传输层
负责数据能够从发送端传输接收器。
再谈端口号
端口号标识了一个主机上进行通信的不同应用程序;
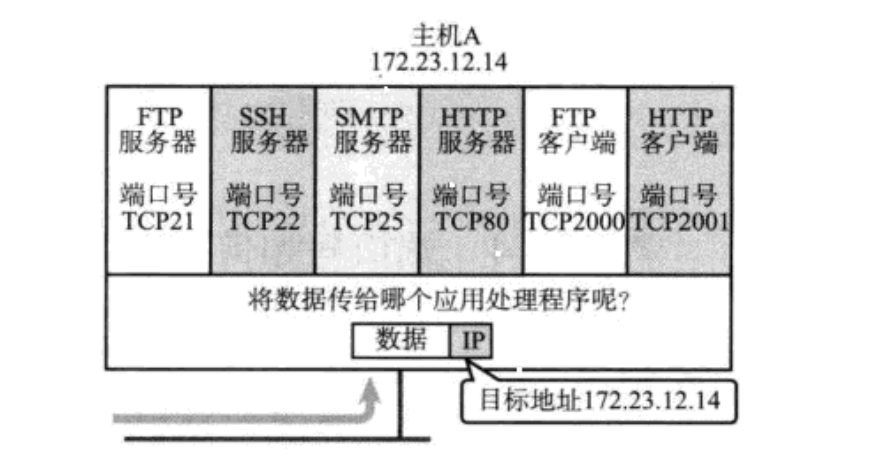
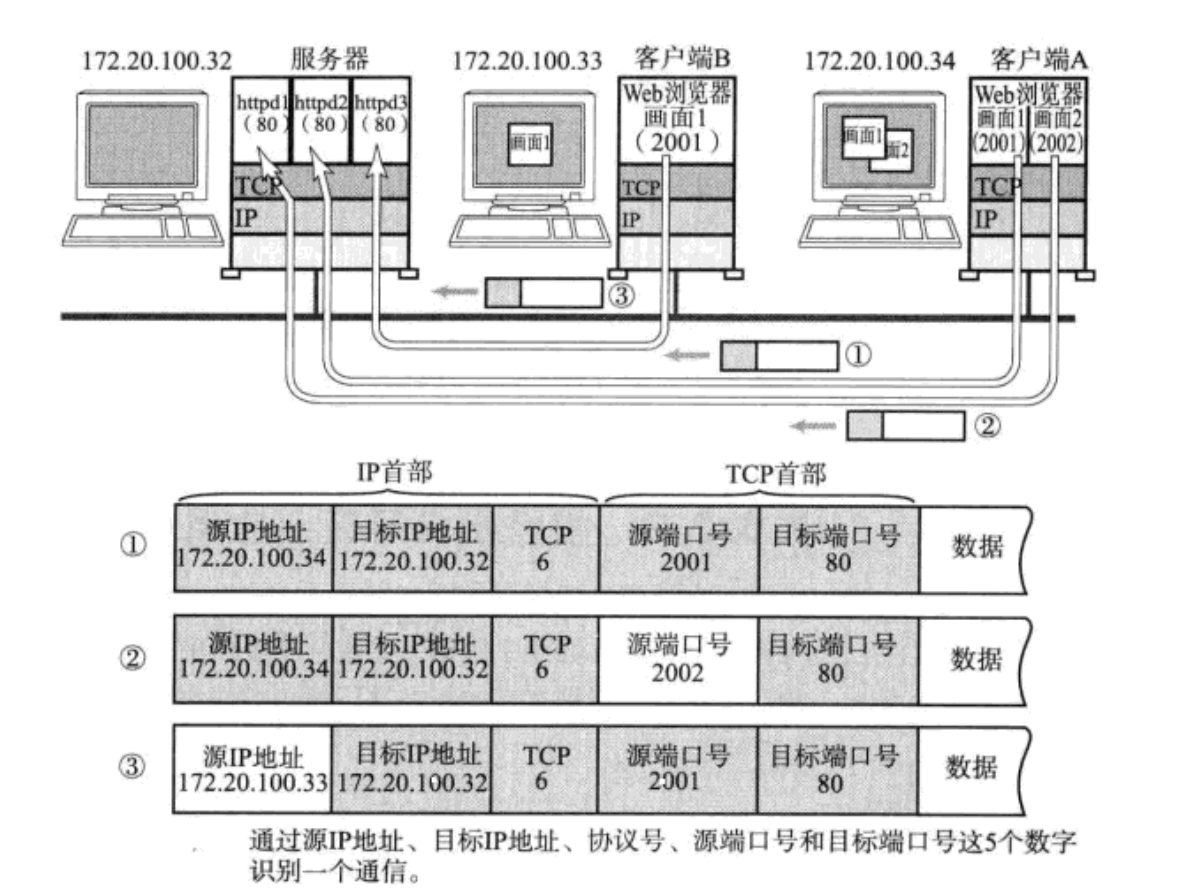
- 在TCP/IP协议中,用"源IP","源端口号","目的IP","目的端口号"这样的一个五元组来标识一个通信
端口号的划分
端口一共分为 3 类:
1. 知名端口(Well-known Ports)
范围:0 ~ 1023
- 固定分配给常用系统服务
- 普通程序不能随便用
- 需要管理员权限
常见 UDP 知名端口:
- 53:DNS(域名解析)
- 67/68:DHCP(自动获取 IP)
- 69:TFTP(简单文件传输)
- 161:SNMP(网络管理)
2. 注册端口(Registered Ports)
范围:1024 ~ 49151
- 给用户程序、第三方软件使用
- 不需要管理员权限
- 可以向 IANA 注册,但不强制
例子:
- 1900:SSDP(设备发现)
- 3478:STUN(NAT 穿透)
3. 临时端口 / 动态端口(Dynamic/Private Ports)
范围:49152 ~ 65535
- 客户端临时自动使用
- 用完就释放
- 不需要手动分配
当你用 UDP 发消息时,操作系统会自动给你分配一个临时端口。
常见的知名端口号
纯 UDP 服务:
- 53:DNS(域名解析)
- 67 / 68:DHCP(自动获取 IP)
- 69:TFTP(简单文件传输)
- 123:NTP(网络时间同步)
- 161:SNMP(网络设备管理)
- 162:SNMP Trap(告警)
TCP服务,日常网络、服务器必用:
- 20 / 21:FTP(文件传输)
- 22:SSH(安全远程登录)
- 23:Telnet(不安全远程登录)
- 25:SMTP(发邮件)
- 53:DNS(也用 TCP)
- 80:HTTP(网页)
- 110:POP3(收邮件)
- 143:IMAP(收邮件)
- 443:HTTPS(加密网页)
- 3389:Windows 远程桌面
问题:
1.一个进程是否可以绑定多个端口号?
- 一个进程(程序)同时绑定多个不同的端口号是非常正常、非常常见的操作,没有任何限制。
- 同时提供多种服务
- TCP和UDP分开
- 区分不同的功能
- 同一个协议 + 同一个端口 = 只能一个进程绑定
- 不同协议 = 端口可以重复,进程 A:TCP 80 ,进程 B:UDP 80
UDP协议
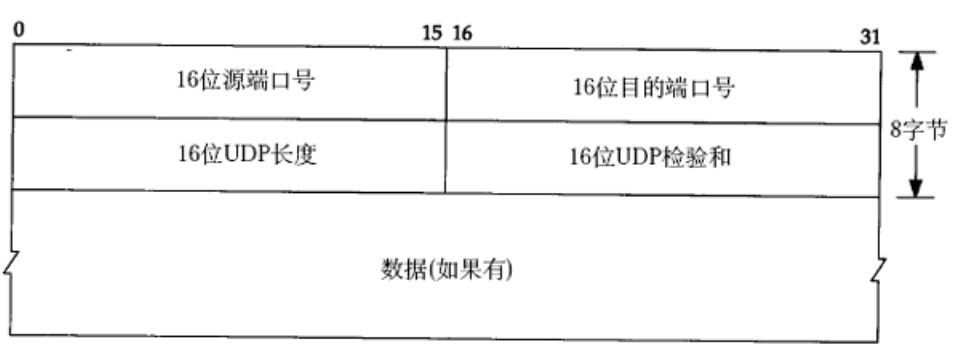
- 内核中UDP协议规定端口号就是16位的
- 16位UDP长度负责UDP报头和报文分离。
- UDP不存在数据粘包问题。
- UDP是用户数据报,发送缓冲区收到一个数据报,就发一个数据报
如何理解UDP协议报头?
协议报头就是一个结构体,通信双方互传结构体变量。
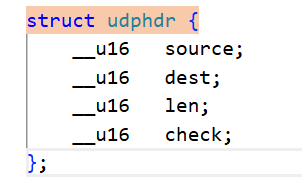
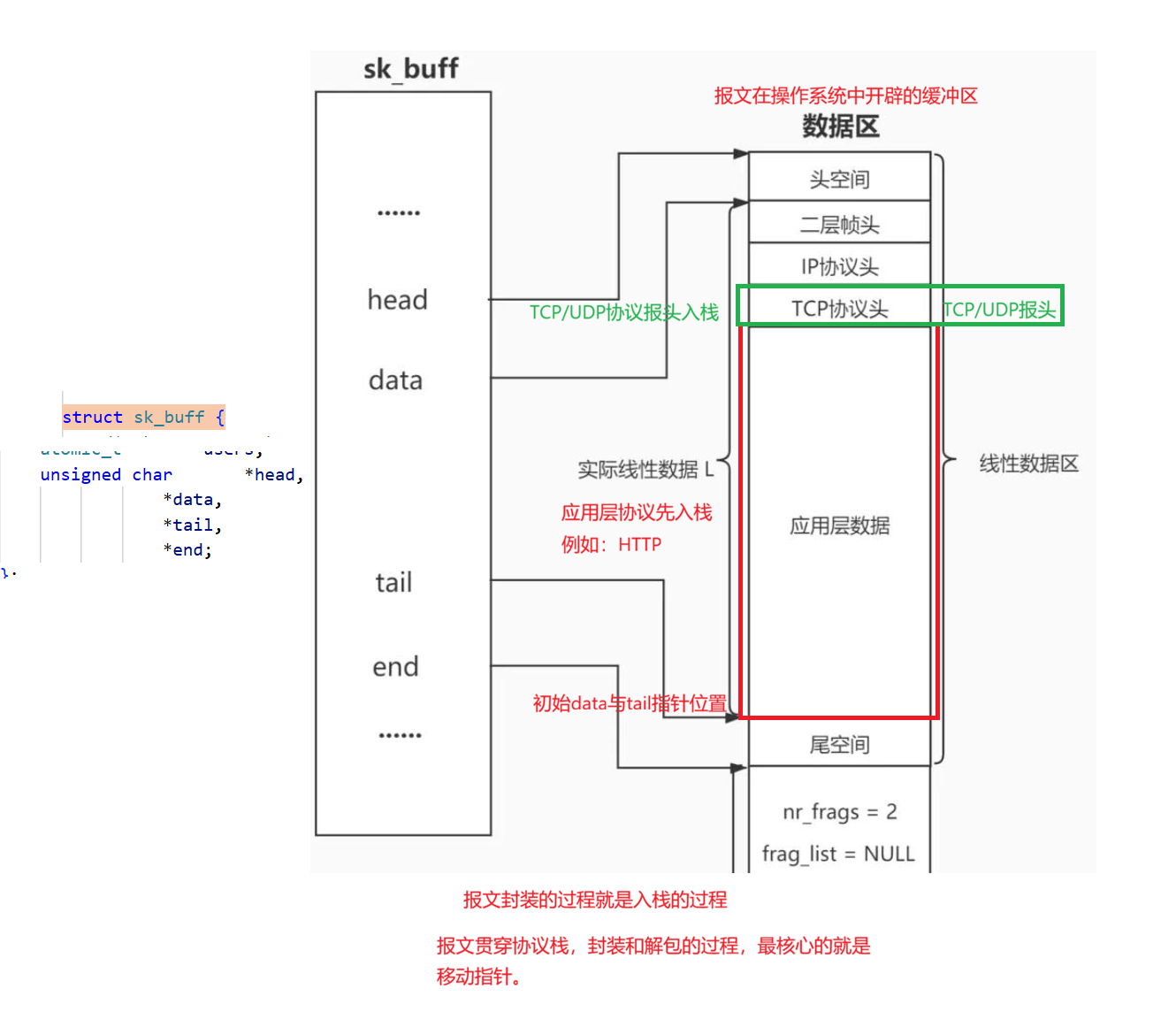
如何理解报文?重新理解封装过程和解包过程?
操作系统内部可能会同时存在很多报文,那么操作系统就要对这些报文进行管理,先描述再组织。
如何理解一个报文:在内核中,struct sk_buff,任何一个报文在操作系统内部都会开辟一个缓冲区。
管理报文的思路和操作系统管理进程的思路一模一样。
cpp
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk;
struct skb_timeval tstamp;
struct net_device *dev;
struct net_device *input_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
struct dst_entry *dst;
struct sec_path *sp;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48];
unsigned int len,
data_len,
mac_len,
csum;
__u32 priority;
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3,
fclone:2,
ipvs_property:1;
__be16 protocol;
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_NETFILTER
struct nf_conntrack *nfct;
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct sk_buff *nfct_reasm;
#endif
#ifdef CONFIG_BRIDGE_NETFILTER
struct nf_bridge_info *nf_bridge;
#endif
__u32 nfmark;
#endif /* CONFIG_NETFILTER */
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
#ifdef CONFIG_NET_DMA
dma_cookie_t dma_cookie;
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
/* These elements must be at the end, see alloc_skb() for details. */
unsigned int truesize;
atomic_t users;
unsigned char *head,
*data,
*tail,
*end;
};
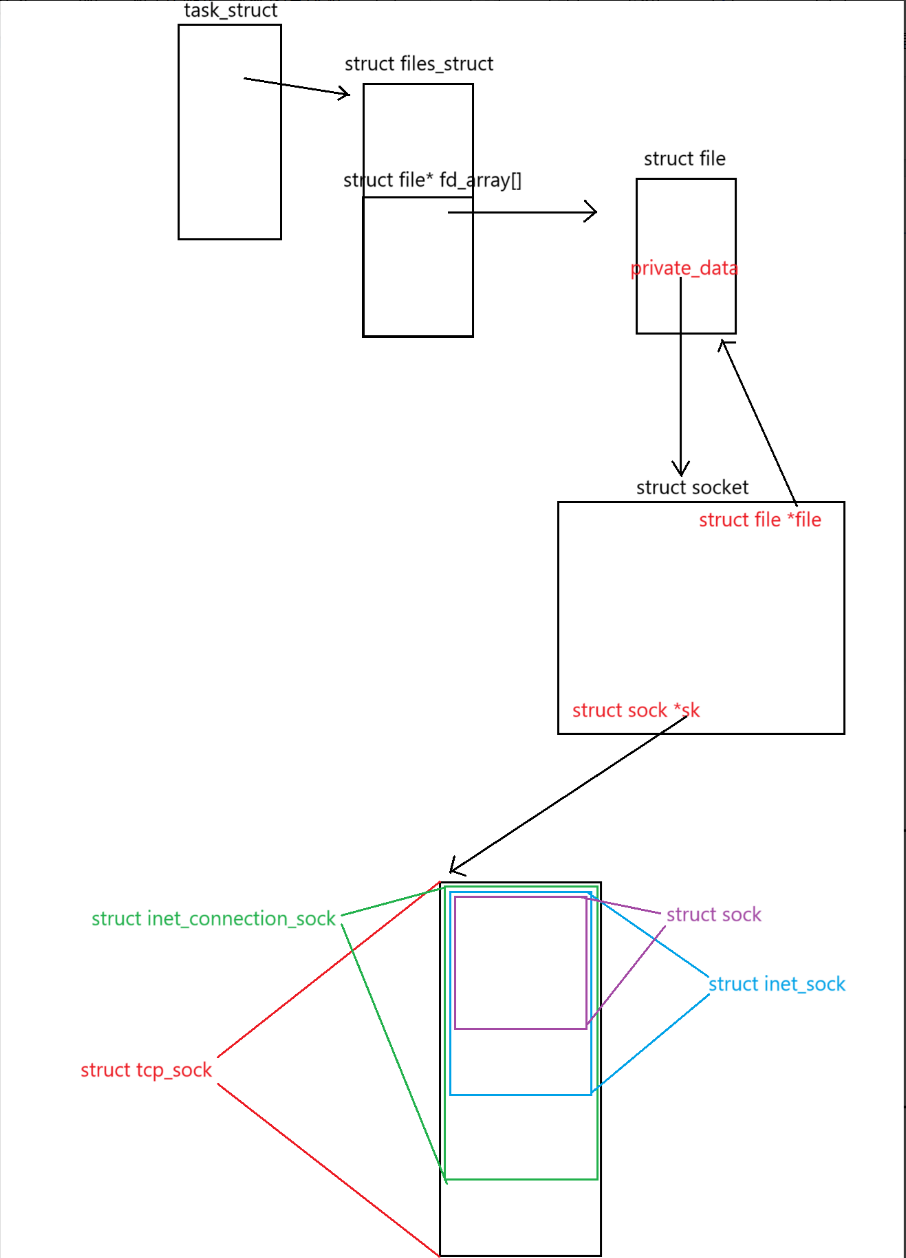
当我们收到一个报文的时候,我们是如何做到用文件原理,读数据到应用层?
cpp
struct sock {
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_family __sk_common.skc_family
#define sk_state __sk_common.skc_state
#define sk_reuse __sk_common.skc_reuse
#define sk_bound_dev_if __sk_common.skc_bound_dev_if
#define sk_node __sk_common.skc_node
#define sk_bind_node __sk_common.skc_bind_node
#define sk_refcnt __sk_common.skc_refcnt
#define sk_hash __sk_common.skc_hash
#define sk_prot __sk_common.skc_prot
unsigned char sk_shutdown : 2,
sk_no_check : 2,
sk_userlocks : 4;
unsigned char sk_protocol;
unsigned short sk_type;
int sk_rcvbuf;
socket_lock_t sk_lock;
wait_queue_head_t *sk_sleep;
struct dst_entry *sk_dst_cache;
struct xfrm_policy *sk_policy[2];
rwlock_t sk_dst_lock;
atomic_t sk_rmem_alloc;
atomic_t sk_wmem_alloc;
atomic_t sk_omem_alloc;
struct sk_buff_head sk_receive_queue;
struct sk_buff_head sk_write_queue;
struct sk_buff_head sk_async_wait_queue;
int sk_wmem_queued;
int sk_forward_alloc;
gfp_t sk_allocation;
int sk_sndbuf;
int sk_route_caps;
int sk_gso_type;
int sk_rcvlowat;
unsigned long sk_flags;
unsigned long sk_lingertime;
/*
* The backlog queue is special, it is always used with
* the per-socket spinlock held and requires low latency
* access. Therefore we special case it's implementation.
*/
struct {
struct sk_buff *head;
struct sk_buff *tail;
} sk_backlog;
struct sk_buff_head sk_error_queue;
struct proto *sk_prot_creator;
rwlock_t sk_callback_lock;
int sk_err,
sk_err_soft;
unsigned short sk_ack_backlog;
unsigned short sk_max_ack_backlog;
__u32 sk_priority;
struct ucred sk_peercred;
long sk_rcvtimeo;
long sk_sndtimeo;
struct sk_filter *sk_filter;
void *sk_protinfo;
struct timer_list sk_timer;
struct timeval sk_stamp;
struct socket *sk_socket;
void *sk_user_data;
struct page *sk_sndmsg_page;
struct sk_buff *sk_send_head;
__u32 sk_sndmsg_off;
int sk_write_pending;
void *sk_security;
void (*sk_state_change)(struct sock *sk);
void (*sk_data_ready)(struct sock *sk, int bytes);
void (*sk_write_space)(struct sock *sk);
void (*sk_error_report)(struct sock *sk);
int (*sk_backlog_rcv)(struct sock *sk,
struct sk_buff *skb);
void (*sk_destruct)(struct sock *sk);
};
cpp
struct inet_sock {
/* sk and pinet6 has to be the first two members of inet_sock */
struct sock sk;
#if defined(CONFIG_IPV6) || defined(CONFIG_IPV6_MODULE)
struct ipv6_pinfo *pinet6;
#endif
/* Socket demultiplex comparisons on incoming packets. */
__u32 daddr;
__u32 rcv_saddr;
__u16 dport;
__u16 num;
__u32 saddr;
__s16 uc_ttl;
__u16 cmsg_flags;
struct ip_options *opt;
__u16 sport;
__u16 id;
__u8 tos;
__u8 mc_ttl;
__u8 pmtudisc;
__u8 recverr:1,
is_icsk:1,
freebind:1,
hdrincl:1,
mc_loop:1;
int mc_index;
__u32 mc_addr;
struct ip_mc_socklist *mc_list;
struct {
unsigned int flags;
unsigned int fragsize;
struct ip_options *opt;
struct rtable *rt;
int length; /* Total length of all frames */
u32 addr;
struct flowi fl;
} cork;
};
cpp
struct udp_sock {
/* inet_sock has to be the first member */
struct inet_sock inet;
int pending; /* Any pending frames ? */
unsigned int corkflag; /* Cork is required */
__u16 encap_type; /* Is this an Encapsulation socket? */
/*
* Following member retains the information to create a UDP header
* when the socket is uncorked.
*/
__u16 len; /* total length of pending frames */
};- udp_sock包含inet_sock,inet_sock包含sock
- sock就是基类,网络协议栈向下传递的过程就是从sock到inet_sock到udp_sock的过程。
UDP的特点
面向数据报
应⽤层交给UDP多⻓的报⽂, UDP原样发送, 既不会拆分, 也不会合并;
⽤UDP传输100个字节的数据:
如果发送端调⽤⼀次sendto, 发送100个字节, 那么接收端也必须调⽤对应的⼀次recvfrom, 接收
100个字节; ⽽不能循环调⽤10次recvfrom, 每次接收10个字节;
这个特点解决了报文的粘包问题。
UDP协议不可靠为什么还要用?
- 不可靠不是说数据传不过去,只是如果数据丢包了,不关心。
- 丢包:比如商家发快递,一个物品分成十份发送,用户收到后需要拼接,丢包率为20%时,客户只收到了8个包裹,如果协议是udp,就算其中几个包裹丢失,商家也不管,不会把丢失的那部分重新给你发。
- 如果网络状态比较好,就不需要重新发送。
- 简单直接说:丢包 ≠ 完全传不过去 ,它是数据传输过程中,部分数据包丢失、损坏、超时,没到达目的地的现象。
- udp不可靠,无连接,说明udp简单,一些不需要关心数据丢失或超时的场景,使用udp可以提高效率,比如直播。
- udp的不可靠,不能说成缺点,而是特点。
UDP的缓冲区
- udp不需要保证可靠性,数据发送出去后,在本地直接就可以把数据删除。
- UDP没有真正意义上的 发送缓冲区. 调⽤sendto会直接交给内核, 由内核将数据传给⽹络层协议进⾏后续的传输动作;
- UDP具有接收缓冲区. 但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序⼀致 如果缓冲区满了, 再到达的UDP数据就会被丢弃
UDP使用的注意事项
我们注意到, UDP协议⾸部中有⼀个16位的最⼤⻓度. 也就是说⼀个UDP能传输的数据最⼤⻓度是
64K(包含UDP⾸部).
然⽽64K在当今的互联⽹环境下, 是⼀个⾮常⼩的数字.
如果我们需要传输的数据超过64K, 就需要在应⽤层⼿动的分包, 多次发送, 并在接收端⼿动拼装;
把网络进程,守护进程化
进程组
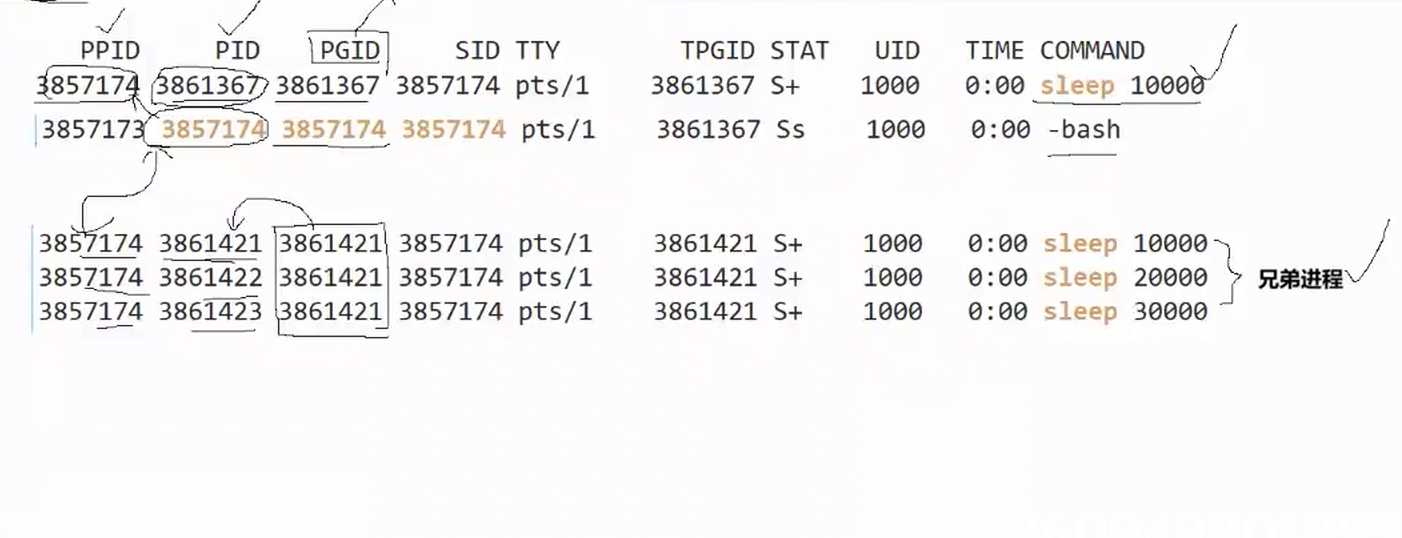
- PGID就是进程组,PGID相同的进程就是同一组进程。
进程间关系与守护进程
进程组



- 同一个进程组中的进程,进程pid最小的是组长。
- 前后台进程管理是以进程组为单位的。
- ctrl+c向发信号是向前台进程组发信号。
- 同一组的进程可以使用隐藏管道通信。
作业

- 进程组和作业是一个硬币的两面
- 作业要由进程组来完成,作业和进程组可以是一回事。
- 使用jobs查看作业数。

- 将后台作业转为前台:fg 作业号
会话
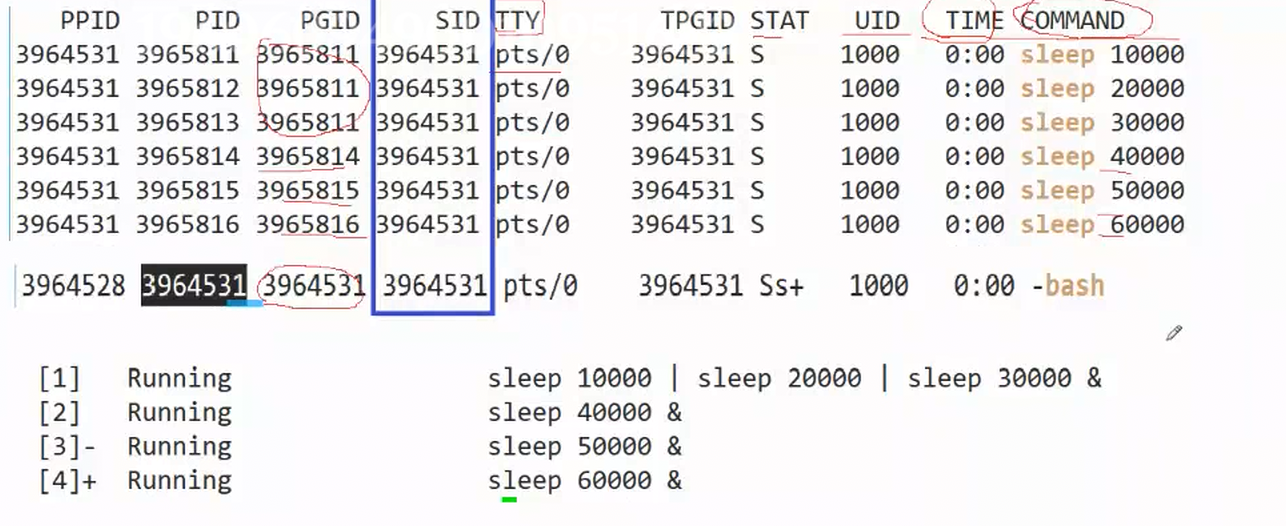
- SID叫做会话ID
- 我们每一次登录xshell就会在远程服务器上创建一个终端文件和bash,这两个加起来叫做会话。
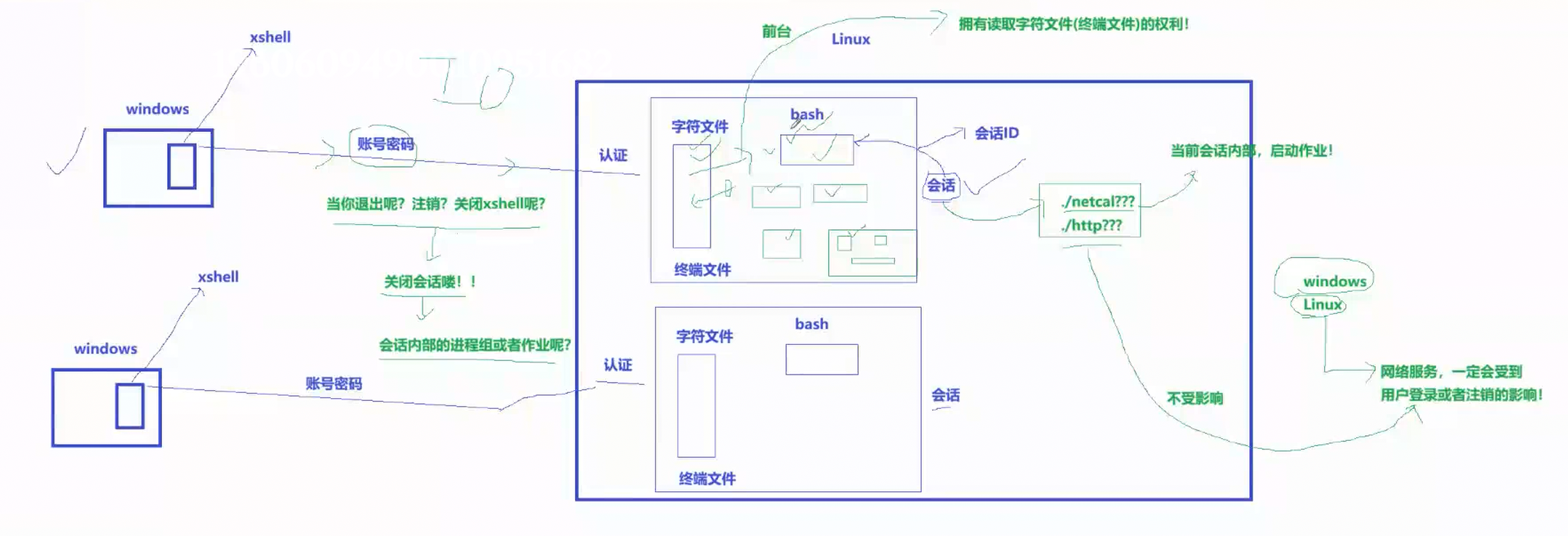
进程如何成为一个独立的会话?

- 哪个进程调用该函数,该进程就会独自成立一个会话
- 创建独立会话的进程不能是进程组的组长。
- 在命令行启动一个进程的作业,这个进程是自成组长的。
- 创建子进程调用setsid,父进程退出,这个子进程就是守护进程,也是孤儿进程。
- 进程组不等于组长进程,组长进程退出,进程组还存在,只有全部进程退出,组才会消失。
守护进程:
守护进程 = 升级版 + 彻底脱离终端 + 永久运行 的 后台进程
守护进程(Daemon)
- 完全脱离终端、脱离用户登录会话
- 系统开机自动运行,用户登出也不会死
- 长期在后台默默服务(httpd、nginx、sshd、crontab)
- 父进程变成
init/systemd(PID=1)
普通后台进程随终端,守护后台进程随系统。
创建守护进程
认识特殊文件dev/null

- 打开zero文件,在这个文件中可以获取一些随机数据。
- null文件类似回收站,写入这个文件中的内容,会被系统自动丢弃,读取这个文件,读到的都是0.
cpp
#pragma once
#include <iostream>
#include<signal.h>
#include <unistd.h>
#include <fcntl.h>
void Daemon()
{
//1.忽略信号
signal(SIGPIPE, SIG_IGN);//忽略SIGPIPE信号,防止写入一个已经关闭的socket时,程序被杀死
signal(SIGCHLD, SIG_IGN);//忽略SIGCHLD信号,防止子进程退出时产生僵尸进程
//2不能是组长
if(fork()>0)
{
exit(0);
}
//3.父进程退出(组长退出),子进程运行,设置新会话
pid_t id = setsid();
(void)id;
//更改守护进程的工作目录
chdir("/");
//4.重定向0,1,2
int fd = open("/dev/null", O_RDWR);
if(fd>=0)
{
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
if(fd>2)
{
close(fd);
}
}
}
- 系统调用的守护进程
- 参数为是否要更改工作目录,是否要重定向,(0,0)更改工作目录并且重定向