Github: https://github.com/real-stanford/universal_manipulation_interface
目录
1.重点内容
代码仓库:
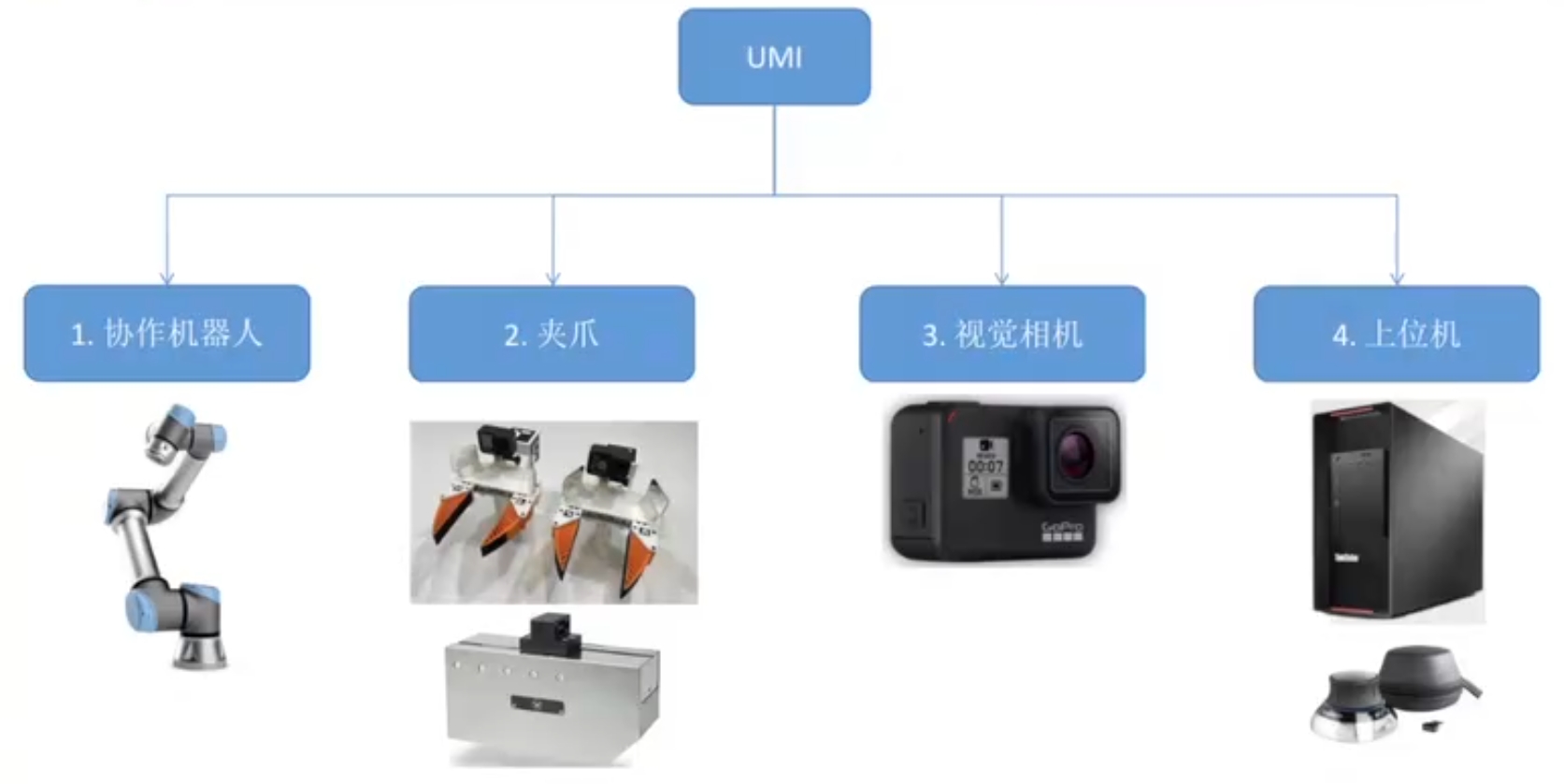
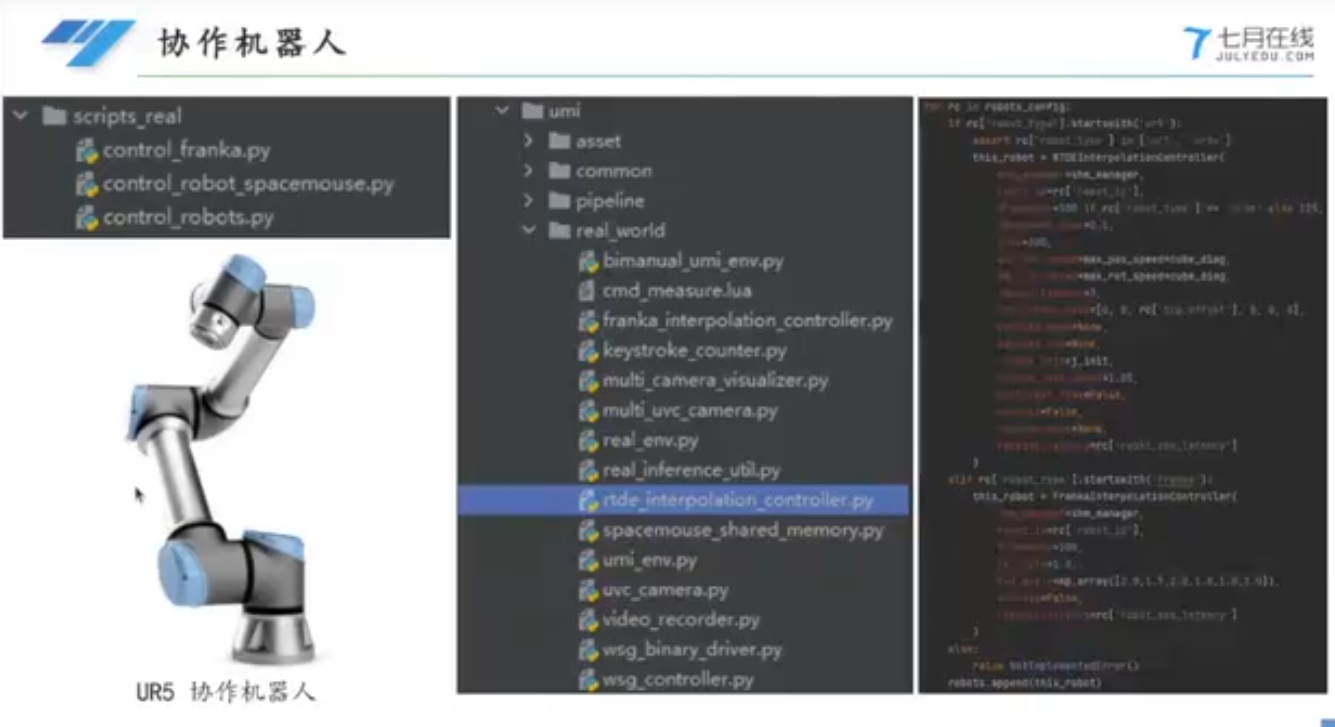
scripts和scripts_real文件夹:里面的脚本可以直接运行,测试脚本umi文件夹:建立扩散策略和机器人本体之间的两个关系对应,umi/real_world/rtde_interpolation_controller.pyUR机器人控制程序umi/real_world/wsg_binary_driver.py、umi/real_world/wsg_controller.py:夹爪控制程序umi/real_world/uvc_camera.py: 视觉相机(坑:建议使用GoPro9),首先得保证是鱼眼相机,因为鱼眼相机能够聚焦于中间的位置,其次鱼眼相机的标定和针孔相机标定不一样,不能使用张正友的标定方法,需要用别的算法进行计算,目前开源的有(https://github.com/urbste/OpenImuCameraCalibrator),是基于纯视频解算的,OpenImuCameraCalibrator文档中已经验证测试了GoPro 9和GoPro 6两款相机的标定精度,计算了相机内参和提取IMU数据。
IMU数据可以将人手采集的数据平移到机器人设备上
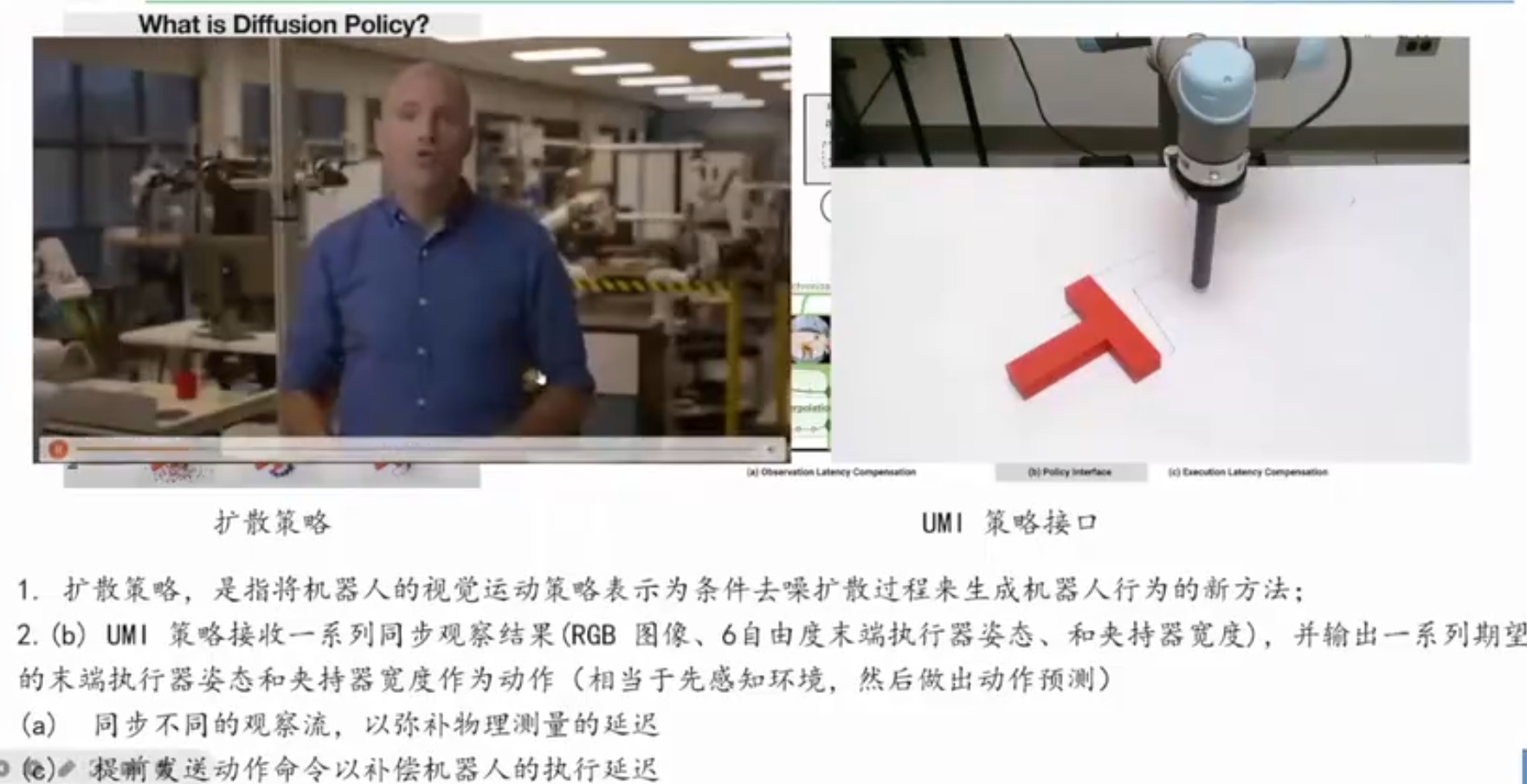
diffusion policy核心:将看到的视频输出成机器人的运动轨迹。
UMI的扩散策略:接收一系列的同步的观察结果(包含rgb图像、末端执行器的pose、夹爪的开合度)的多模态输入,输出末端执行器的姿态和夹爪的开合度。
Dexcap和Umi的区别:Dexcap输入的是两个腕部相机和头顶相机的SLAM轨迹,而不是Umi的rgb图像。


相关截图








2.论文研读
-
1.Q:推理时延迟匹配是什么意思?

推理时延迟匹配和相对轨迹动作表示(policy interface with inference-time latency matching and a relative-trajectory action representation)
-
2.Q:推理时延迟匹配

其次,我们探索了一种硬件无关的策略接口(即观测和动作表示),以实现有效的技能迁移。具体来说,我们采用推理时延迟匹配来处理不同的传感器观测和执行延迟,使用相对轨迹作为动作表示以无需精确的全局动作,最后应用扩散策略 9 来建模多模态动作分布。
Second, we explore the right policy interface (i.e., observation and action representations) that could make the policy hardware-agnostic and thereby enable effec-tive skill transfer.Concretely, we employ inference-timelatency matching to handle different sensor observation and execution latency, use relative trajectory as action representation to remove the need for precise global action, and finally, apply Diffusion Policy 9 to model multimodal action distributions.
-
3.Q:采数据和推理部署都要用同样的鱼眼相机?

以及在教学和测试阶段使用相同的鱼眼腕部安装摄像头。
the shared Fisheye wrist-mounted cameras during teaching and testing.
-
4.Q:ORB---SLAM3

相比之下,UMI 将最先进的同步定位与地图构建(SLAM)6 与 GoPro 的内置 IMU 数据相结合,能够在全局尺度上准确捕捉 6 自由度动作。
In contrast, UMI integrates state-of-the-art SLAM 6 with built-in IMU data from GoPro, to accurately capture 6DoF actions at theglobal scale.
-
5.A:在观测视野范围一样大的情况下,因为鱼眼相机更关注于中心区域的视野,倘若采用针孔式相机,中心关注的区域会很小。
图3:鱼眼镜头与广角镜头 (a) 超微成像(UMI)策略使用原始鱼眼图像作为观测数据。 (b) 将一张155°的大视场图像校正为针孔模型会严重拉伸周边视图(蓝线外),同时将中心最重要的信息压缩到一个小区域(红线内)。
Fig. 3: Fisheye vs Rectilinear (a) UMI policies use raw Fisheye image as observation. (b) Rectifying a large 155° FoV image to the pin-hole model severely stretches the peripheral view (outside of blue line), while compresses the most important information at the center to a small area (inside of red line).

-
6.A:相机安装在两个夹爪中间,无需进行标定

机械稳健性:由于相机相对于手指机械固定,将 UMI 安装在机器人上无需进行相机 - 机器人 - 世界校准。
Mechanical robustness. Because the camera is mechanically fixed relative to the fingers, mounting UMI on robots does not require camera-robot-world calibration.
-
7.A:因为相机视野聚焦于视野中心区域,相当于给模型训练时,弱化了周围的信息,等同于随机裁减ROI区域
相机运动实现自然的数据多样化:实验中我们发现一个额外优势 ------ 使用移动相机训练时,策略会学习关注与任务相关的物体或区域,而非背景结构(效果类似于随机裁剪)。因此,最终策略在推理时自然对干扰物更具稳健性。
Camera motion for natural data diversification. A side benefit we observed from experiments is that when training with a moving camera, the policy learns to focus on task-relevant objects or regions instead of background structures(similar in effect to random cropping). As a result, the finalpolicy naturally becomes more robust against distractors atinference time.

-
8.A:意思是通过眼在手上的鱼眼相机,不依赖于眼在手外那种视觉基站

避免使用外部静态相机也给下游策略学习带来了额外挑战。例如,策略现在需要处理非平稳和部分观测。我们通过使用大视场鱼眼镜头(HD2)和稳健的视觉跟踪(HD4)缓解了这些问题,具体将在以下部分说明。
Avoiding use of external static cameras also introduce additional challenges for downstream policy learning. For example, the policy now needs to handle non-stationary and partial observations. We mitigated these issues by leveraging wide-FoV Fisheye Lens HD2, and robust visual tracking HD4, described in the following sections.
-
9.A:进一步说明安装在两侧镜子的作用,增加立体深度估计,还有当中间相机有盲区时,左右两个相机可以观测到
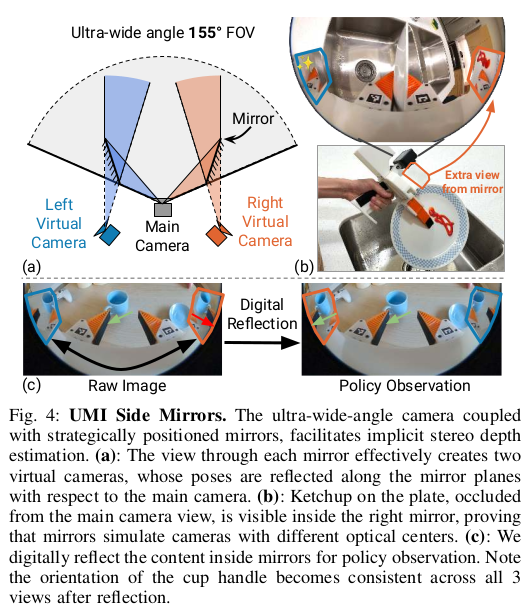
图4:超广角成像(UMI)侧镜。超广角摄像头与巧妙放置的镜子相结合,有助于实现隐式立体深度估计。(a):通过每个镜子看到的景象实际上创建了两个虚拟摄像头,其姿态沿着镜子平面相对于主摄像头进行反射。(b):盘子上的番茄酱被主摄像头遮挡,但在右侧镜子中可见,证明镜子模拟了具有不同光学中心的摄像头。(c):我们通过数字方式反射镜子中的内容以进行策略观察。注意,反射后杯柄的方向在所有三个视图中保持一致。
Fig. 4: UMI Side Mirrors. The ultra-wide-angle camera couple with strategically positioned mirrors, facilitates implicit stereo depth estimation. (a): The view through each mirror effectively creates two virtual cameras, whose poses are reflected along the mirror planes with respect to the main camera. (b): Ketchup on the plate, occluded from the main camera view, is visible inside the right mirror, proving that mirrors simulate cameras with different optical centers. ©: We digitally reflect the content inside mirrors for policy observation. Note the orientation of the cup handle becomes consistent across all 3views after reflection.
-
10.Q:没明白,数字反射后,镜子里面看到的物体方向与主相机视图中的方向相反

HD3. 用于隐式立体视觉的侧镜
为了缓解单目相机视图缺乏直接深度感知的问题,我们在相机边缘视野中放置了一对物理镜子,在同一图像中创建隐式立体视图。如图 4(a)所示,镜子中的图像相当于从沿镜面反射的额外相机中看到的内容,无需额外成本和重量。为了利用这些镜子视图,我们发现对镜子中的图像区域进行数字反射(如图 4(c)所示)能为策略学习带来最佳效果(第 V-A 节)。需要注意的是,若不进行数字反射,通过侧镜看到的物体方向与主相机视图中的方向相反。
HD3. Side mirrors for implicit stereo. To mitigate the lack of direct depth perception from the monocular camera view, we placed a pair of physical mirrors in the cameras' peripheral view which creates implicit stereo views all in the same image. As illustrated in Fig 4 (a), the images inside the mirrors are equivalent to what can be seen from additional cameras reflected along the mirror plane, without the additional cost and weight. To make use of these mirror views, we found that digitally reflecting the crop of the images in the mirrors, shown in Fig 4 ©, yields the best result for policy learning (Sec. V-A). Note that without digital reflection, the orientation of objects seen through side mirrors is the opposite of that in the main camera view.
-
11.惯性测量单元感知跟踪

UMI 利用 GoPro 的内置功能,将 IMU 数据(加速度计和陀螺仪)记录到标准 mp4 视频文件中 18,从而能够捕捉具有绝对尺度的快速运动。基于 ORB-SLAM3 7 的惯性 - 单目 SLAM 系统,通过联合优化视觉跟踪和惯性姿态约束,即使在因运动模糊或缺乏视觉特征(如俯视桌面)导致视觉跟踪失败的情况下,仍能在短时间内维持跟踪。这使得 UMI 能够捕捉并部署高度动态的动作(如投掷,如图 7 所示)。此外,视觉 - 惯性联合优化能够直接恢复真实的度量尺度,这对于动作精度和夹具间姿态本体感知(PD2.3)至关重要 ------ 这是实现双手协同策略的关键因素。
-
12.夹爪采集的数据不是0和1(开和合),可以理解为映射到0-1之间的值,如果夹爪支持的话也可以表示夹爪的开合大小。

与现有研究中使用的二进制开合动作 41, 44, 54 不同,我们发现连续控制夹具宽度能显著扩展平行夹爪夹具可完成的任务范围。例如,投掷任务(图 7)需要精确的物体释放时机。由于物体宽度不同,二进制夹具动作难以满足精度要求。在 UMI 夹具上,手指宽度通过基准标记 16 进行连续跟踪(图 2 左侧)。利用串联弹性末端执行器原理 42,UMI 可以通过连续控制夹具宽度来调节软指的形变,从而隐式记录和控制抓取力。
-
13.因为UMI在采集轨迹的过程中,以起始点作为轨迹的原点,之后的点都是存储的相对位姿即Delta pose,由于脱离了机器人本体,需要对轨迹的可行性进行校验。

虽然数据收集过程与机器人无关,但我们应用简单的基于运动学的数据过滤,为不同机器人形态选择有效的轨迹。具体而言,当已知机器人的基座位置和运动学时,SLAM 恢复的绝对末端执行器姿态可以对演示数据进行运动学和动力学可行性过滤。在过滤后的数据集上训练,可确保策略符合特定形态的运动学约束。
-
14.策略接口设计

-
15.Q:关于时间同步这一部分,观测延迟匹配能理解,采集数据时做了数据的时间同步,但是动作延迟匹配这里没明白,提前发送是为什么?

-
16.Q:夹具间相对于本体感知?

-
17.A:说明UMI采集的轨迹,可行性还是喝机器人选择的起点或者臂型强相关的

-
18.A:说明了鱼眼镜头的重要性

-
19.Q:是否使用绝对空间

-
20.A:左右两侧镜子的影响,需要进行数字反射
