为什么要使用Hadoop
1)数据量增长带来的问题
- 存储问题: 单机难以存储PB级数据
- 处理问题: 海量数据的计算处理瓶颈
- 分析问题: 需要高效分析工具提取价值
- 扩展问题: 数据快速增长时的系统扩展方案
2)单台机器处理能力的局限性
- 硬件限制: 通过增加单机存储、CPU、内存等方式很快达到瓶颈
- 性能瓶颈: 数据量持续增长时单机性能完全跟不上需求
3)分布式系统的提出与问题
- 解决方案: 采用多台计算机分布式处理
- 现存问题:
- 复杂性: 系统扩展和管理复杂度高
- 可靠性: 容易出现错误
- 性能: 处理速度仍不够理想
Hadoop起源历程
1)Doug Cutting开发Nutch项目时发现需求
- 背景: 2002年开发网络爬虫项目Nutch时
- 发现: 需要可靠的分布式存储和处理框架
- 特点: 处理互联网爬取的海量数据需求
2)Doug Cutting借鉴谷歌论文构建分布式平台
- 关键影响: 2003年谷歌发布的GFS和MapReduce论文
- 技术基础: 基于论文思想构建MR( MapReduce)和NDFS
- 演进关系: 这些成为后来HDFS和MapReduce的前身
3)Hadoop的正式产生与阿帕奇项目启动
- 命名起源: 2006年从Nutch项目中分离并命名为Hadoop
- 雅虎支持: 提供资源支持Hadoop发展
- Apache项目: 同年成为Apache顶级项目
- 技术体系: 开始支持MapReduce和HDFS独立发展
Hadoop在百度和淘宝的应用
- 百度应用:2007年开始使用Hadoop进行离线处理,目前约80%-90%的Hadoop集群用于日志处理
- 淘宝应用:2008年投入研究Hadoop系统(代号"云梯"),当时规模达1000多台机器,日处理数据量500TB
Hadoop生态圈
- 与传统工具的区别:相比Tomcat、MySQL等单一功能工具,Hadoop包含大量组件形成完整生态圈,可完成数据管理、并行处理等多样化任务
- 组件构成:由数据存储(HDFS/HBase)、数据集成(Sqoop)、数据处理(MapReduce)和专门分析工具(Hive/Pig)等组件组成
- 学习视角:需要从生态圈整体角度学习,而非单独研究HDFS和MapReduce两个核心组件
- 数据处理层:
- Pig/Hive:提供Pig Latin和HQL高级查询语言,简化MapReduce编程复杂度
- Sqoop:实现HDFS与关系型数据库间的双向数据转换工具
- Flume:日志监控与传输系统
- 协调管理:
- ZooKeeper:集群协同管理组件,淘宝Dubbo等系统底层采用
- Oozie:作业调度工具,可调度MapReduce/Hive脚本执行
- 存储与计算:
- HBase:基于HDFS的NoSQL数据库,支持列式存储
- MapReduce:批处理计算框架
- YARN:Hadoop2.x引入的资源管理框架
- 基础层:
- HDFS:分布式块存储基础
- Tachyon:可选内存分布式缓存(非默认组件)
- 资源调度:
- YARN/Mesos:资源管理框架,Hadoop默认使用YARN
- 计算框架:
- MapReduce:批处理模型
- Tez:DAG计算模型
- Spark:内存计算模型(可基于YARN运行)
- 上层工具:
- Hive/Pig:转换为MapReduce执行
- Mahout/MLlib:机器学习框架(分别支持MapReduce和Spark)
- GraphX/Streaming:图计算与流计算框架
- 辅助系统:
- Kafka:实时消息队列
- Ambari:集群安装部署工具
- Phoenix:为HBase提供SQL接口
Hadoop基本组件介绍
1. Hadoop核心组件
- 基础架构:
- HDFS: 分布式多备份文件系统,提供可靠存储
- MapReduce: 分布式计算模型,处理大规模数据集
- HBase: NoSQL数据库,支持实时读写访问
- 高层应用:
- Hive: 使用类SQL语言(HQL)的数据仓库工具
- Pig: 采用Pig Latin语言的数据流处理工具(课程不重点讲解)
- 辅助工具:
- Zookeeper: 集群协调管理服务
- Oozie: 工作流调度框架
- Sqoop/Flume: 数据导入工具(Sqoop用于关系型数据库,Flume用于日志等流数据)
2. Hadoop版本信息
- Apache社区版:
- 特点: 完全开源免费,迭代快(年更新多次),需自行解决组件兼容问题
- 适用场景: 需要高度定制化的开发环境
- CDH(Cloudera版):
- 优化: 合并社区补丁,优化性能并解决组件兼容问题
- 版本区别:
- 个人免费版支持≤50节点集群
- 企业版需付费,支持更大规模集群
- Hortonworks版:
- 特色: 增强Hive的ODBC驱动性能
- 现状: 国内使用较少,主流选择为Apache或CDH
3. Hadoop企业级应用
- 四层架构:
- 数据存储层:
- 源数据: 业务数据库/日志/用户行为数据等外部数据
- 中间数据: MapReduce/Hive等处理后的结果数据
- 导入工具: Sqoop(关系型数据)、Flume(流式数据)
- 数据处理层:
- 核心组件: Oozie调度MapReduce/Hive任务
- 输出: 生成供其他模块使用的中间数据
- 实时访问层:
- 访问模式: 单条数据访问(HBase原生支持)和数据集访问
- 安全层(可选):
- 功能: 数据权限控制,防止未授权操作
- 数据存储层:
4. Hadoop企业级应用图
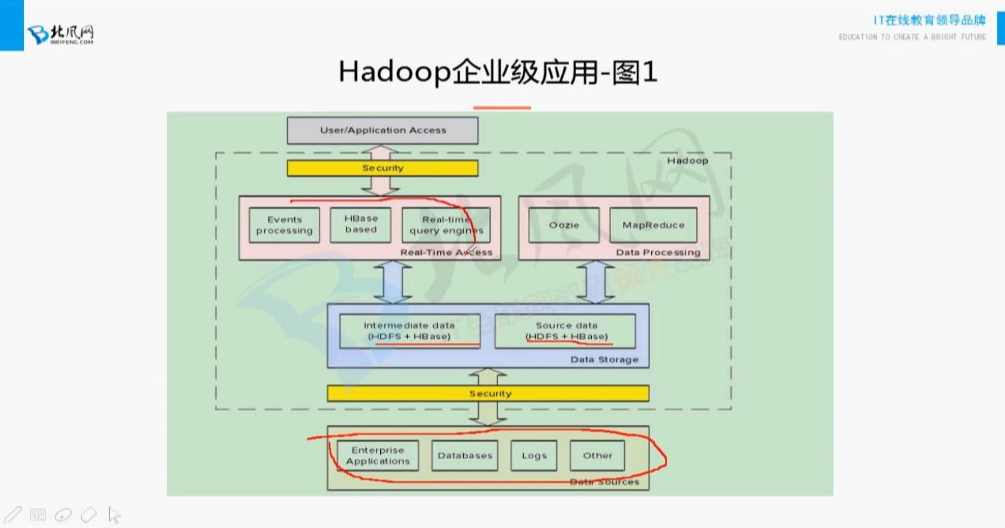
- 数据流向:
- 外部数据源→HDFS/HBase存储→MapReduce/Hive处理→实时应用接口
- 组件协作:
- Oozie协调计算任务,HBase支持实时查询
- 处理结果通过API提供给终端用户或其他应用