目录
- 前言
- [一、Cookie 与 Session 核心原理](#一、Cookie 与 Session 核心原理)
-
- [1.1 HTTP 协议的无状态特性](#1.1 HTTP 协议的无状态特性)
- [1.2 Cookie 原理与特点](#1.2 Cookie 原理与特点)
-
- [1.2.1 什么是 Cookie](#1.2.1 什么是 Cookie)
- [1.2.2 Cookie 核心特点](#1.2.2 Cookie 核心特点)
- [1.2.3 Cookie 常见属性](#1.2.3 Cookie 常见属性)
- [1.3 Session 原理与特点](#1.3 Session 原理与特点)
-
- [1.3.1 什么是 Session](#1.3.1 什么是 Session)
- [1.3.2 Session 核心特点](#1.3.2 Session 核心特点)
- [1.4 Cookie 与 Session 核心区别](#1.4 Cookie 与 Session 核心区别)
- [1.5 会话完整工作流程](#1.5 会话完整工作流程)
- [二、爬虫中 Cookie 的作用](#二、爬虫中 Cookie 的作用)
- [三、Requests 库 Cookie 操作基础](#三、Requests 库 Cookie 操作基础)
-
- [3.1 安装 Requests](#3.1 安装 Requests)
- [3.2 方式一:自动获取与携带 Cookie](#3.2 方式一:自动获取与携带 Cookie)
- [3.3 方式二:手动构造 Cookie 字典](#3.3 方式二:手动构造 Cookie 字典)
- [3.4 方式三:CookieJar 转字典](#3.4 方式三:CookieJar 转字典)
- [3.5 从响应头解析 Set-Cookie](#3.5 从响应头解析 Set-Cookie)
- [四、Session 对象:自动维持连续会话](#四、Session 对象:自动维持连续会话)
-
- [4.1 Session 作用](#4.1 Session 作用)
- [4.2 Session 基础用法](#4.2 Session 基础用法)
- [4.3 Session 优势对比](#4.3 Session 优势对比)
- 五、实战一:模拟登录并爬取会员页面
-
- [5.1 场景说明](#5.1 场景说明)
- [5.2 完整代码](#5.2 完整代码)
- [5.3 关键说明](#5.3 关键说明)
- [六、实战二:Session 连续操作(登录→个人中心→退出)](#六、实战二:Session 连续操作(登录→个人中心→退出))
-
- [6.1 场景](#6.1 场景)
- [6.2 代码实现](#6.2 代码实现)
- [七、实战三:手动解析 Set-Cookie 并设置过期时间](#七、实战三:手动解析 Set-Cookie 并设置过期时间)
-
- [7.1 场景](#7.1 场景)
- [7.2 代码](#7.2 代码)
- 八、常见问题与解决方案
-
- [8.1 携带 Cookie 仍登录失效](#8.1 携带 Cookie 仍登录失效)
- [8.2 Set-Cookie 有多个值无法解析](#8.2 Set-Cookie 有多个值无法解析)
- [8.3 登录需要验证码](#8.3 登录需要验证码)
- [8.4 服务器禁用 Cookie](#8.4 服务器禁用 Cookie)
- [8.5 Cookie 过期太快](#8.5 Cookie 过期太快)
- [九、配图说明(HTML 结构示意)](#九、配图说明(HTML 结构示意))
-
- [9.1 Cookie 与 Session 流程图 HTML](#9.1 Cookie 与 Session 流程图 HTML)
- [9.2 Requests Session 对比图 HTML](#9.2 Requests Session 对比图 HTML)
- 十、总结
前言
在爬虫开发中,保持登录状态是爬取会员内容、个人数据、动态交互页面的核心前提。绝大多数网站通过 Cookie 与 Session 实现用户身份识别与会话保持,若爬虫无法正确处理会话,会频繁出现登录失效、权限不足、页面跳转回登录页等问题。
本文将从原理、区别、实战三个维度,系统讲解 Cookie 与 Session 的工作机制,结合 Python Requests 库实现自动/手动管理 Cookie、使用 Session 对象维持连续会话,并通过完整可运行代码演示登录爬取、连续操作、手动解析与设置 Cookie 等场景,帮助开发者彻底掌握爬虫会话管理。
一、Cookie 与 Session 核心原理
1.1 HTTP 协议的无状态特性
HTTP 是无状态协议,服务器不会主动记忆上一次请求的用户身份。每一次请求对服务器而言都是全新的,无法区分"已登录用户"和"未登录用户"。
为了解决这一问题,Web 系统引入了会话机制,通过 Cookie + Session 组合实现用户状态持久化。
1.2 Cookie 原理与特点
1.2.1 什么是 Cookie
Cookie 是服务器通过 HTTP 响应头 Set-Cookie 发送给浏览器的小型文本数据 ,由浏览器存储在客户端(电脑/手机本地),后续每次请求同一域名时,浏览器会自动通过请求头 Cookie 带回给服务器。
1.2.2 Cookie 核心特点
- 存储位置:客户端(浏览器/本地文件)
- 存储大小:单域名一般限制 4KB 左右
- 可设置属性:过期时间、域名、路径、安全标志、HttpOnly 等
- 传输方式:随 HTTP 请求头自动发送
- 安全性:明文存储,易被窃取、篡改
1.2.3 Cookie 常见属性
| 属性 | 作用 |
|---|---|
Name=Value |
Cookie 名称与值,核心内容 |
Expires/Max-Age |
过期时间,超时自动失效 |
Domain |
生效域名,仅该域名可发送此 Cookie |
Path |
生效路径,如 /user 仅用户页生效 |
HttpOnly |
禁止 JS 读取,防 XSS 窃取 |
Secure |
仅 HTTPS 传输 |
1.3 Session 原理与特点
1.3.1 什么是 Session
Session 是服务器端存储的用户会话数据 ,服务器为每个用户创建唯一的 SessionID,并通过 Cookie 将 SessionID 发送给客户端。
客户端后续请求携带 SessionID,服务器根据 ID 查找对应会话数据,识别用户身份。
1.3.2 Session 核心特点
- 存储位置:服务器内存、文件、数据库、Redis
- 安全性:数据不暴露给客户端,安全性更高
- 依赖关系 :必须依赖 Cookie 传递 SessionID
- 生命周期:默认会话结束(关闭浏览器)失效,可设置超时
- 存储容量:远大于 Cookie,可存储复杂用户信息
1.4 Cookie 与 Session 核心区别
| 对比维度 | Cookie | Session |
|---|---|---|
| 存储位置 | 客户端 | 服务器端 |
| 存储大小 | 小(约4KB) | 大,无严格限制 |
| 安全性 | 低,明文可篡改 | 高,数据不外露 |
| 服务器压力 | 无,客户端存储 | 有,占用服务器资源 |
| 依赖关系 | 独立存在 | 依赖 Cookie 传递 SessionID |
| 生命周期 | 可长期保存(设置过期) | 默认临时,可配置超时 |
| 跨端支持 | 支持 APP、小程序、爬虫 | 依赖客户端携带 ID |
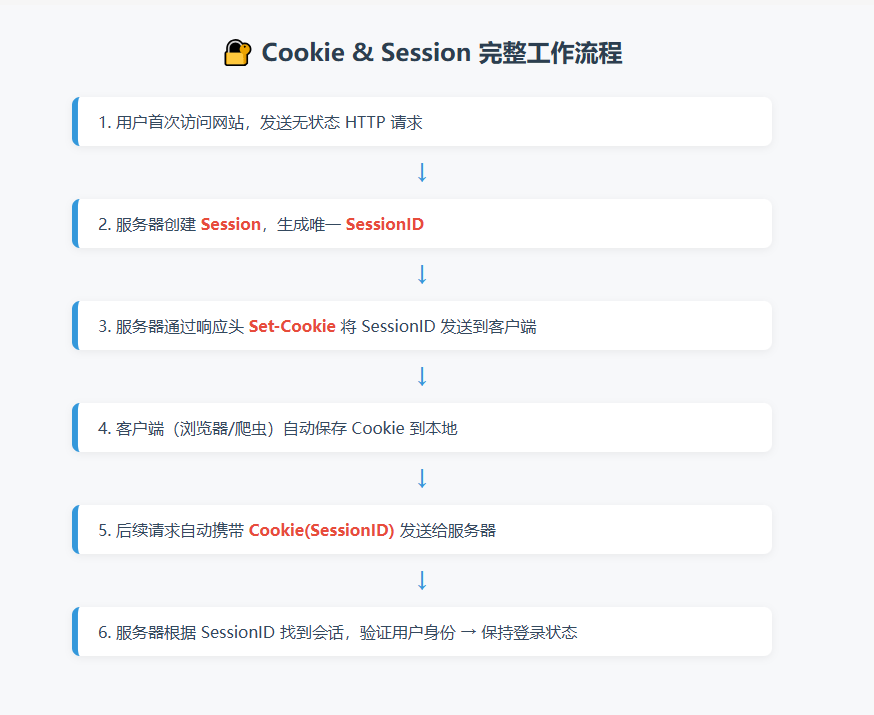
1.5 会话完整工作流程
- 用户首次访问网站,服务器创建 Session,生成唯一
SessionID - 服务器通过
Set-Cookie响应头将SessionID发送给客户端 - 客户端存储 Cookie,后续请求自动携带
- 服务器根据
SessionID找到对应会话,识别用户身份 - 登录成功后,服务器在 Session 中标记用户为已登录
- 用户退出或超时,服务器销毁 Session,Cookie 失效
二、爬虫中 Cookie 的作用
在爬虫场景下,Cookie 是维持身份的核心凭证,主要作用包括:
-
保持登录状态
登录接口验证成功后,服务器返回登录 Cookie,后续请求携带该 Cookie 即可访问会员页面、个人中心、订单数据等需要权限的内容。
-
绕过简单反爬
部分网站校验请求头中是否存在 Cookie,无 Cookie 直接返回 403/跳转首页。
-
记录用户偏好
如主题模式、语言设置、分页数量、地域信息等。
-
维持动态会话
验证码、表单令牌、csrf_token 等常与 Cookie 绑定。
-
避免重复登录
批量爬取时无需每次重新登录,复用有效 Cookie 提升效率。
三、Requests 库 Cookie 操作基础
Python requests 库内置完善的 Cookie 管理机制,支持自动保存、手动携带、格式转换、查看等操作。
3.1 安装 Requests
bash
pip install requests3.2 方式一:自动获取与携带 Cookie
requests.get()/post() 会自动保存响应中的 Cookie,并在后续同域名请求中自动携带。
python
import requests
# 第一次请求:服务器返回 Set-Cookie
url = "https://www.baidu.com"
resp1 = requests.get(url)
# 查看响应中的 Cookie
print("响应 Cookie:", resp1.cookies)
# 第二次请求:自动携带上一次的 Cookie
resp2 = requests.get(url)3.3 方式二:手动构造 Cookie 字典
适用于已知有效 Cookie,直接携带访问。
python
import requests
# 手动构造 Cookie
cookies = {
"username": "test",
"token": "abc123xyz",
"sessionid": "sess_98765"
}
url = "https://example.com/user/profile"
resp = requests.get(url, cookies=cookies)
print(resp.status_code)
print(resp.text[:500])3.4 方式三:CookieJar 转字典
resp.cookies 是 RequestsCookieJar 对象,不方便查看与修改,可通过工具函数转为字典。
python
import requests
url = "https://www.baidu.com"
resp = requests.get(url)
# 转为字典
cookie_dict = requests.utils.dict_from_cookiejar(resp.cookies)
print("Cookie 字典:", cookie_dict)
# 字典转回 CookieJar
cookie_jar = requests.utils.cookiejar_from_dict(cookie_dict)3.5 从响应头解析 Set-Cookie
服务器通过 Set-Cookie 头设置 Cookie,可直接从响应头提取。
python
import requests
url = "https://example.com/login"
data = {"username": "user", "password": "123456"}
resp = requests.post(url, data=data)
# 获取所有 Set-Cookie
set_cookie = resp.headers.get("Set-Cookie")
print("Set-Cookie:", set_cookie)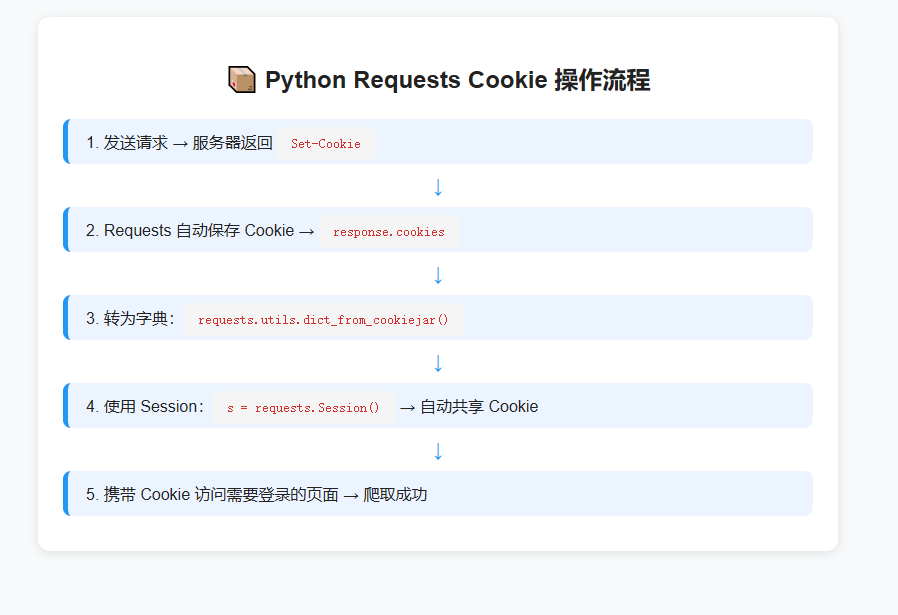
四、Session 对象:自动维持连续会话
4.1 Session 作用
requests.Session() 创建一个会话对象 ,该对象会自动管理 Cookie,所有通过该对象发送的请求共享同一套 Cookie,模拟浏览器连续操作。
4.2 Session 基础用法
python
import requests
# 创建会话
s = requests.Session()
# 登录请求:获取 Cookie
login_url = "https://example.com/login"
login_data = {
"username": "test_user",
"password": "test_pwd"
}
s.post(login_data, data=login_data)
# 后续请求自动携带登录 Cookie
profile_url = "https://example.com/user/info"
resp = s.get(profile_url)
print(resp.text)4.3 Session 优势对比
- 不使用 Session:每次请求独立,Cookie 不共享,登录后立即失效。
- 使用 Session:Cookie 自动持久化,模拟真实浏览器行为,支持连续操作(登录→浏览→退出)。
五、实战一:模拟登录并爬取会员页面
5.1 场景说明
目标:登录某测试网站 → 获取登录 Cookie → 访问个人中心页面 → 提取用户信息。
5.2 完整代码
python
import requests
from fake_useragent import UserAgent
def login_and_crawl():
# 初始化会话
s = requests.Session()
ua = UserAgent()
headers = {
"User-Agent": ua.random,
"Referer": "https://example.com/login"
}
# 1. 登录接口
login_url = "https://example.com/api/login"
login_form = {
"account": "your_username",
"password": "your_password",
"remember": "1"
}
# 发送登录请求
login_resp = s.post(login_url, data=login_form, headers=headers)
print("登录状态码:", login_resp.status_code)
print("登录返回:", login_resp.json())
# 2. 访问需要登录的个人中心
profile_url = "https://example.com/user/profile"
profile_resp = s.get(profile_url, headers=headers)
if profile_resp.status_code == 200:
print("成功访问个人中心")
print("页面内容预览:", profile_resp.text[:1000])
else:
print("访问失败,可能未登录")
if __name__ == "__main__":
login_and_crawl()5.3 关键说明
- 使用
Session确保登录 Cookie 被保存 - 带上
User-Agent、Referer模拟浏览器 - 登录成功后再请求权限页面
- 若网站使用 JSON 接口,可使用
resp.json()解析
六、实战二:Session 连续操作(登录→个人中心→退出)
6.1 场景
模拟完整用户行为:
登录 → 获取个人信息 → 查看订单 → 退出登录 → 验证是否退出成功
6.2 代码实现
python
import requests
def session_flow():
s = requests.Session()
headers = {"User-Agent": "Mozilla/5.0"}
# 1. 登录
login_url = "https://example.com/login"
s.post(login_url, data={
"username": "user1",
"pwd": "123456"
}, headers=headers)
# 2. 个人中心
info = s.get("https://example.com/user/info", headers=headers)
print("个人中心状态:", info.status_code)
# 3. 订单页
order = s.get("https://example.com/user/order", headers=headers)
print("订单页状态:", order.status_code)
# 4. 退出登录
logout = s.get("https://example.com/logout", headers=headers)
print("退出状态:", logout.status_code)
# 5. 验证是否已退出
check = s.get("https://example.com/user/info", headers=headers)
if "登录" in check.text:
print("已成功退出,会话失效")
if __name__ == "__main__":
session_flow()七、实战三:手动解析 Set-Cookie 并设置过期时间
7.1 场景
从响应头提取 Set-Cookie,解析名称、值、过期时间,手动构造 Cookie 并设置自定义过期时间。
7.2 代码
python
import requests
from http.cookies import SimpleCookie
def parse_set_cookie():
url = "https://example.com"
resp = requests.get(url)
# 获取 Set-Cookie
set_cookie_str = resp.headers.get("Set-Cookie", "")
print("原始 Set-Cookie:", set_cookie_str)
# 解析 Cookie
cookie = SimpleCookie()
cookie.load(set_cookie_str)
# 遍历解析结果
cookies = {}
for key, morsel in cookie.items():
cookies[key] = morsel.value
print(f"Key: {key}, Value: {morsel.value}, Expires: {morsel['expires']}")
# 手动设置过期时间(延长1天)
custom_cookies = cookies
print("手动构造带过期的 Cookie:", custom_cookies)
# 携带访问
resp2 = requests.get(url, cookies=custom_cookies)
print(resp2.status_code)
if __name__ == "__main__":
parse_set_cookie()八、常见问题与解决方案
8.1 携带 Cookie 仍登录失效
- 原因:Cookie 错误、过期、域名不匹配、缺少 HttpOnly Cookie、CSRF 校验
- 解决:抓包获取完整 Cookie、使用 Session、带上 Referer、处理 token
8.2 Set-Cookie 有多个值无法解析
- 解决:使用
SimpleCookie或requests.utils.dict_from_cookiejar
8.3 登录需要验证码
- 解决:对接打码平台、OCR 识别、模拟滑动验证
8.4 服务器禁用 Cookie
- 解决:URL 重写携带 SessionID、Token 放请求头/参数
8.5 Cookie 过期太快
- 解决:登录时勾选"记住我",延长 Cookie 有效期;定时刷新登录
九、配图说明(HTML 结构示意)
9.1 Cookie 与 Session 流程图 HTML
9.2 Requests Session 对比图 HTML

十、总结
- Cookie 存客户端,轻量不安全;Session 存服务器,安全但依赖 Cookie
- 爬虫维持登录核心:正确携带有效 Cookie
requests三种 Cookie 用法:自动保存、手动传参、CookieJar 转换- Session 对象是爬虫维持连续会话的最佳方案
- 实战场景:登录爬取、连续操作、解析 Set-Cookie、设置过期时间
- 遇到登录失效优先检查:Cookie 完整性、请求头、Session 使用、CSRF/Token
掌握本文内容后,可应对绝大多数需要登录的网站爬取需求,同时为后续处理复杂反爬(JS 加密 Cookie、Token 刷新、多账号会话池)打下基础。