当业务体量达到百万级用户、日均查询量突破千万次时,一个稳定、精准、低延迟的IP归属地查询能力,就不再是简单的API调用,而是一个需要系统化设计的基础设施。
一、为什么企业需要自建IP归属地查询能力?
无论是内容平台的属地展示、电商系统的地域化推荐,还是风控体系的代理IP识别,IP归属地查询已经渗透到业务的各个角落。
行业数据显示,日均IP查询量超过100万次的企业,如果全部依赖公网API调用,月度成本可达数万元。更关键的是,依赖外部接口意味着可用性、延迟、数据更新节奏都受制于人 。
因此,越来越多的技术团队开始搭建企业级的IP归属地查询平台------既能保障数据安全,又能实现毫秒级响应。
二、企业级IP归属地查询平台的核心要素
一个完整的企业级方案,通常包含以下几个关键模块:
|--------|-----------------|--------------|
| 模块 | 说明 | 关键指标 |
| 数据源 | IP归属地数据的来源与更新机制 | 数据精度、更新频率 |
| 在线查询服务 | 面向业务的API接口 | QPS、响应时间、可用性 |
| 离线数据库 | 本地部署的数据文件 | 查询速度、部署灵活性 |
| 管理后台 | 数据监控、版本管理、权限控制 | 运维效率 |
三、数据源选择:精度与覆盖面的平衡
IP归属地的准确性,从根本上取决于数据源的质量。
常见数据来源对比
|-----------|------------------|------------|
| 数据源类型 | 特点 | 适用场景 |
| 开源免费库 | 成本低,但精度有限,更新滞后 | 个人项目、测试环境 |
| 商业API服务 | 精度高、数据实时更新,按次付费 | 小规模业务、快速验证 |
| 离线商业数据库 | 一次性采购,本地部署,毫秒级响应 | 企业级生产环境 |
行业公开数据显示,头部商业IP库的中国区城市级准确率可达97%以上,而免费库通常在70%-80%之间。对于需要IP精确地理位置的业务场景(如本地生活推荐、区域限售),数据精度直接影响业务效果。
四、 架构设计:在线API + 离线库的双轨方案
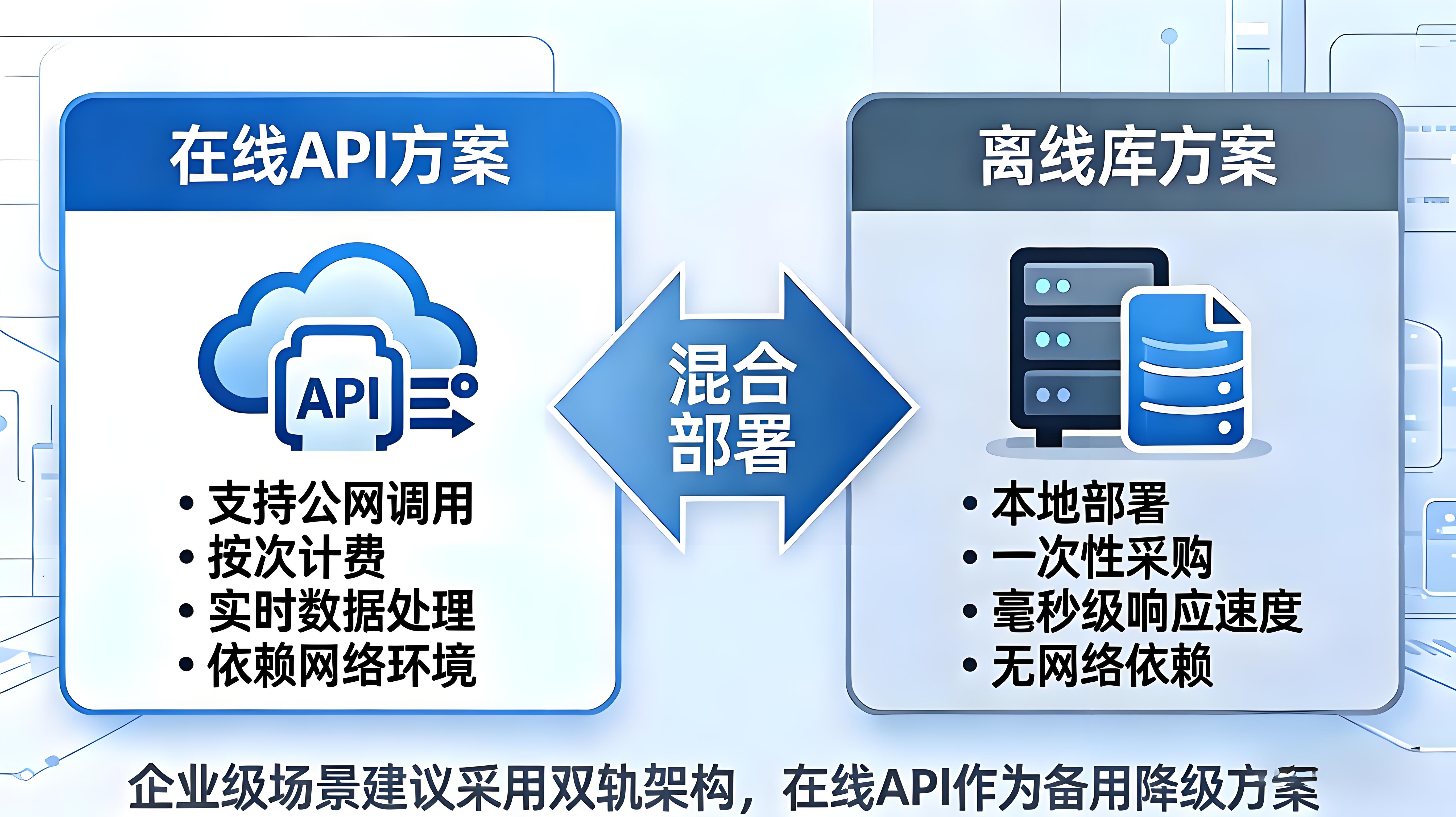
方案一:在线API接口
适用于查询量不大(日均<10万次)、对延迟不敏感的场景。
接入代码示例(Python) :
python
import requests
def query_ip_online(ip):
url = "https://api.ipdatacloud.com/v2/ip/query"# 实际地址以官方文档为准
params = {
"ip": ip,
"key": "your_api_key",
"fields": "country,province,city,isp,net_type"
}
try:
response = requests.get(url, params=params, timeout=3)
response.raise_for_status()
data = response.json()
if data.get("code") == 200:
result = data.get("data")
return {
"ip": ip,
"location": f"{result.get('country', '')}{result.get('province', '')}{result.get('city', '')}",
"isp": result.get("isp"),
"net_type": result.get("net_type")
}
else:
return {"error": data.get("msg")}
except Exception as e:
return {"error": str(e)}
# 调用示例
result = query_ip_online("119.75.217.109")
print(result)方案二:离线IP数据库部署
适用于高并发、低延迟、数据安全敏感的场景。
部署流程 :
- 获取离线库文件 :通常为MMDB或CSV格式,包含IP段与归属地、运营商、网络类型的映射关系
- 本地加载 :将数据加载到内存数据库(如Redis)或直接集成到应用代码中
- 查询接口封装 :对外提供HTTP接口或RPC服务
查询示例(基于本地加载) :
python
import ipaddress
import csv
class LocalIPDB:
def __init__(self, db_path):
self.ip_ranges = []
with open(db_path, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
self.ip_ranges.append({
"start": int(row["ip_start"]),
"end": int(row["ip_end"]),
"country": row["country"],
"province": row["province"],
"city": row["city"],
"isp": row["isp"],
"net_type": row["net_type"]
})
def ip_to_int(self, ip):
return int(ipaddress.IPv4Address(ip))
def query(self, ip):
ip_num = self.ip_to_int(ip)
for item in self.ip_ranges:
if item["start"] <= ip_num <= item["end"]:
return item
return None
# 初始化本地库
db = LocalIPDB("/data/ip_location.csv")
# 查询
result = db.query("119.75.217.109")
print(result)五、性能对比:在线API vs 离线库
根据实际压测数据(单机、4核8G):
|-------|----------|--------|------|-------|
| 方案 | 平均响应时间 | QPS上限 | 网络依赖 | 数据更新 |
| 在线API | 50-150ms | 受限于服务商 | 必须联网 | 实时 |
| 离线库 | 0.1-1ms | 10万+ | 无需联网 | 按版本更新 |
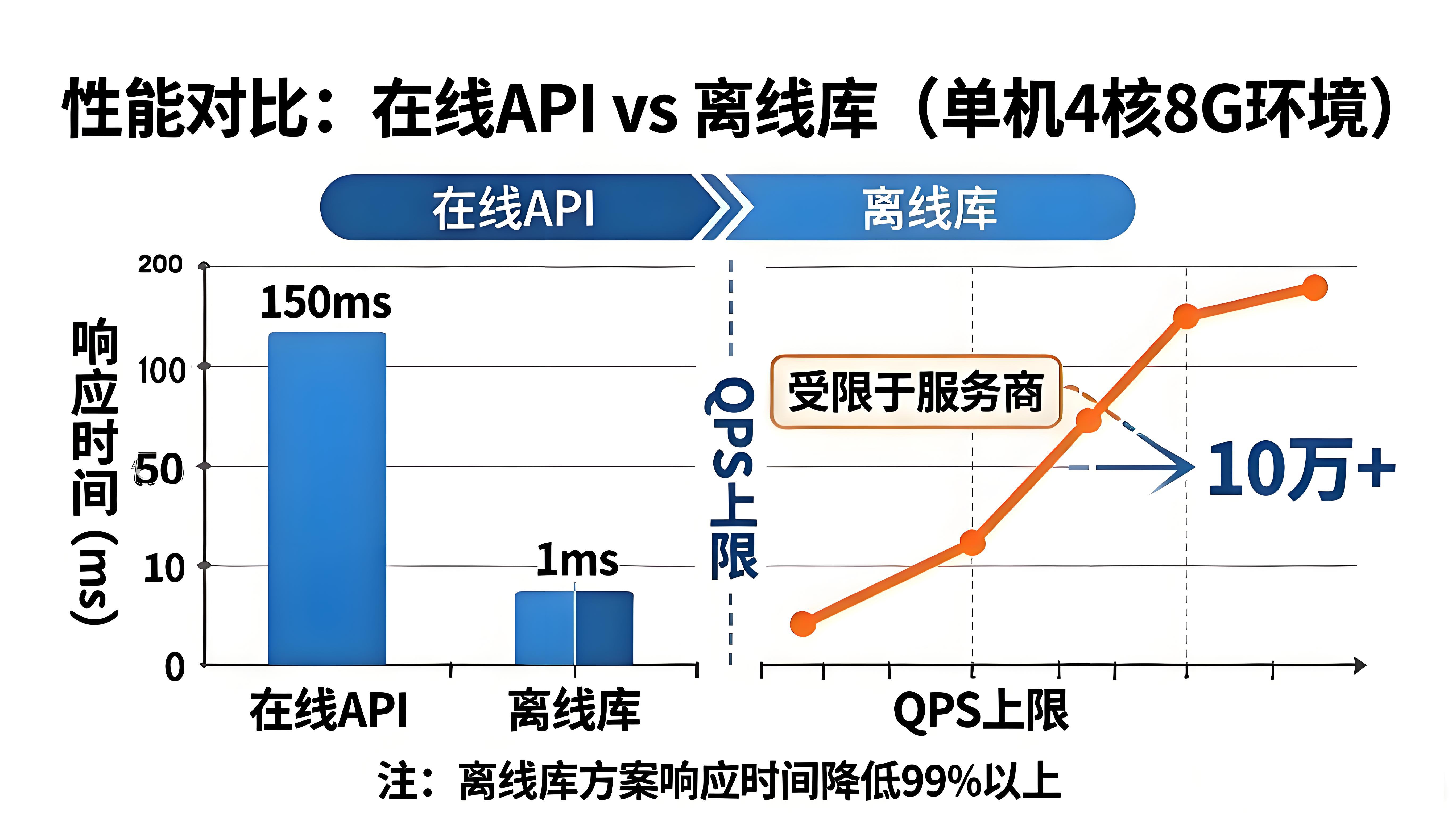
对于日均查询量超过千万次的业务,离线库方案可节省90%以上的接口调用成本,同时将延迟降低两个数量级。
六、数据更新的关键问题
IP归属地的最大挑战在于数据动态变化 ------运营商调整IP段、云厂商扩容、基站漫游等情况每天都在发生。
企业级方案需要建立数据更新机制:
- 在线API :依赖服务商的后台更新,无需维护
- 离线库 :需要定期下载新版数据文件(建议每月更新一次),并支持平滑切换(双版本加载、流量灰度切换)
七、典型应用场景中的能力要求
|----------|--------------|------------------|
| 场景 | 核心需求 | 推荐方案 |
| 网站用户属地展示 | 城市级精度、高并发 | 离线库 + 本地缓存 |
| 电商地域化推荐 | 精确地理位置、运营商识别 | 在线API + 离线库备用 |
| 金融风控 | IP段归属查询、代理识别 | 离线库 + 风险标签字段 |
| 内容平台反爬 | IDC/机房IP识别 | 离线库 + net_type字段 |
八、总结:如何选择适合的搭建方案?
企业级IP归属地查询平台的搭建,没有"一刀切"的标准答案。从实际业务出发:
- 初期验证阶段 :可采用IP归属地API 快速接入,验证业务价值
- 规模化阶段 :建议切换到离线IP数据库部署 方案,控制成本、保障性能
- 混合架构 :在线API作为主库的降级备用,确保高可用
在选型过程中,重点关注三个维度:数据精度 (城市级还是街道级)、更新频率 (实时还是月度)、部署方式 (在线还是离线)。结合IP段归属查询 能力,可以实现更精细化的策略配置;而IP归属地运营商 信息,则是判断用户真实网络环境的重要依据。
本文基于实际工程经验撰写,文中数据来源于行业公开资料。IP归属地相关能力可通过正规技术服务商获取,具体接入方式以对应平台的技术文档为准。