本文主要介绍ACT的演变进程,包括VE、VAE、CVAE以及ACT。
一、简介
ACT算法全称为Action Chunking with Transformers,论文主要内容为如何使用低成本的硬件和模仿学习算法来实现双机械臂操作。截至到25年年底,各公司采用的demo,大部分都是基于ACT算法进行的开发,省时省力,可以解决传统算法中的操作困难问题。
该算法由AE->VAE->CVAE->ACT逐步演进而来。
二、AE(自动编码器)框架
AE是一种无监督学习方法,原理很简单:先将高维的原始数据映射到一个低维特征空间,然后从低维特征学习重建原始的数据。
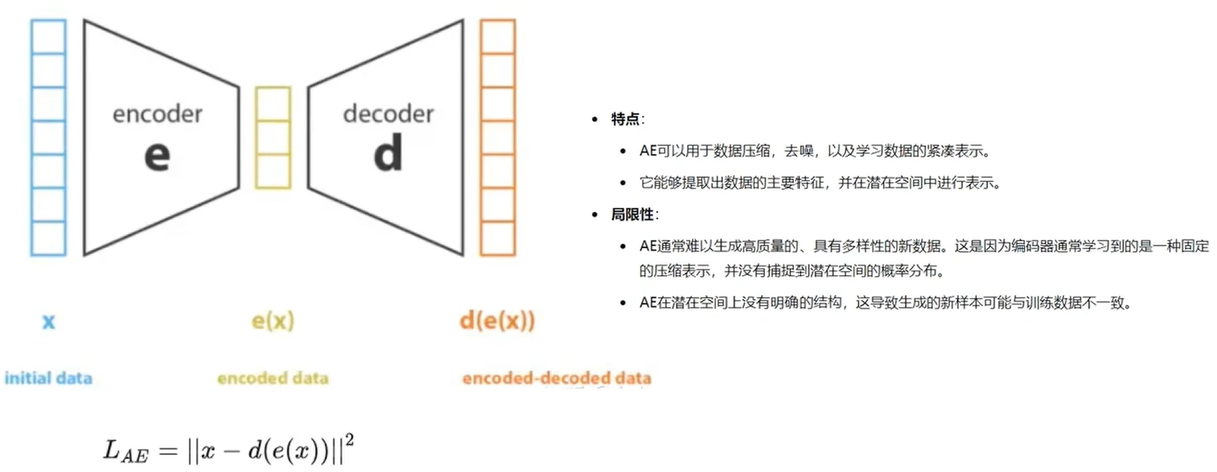
如上图所示,自动编码器主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器和解码器可以看作是两个函数,一个用于将高维输入(如图片)映射为低维数值编码(code),另一个用于将低维数值编码(code)映射为高维输出(如生成的图片)。
存在问题:
通过低维数值编码进行转换生成的操作,在训练过程中,随着不断降低输入图片与输出图片之间的误差,模型会过拟合,泛化性能不好,即只能生成特定的图片。
三、VAE(变分自动编码器)框架
3.1 主要创新点及框架
主要创新点:encoder中引入了重参数化技巧。
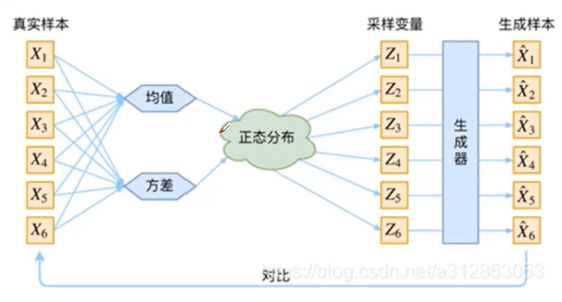
具体:VAE通过将AE中的code替换为某个连续的分布(标准正态分布),并从该分布中采样得到一个随机数或随机向量,然后decoder对该随机数或随机向量进行解码;最终的生成样本是一个接近真实样本但又不完全一样的样本。
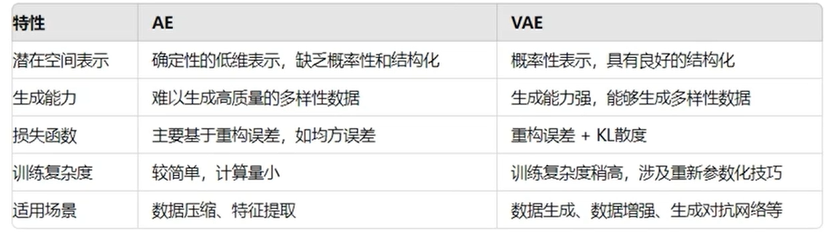
VAE和AE的总结与比较:
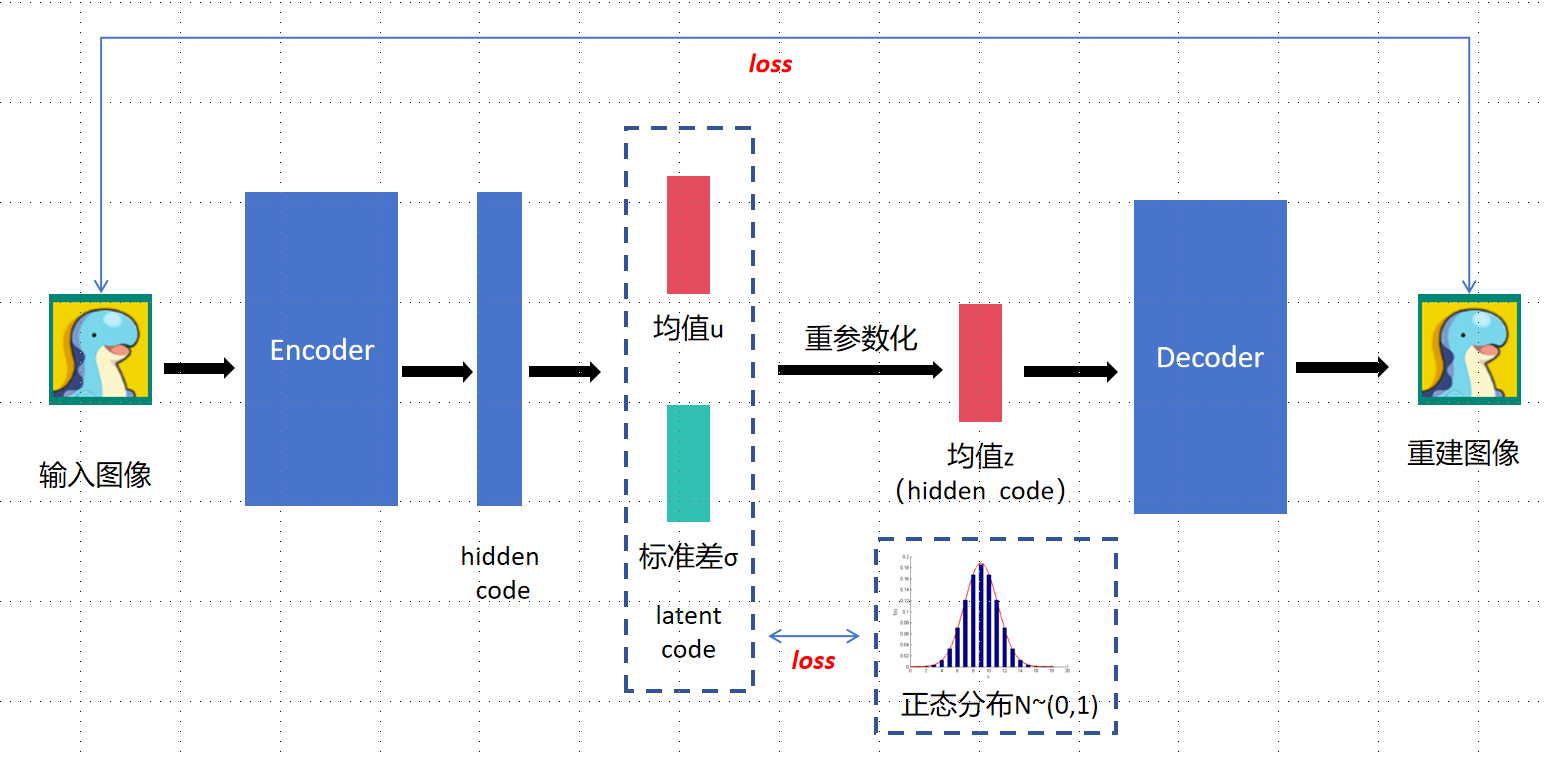
整体架构:输入图像会解析成均值和标准差两个部分,然后通过正态分布来重参数化获得均值Z,VAE计算以下两方面之间的损失:
3.2 VAE损失
重构损失(Reconstruction Loss):这一部分的损失计算的是输入数据与重构数据之间的差异。(输入和输出贴近)
KL散度(Kullback-Leibler Divergence Loss):这一部分的损失衡量的是学习到的潜在表示的分布与先验分布(通常假设为标准正态分布)之间的差异。
3.3 为什么使用重参数化
重参数化技巧是用来解决梯度无法通过随机节点有效传递的问题。在VAE的训练过程中,编码器输出的是一个潜在空间的分布的参数,通常是一个高斯分布的均值和方差。为了生成潜在变量的样本,我们从这个分布中采样;在不使用重参数化的情况下,模型会直接从参数化的分布(例如,正态分布,由均值 μ 和方差 σ2 参数化)中采样,这使得梯度无法回传。
为了允许梯度回传,VAE使用了重参数化技巧。具体来说,它将采样步骤表达为一个确定性的变换。例如,如果潜在变量z假设服从均值为μ、方差为σ2的高斯分布,那么采样步骤可以写为:
其中,ϵ 是从标准正态分布 N(0,I)中采样的噪声,ϵ是独立的,不依赖于任何参数。
重参数化技巧通过引入一个不依赖于模型参数的外部噪声源 (从标准正态分布中抽取的 ϵ),并对这个噪声与模型的均值和方差进行变换,来生成符合目标分布的样本 。这样,模型的随机输出(z)就可以表示为 μ 和 σ 的梯度**和一个随机噪声的组合,**便可以完成梯度回传。
3.4 存在的局限性
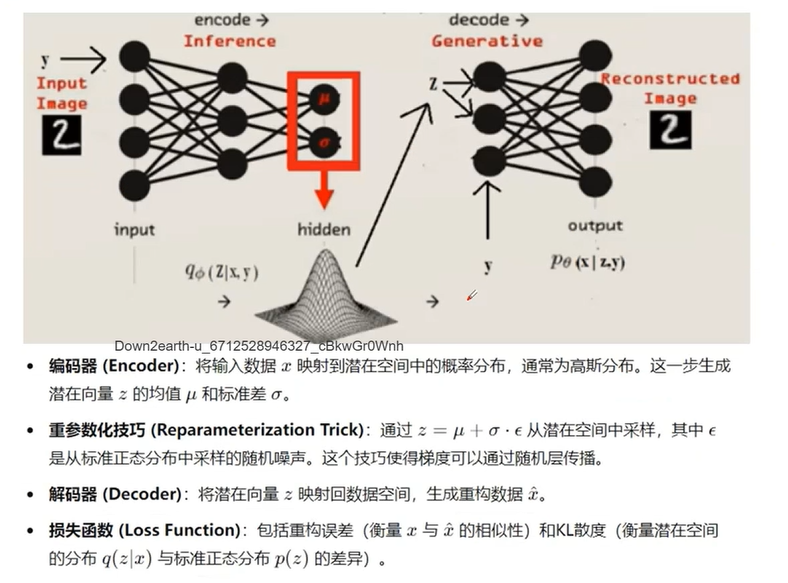
如上图所示:输入数字2,随机输出2(比如不同字体),无法规定特定的字体、特定的格式。
四、CVAE(条件变分自编码器)框架
框架图如下图所示:
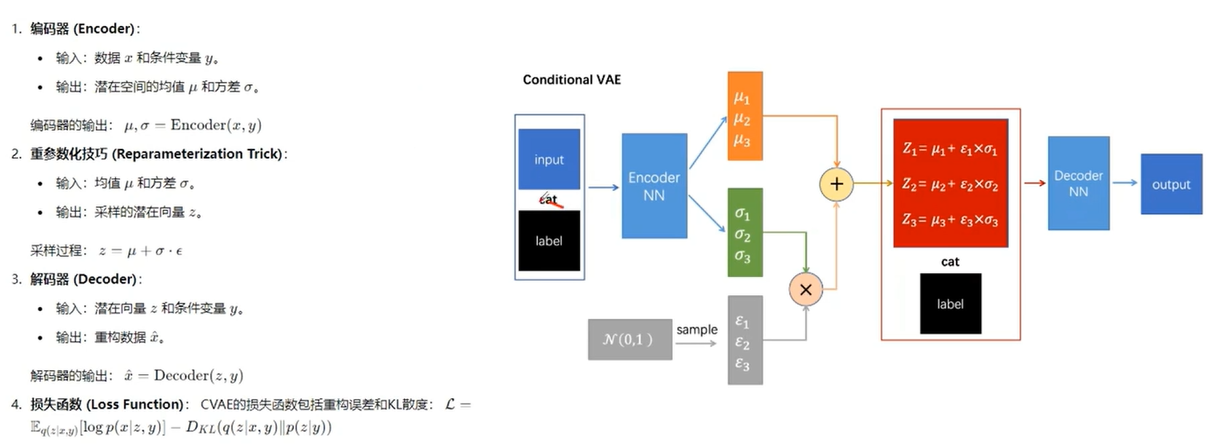
CVAE是VAE的一种扩展,它能够在生成过程中引入额外的信息(条件),以控制生成结果的某些属性。整体结构和VAE相似,区别是在将数据输入Encoder时把数据内容与其标签(label)合并(cat)输入,将编码(z)输入Decoder时把编码内容与数据标签(label)合并(cat)输入。但label并不参与Loss计算,CVAE损失和VAE的一样,input与output的重构损失和潜在表示分布与先验分布的KL散度损失。
五、CVAE --> ACT
在 ACT 中,CVAE 的解码器 是一个完整的 Transformer 编码器-解码器对,编码器处理复杂观察,解码器生成动作序列。因为单一Transformer解码器需要输入token逐步"翻译"动作,但原始图像信息结构复杂,不适合直接拼进去。
5.1 ACT模型结构图
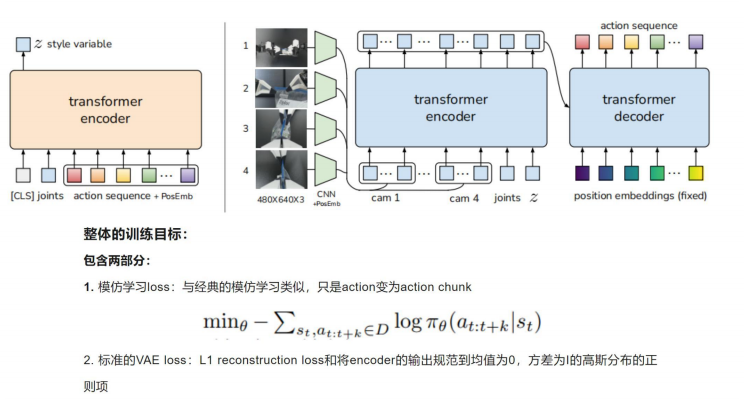
ACT目标是机器人领域,上图右侧为:将图像作为编码器,然后关节角度+动作信息作为解码器,从而生成动作序列。而左侧主要的就是一个编码器,其会用到右侧的解码器输出动作信息以及角度信息,来输出一个z。
5.2 ACT模型算法流程
1)采样数据,以获得CVAE编码器的输入中的关节位置和动作序列

输入:包括4张RGB图像,每张图像的分辨率 为480 ×640,以及两个机器人手臂的关节位置(总共7+7=14 DoF);
输出:动作空间是两个机器人 的绝对关节位置,一个14维向量;
通过动作分块,策略在给定当前观测的情况下输出一个k ×14张量(每个动作都被定义为一个14维的向量,所以k个动作自然便是一个k ×14张量)
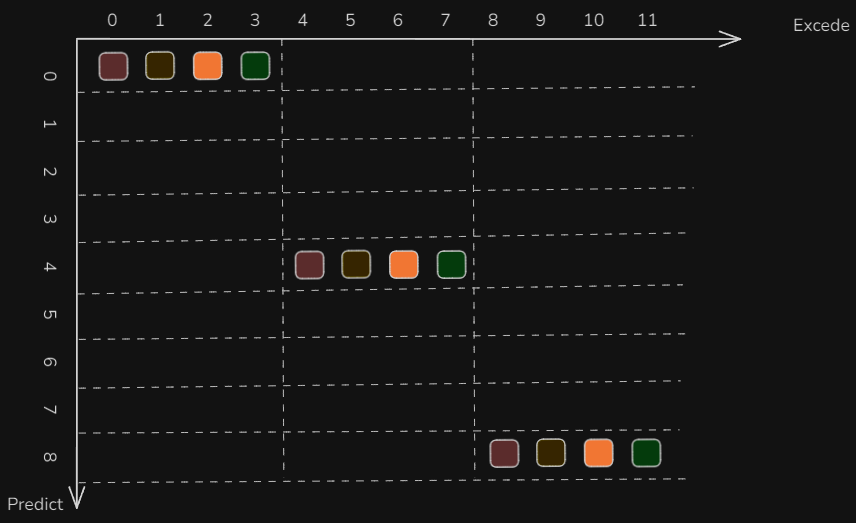
动作分块:
目的:解决累计误差
通俗解释:举例(下棋时),单步策略,一个时间步,只做一个决策;而动作块策略,就是k个时间步,做一个决策。
 ---->
----> 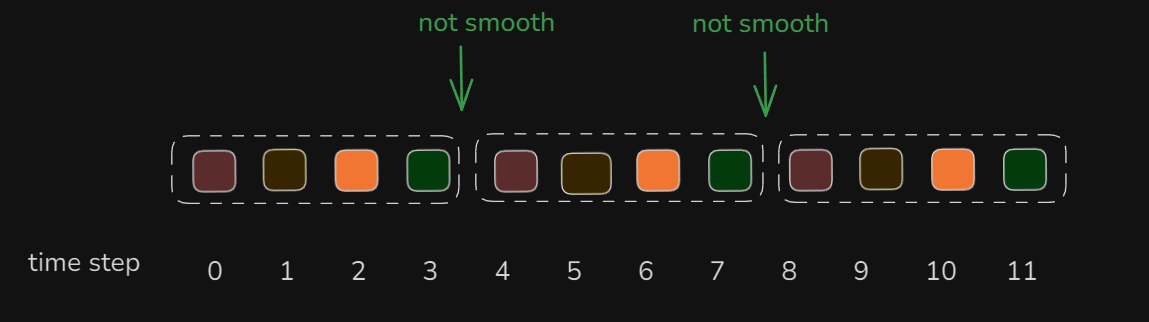
t=0的时候,规划了4个动作,让机器人去执行,横轴是机器人的执行时间。在纵轴t=4的时候,机器人又规划了四个动作。在纵轴t=8的时候,机器人又规划了四个动作。通过动作分块,做了3次决策,产生了12个动作,机器人可以从t=0执行到t=11(横轴)。
但中间会出现每个块之间,动作没有衔接、可能不够平滑,针对此作者提出了**Temporal Ensembling的概念,**用来做时间平滑预测,简单理解就是做加权平均。
比如下图中:在t=3时最终采用什么动作,由t=0,t=1,t=2,t=3这四段进行指数加权平均,来得到最终的结果。

2)推断z,以获得CVAE编码器中的风格变量z
使用下图右侧黄色所示的CVAE编码器推断风格变量z:
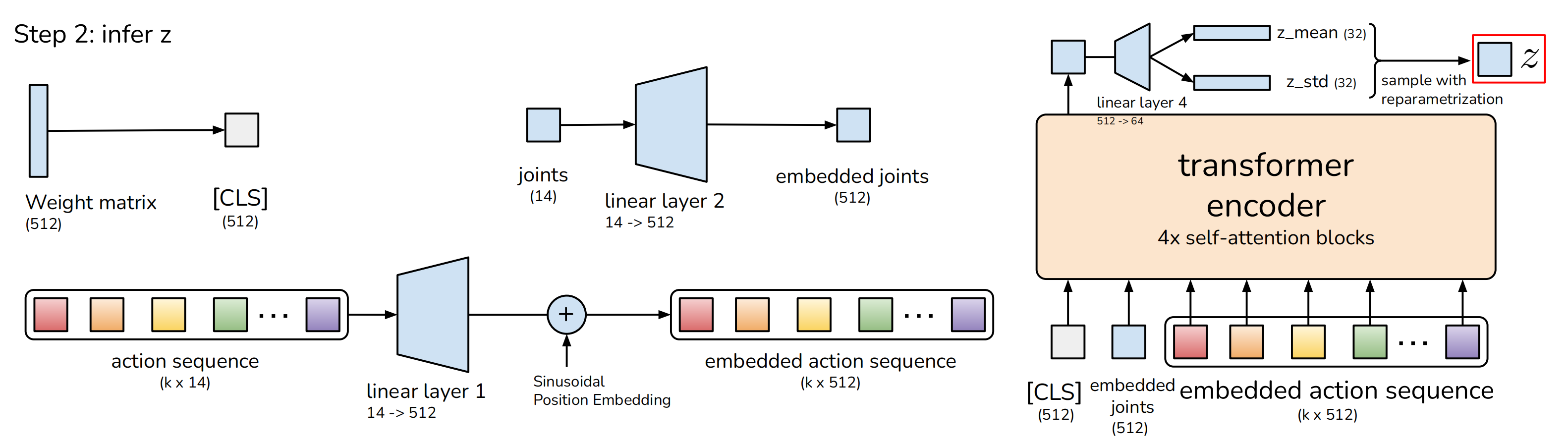
CVAE 编码器的输入目前包括:
① CLS token,它由随机初始化的学习权值组成
② 嵌入关节位置embedded joints:通过一个线性层linear layer2,把joints投影到嵌入维度的关节位置(14维到512维),得到:embedded joints
③ 嵌入动作序列embedded action sequence:通过另一个线性层linear layer1,把k × 14的action sequence投影到嵌入维度的动作序列(k × 14维到k × 512维)
以上三个输入最终形成(k + 2)×embedding_dimension的序列,即(k + 2) × 512,并用CVAE 编码器中的transformer编码器进行处理
CVAE 编码器输出:
只取第一个输出,它对应于CLS标记,并使用另一个线性网络来预测分布的均值和方差,将其参数化为对角高斯分布,且使用重参数化获得
的样本。
3)CVAE解码器预测动作序列
接下来,尝试从CVAE解码器中获得预测的动作,即策略(预测动作序列):
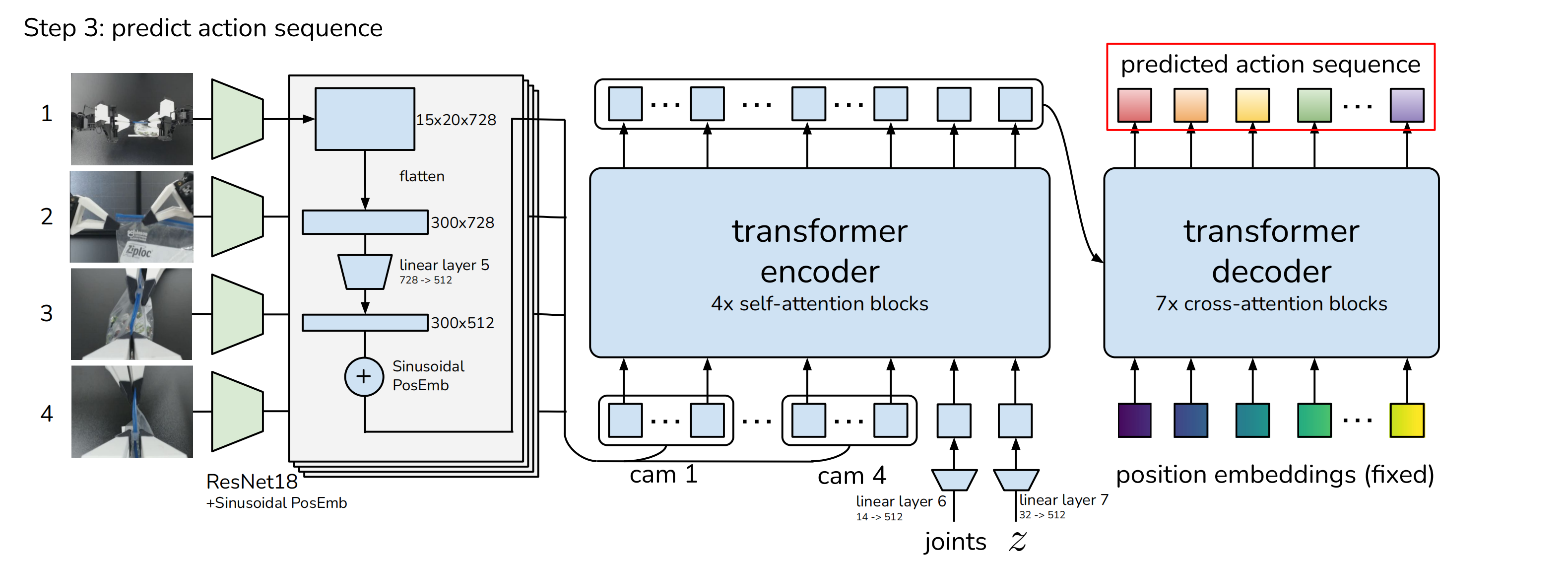
① 首先,transformer encoder的输入:
CVAE解码器中transformer解码器的输入有两个方面:
q:正弦位置输入
k、v:transformer编码器的输出。
解释如下:
对于每一个图像,其被ResNet18处理以获得一个特征图:
480×640×3 --> 经过resize、flatten化和线性层linear layer投影 --> 300×512的特征序列; 为保留空间信息,再添加一个2D正弦位置信息嵌入(即Sinusoidal PosEmb)到特征序列中;对所有4张图像重复此操作,得到一个4 × 300 × 512,即1200 ×512维度的特征序列;将来自每个摄像机的特征序列连接起来,作为CVAE解码器中transformer encoder的输入之一;
其次,对于另外两个输入:当前的关节位置joints和"风格变量"z,它们分别通过线性层linear layer6、linear layer7从各自的原始维度(14、32)都统一投影到512;
最终,the input to the transformer encoder is 1202×512:
4张图像的特征维度1200×512 + 关节位置joins的特征维度1×512 + 风格变量z的特征维度1×512 ;
② transformer decoder 的输出是 k * 512,为了与机械臂关节维度吻合,通过 MLP 降维到 k * 14,对应于接下来k个步骤的预测目标关节位置;
最终,使用L1损失进行重建,而不是更常见的L2损失:且注意到,L1损失导致对动作序列进行更精确的建模。