一、理论基础:RAG 系统评估体系
1.1 为什么必须做 RAG 评估?
1.1.1 原型与生产的核心差距
- 原型:只要能回答几个测试问题就算成功
- 生产:必须保证 99% 以上的场景稳定可靠,回答准确率≥90%,幻觉率≤5%
- 核心差距 :可量化、可迭代、可复现
1.1.2 RAG 失败的三大根源(按影响程度排序)
- 检索失败(占比 60%-70%):没有找到正确的信息
- 生成失败(占比 20%-30%):找到了正确的信息但没有正确使用
- 提示词失败(占比 5%-10%):提示词没有明确约束大模型的行为
1.1.3 只看 "能否回答" 的三大陷阱
- 回答正确但来源错误:大模型用自己的知识回答,而不是知识库的知识
- 回答流畅但存在幻觉:编造了知识库中没有的信息
- 简单问题能答,复杂问题全错:系统没有泛化能力
1.2 RAG 评估的三大核心维度
| 评估维度 | 评估对象 | 核心问题 | 关键指标 | 评估方法 |
|---|---|---|---|---|
| 检索质量评估 | 向量检索 + 重排序 | 有没有找到正确的信息? | Recall@k、Precision@k、F1@k、MRR | 自动评估 |
| 生成质量评估 | LLM 生成环节 | 有没有正确使用找到的信息? | 忠实度、相关性、完整性、幻觉率 | LLM 自动评估 + 人工抽样 |
| 端到端评估 | 整个 RAG 系统 | 用户是否满意? | 自然度、流畅度、响应延迟 | 人工评估 + 性能测试 |
1.3 核心评估指标详解
1.3.1 检索指标
-
Recall@k(召回率 @k)
- 定义:前 k 个检索结果中包含相关文档的比例
- 公式:
Recall@k = 检索到的相关文档数 / 总相关文档数 - 意义:衡量系统 "有没有漏掉有用信息" 的能力
- 工业级要求:Recall@3 ≥ 90%,Recall@5 ≥ 95%
-
Precision@k(精确率 @k)
- 定义:前 k 个检索结果中相关文档的比例
- 公式:
Precision@k = 检索到的相关文档数 / k - 意义:衡量系统 "有没有混入无用信息" 的能力
- 工业级要求:Precision@3 ≥ 80%
-
F1@k(F1 分数 @k)
- 定义:召回率和精确率的调和平均数
- 公式:
F1@k = 2 * (Precision@k * Recall@k) / (Precision@k + Recall@k) - 意义:综合衡量检索效果
- 工业级要求:F1@3 ≥ 85%
-
MRR(平均倒数排名)
- 定义:第一个相关文档出现位置的倒数的平均值
- 公式:
MRR = (1/n) * Σ(1/rank_i),其中 rank_i 是第 i 个查询第一个相关文档的排名 - 意义:衡量系统 "把最相关的文档排在前面" 的能力
- 工业级要求:MRR ≥ 0.8
1.3.2 生成指标
-
忠实度(Faithfulness)
- 定义:生成内容与检索上下文的一致程度
- 评分标准:0-1 分,1 分表示完全基于上下文,0 分表示完全编造
- 工业级要求:平均忠实度 ≥ 0.9
-
相关性(Relevance)
- 定义:生成内容与用户问题的相关程度
- 评分标准:0-1 分,1 分表示完全回答了问题,0 分表示完全不相关
- 工业级要求:平均相关性 ≥ 0.9
-
完整性(Completeness)
- 定义:生成内容覆盖问题要点的比例
- 评分标准:0-1 分,1 分表示覆盖了所有要点,0 分表示一个要点都没覆盖
- 工业级要求:平均完整性 ≥ 0.85
-
幻觉率(Hallucination Rate)
- 定义:生成内容中编造信息的比例
- 公式:
幻觉率 = 存在幻觉的回答数 / 总回答数 - 工业级要求:幻觉率 ≤ 5%
1.3.3 性能指标
- 平均响应时间:从用户发送请求到收到完整回答的时间,工业级要求 ≤ 3 秒
- 95 分位响应时间:95% 的请求能在该时间内完成,工业级要求 ≤ 5 秒
- 并发处理能力:系统每秒能处理的请求数(QPS)
- 资源占用:CPU、内存、GPU 的平均使用率
1.4 评估数据集构建(工业级最佳实践)
1.4.1 黄金标准数据集(Gold Dataset)
- 定义:包含 "问题 - 标准答案 - 相关文档 ID" 三元组的数据集
- 构建方法:自动生成 + 人工审核(效率和质量的最佳平衡)
- 规模:至少 100 个问题,覆盖系统的主要使用场景
1.4.2 自动生成评估数据集
- 从知识库中随机抽取 N 个文档分块
- 用大模型基于每个分块生成 3-5 个问题和对应的标准答案
- 记录每个问题对应的相关文档 ID
- 人工审核并修正错误的问题和答案
1.4.3 评估数据集格式
[
{
"question": "RAG技术是什么时候提出的?",
"gold_answer": "2020年由Facebook AI研究院提出",
"relevant_chunk_ids": ["rag_guide_md_0"]
},
{
"question": "RAG的工作流程分为哪几个步骤?",
"gold_answer": "RAG的工作流程分为三个核心步骤:1. 文档处理;2. 检索;3. 生成",
"relevant_chunk_ids": ["rag_guide_md_1"]
}
]二、检索与生成质量自动评估
2.1 第一步:构建第一个 RAG 评估数据集
代码位置 :core/rag_evaluator.py
python
import json
import random
from typing import List, Dict
from pathlib import Path
from langchain_core.documents import Document
from core.rag_retriever import RAGRetriever
from core.llm_factory import LLMFactory
from config.settings import settings
from utils.logger import logger
class RAGEvaluator:
"""RAG系统评估器"""
def __init__(self, retriever: RAGRetriever = None):
self.retriever = retriever or RAGRetriever()
self.llm = LLMFactory.get_llm()
self.dataset_path = Path("./data/evaluation_dataset.json")
def generate_evaluation_dataset(self, num_samples: int = 100) -> List[Dict]:
"""自动生成评估数据集"""
logger.info(f"正在生成评估数据集,样本数:{num_samples}")
# 获取所有文档分块
all_chunks = self.retriever.vector_store.get()["documents"]
all_ids = self.retriever.vector_store.get()["ids"]
# 随机抽取样本
samples = random.sample(list(zip(all_ids, all_chunks)), min(num_samples, len(all_chunks)))
dataset = []
for chunk_id, chunk_content in samples:
# 基于分块生成问题和答案
prompt = f"""
基于以下文档内容,生成3个不同的问题和对应的标准答案。
要求:
1. 问题要清晰、具体、有意义
2. 答案必须完全来自文档内容
3. 输出格式为JSON数组,每个元素包含"question"和"answer"字段
4. 只输出JSON,不要添加任何其他内容
文档内容:
{chunk_content}
"""
try:
response = self.llm.invoke(prompt)
qa_pairs = json.loads(response.content)
for qa in qa_pairs:
dataset.append({
"question": qa["question"],
"gold_answer": qa["answer"],
"relevant_chunk_ids": [chunk_id]
})
except Exception as e:
logger.warning(f"生成问题失败:{e}")
continue
# 保存数据集
with open(self.dataset_path, "w", encoding="utf-8") as f:
json.dump(dataset, f, ensure_ascii=False, indent=2)
logger.info(f"评估数据集生成完成,共{len(dataset)}个样本")
return dataset
def load_evaluation_dataset(self) -> List[Dict]:
"""加载评估数据集"""
if not self.dataset_path.exists():
logger.info("评估数据集不存在,正在自动生成...")
return self.generate_evaluation_dataset()
with open(self.dataset_path, "r", encoding="utf-8") as f:
return json.load(f)2.2 第二步:检索质量自动评估
python
# 在RAGEvaluator类中添加以下方法
def evaluate_retrieval(self, k_list: List[int] = [1, 3, 5]) -> Dict:
"""评估检索质量"""
dataset = self.load_evaluation_dataset()
logger.info(f"开始检索质量评估,共{len(dataset)}个样本")
results = {}
for k in k_list:
total_recall = 0
total_precision = 0
total_mrr = 0
valid_samples = 0
for sample in dataset:
question = sample["question"]
gold_ids = set(sample["relevant_chunk_ids"])
try:
# 检索前k个结果
retrieved_docs = self.retriever.retrieve(question, top_k=k)
retrieved_ids = set([doc.metadata["chunk_id"] for doc in retrieved_docs])
# 计算召回率
recall = len(retrieved_ids & gold_ids) / len(gold_ids)
total_recall += recall
# 计算精确率
precision = len(retrieved_ids & gold_ids) / k
total_precision += precision
# 计算MRR
mrr = 0
for i, doc in enumerate(retrieved_docs):
if doc.metadata["chunk_id"] in gold_ids:
mrr = 1 / (i + 1)
break
total_mrr += mrr
valid_samples += 1
except Exception as e:
logger.warning(f"评估样本失败:{e}")
continue
if valid_samples == 0:
continue
# 计算平均值
avg_recall = total_recall / valid_samples
avg_precision = total_precision / valid_samples
avg_mrr = total_mrr / valid_samples
avg_f1 = 2 * (avg_precision * avg_recall) / (avg_precision + avg_recall) if (avg_precision + avg_recall) > 0 else 0
results[f"k={k}"] = {
"recall": round(avg_recall, 4),
"precision": round(avg_precision, 4),
"f1": round(avg_f1, 4),
"mrr": round(avg_mrr, 4)
}
logger.info("检索质量评估完成")
for k, metrics in results.items():
logger.info(f"{k}: Recall={metrics['recall']}, Precision={metrics['precision']}, F1={metrics['f1']}, MRR={metrics['mrr']}")
return results2.3 第三步:生成质量自动评估
python
# 在RAGEvaluator类中添加以下方法
def evaluate_generation(self) -> Dict:
"""评估生成质量"""
dataset = self.load_evaluation_dataset()
logger.info(f"开始生成质量评估,共{len(dataset)}个样本")
total_faithfulness = 0
total_relevance = 0
total_completeness = 0
hallucination_count = 0
valid_samples = 0
for sample in dataset:
question = sample["question"]
gold_answer = sample["gold_answer"]
try:
# 获取检索上下文和生成回答
docs = self.retriever.retrieve(question)
context = "\n\n".join([doc.page_content for doc in docs])
answer = self.llm.invoke(f"基于以下上下文回答问题:{question}\n上下文:{context}").content
# 用LLM评估生成质量
evaluation_prompt = f"""
请评估以下回答的质量,从三个维度打分(0-1分):
1. 忠实度:回答是否完全基于上下文,没有编造信息
2. 相关性:回答是否与问题相关,是否回答了问题
3. 完整性:回答是否覆盖了问题的所有要点
问题:{question}
上下文:{context}
回答:{answer}
输出格式为JSON,包含"faithfulness"、"relevance"、"completeness"三个字段,值为0-1的数字。
只输出JSON,不要添加任何其他内容。
"""
evaluation = json.loads(self.llm.invoke(evaluation_prompt).content)
total_faithfulness += evaluation["faithfulness"]
total_relevance += evaluation["relevance"]
total_completeness += evaluation["completeness"]
if evaluation["faithfulness"] < 0.5:
hallucination_count += 1
valid_samples += 1
except Exception as e:
logger.warning(f"评估样本失败:{e}")
continue
if valid_samples == 0:
return {}
# 计算平均值
avg_faithfulness = total_faithfulness / valid_samples
avg_relevance = total_relevance / valid_samples
avg_completeness = total_completeness / valid_samples
hallucination_rate = hallucination_count / valid_samples
results = {
"faithfulness": round(avg_faithfulness, 4),
"relevance": round(avg_relevance, 4),
"completeness": round(avg_completeness, 4),
"hallucination_rate": round(hallucination_rate, 4)
}
logger.info("生成质量评估完成")
logger.info(f"忠实度:{results['faithfulness']}, 相关性:{results['relevance']}, 完整性:{results['completeness']}, 幻觉率:{results['hallucination_rate']}")
return results2.4 第四步:生成完整评估报告
python
# 在RAGEvaluator类中添加以下方法
def generate_full_report(self) -> Dict:
"""生成完整的评估报告"""
logger.info("正在生成完整评估报告...")
report = {
"timestamp": int(time.time()),
"retrieval_metrics": self.evaluate_retrieval(),
"generation_metrics": self.evaluate_generation(),
"system_config": {
"chunk_size": settings.chunk_size,
"chunk_overlap": settings.chunk_overlap,
"embedding_model": settings.embedding_model_name,
"retrieval_top_k": settings.retrieval_top_k,
"similarity_threshold": settings.retrieval_similarity_threshold,
"reranker_enabled": settings.reranker_enabled,
"reranker_model": settings.reranker_model_name
}
}
# 保存报告
report_path = Path(f"./data/evaluation_report_{report['timestamp']}.json")
with open(report_path, "w", encoding="utf-8") as f:
json.dump(report, f, ensure_ascii=False, indent=2)
logger.info(f"完整评估报告已保存到:{report_path}")
return report2.5 测试
python
from dotenv import load_dotenv
load_dotenv()
from core.rag_evaluator import RAGEvaluator
from core.rag_service import RAGService
import os
def test_day6_production_rag():
print("🚀 第6天:RAG系统评估、调优与生产化测试\n")
# 1. 初始化
evaluator = RAGEvaluator()
rag = RAGService()
# 2. 生成评估数据集
print("📊 正在生成评估数据集...")
dataset = evaluator.generate_evaluation_dataset(num_samples=50)
print(f"✅ 生成了{len(dataset)}个评估样本\n")
# 3. 检索质量评估
print("🔍 正在进行检索质量评估...")
retrieval_metrics = evaluator.evaluate_retrieval()
print("\n检索质量评估结果:")
for k, metrics in retrieval_metrics.items():
print(f" {k}: Recall={metrics['recall']}, Precision={metrics['precision']}, F1={metrics['f1']}, MRR={metrics['mrr']}")
# 4. 生成质量评估
print("\n✍️ 正在进行生成质量评估...")
generation_metrics = evaluator.evaluate_generation()
print("\n生成质量评估结果:")
print(f" 忠实度:{generation_metrics['faithfulness']}")
print(f" 相关性:{generation_metrics['relevance']}")
print(f" 完整性:{generation_metrics['completeness']}")
print(f" 幻觉率:{generation_metrics['hallucination_rate']}")
# 5. 生成完整评估报告
print("\n📄 正在生成完整评估报告...")
report = evaluator.generate_full_report()
print(f"✅ 评估报告已保存到:data/evaluation_report_{report['timestamp']}.json\n")
if __name__ == "__main__":
test_day6_production_rag()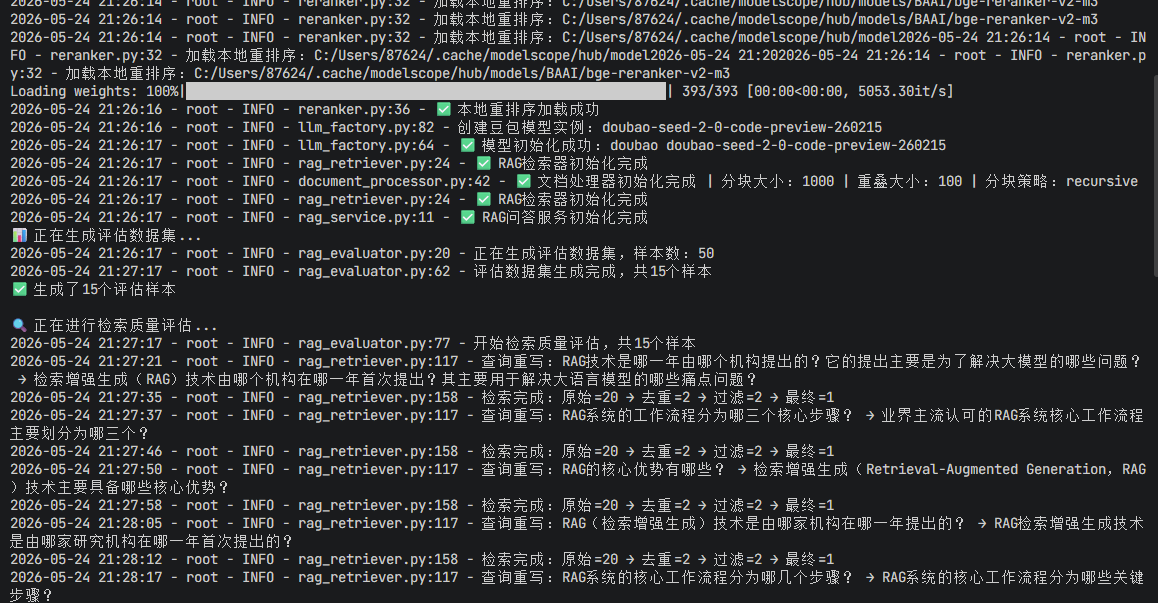
这时候先不要着急启动测试!会反复调用大模型,我们可以使用缓存,将前面已经查询的结果缓存起来。
2.6 多级缓存机制
代码位置 :core/cache.py
python
import json
import hashlib
from pathlib import Path
from typing import Any, Optional
from utils.logger import logger
class LocalCache:
"""本地文件缓存(轻量、无外部依赖)"""
def __init__(self, cache_dir: str = "./data/cache"):
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(parents=True, exist_ok=True)
def _get_cache_key(self, key: str) -> str:
"""生成缓存键"""
return hashlib.md5(key.encode("utf-8")).hexdigest()
def get(self, key: str) -> Optional[Any]:
"""获取缓存"""
cache_key = self._get_cache_key(key)
cache_file = self.cache_dir / f"{cache_key}.json"
if not cache_file.exists():
return None
try:
with open(cache_file, "r", encoding="utf-8") as f:
return json.load(f)
except Exception as e:
logger.warning(f"读取缓存失败:{e}")
return None
def set(self, key: str, value: Any, ttl: int = 3600):
"""设置缓存(ttl单位:秒)"""
cache_key = self._get_cache_key(key)
cache_file = self.cache_dir / f"{cache_key}.json"
try:
with open(cache_file, "w", encoding="utf-8") as f:
json.dump({
"value": value,
"expire_time": int(time.time()) + ttl
}, f, ensure_ascii=False)
except Exception as e:
logger.warning(f"写入缓存失败:{e}")
def get_or_set(self, key: str, func, ttl: int = 3600) -> Any:
"""获取缓存,如果不存在则执行函数并缓存结果"""
value = self.get(key)
if value is not None and value["expire_time"] > time.time():
return value["value"]
value = func()
self.set(key, value, ttl)
return value
# 全局缓存实例
query_cache = LocalCache("./data/cache/query")
embedding_cache = LocalCache("./data/cache/embedding")
retrieval_cache = LocalCache("./data/cache/retrieval")集成到 RAGRetriever:
python
# 在RAGRetriever.__init__中添加
from core.cache import query_cache, embedding_cache, retrieval_cache
# 修改retrieve方法
def retrieve(self, query: str, top_k: int = None, similarity_threshold: float = None, filter: dict = None):
# 缓存键
cache_key = f"{query}_{top_k}_{similarity_threshold}_{str(filter)}"
# 尝试从缓存获取
cached = retrieval_cache.get(cache_key)
if cached is not None and cached["expire_time"] > time.time():
logger.debug(f"从缓存获取检索结果:{query}")
return [Document(**doc) for doc in cached["value"]]
# 原检索逻辑...
# 缓存结果
retrieval_cache.set(cache_key, [doc.dict() for doc in final_docs], ttl=3600)
return final_docs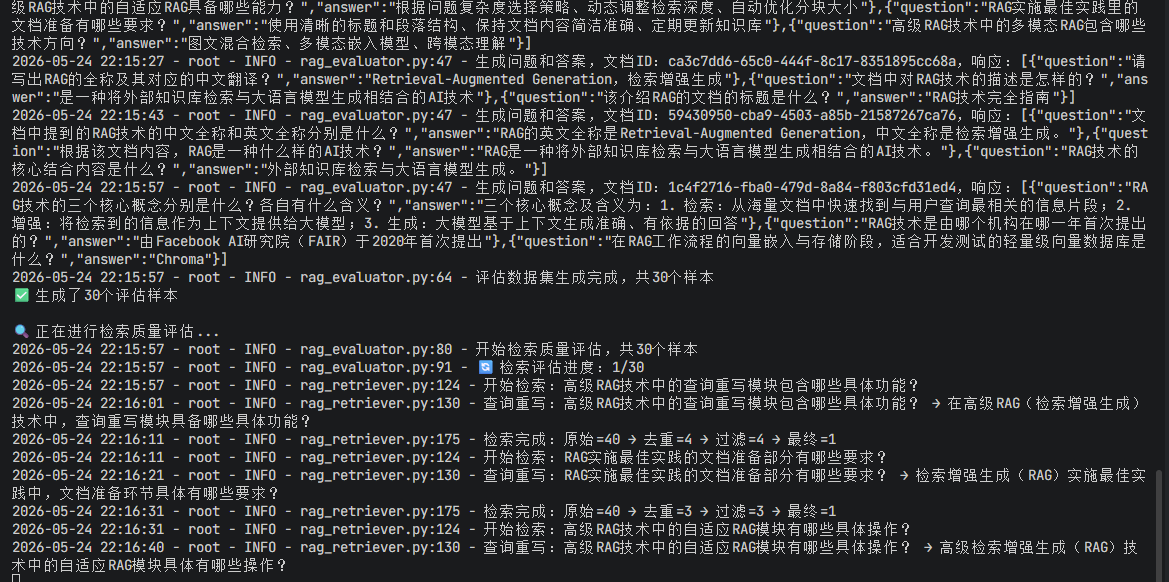
上面的缓存键保留了top_k,所以缓存的时候会有很多缓存文件
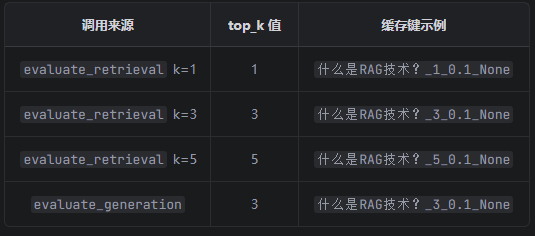
评估过程中每个问题在评估过程中被调用 4 次 :
优化
如果想减少缓存文件,可以修改缓存键策略,不包含 top_k :
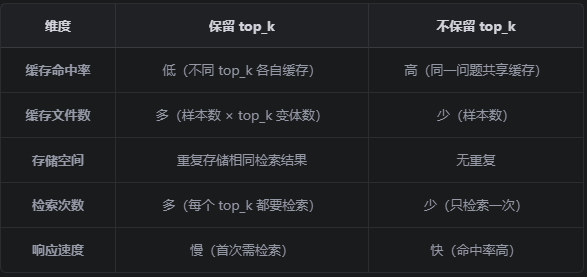
python
# 缓存键(不包含 top_k,提高缓存命中率)
cache_key = f"{query}_{similarity_threshold}_{str(filter)}"获取时
python
# 尝试从缓存获取
cached = retrieval_cache.get(cache_key)
if cached is not None and cached["expire_time"] > time.time():
logger.debug(f"从缓存获取检索结果:{query}")
all_cached_docs = [Document(**doc) for doc in cached["value"]]
return all_cached_docs[:top_k] if top_k else all_cached_docs