有监督学习:
核心目标: 建立一个模型(函数),来描述输入(X)和输出(Y)之间的映射关系
价值: 对于新的输入,通过模型给出预测的输出
这里的输入和输出,不只是数字,它可能还有别的含义,比如花的颜色代表1之类的
有监督学习要点:
1.需要有一定数量的训练样本
- 输入和输出之间有关联关系 (何为无关联关系,给你早上吃的饭,然后预测明天有没有雨)
3.输入和输出可以数值化表示
- 任务需要有预测价值
无监督学习:
给予机器的数据没有标注信息,通过算法对数据进行一定的自动分析处理,得到一些结论
常见任务:
聚类,降维,找特征值
一般流程:
机器学习-从数据到模型:
训练数据 -> 数据处理->算法选择->建模评估->算法调优->模型
常用概念:
训练集:
用于模型训练的训练数据集合
验证集:
对于每种任务一般都有多种算法可以选择,一般会使用验证集验证用于对比不同算法的效果差异
测试集:
最终用于评判算法模型效果的数据集合
k折交叉验证:
初始采样分割成k个字样本,一个单独的子样本被保留作为验证模型的数据,其他k-1个样本用来训练。交叉验证重复k次,每个子样本验证一次,平均k次的结果
一个恰当的比喻:
训练集就相当于我们平常做题,验证集就相当于月考之类的,而测试集就是期末
拟合(假如我们有个公式,我们给它变量,它给我们返回一个值,与真实值的差我们称之为拟合)
1.过拟合:
- 在训练集上表现极好
- 一到验证集 / 测试集(新数据)就拉胯
2.欠拟合 :
模型太简单,连训练数据的基本规律都没学会
深度学习:
猜数字: 我在心里想了一个0-100之间的整数,你猜一下?
B:60
A: 低了
B: 80
A:低了
B 90
A:高了
B: 88
A:对了
首先B随便猜一个数 --模型随机初始化
A计算B的猜测与真正答案的差距 这个用到了损失函数 --计算loss
A告诉B偏大或偏小 --得到loss值
B调整了自己的模型参数 反向传播
参数调整幅度依旧B自定的策略 优化器&学习率
重复以上过程
最终B的猜测与A的答案一致 -- loss = 0
那么这种B不断地猜效率有点低,怎么提高效率
1.随机初始化 假如B一开始选择地k就是对的,就直接结束了
2.优化损失函数 当B猜错地时候 ,A不说低了,而是告知具体低了多少
B的调整方法,也就是优化器,可以二分调整
调整模型结构
深度学习中间层(隐含层)
神经网络模型输入层和输出层之间的部分
隐含层可以有不同的结构:
RNN
CNN
DNN
LSTM
Transformer
等等
随机初始化
隐含层中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算
初始值的选取会影响最终的结果
一般情况下,模型会采取随机初始化,但参数会在一定范围内
在使用预训练模型一类的策略时,随机初始值被训练好的参数代替
损失函数
损失函数用来计算模型的预测值与真实值之间的误差
模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值
损失函数有很多,选择合理的损失函数是模型训练的必要条件
导数与梯度
为什么要知道这些
因为我们要让预测值和真实值更接近或者等于,也就是让损失函数无限接近或者等于0,而导数和梯度告诉我们函数变化的方向
举个最近的例子
loss(损失函数)=kx 那么我们通过求导可以知道,x往哪变化可以让loss接近0
导数表示函数曲线上的切线斜率
优化器(具体是多少,会有数学公式)
知道走的方向,还需要知道走多远
假如一步走太大,就可能错过最小值,如果一步走太小,有可能困在某个局部低点无法离开
学习率,动量都是优化器相关概念
梯度的反方向告诉我们下降最快的方向,而优化器则是告诉我们往这个方向走的程度
MiniBatch ## epoch#
一次训练数据集的一小部分,而不是整个训练集,或单挑数据
它可以是内存较小,不能同时训练整个数据集的电脑也可以训练模型
它是一个可调节的参数,会对最终结果造成影响
不能太大,因为太大了会速度很慢。也不能太小,太小以后可能算法永远不会收敛
我们将遍历一次所有的样本行为叫做epoch
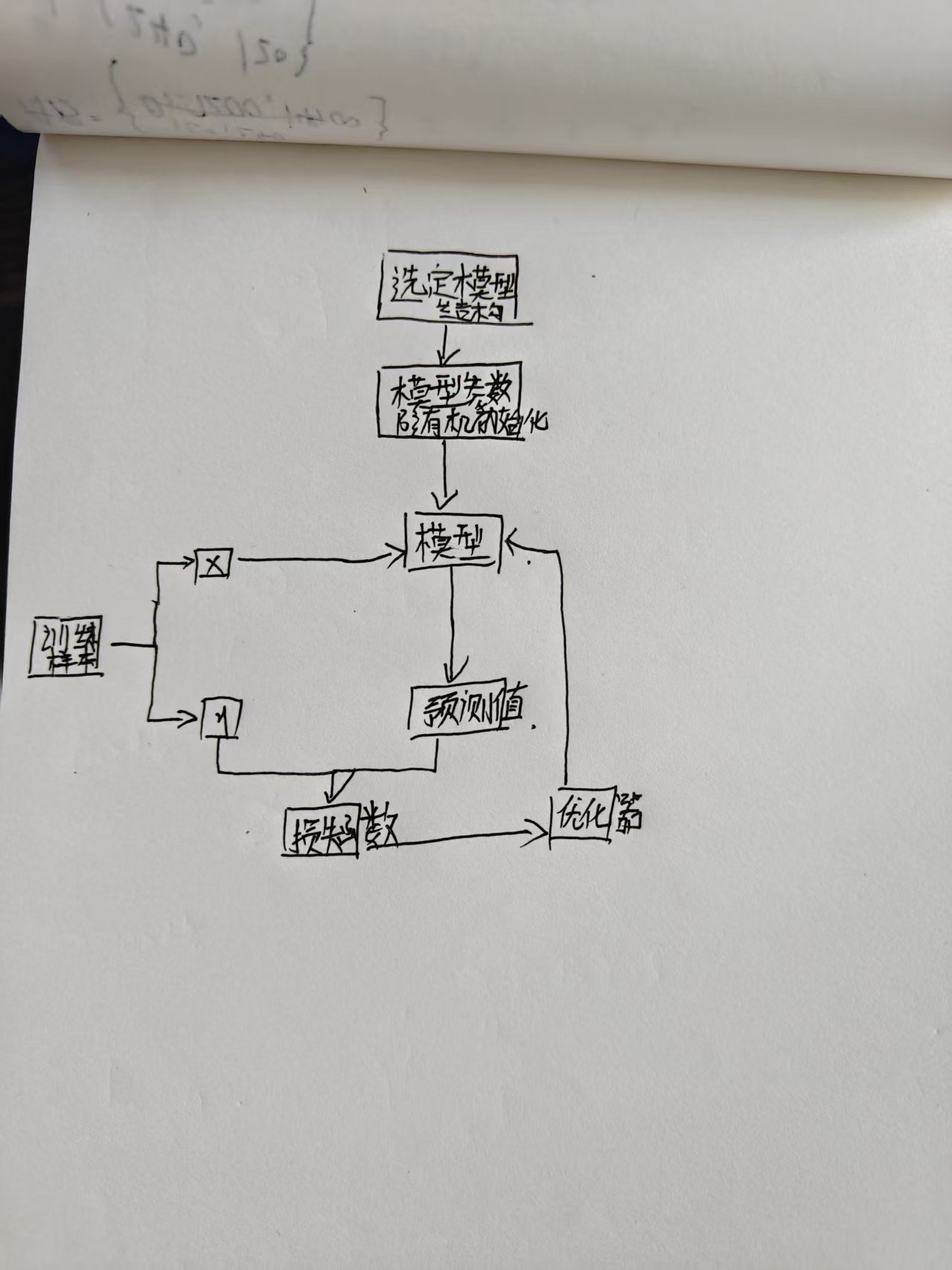
选定模型结构就是选定一个数学函数
x,y是不变的,变的是模型参数和权重