines文件,每行包含一个站点的嵌套数据(meta + values数组),
需要展开为每观测点一行的CSV,18个气象字段名已确认,缺失值替换为0.0,要求流式处理避免内存溢出。AI根据这些约束生成了初版脚本,我们验证了字段映射、处理了空值逻辑、添加了进度日志,最终得到现在的版本。
1.3.4 理解格式转换的ETL本质(阶段性复盘)
先看3个自问自答的追问:
【Q1】为什么NASA/POWER要提供嵌套JSON,而不是直接给CSV?
【A1】因为JSON灵活,适合API传输,是生产者友好的格式。气象数据可能不定期新增指标,JSON可以随时加字段而不破坏下游。
【Q2】为什么Hadoop/Hive不能直接用JSON,而要转成CSV?
【A2】因为Hive分析查询时只需要某几列(比如温度和降水),JSON必须整行解析,浪费大量IO。CSV是消费者友好的格式------虽然不够紧凑,但所有分析工具都支持。
这种"生产者格式→消费者格式"的转换,就是ETL中Transform环节的核心。为了弥合生产与消费之间的鸿沟,大量转换工具被开发出来:
(1)jq是命令行JSON处理器的标杆。
(2)csvkit是CSV处理的瑞士军刀。
(3)Pandas是Python数据处理的标配。
(4)Spark/Flink则是分布式场景下的重型转换引擎。大数据生态中,这种转换操作本身就是数据工作的核心价值------数据不会自己变成适合分析的形态,需要人来设计和执行管道。
2. 实验过程
2.1 HDFS目录创建与文件上传
【核心操作】在master上执行:
bash
# 创建干旱数据原始层目录
hdfs dfs -mkdir -p /drought/raw
# 上传CSV文件
hdfs dfs -put test_set.csv /drought/raw/
# 查看上传结果
hdfs dfs -ls -h /drought/raw/预期输出:
bash
-rw-r--r-- 3 hadoop supergroup 950 M ... /drought/raw/test_set.csv其中:第一列的3表示副本数,需与hdfs-site.xml中dfs.replication一致。此外若上传中断(文件显示_COPYING_),确认所有DataNode在线后重新上传:
hdfs dfs -rm /drought/raw/test_set.csv.COPYING
2.2 观察Block分块与分布
2.2.1 在master上执行 fsck 命令
bash
hdfs fsck /drought/raw/test_set.csv -files -blocks -locations【解读示例】
- 文件总Block数(约8个,950 MB /128 MB≈7.4,向上取整)
- 每个Block的ID(如
blk_1073741825) - 每个Block的副本分布(如
[worker1, worker2, worker3]) - Block Pool ID(如
BP-xxxxxxxx-192.168.10.101-xxxxxxxxxxxx)
【实际输出情况】(仅供参考):
bash
hadoop@master:~$ hdfs fsck /drought/raw/test_set.csv -files -blocks -locations
Connecting to namenode via http://master:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdrought%2Fraw%2Ftest_set.csv
FSCK started by hadoop (auth:SIMPLE) from /192.168.10.101 for path /drought/raw/test_set.csv at Wed May 13 23:20:10 CST 2026
/drought/raw/test_set.csv 1272649677 bytes, replicated: replication=3, 10 block(s): OK
0. BP-2019739581-192.168.10.101-1778513217449:blk_1073741828_1005 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK]]
1. BP-2019739581-192.168.10.101-1778513217449:blk_1073741829_1006 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK]]
2. BP-2019739581-192.168.10.101-1778513217449:blk_1073741830_1007 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK]]
3. BP-2019739581-192.168.10.101-1778513217449:blk_1073741831_1008 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK]]
4. BP-2019739581-192.168.10.101-1778513217449:blk_1073741832_1009 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK]]
5. BP-2019739581-192.168.10.101-1778513217449:blk_1073741833_1010 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK]]
6. BP-2019739581-192.168.10.101-1778513217449:blk_1073741834_1011 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK]]
7. BP-2019739581-192.168.10.101-1778513217449:blk_1073741835_1012 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK]]
8. BP-2019739581-192.168.10.101-1778513217449:blk_1073741836_1013 len=134217728 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK]]
9. BP-2019739581-192.168.10.101-1778513217449:blk_1073741837_1014 len=64690125 Live_repl=3 [DatanodeInfoWithStorage[192.168.10.104:9866,DS-888a7bd3-1167-4007-a420-56889bd559e3,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2d02a3e4-a914-464b-958b-8b2b48512316,DISK], DatanodeInfoWithStorage[192.168.10.105:9866,DS-fbf4e250-54e6-489e-b78c-6fe45bc36403,DISK]]
Status: HEALTHY
Number of data-nodes: 3
Number of racks: 1
Total dirs: 0
Total symlinks: 0
Replicated Blocks:
Total size: 1272649677 B
Total files: 1
Total blocks (validated): 10 (avg. block size 127264967 B)
Minimally replicated blocks: 10 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Blocks queued for replication: 0
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
Blocks queued for replication: 0
FSCK ended at Wed May 13 23:20:10 CST 2026 in 5 milliseconds
The filesystem under path '/drought/raw/test_set.csv' is HEALTHY2.2.2 在WebUI中查看HDFS
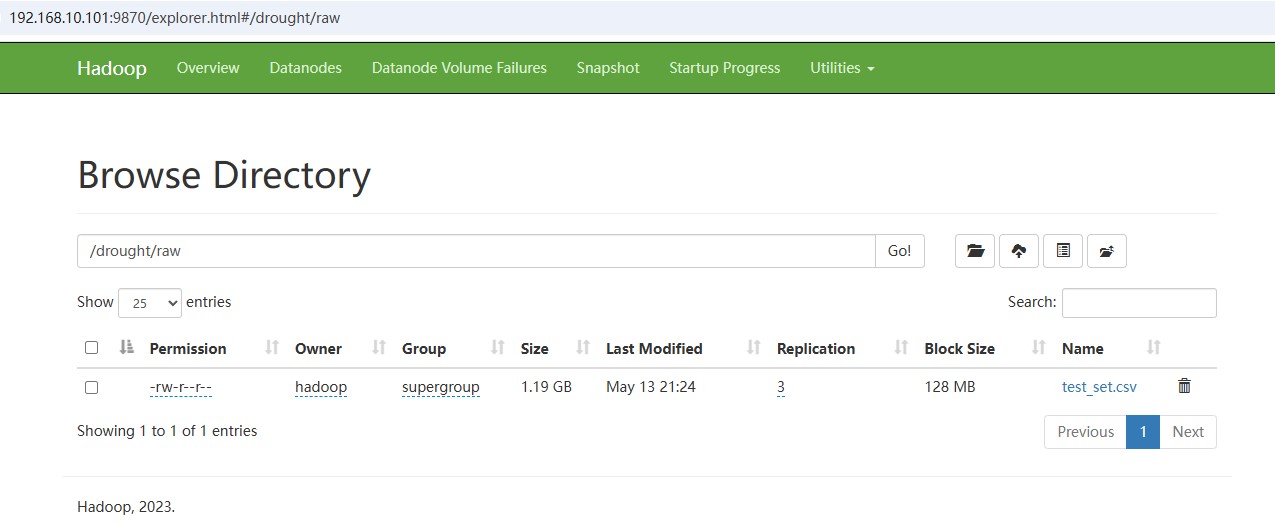
浏览器访问http://192.168.10.101:9870
- Utilities→Browse the file system →导航到
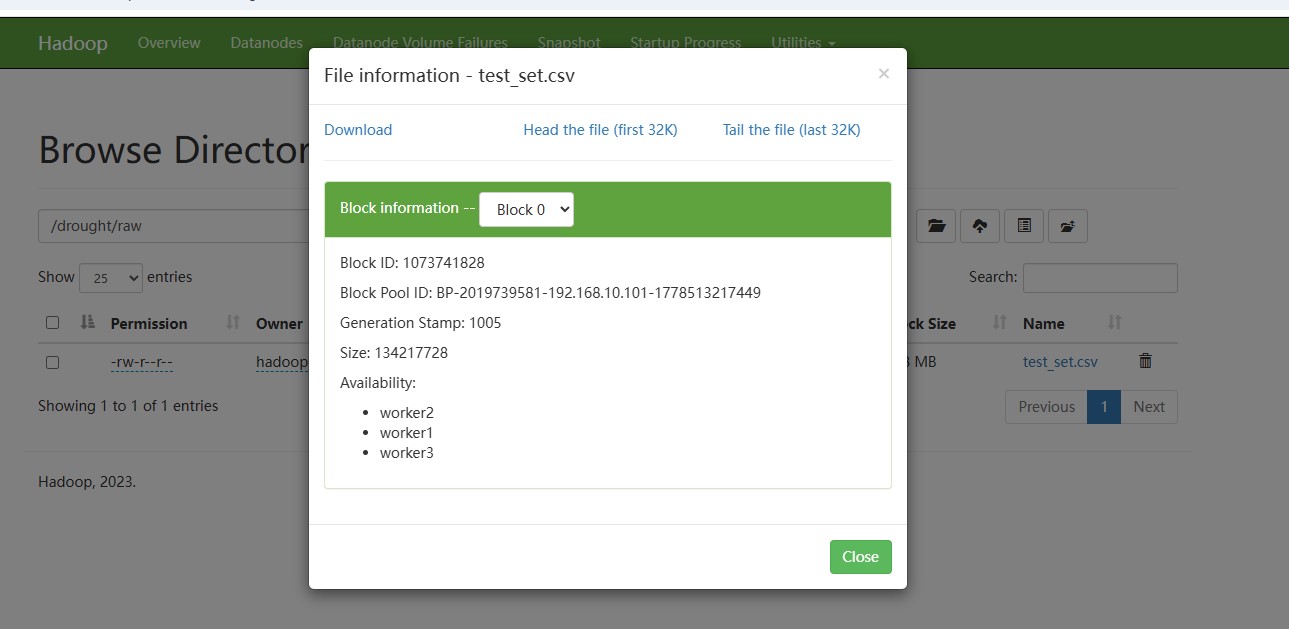
/drought/raw/test_set.csv。 - 点击文件名,查看Block列表和副本数。
- 点击任意Block ID,查看该Block分布在哪些DataNode上。
下面是实操参考吐,可以看到block信息与命令行查询结果一致。
2.2.3 详细解读 fsck 命令输出结果
(1)文件基本信息
bash
/drought/raw/test_set.csv 1272649677 bytes, replicated: replication=3, 10 block(s): OK| 指标 | 数值 | 解读 |
|---|---|---|
| 文件大小 | 1,272,649,677 字节 ≈ 1.19 GB | 实际 CSV 文件大小,比之前预估的 950 MB 大 |
| 副本因子 | 3 | 每个 Block 存 3 份,与 hdfs-site.xml 配置一致 |
| Block 总数 | 10 | 文件被切分成 10 个 Block |
要点
Block 数(向上取整) = 文件大小 ÷ Block 大小 。带入数据计算(块大小参数默认 128 MB):
1272649677 ÷ 134217728 ≈ 9.48 → 向上取整为 10 个 Block。
前 9 个 block 大小都是 128 MB,最后一个约 61.7 MB(对应 Block 9 的 len=64690125)。(2)每个 Block 的详细信息
bash
0. BP-2019739581-192.168.10.101-1778513217449:blk_1073741828_1005 len=134217728 Live_repl=3 [worker1, worker2, worker3]| 字段 | 示例值 | 含义 |
|---|---|---|
| Block Pool ID | BP-2019739581-192.168.10.101-1778513217449 |
集群的块池标识,192.168.10.101 是 NameNode IP,后面是时间戳 |
| Block ID | blk_1073741828_1005 |
块唯一编号,_1005 是生成戳 |
| Block 大小 | len=134217728(128 MB) |
当前块实际大小 |
| 副本状态 | Live_repl=3 |
3 个副本均存活 |
| 物理位置 | 3 个 DataNode 的 IP:9866 | 三个副本分布在 worker1~3 |
要点
(1)每个 Block 的副本节点顺序不同:例如 Block 0 的第一副本在 103,Block 2 的第一副本在 105。
这不是随机排列,而是 HDFS 的副本放置策略:第一个副本在同机架,第二个在另一机架,第三个在
同一机架的另一个节点。
(2)最后一个 Block 9 大小仅 64 MB:HDFS 不会为最后一个 Block 浪费磁盘空间,按实际数据量存储。(3)副本分布与负载均衡
每个 Block 的副本都在 192.168.10.103、104、105 上各存一份,即 worker1、worker2、worker3。
负载均衡概要:
- 10 个 Block,每个 Block 3 副本 = 30 个副本实例。
- 分布在 3 个节点上,平均每个节点存储 10 个副本。
- 实际中 Block 的第一副本位置会轮转,保证每个 DataNode 存储的数据量大致均衡。
(4)集群健康状态总览
bash
Status: HEALTHY
Total size: 1272649677 B (1.19 GB)
Total files: 1
Total blocks (validated): 10
Average block replication: 3.0
Missing blocks: 0
Corrupt blocks: 0| 指标 | 数值 | 含义 |
|---|---|---|
| Status | HEALTHY | 集群健康,无异常 |
| Total blocks | 10 | 共 10 个 Block |
| Minimally replicated blocks | 10 (100%) | 所有 Block 满足最小副本数 |
| Over-replicated blocks | 0 | 无多余副本 |
| Under-replicated blocks | 0 | 无副本不足的 Block |
| Mis-replicated blocks | 0 | 无副本放置错误的 Block |
| Missing blocks | 0 | 无丢失的 Block |
| Corrupt blocks | 0 | 无损坏的 Block |
要点
(1)100% 的 Block 满足最小副本数:说明 HDFS 在 3 个 DataNode 都存活的情况下,自动维护了数据的可靠性。
(2)0 个 Missing/Corrupt blocks:文件完整无损。
(3)状态为 HEALTHY:这是集群正常运行的基线,后续若某个 DataNode 宕机,
fsck 会显示 Under-replicated blocks。2.3 深入DataNode查看物理Block文件
2.2的相关操作,只是展示了数据集被切分成block之后的信息统计情况,但好奇的你此时在脑海中肯定会浮现一个新问题:原始数据集真的被切分成块状物理文件了吗?若是真的,如何求证呢?换句话说:我们已经知晓NameNode用于记录元数据信息(meta),那对应的block文件以什么样的形式存放在DataNode中呢?
回忆2.2的相关信息:
文件总Block数(约8个,950 MB /128 MB≈7.4,向上取整)
每个Block的ID(如`blk_1073741825`)
每个Block的副本分布(如`[worker1, worker2, worker3]`)
Block Pool ID(如`BP-xxxxxxxx-192.168.10.101-xxxxxxxxxxxx`)自然想到取3个worker里查看,例如切换至worker1:
bash
ssh worker1
cd /usr/local/hadoop/data/datanode/current/
ls -l | grep BP-
cd BP-xxxxxxxx-192.168.10.101-xxxxxxxxxxxx/current/finalized/
find . -name "blk_1073741825*"输出示例:可以看到block文件和对应的meta
bash
./subdir12/blk_1073741825
./subdir12/blk_1073741825_1001.meta此时还能查看Block文件的信息
bash
cd subdir12
ls -lh blk_1073741825*整理输出信息,解读示例如下:
| 文件 | 大小 | 含义 |
|---|---|---|
blk_1073741825 |
128 MB | 纯数据块,大小等于dfs.blocksize |
blk_1073741825_1001.meta |
约56字节 | 存储该Block的校验和及元数据 |
还能验证:
(1)验证副本的存在:分别在worker2和worker3上重复上述操作,确认同一个Block在3个DataNode上各存一份物理文件。
(2)验证最后一个Block的实际大小:在master上确认最后一个Block ID,到对应worker节点查看其物理大小。最后一个Block小于128 MB(如仅54 MB),证明HDFS不会为最后一个Block空占磁盘空间。
所以真的是实践出真知,光靠背诵教程和经典数据并不能解决认知逻辑断层;以下是实际探索过程(假设你不知道block的命名规则与存储规则)
bash
hadoop@worker1:~$ ll /usr/local/hadoop/data/
datanode/ namenode/ tmp/
hadoop@worker1:~$ ll /usr/local/hadoop/data/datanode/
current/ in_use.lock
hadoop@worker1:~$ ll /usr/local/hadoop/data/datanode/current/
BP-2019739581-192.168.10.101-1778513217449/ VERSION
hadoop@worker1:~$ ll /usr/local/hadoop/data/datanode/current/BP-2019739581-192.168.10.101-1778513217449/
current/ scanner.cursor tmp/
hadoop@worker1:~$ ll /usr/local/hadoop/data/datanode/current/BP-2019739581-192.168.10.101-1778513217449/current/
dfsUsed finalized/ rbw/ VERSION
hadoop@worker1:~$ ll /usr/local/hadoop/data/datanode/current/BP-2019739581-192.168.10.101-1778513217449/current/finalized/subdir0/subdir0/
total 1252592
drwxrwxr-x 2 hadoop hadoop 4096 May 13 21:24 ./
drwxrwxr-x 3 hadoop hadoop 4096 May 13 20:46 ../
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741828
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741828_1005.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741829
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741829_1006.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741830
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741830_1007.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741831
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741831_1008.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741832
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741832_1009.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741833
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741833_1010.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:23 blk_1073741834
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:23 blk_1073741834_1011.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:24 blk_1073741835
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:24 blk_1073741835_1012.meta
-rw-rw-r-- 1 hadoop hadoop 134217728 May 13 21:24 blk_1073741836
-rw-rw-r-- 1 hadoop hadoop 1048583 May 13 21:24 blk_1073741836_1013.meta
-rw-rw-r-- 1 hadoop hadoop 64690125 May 13 21:24 blk_1073741837
-rw-rw-r-- 1 hadoop hadoop 505399 May 13 21:24 blk_1073741837_1014.meta3 拓展探索
若之前了解过备份机制,就会自然追问两个问题:
【Q1】既然已经看到了DataNode中block文件的真实物理形态,那对应管理元数据的NameNode又如何呢?
【Q2】同理,为master做定期备份的standby呢?
不绕圈子,仿照之前的操作思路,直接展示master上的查询结果:
bash
hadoop@master:~$ ls -l /usr/local/hadoop/data/namenode/current/
total 5152
-rw-rw-r-- 1 hadoop hadoop 1048576 May 11 23:35 edits_0000000000000000001-0000000000000000001
-rw-rw-r-- 1 hadoop hadoop 1048576 May 11 23:46 edits_0000000000000000002-0000000000000000011
-rw-rw-r-- 1 hadoop hadoop 1048576 May 12 23:10 edits_0000000000000000012-0000000000000000012
-rw-rw-r-- 1 hadoop hadoop 1048576 May 13 20:48 edits_0000000000000000013-0000000000000000028
-rw-rw-r-- 1 hadoop hadoop 2175 May 13 22:06 edits_0000000000000000029-0000000000000000064
-rw-rw-r-- 1 hadoop hadoop 102 May 13 23:06 edits_0000000000000000065-0000000000000000067
-rw-rw-r-- 1 hadoop hadoop 1048576 May 13 23:06 edits_inprogress_0000000000000000068
-rw-rw-r-- 1 hadoop hadoop 1173 May 13 22:06 fsimage_0000000000000000064
-rw-rw-r-- 1 hadoop hadoop 62 May 13 22:06 fsimage_0000000000000000064.md5
-rw-rw-r-- 1 hadoop hadoop 1173 May 13 23:06 fsimage_0000000000000000067
-rw-rw-r-- 1 hadoop hadoop 62 May 13 23:06 fsimage_0000000000000000067.md5
-rw-rw-r-- 1 hadoop hadoop 3 May 13 23:06 seen_txid
-rw-rw-r-- 1 hadoop hadoop 217 May 13 20:44 VERSION同理standby亦如此,请自行核验edits和fsimage等理论知识。
4 常见问题(不断更新)
| 问题 | 原因 | 解决 |
|---|---|---|
hdfs dfs -put时卡住 |
DataNode内存不足 | 确认已降低堆内存至512 MB |
find找不到Block |
Block Pool ID或subdir路径不对 | find /usr/local/hadoop/data/datanode -name "blk_*"全盘搜索 |
| WebUI无法访问 | 防火墙或NAT映射问题 | 确认http://192.168.10.101:9870,宿主机需在同一网段 |
put后文件停留在_COPYING_ |
上传中断(某DataNode宕机) | hdfs dfs -rm删除该文件,确认所有DN在线后重新上传 |