中间拖动编辑,暂时性的调整,好的设计
 可以撤回的误触远比需要记忆检索的多键要实用
可以撤回的误触远比需要记忆检索的多键要实用
如果系统提供了极其便捷的撤回(Undo)或容错机制,用户可以更放心地进行模糊操作,从而在宏观上提高效率。
身体本能 vs. 逻辑判断:误触通常是身体灵敏度高于大脑判断的表现。如果误触是可以低成本修复的(例如按下 Esc 或是快捷撤回),那么"身体跑在大脑前面"带来的红利,往往高于为了避免误触而强迫大脑记忆 50 个复杂键位。
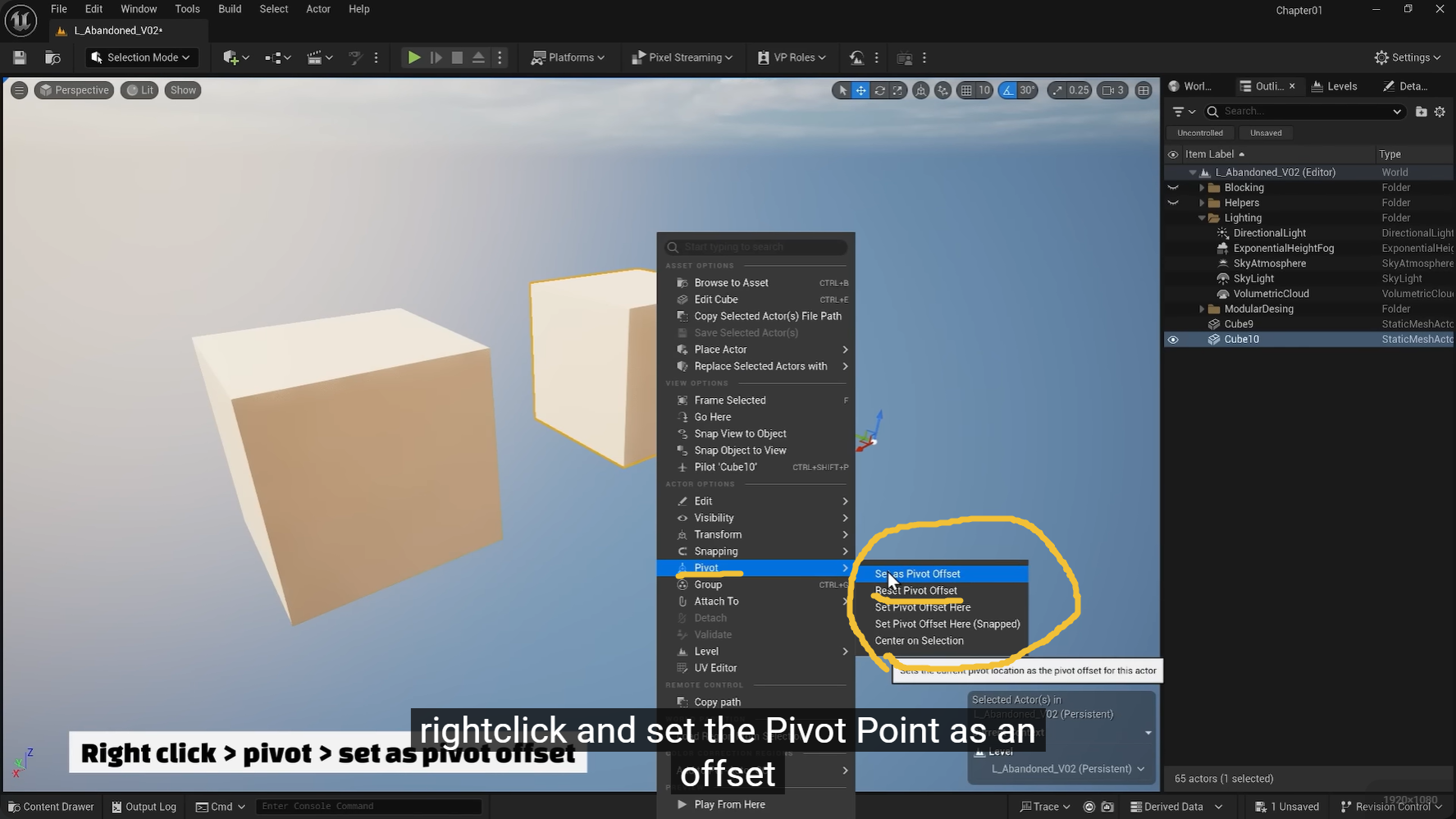
这里也可以长久设计,但同样有一个reset pivot
早期主流 3D 软件(如 Maya )就将 V 键定为顶点吸附的快捷键。UE 在开发过程中沿用了许多数字内容创作(DCC)软件的习惯,以降低美术人员的学习成本。
V 是 Vertex(顶点)的首字母,这种直观的缩写非常符合快捷键的设定逻辑,便于记忆。
Alt + 鼠标中键 可以临时移动 Pivot,此时按住 V 就能精准吸附到某个顶点上。
永久保存 :调整完后,右键点击模型选择 Pivot > Set as Pivot Offset 即可保存该位置。
使用控制台命令(进阶性能分析)
按下键盘上的 ` 键(波浪线 Tab 上方),输入以下命令:
stat fps:显示基础的帧率和毫秒数。stat unit:更推荐此命令。它会详细列出总时长(Frame)、游戏逻辑耗时(Game)、渲染线程耗时(Draw)和 GPU 耗时,帮助你判断性能瓶颈在哪一部分。stat none:关闭所有性能统计显示。
- Edit(编辑) > Editor Preferences(编辑器偏好设置)。
- 搜索 "Performance"(性能)。
- 勾选 "Show Frame Rate and Memory"(显示帧率和内存)。开启后,信息会出现在编辑器最右上角(最小化/关闭按钮附近)。
这是最常见的原因。如果开启了垂直同步,引擎会将帧率锁定在显示器的刷新率(通常是 60Hz),即 16.66ms。
在控制台(~ 键)输入 r.VSync 0 来关闭它。
笔记本电脑电池模式 (Power Saving)
如果你使用的是笔记本电脑且未插电源,UE 编辑器为了省电,会默认将帧率硬性限制在 60 FPS。
- 解决方法 :插上电源,或者在控制台输入命令:
r.DontLimitOnBattery 1
Project Settings 窗口中搜索 VSync 是找不到任何开关的。
- 原因:Epic 认为 VSync 应该由最终玩家在游戏的"画面设置"菜单中决定,或者由开发者通过命令动态控制,而不是在编辑器里一键锁死。
不在
Project Settings(项目设置) 面板中。
- 路径 :
Project Settings>Engine>General Settings>Framerate。 - Use Fixed Frame Rate:如果勾选了这个,FPS 会被强行锁定在设定的数值上(比如 60)。
- Smooth Frame Rate:如果开启,引擎会把帧率限制在一个范围内(通常上限是 62),也会导致你看起来像被锁帧了。
因为
VSync(垂直同步) 的本质是用户侧的硬件匹配,而不是游戏本身的内容
每个玩家的显示器刷新率不同(60Hz, 144Hz, 240Hz)。如果开发者在项目设置里"锁死"了开关,高刷显示器的玩家就无法发挥硬件性能
或者低端机玩家会遇到严重的输入延迟。
- 开启 VSync :画面不撕裂,但会有明显的操作延迟(Input Lag),竞技类游戏玩家通常极其反感。
- 关闭 VSync :响应极快,但画面会出现横向撕裂。
这种"手感 vs 画质"的选择权,在游戏行业惯例中是必须交给玩家的。
- 在编辑器(Editor)里开发时,可能需要关闭 VSync 来测试极限性能;但打包成游戏后,默认开启 VSync 能提供更平滑的视觉演示。UE 将其设计为动态命令,就是为了让你可以根据场景(菜单界面 vs 关卡内)随时切换。
Ctrl (Control) ------ "控制"与"动作"
语义核心:执行命令。
- 本意:Control 代表"控制键",最早用于向终端发送"控制码"(如换行、撤销)。
- 软件逻辑 :它通常用于对数据内容进行直接操作或下达全局指令。
- 经典示例 :
Ctrl + C / V:拷贝/粘贴数据。Ctrl + S:保存当前文档。Ctrl + Z:撤销上一步操作。
- UI 原则 :在 Microsoft 交互指南 中,Ctrl 键被分配给具有"大规模影响"的动作。
Alternate 意为"交替、替代"。它通过"换挡"来改变其他按键或鼠标点击的原本含义。
- 软件逻辑 :它常用于导航界面 、访问菜单 或作为临时修正符。
- 经典示例 :
Alt + Tab:在窗口间切换(交替视图)。Alt + F4:关闭应用程序(不同于 Ctrl 的内容级关闭)。Alt + 鼠标点击:在 3D 软件中通常从"选中"状态切换为"减选"状态。
- UI 原则:Alt 常用于激活界面的"加速键"(如按下 Alt 显示菜单下划线字母),用于界面导航而非直接修改数据。
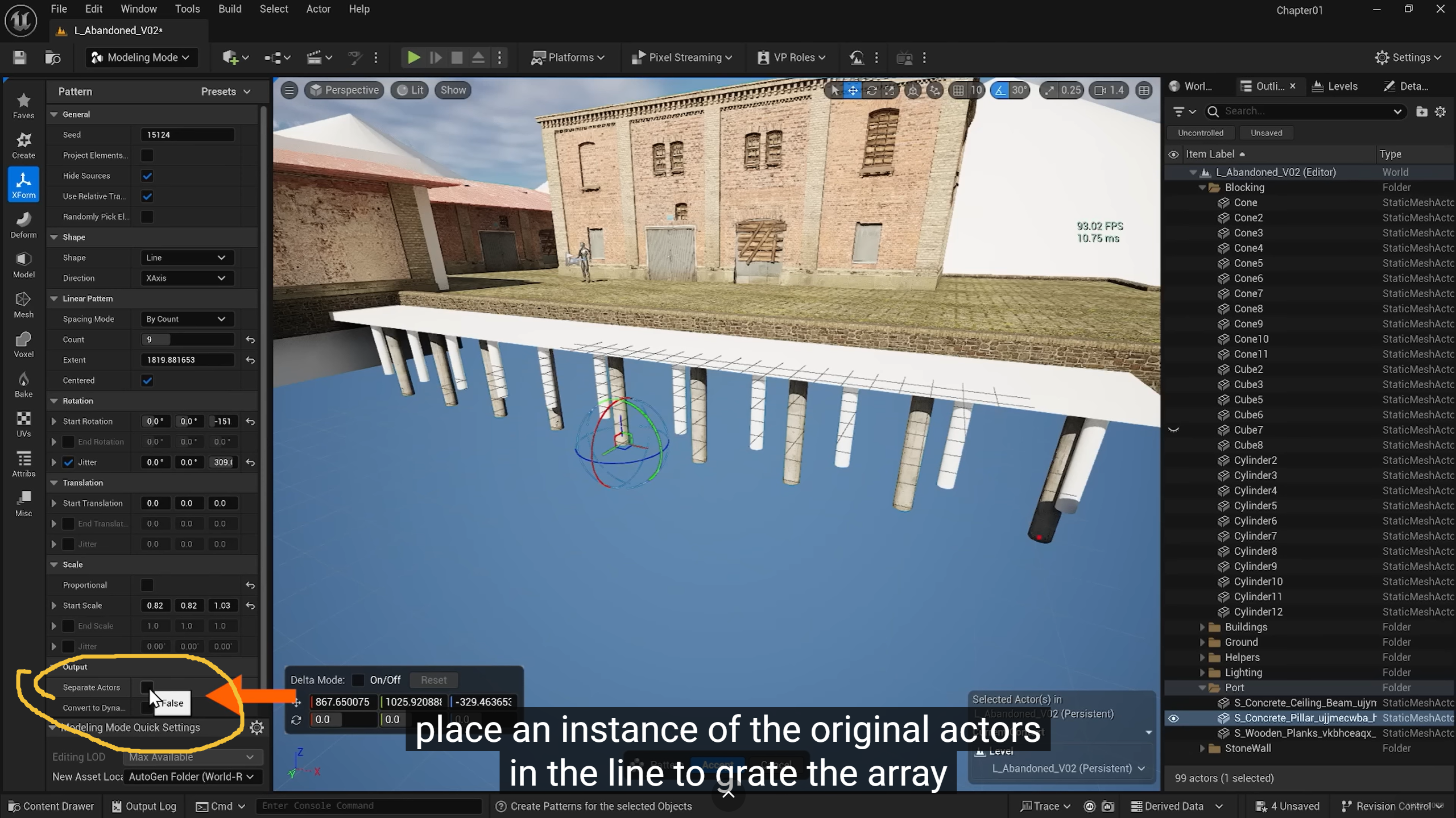
这个选项默认是不勾选,因为目的是让你产生新的模型,如果勾选了就是在场景里复制使用而已,不会增加新模型,(无论是output separate actors 还是默认不选,都不会修改原资产)
决定了它是修改资产还是操作场景中的物体(Actor)。
勾选了 Separate Actors (True)默认不勾选:
- 做法: 它不会创建一个包含多根柱子的巨型新模型,而是直接在场景里生成一堆独立的 Static Mesh Actor。
产影响: 这些生成的柱子依然引用你原来的那根"柱子资产"。它只是在场景里帮你自动摆放了位置。
可逆性: 非常安全。你如果不满意,直接在场景(Outliner)里删掉多出来的柱子就行,原资产完全没变。
如果不勾选 (False):
- 做法: 建模工具会把这一排柱子合并成一个整体,生成一个新的 Static Mesh 资产。
- 资产影响: 会在你的文件夹里多出一个名为
SM_Pattern_...之类的模型。 - 可逆性: 原资产依然没变,但你以后想单独移动其中一根柱子就会很麻烦,因为它们已经黏在一起变成一个资产了。
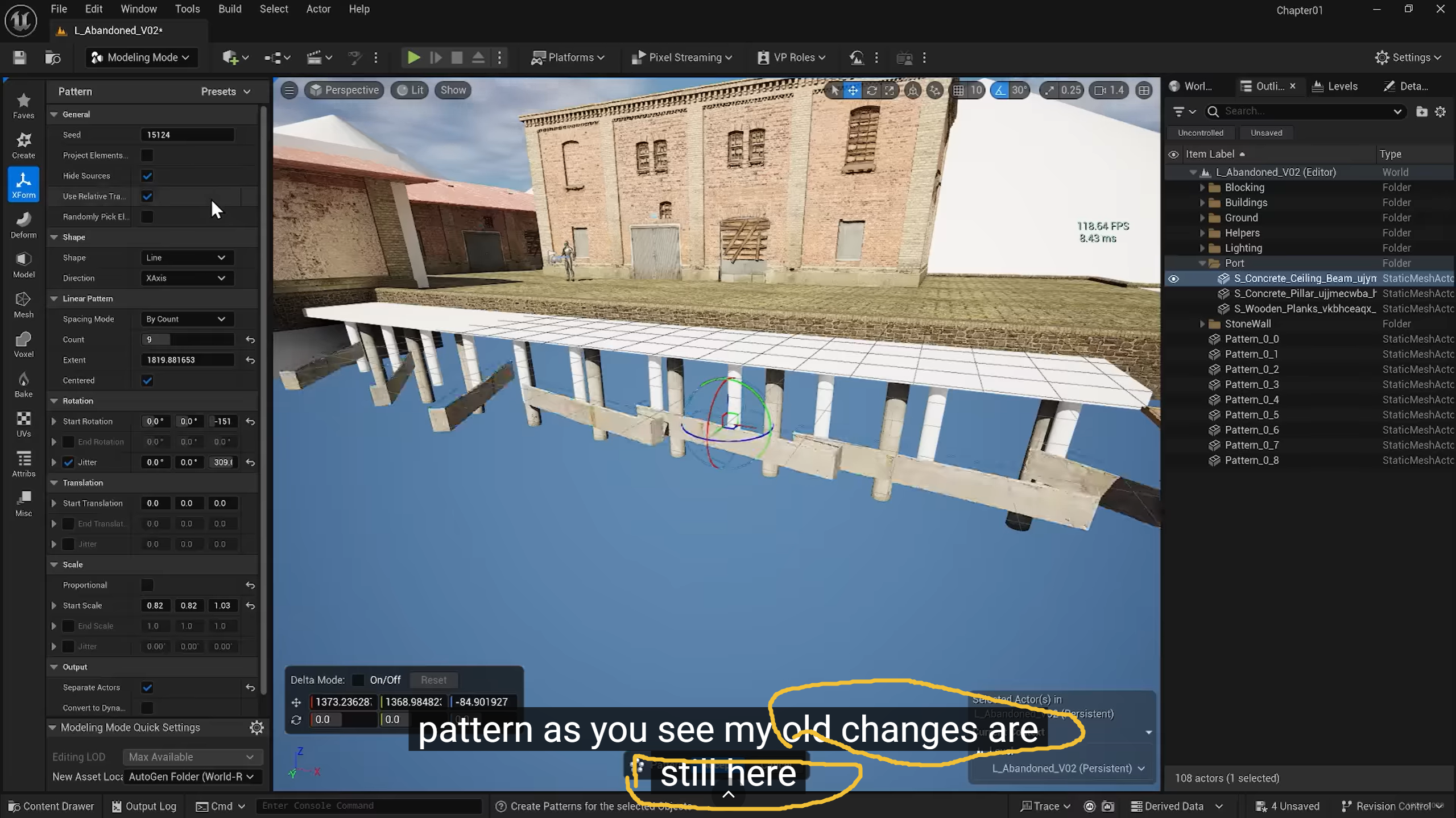
ue modelling下生成的separate actors 依然是当做不同的个体,需要转成Instanced Static Mesh (ISM)
使用separate actor性能上更好,因为使用的是同一个实例,即使是剔除也会更加容易,如果生成一个大mesh,
Unreal 中,真正兼顾"性能极好"和"引用原资产"的技术叫做 ISM (Instanced Static Mesh):
- 它依然只引用一个原资产(省显存)。
- 它能通过 1 次 Draw Call 同时渲染成千上万个实例(省 CPU)。
- 注意: 建模模式的
Separate Actors通常生成的是普通的 Static Mesh Actor。如果你追求极致性能,建议在生成后,将这些柱子选中,并++使用 Merge Actors 工具中的 Batch(批处理) 选项将它们转换为 ISM 或 HISM。++
为什么"整面墙"有时更高效?
- 1 次 Draw Call: 显卡一次性画完一整面墙,CPU 几乎不费力。
- 遮挡剔除 (Occlusion Culling): 引擎是以 Actor 为单位判断"这个东西在不在屏幕里"的。
- 全是砖: 引擎要计算 1000 次"这块砖看得到吗?"。
- 整面墙: 引擎只计算 1 次"这面墙看得到吗?"。
最高效的方案通常是:
- 做一个 3x3 米的墙面模块(包含了几十块砖的纹理)。
- 在场景中重复拼凑这个 3 米宽的模块。
- 使用 Instanced Static Mesh (ISM): 告诉引擎,这 100 个模块其实是一个东西,请用 1 个指令画出来。
"会卡死 CPU"是指当你盲目地、无限制地使用独立 Actor 堆砌细节时,会触碰到 CPU 处理对象数量的上限。
ISM: CPU 只发送 1 个渲染指令 (如 DrawIndexedPrimitiveInstanced ),随指令附带那份包含 1000 个坐标的列表。
当 GPU 收到这 1 条指令和 1000 个坐标后:
- 顶点着色器(Vertex Shader) 会被触发。
- 它会根据
InstanceID(实例编号)从坐标列表中读取对应的位置信息。 - GPU 在其内部循环 1000 次,每次都使用同一个"母本"网格数据,但在不同的位置画出来。
- 结果: 对 CPU 来说,它只干了 1 份活;对显卡来说,它避免了反复切换渲染状态的开销。
- ++GPU Instancing (图形学术语): 是一种绘图技术,允许 CPU 只调用一次渲染命令(Draw Call),就让 GPU 使用同一个网格数据(Mesh Data)在不同的位置绘制多个副本。++
- ISM (虚幻引擎术语): 是虚幻引擎封装好的一个组件(Component),专门用来驱动 GPU 的 Instancing 功能。
顶点缓冲区 (Vertex Buffer):
实例缓冲区 (Instance Buffer):
更高级的版本:HISM (Hierarchical Instanced Static Mesh)。
PU Instancing 的基础上增加了 LOD(多细节层次) 和 分块剔除(Culling)。
- 几万棵树,离你远的树会自动切换到低模,而且不在镜头里的树会被剔除,这比原始的 GPU Instancing 还要高效。
CPU 端剔除:以 Actor 为单位
-
逻辑 :CPU 检查这个 Actor 的包围盒(Bounds)是否在镜头内。
-
结果 :只要这 1000 根柱子中,有哪怕一根还在你的屏幕边缘,CPU 就会判定这个 Actor "可见"。
-
后果 :CPU 会把这 1000 个实例的所有坐标数据全部提交给 GPU。
-
浪费 :即便你背对着其中 999 根柱子,只要你盯着第 1 根,GPU 依然会在硬件底层处理这 1000 个实例的顶点计算。虽然硬件实例化很快,但在实例数量达到数万个时,这种"无效渲染"会显著浪费 GPU 性能。
如何解决?------ 引入 HISM (Hierarchical ISM)
为了解决你发现的这个"全进全出"问题,UE 提供了 HISM:
- 分层剔除 (Cluster Culling):HISM 不再把 1000 个实例看作一个整体。它会在内部把这 1000 个实例分成多个"小簇"(Clusters)。
- 局部剔除 :如果左边的 500 根柱子在镜头外,CPU 会直接把这 500 个实例的数据剔除掉,不发给 GPU。
- LOD 支持:HISM 允许远处的实例显示低模,近处的显示高模。而普通的 ISM 只能全高或全低。
HISM 的分层剔除(Culling)和 LOD 切换逻辑确实是跑在 CPU
点击 Accept 生成 HISM 时,CPU 会在后台构建一个 BVH(层次包围盒)树。它把这 1000 根柱子按照空间位置分组成多个"簇"(Clusters)。
- 视图锥体剔除 (Frustum Culling): CPU 检查 BVH 树的各个分支。如果某个"簇"完全在镜头之外,CPU 就会直接丢弃该分支下的所有实例数据。
- LOD 计算: CPU 计算相机到每个"簇"中心的距离,决定这个簇里的实例应该使用哪个 LOD(多细节层次) 级别。
- 结果提交: CPU 只把通过了剔除测试、且处于相同 LOD 等级的实例坐标(Transform)打包,作为 Instance Buffer 提交给 GPU。
- 普通 ISM: CPU 很懒,只做 Actor 级的粗略剔除。GPU 很累,经常要画镜头外的物体。
- HISM: CPU 很勤快(跑分层逻辑),GPU 很轻松(只画看到的、适合精细度的物体)。
由于 HISM 的这些逻辑(剔除、LOD 计算)是运行在 CPU 上的,所以如果你的实例数量多到变态(比如几百万个),HISM 的 CPU 计算开销本身也会变成瓶颈。
技术演进的角度看,
Nanite 确实正在取代 HISM 的绝大部分应用场景,
Nanite 的设计初衷就是为了解决 HISM 的痛点:
- 剔除精度: HISM 的剔除是 CPU 端的粗粒度剔除 (按实例簇)。Nanite 是 GPU 端的像素级/簇级剔除,能精确到三角形,遮挡剔除效率远超 HISM。
- LOD 切换: HISM 在切换 LOD 时会有明显的"跳变"(Popping),需要 CPU 计算距离。Nanite 是连续的、无缝的流式细节缩放,完全不占用 CPU 资源。
- 绘制调用 (Draw Calls): 虽然 HISM 优化了 Draw Call,但 Nanite 通过 可编程光栅化 (Programmable Rasterization) 和自动合批,将成千上万个不同物体的渲染压力几乎降为零。
尽管 Nanite 很强,但在以下情况你可能仍会看到 HISM:
- 非 Nanite 平台: 在一些移动端(低端 Android/iOS)或旧世代主机上,Nanite 无法运行,HISM 依然是海量植被渲染的唯一选择。
虽然 Nanite 已经支持了半透明和遮罩(Masked)材质,但在处理极高性能敏感的超大面积草地时,一些开发者仍会习惯性地对比 HISM 的性能表现。
在 UE5 纯原生开发(特别是中大型项目)中:
- 植被 (Foliage): 官方已经建议全面转向 Nanite Foliage。
- 建筑/重复物件: 就像你图中的柱子,只要开启了 Nanite,你甚至不需要手动去转 ISM/HISM,引擎在底层会自动处理这种实例化引用 。
它是如何"自动"的?
当 Nanite 渲染器扫描场景时:
- 识别相同资源 :它会发现这 1000 个 Actor 引用的是同一个 Nanite Mesh 资产。
- 显存共享:它只在显存里存一份该资产的几何数据(Clusters)。
- 绘制调用压缩 :Nanite 会在 GPU 端 自动将这些具有相同材质和网格的实例聚合成一个极小的批次进行处理。
- 结果 :即使你在大纲视图(Outliner)里看到的是 1000 个独立的 Actor,它们在渲染层级的开销已经接近于 1 个 Draw Call。
为什么这比手动转 ISM 更好用?
- 保持灵活性:你可以保留 1000 个独立的 Actor,每一根柱子都可以有自己的逻辑、物理碰撞、甚至是不同的缩放。你不需要为了性能强行把它们"捆绑"在一个 ISM 组件里。
- 不再纠结"合批":你只管像搭积木一样盖房子,优化工作交给 Nanite 渲染器。
虽然 Nanite 很强,但 ISM/HISM 在以下场景依然有不可替代的优势:
- 海量物件的数据管理 :如果你要种 100 万棵草,存 100 万个 Actor 本身就会让你的电脑内存(RAM)爆掉。这时候必须用 ISM/HISM,因为它们只存 100 万个坐标点(数据极轻),而不是 100 万个完整的 Actor 对象。
- 非 Nanite 平台:如果你要发布到移动端或 Switch,由于不支持 Nanite,你必须退回到 ISM 手动优化。
Packed Level Instance (PLI) 底层正是通过蓝图类 (Blueprint Class) 实现的,但它的核心价值在于关卡编辑流(Workflow)和自动性能优化。
手动创建一个蓝图,在里面手动添加 100 个 Static Mesh 组件:
- 编辑极其痛苦: 你在蓝图视口里摆放家具、对齐墙角非常不直观。
- 性能需要手动调: 你得手动把组件改成 ISM/HISM 才能合批。
- 不支持嵌套优化: 蓝图很难像关卡一样进行分层流送(Level Streaming)。
PLI 的本质是: "像编辑关卡一样自由,像蓝图一样打包,像 ISM 一样高效。"
- 可视化编辑: 你直接在主场景里像搭积木一样摆放几百个独立 Actor(椅子、桌子、灯),然后一键"打包"。
- 自动合批: 当你点击****Create Packed Level Instance** 时,UE 会自动创建一个蓝图** 。这个蓝图内部自动 将所有相同的静态网格体转换成 ISM/HISM。
- 资源引用: 它生成的
.uasset实际上就是一个包含优化组件的特殊蓝图****。
两者的分工(现状)
| 维度 | 蓝图 (Blueprint) | Packed Level Instance (PLI) |
|---|---|---|
| 侧重点 | 逻辑控制(开关门、AI、机关)。 | 视觉表现(建筑组团、精细装修)。 |
| 编辑方式 | 在蓝图编辑器里摆组件(抽象)。 | 在视口里直接选 Actor 打包(直观)。 |
| 性能 | 默认较差,需手动优化为 ISM。 | 默认极强,自动为你做硬件实例化。 |
PLI 会成为主流的"组装方式"
在 UE5 的大世界开发中,趋势是:
- 用 Static Mesh 做最小单元。
- 用 Packed Level Instance 把单元拼成"房子"或"房间"(解决性能和复用)。
- 在 PLI 生成的蓝图里添加 逻辑代码(如果需要交互)。
所以,PLI 不会消失,它反而让蓝图变得更强大了。
Packed Level Instance (PLI) 确实可以被看作是 Sub Level(子关卡) 模式在 UE5 中的现代化升级版,它是专门为 World Partition(世界分区) 系统设计的组织方式。
pli可以直接放在map里,也就是相当于sub level的组织模式
它是如何像 Sub Level 一样工作的?
- 直接放置: 你可以把 PLI 像普通物体一样直接拖进主地图中。
- 关卡级引用: PLI 实际上引用了一个独立的
.umap文件。这意味着它本质上就是一个关卡 ,只是被包装成了一个可以在主场景中自由移动、旋转、甚至多次复制的 Actor。
按需加载: 就像旧版的子关卡一样,PLI 支持异步加载和管理。在运行或渲染时,系统会根据你的设置来决定何时将其内容"流送"进内存。
PLI 与传统 Sub Level 的核心进化
虽然逻辑相似,但 PLI 解决了传统子关卡最头疼的几个问题:
| 维度 | 传统 Sub Level (旧) | Packed Level Instance (新) |
|---|---|---|
| 复用性 | 一个关卡文件通常只能在主图里放一次。 | 同一个 PLI 文件可以在主图里无限次重复放置。 |
| 编辑流 | 必须切换当前关卡才能编辑。 | 支持 In-Context Editing,直接在主图中双击即可进入编辑状态,其他物体变灰。 |
| 渲染性能 | 子关卡里的物体各算各的,容易 Draw Call 过高。 | 只要勾选 Packed 模式,它会自动把内部相同的 Static Mesh 合并为 ISM/HISM 渲染。 |
| 管理模式 | 依赖 Layers 或手动加载。 | 完美适配 World Partition 的流送网格(Streaming Grids)。 |
应用建议
- 中大型模块: 比如你搭了一座精修过的"楼房"或"房间",把它做成 PLI 放在主图里,是最科学的组织方式。
- 替代 Blueprint Prefab: 相比于把几百个物体塞进一个蓝图,PLI 在编辑效率(直接在场景里摆)和内存管理上都更优越。
a level is a container for actors

Color+Line=Nature 成立,必须对算子"+"以及操作数进行本体论层面的重定义。
禁止将"线"理解为欧几里得几何中的一维轨迹,而应将其定义为德勒兹(Gilles Deleuze)意义上的**"逃逸线"(Line of flight)**或动态向量。
重构逻辑: 线不再是边界,而是自然中强度的梯度(Intensity gradient)。
等式转换: 当"线"代表能量流动的矢量,它便承载了自然的生成属性。
将"颜色"重定义为"强度"与"频率"(Phenomenology of Perception)
颜色不是覆盖在物体表面的属性,而是自然表现自身的振荡频率。
画作与主题的关系并非"容器与内容"
而是**"涌现与结构"**
在画布动笔之前,它并非"空白",而是被无数现成的意象、文化陈规(主题)所占据。创作的过程并非"传达"这些已知主题,而是通过**"图表"(Diagram)**------即由线条和颜色构成的非代表性区域------去摧毁这些陈规。
https://opencv.org/releases/
OpenCV(Open Source Computer Vision Library)是一个开源的跨平台计算机视觉和机器学习软件库,专注于实时图像处理、分析以及模式识别
。它由英特尔公司发起,采用 BSD 协议,可免费用于商业和科研,支持 C++、Python、Java 等多种语言。
计算机视觉算法: 提供超过 2,500 种优化算法,用于人脸识别、物体检测、三维重建和相机标定。
- 高性能: 使用 C/C++ 编写,支持 GPU 加速(CUDA/OpenCL),适用于实时应用。
- 跨平台: 运行在 Windows、Linux、macOS、Android 和 iOS 上。
OpenCV 被广泛应用于安防监控、自动驾驶、医学图像分析、机器人技术以及工业自动化等领域。
推荐方案:Python + MediaPipe → UDP → UE5
原因:
- MediaPipe 是 Google 出的,人脸 468 个关键点,笔记本摄像头实时跑 30fps 没问题
- Python 大概 20 行代码就能跑起来
- 通过 UDP 把头部 Yaw/Pitch 发给 UE5,UE5 这边用 C++ 监听 UDP socket 接收,非常稳定
- 完全不需要改 UE5 的构建系统,不需要链接任何第三方库
MediaPipe 是 Google 开源的、跨平台的多媒体机器学习(ML)框架,专为实时处理视频、音频和传感器数据而设计
。它允许开发者在移动端(Android/iOS)、Web、桌面和嵌入式设备上快速构建和部署计算机视觉应用,如手势控制、人脸检测和人体姿态追踪。
虚幻引擎 (Unreal Engine, UE) 的开发场景中,MediaPipe 确实是目前在"笔记本摄像头"这一硬件限制下实现人脸捕捉的 最优解。
以下是针对 Live Link、OpenCV 与 MediaPipe 在 UE 中表现的深度对比:
- 为什么 Live Link (官方原生) 在笔记本上表现不佳?
- 硬件锁定 :Epic 官方的 Live Link Face App 是专为 iPhone (具有 TrueDepth 摄像头) 设计的。它依赖苹果的 ARKit 硬件级深度感知,而笔记本摄像头只有普通的 2D 画面,无法直接触发原生的 ARKit 数据流。
- 协议屏障:虽然 UE 5.6 开始尝试增加对普通 WebCam 的支持,但在老版本或标准流程中,如果没有 iPhone,你必须自己写一个"桥梁"来模拟 Live Link 协议。
为什么 OpenCV 并非上策?
- 计算开销:OpenCV 只是一个视觉库,它本身不提供高精度的预训练人脸模型。如果你用 OpenCV 自带的 Haar 或 LBP 级联分类器,精度极差;如果你在 OpenCV 里跑复杂的深度学习模型,笔记本 CPU 往往会瞬间满载,导致 UE 帧率掉到个位数。
- 缺乏语义信息:OpenCV 很难直接给出 468 个带语义(如"左眼睑"、"嘴角")的关键点坐标,你需要花费大量精力去做后续的数据清洗。
MediaPipe 在 UE 里的"降维打击"优势
- 伪 Live Link 方案 :目前社区最流行的做法是:Python (MediaPipe)→**** UDP/OSC 协议
→ UE (Live Link)。- MeFaMo 或类似的开源项目 利用 MediaPipe 提取 468 个点,然后将这些点转换为苹果 ARKit 标准的 52 个混合形变 (BlendShapes) 系数。
- 这让 UE 认为信号来自 iPhone,从而直接驱动 MetaHuman,效果极其顺滑。
- 低延迟异步处理 :你可以让 MediaPipe 在后台 Python 进程中跑,通过网络协议把计算好的系数发给 UE。这样 UE 负责渲染,Python 负责计算,互不占用主线程资源,笔记本风扇也不会狂转。
:它不需要你安装复杂的 C++ 编译环境(如 dlib),直接通过 Mediapipe-Unreal 插件 就能在引擎内直接调用。
安装在 Python 主程序的目录下:
- Windows :
C:\Users\你的用户名\AppData\Local\Programs\Python\Python3x\Lib\site-packages - 如果你是通过 Python 官网下载并为所有用户安装的 :
C:\Program Files\Python3x\Lib\site-packages
VS Code 项目文件夹里创建了虚拟环境(比如文件夹叫 .venv 或 env ),那么库会安装在:
你的项目文件夹/.venv/lib/site-packages- 好处:这样不会污染全局 Python 环境,且不同项目之间的依赖库不会冲突。
先把系统路径排在前面,再把用户路径拼在后面,组成一个长长的搜索清单。
勾选了 "Install for all users" ,它通常会把自己塞进系统变量。
只是点"下一步",它默认安装在 AppData 下,
- 策:
- 手动调序 :在环境变量编辑窗口,选中你最想用的那个路径,点 "上移 (Move Up)" 到最顶端。
- 强制指定:如果不想调序,就在终端里输入具体的路径来运行,或者在 VS Code 右下角手动切换 Python 解释器。
生效的永远只有排在前面的那个。
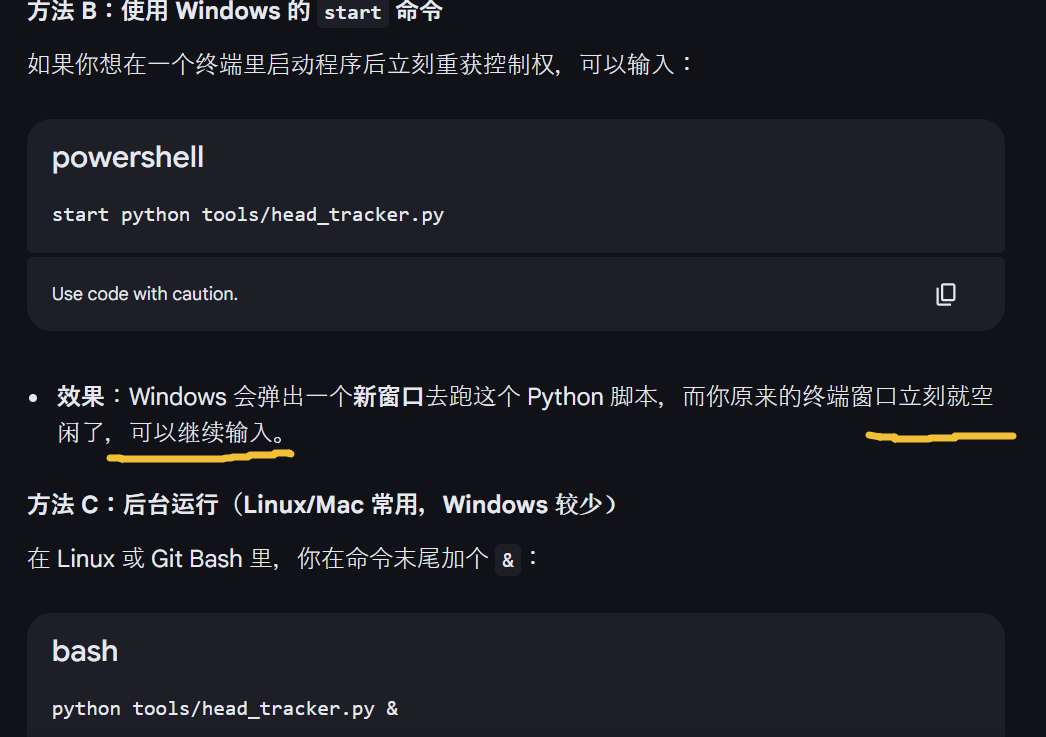
在一个标准的终端窗口(命令行)里,如果你启动了一个程序(比如 Python 脚本),它会"霸占"这个窗口的前台(Foreground),直到它运行结束,你才能输入下一个命令。
- 可以开 10 个终端,左边跑 Python 抓人脸,右边编译 UE 代码,互不干扰。
- VS Code 特色 :你可以点击 Split Terminal 按钮(分屏图标),让两个终端并排显示,一边看 Python 的坐标输出,一边看 UE 的日志。
MediaPipe 是"大脑"(负责识别),而 OpenCV 是"手和眼睛"(负责搬运图像)。
虽然 MediaPipe 的算法很强,但它自己 不具备 以下基础功能,必须借用 OpenCV 的"工具箱":
- 调用摄像头 :MediaPipe 并不直接去驱动你的笔记本摄像头硬件,它需要 OpenCV 的
cv2.VideoCapture()把画面一帧一帧地"抓"出来。 - 图像预处理 :摄像头抓到的画面通常是 BGR 格式的,而 MediaPipe 的大脑只认识 RGB。我们需要 OpenCV 做一次颜色转换。
- 实时预览窗口 :你在屏幕上看到的那个带绿点点的人脸弹窗,是 OpenCV 的
cv2.imshow()生成的。如果没有 OpenCV,MediaPipe 也能算出坐标,但你完全看不到实时画面,调试会非常痛苦。
- 如果你运行
pip install mediapipe,而你已经装了旧版本,pip通常不会 自动帮你更新到最新版(除非你加了--upgrade参数)。它会觉得"既然有了,那就不动它"。 - 如果你运行
pip install mediapipe==0.10.0(指定版本),而你装的是 0.9.0,这时pip就会动作:先卸载旧版,再安装你指定的版本。
同步 C++ 代码结构与编译器所需的工程文件。
使用其专有的 Unreal Build Tool (UBT) 来扫描项目目录。
生成 .sln 文件:为 Visual Studio 重新创建解决方案文件。
- 更新
.vcxproj文件:为每个模块生成项目文件,包含源文件列表、包含路径(Include Paths)和预处理器宏定义。
正交视图:在顶视图、侧视图等正交视图中,你可以直接使用鼠标左键拖动进行框选。
按下 Q 后,你依然需要配合 Ctrl + Alt + 左键拖动 来实现框选。
能判断"项目里有这几个角色资产",但不能判断"这个角色的右手骨骼叫 hand_r 还是 RightHand 还是别的"。